Создав и поддерживая проект с открытыми исходными текстами хочется сразу решить все возможные проблемы по мультиязычной поддержке как проекта, так и сайта. С поддержкой мультиязычности в различных проектах я сталкиваюсь очень давно, начиная ещё с десктопных программ. Таким образом, имея представление о возможных потребностях, я начал знакомиться с предлагаемыми решениями. Да, практически все SaaS сервисы предлагают бесплатное использование для open-source проектов, но там в основном всё заточено на перевод строковых ресурсов. А как быть с сайтом и документацией? К сожалению, я так и не нашел ничего подходящего и приступил к самостоятельной реализации. Сразу скажу, что результатом доволен и использую систему практически полгода, хотя предупреждаю, что это не массовое законченное решения, а скорее конкретная реализация под мои нужды, но я надеюсь, что некоторые идеи могут быть полезны и другим разработчикам.
Для начала я перечислю требования, которые установил для будущего детища.
Отображение изменений в реальном времени мне было не актуально, и я решил сделать несколько промежуточных таблиц со всей внутренней кухней и затем по команде делать сборку JSON и генерацию страниц самого сайта. На самом деле, достаточно четырех таблиц.
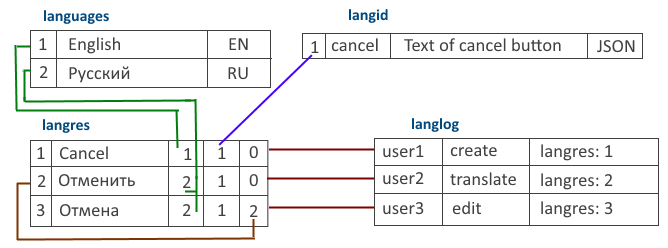
Таблица языков languages с тремя полями name, native, iso639. Пример записи: Russian, Русский, ru
Таблица текстовых идентификаторов ресурсов langid, где можно указать еще комментарий и тип. Я разделил для себя все ресурсы на несколько типов: JSON строка, страница сайта, простой текст, текст в формате MarkDown. Вы можете конечно использовать свои собственные типы.
Пример: сancelbtn, Text for Cancel button, JSON
Таблица текстовых ресурсов langres ( langid, language, text, prev). Храним ссылки на идентификатор, язык и сам текст.
Последнее поле prev обеспечивает версионность текста при правках и указывает на предыдущую версию ресурса.
Все изменения фиксируются в лог-таблице langlog ( iduser, idlangres, action ). Поле action будет указывать на совершенное действие — создание, редактирование, проверка.
Я не буду останавливаться на работе с пользователями, скажу лишь, что пользователь регистрируется автоматически при отправке перевода или исправления. Так как email не обязателен, то пользователю сразу сообщается логин и пароль. Все сделанные им изменения будут привязаны к его аккаунту. В дальнейшем он может указать свой email и прочие данные или просто забыть про эту регистрацию.
Я нарисовал схему, чтобы вы лучше представили все связи между таблицами.
Так как мне нужна возможность вставки ресурсов в другие ресурсы, то я добавил макросы вида #идентификатор#. Например, в простейшем случае, если мы имеем ресурс name = «Имя», то мы можем использовать его в ресурсе entername = «Укажите своё #name#», которое при генерации заменится на Укажите свое Имя.
Теперь, для генерации страниц сайта достаточно пройтись по всем языкам и ресурсам с соответствующим типом, обработать каждый текст специальной функцией замены и записать результат в отдельную таблицу с готовыми страницами. Причем обработка происходит таким образом, что если #идентификатор# не найден на текущем языке, то он ищется на других языках. Вот набросок рекурсивной функции (с защитой от зацикливания), которая производит эту обработку.
Кроме замены макросов вида #name#, я также сразу конвертирую MarkDown разметку в HTML и обрабатываю свои собственные директивы. Например, у меня есть таблица картинок, где на одну запись можно навесить скриншоты для разных языков, и если я в тексте указываю тэг [img "/file/#*indexes#"], то у меня подставляется изображение с именем indexes с нужным мне языком. Но самое главное — я могу генерировать выгрузки для различных целей в любом формате. В качестве примера приведу код генерации JSON файлов, там правда, за ненадобностью, не используется функция подстановки идентификаторов.
Таким образом, затратив не так много усилий я реализовал практически всё, что хотел. Нереализованными остались только вещи, которые неактуальны на данный момент из-за низкой активности на сайте. Зато были добавлены дополнительные возможности, которые понадобились в процессе использования. Например, получение текстового файла с ресурсами, которые нуждаются в переводе и обратная загрузка переведенного текста.
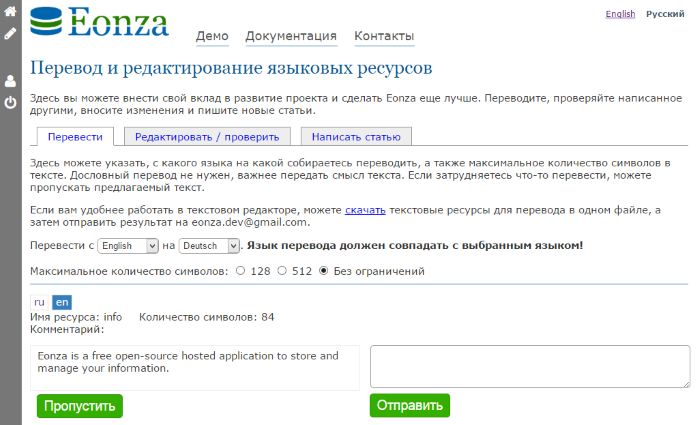
Желающие могут взглянуть на рабочую страницу, где пользователи могут переводить, редактировать и создавать новые ресурсы для моего проекта.
Для начала я перечислю требования, которые установил для будущего детища.
- Локализовать нужно как ресурсы для проекта хранящиеся в виде JSON в .js, так и все тексты и документацию на сайте.
- Ресурс может не иметь перевода на другие языки. То есть, я например могу накопить тексты на русском, а потом отдать переводчику, причем в русской версии сайта эти тексты уже будут доступны.
- Должна быть удобная система на сайте для того чтобы пользователь мог перевести не переведенные на его язык ресурсы, создать новый ресурс (текст) или проверить и отредактировать уже существующие тексты на своем родном языке. Выглядеть это должно примерно так — пользователь выбирает действие (перевод, проверка), родной язык (и в случае перевода еще язык оригинала), а также желаемый объем. По этим параметрам ищется ресурс и предлагается пользователю для перевода или редактирования. Естественно, должен вестись лог действий пользователя и накапливаться статистика по выполненным работам.
- На сайте должен быть выбор языков, но на каждой странице должны показываться только те языки, для которых уже есть перевод данной страницы.
- Одна и та же строка может использоваться в нескольких местах. Например, строка используется в .js и в документации. То есть, ресурс должен быть в одном экземпляре и при его изменении, он должен меняться и в JSON и в документации.
- В идеале должна быть какая-то авто-модерируемая система, но пока можно остановится на личном принятии решений по публикации.
Отображение изменений в реальном времени мне было не актуально, и я решил сделать несколько промежуточных таблиц со всей внутренней кухней и затем по команде делать сборку JSON и генерацию страниц самого сайта. На самом деле, достаточно четырех таблиц.
Структура таблиц
CREATE TABLE IF NOT EXISTS `languages` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `_uptime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, `_owner` smallint(5) unsigned NOT NULL, `name` varchar(32) NOT NULL, `native` varchar(32) NOT NULL, `iso639` varchar(2) NOT NULL, PRIMARY KEY (`id`), KEY `_uptime` (`_uptime`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 ; CREATE TABLE IF NOT EXISTS `langid` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `_uptime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, `_owner` smallint(5) unsigned NOT NULL, `name` varchar(96) NOT NULL, `comment` text NOT NULL, `restype` tinyint(3) unsigned NOT NULL, `attrib` tinyint(3) unsigned NOT NULL, PRIMARY KEY (`id`), KEY `_uptime` (`_uptime`), KEY `name` (`name`), KEY `restype` (`restype`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 ; CREATE TABLE IF NOT EXISTS `langlog` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `_uptime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, `_owner` smallint(5) unsigned NOT NULL, `iduser` int(10) unsigned NOT NULL, `idlangres` int(10) unsigned NOT NULL, `action` tinyint(3) unsigned NOT NULL, PRIMARY KEY (`id`), KEY `_uptime` (`_uptime`), KEY `iduser` (`iduser`,`idlangres`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 ; CREATE TABLE IF NOT EXISTS `langres` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `_uptime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, `_owner` smallint(5) unsigned NOT NULL, `langid` smallint(5) unsigned NOT NULL, `lang` tinyint(3) unsigned NOT NULL, `text` text NOT NULL, `prev` mediumint(9) unsigned NOT NULL, `verified` tinyint(3) NOT NULL, `size` mediumint(9) unsigned NOT NULL, PRIMARY KEY (`id`), KEY `_uptime` (`_uptime`), KEY `langid` (`langid`,`lang`), KEY `size` (`size`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 ;
Таблица языков languages с тремя полями name, native, iso639. Пример записи: Russian, Русский, ru
Таблица текстовых идентификаторов ресурсов langid, где можно указать еще комментарий и тип. Я разделил для себя все ресурсы на несколько типов: JSON строка, страница сайта, простой текст, текст в формате MarkDown. Вы можете конечно использовать свои собственные типы.
Пример: сancelbtn, Text for Cancel button, JSON
Таблица текстовых ресурсов langres ( langid, language, text, prev). Храним ссылки на идентификатор, язык и сам текст.
Последнее поле prev обеспечивает версионность текста при правках и указывает на предыдущую версию ресурса.
Все изменения фиксируются в лог-таблице langlog ( iduser, idlangres, action ). Поле action будет указывать на совершенное действие — создание, редактирование, проверка.
Я не буду останавливаться на работе с пользователями, скажу лишь, что пользователь регистрируется автоматически при отправке перевода или исправления. Так как email не обязателен, то пользователю сразу сообщается логин и пароль. Все сделанные им изменения будут привязаны к его аккаунту. В дальнейшем он может указать свой email и прочие данные или просто забыть про эту регистрацию.
Я нарисовал схему, чтобы вы лучше представили все связи между таблицами.
Так как мне нужна возможность вставки ресурсов в другие ресурсы, то я добавил макросы вида #идентификатор#. Например, в простейшем случае, если мы имеем ресурс name = «Имя», то мы можем использовать его в ресурсе entername = «Укажите своё #name#», которое при генерации заменится на Укажите свое Имя.
Теперь, для генерации страниц сайта достаточно пройтись по всем языкам и ресурсам с соответствующим типом, обработать каждый текст специальной функцией замены и записать результат в отдельную таблицу с готовыми страницами. Причем обработка происходит таким образом, что если #идентификатор# не найден на текущем языке, то он ищется на других языках. Вот набросок рекурсивной функции (с защитой от зацикливания), которая производит эту обработку.
Пример PHP функции подстановки
public function proceed( $input, $recurse = false ) { global $db, $syslang; if ( !$recurse ) $this->chain = array(); $result = ''; $off = 0; $start = 0; $len = strlen( $input ); while ( ($off = strpos( $input, '#', $off )) !== false && $off < $len - 2 ) { $end = strpos( $input, '#', $off + 2 ); if ( $end === false ) break; if ( $end - $off > $this->lenlimit ) { $off = $end - 1; continue; } $name = substr( $input, $off + 1, $end - $off - 1 ); $langid = $db->getone("select id from langid where name=?s", $name ); if ( $langid && !in_array( $langid, $this->chain )) { $langres = $db->getrow("select _uptime, id,text from langres where langid=?s && verified>0 order by if( lang=?s, 0, 1 ),lang", $langid, $this->lang ); if ( $langres ) { if ( $langres['_uptime'] > $this->time ) $this->time = $langres['_uptime']; $result .= substr( $input, $start, $off - $start ); $off = $end + 1; $start = $off; array_push( $this->chain, $langid ); $result .= $this->proceed( $langres['text'], true ); array_pop( $this->chain ); if ( $off >= $len - 2 ) break; continue; } } $off = $end - 1; } if ( $start < $len ) $result .= substr( $input, $start ); return $result; }
Кроме замены макросов вида #name#, я также сразу конвертирую MarkDown разметку в HTML и обрабатываю свои собственные директивы. Например, у меня есть таблица картинок, где на одну запись можно навесить скриншоты для разных языков, и если я в тексте указываю тэг [img "/file/#*indexes#"], то у меня подставляется изображение с именем indexes с нужным мне языком. Но самое главное — я могу генерировать выгрузки для различных целей в любом формате. В качестве примера приведу код генерации JSON файлов, там правда, за ненадобностью, не используется функция подстановки идентификаторов.
Генерация JSON файлов для RU и EN
function jsonerror( $message ) { print $message; exit(); } function save_json( $filename ) { global $db, $original; preg_match("/^\w*_(?<lang>\w*)\.js$/", $filename, $matches ); if ( empty( $matches['lang'] )) jsonerror( 'No locale' ); $lang = $db->getrow("select * from languages where iso639=?s", $matches['lang'] ); if ( !$lang ) jsonerror( 'Unknown locale '.$matches['lang'] ); $list = $db->getall("select lng.name, r.text from langid as lng left join langres as r on r.langid = lng.id where lng.restype=5 && verified>0 && r.lang=?s order by lng.name", $lang['id'] ); $out = array(); foreach ( $list as $il ) $out[ $il['name']] = $il['text']; if ( $lang['id'] == 1 ) $original = $out; else foreach ( $original as $ik => $io ) if ( !isset( $out[ $ik ] )) $out[ $ik ] = $io; $output = "/* This file is automatically generated on eonza.org. Use http://www.eonza.org/translate.html to edit or translate these text resources. */ var lng = { \tcode: '$lang[iso639]', \tnative: '$lang[native]', "; foreach ( $out as $ok => $ov ) { if ( strpos( $ov, "'" ) === false ) $text = "'$ov'"; elseif (strpos( $ov, '"' ) === false ) $text = "\"$ov\""; else jsonerror( 'Wrong text:'.$text ); $output .= "\t$ok: $text,\r\n"; } $output .= "\r\n};\r\n"; $jsfile = dirname(__FILE__)."/i18n/$lang[iso639].js"; if ( file_exists( $jsfile )) $output .= file_get_contents( $jsfile ); if (file_put_contents( HOME."tmp/$filename", $output )) print "Save: ".HOME."tmp/$filename<br>"; else jsonerror( 'Save error:'.HOME."tmp/$filename" ); } $original = array(); $files = array( 'en', 'ru'); foreach ( $files as $if ) save_json( "locale_$if.js" ); $zip = new ZipArchive(); print $zip->open( HOME."tmp/locale.zip", ZipArchive::CREATE ); foreach ( $files as $f ) print $zip->addFile( HOME."tmp/locale_$f.js", "locale_$f.js" ); print $zip->close(); print "Finish<br><a href='/tmp/locale.zip'>ZIP file</a>";
Таким образом, затратив не так много усилий я реализовал практически всё, что хотел. Нереализованными остались только вещи, которые неактуальны на данный момент из-за низкой активности на сайте. Зато были добавлены дополнительные возможности, которые понадобились в процессе использования. Например, получение текстового файла с ресурсами, которые нуждаются в переводе и обратная загрузка переведенного текста.
Желающие могут взглянуть на рабочую страницу, где пользователи могут переводить, редактировать и создавать новые ресурсы для моего проекта.
