
Конечно, можно быть успешным программистом и без сакрального знания структур данных, однако они совершенно незаменимы в некоторых приложениях. Например, когда нужно вычислить кратчайший путь между двумя точками на карте, или найти имя в телефонной книжке, содержащей, скажем, миллион записей. Не говоря уже о том, что структуры данных постоянно используются в спортивном программировании. Рассмотрим некоторые из них более подробно.
Очередь
Итак, поздоровайтесь с Лупи!

Лупи обожает играть в хоккей со своей семьей. И под “игрой”, я подразумеваю:

Когда черепашки залетают в ворота, их выбрасывает на верх стопки. Заметьте, первая черепашка, добавленная в стопку — первой ее покидает. Это называется Очередь. Так же, как и в тех очередях, что мы видим в повседневной жизни, первый добавленный в список элемент — первым его покидает. Еще эту структуру называют FIFO (First In First Out).
Как насчет операций вставки и удаления?
q = [] def insert(elem): q.append(elem) #добавляем элемент в конец очереди print q def delete(): q.pop(0) #удаляем нулевой элемент из очереди print q
Стек
После такой веселой игры в хоккей, Лупи делает для всех блинчики. Она кладет их в одну стопку.

Когда все блинчики готовы, Лупи подает их всей семье, один за одним.

Заметьте, что первый сделанный ею блинчик — будет подан последним. Это называется Стек. Последний элемент, добавленный в список — покинет его первым. Также эту структуру данных называют LIFO (Last In First Out).
Добавление и удаление элементов?
s = [] def push(elem): #Добавление элемента в стек - Пуш s.append(elem) print s def customPop(): #удаление элемента из стека - Поп s.pop(len(s)-1) print s
Куча
Вы когда-нибудь видели башню плотности?
Все элементы сверху донизу расположились по своим местам, согласно их плотности. Что случится, если бросить внутрь новый объект?

Он займет место, в зависимости от своей плотности.
Примерно так работает Куча.
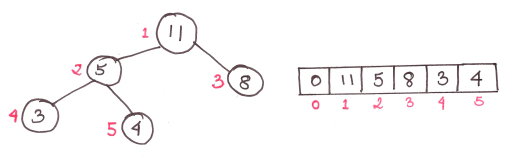
Куча — двоичное дерево. А это значит, что каждый родительский элемент имеет два дочерних. И хотя мы называем эту структуру данных кучей, но выражается она через обычный массив.
Также куча всегда имеет высоту logn, где n — количество элементов
На рисунке представлена куча типа max-heap, основанная на следующем правиле: дочерние элементы меньше родительского. Существуют также кучи min-heap, где дочерние элементы всегда больше родительского.
Несколько простых функций для работы с кучами:
global heap global currSize def parent(i): #Получить индекс родителя для i-того элемента return i/2 def left(i): #Получить левый дочерний элемент от i-того return 2*i def right(i): #Получить правый дочерний элемент от i-того return (2*i + 1)
Добавление элемента в существующую кучу
Для начала, мы добавляем элемент в самый низ кучи, т.е. в конец массива. Затем мы меняем его местами с родительским элементом до тех пор, пока он не встанет на свое место.

Алгоритм:
- Добавляем элемент в самый низ кучи.
- Сравниваем добавленный элемент с родительским; если порядок верный — останавливаемся.
- Если нет — меняем элементы местами, и возвращаемся к предыдущему пункту.
Код:
def swap(a, b): #меняем элемент с индексом a на элемент с индексом b temp = heap[a] heap[a] = heap[b] heap[b] = temp def insert(elem): global currSize index = len(heap) heap.append(elem) currSize += 1 par = parent(index) flag = 0 while flag != 1: if index == 1: #Дошли до корневого элемента flag = 1 elif heap[par] > elem: #Если индекс корневого элемента больше индекса нашего элемента - наш элемент на своем месте flag = 1 else: #Меняем местами родительский элемент с нашим swap(par, index) index = par par = parent(index) print heap
Максимальное количество проходов цикла while равно высоте дерева, или logn, следовательно, трудоемкость алгоритма — O(logn).
Извлечение максимального элемента кучи
Первый элемент в куче — всегда максимальный, так что мы просто удалим его (предварительно запомнив), и заменим самым нижним. Затем мы приведем кучу в правильный порядок, используя функцию:
maxHeapify().

Алгоритм:
- Заменить корневой элемент самым нижним.
- Сравнить новый корневой элемент с дочерними. Если они в правильном порядке — остановиться.
- Если нет — заменить корневой элемент на одного из дочерних (меньший для min-heap, больший для max-heap), и повторить шаг 2.
Код:
def extractMax(): global currSize if currSize != 0: maxElem = heap[1] heap[1] = heap[currSize] #Заменяем корневой элемент - последним heap.pop(currSize) #Удаляем последний элемент currSize -= 1 #Уменьшаем размер кучи maxHeapify(1) return maxElem def maxHeapify(index): global currSize lar = index l = left(index) r = right(index) #Вычисляем, какой из дочерних элементов больше; если он больше родительского - меняем местами if l <= currSize and heap[l] > heap[lar]: lar = l if r <= currSize and heap[r] > heap[lar]: lar = r if lar != index: swap(index, lar) maxHeapify(lar)
И вновь максимальное количество вызовов функции maxHeapify равно высоте дерева, или logn, а значит трудоемкость алгоритма — O(logn).
Делаем кучу из любого рандомного массива
Окей, есть два пути сделать это. Первый — поочередно вставлять каждый элемент в кучу. Это просто, но совершенно неэффективно. Трудоемкость алгоритма в этом случае будет O(nlogn), т.к. функция O(logn) будет выполняться n раз.
Более эффективный способ — применить функцию maxHeapify для ‘под-кучи’, от (currSize/2) до первого элемента.
Сложность получится O(n), и доказательство этого утверждения, к сожалению, выходит за рамки данной статьи. Просто поймите, что элементы, находящиеся в части кучи от currSize/2 до currSize, не имеют потомков, и большинство образованных таким образом ‘под-куч’ будут высотой меньше, чем logn.
Код:
def buildHeap(): global currSize for i in range(currSize/2, 0, -1): #третий агрумент в range() - шаг перебора, в данном случае определяет направление. print heap maxHeapify(i) currSize = len(heap)-1

Действительно, зачем это все?
Кучи нужны для реализации особого типа сортировки, называемого, как ни странно, “сортировка кучей”. В отличие от менее эффективных “сортировки вставками” и “сортировки пузырьком”, с их ужасной сложностью в O(n2), “сортировка кучей” имеет сложность O(nlogn).
Реализация до неприличия проста. Просто продолжайте последовательно извлекать из кучи максимальный (корневой) элемент, и записывайте его в массив, пока куча не опустеет.
Код:
def heapSort(): for i in range(1, len(heap)): print heap heap.insert(len(heap)-i, extractMax()) #вставляем максимальный элемент в конец массива currSize = len(heap)-1
Чтобы обобщить все вышесказанное, я написала несколько строчек кода, содержащего функции для работы с кучей, а для фанатов ООП оформила все в виде класса.
Легко, не правда ли? А вот и празднующая Лупи!

Хеш
Лупи хочет научить своих детишек различать фигуры и цвета. Для этого она принесла домой огромное количество разноцветных фигур.
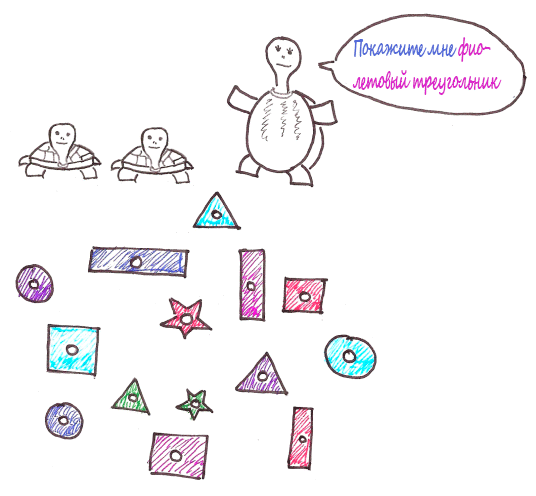
Через некоторое время черепашки окончательно запутались

Поэтому она достала еще одну игрушку, чтобы немного упростить процесс

Стало намного легче, ведь черепашки уже знали, что фигуры рассортированы по форме. А что, если мы пометим каждый столб?
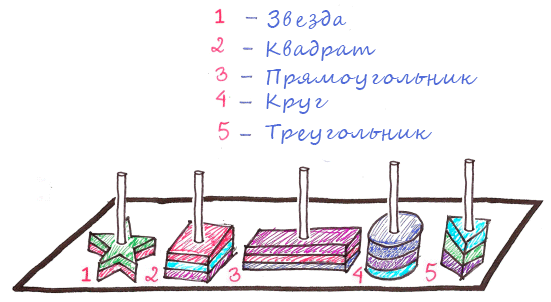
Черепашкам теперь нужно проверить столб с определенным номером, и выбрать из гораздо меньшего количества фигурок нужную. А если еще и для каждой комбинации формы и цвета у нас отдельный столб?
Допустим, номер столба вычисляется следующим образом:
Фиолетовый треугольник
ф+и+о+т+р+е = 22+10+16+20+18+6 = Столб 92
Красный прямоугольник
к+р+а+п+р+я = 12+18+1+17+18+33 = Столб 99
и.т.д.
Мы знаем, что 6*33 = 198 возможных комбинаций, значит нам нужно 198 столбов.
Назовем эту формулу для вычисления номера столба — Хеш-функцией.
Код:
def hashFunc(piece): words = piece.split(" ") #разбиваем строку на слова colour = words[0] shape = words[1] poleNum = 0 for i in range(0, 3): poleNum += ord(colour[i]) - 96 poleNum += ord(shape[i]) - 96 return poleNum
(с кириллицей немного сложнее, но я оставил так для простоты. — прим.пер.)
Теперь, если нам нужно будет узнать, где хранится розовый квадрат, мы сможем вычислить:
hashFunc('розовый квадрат')
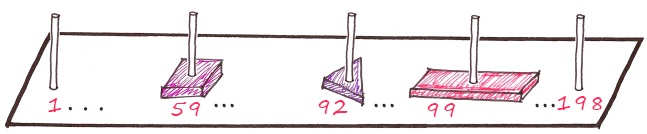
Это пример хеш-таблицы, где местоположение элементов определяется хеш-функцией.
При таком подходе время, затраченное на поиск любого элемента, не зависит от количества элементов, т.е. O(1). Другими словами, время поиска в хеш-таблице — константная величина.
Ладно, но допустим мы ищем “карамельный прямоугольник” (если, конечно, цвет “карамельный” существует).
hashFunc('карамельный прямоугольник')
вернет нам 99, что совпадает с номером для красного прямоугольника. Это называется “Коллизия”. Для разрешения коллизии мы используем “Метод цепочек”, подразумевающий, что каждый столб хранит список, в котором мы ищем нужную нам запись.
Поэтому мы просто кладем карамельный прямоугольник на красный, и выбираем один из них, когда хеш-функция указывает на этот столб.
Ключ к хорошей хеш-таблице — выбрать подходящую хеш-функцию. Бесспорно, это самая важная вещь в создании хеш-таблицы, и люди тратят огромное количество времени на разработку качественных хеш-функций.
В хороших таблицах ни одна позиция не содержит более 2-3 элементов, в обратном случае, хеширование работает плохо, и нужно менять хеш-функцию.

Еще раз, поиск, не зависящий от количества элементов! Мы можем использовать хеш-таблицы для всего, что имеет гигантские размеры.
Хеш-таблицы также используются для поиска строк и подстрок в больших кусках текста, используя алгоритм Рабина-Карпа или алгоритм Кнута-Морриса-Пратта, что полезно, например, для определения плагиата в научных работах.

На этом, думаю, можно заканчивать. В будущем я планирую рассмотреть более сложные структуры данных, например Фибоначчиеву кучу и Дерево отрезков. Надеюсь, этот неформальный гайд получился интересным и полезным.
Переведено для Хабра запертым на чердаке программистом.
