
Александр Зайцев отвечает на вопросы относительно переезда на Yandex ClickHouse. Это — расшифровка доклада Highload++ 2016.
Всем здравствуйте! За эти два дня на конференции было два двухчасовых митапа, сегодня даже почти трёхчасовой митап по ClickHouse. После этого Виктор с Алексеем сделали замечательный доклад, казалось бы — больше уже ничего не расскажешь. На самом деле это не так.
Я вам расскажу, как на ClickHouse переезжать, если у вас уже что-то есть. Обычно если ничего нет, то всё очень просто. Берёте и строите на новой системе. А вот если что-то есть, то это гораздо сложнее. Сейчас у вас всё хорошо. Вы поняли, что ClickHouse замечательная система. Виктор с Алексеем ответят на все вопросы, я не сомневаюсь, чтобы ещё больше уверить вас в том, что это правильное решение.
На самом деле, не всё так хорошо, как они рассказывают если вы собираетесь переезжать. Потому что ClickHouse достаточно сильно отличается от всего с чем вы имели дело в прошлом.
Всё это совершенно новый и достаточно специфический опыт, он требует большой работы для того чтобы всё получилось хорошо. Какие-то простые вещи работают сразу, например, логи загрузить. А какие-то не очень простые вещи работают совсем не сразу. В конце концов, я убеждён что у всех всё получится, потому что у нас получилось. Мы прорвались через все препятствия.
Кто такие мы?
Я работаю в компании LifeStreet – это рекламная сеть. Достаточно крупная сеть, мы существуем на рынке больше 10 лет, занимаемся оптимизацией разного типа рекламных вещей: кампании, объявления, части объявлений, bidding, интегрирования с внешними системами и т.д.
Это совершенно живая компания, которая зарабатывает десятки миллионов долларов ежегодно, у нас не так много данных, как в Яндексе, а где-то вполовину меньше. Всего лишь 10 миллиардов событий в день. Всё это дело хранится в большой аналитической системе: используется как внутренними пользователями, так и внешними, так и алгоритмами machine learning, оптимизацией и прочим. Инфраструктура, которая у нас есть, она очень хорошая, выверенная, построена на Vertica 2010 года, мы одни из самых первых кто начали использовать Vertica в России, хотя компания американская. Об это я рассказывал на HighLoad два раза, последний раз в 2013 году. В тот раз я рассказывал какие еще есть варианты построения аналитических систем. ClickHouse тогда не существовало. Я там рассмотрел разные и лучше Vertica не нашёл. Тогда ничего лучше не было.
Но мы продолжали смотреть — нам Vertica всем нравилось, но были некоторые вещи, и мы хотели рано или поздно от неё отказаться. В прошлом году появилась такая штука как Snowflake, компания целиком на Amazon. Замечательно масштабируется, она on demand поднимает сервера, то есть вы можете на ночь сервера выключать, а днём включать и не платить за них. Данные все хранятся в Amazon S3 и т.д. Она настолько хорошая, потому что разрабатывалась бывшими программистами Vertica — они плохого не сделают.
У нас пока всё хорошо, но мы хотим уйти с Vertica.
В один прекрасный момент появляется, как кролик из шапки, ClickHouse. Все бросаются на него смотреть — что же это такое. Потому что он быстрый, очень быстро бегает, ребята сказали правду. Он замечательно масштабируется, посадили одного кролика, через месяц уже целое семейство. Это правда классная штука, большое вам спасибо ото всех.
Наш CTO присылает мне письмо следующего содержания:

Саша, у ClickHouse похожие use case, они рекламная сеть, они считают клики и т.д. Они выпустили систему и на бумаге выглядит всё идеально. Практически то, что нам нужно. Абсолютно ко всему подходит, если мы сможем это использовать – это будет очень круто. Пожалуйста посмотри.
Сказано — сделано
Что такое ClickHouse летом-осенью 2016 года?
Во-первых, он только появился — штука новая совершенно. Это обычно плохо для любого продукта, там скорее всего много багов и т.д. Это внутренний проект Яндекса. Это первый внешний продукт с непонятными тогда ещё перспективами.
Выпустили в Open Source, хорошо. И что?
Тогда еще не было независимых инсталляций, а сейчас хоть и говорят, что есть продакшн инсталляции — на самом деле неизвестно у кого, неизвестно с какими результатами, нагрузками. Нет case studies хороших, чтобы на них посмотреть и понять, что это действительно то, что нужно. Нет поддержки, Алексей — это единственная поддержка, которая есть, но он один. Нет roadmap, непонятно как продукт будет развиваться. Никаких планов компания не разглашает, это всё внутреннее, то есть продукт вроде и Open Source, но все планы внутренние. Было всего три разработчика, как объявлено, у самого ClickHouse и ещё несколько из Яндекс.Метрики помощников.
Сразу было понятно из документации, что много известных ограничений, которые уже задокументированы. А сколько неизвестных было непонятно, но было понятно, что они тоже есть.
Немножко давили истории других проектов, которые только и сделали, что выпустили в Open Source, потому что они не всегда были успешны. Например, Facebook выпустил Cassandra в Open Source, когда она была очень сырая, в конце концов он её уже не использует, но Cassandra повезло, её развивают другие.
Если вы были на докладах Петра Зайцева, он наверняка рассказывал про TokuDB и TokuMX, которые входят в Percona сервер. Это была такая компания Tokutek в Бостоне. Она делала совершенно замечательный аналитический engine для MySQL, который блоками хранил и брал данные, гораздо лучше, чем InnoDB для ряда задач. Компания замечательная, но продавалось всё это очень плохо — в конце концов она обанкротилась, но, чтобы её результаты не потерялись, она всё это выпустила в Open Source.
С таким вот списочком мы приходим к нашему директору в LifeStreet, который отвечает за это направление и за деньги. Мы говорим ему: «Пол, мы хотим Vertica и твою аналитическую структуру поменять на вот это, разработано в России». Как вы думаете, что он сказал? Он вежливый человек, но он сказал: «Вы что с ума сошли? Вы хотите это заменить на то что у меня работает и приносит деньги?».
К счастью, не он принимает решения, но он так сказал.
Дальше мы пошли к разработчикам, которые умеют разрабатывать для баз данных, знают SQL и все вот эти вещи. Они стали смотреть на ClickHouse. Они поняли, что в ClickHouse почти ничего нет:
- Там нет транзакций, нет констрейнтов.
- Там есть primary key, но это не primary key на самом деле, можно сказать это порядок физической сортировки.
- Там нет Consistency, то есть Consistency никак не гарантируется.
- Нет удалений и апдейта.
- Нет NULLs, система к которой вообще нельзя Null записать.
- Нет миллисекунд, то есть время с точностью до секунды, хотите миллисекунды – храните их по-своему, как Int64 или отдельным полем.
- Нет автоматических приведения типов, то есть даже Int8 к Int16 надо приводить явно.
- Нет нормального SQL, это понятно из всего предыдущего списка.
- Нет произвольного партиционирования, партиционировать можно только по месяцам, то есть нельзя по дням или по неделям отпартиционировать или по произвольным ключам, нельзя и всё.
- Нет средств управления кластером, то есть они, наверное, есть у самого Яндекса, но он их не смог настолько запаковать, чтобы это можно было увидеть в Open Source или не захотел.
Как думаете, что сказал разработчик, когда увидел этот список?
Он сказал: «И они называют это базой данных?» «Они» — это имеется ввиду Яндекс. Тем не менее, несмотря на понимание, что у системы есть серьёзные ограничения — мы решили попробовать.
Решили попробовать в первую очередь потому, что действительно близкая предметная область и задача. А раз близкая задача, то и решение для нас скорее всего заработает, кроме того в России авторитет Яндекса очень высок. Я знаю достаточное количество людей, которые работали или работают в Яндексе — все они очень высокие профессионалы. Сразу активный интерес сообщества к этой теме. Он показал, что она действительно интересная и это не может быть пустым звуком. Нам это стало очень интересно. Нам захотелось действительно попробовать, потому что это интересная штука. И это бесплатно.
Мы попробовали — сделали быстренько небольшой пилотный проект и поняли, что это действительно работает. Яндекс говорит правду. Это работает быстро.
Это первая база данных на нашей памяти — за последние годы, которые мы проверяли, а проверяли достаточно много — которая не была хуже Vertica. На яндексовских она была лучше, на наших тестах она была примерно ровно, где-то чуть-чуть лучше, где-то чуть-чуть хуже. Это очень сильный результат.
Много особенностей — это мы тоже поняли. Что очень неплохая документация, то есть как документация для проекта, который только-только выпущен в Open Source. Она была и остаётся идеальной, на мой взгляд, там конечно некоторых вещей нет, но, во-первых, их всегда можно спросить, во-вторых то, что есть, этого уже достаточно чтобы начать и далеко не только начать. Совершенно живой форум на Google Groups, где на ответы Алексей, по его собственному признанию, тратит чуть ли не половину рабочего времени. Эти ответы всегда очень развёрнуты, он пытается вникнуть в суть проблемы и это нас убедило, что в Яндексе отношение более чем серьезное.
Ну, я уже говорил про Алексея: из-за его ответов на вопросы, на личную почту и, даже дошло до того, что мы лично приехали в Яндекс — я приехал с одним из своих разработчиков, чтобы поговорить с Алексеем и посмотреть ему в глаза. Мы посмотрели и поняли, что «можно».
Так что мы поехали
Как я уже сказал: главной проблемой было то, что нужно было перевести существующую систему на ClickHouse. Это схемы данных, это скрипты загрузки, это OLAP-сервис, который использовался для отдачи этих данных всем нашим клиентам и внутренним, и внешним, а также некоторые процедуры администрирования.
Существует фундаментальная проблем переезда. Если вы переезжаете в другое место — обычно вам что-нибудь, да не подходит. Вы переезжаете в Англию, вам приходится ездить по другой стороне. Вы переезжаете в Америку, у вас там вилка к розетке не подходит. Есть определенные привычки, какие вещи, к которым вы привыкли. Они у вас работают, вы переезжаете, и они у вас перестают работать. Эта проблема переезда существует всегда, на что вы бы ни переезжали, даже очень близких систем. И вот в ClickHouse это сложность — она была основной. То, к чему мы привыкли в нашей наработанной практике, в базах данных таких, как: MySQL, Oracle, Vertica — если говорить о подходах и их применимости в ClickHouse, в лоб они не работали никогда, а не в лоб их всегда удавалось сделать.
Самое важное — это, конечно, схема. От схемы данных зависит всё. И схемы, которые используются в аналитических задачах, это такая звезда, вложенная в куб или куб, развёрнутый в звезду. Такая хитрая геометрия.
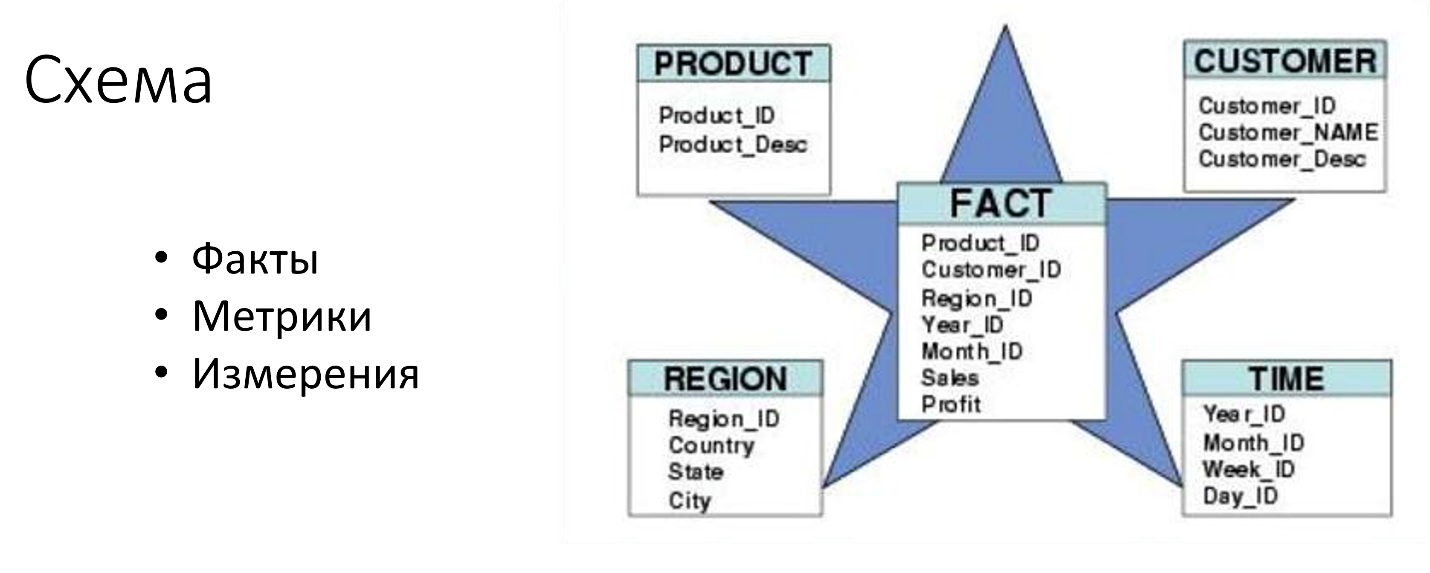
Эта табличка посредине — её обычно называют «факты», а таблички по сторонам называют «измерениями» или «деменшенами». Кроме того, есть такое синтетическое понятие как метрика — это некоторая функция, агрегирующая над фактами.
Вот эта схема необязательно выглядит так, как здесь нарисована, потому что всегда существует две крайности. Можно все положить в таблицу фактов, в том числе все измерения, и это будет очень дорого по диску, много потребуется места, дорого получить список. Если у вас миллиард записей, а вы хотите получить список всех стран, которые там есть, то какое бы эффективное хранение колонки ни было — если она конечно не хранит список стран отдельно — то придётся её всю прочитать, что будет дорого. И нельзя ничего менять. Обычно таблицу фактов никогда не меняют.
Другая крайность — это когда у вас всё в таблице измерения (и здесь ClickHouse подкладывает большую свинью, так скажем — тем что в нем очень плохие join, я про них потом скажу, join очень ограничено применимые). И опять же нет апдейтов — хотя измерение это первое дело, что достаточно часто требуется обновлять или добавлять в них какие-то вещи.
Немного подробнее здесь остановлюсь
Измерения можно разделить на три условных типа. Первое — это статические справочники, которые не меняются никогда, ну или крайне редко. Например, список стран, иерархия времени, иерархия географии и тому подобное. Они почти никогда не меняются. Кроме того, обычно в компании есть какая-то своя CRM и RP, а в ней есть изменяемые справочники: список клиентов, список рекламных компаний, какие-то характеристики объявлений и так далее. Они изменяются, но не часто. Если база данных LTP обычная, то там что-то да когда-то меняется. И эти изменения нужно отображать в аналитической базе данных. И кроме того есть ряд данных, которым произвольные атрибуты, прибегают из сети — например, id application или модели телефонов, которые меняются так часто и так быстро, появляются новые, что сделать статический справочник или даже слабоизменяемый практически невозможно. Вы никогда не знаете, что у вас из трафика прилетит.
Как оказалось, в ClickHouse есть такая замечательная штука, как словари. Виктор немного о них сказал, а я скажу о них подробно. Словари позволяют с ключом связывать нечто, если брать аналог из Cassandra — это column family, то есть по ключу есть ряд колонок со значениями. Все эти словари можно брать из разных источников, например, из файлов или MySQL базы данных. Они описываются в XML, при чем здесь можно описать в одном файле один словарь, тем самым легко поддерживать версии и всем этим делом управлять немного легче.
Они обновляемые, хотя с некоторыми нюансами, о которых я расскажу дальше.
И к ним доступ через функцию — не через такую, как показал Виктор, потому что он показал доступ к своим словарям, которые зашиты внутрь ClickHouse, а вот к словарю общего типа доступ и через функцию общего типа.
У словарей есть определенные ограничения. Одно из ограничений, их на самом деле в ClickHouse много — тип Ulnt64, других типов не может быть. А поскольку imple set явных приведений типа ClickHouse нет, если у вас тип колонке в другой таблице другой, то приходится приводить к типу, что не очень удобно.
Второе ограничение, достаточно для нас существенное, может для кого-то и нет — это то, что нет прямого способа получить все значения колонки. Вы не можете из словаря понять, что там лежит. Такого способа нет, можно только посмотреть в источник, а вот из ClickHouse в лоб спросить нельзя.
Есть определенное ограничение по размеру. Там есть три типа словарей и самый эффективный и быстрый, он огранен размером 500 тысяч строк, очередное магическое число. Есть и другие типы, которые менее ограничены, но они работают медленнее. Нельзя обновить словарь по требованию или по изменению источника, опять же с некоторыми нюансами. Приходится как-то за этим следить. На каждом узле кластера все независимо. Если у вас 100 нодов в кластере и вам нужно обновить словарь — необходимо на каждый нод сходить, чтобы он обновился. И в некоторых случаях запросы могут работать медленно.

Мы придумали вот такую штуку. Сейчас ноу-хау, не знаю использует ли сейчас Яндекс такое или нет. Мы придумали такое ноу-хау — мы делаем таблицы, к каждому словарю приделываем еще таблицу, в которой храним только ключи.
Что это даёт

Это даёт возможность получить все записи из словаря таким, например, образом с одной стороны, а с другой даёт возможность оптимизировать такие запросы. Если у вас есть очень-очень большая таблица и вы делаете, например, такой вот запрос с такого рода условием, то эта функция будет вызываться каждую строчку, вероятно, что для очень большой таблицы не слишком быстро. А вот с использованием отдельной таблички для ключей можно запрос переписать. Можно сначала вытащить отдельный набор ключей, очень простым запросом, а потом работает очень эффективный select.
Это конечно упрощенные запросы. В реальности там еще какие-то другие условия будут, но мысль, наверное, понятна.
Обновление словарей для нас тоже важно, потому что данные меняются. Стандартный способ по таймеру, который по-умолчанию 5 минут. Чем это плохо? Тем, что если у вас много словарей и много серверов — то коннектов идёт, например, к MySQL очень много и они его могут озадачить.
Нужно какие-то или реплики ставить, или как-то это разрешать по-другому, но если вам так повезло, что у вас исходная таблица в MyISAM, то ClickHouse сам понимает, что словарь изменился. Поскольку то, что в MyISAM таблице, в её описании, если смотреть show table, то там будет дата последнего изменения и ClickHouse умеет на это дело смотреть и подцеплять изменения.
Еще один замечательный способ — это сделать Touch конфига. То есть если зайти на сервер, сделать Touch конфиг файла описания словаря — то ClickHouse подумает, что словарь поменялся и его заберёт. Но нужно пройтись по всем серверам кластера.
И наконец, последний способ, который мы придумали — придумали, но не пробовали. Это, например, сделать Shared-файл где-нибудь и забирать словарь из файла. Shared-файл проще поменять, чем идти по всем нодам.
Вообще, как и Виктор заметил — что 80% join это убрало, так и для нас это настоящая серебряная пуля, даже целый серебряная лавка, который позволяет star schema (звезда в кубе) сделать хоть как-то работающей.
Но таблицы все-таки иногда нужны
Во-первых, это для ключей. Во-вторых это атрибуты из веб-трафика, который в словари никак не укладываются. В-третьих это join по сложному ключу, если у вас ключ составной, если вы не можете хеш сделать по каким-то причинам, то словарь не получится.
Если вам нужно делать join по промежутку дат — у вас есть таблица, где какой-то диапазон дат и есть какое-то значение. Вам нужно взять это значение на сегодняшнюю дату или на вчера, и так далее. Такой специфический use case, всегда его можно решить по-другому, но на словарях это не работает.
Раз появляется таблица, то появляется вопрос «как обновлять таблицу?». ClickHouse говорит, что этого делать не нужно, но если вам нужно обновить — то перепишите целиком. Ну а если очень хочется, то можно.
Для этого есть такая штука, как ReplacingMergeTree. Она позволяет в принципе обновить запись, но, во-первых, это очень Eventually — однажды она у вас обновится, вы туда добавляете запись и однажды эта новая запись станет текущей, но когда – вы не знаете. Можно позвать optimize и тогда она у вас действительно станет текущей сразу, если повезет, а можно поставить final и он тоже вытаскивает текущую запись. Яндекс говорит, что это медленно и не эффективно, хотя для маленьких таблиц разницы никакой нет.
Неудобно обновлять отдельные поля, то есть удобно всю запись целиком. Отдельные поля неудобно, потому что нужно значения вытащить отдельным select и после записать обратно.
Есть еще такая проблема, что в ClickHouse для каждой таблицы должен быть partition key, который дата для каждой. Даже если вам дата не нужна, то все равно её нужно добавить. И есть иногда такое желание положить в эту дату что-нибудь полезное. И если туда класть что-то полезное, то с ReplacingMergeTree это не получится, потому что разные partition не схлопываются.
А если нужно удалять — то еще хуже. Если удалять таблицу нельзя, только если там нулями все перезаписать — а из фактов есть такая штука, как CollapsingMergeTree, и на митапе последнем это подробно объясняли. Это аналог такого банковского «сторно», когда вы добавляете что-то с другим знаком, а потом добавляете запись с правильным знаком. Она, опять же Eventually, то есть когда-нибудь станет правильной. Исправлять можно только метрики, то есть только деньги или только циферки, по-хорошему. И исправляются не данные обычно, а результат агрегации. Данные когда-нибудь, может быть, исправятся, но не обязательно.
Следующее, о чем нужно сказать прежде чем продолжить — это вопросы, связанные с сегментацией и шардингом. У каждой компании разные требования к этому. Например, у Яндекса сразу понятно, что шардинг идет на основании аккаунта или клиента, и там у них очень много пользователей, их можно очень хорошо разбросать по разным серверам. Насколько я помню, они делают двухуровневую систему для этого и все очень удобно.
У нашей компании нет такого, и у компаний типа нашей, которые «рекламные сети» — у них не так много, может быть, клиентов — есть какие-то другие потребности анализа. Однозначно расшардировать не получается и надо придумать какие-то другие способы, чтобы это сделать хорошо, но обязательно об этом нужно думать, потому что от шардинга зависит производительность и загрузки, и запросов.
Дальше в ClickHouse есть такие замечательные штуки, как Replicated таблицы. Когда вы берете одного кролика и кладете его на два разных сервера — у вас получается два кролика. Или на три сервера — тогда у вас получается три кролика. Один сервер упал, второй остался.
Есть такая штука, как Distributed таблица. Когда вы берете кролика и режете его на кусочки (не по-настоящему), раскладываете кусочки по разным серверам. Для того чтобы получить целого кролика — нужно сходить на все сервера, но на каждом маленький кусочек и это как бы быстрее сделать, хотя результат будет одинаковый.
Эти подходы надо комбинировать, то есть у вас есть кролик, и каждый кусочек лежит на нескольких серверах. Вы можете терять и быстро к этому обращаться.
Если все предыдущие знания обобщить, то у вас получится такая ферма FarmVille из ClickHouse, где факты разложены на многих-многих шардах, какие-то шарды реплицируются, поверх них есть Distributed таблица, чтобы из этого читать.
Сами шарды реплицируются как минимум один раз, а лучше два. Таблицы-измерения реплицируются на все узлы, потому что вам нужно фильтровать данные на всех узлах и ходить на все. А некоторые таблицы можно хранить согласованно с фактами — например, на тех самых шардах. Это те, которые прибегают из трафика, потому что они пришли с данными — пусть они и хранятся радом с данными, мы так сохраним локальность и не будет лишней.
И если там все правильно со стороны дизайна — то можно сделать загрузку, которая по share nothing. Концепция сделана и ничего не использует, а лишнее никуда не посылает. И чтобы это получилось, старайтесь не грузить Distributed — режьте кроликов сами на кусочки и складывайте их в нужные шарды. А Distributed только для select.
Кроме того, даже если вам не нужна репликация, лучше использовать Replicated таблицы.
Потому что в этом случае работает ZooKeeper, а он считает чек-суммы блоков. Если у вас что-нибудь сломается посередине, а транзакций нет и вы не знаете, что у вас записалось, а что нет — ZooKeeper (если вы попытаетесь, то же самое записать) по чек-суммам сравнит и запишет те блоки, которые еще не записались, с его точки зрения. Это дает какие-то ложные ощущения Consistency. И временные/промежуточные таблицы тоже всегда помогают.
Можно в промежуточные таблицы записать много маленьких кусочков данных, потом их объединить и записать в большую. Или записать во временную таблицу, проделать какие-то манипуляции, добавить какие-то словари, join, что-то с данными сделать и записать в основную таблицу. Если все это правильно сделать, то загрузка получается очень быстро. У нас получилось быстрее, чем Vertica, однозначно, не сильно быстрее, но все же.
Другой больной вопрос, который станет перед тем, кто пытается что-то перевести на ClickHouse — это агрегация.
Что это такое
Если у вас есть пачка морковки, то можно взять одну морковку, написать число 10 и сказать, что это новая морковка такая. При этом она не будет такая же, как те — она будет не просто морковкой, она потеряет индивидуальность. Яндекс считает, что агрегация вообще не нужна именно потому, что вы теряете детали, лучше храните всё и всегда.
Но считая так, тем не менее, не все в Яндексе придерживаются этого мнения, потому что в ClickHouse есть средства, которые делают агрегацию именно средствами самого ClickHouse – это Aggregated и SummingMergeTree, которые работают как таблица, в которой вы делаете insert, а на выходе она на самом деле агрегирует то, что вы уже вставили и хранит сагрегированные и сжатые данные.
Что самое приятное — если вы пойдете по этому пути, то можно этот Aggregated и SummingMergeTree сделать как MV поверх фактов. И вы вроде как вставляете факты, а у вас в сторонке, магическим образом, появляется агрегат. С ним тоже могут быть всякие проблемы и сложности, о которых я здесь не буду говорить, но тем не менее — это работающее решение и может быть оно кому-то поможет.
Потом мы добрались до доступа к данным. Сразу много интересной специфики, которой в других базах данных не найдете. Это массивы и функции высших порядков для работы с ними, или ARRAY JOIN, который массив разворачивает в строчки. Достаточно необычные переобозначения для select-выражений. В любом месте можно поставить alias для выражения или для колонки и его можно использовать, не обязательно в having — можно использовать дальше в той же select строке. Иногда это удобно, но иногда это приводит к ошибкам, которые очень тяжело отловить, особенно если использовать имя, которое уже где-то используется.
Интересная специфика, которая связана с join, совершенно не SQL, совершенно не стандартная. Поскольку ClickHouse никогда не гарантирует по primary key. Чтобы с этим делом справиться они придумали такую штуку, как ANY vs ALL JOIN.
Что это?
ALL JOIN возвращает все, что подходит под JOIN условия с той стороны, а ANY возвращает одну запись — первую, которая попадет. Тем самым, если у вас идут неуникальные записи в таблицах, которые вы join, вам это не страшно — вы получите максимум одну.
Есть интересная специфика, связанная уже с распределенными вещами это PREWHERE vs WHERE. Одна выполняется на шардах, другая после шардов.
GLOBAL IN, GLOBAL JOIN — это из того, что нам понравилось. И приблизительные вычисления – это семплинг или вероятностные модели, о которых Виктор говорил, тоже для многих случаев, когда очень большой массив данных и нам нужна точность, это можно использовать.
Но это все хорошее.
Теперь боль. Чего нет в этом диалекте SQL, который иногда даже SQL назвать очень сложно, но очень хочется.
Это авто-приведение типов, я об этом буду повторять очень много раз. Переобозначение alias для таблиц — это понятно почему, потому что свой синтаксис для JOIN. Можно сделать один раз JOIN таблицу, то есть select таблицы JOIN один раз, два раза уже нельзя, работать уже не будет. Поэтому переобозначение и не нужно.
Чтобы сделать два JOIN нужно делать под-select и делать второй раз, я потом покажу. И JOIN поддерживает только using — это значит, что у вас колонка должна называться одинаково с обоих сторон и тип у нее должен быть одинаковый. Если тип разный, то придётся опять делать под-select, приводить тип или переименовывать.
Нет такой полезной штуки в SQL, как group by/order by 1,2,3… Если аналитик, которому удобно и быстро работать с ClickHouse работает и меняет измерения, по которым он хочет делать slicing and dicing, так они это называют. Когда он поменяет измерение в select, ему придётся бежать в group by, там тоже переименовывать в order by. С другими базами данных это очень удобно, когда написал order by 1,2,3… ты уже не паришься, какие у тебя там колонки есть, которые ты анализируешь.
Нет nulls и нет coalesce, жутко полезная функция и я не знаю, как люди без нее живут.
И еще — из-за чего нам было больно несколько, так это то, что через JDBC и HTTP интерфейс нет временных таблиц, потому что нет сессии. Яндекс обещает это как-то тем или иным способом поправить, а пока что приходится использовать постоянные таблицы и следить за тем, чтобы они вовремя удалялись, что не всегда просто.
Соответственно мы придумываем различные костыли. То есть переводим типы явно, оборачиваем join. Вот если вы делаете join не двух таблиц, трех или четырех, то эта конструкция растет и растет. И на каждый под-select у вас расходуется память — если к большой таблице нужно присоединить много маленьких, то чтобы понять, сколько памяти нужно, то вот эту большую таблице после каких-то where условий в каждый join она перетекает, расходуя и расходуя память. Не очень удобно. Поэтому словари!
Вот замечательно, как можно переписать coalesce, если nulls заменить на нули через функцию высоких порядков arrayFilter. Это мой любимый пример. Что здесь сразу удивляет разработчиков и надеюсь вас тоже удивило — то, что массивы нумеруются, начиная с 1, а не с 0. Бывает и так.
И следующее — не знаю боль это или не боль, а администрирование
Администрирование ClickHouse выглядит примерно так:

Это набор «умелые руки» или «сделай сам». То есть у вас есть всё — можно собрать, что угодно.
Все очень-очень гибко и очень-очень вручную. И одна из основных болей, это то, что любые DDL операции (alter table или что-то еще), вам нужно выполнять на всех узлах. На каждый узел зайти и сделать create table или alter table, если про какой-то узел забудете, то при каком-то запросе это может упасть.
Есть ZooKeeper. У него свои понятия о таблицах. На самом деле реплицированные таблицы имеют имя в ClickHouse, и у них есть имя в ZooKeeper. Когда вы переименовываете таблицу — она переименовывается только в ClickHouse, в ZooKeeper она не переименовывается. И это может приводить к очень интересным открытиям. Например, если вы хотите таблицу переименовать, создать новую на том же месте, с какой-то другой структурой и скопировать данные, это у вас в лоб не получится, потому что в ZooKeeper имена остались старые.
Предыдущий доклад был озаглавлен «Яндекс — это очень быстро и удобно», но на наш взгляд не удобно, хоть и очень быстро. Но, тем не менее можно переехать на ClickHouse, если вам очень нужно. И в первую очередь нужно разобраться в функциональности и ограничениях, то есть понять куда мы едем и на чем.
Очень важно угадать Yandex Way (название наше) — это тот use case, который Яндекс рассматривал, когда строил свою систему. Это метрика, как она работает и понимая дорогу Яндекса, можно либо по ней идти, либо мостить свою дорогу и понимать, что вы делаете свою дорогу, а вам никто ничего не гарантирует.
Например, первая вещь, на которую мы наткнулись в ClickHouse, когда начали её использовать — там не поддерживались отрицательные ключи, то есть таблицу составляете -1 и получаете ошибку. Быстро пофиксили этот баг. То есть у Яндекса не было отрицательных ключей, а у кого-то появились.
И понятно, что у Яндекса скорее всего unit test покрыто то, что им нужно чтоб регрессии не было, а то, что вам нужно — никто не гарантирует и приходится проверять.
Приходится пробовать, не нужно стеснятся пробовать и спрашивать дорогу у Алексея и у Виктора на форуме, я описал наш путь.
Можно подумать, что я ругаюсь на Яндекс. Но ни в коем случае — я на самом деле испытываю к ним огромную благодарность, они сделали отличный проект и то, что в нем какие-то вещи не работают — они не работают для нас и для компаний, которые пытаются с RDBMS переехать. Для кого-то они работают с одной стороны, а другой стороны они очень хотели обратную связь от сообщества — и вот они его таким образом получают, чтобы понять, в какую сторону развивать продукт.
В конце дороги всех ждет изумрудный город, очень быстрый, очень хороший. Действительно ClickHouse здорово работает.
У меня все.
Доклад: Переезжаем на Yandex ClickHouse.
