Comments 32
Это реально такая архитектура для системы, которая делает CRUDL для одной таблицы с примитивными отчетами?
Нет, конечно. Я описал архитектуру проекта, над которым работаю, на очень простом примере. Реальный проект, само собой, намного сложнее.
Если требуется держать 100500 мульёнов коннектов и не терять данные в запросах из-за 504, например, то либо так, либо писать части системы на Erlang. Вообще это классические SOA + CQRS + Шина данных. AlexanderByndyu много на эту тему рассказывает, например вот: blog.byndyu.ru/2014/07/command-and-query-responsibility.html.
Как CQRS помогает держать «100500 мульёнов коннектов»?
CQRS делает каждую операцию записи дороже, так как нужно записать сначала в очередь, а потом в хранилище. Если операция записи в хранилище дорогая, то может быть выгодно записать в очередь и клиенту сказать «спасибо, ваше сообщение обрабатывается» или еще как-то оптимизировать за счет пакетной обработки.
Но в этом примере запись данных в хранилище — просто добавление строки в таблиц, а для построения графика делается простая выборка, которая прекрасно покрывается индексами.
CQRS делает каждую операцию записи дороже, так как нужно записать сначала в очередь, а потом в хранилище. Если операция записи в хранилище дорогая, то может быть выгодно записать в очередь и клиенту сказать «спасибо, ваше сообщение обрабатывается» или еще как-то оптимизировать за счет пакетной обработки.
Но в этом примере запись данных в хранилище — просто добавление строки в таблиц, а для построения графика делается простая выборка, которая прекрасно покрывается индексами.
Простой пример: подсчет кол-ва просмотров/комментариев к статье, как на Хабре например. Если одновременно делать ViewCount++ а потом возвращать вьюху, то очень быстро начнутся read-write локи на уровне доступа к БД.
И что вы предлагаете? Сначала писать в очередь, а потом в базу, то есть на каждый хит писать два раза? И это не вызовет локов при записи в хранилище? Или первую очередь не-persistent сделать и иметь вероятность потерь? Тогда можно просто в кеш писать количество хитов и периодически сбрасывать в хранилище инфу.
Посмотрите доклад по ссылке выше, там подробно описано. В общем случае правило простое: пишем в одно место, читаем из другого. По тригеру или таймеру синхронизируем состояние хранилищ. Что это будет NoSQL, Кеш или просто другая таблица в БД — детали реализации. CQRS часто используется вместе с очередями, но это не обязательное условие.
Читаем из кеша, а пишем в базу. С примером про viewcount — как раз такая схема подходит идеально. Статья меняется редко, попадает в кеш сразу и потом отдается без запроса к базе. Это дает возможность делать на каждый запрос update set viewcount=viewcount+1, причем ответа от базы можно не ждать — «выстрелил и забыл».
CQRS это «пишем в кэш, а читаем из базы», гораздо более медленная и менее надежная архитектура.
CQRS это «пишем в кэш, а читаем из базы», гораздо более медленная и менее надежная архитектура.
А данные-то по количеству просмотров в кэше как обновляются?
Вместе с базой в кэш хиты писать. Это если их на каждый запрос показывать.
То есть при каждом просмотре надо (а) записать в БД и (б) записать в кэш, так?
Да, только запись в кеш практически бесплатная (никаких гарантий не нужно) и синхронная с точки зрения пользователя. А в базу можно писать асинхронно, вызываю команду на сервере, и не дожидаясь завершения. Пока не уперлись в скорость записи в БД никаких других приемов использовать не надо.
А в случае с CQRS мы сначала пишем в ненадежное хранилище (ибо писать в надежное — дорого), а потом переливаем данные в надежное. Для пользователя такое поведение асинхронно, ибо он не увидит результатов до того, как данные перелились в надежное хранилище (читаем мы из него), а также надежность ниже, ибо любое ненадежное хранилище может потерять данные.
А в случае с CQRS мы сначала пишем в ненадежное хранилище (ибо писать в надежное — дорого), а потом переливаем данные в надежное. Для пользователя такое поведение асинхронно, ибо он не увидит результатов до того, как данные перелились в надежное хранилище (читаем мы из него), а также надежность ниже, ибо любое ненадежное хранилище может потерять данные.
А в базу можно писать асинхронно, вызываю команду на сервере, и не дожидаясь завершения.
А если во время записи произошла ошибка? Поскольку у вас fire-and-forget, вы об этом не узнали. Данные в БД не обновились. Что делать?
А в случае с CQRS мы сначала пишем в ненадежное хранилище (ибо писать в надежное — дорого), а потом переливаем данные в надежное.
Ну нет. В случае с CQRS запись делается в настолько надежное хранилище, насколько нужно (т.е., если нужна персистентность — то в честно персистентное).
А если во время записи произошла ошибка? Поскольку у вас fire-and-forget, вы об этом не узнали. Данные в БД не обновились. Что делать?
Ничего, потому что ошибки просто так не возникают. Если нет возможности соединиться с базой, то упадет все, а не только запись viewcount. Вероятность на СУБД получить отказ в одной операции update, когда работает все остальное, настолько мала, что ей можно пренебречь.
Ну нет. В случае с CQRS запись делается в настолько надежное хранилище, насколько нужно (т.е., если нужна персистентность — то в честно персистентное).
А в чем тогда выигрыш быстродействия, если нам все равно писать надо на каждый запрос? Все равно все запросы на запись выстраиваются в очередь и клиент ждет завершения.
CQRS имеет смысл если записей в единицу времени много, а чтение тяжелое. Но viewcount к этому не относится.
Вероятность на СУБД получить отказ в одной операции update, когда работает все остальное, настолько мала, что ей можно пренебречь.
На самом деле, нет. Дедлок — и все. Ну и да, у вас же fire-and-forget, вы потеряли данные уже.
А в чем тогда выигрыш быстродействия, если нам все равно писать надо на каждый запрос? Все равно все запросы на запись выстраиваются в очередь и клиент ждет завершения.
В том, что запись в хранилище, оптимизированное для записи, — быстрее, чем запись в хрналищие, оптимизированное для чтения. А между ними данные можно трансферить тем способом, который оптимален для задачи.
Дедлок на апдейте viewcount? В SQL Server этого можно добиться только одним способом, который по сути является ошибкой проектирования. Сам по себе в корректной программе дедлок не возникнет. А других базах должно быть примерно также.
Сокращать надо время ожидания пользователя, а не время записи. Поэтому чем больше лаг между отправкой команды и записью в хранилище для чтения, тем хуже. А чем меньше лаг, тем более неэффективная схема получается, ибо писать все равно в два места надо.
В том, что запись в хранилище, оптимизированное для записи, — быстрее, чем запись в хрналищие, оптимизированное для чтения. А между ними данные можно трансферить тем способом, который оптимален для задачи.
Сокращать надо время ожидания пользователя, а не время записи. Поэтому чем больше лаг между отправкой команды и записью в хранилище для чтения, тем хуже. А чем меньше лаг, тем более неэффективная схема получается, ибо писать все равно в два места надо.
В SQL Server этого можно добиться только одним способом, который по сути является ошибкой проектирования.
Вот CQRS — это паттерн, который позволяет уменьшить такие ошибки проектирования.
Сокращать надо время ожидания пользователя, а не время записи. Поэтому чем больше лаг между отправкой команды и записью в хранилище для чтения, тем хуже.
Так этот конкретный пользователь, который открывает статью на чтение, не ждет результата записи счетчика прочитанных. У него как раз честный fire-and-forget — его прочтение должны учесть, но ему самому не важно, когда. Поэтому для него как раз важно только и исключительно время отклика хранилища на запись.
Прямое применения CQRS еще большая ошибка, чем неправильно построенный индекс в SQL Server.
Он как минимум ждет ответа хранилища. Чтобы не ждать нужно использовать кэш, внезапно в кэше оказываются те же данные, которые пишутся при просмотре, CQRS становится бесполезным, важно остается обеспечить когерентность кэша, что проще всего сделать записав данные одновременно в два места.
Так этот конкретный пользователь, который открывает статью на чтение, не ждет результата записи счетчика прочитанных.
Он как минимум ждет ответа хранилища. Чтобы не ждать нужно использовать кэш, внезапно в кэше оказываются те же данные, которые пишутся при просмотре, CQRS становится бесполезным, важно остается обеспечить когерентность кэша, что проще всего сделать записав данные одновременно в два места.
Прямое применения CQRS еще большая ошибка, чем неправильно построенный индекс в SQL Server.
Что вы понимаете под «прямым применением»?
Он как минимум ждет ответа хранилища.
Хранилища на запись, которое должно быть быстрее, чем хранилище на чтение.
Что вы понимаете под «прямым применением»?
Ровно так как в этой статье.
Хранилища на запись, которое должно быть быстрее, чем хранилище на чтение.
Нет, я как раз говорю про ожидания того хранилища, которое на чтение. Как бы вы не извращались, но все равно вы под нагрузкой будете использовать кеш для чтения. И это сделает CQRS бесполезным в 99% случаев.
Как бы вы не извращались, но все равно вы под нагрузкой будете использовать кеш для чтения. И это сделает CQRS бесполезным в 99% случаев.
Ну, если для вас уменьшение конфликтов — это бесполезная операция, то ок. Что характерно, в адекватных статьях про CQRS пишут, что его надо применять в конкретных случаях, а не везде.
(а вообще, в каком-то смысле кэш — это уже CQRS)
Ну так можно договорится до того, что CQRS уже есть в СУБД, ибо там данные пишутся в лог, а потом уже изменяются страницы данных.
А что касается применения CQRS, то в каких случаях его стоит применять? Пример в этой стате это адекватное применение или нет?
Только не надо употреблять банальности типа «высокая нагрузка», она к CQRS не имеет отношения.
А что касается применения CQRS, то в каких случаях его стоит применять? Пример в этой стате это адекватное применение или нет?
Только не надо употреблять банальности типа «высокая нагрузка», она к CQRS не имеет отношения.
Классы, определяющие контракт API MoneyFlow для экранов списка, создания и редактирования операций.
public class ChargeOpForAdding public class ChargeOpForList : ChargeOpForAdding public class ChargeOpForEditing : ChargeOpForList
Нет, так делать не надо. Вы применяете наследование для повторного использования, в то время как его цель — это семантика «я являюсь».
Но вообще, конечно, да, типичный такой CQRS.
А как обрабатывается ситуация, когда сервис с асинхронным стеком по какой-либо причине вырубится совсем? Ведь, если я правильно понимаю, все необработанные сообщения хранятся в оперативной памяти. Получается при остановке сервиса сообщения просто потеряются?
Использую очень похожую архитекуру. Добавлю свои пять копеек
Я бы добавил класс ChargeOperation, в который перенес бы валидацию на то, что сумма больше нуля. И соответственно в _chargeOpsStorage передавал бы объект ChargeOperation.
Тут перебор с аргументами, в данном случае имеет смысл создать объект MonthReport, в котором инкапсулировать эти аргументы
//Проверяем входные данные
CheckingData(op);
...
_chargeOpsStorage.CreateChargeOp(op);
Я бы добавил класс ChargeOperation, в который перенес бы валидацию на то, что сумма больше нуля. И соответственно в _chargeOpsStorage передавал бы объект ChargeOperation.
//обновить отчет за месяц
public void UpdateMonthReport(Guid userId, ECategory category, int year, int month, double sum)
Тут перебор с аргументами, в данном случае имеет смысл создать объект MonthReport, в котором инкапсулировать эти аргументы
Здравствуйте спасибо за статью, возникла пара вопросов: Первый слой это синхронный стек, как обеспечивается его отказоустойчивость, к примеру при обновлении приложения, как минимизируется время простоя, какие технологии применяются?
Ещё опишите пожалуйста как осуществляется процесс разработки, тестирования и обновление production'а.
Ещё опишите пожалуйста как осуществляется процесс разработки, тестирования и обновление production'а.
Добрый день. У нашего приложения есть несколько версий, кастомизированных под различных заказчиков. Там где критична отказоустойчивость у нас поднят балансировщик и несколько IIS. Обновления у нас проводятся руками.
По процессу обновления — в случае глобальных изменений, вроде изменения структуры БД, переносе части данных из одной БД в другую, мы включаем заглушку «профилактические работы» на запросы извне и начинаем процесс обновления — копируем файлы по папкам, мигрируем БД и т.д… После этого мы проверяем с внутреннего адреса что все завелось нормально и снимаем заглушку. Делаем мы это само собой по ночам и не часто. Для мелких изменений проводим процесс обновления «на лету», просто копируя изменившиеся сборки.
Процесс разработки — обычный Continious Integration с тестовыми стендами (у нас их целых пять).
Я немного дополнил статью, вставив картинку с тем как все устроено.
По процессу обновления — в случае глобальных изменений, вроде изменения структуры БД, переносе части данных из одной БД в другую, мы включаем заглушку «профилактические работы» на запросы извне и начинаем процесс обновления — копируем файлы по папкам, мигрируем БД и т.д… После этого мы проверяем с внутреннего адреса что все завелось нормально и снимаем заглушку. Делаем мы это само собой по ночам и не часто. Для мелких изменений проводим процесс обновления «на лету», просто копируя изменившиеся сборки.
Процесс разработки — обычный Continious Integration с тестовыми стендами (у нас их целых пять).
Я немного дополнил статью, вставив картинку с тем как все устроено.
Картинка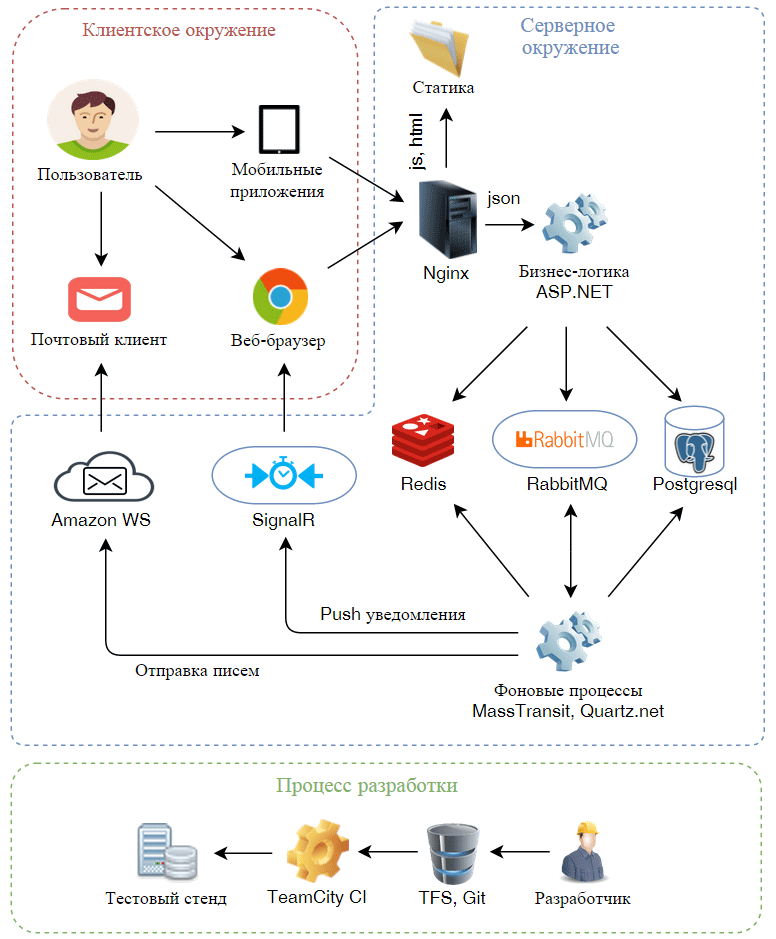
Огромное спасибо за статью! У нас похожая архитектура и такой же технологический стек, только мы на первой итерации ещё. :)
А у вас используется единый язык? Зафиксирована ли в каком-то виде структура предметной области? Если да, то отражены ли там DTO?
А у вас используется единый язык? Зафиксирована ли в каком-то виде структура предметной области? Если да, то отражены ли там DTO?
На сервере у нас все написано на C#. Предметная область у нас зафиксирована в виде технических заданий с подробно описанными юзер- кейсами. DTO контракты зафиксированы только в коде, но у нас есть строгие правила по разбиению классов по сборкам. Например, контракт обмена между клиентом и сервером описан в отдельной сборке, со строго определенными пространствами имен. Зная правила именования классов найти что-либо в проекте у нас просто.
Sign up to leave a comment.
Как устроен наш код. Серверная архитектура одного проекта