Не так давно было много шума об инициатике CommonMark по унификации маркдауна. Казалось бы, наконец-то в этой замечательной разметке наступит порядок. Но на практике не все так просто. Сейчас ведется работа над базовым синтаксисом, и до расширений дело дойдет не скоро. Ждать год с лишним могут не все. Но разработки спецификаций — это скорее научная работа. Нас же интересует практика — как приворачивать маркдаун к конкретным проектам.
Что же может потребоваться программисту от хорошего парсера маркдауна? Ну конечно же не скорость :). А нужна на самом деле возможность добавлять свои расширения синтаксиса. К сожалению, во всех реализациях парсеров, что я до этого встречал, логика разбора разметки приколочена намертво. Все что остается — ковырять гвоздиком конечный результат и надеяться что конфликтов не случится. Конечно, гарантировать при этом надежный выхлоп невозможно. Можно пойти другим путем — попробовать заслать патч в апстрим. Но тут нет ни каких гарантий, что синтаксис вашего расширения будет нужен кому-то еще кроме вас, и что ваш код будет принят.
Как же быть? К счастью, теперь у нас есть markdown-it!
Чем же markdown-it отличается от других парсеров?
1. Возможность менять правила парсинга. От мнения авторов проекта вы теперь не зависите — делайте свой плагин и будьте счастливы.
2. Строгое следование CommonMark.
3. Поддержка таблиц и перечеркнутого текста, как на гитхабе. В ближайшее время авторы планируют добавить остальные популярные расширения.
4. Всякие бонусные плюшки вроде типографа, правила которого тоже можно дополнять.
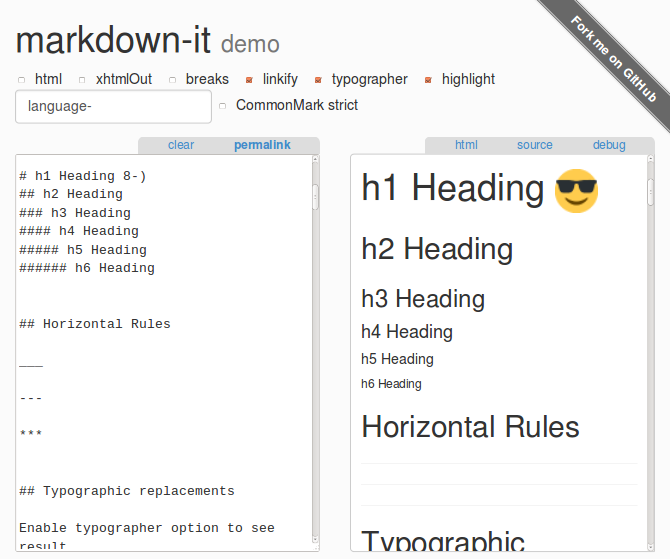
Демо
Самое забавное, что при всей разухабистой системе плагинов парсер работает очень быстро. Он в 2-3 раза обгоняет референсный парсер, написанный на яваскрипте, а варианту на С по прикидкам должен проигрывать всего раза в два. Видимо сказывается опыт разработчиков. В свое время я уже писал про их порт zlib, показывающий впечатляющую скорость.
Что еще полезного в парсере с практической точки зрения? Полностью отпадает необходимость в использовании встроенного HTML (ведь можно добавить все нужное через плагины). Соответственно, отпадает необходимость в валидаторах для защиты от XSS. Это очень удобно, особенно для браузеров, куда не затащить развесистые серверные пакеты вроде OWASP.
В общем, результат очень впечатлает, потому что построение конфигурируемого парсера задача сама по себе непростая, даже если не думать о скорости. Ну и практическая польза очевидна.
Адрес проекта на гитхабе — github.com/markdown-it/markdown-it
Что же может потребоваться программисту от хорошего парсера маркдауна? Ну конечно же не скорость :). А нужна на самом деле возможность добавлять свои расширения синтаксиса. К сожалению, во всех реализациях парсеров, что я до этого встречал, логика разбора разметки приколочена намертво. Все что остается — ковырять гвоздиком конечный результат и надеяться что конфликтов не случится. Конечно, гарантировать при этом надежный выхлоп невозможно. Можно пойти другим путем — попробовать заслать патч в апстрим. Но тут нет ни каких гарантий, что синтаксис вашего расширения будет нужен кому-то еще кроме вас, и что ваш код будет принят.
Как же быть? К счастью, теперь у нас есть markdown-it!
Чем же markdown-it отличается от других парсеров?
1. Возможность менять правила парсинга. От мнения авторов проекта вы теперь не зависите — делайте свой плагин и будьте счастливы.
2. Строгое следование CommonMark.
3. Поддержка таблиц и перечеркнутого текста, как на гитхабе. В ближайшее время авторы планируют добавить остальные популярные расширения.
4. Всякие бонусные плюшки вроде типографа, правила которого тоже можно дополнять.
Демо
Самое забавное, что при всей разухабистой системе плагинов парсер работает очень быстро. Он в 2-3 раза обгоняет референсный парсер, написанный на яваскрипте, а варианту на С по прикидкам должен проигрывать всего раза в два. Видимо сказывается опыт разработчиков. В свое время я уже писал про их порт zlib, показывающий впечатляющую скорость.
Что еще полезного в парсере с практической точки зрения? Полностью отпадает необходимость в использовании встроенного HTML (ведь можно добавить все нужное через плагины). Соответственно, отпадает необходимость в валидаторах для защиты от XSS. Это очень удобно, особенно для браузеров, куда не затащить развесистые серверные пакеты вроде OWASP.
В общем, результат очень впечатлает, потому что построение конфигурируемого парсера задача сама по себе непростая, даже если не думать о скорости. Ну и практическая польза очевидна.
Адрес проекта на гитхабе — github.com/markdown-it/markdown-it
