
Хочу рассказать о своем эксперименте по проверке «Теории шести рукопожатий». На написание этого материала меня вдохновила статья «Анализ дружеских связей VK с помощью Python» (чтобы избежать повторений, в дальнейшем я буду ссылаться на нее). Так как в целом задача мной была поставлена по-другому, да и использованные методы тоже отличаются, то я решил что это может быть интересно.
Формулировка задачи: визуализировать все связи между двумя пользователями внутри одной социальной сети. При этом связи не должны дублироваться, например если Ваня знает Петю через Олю, то Оля в дальнейших итерациях по поиску общих друзей не участвует. Чтобы попрактиковаться в API, я выбрал “Вконтакте”.
Отталкиваясь от ограничений API и функциональности методов, было решено, что оптимальным количеством «рукопожатий» с позиции времени получения информации будет 3. Так что проверять все-таки будем «Теорию трех рукопожатий», пока что. Таким образом при среднем количестве друзей 200, мы получаем выборку из 8 млн. человек. Например, в масштабах Украины я практически всегда находил связи. Структурно задачу можно разбить на следующие этапы:
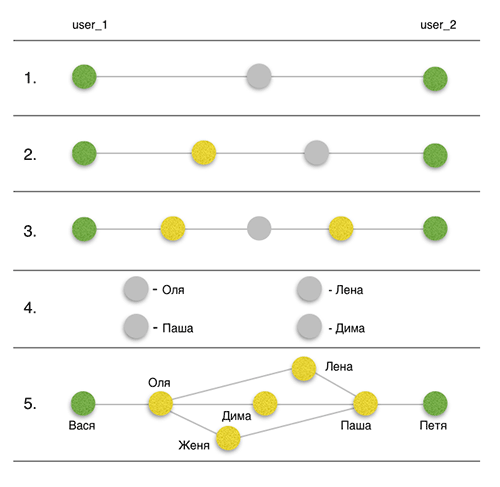
- Поиск общих друзей между исходным пользователем 1 (user_1) и исходным пользователем 2 (user_2).
- Поиск общих друзей между user_2 и друзьями user_1.
- Поиск общих друзей между друзьями user_2 и друзьями user_1.
- Получение детальной информации о найденных связях.
- Визуализация.
Итак, что нам понадобится:
import requests import time from threading import Thread from tokens import *
Requests — распространенная HTTP библиотека для Python, описана в статье «Библиотека для упрощения HTTP-запросов».
Time — базовый модуль, название которого говорит само за себя. Будем использовать для введения задержек во времени.
Threading — базовый модуль для работы с потоками. Хорошо описан в статье «Учимся писать многопоточные и многопроцессные приложения на Python».
Tokens — файл tokens.py будет содержать OAuth токены для авторизации в API. Как получить токен описано в исходной статье, а также на странице API «Вконтакте».
Прежде чем приступать к первому этапу, тезисно остановлюсь на функциональности API и некоторых ограничениях:
- Для обращения к методу API используется POST или GET запрос.
- Список использованных мной методов: users.get, friends.get, friends.getMutual, execute.
- Метод execute позволяет запускать до 25 методов одним запросом.
- В секунду можно осуществить не более 3 запросов (используя один токен).
- Ограничение для параметра target_uids метода friends.getMutual — 300. Об этом более подробно остановлюсь ниже.
Таким образом глобально схема сводится к отправке GET запросов на сервер «Вконтакте» и анализу ответов от сервера в формате json. При этом для оптимизации времени мы используем метод execute и многопоточность.
Ремарка к исходной статье, которая меня вдохновила. Автор статьи STLEON использует метод friends.getMutual в режиме “один к одному”, используя параметр target_uid. Я полагаю, что это было вызвано отсутствием параметра target_uids в прошлой версии API. Я же использую этот метод в режиме “один к многим”, что значительно экономит время. Параметр target_uids имеет ограничение на длину строки, о котором я ничего не нашел в документации. Экспериментально было установлено, что максимальная длина составляет порядка 310-330 UID в зависимости от длины каждого идентификатора. Я округлил этот показатель до 300.
Все выше сказанное подытожим объявлением следующих констант:
f_1_max = 300 f_2_max = 24 t = 0.35
Почему f_2_max = 24, а не 25, будет ясно позже.
Этап 1. Поиск общих друзей между user_1 и user_2

Напишем функцию, с помощью которой мы будем общаться с сервером «Вконтакте» посредствам GET запроса:
def vk (method, parameters, token): return requests.get('https://api.vk.com/method/%s?%s&access_token=%s' % (method, '&'.join(parameters), token)).json()
У этой функции есть три аргумента:
- method — название метода, к которому мы обращаемся через API.
- parameters — параметры этого метода (можно найти в описании каждого метода).
- token — строка, которая авторизирует Вас на сервере. Повторюсь, что получение токена подробно описано здесь и здесь.
Далее для сохранения всей собранной информации мы будем использовать множества. Инициализируем множества для каждого из трех “рукопожатий”.
edges_1, edges_2, edges_3 = set(), set(), set()
Для выполнения условия, чтобы связи не дублировались и Оля не фигурировала как общий друг Пети и Вани во всех трех “рукопожатиях”, а только в первом, необходимо ввести фильтры. Сразу же добавляем в фильтр первого “рукопожатия” исходных пользователей.
filter_1, filter_2 = set(), set() filter_1.update([user_1, user_2])
Находим друзей user_1 с помощью вызова метода friends.get. После выполнения обращения к методу API, вводим необходимую задержу во времени t = 0.35. Заметьте, что одним из параметров является версия API (v=5.4 в моем случае). Очень важно везде ее указывать, потому что могут появиться несоответствия. Параметры метода order и count — использовать опционально.
friends_1 = set(vk('friends.get', ['user_id=%s' % user_1, 'order=hints', 'count=900', 'v=5.4'], token_1)['response']['items']) time.sleep(t)
Далее переходим непосредственно к поиску общих друзей между user_1 и user_2 с помощью вызова метода friends.getMutual.
mutual_friends = vk('friends.getMutual', ['source_uid=%s' % user_1, 'order=hints', 'target_uid=%s' % user_2, 'v=5.4'], token_1)['response'] time.sleep(t)
И последний пункт первого этапа — сохранение информации в множество edges_1, обновление filtr_1 и удаление найденных общих друзей из списка друзей user_1, чтобы избежать повторений в будущем.
for user in mutual_friends: edges_1.update([(user_1, user), (user, user_2)]) friends_1.remove(user) filter_1.update([user])
Этап 2. Поиск общих друзей между user_2 и друзьями user_1 (friends_1)

Глобально второй этап повторяет первый, вся разница в том, что вместо поиска общих друзей в режиме “один к одному”, мы используем режим “один к многим”, что требует несколько лишних строк кода.
Инициализируем список, в который будем сохранять добытых друзей, а также некоторые переменные, которые нам понадобятся в промежуточных вычислениях.
user_1_mutual_friends, temp_users, j = [], [], 0
Далее, отсчитывая порции (не самое подходящее слово) из друзей user_1 по 300 UID, мы поочередно отправляем запросы к серверу об общих друзьях между user_2 и порцией UID, которые записываются в параметр target_uids метода friends.getMutual.
for i, friend in enumerate(friends_1): temp_users += [friend] j += 1 if j == f_1_max: user_1_mutual_friends += vk('friends.getMutual', ['source_uid=%s' % user_2, 'order=hints', 'target_uids=%s' % str(temp_users)[1:-1], 'v=5.4'], token_1)['response'] temp_users, j = [], 0 time.sleep(t) if i == len(friends_1) - 1 and len(friends_1) % f_1_max != 0: user_1_mutual_friends += vk('friends.getMutual', ['source_uid=%s' % user_2, 'order=hints', 'target_uids=%s' % str(temp_users)[1:-1], 'v=5.4'], token_1)['response'] time.sleep(t)
Сохраняем полученную информацию в множество edges_2 и обновляем информацию в фильтре, как было в предыдущем этапе. Здесь могут быть исключения, допустим если UID закрыл доступ к общим друзьям или страница пользователя удалена, поэтому используем конструкцию try-except.
for friend in user_1_mutual_friends: if friend['id'] != user_2 and friend['id'] not in filter_1: try: if friend['common_count'] > 0: for common_friend in friend['common_friends']: if common_friend != user_1 and common_friend not in filter_1: edges_2.update([(user_1, friend['id']), (friend['id'], common_friend), (common_friend, user_2)]) friends_1.remove(friend['id']) filter_2.update([friend['id'], common_friend]) except: continue
Этап 3. Поиск общих друзей между друзьями user_2 и друзьями user_1
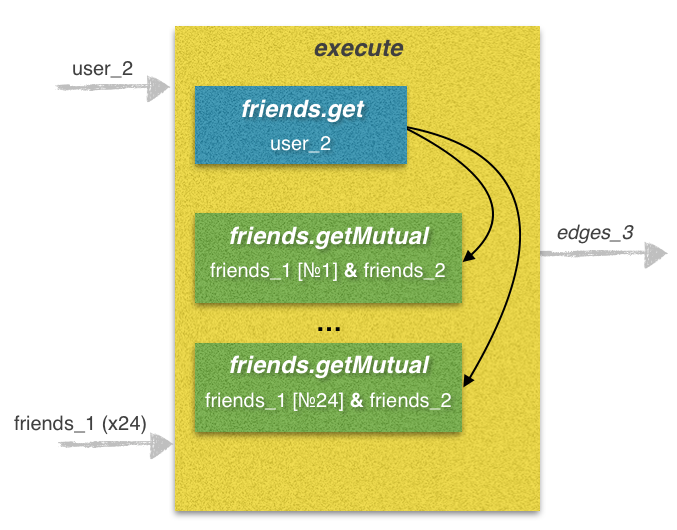
Данный этап является наиболее затратным по времени, так как запросов отправить нужно очень много. Именно здесь невозможно обойтись без использования метода execute. Из практики скажу, что без использования многопоточности, время на выполнение данного этапа по этому алгоритму составляет 50 — 120 секунд, а в некоторых случаях еще больше. С помощью использования нескольких потоков возможно свести время до выполнения одного запроса execute, который обрабатывается от 5 до 12 секунд.
Объявляем filter_3, объединяя множества filter_1 и filter_2. Преобразуем множество друзей user_1 (friends_1) в список.
filter_3 = filter_1.union(filter_2) friends_1 = list(friends_1)
Далее последует монстрозный блок кода, в котором мы объявляем функцию для поиска общих друзей между друзьями user_1 и друзьями user_2 и сохранения информации в множество edges_3. Здесь опять-таки весь алгоритм такой же, как и в предыдущих этапах, только используется принцип “многие ко многим”, что еще больше усложняет код, тем более в моей имплементации он явно избыточный, так что вам есть над чем поработать. Ниже я приведу некоторые пояснения к этому многобуквию.
def get_edges_3 (friends_1, token): prefix_code = 'code=var friends = API.friends.get({"v": "5.4", "user_id":"%s", "count":"500", "order": "hints"}).items; ' % user_2 lines, j, k = [], 0, -1 for i, friend in enumerate(friends_1): lines += ['API.friends.getMutual({"v": "5.4", "source_uid": "%s", "count":"500", "target_uids": friends})' % friend] # Generating string for 'execute' request. j += 1 if j == f_2_max: code = prefix_code + 'return [' + ','.join(str(x) for x in lines) + '];' response = vk('execute', [code, 'v=5.4'], token_1) for friends in response['response']: k += 1 if len(edges_3) < max_edges_3: try: for one_friend in friends: if one_friend['common_count'] > 0: for common_friend in one_friend['common_friends']: if common_friend not in filter_3 and one_friend['id'] not in filter_3: edges_3.update([(user_1, friends_1[k]), (friends_1[k], common_friend), (common_friend, one_friend['id']), (one_friend['id'], user_2)]) except: continue lines, j = [], 0 time.sleep(t) if i == len(friends_1) - 1 and len(friends_1) % f_2_max != 0 : code = prefix_code + 'return [' + ','.join(str(x) for x in lines) + '];' response = vk('execute', [code, 'v=5.4'], token_1) for friends in response['response']: k += 1 if len(edges_3) < max_edges_3: try: for one_friend in friends: if one_friend['common_count'] > 0: for common_friend in one_friend['common_friends']: if common_friend not in filter_3 and one_friend['id'] not in filter_3: edges_3.update([(user_1, friends_1[k]), (friends_1[k], common_friend), (common_friend, one_friend['id']), (one_friend['id'], user_2)]) except: continue time.sleep(t)
Сумма строк prefix_code и lines представляет собой код в формате VKScript и является единственным параметром для метода execute. Этот скрипт содержит в себе 25 обращений к методам API.
prefix_code — часть строки, содержащая обращение №1 к методу friends.get. Здесь мы получаем список друзей user_2 и присваиваем его переменной friends.
lines — вторая часть строки, содержащая обращения №№ 2-25 к методу friends.getMutual. Здесь мы получаем список общих друзей между каждым из 24 друзей user_1 и списком друзей user_2. В цикле мы складываем prefix_code и 24 строки lines, таким образом получая строку code, которую используем как параметр к методу execute.
Далее я приведу пример с использованием нескольких потоков, но подробно не буду останавливаться на нем. Всю информацию можно найти в статье «Учимся писать многопоточные и многопроцессные приложения на Python».
t1 = Thread(target=get_edges_3, args=(friends_1[ : len(friends_1) * 1/3], token_1)) t2 = Thread(target=get_edges_3, args=(friends_1[len(friends_1) * 1/3 : len(friends_1) * 2/3], token_2)) t3 = Thread(target=get_edges_3, args=(friends_1[len(friends_1) * 2/3 : ], token_3)) t1.start() t2.start() t3.start() t1.join() t2.join() t3.join()
Этап 4. Получение детальной информации о найденных связях
Теперь мы должны сложить все ребра нашего еще непостроенного графа друзей и извлечь из них список вершин. Далее по описанному выше шаблону с помощью метода users.get порциями по 300 UID отправляем запросы на получение данных о фамилии и имени пользователей. На выходе получаем список, в каждой ячейке которого будет UID и словарь с информацией о данном UID. Эти данные в комплексе с множествами ребер в дальнейшем используем для визуализации.
edges = list(edges_1) + list(edges_2) + list(edges_3) nodes = [] for edge in edges: nodes += [edge[0], edge[1]] nodes = list(set(nodes)) nodes_info, temp_nodes, j = [], [], 0 for i, node in enumerate(nodes): temp_nodes += [node] j += 1 if j == f_1_max: nodes_info += vk('users.get', ['user_ids=%s' % str(temp_nodes)[1:-1], 'fields=first_name, last_name', 'v=5.4'], token_1)['response'] temp_nodes, j = [], 0 time.sleep(t) if i == len(nodes) - 1 and len(nodes) % f_1_max != 0: nodes_info += vk('users.get', ['user_ids=%s' % str(temp_nodes)[1:-1], 'fields=first_name, last_name', 'v=5.4'], token_1)['response'] time.sleep(t) for i, node in enumerate(nodes_info): try: nodes[i] = (nodes[i], {'first_name': node['first_name'], 'last_name': node['last_name']}) except: continue
Этап 5. Визуализация
На технической реализации этого этапа я подробно останавливаться не буду. Опишу лишь кратко свой опыт.
Как и в исходной статье, я пробовал использовать библиотеку networkx для построения графа. Изменял диаметр и цвет вершин в зависимости от пола или количества связей, испробовал много методов визуализации, которые доступны в этой библиотеке, но результат мне не нравился. Беспорядочный граф получался не информативным при среднем и большом количестве ребер и вершин. Информация терялась.
Я пришел к выводу, что необходимо какое-то интерактивное решение. Первым, что я нашел, была библиотека D3.js. Но и здесь в формате обычного графа, несмотря на интерактивность, результат был неудовлетворительным. Затем в той же библиотеке был найден пример древовидного построения “Radial Reingold–Tilford Tree”, который мне показался подходящим. При таком построении в центре оказывается user_1, а user_2 — как бы на краю каждой ветви дерева.

Я смоделировал всю связку с использованием веб-фреймворка СherryPy и результат меня удовлетворил, хотя и пришлось все равно ввести ограничения для отображаемых данных (в зависимости от типа и количества найденных связей). Я намеренно опустил подготовку данных для визуализации, так как эта процедура не представляет интереса и отличается в зависимости от выбранного метода. Мой вариант кода доступен на репозитории GitHub, где также описана подготовка данных для использования с библиотекой D3.js на примере шаблона “Radial Reingold–Tilford Tree”.
Еще было бы интересно отобразить взаимосвязи между списком друзей вот таким образом (см. рисунок ниже), так что можете экспериментировать. Этот пример взят также из D3.js и называется он D3 Dependencies.
Что касается проверки теории, то в масштабах Украины схема с тремя рукопожатиями работает в 90% случаев. Исключения составляют пользователи с очень маленьким количеством друзей.
Спасибо за внимание.
