Как это начиналось
Я всю жизнь занимался разработкой под Windows. Сначала на С++, затем на C#. В промежутках мелькали VB, Java Script и другая нечисть. Однако некоторое время назад всё изменилось и я впервые столкнулся с миром Linux, Java и Scala. У нас с Денисом, моим другом и соратником по многочисленным идеям, уже был свой проект – набор утилит для Windows, который пользовался широким спросом в узких кругах. В какой-то момент мы оба потеряли интерес к этому проекту и встал вопрос – что же делать дальше. Денис стал инициатором идеи нового проекта – сервис по обмену clipboard между разными устройствами. Этот проект существенно отличался от предыдущего помимо технологий ещё и целевой аудиторией. Этот сервис должен был стать полезен всем. Скопируйте данные в буфер обмена и вставьте из него на любом другом устройстве. Звучит проще некуда, пока не задумаешься над тем сколько сейчас разных устройств, а также как это все будет работать при большом количестве пользователей.
Первый прототип появился через несколько месяцев. Сервер был написан на ASP.NET и хостился на MS IIS. Было написано 2 клиента: на С++ под Windows и на Java под Android.
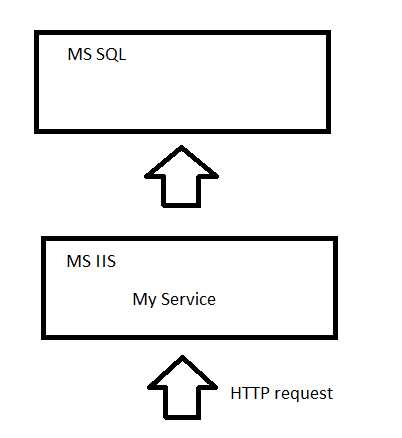
Тестирование показало, что прототип держит около 500 соединений. Что же делать, если их будет больше, мы ведь расчитываем на сотни тысяч пользователей ;) Как написать сервер, который может работать с большим количеством соединений, который не надо будет выключать во время апгрейда железа или софта и который будет легко масштабироваться (то есть расширяться в случае увелечения количества пользователей).
Распределенная масштабируемая система
Для меня такие сложные термины как «распределенная масштабируемая система» ( хорошая статья ) обычно остаются пустым звуком до тех пор, пока я не пойму что за этим стоит с точки зрения технологий и продуктов. Мне недостаточно знать характеристики таких систем и хочется самому попробовать создать такую систему, чтобы осознать все её достоинства и недостатки.
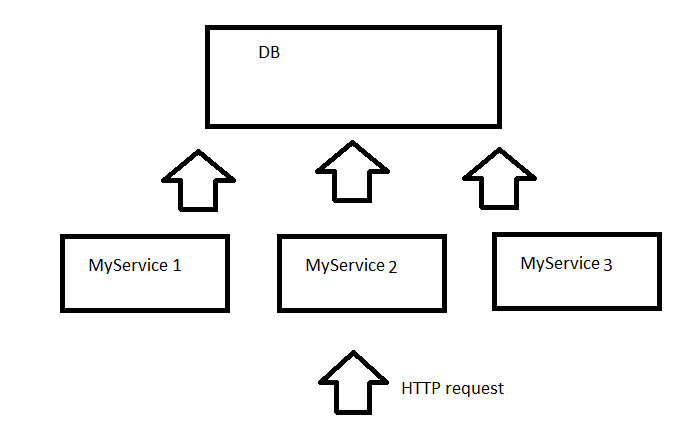
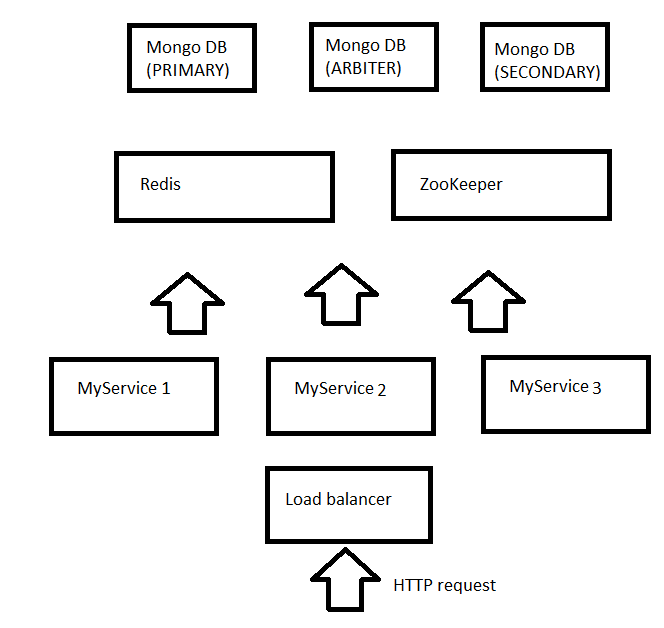
Итак масштабируемая система должна иметь несколько узлов (nodes), чтобы в случае увеличения нагрузки мы могли добавлять новые узлы и в случае выхода одного узла из строя остальные бы продолжали работать. Узел это железная или виртуальная машинка. На этом и остальных рисунках каждый квадратик это сервис, в соответствии с лучшими традициями SOA (Service-Oriented Architecture). В дальнейшем мы поговорим о том где и как можно располагать эти сервисы.
На чем современные компании пишут свои сервера. Например Twitter использует функциональный язык – Scala и имеет свою собственную библиотеку Finagle ( The twitter stack ). Scala позволяет писать неблокирующий (non blocking), неизменяющий ( immutable) код. Первое важно, чтобы экономить ресурсы сервера, тк поток не ждёт освобождение какого-либо ресурса, например при IO (input output) операциях. Второе позволяет в любой момент времени распараллелить код и выполнять вычисления в разных потоках без дополнительных усилий по синхронизации. Новый сервер мы стали писать именно на Scala и сначала с использованием Finagle но позднее переехали на Play framework. Преимущество второго в том, что он более динамично развивается и к нему постоянно появляется множество плагинов.
Для того, чтобы клиенты быстро получали информацию о добавлении нового клипборда на сервер мы использовали long poll технологию. Клиент обращается к сервису и если у сервиса нет новых данных то он не сра��у отвечает клиенту, а держит коннекцию в течении заданного таймаута, например 60 секунд. Если в течении этого таймаута сервер получает новые данные, то он немедленно возвращает их для удерживаемых коннекций. Клиент таким образом постоянно повторяет запросы и ждёт обновленных данных.
При таком механизме сервисы MyService1, MyService2 и тд должны уметь сообщать друг другу о новом буфере. Например если клиент висит и ждёт результата от MyService1 однако буфер был добавлен другим клиентом на MyService2 то MyService1 должен немедленно узнать об этом. Для того чтобы сервисы могли извещать друг друга о таких изменениях мы использовали remote actors из библиотеки Akka. Akka это библиотека которая позволяет изпользовать объекты без необходимости синхронизации доступа к ним. Это достигается тем, что каждому actor посылается сообщение, а не делается прямой вызов и в отдельный момент времени только одно сообщение обрабатывается actor. Кроме этого Akka позволяет вызывать actors из другого сервиса таким же образом как и локальные actors. Механизм remote actors скрывает межсетевое взаимодействие, что существенно облегчает разработку. Таким образом используя Akka MyService1 (и любой другой сервис) может извещать все остальные сервисы если к нему поподают новые данные.
Откуда же MyService1 может узнать IP адреса MyService2 и MyService3. Мы использовали ZooKeeper для того, чтобы хранить конфигурацию системы. Таким образом каждый сервис знает IP адрес ZooKeeper и может зарегестрироваться на нем, а также получить с него информацию о том, какие ещё ноды есть в системе.
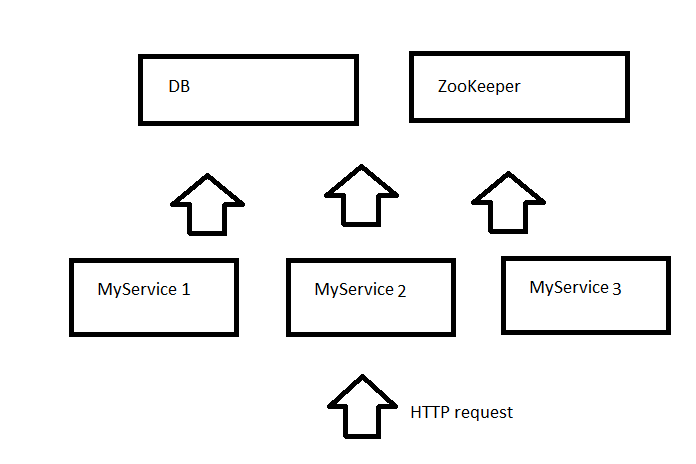
Из рисунка видно, что хотя мы создали масштабируемую систему, где можно добавлять или удалять ноды прямо в рантайм, однако база данных одна и она остается слабым местом системы. Каждое обращение к базе это достаточно долгая операция. Для того, чтобы снизить нагрузку на базу и увеличить общую производительность системы мы решили добавить кеш. В качестве кеша решено было использовать Redis. Redis это хранилище данных в памяти в формате ключ-значение (NoSQL key-value data store). Несмотря на то, что звучит не слишком понятно, идея очень простая. Redis позволяет получать значения по ключу и хранит всё это в памяти. Таким образом обращение к Redis очень быстрое. Чтобы использовать Redis наш сервис был соответственно изменен и стал обращаться за новыми данными сначала к Redis а только затем, если данные не найдены, к базе. Соответсвенно, когда приходил новый буфер, то он попадал сразу и в базу и в кеш.

Количество квадратиков в нашей схеме непрерывно прирастает, но зато увеличивается и надежность системы. Уберите MyService2 и запросы продолжат обрабатывать MyService1 и MyService3. Уберите Redis и сервисы будут напрямую получать данные из базы. Уберите… Нет, DB и ZooKeeper убирать пока что не надо, тк это обрушит всю нашу систему :)
Для того, чтобы обеспечить надежность базы данных она должна поддерживать репликации. Мы выбрали NoSQL базу данных MongoDB тк наши сервисы имеют JSON интерфейс и результаты удобнее хранить в JSON формате, который и поддерживается MongoDB. Кроме этого MongoDB прекрасно поддерживает репликации, те мы можем запустить несколько узлов с MongoDB, связать их в одну реплику и в случае выхода из строя какого либо узла все клиенты смогут продолжить работать с другими узлами. Реплики в MongoDB должны состоять не менее чем из 3х узлов: главный (primary) узел, второстепенный (secondary) и арбитр (arbiter) который следит за остальными узлами и в случае если главный узел вышел из строя, то делает второстепенный узел главным.
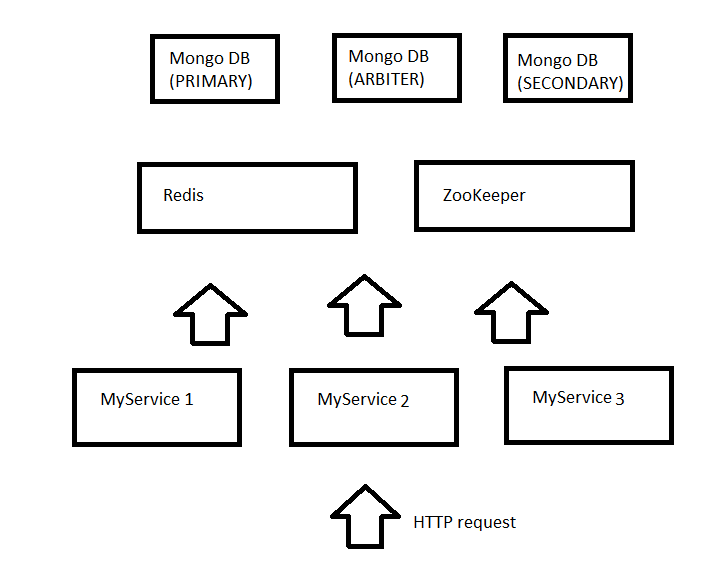
Теперь мы можем смело выключать один из узлов с MongoDB и наша система этого даже не заметит. Я не буду подробно останавливаться на ZooKeeper, но и он не будет являться ахелесовой пятой нашей системы, тк также как и MongoDB поддерживает репликации.
Дотошный читатель обратит внимание, что я обошел вопросом как распределяются запросы между узлами MyService1, MyService2 и MyService3. В серьёзных системах для этого используется балансировщик нагрузки – load balancer. Однако, если вы уже устали от бесконечного числа вспомогательных сервисов в нашей системе, то можете использовать DNS в качестве простого балансировщика нагрузки. Когда в DNS приходит запрос к сервису api.myservice.com то он возвращает несколько IP адресов. Хитрость в том, что для каждого запроса порядок этих IP адресов меняется. Например для первого запроса api.myservice.com вернулись: 132.111.21.2, 132.111.21.3, 132.111.21.4 а для второго 132.111.21.3, 132.111.21.4, 132.111.21.2 соответственно клиенты всегда пытаются сначала обратиться к первому IP из списка и только в случае ошибки будут использовать 2-й или 3-й.
Развертывание
В результате мы построили по-настоящему масштабируемую (можно добавлять и удалять узлы-сервисы), распределенную (сервисы могут находится на разных узлах и даже в разных data centers) систему.
Давайте проверим удовлетворяет ли наше приложение основным требованиям предъявляемым к подобным системам.
- Доступность – наша система всегда доступна. Если мы меняем железо для любой ноды, то остальные ноды продолжают работать. Также мы можем по очереди обновлять ПО
- Производительность – используя более сложных балансировщик нагрузки мы можем напрявлять европейских пользователей на европейский узел, а пользователей из америки на американский узел. Кроме того использование Redis существенно сокращает обращение к базе данных
- Надежность – при выходе из строя любого узла, остальные узлы продолжают работать
- Масштабируемость – можно сколько угодно добавлять MyServiceN
- Управляемость – хммм, здесь всё ещё есть вопросы, не так ли?
- Стоимость – все технологии и библиотеки, использованные в данном проекте бесплатные и/или open source
Таким образом под вопросом остался только один критерий – управляемость. Как проще всего разворачивать SOA системы, состоящие из десятков сервисов? Мы решили использовать довольно новую, но хорошо себя зарекомендовавшую технологию – Docker. Docker в чем-то схож с широко изспользуемыми виртуальными машинами, однако имеет ряд преимуществ. Используя Docker вы можете создать docker container для каждого сервиса, а затем запустить их все либо на одной либо на разных машинах. Важный момент, что так как Docker использует встроенный в Linux механизм виртуализации, то он не требует дополнительных ресурсов в отличие от виртуальных машин. Итак мы создали контейнеры для всех узлов нашей системы. Это позволяет одинаково легко развернуть тестовое окружение, где все контейнеры запущены на одном узле и рабочее окружение, где каждый контейнер на своём узле.
В какой-то момент мы столкнулись с вопросом где же размещать нашу систему. Рассматривался самый популярный облачный провайдер – Amazon, однако решили сэкономить и разместить наше приложение на более дешевом Digital Ocean.
