Данная статья в первую очередь предназначена для подготовки к собеседованиям на позицию Java разработчика (на самом деле, это шпаргалка, которую я писал для себя в течении многих лет, и повторяю при каждом новом поиске работы).
Предполагается. что вы знакомы с многими функциями из Java SE, поэтому в основном информация дается кратко. Конечно, можно использовать эту статью и просто для обучения основам Java SE платформы (но в этом случае, после чтения статьи вам скорее всего придется обратиться к другим источникам).

Итак, вы пытаетесь вспомнить все, что знаете перед собеседованием и не важно сколько лет опыта, без подготовки вас все равно могут поймать на том вопросе, который вы вроде бы помнили, но именно на собеседовании забыли. Это шпаргалка позволит вам освежить некоторые из ваших знаний.
Внимание: я не буду касаться вопросов по самому языку Java (вроде для чего нужно слово final или чем overriding отличается от overloading), это потребует отдельной статьи, это вопросы именно по Java SE (6-9) платформе.
Вопросов по коллекциям всегда много, независимо от вашего уровня. Поэтому давайте кратко вспомним все особенности о коллекциях.
Подробнее в этой моей статье, например раздел про операции с коллекциями или вопросы использования коллекций из guava, apache commons и Eclipse (GS Collections).
Функциональное программирование, лямбды и возможности, добавленные в Java 8, тоже очень часто встречаются на интервью. Подробно я описывал в этой шпаргалке, тут дам лишь краткое описание:
Если, что-то выше не понятно, советую посмотреть отдельную статью
По этой теме тоже бывают достаточно часто вопросы на собеседованиях.
Вот по этой теме вопросы очень редки (точнее не помню ни одного вопроса по этой теме), однако на всякий случай стоит помнить и о них.
А вот про Reference объектах вопросы встречаются и очень часто на них разработчики плавают, так как это довольно редко используемые классы. По сути, это классы для более гибкого управления памятью, чем обычные «сильные» указатели.
Опять редкая тема для собеседований, но помнить стоит.
Для работы с регулярными выражениями существует два основных класса и один интерфейс:
1. Pattern — Скомпилированное регулярное выражение, которое будет использоваться в Matcher
Matcher. Класс для выполнения скомпилированного регулярного выражения (класс Pattern) над CharSequence.
2. MatchResult — Служит для возврата результатов Matcher’а
Тоже не помню вопросов по этой теме, но повторить стандартное логирование в SE все-таки полезно.
Спасибо за внимание. Другие шпаргалки можно найти в моем профиле.
Предполагается. что вы знакомы с многими функциями из Java SE, поэтому в основном информация дается кратко. Конечно, можно использовать эту статью и просто для обучения основам Java SE платформы (но в этом случае, после чтения статьи вам скорее всего придется обратиться к другим источникам).
Итак, вы пытаетесь вспомнить все, что знаете перед собеседованием и не важно сколько лет опыта, без подготовки вас все равно могут поймать на том вопросе, который вы вроде бы помнили, но именно на собеседовании забыли. Это шпаргалка позволит вам освежить некоторые из ваших знаний.
Внимание: я не буду касаться вопросов по самому языку Java (вроде для чего нужно слово final или чем overriding отличается от overloading), это потребует отдельной статьи, это вопросы именно по Java SE (6-9) платформе.
I. Коллекции
Вопросов по коллекциям всегда много, независимо от вашего уровня. Поэтому давайте кратко вспомним все особенности о коллекциях.
Много информации о коллекциях
1) Интерфейсы коллекций JDK
2) Таблица с очень кратким описанием всех коллекций
3) Устаревшие коллекции в JDK
4) Коллекции, реализующие интерфейс List (список)
5) Коллекции, реализующие интерфейс Set (множество)
6) Коллекции, реализующие интерфейс Map (ассоциативный массив)
7) Коллекции, основанные на интерфейсах Queue/Deque (очереди)
8) Прочие коллекции
9) Методы работы с коллекциями
10) Как устроенны разные типы коллекций JDK внутри
11) Другие полезные сущности стандартной библиотеки коллекций
Замечание о коллекциях для начинающих
Иногда достаточно сложно для начинающих (особенно если они перешли из других языков программирования) понять, что в коллекции Java хранятся только ссылки/указатели и ничего более. Им кажется, что при вызове add или put объекты действительно хранятся где-то внутри коллекции, это верно только для массивов, когда они работают с примитивными типами, но никак не для коллекций, которые хранят только ссылки. Поэтому очень часто на вопросы собеседований вроде «А можно ли назвать точный размер коллекции ArrayList» начинающие начинают отвечать что-то вроде «Зависит от типа объектов что в них хранятся». Это совершенно не верно, так коллекции никогда не хранят сами объекты, а только ссылки на них. Например, можно в List добавить миллион раз один и то же объект (точнее создать миллион ссылок на один объект).
1) Интерфейсы коллекций JDK
Интерфейсы коллекций JDK
Интерфейсы коллекций
Интерфейсы из пакета java.util.concurrent
Если вам интересны более подробная информация о интерфейсах и коллекциях из java.util.concurrent советую
прочитать вот эту статью.
| Название | Описание |
|---|---|
| Iterable | Интерфейс означающий что у коллекции есть iterator и её можно обойти с помощью for(Type value:collection). Есть почти у всех коллекций (кроме Map) |
| Collection | Основной интерфейс для большинства коллекций (кроме Map) |
| List | Список это упорядоченная в порядке добавления коллекция, так же известная как последовательность (sequence). Дублирующие элементы в большинстве реализаций — разрешены. Позволяет доступ по индексу элемента. Расширяет Collection интерфейс. |
| Set | Интерфейс реализующий работу с множествами (похожими на математические множества), дублирующие элементы запрещены. Может быть, а может и не быть упорядоченным. Расширяет Collection интерфейс. |
| Queue | Очередь — это коллекция, предназначенная для хранения объектов до обработки, в отличии от обычных операций над коллекциями, очередь предоставляет дополнительные методы добавление, получения и просмотра. Быстрый доступ по индексу элемента, как правило, не содержит. Расширяет Collection интерфейс |
| Deque | Двухсторонняя очередь, поддерживает добавление и удаление элементов с обоих концов. Расширяет Queue интерфейс. |
| Map | Работает со соответствием ключ — значение. Каждый ключ соответствует только одному значению. В отличие от других коллекций не расширяет никакие интерфейсы (в том числе Collection и Iterable) |
| SortedSet | Автоматически отсортированное множество, либо в натуральном порядке (для подробностей смотрите Comparable интерфейс), либо используя Comparator. Расширяет Set интерфейс |
| SortedMap | Это map'а ключи которой автоматически отсортированы, либо в натуральном порядке, либо с помощью comparator'а. Расширяет Map интерфейс. |
| NavigableSet |
Это SortedSet, к которому дополнительно добавили методы для поиска ближайшего значения к заданному значению поиска. NavigableSet может быть доступен для доступа и обхода или в порядке убывания значений или в порядке возрастания. |
| NavigableMap |
Это SortedMap, к которому дополнительно добавили методы для поиска ближайшего значения к заданному значению поиска. Доступен для доступа и обхода или в порядке убывания значений или в порядке возрастания. |
Интерфейсы из пакета java.util.concurrent
| Название | Описание |
|---|---|
| BlockingQueue |
Многопоточная реализация Queue, содержащая возможность задавать размер очереди, блокировки по условиях, различные методы, по-разному обрабатывающие переполнение при добавлении или отсутствие данных при получении (бросают exception, блокируют поток постоянно или на время, возвращают false и т.п.) |
| TransferQueue |
Эта многопоточная очередь может блокировать вставляющий поток, до тех пор, пока принимающий поток не вытащит элемент из очереди, таким образом с её помощью можно реализовывать синхронные и асинхронные передачи сообщений между потоками |
| BlockingDeque |
Аналогично BlockingQueue, но для двухсторонней очереди |
| ConcurrentMap |
Интерфейс, расширяет интерфейс Map. Добавляет ряд новых атомарных методов: putIfAbsent, remove, replace, которые позволяют облегчить и сделать более безопасным многопоточное программирование. |
| ConcurrentNavigableMap |
Расширяет интерфейс NavigableMap для многопоточного варианта |
Если вам интересны более подробная информация о интерфейсах и коллекциях из java.util.concurrent советую
прочитать вот эту статью.
2) Таблица с очень кратким описанием всех коллекций
Таблица с очень кратким описанием всех коллекций
* — на самом деле, BitSet хоть и называется Set'ом, интерфейс Set не наследует.
| Тип | Однопоточные | Многопоточные |
|---|---|---|
| Lists |
|
|
| Queues / Deques |
|
|
| Maps |
|
|
| Sets |
|
|
* — на самом деле, BitSet хоть и называется Set'ом, интерфейс Set не наследует.
3) Устаревшие коллекции в JDK
Устаревшие коллекции Java
Универсальные коллекции общего назначения, которые признаны устаревшими (legacy)
Специализированные коллекции, построенные на устаревших (legacy) коллекциях
| Имя | Описание |
|---|---|
| Hashtable |
Изначально задумывался как синхронизированный аналог HashMap, когда ещё не было возможности получить версию коллекции используя Collecions.synchronizedMap. На данный момент как правило используют ConcurrentHashMap. HashTable более медленный и менее потокобезопасный чем синхронный HashMap, так как обеспечивает синхронность на уровне отдельных операций, а не целиком на уровне коллекции. |
| Vector | Раньше использовался как синхронный вариант ArrayList, однако устарел по тем же причинам что и HashTable. |
| Stack | Раньше использовался как для построения очереди, однако поскольку построен на основе Vector, тоже считается морально устаревшим. |
Специализированные коллекции, построенные на устаревших (legacy) коллекциях
| Имя | Основан на | Описание |
|---|---|---|
| Properties |
Hashtable | Как структура данных, построенная на Hashtable, Properties довольно устаревшая конструкция, намного лучше использовать Map, содержащий строки. Подробнее почему Properties не рекомендуется использовать можно найти в этом обсуждении. |
| UIDefaults |
Hashtable | Коллекция, хранящая настройки по умолчанию для Swing компонент |
4) Коллекции, реализующие интерфейс List (список)
Коллекции, реализующие интерфейс List (список)
Универсальные коллекции общего назначения, реализующие List:
Коллекции из пакета java.util.concurrent
Узкоспециализированные коллекции на основе List.
* — размер дан в байтах для 32 битных систем и Compressed Oops, где N это capacity списка
| Название | Основан на |
Описание | Размер* |
|---|---|---|---|
| ArrayList |
List | Реализация List интерфейса на основе динамически изменяемого массива. В большинстве случаев, лучшая возможная реализация List интерфейса по потреблению памяти и производительности. В крайне редких случаях, когда требуются частые вставки в начало или середину списка с очень малым количеством перемещений по списку, LinkedList будет выигрывать в производительности (но советую в этих случаях использовать TreeList от apache). Если интересны подробности ArrayList советую посмотреть эту статью. |
4*N |
| LinkedList |
List | Реализация List интерфейса на основе двухстороннего связанного списка, то есть когда каждый элемент, указывает на предыдущий и следующий элемент. Как правило, требует больше памяти и хуже по производительности, чем ArrayList, имеет смысл использовать лишь в редких случаях когда часто требуется вставка/удаление в середину списка с минимальными перемещениями по списку (но советую в этих случаях использовать TreeList от apache).Так же реализует Deque интерфейс. При работе через Queue интерфейс, LinkedList действует как FIFO очередь. Если интересны подробности LinkedList советую посмотреть эту статью. |
24*N |
Коллекции из пакета java.util.concurrent
| Название | Основан на |
Описание |
|---|---|---|
| CopyOnWriteArrayList |
List | Реализация List интерфейса, аналогичная ArrayList, но при каждом изменении списка, создается новая копия всей коллекции. Это требует очень больших ресурсов при каждом изменении коллекции, однако для данного вида коллекции не требуется синхронизации, даже при изменении коллекции во время итерирования. |
Узкоспециализированные коллекции на основе List.
| Название | Основан на | Описание |
|---|---|---|
| RoleList |
ArrayList | Коллекция для хранения списка ролей (Roles). Узкоспециализированная коллекция основанная на ArrayList с несколькими дополнительными методами |
| RoleUnresolvedList |
ArrayList | Коллекция для хранения списка unresolved ролей (Unresolved Roles). Узкоспециализированная коллекция основанная на ArrayList с несколькими дополнительными методами |
| AttributeList |
ArrayList | Коллекция для хранения атрибутов MBean. Узкоспециализированная коллекция основанная на ArrayList с несколькими дополнительными методами |
* — размер дан в байтах для 32 битных систем и Compressed Oops, где N это capacity списка
5) Коллекции, реализующие интерфейс Set (множество)
Коллекции, реализующие интерфейс Set (множество)
* — размер дан в байтах для 32 битных систем и Compressed Oops, где С это capacity списка, S это size списка
Узкоспециализированные коллекции на основе Set
Коллекции из пакета java.util.concurrent
| Название | Основан на |
Описание | Размер* |
|---|---|---|---|
| HashSet | Set | Реализация Set интерфейса с использованием хеш-таблиц. В большинстве случаев, лучшая возможная реализация Set интерфейса. |
32*S + 4*C |
| LinkedHashSet |
HashSet | Реализация Set интерфейса на основе хеш-таблиц и связанного списка. Упорядоченное по добавлению множество, которое работает почти так же быстро как HashSet. В целом, практически тоже самое что HashSet, только порядок итерирования по множеству определен порядком добавления элемента во множество в первый раз. |
40 * S + 4*C |
| TreeSet | NavigableSet |
Реализация NavigableSet интерфейса, используя красно-черное дерево. Отсортировано с помощью Comparator или натурального порядка, то есть обход/итерирование по множеству будет происходить в зависимости от правила сортировки. Основано на TreeMap, так же как HashSet основан на HashMap |
40 * S |
| EnumSet | Set | Высокопроизводительная реализация Set интерфейса, основанная на битовом векторе. Все элементы EnumSet объекта должны принадлежать к одному единственному enum типу |
S/8 |
* — размер дан в байтах для 32 битных систем и Compressed Oops, где С это capacity списка, S это size списка
Узкоспециализированные коллекции на основе Set
| Название | Основан на |
Описание |
|---|---|---|
| JobStateReasons |
HashSet | Коллекция для хранения информации о заданиях печати (print job's attribute set). Узкоспециализированная коллекция основанная на HashSet с несколькими дополнительными методами |
Коллекции из пакета java.util.concurrent
| Название | Основан на |
Описание |
|---|---|---|
| CopyOnWriteArraySet |
Set | Аналогично CopyOnWriteArrayList при каждом изменении создает копию всего множества, поэтому рекомендуется при очень редких изменениях коллекции и требованиях к thread-safe |
| ConcurrentSkipListSet |
Set | Является многопоточным аналогом TreeSet |
6) Коллекции, реализующие интерфейс Map (ассоциативный массив)
Коллекции, реализующие Map интерфейс
Универсальные коллекции общего назначения, реализующие Map:
* — размер дан в байтах для 32 битных систем и Compressed Oops, где С это capacity списка, S это size списка
Коллекции из пакета java.util.concurrent
| Название | Основан на |
Описание | Размер* |
|---|---|---|---|
| HashMap | Map | Реализация Map интерфейса с помощью хеш-таблиц (работает как не синхронная Hashtable, с поддержкой ключей и значений равных null). В большинстве случаев лучшая по производительности и памяти реализация Map интерфейса. Если интересны подробности устройства HashMap советую посмотреть эту статью. |
32 * S + 4*C |
| LinkedHashMap |
HashMap | Реализация Map интерфейса, на основе хеш-таблицы и связного списка, то есть ключи в Map'е хранятся и обходятся во порядке добавления. Данная коллекция работает почти так же быстро как HashMap. Так же она может быть полезна для создания кешей (смотрите removeEldestEntry(Map.Entry) ). Если интересны подробности устройства LinkedHashMap советую посмотреть эту статью. |
40 * S + 4*C |
| TreeMap | NavigableMap |
Реализация NavigableMap с помощью красно-черного дерева, то есть при обходе коллекции, ключи будут отсортированы по порядку, так же NavigableMap позволяет искать ближайшее значение к ключу. |
40 * S |
| WeakHashMap |
Map | Аналогична HashMap, однако все ключи являются слабыми ссылками (weak references), то есть garbage collected может удалить объекты ключи и объекты значения, если других ссылок на эти объекты не существует. WeakHashMap один из самых простых способов для использования всех преимуществ слабых ссылок. |
32 * S + 4*C |
| EnumMap | Map | Высокопроизводительная реализация Map интерфейса, основанная на простом массиве. Все ключи в этой коллекции могут принадлежать только одному enum типу. |
4*C |
| IdentityHashMap |
Map | Identity-based Map, так же как HashMap, основан на хеш-таблице, однако в отличии от HashMap он никогда не сравнивает объекты на equals, только на то является ли они реально одиним и тем же объектом в памяти. Это во-первых, сильно ускоряет работу коллекции, во-вторых, полезно для защиты от «spoof attacks», когда сознательно генерируется объекты equals другому объекту. В-третьих, у данной коллекции много применений при обходе графов (таких как глубокое копирование или сериализация), когда нужно избежать обработки одного объекта несколько раз. |
8*C |
* — размер дан в байтах для 32 битных систем и Compressed Oops, где С это capacity списка, S это size списка
Коллекции из пакета java.util.concurrent
| Название | Основан на |
Описание |
|---|---|---|
| ConcurrentHashMap |
ConcurrentMap |
Многопоточный аналог HashMap. Все данные делятся на отдельные сегменты и блокируются только отдельные сегменты при изменении, что позволяет значительно ускорить работу в многопоточном режиме. Итераторы никогда не кидают ConcurrentModificationException для данного вида коллекции |
| ConcurrentSkipListMap |
ConcurrentNavigableMap |
Является многопоточным аналогом TreeMap |
7) Коллекции, основанные на интерфейсах Queue/Deque (очереди)
Коллекции, основанные на Queue/Deque
* — размер дан в байтах для 32 битных систем и Compressed Oops, где С это capacity списка, S это size списка
Многопоточные Queue и Deque, который определены в java.util.concurrent, требуют отдельной статьи, поэтому здесь приводить их не буду, если вам интересна информация о них советую прочитать вот эту статью
| Название | Основан на |
Описание | Размер* |
|---|---|---|---|
| ArrayDeque |
Deque | Эффективная реализация Deque интерфейса, на основе динамического массива, аналогичная ArrayList |
6*N |
| LinkedList |
Deque | Реализация List и Deque интерфейса на основе двухстороннего связанного списка, то есть когда каждый элемент, указывает на предыдущий и следующий элемент.При работе через Queue интерфейс, LinkedList действует как FIFO очередь. |
40*N |
| PriorityQueue |
Queue | Неограниченная priority queue, основанная на куче (нeap). Элементы отсортированы в натуральном порядке или используя Comparator. Не может содержать null элементы. |
* — размер дан в байтах для 32 битных систем и Compressed Oops, где С это capacity списка, S это size списка
Многопоточные Queue и Deque, который определены в java.util.concurrent, требуют отдельной статьи, поэтому здесь приводить их не буду, если вам интересна информация о них советую прочитать вот эту статью
8) Прочие коллекции
Прочие коллекции
| Название | Описание | Размер* |
|---|---|---|
| BitSet |
Несмотря на название, BitSet не реализует интерфейс Set. BitSet служит для компактной записи массива битов. |
N / 8 |
9) Методы работы с коллекциями
Методы работы с коллекциями
Алгоритмы- В классе Collections содержится много полезных статистических методов.
Для работы с любой коллекцией:
Для работы со списками:
В Java 8 так же появился такой способ работы с коллекциями как stream Api, но мы рассмотрим примеры его использование далее в разделе 5.
Для работы с любой коллекцией:
| Метод | Описание |
|---|---|
| frequency(Collection, Object) |
Возвращает количество вхождений данного элемента в указанной коллекции |
| disjoint(Collection, Collection) | Возвращает true, если в двух коллекциях нет общих элементов |
| addAll(Collection<? super T>, T...) | Добавляет все элементы из указанного массива (или перечисленные в параметрах) в указанную коллекцию |
| min(Collection) | Возвращение минимального элемента из коллекции |
| max(Collection) | Возвращение максимального элемента из коллекции |
Для работы со списками:
| Метод | Описание |
|---|---|
| sort(List) | Сортировка с использованием алгоритма сортировки соединением (merge sort algorithm), производительность которой в большинстве случаев близка к производительности быстрой сортировки (high quality quicksort), гарантируется O(n*log n) производительность (в отличии от quicksort), и стабильность (в отличии от quicksort). Стабильная сортировка это такая которая не меняет порядок одинаковых элементов при сортировке |
| binarySearch(List, Object) | Поиск элемента в списке (list), используя binary search алгоритм. |
| reverse(List) | Изменение порядка всех элементов списка (list) |
| shuffle(List) | Перемешивание всех элементов в списке в случайном порядке |
| fill(List, Object) | Переписывание каждого элемента в списке каким-либо значением |
| copy(List dest, List src) | Копирование одного списка в другой |
| rotate(List list, int distance) | Передвигает все элементы в списке на указанное расстояние |
| replaceAll(List list, Object oldVal, Object newVal) | Заменяет все вхождения одного значения на другое |
| indexOfSubList(List source, List target) | Возвращает индекс первого вхождения списка target в список source |
| lastIndexOfSubList(List source, List target) | Возвращает индекс последнего вхождения списка target в список source |
| swap(List, int, int) | Меняет местами элементы, находящиеся на указанных позициях |
В Java 8 так же появился такой способ работы с коллекциями как stream Api, но мы рассмотрим примеры его использование далее в разделе 5.
10) Как устроенны разные типы коллекций JDK внутри
Как устроенны разные типы коллекций JDK внутри
| Коллекция | Описание внутреннего устройства |
|---|---|
| ArrayList | Данная коллекция лишь настройка над массивом + переменная хранящая size списка. Внутри просто массив, который пересоздается каждый раз когда нет места для добавления нового элемента. В случае, добавления или удаления элемента внутри коллекции весь хвост сдвигается в памяти на новое место. К счастью, копирование массива при увеличении емкости или при добавлении/удалении элементов производится быстрыми нативными/системными методами. Если интересны подробности советую посмотреть эту статью. |
| LinkedList | Внутри коллекции используется внутренний класс Node, содержащий ссылку на предыдущий элемент, следующий элемент и само значение элемента. В самом инстансе коллекции хранится размер и ссылки на первый и последний элемент коллекции. Учитывая что создание объекта дорогое удовольствие для производительности и затратно по памяти, LinkedList чаще всего работает медленно и занимает намного больше памяти чем аналоги. Обычно ArrayList, ArrayDequery лучшее решение по производительности и памяти, но в некоторых редких случаях (частые вставки в середину списка с редкими перемещениями по списку), он может быть быть полезен (но в этом случае полезнее использовать TreeList от apache). Если интересны подробности советую посмотреть эту статью. |
| HashMap | Данная коллекция построена на хеш-таблице, то есть внутри коллекции находится массив внутреннего класса (buket) Node равный capacity коллекции. При добавлении нового элемента вычисляться его хеш-функция, делиться на capacity HashMap по модулю и таким образом вычисляется место элемента в массиве. Если на данном месте ещё не храниться элементов создается новый объект Node с ссылкой на добавляемый элемент и записывается в нужное место массива. Если на данном месте уже есть элемент/ы (происходит хеш-коллизия), то так Node является по сути односвязным списком, то есть содержит ссылку на следующий элемент, то можно обойти все элементы в списке и проверить их на equals добавляемому элементу, если этот такого совпадение не найдено, то создается новый объект Node и добавляется в конец списка. В случае, если количество элементов в связном списке (buket) становится более 8 элементов, вместо него создается бинарное дерево. Подробнее о хеш таблицах смотрите вики (в HashMap используется метод цепочек для разрешения коллизий). Если интересны подробности устройства HashMap советую посмотреть эту статью. |
| HashSet | HashSet это просто HashMap, в которую записывается фейковый объект Object вместо значения, при этом имеет значение только ключи. Внутри HashSet всегда хранится коллекция HashMap. |
| IdentityHashMap | IdentityHashMap это аналог HashMap, но при этом не требуется элементы проверять на equals, так как разными считаются любые два элементы. указывающие на разные объекты. Благодаря этому удалось избавится от внутреннего класса Node, храня все данные в одном массиве, при этом при коллизиях ищется подходящая свободная ячейка до тех пор пока не будет найдена (метод открытой адресации).Подробнее о хеш таблицах смотрите вики (в IdentityHashMap используется метод открытой адресации для разрешения коллизий) |
| LinkedHashMap/LinkedHashSet | Внутренняя структура практически такая же как при HashMap, за исключением того что вместо внутреннего класса Node, используется TreeNode, которая знает предыдущее и следующее значение, это позволяет обходить LinkedHashMap по порядку добавления ключей. По сути, LinkedHashMap = HashMap + LinkedList. Если интересны подробности устройства LinkedHashMap советую посмотреть эту статью. |
| TreeMap/TreeSet | Внутренняя структура данных коллекций построена на сбалансированным красно-черным деревом, подробнее о нем можно почитать в вики |
| WeakHashMap | Внутри все организовано практически как в HashMap, за исключением что вместо обычных ссылок используются WeakReference и есть отдельная очередь ReferenceQueue, необходимая для удаления WeakEntries |
| EnumSet/EnumMap | В EnumSet и EnumMap в отличие от HashSet и HashMap используются битовые векторы и массивы для компактного хранения данных и ускорения производительности. Ограничением этих коллекций является то что EnumSet и EnumMap могут хранить в качестве ключей только значения одного Enum'а. |
11) Другие полезные сущности стандартной библиотеки коллекций
Другие полезные сущности стандартной библиотеки коллекций
Давайте посмотрим какие ещё полезные сущности содержит официальный гайд по коллекциями
1) Wrapper implementations – Обертки для добавления функциональности и изменения поведения других реализаций. Доступ исключительно через статистические методы.
2) Adapter implementations – данная реализация адаптирует один интерфейс коллекций к другому
3) Convenience implementations – Высокопроизводительные «мини-реализации» для интерфейсов коллекций.
4) Абстрактные реализации интерфейсов — Реализация общих функций (скелета коллекций) для упрощения создания конкретных реализаций коллекций.
4) Инфраструктура
5) Ordering
6) Runtime exceptions
7) Производительность
8) Утилиты для работы с массивами
1) Wrapper implementations – Обертки для добавления функциональности и изменения поведения других реализаций. Доступ исключительно через статистические методы.
- Collections.unmodifiableInterface– Обертка для создания не модифицируемой коллекции на основе указанной, при любой попытки изменения данной коллекции будет выкинут UnsupportedOperationException
- Collections.synchronizedInterface– Создания синхронизированной коллекции на основе указанной, до тех пор пока доступ к базовой коллекции идет через коллекцию-обертку, возвращенную данной функцией, потокобезопасность гарантируется.
- Collections.checkedInterface – Возвращает коллекцию с проверкой правильности типа динамически
(во время выполнения), то есть возвращает type-safe view для данной коллекции, который
выбрасывает ClassCastException при попытке добавить элемент ошибочного типа. При использовании
механизма generic'ов JDK проверяет на уровне компиляции соответствие типов, однако этот механизм
можно обойти, динамическая проверка типов не позволяет воспользоваться этой возможностью.
2) Adapter implementations – данная реализация адаптирует один интерфейс коллекций к другому
- newSetFromMap(Map) – Создает из любой реализации Set интерфейса реализацию Map интерфейса.
- asLifoQueue(Deque) - возвращает view из Deque в виде очереди работающей по принципу Last In First Out (LIFO).
3) Convenience implementations – Высокопроизводительные «мини-реализации» для интерфейсов коллекций.
- Arrays.asList – Позволяет отобразить массив как список (list)
- emptySet, emptyList и emptyMap – возвращает пустую не модифицированную реализацию empty set, list, or
map
- singleton, singletonList и singletonMap – возвращает не модифицируемый set, list или map, содержащий один заданный объект (или одно связь ключ-значение)
- nCopies – Возвращает не модифицируемый список, содержащий n копий указанного объекта
4) Абстрактные реализации интерфейсов — Реализация общих функций (скелета коллекций) для упрощения создания конкретных реализаций коллекций.
- AbstractCollection – Абстрактная реализация интерфейса Collection для коллекций, которые не являются ни множеством, ни списком (таких как «bag» или multiset).
- AbstractSet — Абстрактная реализация Set интерфейса.
- AbstractList – Абстрактная реализация List интерфейса для списков, позволяющих позиционный доступ (random access), таких как массив.
- AbstractSequentialList – Абстрактная реализация List интерфейса, для списков, основанных на последовательном доступе (sequential access), таких как linked list.
- AbstractQueue — Абстрактная Queue реализация.
- AbstractMap — Абстрактная Map реализация.
4) Инфраструктура
- Iterators – Похожий на обычный Enumeration интерфейс, но с большими возможностями.
- Iterator – Дополнительно к функциональности Enumeration интерфейса, который включает возможности по удалению элементов из коллекции.
- ListIterator – это Iterator который используется для lists, который добавляет к функциональности обычного Iterator интерфейса, такие как итерация в обе стороны, замена элементов, вставка элементов, получение по индексу.
5) Ordering
- Comparable — Определяет натуральный порядок сортировки для классов, которые реализуют их. Этот порядок может быть использован в методах сортировки или для реализации sorted set или map.
- Comparator — Represents an order relation, which can be used to sort a list or maintin order in a sorted set or map. Can override a type's natural ordering or order objects of a type that does not implement the Comparable interface.
6) Runtime exceptions
- UnsupportedOperationException – Это ошибка выкидывается когда коллекция не поддерживает операцию, которая была вызвана.
- ConcurrentModificationException – Выкидывается iterators или list iterators, если коллекция на которой он основан была неожиданно (для алгоритма) изменена во время итерирования, также выкидывается во views основанных на списках, если главный список был неожиданно изменен.
7) Производительность
- RandomAccess — Интерфейс-маркер, который отмечает списки позволяющие быстрый (как правило за константное время) доступ к элементу по позиции. Это позволяет генерировать алгоритмы учитывающие это поведение для выбора последовательного и позиционного доступа.
8) Утилиты для работы с массивами
- Arrays – Набор статических методов для сортировки, поиска, сравнения, изменения размера, получения хеша для массива. Так же содержит методы для преобразования массива в строка и заполнения массива примитивами или объектами.
Подробнее в этой моей статье, например раздел про операции с коллекциями или вопросы использования коллекций из guava, apache commons и Eclipse (GS Collections).
II. Stream Api
Функциональное программирование, лямбды и возможности, добавленные в Java 8, тоже очень часто встречаются на интервью. Подробно я описывал в этой шпаргалке, тут дам лишь краткое описание:
Stream Api
Java Stream API предлагает два вида методов:
1. Конвейерные — возвращают другой stream, то есть работают как builder,
2. Терминальные — возвращают другой объект, такой как коллекция, примитивы, объекты, Optional и т.д.
Для тех кто совсем не знает что такое Stream Api
Stream API это новый способ работать со структурами данных в функциональном стиле. Чаще всего с помощью stream в Java 8 работают с коллекциями, но на самом деле этот механизм может использоваться для самых различных данных.
Stream Api позволяет писать обработку структур данных в стиле SQL, то если раньше задача получить сумму всех нечетных чисел из коллекции решалась следующим кодом:
То с помощью Stream Api можно решить такую задачу в функциональном стиле:
Более того, Stream Api позволяет решать задачу параллельно лишь изменив stream() на parallelStream() без всякого лишнего кода, т.е.
Уже делает код параллельным, без всяких семафоров, синхронизаций, рисков взаимных блокировок и т.п.
Stream Api позволяет писать обработку структур данных в стиле SQL, то если раньше задача получить сумму всех нечетных чисел из коллекции решалась следующим кодом:
Integer sumOddOld = 0; for(Integer i: collection) { if(i % 2 != 0) { sumOddOld += i; } }
То с помощью Stream Api можно решить такую задачу в функциональном стиле:
Integer sumOdd = collection.stream().filter(o -> o % 2 != 0).reduce((s1, s2) -> s1 + s2).orElse(0);
Более того, Stream Api позволяет решать задачу параллельно лишь изменив stream() на parallelStream() без всякого лишнего кода, т.е.
Integer sumOdd = collection.parallelStream().filter(o -> o % 2 != 0).reduce((s1, s2) -> s1 + s2).orElse(0);
Уже делает код параллельным, без всяких семафоров, синхронизаций, рисков взаимных блокировок и т.п.
I. Способы создания стримов
Способы создания стримов
Перечислим несколько способов создать стрим
| Способ создания стрима | Шаблон создания | Пример |
|---|---|---|
| 1. Классический: Создание стрима из коллекции | collection.stream() |
|
| 2. Создание стрима из значений | Stream.of(значение1,… значениеN) |
|
| 3. Создание стрима из массива | Arrays.stream(массив) |
|
| 4. Создание стрима из файла (каждая строка в файле будет отдельным элементом в стриме) | Files.lines(путь_к_файлу) |
|
| 5. Создание стрима из строки | «строка».chars() |
|
| 6. С помощью Stream.builder | Stream.builder().add(...)....build() |
|
| 7. Создание параллельного стрима | collection.parallelStream() |
|
| 8. Создание бесконечных стрима с помощью Stream.iterate |
Stream.iterate(начальное_условие, выражение_генерации) |
|
| 9. Создание бесконечных стрима с помощью Stream.generate | Stream.generate(выражение_генерации) |
|
II. Методы работы со стримами
Java Stream API предлагает два вида методов:
1. Конвейерные — возвращают другой stream, то есть работают как builder,
2. Терминальные — возвращают другой объект, такой как коллекция, примитивы, объекты, Optional и т.д.
О том чем отличаются конвейерные и терминальные методы
Общее правило: у stream'a может быть сколько угодно вызовов конвейерных вызовов и в конце один терминальный, при этом все конвейерные методы выполняются лениво и пока не будет вызван терминальный метод никаких действий на самом деле не происходит, так же как создать объект Thread или Runnable, но не вызвать у него start.
В целом, этот механизм похож на конструирования SQL запросов, может быть сколько угодно вложенных Select'ов и только один результат в итоге. Например, в выражении collection.stream().filter((s) -> s.contains(«1»)).skip(2).findFirst(), filter и skip — конвейерные, а findFirst — терминальный, он возвращает объект Optional и это заканчивает работу со stream'ом.
В целом, этот механизм похож на конструирования SQL запросов, может быть сколько угодно вложенных Select'ов и только один результат в итоге. Например, в выражении collection.stream().filter((s) -> s.contains(«1»)).skip(2).findFirst(), filter и skip — конвейерные, а findFirst — терминальный, он возвращает объект Optional и это заканчивает работу со stream'ом.
2.1 Краткое описание конвейерных методов работы со стримами
Подробнее...
| Метод stream | Описание | Пример |
|---|---|---|
| filter | Отфильтровывает записи, возвращает только записи, соответствующие условию | collection.stream().filter(«a1»::equals).count() |
| skip | Позволяет пропустить N первых элементов | collection.stream().skip(collection.size() — 1).findFirst().orElse(«1») |
| distinct | Возвращает стрим без дубликатов (для метода equals) | collection.stream().distinct().collect(Collectors.toList()) |
| map | Преобразует каждый элемент стрима | collection.stream().map((s) -> s + "_1").collect(Collectors.toList()) |
| peek | Возвращает тот же стрим, но применяет функцию к каждому элементу стрима | collection.stream().map(String::toUpperCase).peek((e) -> System.out.print("," + e)). collect(Collectors.toList()) |
| limit | Позволяет ограничить выборку определенным количеством первых элементов | collection.stream().limit(2).collect(Collectors.toList()) |
| sorted | Позволяет сортировать значения либо в натуральном порядке, либо задавая Comparator | collection.stream().sorted().collect(Collectors.toList()) |
| mapToInt, mapToDouble, mapToLong |
Аналог map, но возвращает числовой стрим (то есть стрим из числовых примитивов) | collection.stream().mapToInt((s) -> Integer.parseInt(s)).toArray() |
| flatMap, flatMapToInt, flatMapToDouble, flatMapToLong |
Похоже на map, но может создавать из одного элемента несколько | collection.stream().flatMap((p) -> Arrays.asList(p.split(",")).stream()).toArray(String[]::new) |
2.2 Краткое описание терминальных методов работы со стримами
Подробнее...
Обратите внимание методы findFirst, findAny, anyMatch это short-circuiting методы, то есть обход стримов организуется таким образом чтобы найти подходящий элемент максимально быстро, а не обходить весь изначальный стрим.
| Метод stream | Описание | Пример |
|---|---|---|
| findFirst | Возвращает первый элемент из стрима (возвращает Optional) | collection.stream().findFirst().orElse(«1») |
| findAny | Возвращает любой подходящий элемент из стрима (возвращает Optional) | collection.stream().findAny().orElse(«1») |
| collect | Представление результатов в виде коллекций и других структур данных | collection.stream().filter((s) -> s.contains(«1»)).collect(Collectors.toList()) |
| count | Возвращает количество элементов в стриме | collection.stream().filter(«a1»::equals).count() |
| anyMatch | Возвращает true, если условие выполняется хотя бы для одного элемента | collection.stream().anyMatch(«a1»::equals) |
| noneMatch | Возвращает true, если условие не выполняется ни для одного элемента | collection.stream().noneMatch(«a8»::equals) |
| allMatch | Возвращает true, если условие выполняется для всех элементов | collection.stream().allMatch((s) -> s.contains(«1»)) |
| min | Возвращает минимальный элемент, в качестве условия использует компаратор | collection.stream().min(String::compareTo).get() |
| max | Возвращает максимальный элемент, в качестве условия использует компаратор | collection.stream().max(String::compareTo).get() |
| forEach | Применяет функцию к каждому объекту стрима, порядок при параллельном выполнении не гарантируется | set.stream().forEach((p) -> p.append("_1")); |
| forEachOrdered | Применяет функцию к каждому объекту стрима, сохранение порядка элементов гарантирует | list.stream().forEachOrdered((p) -> p.append("_new")); |
| toArray | Возвращает массив значений стрима | collection.stream().map(String::toUpperCase).toArray(String[]::new); |
| reduce | Позволяет выполнять агрегатные функции на всей коллекцией и возвращать один результат | collection.stream().reduce((s1, s2) -> s1 + s2).orElse(0) |
Обратите внимание методы findFirst, findAny, anyMatch это short-circuiting методы, то есть обход стримов организуется таким образом чтобы найти подходящий элемент максимально быстро, а не обходить весь изначальный стрим.
2.3 Краткое описание дополнительных методов у числовых стримов
Подробнее...
| Метод stream | Описание | Пример |
|---|---|---|
| sum | Возвращает сумму всех чисел | collection.stream().mapToInt((s) -> Integer.parseInt(s)).sum() |
| average | Возвращает среднее арифметическое всех чисел | collection.stream().mapToInt((s) -> Integer.parseInt(s)).average() |
| mapToObj | Преобразует числовой стрим обратно в объектный | intStream.mapToObj((id) -> new Key(id)).toArray() |
2.4 Несколько других полезных методов стримов
Подробнее...
| Метод stream | Описание |
|---|---|
| isParallel | Узнать является ли стрим параллельным |
| parallel | Вернуть параллельный стрим, если стрим уже параллельный, то может вернуть самого себя |
| sequential | Вернуть последовательный стрим, если стрим уже последовательный, то может вернуть самого себя |
Если, что-то выше не понятно, советую посмотреть отдельную статью
III. Serialization
По этой теме тоже бывают достаточно часто вопросы на собеседованиях.
Читать...
Основные классы:
1. ObjectOutput — интерфейс стрима для “ручной” сериализации объектов. Основные методы writeObject(объект) — запись объекта в стрим, write(...) — запись массива, flush() — сохранение стрима. Основная реализация ObjectOutputStream
2. ObjectInput — интерфейс стрима для ручного восстановления объектов после сериализации. Основные методы readObject() — чтение объектов, skip — пропустить n байт. Основная реализация ObjectInputStream.
3. Serializable — интерфейс, при котором Object Serialization автоматически сохраняет и восстанавливает состояние объектов.
Объекты реализующие этот интерфейс должны:
1. иметь доступ к конструктору без аргументов у ближайшего несериализуемного предка,
отмечать сериализуемые и несериализуемые поля используя serialPersistentFields и transient.
Также такие классы могут реализовать методы (опционально):
1. writeObject — для контроля на сериализацией или записи дополнительной информации.
2. readObject — для контроля на десериализацией,
3. writeReplace — для замены объекта. который уже был записан в стрим,
4. readResolve — определения объектов для восстановления из стрима.
4. Externalizable — интерфейс, при котором Object Serialization делегирует функции сохранения и восстановления объектов функциям, определенных программистами. Externalizable расширяет интерфейс Serializable.
Объекты реализующие этот интерфейс должны:
1. иметь публичный конструктор без аргументов,
2. реализовать методы writeExternal и readExternal для чтения и записи соответственно,
3. Также такие классы могут реализовать методы (опционально):
— writeReplace — для замены объекта. который уже был записан в стрим,
— readResolve — определения объектов для восстановления из стрима.
1. ObjectOutput — интерфейс стрима для “ручной” сериализации объектов. Основные методы writeObject(объект) — запись объекта в стрим, write(...) — запись массива, flush() — сохранение стрима. Основная реализация ObjectOutputStream
2. ObjectInput — интерфейс стрима для ручного восстановления объектов после сериализации. Основные методы readObject() — чтение объектов, skip — пропустить n байт. Основная реализация ObjectInputStream.
3. Serializable — интерфейс, при котором Object Serialization автоматически сохраняет и восстанавливает состояние объектов.
Объекты реализующие этот интерфейс должны:
1. иметь доступ к конструктору без аргументов у ближайшего несериализуемного предка,
отмечать сериализуемые и несериализуемые поля используя serialPersistentFields и transient.
Также такие классы могут реализовать методы (опционально):
1. writeObject — для контроля на сериализацией или записи дополнительной информации.
2. readObject — для контроля на десериализацией,
3. writeReplace — для замены объекта. который уже был записан в стрим,
4. readResolve — определения объектов для восстановления из стрима.
4. Externalizable — интерфейс, при котором Object Serialization делегирует функции сохранения и восстановления объектов функциям, определенных программистами. Externalizable расширяет интерфейс Serializable.
Объекты реализующие этот интерфейс должны:
1. иметь публичный конструктор без аргументов,
2. реализовать методы writeExternal и readExternal для чтения и записи соответственно,
3. Также такие классы могут реализовать методы (опционально):
— writeReplace — для замены объекта. который уже был записан в стрим,
— readResolve — определения объектов для восстановления из стрима.
IV. Математика
Вот по этой теме вопросы очень редки (точнее не помню ни одного вопроса по этой теме), однако на всякий случай стоит помнить и о них.
Читать...
Есть всего несколько классов для реализации математических расчетов в Java SE:
1. java.lang.Math — класс, содержащий большое количество статических математических функций, в отличии от StrictMathих — математические функции не всегда возвращают абсолютно одинаковые значения для одного и того же аргумента (значения вещественных чисел могут отличаться на очень небольшое значение), Это позволяет достичь лучшей производительности.
2. java.lang.StrictMath — класс, содержащий большое количество статических математических функций. В отличие от Math для одного аргумента результат всегда абсолютно одинаковый. Содержить функции аналогов, которых нет в Math.
3. java.math.BigDecimal и java.math.BigInteger — классы для работы с числами требующими большой точности и размерности.
4. java.math.MathContext — настройки, которые могут использоваться в классах BigDecimal или BigInteger.
1. java.lang.Math — класс, содержащий большое количество статических математических функций, в отличии от StrictMathих — математические функции не всегда возвращают абсолютно одинаковые значения для одного и того же аргумента (значения вещественных чисел могут отличаться на очень небольшое значение), Это позволяет достичь лучшей производительности.
2. java.lang.StrictMath — класс, содержащий большое количество статических математических функций. В отличие от Math для одного аргумента результат всегда абсолютно одинаковый. Содержить функции аналогов, которых нет в Math.
3. java.math.BigDecimal и java.math.BigInteger — классы для работы с числами требующими большой точности и размерности.
4. java.math.MathContext — настройки, которые могут использоваться в классах BigDecimal или BigInteger.
V. Reference Objects
А вот про Reference объектах вопросы встречаются и очень часто на них разработчики плавают, так как это довольно редко используемые классы. По сути, это классы для более гибкого управления памятью, чем обычные «сильные» указатели.
Читать...
Классы, позволяющие создавать разные Reference объекты:
1. Reference — Абстрактный класс для подобных объектов.
2. SoftReference — Мягкие ссылки, объекты будут удалены, когда garbage collector обнаружит что не осталось свободной памяти.
3. WeakReference — Слабая ссылка. Garbage collector при следующем проходе удалит объект, доступ к которому есть только по такой ссылке. Используется для кэшей и временных объектов.
4. PhantomReference — Создает фантомную ссылку, сама ссылка всегда возвращает null, но перед удалением объекта ссылка помещается в очередь ReferenceQueue и можно освобождать ресурсы, связанные с объектом, обходя эту очередь, то есть это явлется аналогом финалайзеров.
5. ReferenceQueue — Очередь куда ссылки добавляются когда garbage collector удалил объекты на которые они ссылаются.
1. Reference — Абстрактный класс для подобных объектов.
2. SoftReference — Мягкие ссылки, объекты будут удалены, когда garbage collector обнаружит что не осталось свободной памяти.
3. WeakReference — Слабая ссылка. Garbage collector при следующем проходе удалит объект, доступ к которому есть только по такой ссылке. Используется для кэшей и временных объектов.
4. PhantomReference — Создает фантомную ссылку, сама ссылка всегда возвращает null, но перед удалением объекта ссылка помещается в очередь ReferenceQueue и можно освобождать ресурсы, связанные с объектом, обходя эту очередь, то есть это явлется аналогом финалайзеров.
5. ReferenceQueue — Очередь куда ссылки добавляются когда garbage collector удалил объекты на которые они ссылаются.
VI. Регулярные выражения
Опять редкая тема для собеседований, но помнить стоит.
Для работы с регулярными выражениями существует два основных класса и один интерфейс:
1. Pattern — Скомпилированное регулярное выражение, которое будет использоваться в Matcher
Matcher. Класс для выполнения скомпилированного регулярного выражения (класс Pattern) над CharSequence.
2. MatchResult — Служит для возврата результатов Matcher’а
VII. Логирование
Тоже не помню вопросов по этой теме, но повторить стандартное логирование в SE все-таки полезно.
Читать...
Основная схема логирования
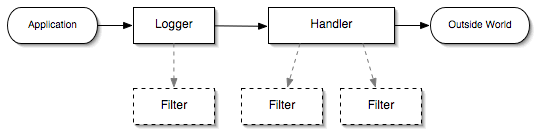
Как видно из схемы, при логирование Logger применяет фильтры и передает сообщение Handler (или цепочки Handler’ов), который также применяет фильтры, форматирование и отдает сообщение во внешний мир (выводит на консоль, сохраняет в файл и т.д.)
Каждое сообщение имеет уровень (класс Level) от FINEST до SEVERE,
Основные виды классов логгирования в Java SE:
I, Handler'ы
Существует несколько Handler в Java SE:
1. StreamHandler — Запись в OutputStream,
2. ConsoleHandler — Запись в System.err (консоль),
3. FileHandler — Запись в файл,
4. SocketHandler — Запись в TCP ports,
5. MemoryHandler — Сохранение логов в памяти,
II, Форматеры
Java SE предоставляет два вида форматеров:
1. SimpleFormatter — форматирование в виде удобном для чтения человеком,
2. XMLFormatter — форматирование xml структуру
III. Служебные классы
1. LogManager — Класс LogManager хранит информацию о всех логерах системы и их свойствамх,
2. Класс LoggingPermission служит для определения прав по изменению логгеров и т.п. для SecurityManager.
3. Класс Logger служит для логирования сообщений, а класс LogRecord — для передачи сообщений между фремворками логирования и Handlers.
Как видно из схемы, при логирование Logger применяет фильтры и передает сообщение Handler (или цепочки Handler’ов), который также применяет фильтры, форматирование и отдает сообщение во внешний мир (выводит на консоль, сохраняет в файл и т.д.)
Каждое сообщение имеет уровень (класс Level) от FINEST до SEVERE,
Основные виды классов логгирования в Java SE:
I, Handler'ы
Существует несколько Handler в Java SE:
1. StreamHandler — Запись в OutputStream,
2. ConsoleHandler — Запись в System.err (консоль),
3. FileHandler — Запись в файл,
4. SocketHandler — Запись в TCP ports,
5. MemoryHandler — Сохранение логов в памяти,
II, Форматеры
Java SE предоставляет два вида форматеров:
1. SimpleFormatter — форматирование в виде удобном для чтения человеком,
2. XMLFormatter — форматирование xml структуру
III. Служебные классы
1. LogManager — Класс LogManager хранит информацию о всех логерах системы и их свойствамх,
2. Класс LoggingPermission служит для определения прав по изменению логгеров и т.п. для SecurityManager.
3. Класс Logger служит для логирования сообщений, а класс LogRecord — для передачи сообщений между фремворками логирования и Handlers.
VIII. Concurrency
Читать...
Возможные вопросы
- How can we make sure main() is the last thread to finish in Java Program?
- Как thread могут взаимодействовать с друг другом?
- Why thread communication methods wait(), notify() and notifyAll() are in Object class?
- Why wait(), notify() and notifyAll() methods have to be called from synchronized method or block?
- Почему Thread sleep() и yield() методы статические?
- Как обеспечить thread safety в Java?
- Что такое volatile keyword в Java
- Что предпочтительнее Synchronized метод или Synchronized блок?
- Что такое ThreadLocal?
- Что такое Thread Group? Стоит ли их использовать?
- Что такое Java Thread Dump, Как получить Java Thread dump программы?
- Что такое Java Timer Class? Как запустить task после определенного интервала времени?
- Что такое Thread Pool? Как создать Thread Pool в Java?
- Что произойдет если не override метод run() у класса Thread ?
Thread
Читать...
Processes and threads — разница в том что процессы это независимые приложения (управляются ОС), thread это отдельные легковесные нити для параллельного выполнения в Java (управляются JVM и программистом).
Преимущества multi-threaded программирования — правильно написанная multi-threaded приложение работает быстрее за счет использования нескольких процессоров и процессор не простаивает пока один из потоков ожидает получения ресурсов.
daemon thread — thread, который работает в фоновом режиме и JVM не требуется ждать его окончания, чтобы завершить работу. Можно сделать любой thread демоном используя setDaemon(true), но этот метод должен вызваться до запуска thread с помощью start.
ThreadGroup — устаревший API, который предоставляет информацию о группе потоков. Сейчас не рекомендуется к использованию.
Java Thread Dump — получение информации о состоянии всех потоков JVM и поиска deadlock ситуаций или других проблем с многопоточностью. Есть много способов генерации Java Thread Dump, например в Java 8 можно сгененерить с помощью команды jcmd PID имя_файла_для_дампа или kill -3 PID, либо с помощью любого профайлера (VisualVM, jstack и т.д.)
Способы создания thread в Java SE:
1. Создать класс, реализующий Runnable интерфейс, реализовать метод run и запустить thread методом start, обратите внимание вызвать метод run неправильно, в этом случае не будет создан новый thread (хотя он отработает).
2. Создать класс-наследника от класса Thread, также переопределить метод run и запустить thread методом start. В отличии от способа 1, класс Thread предоставляет ряд уже определенных методов, однако реализация интерфейса дает больше гибкости (так как множественное наследование в Java невозможно),
3. Использовать Executors, который предоставляет высокоуровневый аналог способов 1-2.
Методы работы с Thread
1. sleep — останавливает выполнение на указанное время, либо до момента когда Thread не был прерван,
2. interrupt — посылает сигнал в Thread, о том что тот должен быть прекращен (мягкое прерывание потока), поток должен поддерживать обработку данного сигнала (опрашивая периодически флаг Thread.interrupted),
3. join — ждет окончания другого потока или сигнала остановки треда,
4. synchronized — ключевое слово перед методами либо блок synchronized(ссылка) {...}
5. wait — остановка треда и ожидания вызова notify или notifyAll.
6. stop (deprecated) — немедленная остановка треда, крайне не рекомендуется использовать, так как состояние общих переменных может оказаться в некорректном состоянии.
7. suspend (deprecated) и resume (deprecated) — временная остановка потока и его восстановление. Не рекомендуется использовать так как очень часто это приводит к deadlock«у (ресурсы при временной остановки остаются заблокированными)
8. setUncaughtExceptionHandler — возможность добавить обработчик исключений в данный поток.
Особые переменные для thread:
ThreadLocal — переменная локальная только для одного thread'а, каждый thread будет видеть свое значение.
volatile — ключевое слово, которое отмечает переменные, которые все потоки читают из памяти (heap) и не кэшируют. Это не решает все проблемы синхронизации, однако обычные переменные потоки имеют право за кэшировать и вообще не обновлять долгое время. Для более надежной работы с несколькими thread'ами стоит использовать Atomic переменные или блоки синхронизации.
Возможные вопросы
- В чем разница между Process и Thread?
- В чем преимущества multi-threaded программирования?
- В чем разница между user Thread и daemon Thread?
- Как создать Thread в Java?
- Какие есть различные состояние у Thread?
- Можно ли вызвать run() метод у Thread класса?
- Как можно остановить выполнения Thread на определенное время?
- Что такое Thread Priority?
- Что такое Thread Scheduler и Time Slicing?
- Что такое context-switching в multi-threading?
- Как создать daemon thread в Java?
Processes and threads — разница в том что процессы это независимые приложения (управляются ОС), thread это отдельные легковесные нити для параллельного выполнения в Java (управляются JVM и программистом).
Преимущества multi-threaded программирования — правильно написанная multi-threaded приложение работает быстрее за счет использования нескольких процессоров и процессор не простаивает пока один из потоков ожидает получения ресурсов.
daemon thread — thread, который работает в фоновом режиме и JVM не требуется ждать его окончания, чтобы завершить работу. Можно сделать любой thread демоном используя setDaemon(true), но этот метод должен вызваться до запуска thread с помощью start.
ThreadGroup — устаревший API, который предоставляет информацию о группе потоков. Сейчас не рекомендуется к использованию.
Java Thread Dump — получение информации о состоянии всех потоков JVM и поиска deadlock ситуаций или других проблем с многопоточностью. Есть много способов генерации Java Thread Dump, например в Java 8 можно сгененерить с помощью команды jcmd PID имя_файла_для_дампа или kill -3 PID, либо с помощью любого профайлера (VisualVM, jstack и т.д.)
Способы создания thread в Java SE:
1. Создать класс, реализующий Runnable интерфейс, реализовать метод run и запустить thread методом start, обратите внимание вызвать метод run неправильно, в этом случае не будет создан новый thread (хотя он отработает).
2. Создать класс-наследника от класса Thread, также переопределить метод run и запустить thread методом start. В отличии от способа 1, класс Thread предоставляет ряд уже определенных методов, однако реализация интерфейса дает больше гибкости (так как множественное наследование в Java невозможно),
3. Использовать Executors, который предоставляет высокоуровневый аналог способов 1-2.
Методы работы с Thread
1. sleep — останавливает выполнение на указанное время, либо до момента когда Thread не был прерван,
2. interrupt — посылает сигнал в Thread, о том что тот должен быть прекращен (мягкое прерывание потока), поток должен поддерживать обработку данного сигнала (опрашивая периодически флаг Thread.interrupted),
3. join — ждет окончания другого потока или сигнала остановки треда,
4. synchronized — ключевое слово перед методами либо блок synchronized(ссылка) {...}
5. wait — остановка треда и ожидания вызова notify или notifyAll.
6. stop (deprecated) — немедленная остановка треда, крайне не рекомендуется использовать, так как состояние общих переменных может оказаться в некорректном состоянии.
7. suspend (deprecated) и resume (deprecated) — временная остановка потока и его восстановление. Не рекомендуется использовать так как очень часто это приводит к deadlock«у (ресурсы при временной остановки остаются заблокированными)
8. setUncaughtExceptionHandler — возможность добавить обработчик исключений в данный поток.
Особые переменные для thread:
ThreadLocal — переменная локальная только для одного thread'а, каждый thread будет видеть свое значение.
volatile — ключевое слово, которое отмечает переменные, которые все потоки читают из памяти (heap) и не кэшируют. Это не решает все проблемы синхронизации, однако обычные переменные потоки имеют право за кэшировать и вообще не обновлять долгое время. Для более надежной работы с несколькими thread'ами стоит использовать Atomic переменные или блоки синхронизации.
Atomic операции и классы
Читать...
Atomic операции — операции которые выполняются или не выполняются целиком.
Следующие операции atomic:
1. Чтение и запись ссылок и примитивных типов (кроме long и double)
2. Чтение и запись всех переменных отмеченных как volatile (так как запись и чтение выполняется как happens-before relationship, то есть в гарантированном порядке),
Atomic переменные для простого способа создания переменных общих для разных тредов с минимизаций синхронизации и ошибок. Подробнее см javadoc
Возможные вопросы
- Какие типы данных в Java являются атомарными для операций чтения/записи с точки зрения многопоточности?
- Что такое atomic operation?
- Какие atomic классы в Java Concurrency API вы знаете?
Atomic операции — операции которые выполняются или не выполняются целиком.
Следующие операции atomic:
1. Чтение и запись ссылок и примитивных типов (кроме long и double)
2. Чтение и запись всех переменных отмеченных как volatile (так как запись и чтение выполняется как happens-before relationship, то есть в гарантированном порядке),
Atomic переменные для простого способа создания переменных общих для разных тредов с минимизаций синхронизации и ошибок. Подробнее см javadoc
Liveness problem
Читать...
Проблемы при выполнении у многопоточных приложений (liveness problem):
1. Deadlock — блокировка двух разных ресурсов двумя тредами с бесконечным ожиданием освобождения,
2, Starvation — один из потоков блокирует часто используемый ресурс на долгое время заставляя остальные потоки ждать освобождения
3. Livelock — когда два потока освобождают и занимают одни и те же ресурсы в ответ на действия друг друга, при этом не могут занять все необходимые ресурсы и продолжить выполнения.
Возможные вопросы
- Что такое Deadlock? Как анализировать и избегать deadlock?
- Какие проблемы при многопоточности бывают кроме Deadlock?
- Что такое Starvation и Livelock?
Проблемы при выполнении у многопоточных приложений (liveness problem):
1. Deadlock — блокировка двух разных ресурсов двумя тредами с бесконечным ожиданием освобождения,
2, Starvation — один из потоков блокирует часто используемый ресурс на долгое время заставляя остальные потоки ждать освобождения
3. Livelock — когда два потока освобождают и занимают одни и те же ресурсы в ответ на действия друг друга, при этом не могут занять все необходимые ресурсы и продолжить выполнения.
Стратегия определения неизменяемых объектов
Читать...
Для создания неизменяемых объектов требуется придерживаться следующих правил:
1. Не предоставлять „setter“ методов, все поля должны быть final и private,
2. Не позволять наследникам переопределять методы, простейший путь определить класс как final. Более сложный путь определить конструктор как private и создать объекты с помощью factory метода.
3. Поля, включая поля с ссылками на mutable objects не должны позволять изменения:
4. Не предоставлять методов по изменению mutable объектов,.
5. Не отдавать ссылок на mutable объекты, при необходимости создавать копии и передавать копии объектов.
1. Не предоставлять „setter“ методов, все поля должны быть final и private,
2. Не позволять наследникам переопределять методы, простейший путь определить класс как final. Более сложный путь определить конструктор как private и создать объекты с помощью factory метода.
3. Поля, включая поля с ссылками на mutable objects не должны позволять изменения:
4. Не предоставлять методов по изменению mutable объектов,.
5. Не отдавать ссылок на mutable объекты, при необходимости создавать копии и передавать копии объектов.
Высокоуровневые средства работы с многопоточностью
Читать...
Возможные вопросы
- Что такое Lock interface в Java Concurrency API? Какие его плюсы по сравнению synchronization?
- Что такое Executors Framework?
- Что такое BlockingQueue? Как избежать Producer-Consumer проблему используя Blocking Queue?
- Что такое Callable и Future?
- Что такое FutureTask класс?
- Что такое Concurrent Collection класс?
- Что такое Executors класс?
- Какие улучшению в Concurrency API есть в Java 8?
Читать...
В отличие от synchronized блоков и т.п. низкоуровневых средств работы с многопоточными приложениями, J8SE так же предоставляет много средств для более удобных средств работы с многопоточными приложениями в отличие от низкоуровневых средств ручного управления тредами и блокировками.
Основные виды:
1. Task scheduling framework ( Executor) — интерфейс для запуска заданий в новом треде с запуском по расписанию, управлением асинхорными тасками и т.п.
2. ForkJoinPool — класс, реализующий Executors и ExecutorService для реализации многопоточных стримов и т.п. Он разработан для для эффективного распараллеливания большого количества небольших по времени задач, используя пул тредов (используется технология work-stealing).
3. Lock объекты — удобный способ блокировки объектов и передачи данных между тредами,
4. Executors определяет высокоуровневый способ создания и управления тредами с помощью пула объектов,
5. Многопоточные коллекции — коллекции, работающие в многопоточном приложении (Concurrent Collection, BlockingQueue, Если вам интересны более подробная информация о интерфейсах и коллекциях из java.util.concurrent советую прочитать раздел коллекции этой статьи или вот эту статью.),
6. Atomic переменные для простого способа создания переменных общих для разных тредов с минимизаций синхронизации и ошибок. Подробнее см javadoc
7. ThreadLocalRandom (с JDK 7) предоставляет эффективный способ создания псевдослучайных чисел для многопоточных программ.
Основные виды:
1. Task scheduling framework ( Executor) — интерфейс для запуска заданий в новом треде с запуском по расписанию, управлением асинхорными тасками и т.п.
2. ForkJoinPool — класс, реализующий Executors и ExecutorService для реализации многопоточных стримов и т.п. Он разработан для для эффективного распараллеливания большого количества небольших по времени задач, используя пул тредов (используется технология work-stealing).
3. Lock объекты — удобный способ блокировки объектов и передачи данных между тредами,
4. Executors определяет высокоуровневый способ создания и управления тредами с помощью пула объектов,
5. Многопоточные коллекции — коллекции, работающие в многопоточном приложении (Concurrent Collection, BlockingQueue, Если вам интересны более подробная информация о интерфейсах и коллекциях из java.util.concurrent советую прочитать раздел коллекции этой статьи или вот эту статью.),
6. Atomic переменные для простого способа создания переменных общих для разных тредов с минимизаций синхронизации и ошибок. Подробнее см javadoc
7. ThreadLocalRandom (с JDK 7) предоставляет эффективный способ создания псевдослучайных чисел для многопоточных программ.
IX. Exceptions и Errors
Читать...
В Java есть два вида сообщений о ошибках:
1. Error — критические ошибки, которые обычно не возможно исправить, и которые приводят к завершению программы, такие как OutOfMemoryError. Их можно перехватить с помощью catch, но в этом редко бывает смысл.
2. Exception — ошибки приложения, которые можно обработать. Они делятся на:
— checked — Exception, которые обязательно нужно либо перехватить в методе с помощью catch или переслать дальше с помощью throws (указать данный Exception или его суперкласс в секции throws метода)
— unchecked — Exception, которые можно не перехватывать и не указывать в секции throws метода,
Структура наследования:
1. Throwable — любые ошибки и exception
1.1 Error — критические ошибки, которые обычно не обрабатываются и завершают программу,
1.2 Exception — все exception, по умолчанию все наследуемые классы checked exception (кроме тех кто наследуются от RuntimeException)
1.2.1 RuntimeException — все наследуемые от этого классы — unchecked exception,
Бывают вопросы о самом любимом и нелюбимом Exception'е. На мой вгляд самый неприятный вид Exception это, скорее всего, NullPointerException (он показывает, что что-то написано скорее всего неправильно), самый „лучший“ IllegalArgumentException (это значит, что программист предусмотрел проверку данной ситуации).
Возможные вопросы
- Можно ли указывать unchecked исключения в секции throws?
- Что будет, если в секции throws одно и то же исключение указано несколько раз?
- Можно ли смешивать checked и unchecked исключения?
- В чем отличие checked и unchecked исключений?
- В чем отличие Exception и Error?
- Самом любимый и нелюбимый Exception?
- Можно ли перехватить Error или Throwable?
В Java есть два вида сообщений о ошибках:
1. Error — критические ошибки, которые обычно не возможно исправить, и которые приводят к завершению программы, такие как OutOfMemoryError. Их можно перехватить с помощью catch, но в этом редко бывает смысл.
2. Exception — ошибки приложения, которые можно обработать. Они делятся на:
— checked — Exception, которые обязательно нужно либо перехватить в методе с помощью catch или переслать дальше с помощью throws (указать данный Exception или его суперкласс в секции throws метода)
— unchecked — Exception, которые можно не перехватывать и не указывать в секции throws метода,
Структура наследования:
1. Throwable — любые ошибки и exception
1.1 Error — критические ошибки, которые обычно не обрабатываются и завершают программу,
1.2 Exception — все exception, по умолчанию все наследуемые классы checked exception (кроме тех кто наследуются от RuntimeException)
1.2.1 RuntimeException — все наследуемые от этого классы — unchecked exception,
Бывают вопросы о самом любимом и нелюбимом Exception'е. На мой вгляд самый неприятный вид Exception это, скорее всего, NullPointerException (он показывает, что что-то написано скорее всего неправильно), самый „лучший“ IllegalArgumentException (это значит, что программист предусмотрел проверку данной ситуации).
X. Строки
Читать...
String это такой же класс, как и любой другой и не является примитивным типом. Однако у него есть определенные особенности, он неизменяемый (immutable) и не расширяемый (final), это сделано для безопасности (невозможность поменять строку содержащую, например, адрес до сервера), многопоточности (так как он immutable, то потокобезопасен), а так же удобства использования в качестве ключа в коллекциях, например, Map, так как по контракту они требуют immutable объектов в качестве ключа.
Способы создания String — с помощью кавычек „abc“, с помощью new как любой другой объект (new String(»abc")) или используя другие классы, такие как StringBuffer или StringBuilder.
Для производительности используется String Pool (кеш, хранящий используемые строки и позволяющий не создавать объект строки снова). C помощью метода intern() сохранить строку в пуле.
StringBuffer и StringBuilder два класса генерации строки, которые часто работают быстрее если нужно собрать строку из нескольких кусочков, при это StringBuffer синхронизированный и потокобезопасный, а StringBuilder — нет, если нет проблемы с потокобезопасностью или это локальная переменные — StringBuilder работает намного быстрее.
Возможные вопросы...
- Что такое String в Java? String — это тип данных?
- Каковы различные способы создания String ?
- Как мы можем сделать строчный верхний регистр или нижний регистр?
- Что такое метод SubSequence у класса String?
- Как сравнить две строки в java-программе?
- Как преобразовать строку в char и наоборот?
- Как преобразовать String в массив байтов и наоборот?
- Можно ли использовать строку в switch операторе?
- Разница между String, StringBuffer и StringBuilder?
- Почему String immutable и final в Java
- Как разделить строку в java?
- Почему массив Char предпочтительнее String для хранения пароля?
- Как вы проверяете, равны ли две строки в Java?
- Что такое String Pool?
- Что делает метод string ()?
- Строка является потокобезопасной в Java?
- Почему String является популярным ключом HashMap на Java?
String это такой же класс, как и любой другой и не является примитивным типом. Однако у него есть определенные особенности, он неизменяемый (immutable) и не расширяемый (final), это сделано для безопасности (невозможность поменять строку содержащую, например, адрес до сервера), многопоточности (так как он immutable, то потокобезопасен), а так же удобства использования в качестве ключа в коллекциях, например, Map, так как по контракту они требуют immutable объектов в качестве ключа.
Способы создания String — с помощью кавычек „abc“, с помощью new как любой другой объект (new String(»abc")) или используя другие классы, такие как StringBuffer или StringBuilder.
Для производительности используется String Pool (кеш, хранящий используемые строки и позволяющий не создавать объект строки снова). C помощью метода intern() сохранить строку в пуле.
StringBuffer и StringBuilder два класса генерации строки, которые часто работают быстрее если нужно собрать строку из нескольких кусочков, при это StringBuffer синхронизированный и потокобезопасный, а StringBuilder — нет, если нет проблемы с потокобезопасностью или это локальная переменные — StringBuilder работает намного быстрее.
Спасибо за внимание. Другие шпаргалки можно найти в моем профиле.
