На просторах интернета много отрывочной информации о той или иной ORM для Андроид. Пока что мне не попадалось качественное сравнение ведущих ORM. Существующие статьи попахивают пиаром той или иной системы и ставят в невыгодное положение своих конкурентов либо некорректной постановкой тестирования, либо вообще использованием заведомо неверных настроек, либо не включением в тестирование сильных соперников.
Данное тестирование проведено было скорее для собственного интереса. Т.к. ORM много, все они разные, и хотелось бы иметь объективное представление о существующих системах.
За основу был взят репозиторий AndroidDatabaseLibraryComparison. Здесь их изначальная статья. Как видно автор сначала попытался не включить в обзор GreenDao, а когда его несколько раз попросили включил его с абсолютно неверными настройками, в результате чего “superfast Android ORM” оказался чуть ли не медленнее всех.
Отдельно хочу отметить, что большинство ORM все таки не полноценные и очень редко какая библиотека поддерживает запись и чтение объекта с вложенными коллекциями без танцев с аннотациями и отдельных подзапросов.
Тестировались 2 модели. Простая, т.н. POJO:
Простые типы, линейная структура. Данный объект создавался в 10000 экземплярах, экземпляры помещались в коллекцию и коллекция сохранялась средствами ORM в базу. Повторялось 6 раз.
На этапе чтения – коллекция считывалась, производилась сверка считаных полей во первых для контроля того, что данные были записаны и прочитаны, во вторых чтобы избежать хитрых Lazy чтений. После каждого считывания приложение закрывалось через менеджер задач и запускалось заново. Дело в том, что у некоторых ORM, таких как Realm, DBFlow и GreenDao есть свои кэши. И если считать сразу после записи, либо 2 раза подряд, чтение происходит их кэша практически мгновенно, что искажает общий результат. Да это можно считать как преимущество и следует учитывать при выборе ORM.
Сложная модель. Объект с вложенными списками:
Объект создавался в 50 экземплярах. Каждая вложенная коллекция так же заполнялась 50 экземплярами. Производилась запись. При считывании данные проверялись на корректность.
Каждый тест, опять же, проводился 6 раз. В результирующих графиках числа у столбцов — усредненные значения времени выполнения.
Картинок много, поэтому под спойлером:
Действительно очень быстрый. Действительно в некоторых случаях быстрее чистого SQLite (здесь следует отметить что в SQL использовался простой плоских алгоритм. Если подумать, то можно уменьшить число обращений к базе, использовав LEFT JOIN, но тут надо было думать, потом дебажить а мне было не охота, так что если есть желание — welcome). Что следует особенно подчеркнуть – очень простой во внедрении. Интуитивно понятен. Огромный плюс, это то, что Realm является полноценной ORM. Т.е. сохраняешь объект/считываешь объект: не нужно думать о внутренних коллекциях, их соотношениях, аннотировать безумными «Foreign...», «One-to-many...» ключами и прочими наворотам. Все работает их коробки.
Но есть и свои недостатки. Это все таки присутствуют странные падения с ассемблерным стеком в консоле. Да они очень редки, но есть. Все поля должны быть private, должен быть пустой конструктор и getter+setter каждому полю. Конечно в последних версиях появилась поддержка Lombok, но это еще +1 библиотека и +1 плагин в проект. Конечно и без Lombok это делается в 3 шортката в Android Studio, но это еще пачка boilerplate кода вам в проект. Кстати о размере: +5 мегабайтов к apk просто за подключение Realm.
Так же следует учитывать compile-time классы, которые не существуют до того как вы соберете первый раз проект. Сложности с Parceler, различия RealmResult и RealmObject, невозможности чтения объекта после realm.close(). Коллекции RealmList/RealmResult хоть и унаследованы от List, но не поддерживают многих базовых методов, таких как addAll, indexOf, toArray. Все это добавляет дополнительные проблемы. Конечно они решаемы, но сложность проекта возрастает и это тоже следует учитывать.
В целом работать с Realm приятно. Плюс: хорошая документация, практически все вопросы можно решить прочитав официальный сайт.
Очень старый и хорошо себя зарекомендовавший ORM. Одна проблема: последний релиз был 3 года назад. Много устарело. Сам подход устарел. Кодогенерация при наличии compile-time аннотаций в 2016 году? Вы серьезно хотите в это ввязаться? В целом показывает себя обычным середнячком. Где-то не 5-6м месте. Единственная приятная особенность: считывание вложенных коллекций автоматом при считывании родителя. Прямо как Realm. Только медленнее. Но у других ORM этого нет.
The superfast Android ORM for SQLite. Так заявлено на официальном сайте. И он действительно superfast. Иногда даже быстрее Realm. Но опять же кодогенерация. Вам придется создавать базу в отдельном проекте, при помощи дополнительных команд, потом его компилить и только тогда у вас появятся классы с которыми можно будет работать. Сгенерированые классы можно модифицировать, но следует помнить, что если не включить специальные комментарии, все они создадутся по новой при перегенерирации. Сама библиотека – быстрая и небольшого размера. Так что есть свои плюсы и свои минусы. Использовать или нет — решать вам.
Еще один фаворит по скорости (но не по удобству). Очень быстрая, как заявляли авторы — FASTEST ANDROID ORM DATABASE LIBRARY, но, мы видим, это не так. Annotation processing, т.е. генерация кода в процессе компиляции. Как следствие, например save() превращается в команды sql compileStatement, что обеспечивает наибольшую производительность. Потери скорости конечно на фабриках и рефлексии, куда же без этого. Поддерживает кэширование результатов, что позволяет получать данные из кэша практически мгновенно.
Но есть и минусы: библиотека развивается, сейчас в релизе 3я бета версия не совместимая со 2й. Половина официальной документации на 2ю, примеров мало, официальная документация неполная и порой вообще с ошибками. Глюки вылазят в самых неожиданных местах. Например если назвать имя pakage, в котором лежит ваш класс с большой буквы, проект у вас не скомпилируется. И вы даже не будете знать почему. Нормального текста ошибок нет. Проблемы с миграцией. Может если посидеть подольше, что-то и получится, но у меня миграция так и не взлетела, хотя все делал по примерам. В общем нужно вложить много человеко-часов чтобы начать пользоваться этот библиотекой нормально. Да что за примером далеко ходить, у самих авторов пример в этом тесте был не рабочий, пришлось доделывать.
Простая, не очень медленная, порой даже быстрая. Работает даже без аннотаций! Но для желающих, конечно, есть всякие @Ignore и даже Index. Единственная проблема – работает не от объекта, а от базы данных. Т.е. чтобы записать объект надо сделать примерно следующие манипуляции:
Что не всегда удобно. Плюс обязательно надо заводить поле Long _id у каждого объекта.
Библиотека была добавлена в обзор не мной, но доделывал недостающие тесты я. Библиотека ужасна. Просто ужасна. Просто посмотрите на графики. Знаете почему так? Потому что авторы делают «SELECT * FROM %s WHERE %s LIMIT 1» на КАЖДУЮ запись в базу! Да да. Это авторы эмулируют «INSERT OR REPLACE». Причем выбора у вас нет. У вас есть только Save() и все. Считывание – простая обертка над sql: Query.many(AddressItem.class, «select * from AddressItem where addressBook=?», String.valueOf(id)).get().asList(). Это ORM? Правда? Механизма создания базы – нет вообще. Пишите «CREATE TABLE» вручную.
Ну, что тут скажешь. Просто ORM без преимуществ. Скоростью не отличается.
Еще один compile-time ORM. В целом довольно шустрый. Что-то сказать о преимуществах/недостатках не могу, т.к. не работал.
Простой, доступный, но ужасно медленный. Рефлексия на рефлексии с runtime-чтениями аннотаций выливается в очень медленную работу. До недавнего времени писал на каждую запись в базу «Log.i(SUGAR, object.getClass().getSimpleName() + " saved: " + id);». Если убрать эту строку – скорость записи возрастает иногда в 2 раза! Похоже авторы не озабочены производительностью в угоду простоты. Но с простотой тут все в порядке: минимум аннотаций, простые save(), find(), хотя, кого этим удивишь?
Здесь речь пойдет про чистый SQL, нацеленный на максимальную скорость. Это «compileStatement» и bindString(i, value), да, да, по индексу, а не по имени. И никаких ContentValues. Только не в мою смену!
SQLlist безусловно в чистом виде практически всегда лидер. Исключение составляет только Realm на операциях комплексного чтения, вероятно дает знать nosql структура базы. Но, как я упоминал выше, уверен это можно оптимизировать.
Кто-то спросит, что означает на первом графике колонка «SQLite 50x»? Это multi-row запись, когда каждая вставка в базу делается по 50 объектов:
INSERT INTO table VALUES(?1, ?2, ?3), VALUES(?4, ?5, ?6), VALUES(?7, ?8, ?9)…
Это значительно усложняет код, поэтому я сделал его только для простого теста. В проекте на гитхабе этот код закомментирован.
Так же на чистом SQL особенно заметно влияние индексов и то, как замедляется запись в индексированную таблицу, и то как ускоряется чтение. Ну это уже прописные истины и использование индексов каждый должен выбирать под задачу.
Безусловно тестирование не полное. Безусловно не учтены скорость случайного чтения. Так же нет тестирования на скорость инициализации ORM, т.е. время от момента создания самой обертки ORM до готовности работать с базой. Есть NoSQL вроде Snappy-DB, которые было бы интересно посмотреть в деле. Есть новые ORM вроде requery, о которых тоже мало что известно, но заявления у них как всегда громкие (поддержка RxJava, reflection-free и прочее).
На все это нужно время и, если есть желающие, код проекта открыт: github.com/Rexee/AndroidDatabaseLibraryComparison
Данное тестирование проведено было скорее для собственного интереса. Т.к. ORM много, все они разные, и хотелось бы иметь объективное представление о существующих системах.
За основу был взят репозиторий AndroidDatabaseLibraryComparison. Здесь их изначальная статья. Как видно автор сначала попытался не включить в обзор GreenDao, а когда его несколько раз попросили включил его с абсолютно неверными настройками, в результате чего “superfast Android ORM” оказался чуть ли не медленнее всех.
Отдельно хочу отметить, что большинство ORM все таки не полноценные и очень редко какая библиотека поддерживает запись и чтение объекта с вложенными коллекциями без танцев с аннотациями и отдельных подзапросов.
Методика тестирования
Тестировались 2 модели. Простая, т.н. POJO:
Простая
public class SimpleAddressItem{ String name; String address; String city; String state; long phone; }
Простые типы, линейная структура. Данный объект создавался в 10000 экземплярах, экземпляры помещались в коллекцию и коллекция сохранялась средствами ORM в базу. Повторялось 6 раз.
На этапе чтения – коллекция считывалась, производилась сверка считаных полей во первых для контроля того, что данные были записаны и прочитаны, во вторых чтобы избежать хитрых Lazy чтений. После каждого считывания приложение закрывалось через менеджер задач и запускалось заново. Дело в том, что у некоторых ORM, таких как Realm, DBFlow и GreenDao есть свои кэши. И если считать сразу после записи, либо 2 раза подряд, чтение происходит их кэша практически мгновенно, что искажает общий результат. Да это можно считать как преимущество и следует учитывать при выборе ORM.
Сложная модель. Объект с вложенными списками:
Сложная
public class AddressBook{ Long id; String name; String author; Collection<AddressItem> addresses; Collection<Contact> contacts; } public class AddressItem extends SimpleAddressItem { AddressBook addressBook; } public class Contact{ String name; String email; AddressBook addressBook; }
Объект создавался в 50 экземплярах. Каждая вложенная коллекция так же заполнялась 50 экземплярами. Производилась запись. При считывании данные проверялись на корректность.
Каждый тест, опять же, проводился 6 раз. В результирующих графиках числа у столбцов — усредненные значения времени выполнения.
Результаты
Картинок много, поэтому под спойлером:
Результаты
Простая модель. Запись:
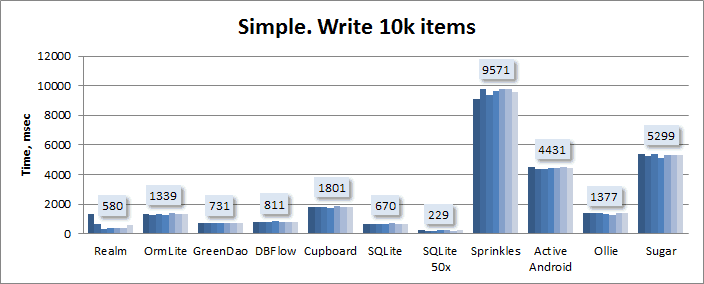
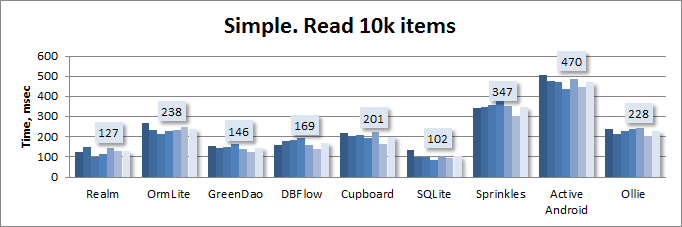
Простая модель. Чтение:

Простая модель. Чтение без Sugar ORM:
Сложная модель. Запись:

Сложная модель. Чтение:
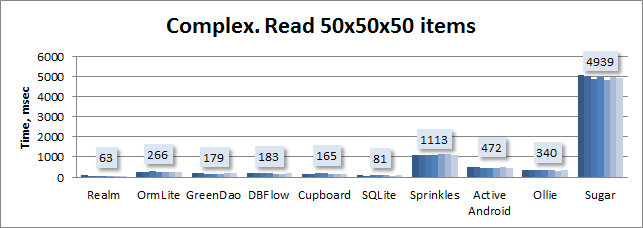
Сложная модель. Чтение без Sugar ORM:
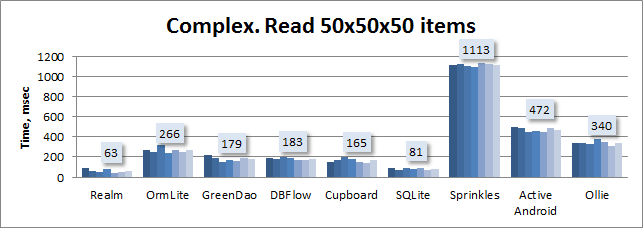
Простая модель. Чтение:
Простая модель. Чтение без Sugar ORM:
Сложная модель. Запись:
Сложная модель. Чтение:
Сложная модель. Чтение без Sugar ORM:
Участники тестирования
1. Realm
Действительно очень быстрый. Действительно в некоторых случаях быстрее чистого SQLite (здесь следует отметить что в SQL использовался простой плоских алгоритм. Если подумать, то можно уменьшить число обращений к базе, использовав LEFT JOIN, но тут надо было думать, потом дебажить а мне было не охота, так что если есть желание — welcome). Что следует особенно подчеркнуть – очень простой во внедрении. Интуитивно понятен. Огромный плюс, это то, что Realm является полноценной ORM. Т.е. сохраняешь объект/считываешь объект: не нужно думать о внутренних коллекциях, их соотношениях, аннотировать безумными «Foreign...», «One-to-many...» ключами и прочими наворотам. Все работает их коробки.
Но есть и свои недостатки. Это все таки присутствуют странные падения с ассемблерным стеком в консоле. Да они очень редки, но есть. Все поля должны быть private, должен быть пустой конструктор и getter+setter каждому полю. Конечно в последних версиях появилась поддержка Lombok, но это еще +1 библиотека и +1 плагин в проект. Конечно и без Lombok это делается в 3 шортката в Android Studio, но это еще пачка boilerplate кода вам в проект. Кстати о размере: +5 мегабайтов к apk просто за подключение Realm.
Так же следует учитывать compile-time классы, которые не существуют до того как вы соберете первый раз проект. Сложности с Parceler, различия RealmResult и RealmObject, невозможности чтения объекта после realm.close(). Коллекции RealmList/RealmResult хоть и унаследованы от List, но не поддерживают многих базовых методов, таких как addAll, indexOf, toArray. Все это добавляет дополнительные проблемы. Конечно они решаемы, но сложность проекта возрастает и это тоже следует учитывать.
В целом работать с Realm приятно. Плюс: хорошая документация, практически все вопросы можно решить прочитав официальный сайт.
2. OrmLite
Очень старый и хорошо себя зарекомендовавший ORM. Одна проблема: последний релиз был 3 года назад. Много устарело. Сам подход устарел. Кодогенерация при наличии compile-time аннотаций в 2016 году? Вы серьезно хотите в это ввязаться? В целом показывает себя обычным середнячком. Где-то не 5-6м месте. Единственная приятная особенность: считывание вложенных коллекций автоматом при считывании родителя. Прямо как Realm. Только медленнее. Но у других ORM этого нет.
3. GreenDao
The superfast Android ORM for SQLite. Так заявлено на официальном сайте. И он действительно superfast. Иногда даже быстрее Realm. Но опять же кодогенерация. Вам придется создавать базу в отдельном проекте, при помощи дополнительных команд, потом его компилить и только тогда у вас появятся классы с которыми можно будет работать. Сгенерированые классы можно модифицировать, но следует помнить, что если не включить специальные комментарии, все они создадутся по новой при перегенерирации. Сама библиотека – быстрая и небольшого размера. Так что есть свои плюсы и свои минусы. Использовать или нет — решать вам.
4. DBFlow
Еще один фаворит по скорости (но не по удобству). Очень быстрая, как заявляли авторы — FASTEST ANDROID ORM DATABASE LIBRARY, но, мы видим, это не так. Annotation processing, т.е. генерация кода в процессе компиляции. Как следствие, например save() превращается в команды sql compileStatement, что обеспечивает наибольшую производительность. Потери скорости конечно на фабриках и рефлексии, куда же без этого. Поддерживает кэширование результатов, что позволяет получать данные из кэша практически мгновенно.
Но есть и минусы: библиотека развивается, сейчас в релизе 3я бета версия не совместимая со 2й. Половина официальной документации на 2ю, примеров мало, официальная документация неполная и порой вообще с ошибками. Глюки вылазят в самых неожиданных местах. Например если назвать имя pakage, в котором лежит ваш класс с большой буквы, проект у вас не скомпилируется. И вы даже не будете знать почему. Нормального текста ошибок нет. Проблемы с миграцией. Может если посидеть подольше, что-то и получится, но у меня миграция так и не взлетела, хотя все делал по примерам. В общем нужно вложить много человеко-часов чтобы начать пользоваться этот библиотекой нормально. Да что за примером далеко ходить, у самих авторов пример в этом тесте был не рабочий, пришлось доделывать.
5. Cupboard
Простая, не очень медленная, порой даже быстрая. Работает даже без аннотаций! Но для желающих, конечно, есть всякие @Ignore и даже Index. Единственная проблема – работает не от объекта, а от базы данных. Т.е. чтобы записать объект надо сделать примерно следующие манипуляции:
CupboardDatabase database = new CupboardDatabase(context); SQLiteDatabase db = database.getWritableDatabase(); DatabaseCompartment dbc = cupboard().withDatabase(db); dbc.put(addresses);
Что не всегда удобно. Плюс обязательно надо заводить поле Long _id у каждого объекта.
6. Sprinkles
Библиотека была добавлена в обзор не мной, но доделывал недостающие тесты я. Библиотека ужасна. Просто ужасна. Просто посмотрите на графики. Знаете почему так? Потому что авторы делают «SELECT * FROM %s WHERE %s LIMIT 1» на КАЖДУЮ запись в базу! Да да. Это авторы эмулируют «INSERT OR REPLACE». Причем выбора у вас нет. У вас есть только Save() и все. Считывание – простая обертка над sql: Query.many(AddressItem.class, «select * from AddressItem where addressBook=?», String.valueOf(id)).get().asList(). Это ORM? Правда? Механизма создания базы – нет вообще. Пишите «CREATE TABLE» вручную.
7. ActiveAndroid
Ну, что тут скажешь. Просто ORM без преимуществ. Скоростью не отличается.
8. Ollie
Еще один compile-time ORM. В целом довольно шустрый. Что-то сказать о преимуществах/недостатках не могу, т.к. не работал.
9. Sugar ORM
Простой, доступный, но ужасно медленный. Рефлексия на рефлексии с runtime-чтениями аннотаций выливается в очень медленную работу. До недавнего времени писал на каждую запись в базу «Log.i(SUGAR, object.getClass().getSimpleName() + " saved: " + id);». Если убрать эту строку – скорость записи возрастает иногда в 2 раза! Похоже авторы не озабочены производительностью в угоду простоты. Но с простотой тут все в порядке: минимум аннотаций, простые save(), find(), хотя, кого этим удивишь?
10. SQLlite.
Здесь речь пойдет про чистый SQL, нацеленный на максимальную скорость. Это «compileStatement» и bindString(i, value), да, да, по индексу, а не по имени. И никаких ContentValues. Только не в мою смену!
SQLlist безусловно в чистом виде практически всегда лидер. Исключение составляет только Realm на операциях комплексного чтения, вероятно дает знать nosql структура базы. Но, как я упоминал выше, уверен это можно оптимизировать.
Кто-то спросит, что означает на первом графике колонка «SQLite 50x»? Это multi-row запись, когда каждая вставка в базу делается по 50 объектов:
INSERT INTO table VALUES(?1, ?2, ?3), VALUES(?4, ?5, ?6), VALUES(?7, ?8, ?9)…
Это значительно усложняет код, поэтому я сделал его только для простого теста. В проекте на гитхабе этот код закомментирован.
Так же на чистом SQL особенно заметно влияние индексов и то, как замедляется запись в индексированную таблицу, и то как ускоряется чтение. Ну это уже прописные истины и использование индексов каждый должен выбирать под задачу.
Заключение
Безусловно тестирование не полное. Безусловно не учтены скорость случайного чтения. Так же нет тестирования на скорость инициализации ORM, т.е. время от момента создания самой обертки ORM до готовности работать с базой. Есть NoSQL вроде Snappy-DB, которые было бы интересно посмотреть в деле. Есть новые ORM вроде requery, о которых тоже мало что известно, но заявления у них как всегда громкие (поддержка RxJava, reflection-free и прочее).
На все это нужно время и, если есть желающие, код проекта открыт: github.com/Rexee/AndroidDatabaseLibraryComparison
