Содержание курса
- Статья 1: алгоритм Брезенхэма
- Статья 2: растеризация треугольника + отсечение задних граней
- Статья 3: Удаление невидимых поверхностей: z-буфер
- Статья 4: Необходимая геометрия: фестиваль матриц
- 4а: Построение перспективного искажения
- 4б: двигаем камеру и что из этого следует
- 4в: новый растеризатор и коррекция перспективных искажений
- Статья 5: Пишем шейдеры под нашу библиотеку
- Статья 6: Чуть больше, чем просто шейдер: просчёт теней
Улучшение кода
Official translation (with a bit of polishing) is available here.
Построение перспективного искажения
Четвёртая статья будет разбита на две, первая часть говорит про построение перспективного искажения, вторая про то, как двигать камеру и что из этого следует. Задача на сегодня — научиться генерировать вот такие картинки:

Геометрия на плоскости
Линейные преобразования плоскости
Линейное на плоскости отображение задаётся соответствующей матрицей. Если мы возьмём точку (x,y), то её преобразование записывается следующим образом:

Самое простое (невырожденное) преобразование задаётся единичной матрицей, оно просто оставляет каждую точку на месте

Коэффициенты на диагонали матрицы задают растягивание/сжатие плоскости. Давайте проиллюстрируем картинкой: например, если мы запишем следующее преобразование:

То белый объект (квадрат с отрезанным углом) преобразуется в жёлтый. Красный и зелёный отрезки дают единичные векторы по оси x и y, соответственно.

Все картинки к этой статье сгенерированы вот этим кодом.
Зачем вообще использовать матрицы? Потому что это удобно. Начнём с того, что в матричной форме преобразование всего объекта можно записать вот таким образом:

Здесь преобразование то же, что и в предыдущем примере, а вот матрица в две строки и пять столбцов не что иное, как массив координат нашего куба с обрезанным углом. Мы просто взяли целиком массив, умножили на преобразование, и получили уже преобразованный объект. Красиво? Окей, согласен, притянуто за уши.
Настоящая причина в том, что крайне регулярно мы хотим, чтобы объект подвергся нескольким преобразованиями подряд. Представьте, что вы пишете в вашем коде функции преобразований типа
vec2 foo(vec2 p) return vec2(ax+by, cx+dy);
vec2 bar(vec2 p) return vec2(ex+fy, gx+hy);
[..]
for (each p in object) {
p = foo(bar(p));
}
Этот код делает два линейных преобразования на каждую вершину объекта, а они исчисляются в миллионах. И преобразований зачастую мы хотим с добрый десяток. Дорого. А с матричным подходом мы перемножаем все матрицы преобразования и умножаем на наш объект один раз. В умножении мы можем ставить скобки где хотим, правда ведь?
Продолжаем разговор, мы знаем, что диагональные элементы нам дают масштабирование по осям. За что отвечают два других коэффициента матрицы? Давайте рассмотрим такое преобразование:

Соответствующая картинка:

Не что иное, как простой сдвиг вдоль оси x. Второй анти-диагональный элемент даст сдвиг вдоль оси y. Таким образом, базовых линейных преобразований на плоскости только два: растягивание по осям и сдвиг вдоль оси. Постойте, скажут мне, а как же, например, вращение вокруг начала координат?
Выясняется, что вращение может быть представлено как композиция трёх сдвигов, здесь белый объект преобразован сначала в красный, затем в зелёный, затем в синий:

Но не будем ударяться в крайности, матрица вращения против часовой стрелки вокруг начала координат может быть записана напрямую (помните про расстановку скобок?):

Перемножать мы можем, конечно, в любом порядке, только давайте не забывать, что для матриц умножение некоммутативно:

Что нормально, сдвинуть и затем повернуть (красный объект) не то же самое, что сначала повернуть, а затем сдвинуть (зелёный объект):

Аффинные преобразования на плоскости
То есть, любое линейное преобразование на плоскости это композиция растягиваний и сдвигов. Что означает, что какой бы ни была матрица нашего преобразования, начало координат всегда перейдёт в начало координат. Таким образом, линейные преобразования — это прекрасно, но если мы не можем представить элементарного параллельного переноса, то наша жизнь будет печальна. Или можем? А что, если добавить его отдельно и записать аффинное преобразование как композицию линейной части и параллельного переноса? Примерно вот так:

Это, конечно, прекрасная запись, но вот только давайте посмотрим, на что похожей выглядит композиция двух таких преобразований (я напоминаю, что в реальной жизни нам нужно уметь аккумулировать десятки преобразований):

Это начинает выглядеть крайне неприятно уже для одной-единственной композиции. Попробуйте преобразовать это выражение, чтобы применить к нашему объекту только одно преобразование вида линейная часть + параллельный перенос. Лично мне очень не хочется этого делать.
Однородные координаты
А что же делать? Колдовать! Представьте теперь, что я допишу руками одну строчку и один столбец к нашей матрице преобразования и добавлю третью координату, которая равна единице у вектора, который мы преобразовываем:

При умножении этой 3x3 матрицы и нашего вектора, дополненного единицей, мы снова получили вектор с единицей в третьей компоненте, а остальные две имеют ровно тот вид, который мы хотели! Колдунство.
На самом деле, идея очень простая: параллельный перенос не является линейной операцией в двумерном пространстве.
Поэтому мы погружаем наше двумерное пространство в трёхмерное (добавив единицу в третью компоненту). Это означает, что наше двумерное пространство это плоскость z=1 внутри трёхмерного. Затем мы делаем линейное преобразование в трёхмерном пространстве и проецируем всё трехмерное пространство обратно на нашу физическую плоскость. Параллельный перенос от этого не стал линеен, но пайплайн всё же прост.
Как именно мы проецируем трёхмерное пространство обратно в нашу плоскость? Очень просто:

Секундочку, но ведь на ноль делить нельзя!
Кто вам сказал? Шутка. Давайте ещё раз поймём, что происходит.
- Мы погружаем наше 2d пространство в 3d, сделав его плоскостью z=1
- Делаем что хотим в 3d
- Для каждой точки, которую хотим спроецировать обратно в 2d, проводим прямую между началом координат и данной точкой и ищем её пересечение с физической плоскостью z=1.
На этой картинке наша физическая плоскость фиолетовая, и точка (x,y,z) проецируется в точку (x/z, y/z):
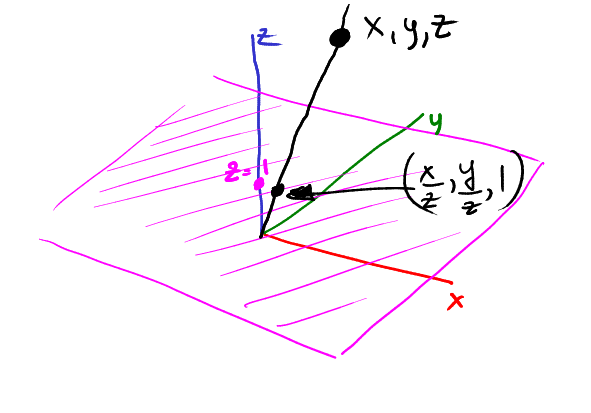
Теперь давайте представим вертикальный рельс, проходящий через точку (x,y,1). Куда спроецируется точка (x,y,1)? Конечно же, в (x,y):

Теперь давайте начнём скользить вниз по рельсу, например, точка (x, y, 1/2) спроецируется в (2x, 2y):
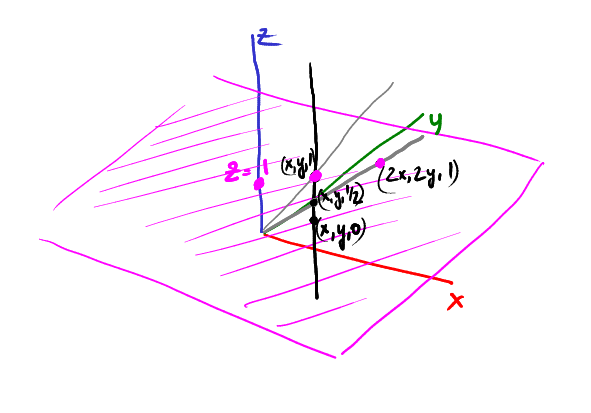
Продолжим скользить: точка (x,y,1/4) спроецируется в (4x, 4y):
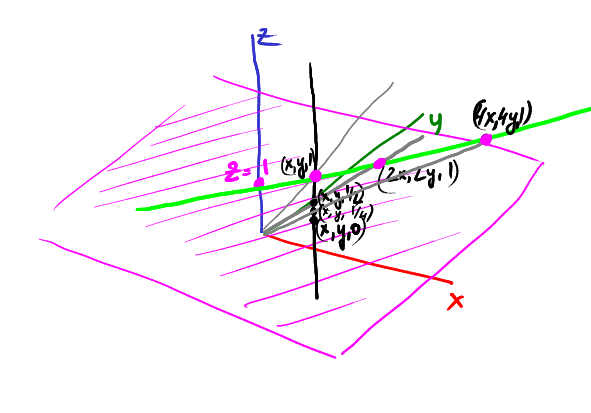
Продолжая скользить к нулю по z, наша проекция уходит всё дальше и дальше от центра координат по направлению (x,y).
То есть, точка (x,y,0) проецируется в бесконечно далёкую точку в направлении (x,y). А что это? Правильно, это вектор!
Однородные координаты дают возможность различать вектор и точку. Если программист пишет vec2 v(x,y), это вектор или точка?
Трудно сказать. А в однородных координатах всё, что с нулём по третьей компоненте, это вектор, всё остальное конечные точки.
Смотрите: вектор + вектор = вектор. Вектор-вектор = вектор. Точка + вектор = точка. Ну не здорово ли?
Пример составного преобразования
Я уже говорил, что нам нужно уметь накапливать десятки преобразований. Почему? Предположим, вам нужно повернуть плоский объект вокруг точки (x0, y0). Как это сделать? Можно пойти и искать формулы, а можно сделать самим, ведь у нас есть все инструменты.
Мы умеем вращать вокруг центра координат, мы умеем сдвигать. Что ещё надо? Сдвигаем x0,y0 в центр координат, вращаем, возвращаем назад. Халява!

В 3д последовательности действий будут немного длиннее, но смысл остаётся прежним: нам достаточно уметь делать несколько базовых преобразований, и с их помощью мы можем закодировать какое угодно сложное.
Постойте, а имею ли я право трогать нижнюю строку матрицы 3x3?
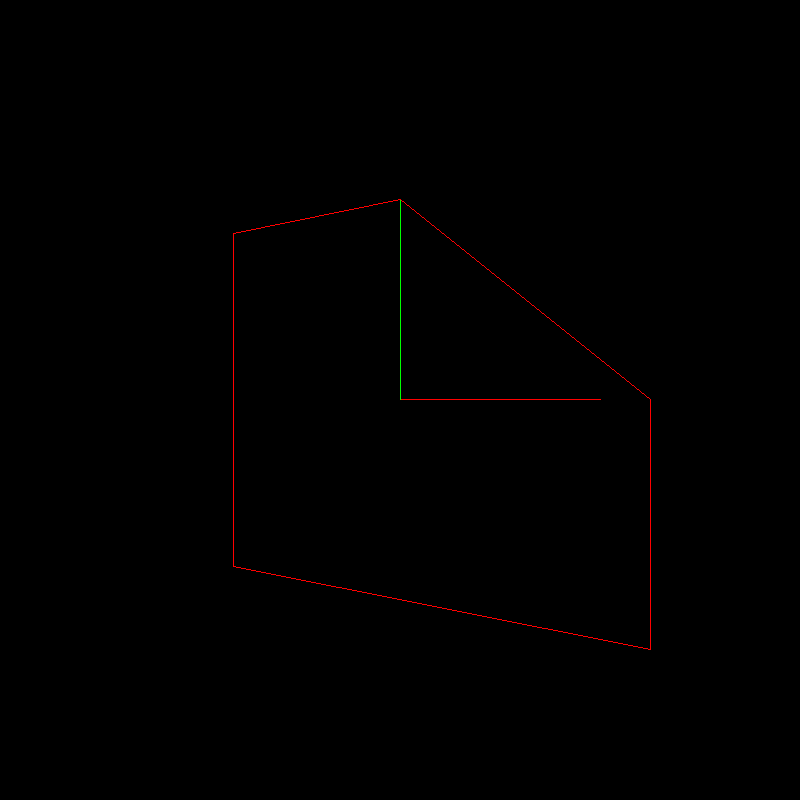
Ещё как! Давайте применим вот это преобразование:

к нашему стандартному тестовому объекту. Напоминаю, что тестовый объект белый, единичные икс и игрек вектора показаны красным и зелёным, соответственно
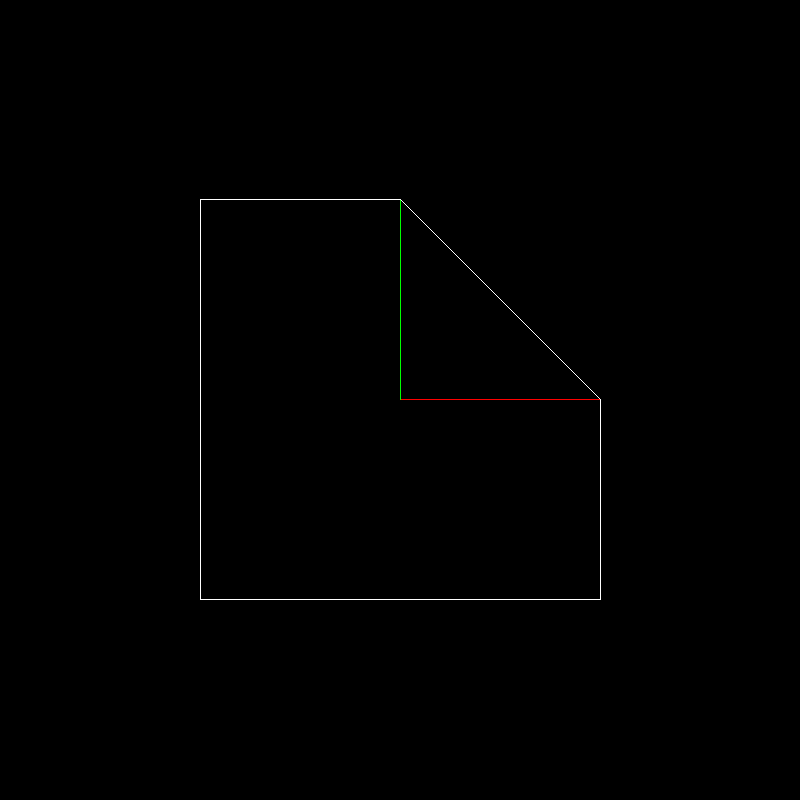
Вот наш преобразованный объект:
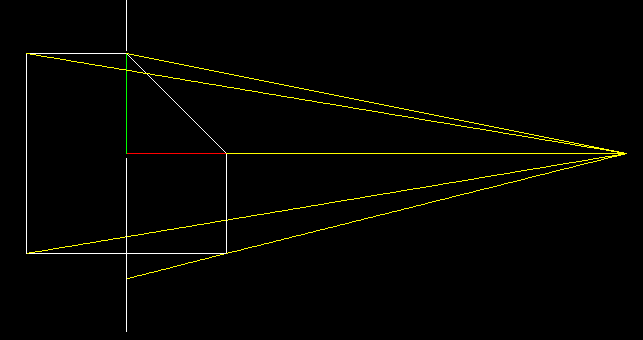
И вот тут начинается самое интересное. Помните наше упражнение про игрек-буфер? Здесь мы будем делать практически то же самое.
Мы будем проецировать наш двумерный объект на прямую x=0. Причём теперь усложним задачу: проекция будет центральной, наша камера находится в точке (5, 0) и смотрит в начало координат. Чтобы найти проекцию, мы должны провести прямые, проходящие через точку камеры и каждую вершину нашего объекта (жёлтые прямые), а затем найти их пересечение с прямой экрана (белая вертикальная).
А теперь давайте уберём оригинальный объект и вместо него нарисуем трансформированный.
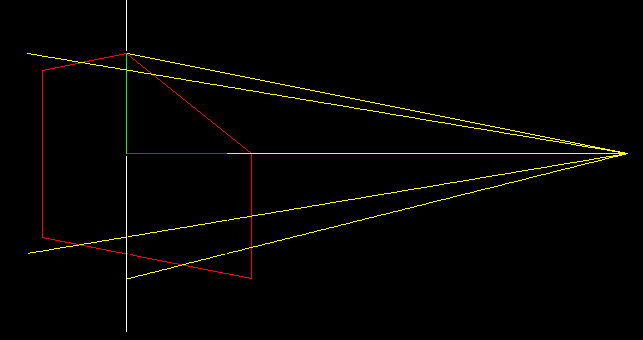
Если мы используем обычную ортогональную проекцию нашего трансформированного объекта, то мы найдём ровно те же самые точки!
Ведь что делает это отображение? Оно каждое вертикальное ребро оставляет вертикальным, но при этом растягивает те, которые близко к камере, и сжимает те, что дальше от камеры. Правильно подобрав коэффициент растяжения-сжатия мы можем как раз достичь эффекта, что простой ортогональной проекцией мы получаем изображение в перспективном искажении! В следующем параграфе мы добавим одно измерение и покажем, откуда взялся коэффициент -1/5.
Пора перейти к трём измерениям
Давайте объяснять только что произошедшую магию.
Как и в случае двумерных аффинных преобразований, в трёхмерном пространстве мы тоже будем использовать однородные координаты.
Берём точку (x,y,z), погружаем её в четырёхмерное пространство, добавив единицу в четвёртую компоненту, преобразуем в четырёх измерениях и проецируем обратно в 3d. Например, возьмём такое преобразование:

Проекция на 3д даёт следующие координаты:

Хорошо запомним этот результат, но на пару минут его отложим. Давайте вернёмся к стандартному определению центральной проекции в обычном 3д, без однородных координат и прочих экзотических вещей. Пусть у нас будет точка P=(x,y,z), которую мы хотим спроецировать на плоскость z=0, камера находится на оси z на расстоянии c от центра координат.
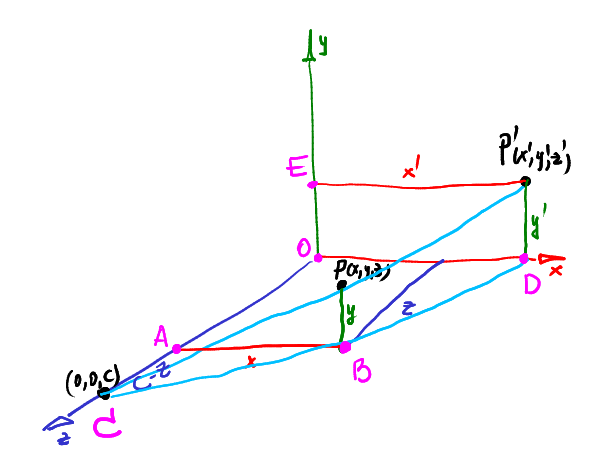
Мы знаем, что треугольники ABC и ODC подобны. То есть, мы можем записать |AB|/|AC|=|OD|/|OC| => x/(c-z) = x'/c.

Рассматривая треугольники CPB и CP'D, можно легко прийти к подобной записи и для координаты y:

Итак, это очень-очень похоже на результат проекции через однородные координаты, только там это всё считалось одним матричным умножением. Мы вывели зависимость коэффициентов r = -1/c.
Для закрепления материала: главная формула на сегодня
Хотя если вы просто возьмёте эту формулу, не поняв весь предыдущий текст, то я вас ненавижу. Итак, если мы хотим построить центральную перспективу с (важно!) камерой, находящейся на оси z на расстоянии c от начала координат, то сначала мы погружаем трёхмерные точки в четырёхмерное пространство, добавив 1. Затем умножаем на следующую матрицу и проецируем результат обратно в 3D:

Мы деформировали наш объект так, что теперь для построения проволочного рендера с перспективой нам достаточно просто забыть про новополученную координату z. Если мы хотим строить z-буфер, то, разумеется, мы её используем. Слепок кода доступен на гитхабе. Результат его работы виден в самом начале нашей статьи.
