По ящикам шкафов да пыльным полкам уже десятилетиями складируются дюжины семейных фотоальбомов. Состояние некоторых из них давно заставляет задумываться об «оцифровке» накопившегося материала. И чтобы хоть чуточку ускорить предстоящий процесс, было принято решение сканировать по несколько фотографий за раз. Однако перспектива разгребать получаемый в результате этого контент и руками дробить его на отдельные кадры мне не улыбалась. В итоге родилось решение...
Учитывая мое знакомство с основами python и интерес к компьютерному зрению, подвернувшаяся практическая задачка пришлась весьма кстати. В самом начале я проводил тестирование на изображении собранном в Pixelmator'е из трех других. Забегая вперед, нужно сказать что тогда я не предусмотрел возможность наклона фотографий на исходном изображении. Каждой в свою сторону. Тогда, отобрав несколько фотографий и сделав пару заходов к МФУ, я получил два изображения, на которых проверял работоспособность кода по мере написания. Ввиду личного содержимого альбомов, пример я приведу на иных изображениях.
Так программа выглядит из терминала:
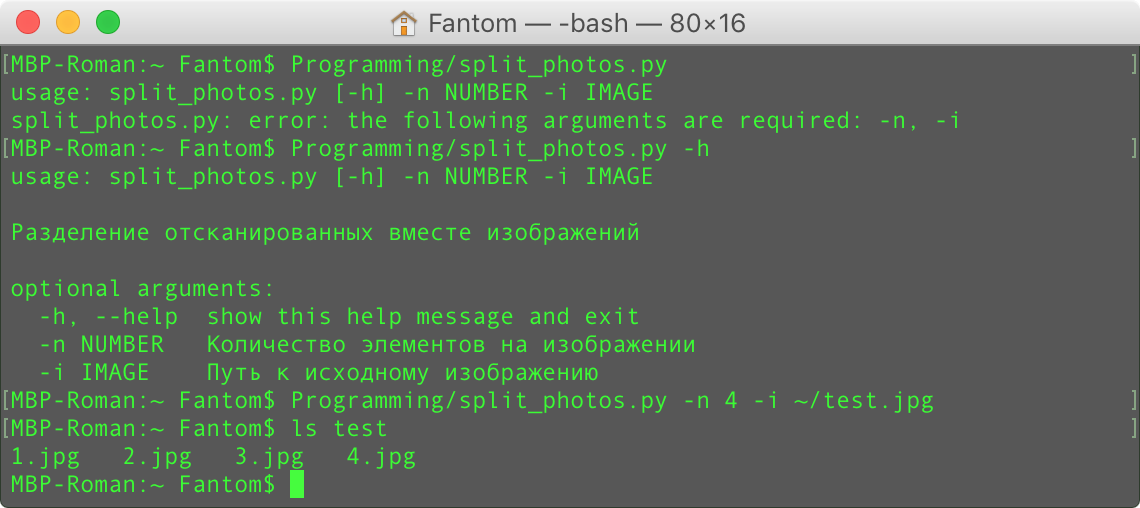
Заинтересовались? Продолжаем.
Установку OpenCV рассматривать не буду, многочисленные инструкции можно найти на просторах Сети. Итак, изначально мы импортируем зависимости:
Функция main() выглядит следующим образом:
Слишком сложно? Давайте по порядку.
Создаем объект типа ArgumentParser с аргументом description, описывающим наше будущее приложение. Добавляем аргумент '-n' целочисленного типа, который будем хранить как 'number', а также прикладываем описание параметра для команды -h/--help. Аналогично со строковым аргументом '-i', оба аргумента обязательны (required=True). В последней строке разбираем аргументы, которые были переданы скрипту при запуске.
Далее:
Из параметра args.image получаем путь к директории с файлом (если он есть), имя файла, расширение и имя без расширения.
Если папка с изображением — не текущая рабочая директория, переходим в нее. На месте создаем папку с именем исходного изображения без расширения куда будем складывать итоговые.
Открываем наше изображение. Находим описывающие прямоугольники для каждого из args.number количества изображений.
Описание функции get_contours() ниже по тексту.
Задаем счетчик. Далее начинается цикл в котором мы перебираем контуры найденных изображений:
Внутри цикла:
Получаем двумерный массив точек минимального описывающего прямоугольника.
Делаем кроп изображения по этим точкам.
Поворачиваем изображение. Описание функции rotate() ниже по тексту.
Сохраняем изображение под соответствующим номером в созданной по имени исходного файла без расширения папке.
Тикает счетчик.
И так пока не пройдемся по всем элементам исходного изображения. В общем-то, все. Теперь рассмотрим функции.
get_contour() выглядит так:
Внутри функции мы немного расширяем изображение для определния изображений «прилипших» к краям, приводим к оттенкам серого, бинаризируем и находим контуры. В случае если вызов этой функции был произведен из функции rotate(), параметр num останется равен 0, тогда мы возвращаем только один (второй, ибо первый, который с индексом 0, описывает все исходное изображение) элемент (контур) отсортированного по площади контура массива. Если же вызов производился из функции main(), параметр num содержит args.number и функция get_contours() вернет args.number контуров.
Функция rotate(). Здесь я позволю себе обойтись комментариями в коде.
Спасибо за прочтение. Если кто-то знает как можно оптимизировать алгоритм и какие где косяки я допустил, добро пожаловать в комментарии. Надеюсь, кому-то эта статья будет полезна.
Учитывая мое знакомство с основами python и интерес к компьютерному зрению, подвернувшаяся практическая задачка пришлась весьма кстати. В самом начале я проводил тестирование на изображении собранном в Pixelmator'е из трех других. Забегая вперед, нужно сказать что тогда я не предусмотрел возможность наклона фотографий на исходном изображении. Каждой в свою сторону. Тогда, отобрав несколько фотографий и сделав пару заходов к МФУ, я получил два изображения, на которых проверял работоспособность кода по мере написания. Ввиду личного содержимого альбомов, пример я приведу на иных изображениях.
Так программа выглядит из терминала:
Исходное изображение
Результаты



Заинтересовались? Продолжаем.
Установку OpenCV рассматривать не буду, многочисленные инструкции можно найти на просторах Сети. Итак, изначально мы импортируем зависимости:
from numpy import int0, zeros_like, deg2rad, sin, cos, dot, array as nparray from math import ceil import cv2 from os import mkdir, chdir from os.path import basename, dirname, isdir, join as path_join from argparse import ArgumentParser
Функция main() выглядит следующим образом:
def main(): parser = ArgumentParser(description='Разделение отсканированных вместе изображений') parser.add_argument('-n', type=int, dest='number', required=True, help='Количество элементов на изображении') parser.add_argument('-i', dest='image', required=True, help='Путь к исходному изображению') args = parser.parse_args() folder = dirname(args.image) image_name = basename(args.image) extension = image_name.split('.')[-1] image_name_without_extension = '.'.join(image_name.split('.')[:-1]) if folder: chdir(folder) if not isdir(image_name_without_extension): mkdir(image_name_without_extension) image = cv2.imread(image_name) contours = get_contours(image, args.number) i = 1 for c in contours: ca = int0(cv2.boxPoints(cv2.minAreaRect(c))) im = image[ca[2][1]:ca[0][1],ca[1][0]:ca[3][0]] im = rotate(ca, im) cv2.imwrite(path_join(image_name_without_extension, '%s.%s'%(i, extension)), im) i += 1 cv2.destroyAllWindows()
Слишком сложно? Давайте по порядку.
parser = ArgumentParser(description='Разделение отсканированных вместе изображений') parser.add_argument('-n', type=int, dest='number', required=True, help='Количество элементов на изображении') parser.add_argument('-i', dest='image', required=True, help='Путь к исходному изображению') args = parser.parse_args()
Создаем объект типа ArgumentParser с аргументом description, описывающим наше будущее приложение. Добавляем аргумент '-n' целочисленного типа, который будем хранить как 'number', а также прикладываем описание параметра для команды -h/--help. Аналогично со строковым аргументом '-i', оба аргумента обязательны (required=True). В последней строке разбираем аргументы, которые были переданы скрипту при запуске.
Далее:
folder = dirname(args.image) image_name = basename(args.image) extension = image_name.split('.')[-1] image_name_without_extension = ''.join(image_name.split('.')[:-1])
Из параметра args.image получаем путь к директории с файлом (если он есть), имя файла, расширение и имя без расширения.
if folder: chdir(folder) if not isdir(image_name_without_extension): mkdir(image_name_without_extension)
Если папка с изображением — не текущая рабочая директория, переходим в нее. На месте создаем папку с именем исходного изображения без расширения куда будем складывать итоговые.
image = cv2.imread(image_name) contours = get_contours(image, args.number)
Открываем наше изображение. Находим описывающие прямоугольники для каждого из args.number количества изображений.
Описание функции get_contours() ниже по тексту.
Задаем счетчик. Далее начинается цикл в котором мы перебираем контуры найденных изображений:
i=1 for c in contours:
Внутри цикла:
Получаем двумерный массив точек минимального описывающего прямоугольника.
ca = int0(cv2.boxPoints(cv2.minAreaRect(c)))
Делаем кроп изображения по этим точкам.
im = image[ca[2][1]:ca[0][1],ca[1][0]:ca[3][0]]
Поворачиваем изображение. Описание функции rotate() ниже по тексту.
im = rotate(ca, im)
Сохраняем изображение под соответствующим номером в созданной по имени исходного файла без расширения папке.
cv2.imwrite(path_join(image_name_without_extension, '%s.%s'%(i, extension)), im)
Тикает счетчик.
i += 1
И так пока не пройдемся по всем элементам исходного изображения. В общем-то, все. Теперь рассмотрим функции.
get_contour() выглядит так:
def get_contours(src, num=0): src = cv2.copyMakeBorder(src, 2, 2, 2, 2, cv2.BORDER_CONSTANT, value=(255, 255, 255)) gray = cv2.cvtColor(src, cv2.COLOR_BGR2GRAY) thresh = cv2.threshold(gray, 230, 255, cv2.THRESH_BINARY)[1] contours = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_TC89_L1)[1] if not num: return sorted(contours, key = cv2.contourArea, reverse = True)[1] else: return sorted(contours, key = cv2.contourArea, reverse = True)[1:num+1]
Внутри функции мы немного расширяем изображение для определния изображений «прилипших» к краям, приводим к оттенкам серого, бинаризируем и находим контуры. В случае если вызов этой функции был произведен из функции rotate(), параметр num останется равен 0, тогда мы возвращаем только один (второй, ибо первый, который с индексом 0, описывает все исходное изображение) элемент (контур) отсортированного по площади контура массива. Если же вызов производился из функции main(), параметр num содержит args.number и функция get_contours() вернет args.number контуров.
Функция rotate(). Здесь я позволю себе обойтись комментариями в коде.
def rotate(contour, src): #вычисляем угол поворота angle = cv2.minAreaRect(contour)[2] if angle > 45: angle -= 90 if angle < -45: angle += 90 #получаем ширину и высоту w, h = src.shape[1], src.shape[0] #переводим градусы в радианы rotangle = deg2rad(angle) #вычисляем новые ширину и высоту изображения nw = abs(sin(rotangle)*h) + abs(cos(rotangle)*w) nh = abs(cos(rotangle)*h) + abs(sin(rotangle)*w) #строим матрицу поворота rotation_matrix = cv2.getRotationMatrix2D((nw*0.5, nh*0.5), angle, 1.0) rotatiom_move = dot(rotation_matrix, nparray([(nw-w)*0.5, (nh-h)*0.5,0])) rotation_matrix[0,2] += rotatiom_move[0] rotation_matrix[1,2] += rotatiom_move[1] #поворачиваем изображение src = cv2.warpAffine(src, rotation_matrix, (int(ceil(nw)), int(ceil(nh))), flags=cv2.INTER_LANCZOS4, borderValue=(255,255,255)) #избавляемся от белой рамки по краям ca = int0(cv2.boxPoints(cv2.minAreaRect(get_contours(src)))) #кропаем и возвращаем из функции повернутое, "чистое" изображение return src[ca[2][1]+14:ca[0][1]-3,ca[1][0]+3:ca[3][0]-3]
Спасибо за прочтение. Если кто-то знает как можно оптимизировать алгоритм и какие где косяки я допустил, добро пожаловать в комментарии. Надеюсь, кому-то эта статья будет полезна.
Код целиком
#!/usr/local/bin/python3 from numpy import int0, zeros_like, deg2rad, sin, cos, dot, array as nparray from math import ceil import cv2 from os import mkdir, chdir from os.path import basename, dirname, isdir, join as path_join from argparse import ArgumentParser def get_contours(src, num=0): #расширяем изображение для определния изображений "прилипших" к краям src = cv2.copyMakeBorder(src, 2, 2, 2, 2, cv2.BORDER_CONSTANT, value=(255, 255, 255)) #приводим к оттенкам серого gray = cv2.cvtColor(src, cv2.COLOR_BGR2GRAY) #бинаризируем thresh = cv2.threshold(gray, 230, 255, cv2.THRESH_BINARY)[1] #находим контуры contours = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_TC89_L1)[1] if not num: #возвращаем один контур при вызове из функции поворота return sorted(contours, key = cv2.contourArea, reverse = True)[1] else: #возвращаем ars.n объектов при вызове из функции main() return sorted(contours, key = cv2.contourArea, reverse = True)[1:num+1] def rotate(contour, src): #вычисляем угол поворота angle = cv2.minAreaRect(contour)[2] if angle > 45: angle -= 90 if angle < -45: angle += 90 #получаем длину и ширину w, h = src.shape[1], src.shape[0] #переводим градусы в радианы rotangle = deg2rad(angle) #вычисляем новые ширину и высоту изображения nw = abs(sin(rotangle)*h) + abs(cos(rotangle)*w) nh = abs(cos(rotangle)*h) + abs(sin(rotangle)*w) #строим матрицу поворота rotation_matrix = cv2.getRotationMatrix2D((nw*0.5, nh*0.5), angle, 1.0) rotatiom_move = dot(rotation_matrix, nparray([(nw-w)*0.5, (nh-h)*0.5,0])) rotation_matrix[0,2] += rotatiom_move[0] rotation_matrix[1,2] += rotatiom_move[1] #поворачиваем изображение src = cv2.warpAffine(src, rotation_matrix, (int(ceil(nw)), int(ceil(nh))), flags=cv2.INTER_LANCZOS4, borderValue=(255, 255, 255)) #избавляемся от белых полос ca = int0(cv2.boxPoints(cv2.minAreaRect(get_contours(src)))) #кропаем и возвращаем повернутое, "чистое" изображение return src[ca[2][1]+14:ca[0][1]-3, ca[1][0]+3:ca[3][0]-3] def main(): parser = ArgumentParser(description='Разделение отсканированных вместе изображений') parser.add_argument('-n', type=int, dest='number', required=True, help='Количество элементов на изображении') parser.add_argument('-i', dest='image', required=True, help='Путь к исходному изображению') args = parser.parse_args() folder = dirname(args.image) image_name = basename(args.image) extension = image_name.split('.')[-1] image_name_without_extension = '.'.join(image_name.split('.')[:-1]) if folder:#если папка с изображением - не cwd chdir(folder)#переходим в нее if not isdir(image_name_without_extension): mkdir(image_name_without_extension)#создаем папку по названию исходного файла без расширения #открываем изображение image = cv2.imread(image_name) #находим описывающие прямоугольники contours = get_contours(image, args.number) i = 1#счетчик for c in contours: #получаем np.масив точек наименьшего описывающего прямоугольника ca = int0(cv2.boxPoints(cv2.minAreaRect(c))) #делаем кроп изображения по этим точкам im = image[ca[2][1]:ca[0][1], ca[1][0]:ca[3][0]] #поворачиваем изображение im = rotate(ca, im) #записываем в папку cv2.imwrite(path_join(image_name_without_extension, '%s.%s'%(i, extension)), im) #счетчик тикает i += 1 if __name__=='__main__': main()
