
На конференции HighLoad++ 2016 Олег Облеухов рассказал о не требующей при росте нагрузки вмешательства администратора архитектуре, которую он спланировал и внедрил в компании InnoGames.
Всем привет. Буквально пару слов обо мне. Меня зовут Олег, до этого я работал в компании «Яндекс», жил в замечательном городе Санкт-Петербурге. Сейчас я переехал в Германию и работаю в InnoGames. Компания занимается разработкой онлайн-игр. На счету 150 миллионов пользователей — достаточно большая компания, ну поменьше, чем «Яндекс», конечно. И сегодня мы поговорим с вами о том, как сделать высоконагруженный сервис без данных о нагрузке, не зная её количество.
Прежде чем мы начнем. Теперь вы все знаете обо мне, я хотел бы узнать немножко об аудитории. Поднимите руку те, кто использует Docker на продакшне? Ну треть зала примерно, хорошо. А теперь из тех, кто поднял руку, поднимите те, кто доволен использованием Docker на продакшне? Значительно меньше. А теперь ещё более сложный вопрос. Те, кто доволен использованием Docker на продакшне, поднимите руку те, кто сисадмин или инженер, или еще кто-то не-разработчик. Я вижу троих. Окей.
На самом деле мы не будем сегодня разговаривать о Docker. Но мы будем разговаривать о CRM. Я вам расскажу, что это такое, зачем нам нужна эта система.

Как вы видите на экране, это скриншот с одной из наших самых популярных игр — Forge of Empires, может, кто даже слышал. Примерно вот так она выглядит. Когда игрок играет в Forge of Empires, любые действия этого игрока (например, «построить здание» или просто «кликнуть на оплату» каких-то дополнительных денег, внутренней валюты) отправляются в наше хранилище. Все эти действия записываются. За некоторое время в нашем хранилище (это Hadoop, разумеется) накопилось примерно 400 миллиардов таких событий, всех кликов всех пользователей. Это в дисковом эквиваленте 25 терабайт, не считая реплика-факторов и всего прочего.
Зачем нам нужны эти данные? Мы можем построить шаблоны поведения пользователя по этим данным. У нас есть специальная группа менеджеров, которые занимаются ничем другим, как объявляют каким пользователям с каким поведением мы сегодня выдаём какую-то скидку. Это так называемые Near-Time campaign, или внутренняя реклама.

Выглядит она примерно вот так. Вы можете видеть, что, например, если вы закрыли платежное окно, вы тут же получите баннер «вообще, как бы заплати сейчас, и ты получишь на 40 % больше внутренней валюты». Конечно, там есть и другие шаблоны поведения. Например, если пользователь ведет себя так, будто он скоро покинет игру: он заходит реже, меньше действий совершает в игре. Терять пользователей — плохо: достаточно часто мы платим за то, чтобы пользователи приходили. Нам нужно удерживать этих пользователей.
Зачем нужна эта система? Почему бы просто не дать пользователям играть и не разрешить платить, когда они хотят?
Ну разумеется, ради денег. Этот сервис работает не так давно, около года. Мы по статистике подтвердили, что в два, а то и больше раз увеличился доход просто за счёт того, что мы показываем пользователю: «Эй, товарищ, заплати-ка, мы тебе просто в больше дадим бриллиантов, если ты это сделаешь!» И пользователь охотнее платит.
Ну и второе, очень приятное свойство — это то, что мы задерживаем пользователей в игре. То есть если пользователь ведет себя так, будто он хочет покинуть игру, мы ему говорим: «Не, не, не, останься, мы тебе бесплатно надаем бонусов. Может, даже не со скидкой, а бесплатно полностью. Пожалуйста, только вот останься!» Разумеется, каждый пользователь нам очень важен.
Ну и очень-очень важное свойство — это привлечение новых игроков. Если пользователь остался доволен, он такой счастливый, получил свою скидку либо вообще бесплатные бриллианты, он скажет: «Играй в Forge of Empires. Это же так здорово, там можно получать бесплатные бриллианты. Только тебе нужно определенные действия совершить, тогда и будет».
Как я уже упомянул, примерно год назад я получил задачу сформировать архитектуру вот этого сервиса. На тот момент для меня это было чёрным ящиком. Мне просто сказали: «Олег, у нас есть три наших самых популярных игры». У нас было больше, но это самые популярные — Forge of Empires, Elvenar и Grepolis. Все эти игры уже на тот момент отправляли события в Hadoop, вот те самые клики ваши, если кто играет. В общем, все эти клики попадают в Hadoop и их примерно 500 миллионов в день. Это немаленькое количество.
Так вот, нужно было написать какую-то систему, сформировать её, сделать архитектуру, которая вытаскивала бы эти события, как-то их отфильтровывала, смотрела, дополняла и отправляла бы уже в игру, чтобы предоставить пользователю скидку.

Примерно так это выглядит.
Один из самых важных критериев — это то, что мы должны доставить это сообщение, эту скидку, настолько быстро, насколько это возможно. Например, пользователь закрыл платежное окно, он еще тёпленький, он думает ещё: «Эх, хотел купить, но дорого что-то». А мы ему бац — скидку. Здорово? Здорово! Это был один из критериев.
Какие вопросы возникли у меня как у инженера, когда мне сказали, что нужно сделать эту систему?
- Какая должна быть архитектура у этой системы? Потому что кода не было, ничего не было, не существовало. Мы думали с разработчиками, как это всё сделать.
- Должна ли быть надежность? То есть, скорость доставки очень важна. Но если это в субботу вечером сломается, нужно ли бежать чинить? Или можно оставить это всё до понедельника и спать спокойно, ничего страшного?
- И самый главный вопрос: какое количество нагрузки должна эта система принимать? Как вы помните, у нас постоянный поток событий — 500 миллионов в день. Но какое количество из них мы должны на себя брать и обрабатывать, проводить через нашу систему и выдавать в игры?
Архитектура
Давайте немного нырнем в архитектуру сервиса, который у нас получился.
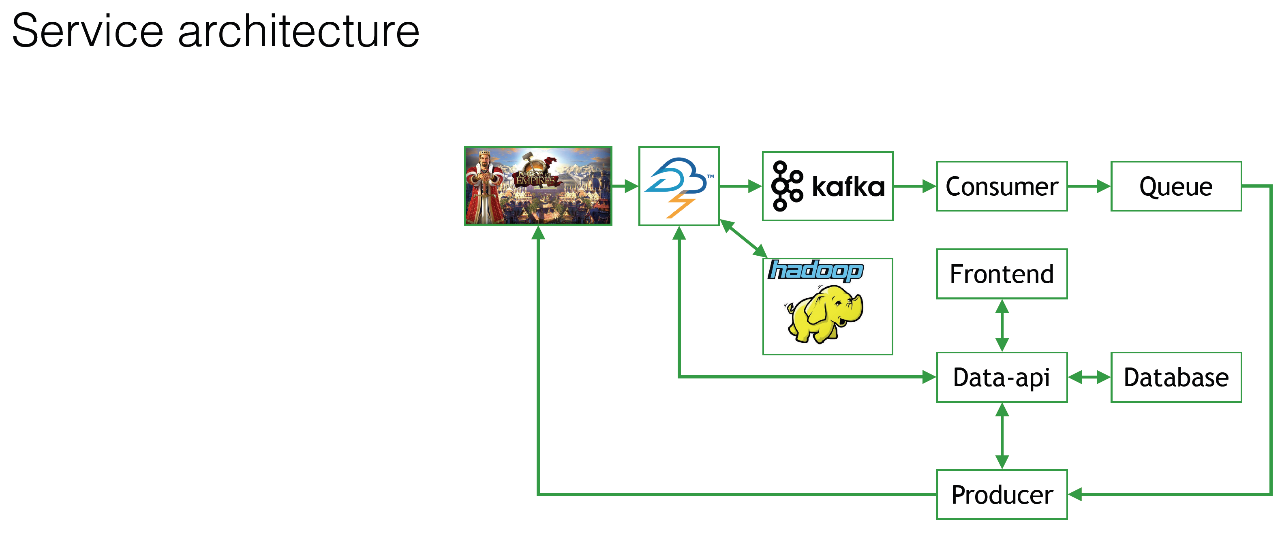
Мелкое лого, которое не очень хорошо видно, — это Forge of Empires, одна из наших самых популярных игр. Эта игра и еще несколько других оправляют все 500 миллионов событий в Apache Storm. Многие из вас знают, что это такое — объяснять не буду.
На CRM, на нашей стороне, есть так называемый Frontend, в котором те самые менеджеры сидят и говорят: «А давайте-ка мы сегодня всем, кто хотя бы 30 минут играет запилим какую-то скидку? Просто потому что мы такие добрые». Они работают с этим Frontend. В базу данных записываются все данные о том, что с таким-то шаблоном, такую-то скидку, баннер будет выглядеть вот так. Всё это сохраняется в БД. То есть нужна какая-то база данных.
Те данные, которые будут отфильтрованы, которые нам интересны, попадут из Apache Storm в Kafka на нашу сторону, в нашу систему. Разумеется, всё это без исключения летит в Hadoop. Просто чтоб было, как говорится. Чтобы мы могли потом воспользоваться этими данными.
Затем на стороне нашего сервиса есть так называемый потребитель (Consumer), который вычитывает эти данные из Kafka и как-то их фильтрует, может, дополняет, как-то обобщает, смотрит на поведение и запихивает всё в очередь. Это все сделано для надежности. Далее у нас стоит Producer, который сверяется с базой данных, дополняет events, добавляет туда баннеры, что-то оттуда удаляет и отправляет это всё в игры.
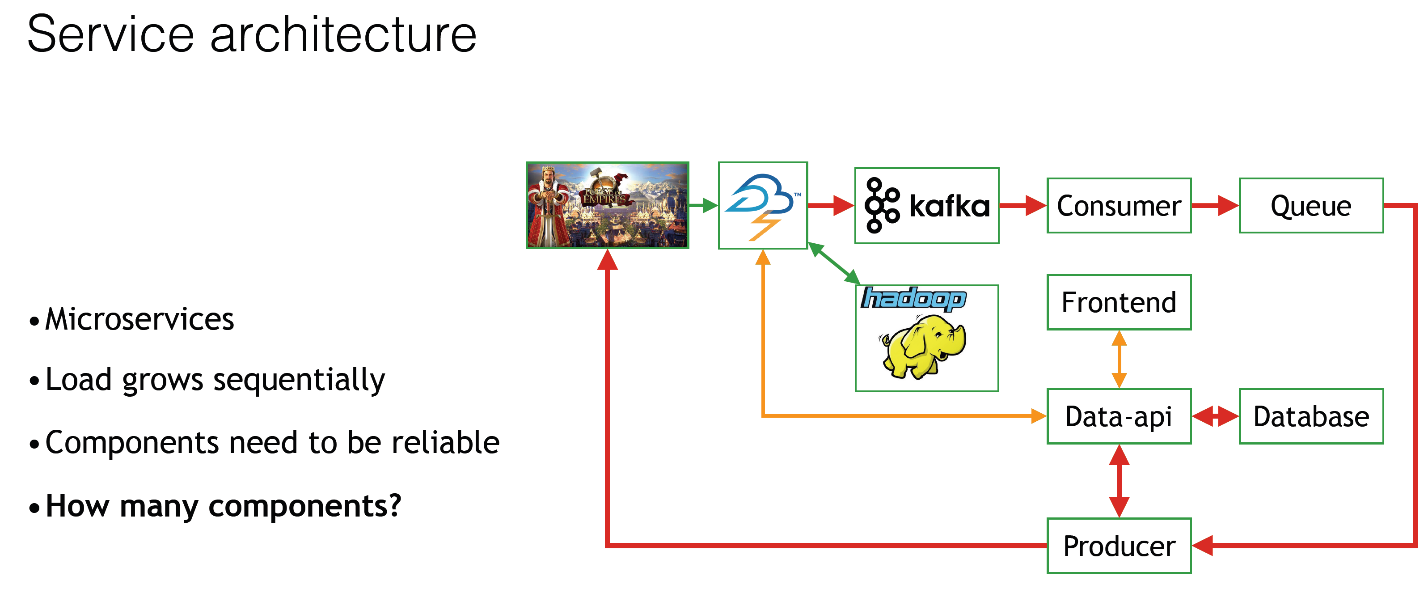
Что мы видим даже на этой картинке?
- Мы используем микросервисы. У нас на самом деле много-много маленьких компонентов. Они здесь не все представлены, но это общая картинка, чтоб было понятно.
- Нагрузка растет последовательно. Сегодня менеджер в хорошем настроении, и он говорит: «А давайте-ка мы вообще всем пользователям дадим скидку? Всем, кто онлайн, всем нескольким миллионам, десяткам миллионов пользователей, кто прямо сейчас играет, мы дадим им всем скидку?» Естественно, у нас из Apache Storm увеличится поток данных в Kafka, и из Kafka это уже пойдёт на сторону нашей системы, далее на каждый-каждый компонент нашей системы, сильно увеличится нагрузка.
Если к нам придут все 500 миллионов событий, у нас будет все супер-сильно нагружено. Менеджер в плохом настроении, и он говорит: «Я не хочу никому сегодня скидку давать, меня все задолбали вообще». Нагрузки соответственно не будет вообще, сервера будут вообще ничего не делать.
- Компоненты должны быть супер-надежны. Если, например, посреди ночи сломается потребитель из Kafka, то это всё застопорится, Kafka переполнится, потеряем кучу данных. В общем будет очень печально, нам потом придётся это все руками восстанавливать.
- Ну и какое собственно количество компонентов должно быть? Хороший вопрос, да? Потому что непонятно, в какой момент на какой компонент придёт большее количество нагрузки.
У кого в зале появилась идея, почему бы не стартануть 100 виртуальных машин и держать их все время запущенными? Просто на всякий случай жизни, если придёт нагрузка — мы их все проглотим, если нет — будут стоять и ничего не делать. У кого-то есть такая идея? Потому что на самом деле здравая идея. Вот один человек здравый сидит.
Как я уже упомянул, компания находится в Германии. Может это не так сильно актуально для России, но мы платим за электричество. У нас собственный дата-центр. Если вы сделаете измерения, то вы увидите, что любая виртуальная машина, пустая, без какой-либо полезной нагрузки, которая не делает абсолютно ничего, потребляет 12 ватт электричества. Просто потому, что она запущена. Это один график измерений. Я сделал таких кучу — поверьте мне на слово.
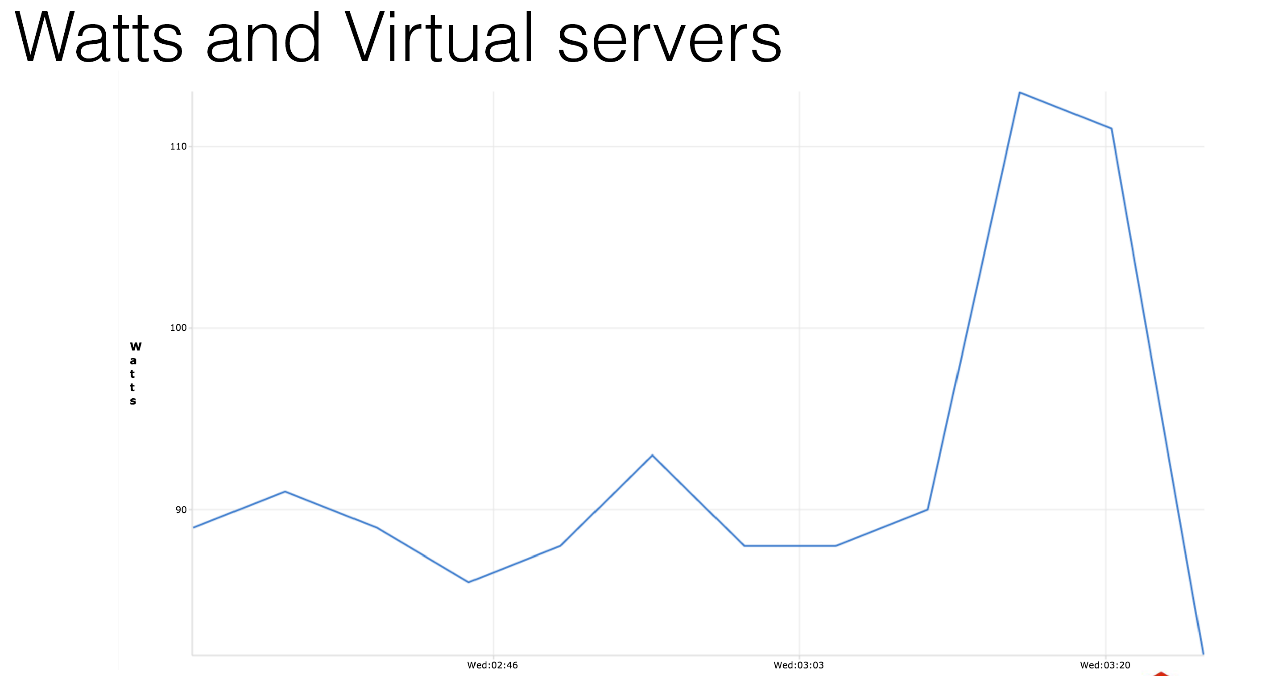
Оно вам надо? Вы запустите 100 виртуальных серверов, они будут у вас работать и потреблять сотню евро в месяц просто за то, что они ничего не делают, вообще ничего. А может быть у вас побольше система? 1000 серверов, выглядеть это будет примерно вот так вот.

Мы просто греем воздух в датацентре. Зачем нам это нужно, правда?
Что же мы можем тут сделать? Как бы выйти из такой ситуации? Правильно! Мы используем autoscaling! Почему бы и нет?
Когда система ничего не делает (например, наши менеджеры решили, что они сегодня вредные и не дадут никому никаких скидок), то мы поддерживаем только минимальную, необходимую высокую доступность. У нас запущено по два компонента, все по-минимуму.
Многие компании так делают. Я уж не говорю про то, что там есть Amazon-решение для этого и прочее. Даже Facebook так делает. Они недавно опубликовали статью о том, как они физически выключают жесткие диски, например. Многие компании пытаются таким образом сэкономить на электричестве или просто на ресурсах, чтобы не жечь сервера в пустую.
Если нам понадобится, если придёт нагрузка, почему бы нам не запустить пару дополнительных инстансов, вот тех самых компонентов? Потребителя событий из Kafka мы просто запустим, и всё будет хорошо. А если и этого недостаточно: запустили кучу компонентов, но у нас не хватает виртуальных машин? Давайте добавим виртуальные машины, в чем проблема — это тоже не очень сложно.
Ну и как приятный бонус. Системные администраторы и инженеры меня поймут — система сама себя лечит. Если у вас по какой-то причине умерли все компоненты одного из видов, система стартанет эти компоненты; если надо, запустит сервера. Избавит вас от бессонной ночи, может, ссоры с женой или других проблем, которые могут возникнуть от работ по ночам.
Истоки
Чтобы понять, как работает наш autoscaling, нужно обратиться к истокам и понять, что у нас было на тот момент.
У нас были (и сейчас есть) три дата-центра. У нас тысячи виртуальных машин и сотни машинок-гипервизоров. В основном мы используем их для виртуальных машин. Мы только что закончили миграцию с Xen на KVM, по большей части из-за живой миграции.
Мы достаточно современная компания. Мы тестируем разные cloud-решения. Забегая вперёд, я скажу, что они все намного более дорогие, чем использование своих собственных дата-центров. Я уж молчу про то, что если у вас сломается autoscaling, и запустятся 1000 виртуальных машин в Amazon, вы вообще разоритесь, и никакие CRM-скидки вам не помогут.
Мы используем Docker, даже используем его на продакшне. Но я не поднимал руку, я им не очень доволен. По большей части он нам не подошёл, у него отсутствует живая миграция. Зачем она нужна я расскажу вам попозже.
У нас на тот момент уже было своё облачное решение. На самом деле ничего особенного, просто написанный на Python веб-интерфейс, потом расскажу о нем.
У нас используются достаточно примитивные Open Source решения: Graphite, Puppet, Nagios — всем известные вещи. Но у нас есть одна изюминка: наш коллега, написанный на Python — системный администратор, которого зовут BrassMonkey.
Итак, нам нужно как-то балансировать нагрузку на все наши сервисы. Вы помните, что у нас куча компонентов, может появиться ещё 10 тысяч новых. И мы всё равно должны активно балансировать на них нагрузку. Если мы подняли новый, мы балансируем на него моментально.
Как вы видите, у нас есть несколько хостов, на каждом из них запущено какое-то количество микросервисов, и для каждого из этих микросервисов на интерфейсе loopback у нас есть публичный IP адрес.
Мы осуществляем балансировку нагрузки при помощи FreeBSD и packet filter. Файервол, условно говоря, умеет балансировать нагрузку. Это работает достаточно просто. У нас есть наш hardware load balancer, на нём подняты виртуальные load balancer с теми же самыми IP. Из Интернета приходит нагрузка, и всё это благополучно отправляется на сервера, на компоненты.
Но что случится, если сервис N хочет подключиться к сервису 1?

На слайде видно: Linux по умолчанию будет вам предлагать использовать самый короткий путь, то есть напрямую, через локальный сетевой стек. Что случится, если сервис 1 умрет? Разумеется, у нас разорвётся вся эта связь. Сервис N никогда об этом не узнает. Ничего не будет работать, а вы не будете понимать, почему, пока не полезете в логи.
Чтобы решить эту проблему, мы просто сделали маленький хак. Мы отправляем вообще весь трафик, который имеет отношение к этому IP, всегда наружу. Это немного замедляет, но сервера стоят в одной и той же стойке. В большинстве случаев виртуальные машины работают на тех же самых гипервизорах. Это не так сложно и страшно.
Сделать это очень просто, не нужно никаких магий. Когда вы добавляете любой IP на хост, в Linux у вас по умолчанию добавляется маршрут в локальную таблицу маршрутизации «на этот IP всегда отправляем трафик локально. Этот маршрут просто нужно удалить и добавить свою таблицу и сказать: «А иди-ка ты всегда через внешний интерфейс». И всё. Это всё, что нужно для того, чтобы отправлять трафик наружу. У вас всегда были health check, вы всегда знали, в каком состоянии ваш сервис, и если что-то сломалось, вам всегда будет легко перебалансировать на другой хост. Никаких проблем.
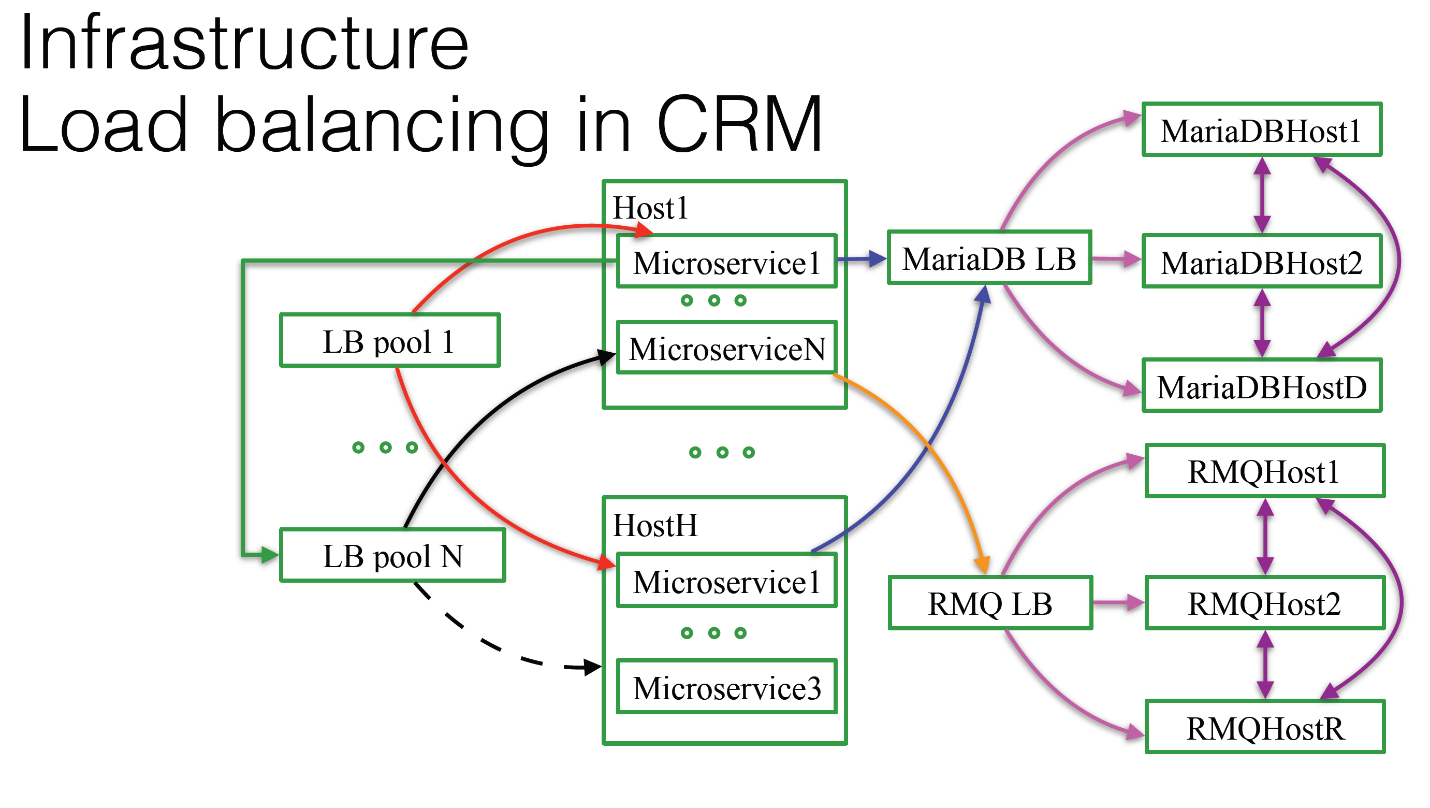
У нас используется эта балансировка нагрузки в нашем CRM, у нас есть много хостов, на них запущены микросервисы. Как вы видите, на каждом хосте необязательно должен быть полный набор всех возможных микросервисов. Это могут быть совершенно разные, какое-то их количество. И у нас перед ними собраны балансировщики нагрузки. Всё это благополучно балансируется.
Что произойдет, если LB pool собран, load balancer собран над хостом Н, где нет микросервиса N? У нас не будет туда балансироваться нагрузка, пока он там не появится. Всё очень просто и тривиально. А если мы захотим подключиться напрямую, мы не будем подключаться, мы подключимся через load balancer, как мы это обсуждали выше.
Load balancers у нас собраны практически везде. У нас есть база данных, о которой мы уже говорили. В этом случае мы используем MariaDB, у нас есть Galera-кластер, полностью синхронный. С ним очень удобно работать системным администраторам. Большой нагрузки на нем нет, пусть работает. Нагрузка на него балансируется точно таким же образом. Мы в любой момент можем выкинуть хост и добавить обратно, если, например, нам нужно больше нагрузки.
Компоненты подключаются напрямую через балансировщик нагрузки. Точно такая же система у нас собрана для той самой очереди, которую вы видели. Мы используем RabbitMQ.
Autoscaling
Мы с вами уже подготовлены и знаем абсолютно все про архитектуру CRM, давайте поговорим об autoscaling.
У нас есть гипервизор, у нас их много, на каждом из них запущено много виртуальных машин. На каждом виртуальном хосте у нас запущено много микросервисов. Нам каким-то образом нужно оправлять данные об использовании процессора и памяти.
Мы отправляем их в Graphite. Но поскольку Graphite может быть ненадежным, приходится его иногда перезагружать или ещё делать ещё что-то нехорошее. Вам нужно, чтобы autoscaling работал достаточно надежно, поэтому вам нужно, чтобы метрики всегда доезжали в Graphite, иначе у вас система сойдёт с ума. Проходили, знаем.
Для этого нам нужен специальный клиент Grafsy, вы можете найти его на GitHub. Этот Grafsy отправляет все метрики в Graphite надежно.
Поговорим о Graphite. Мы используем Grafana, как и все в этом зале — никто не использует Graphite просто так. Вот интересные детали об использовании Graphite.

Мы используем его как стену позора. Тут у нас есть каждый системный администратор нашей компании. Мы показываем, сколько у человека проблем в нашей мониторинговой системе. Это на самом деле помогает поддерживать чистоту и порядок. Мы просто отправляем эти данные туда, и все это видят. Если что: «Эй, иди почини!»
Если говорить о Graphite, у нас всего 2 хоста, но они довольно большие. У нас примерно 400 гигабайт оперативной памяти на них. Мы используем Whisper. Почему Whisper? Все знают, что это достаточно старая файловая база данных. Мы используем её потому, что у нас достаточно большая нагрузка на ней. Это 50 тысяч (а то и больше) метрик в секунду, что немало. Мы пытались мигрировать на ClickHouse или Cassandra, но это всё не так безоблачно, как говорят. Работает оно примерно в 2 раза медленнее, чем на Whisper.
У нас используется клиент Grafsy, который запущен на каждом без исключения виртуальном хосте. Он получает метрики в себя. Если Graphite по какой-то причине недоступен, мы переотправим все эти метрики чуть-чуть попозже. Суть этого клиента очень простая. Он очень легкий — занимает буквально 2 мегабайта в памяти — и работает на всех серверах. Он обладает гораздо большей функциональностью. Можете посмотреть на GitHub.
У нас также используется специальный notifier, поскольку в веб-интерфейсе Grafana что-то обещают сделать, но ещё не сделали. Они обещали нам уже давно, что если что-то меняется на графиках в Grafana, то мы будем об это уведомлены. Но это всё ещё не сделано. Если у нас дисковое пространство увеличивается, то мы это можем увидеть только благодаря проверке в нашем мониторинге, но никак не в Graphite. Есть вот такой простой демон, даже скрипт. Он тоже на GitHub. Он уведомит вас и вашу мониторинговую систему. Он достаточно универсальный, может уведомить много разных мониторинговых систем.
Мы собираем статистику с помощью IGCcollect. Это IG образовано от InnoGames. Его тоже можно найти на GitHub.
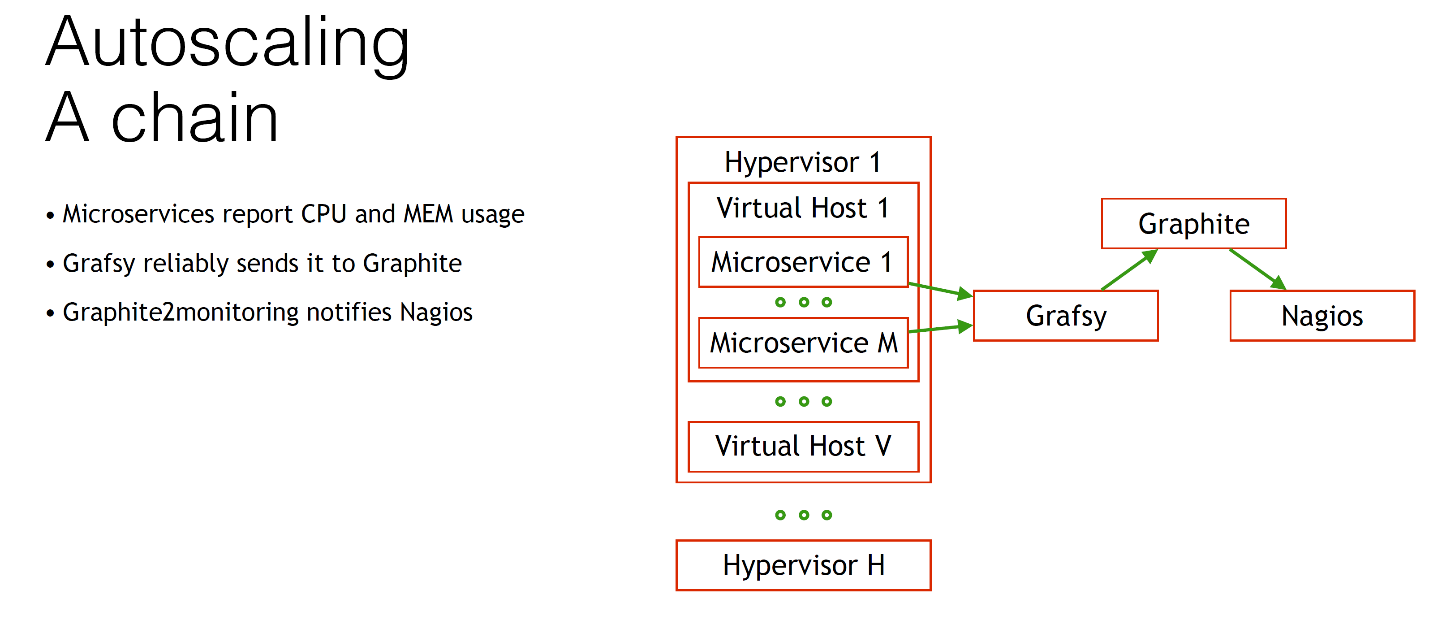
Когда все метрики приехали в Graphite, уведомляется наш Nagios. Если у нас увеличивается количество потребления процессора, мы уведомляем об этом Nagios при помощи того самого notifier.
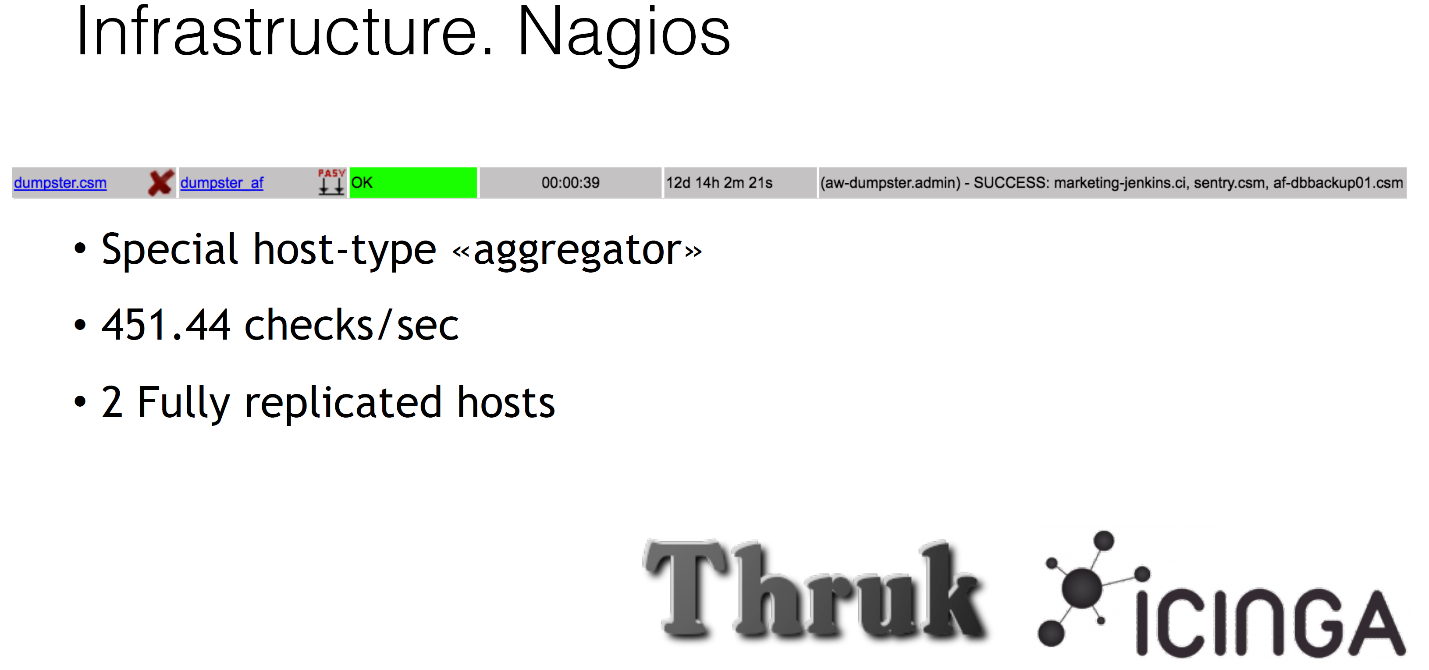
Пару слов о нашем Nagios. Все мы используем Icinga и Thruk как веб-интерфейс. Мы также используем Nagios для многих интересных задач, к примеру, фейковые хосты, которые на самом деле не имеют ни IP-адреса, ничего, они просто такие dummy-дурачки какие-то. Они в нашем Nagios, и мы вешаем на них какие-то проверки, например, валидируем бекапы. Мы не просто делаем бекап, мы его потом его еще отдельно где-то распаковываем и уведомляем о том, что всё хорошо. Это называется special host-type «aggregator». В дальнейшем мы его будем использовать для autoscaling.
Nagios у нас тоже достаточно большой: он осуществляет примерно 450 проверок в секунду c одного хоста — у нас 2 хоста в разных датацентрах, одного за глаза хватает, даже запас ещё есть.
Что происходит дальше? После того как Nagios как-то получает информацию, например, о том, что у нас использование процессора каким-то компонентом слишком большое, у нас в дело вступает наш великий и могучий BrassMonkey. Это наш коллега, как я уже упоминал. Наш системный администратор. Давайте немного поговорим о нём. Вот так вот он примерно выглядит.
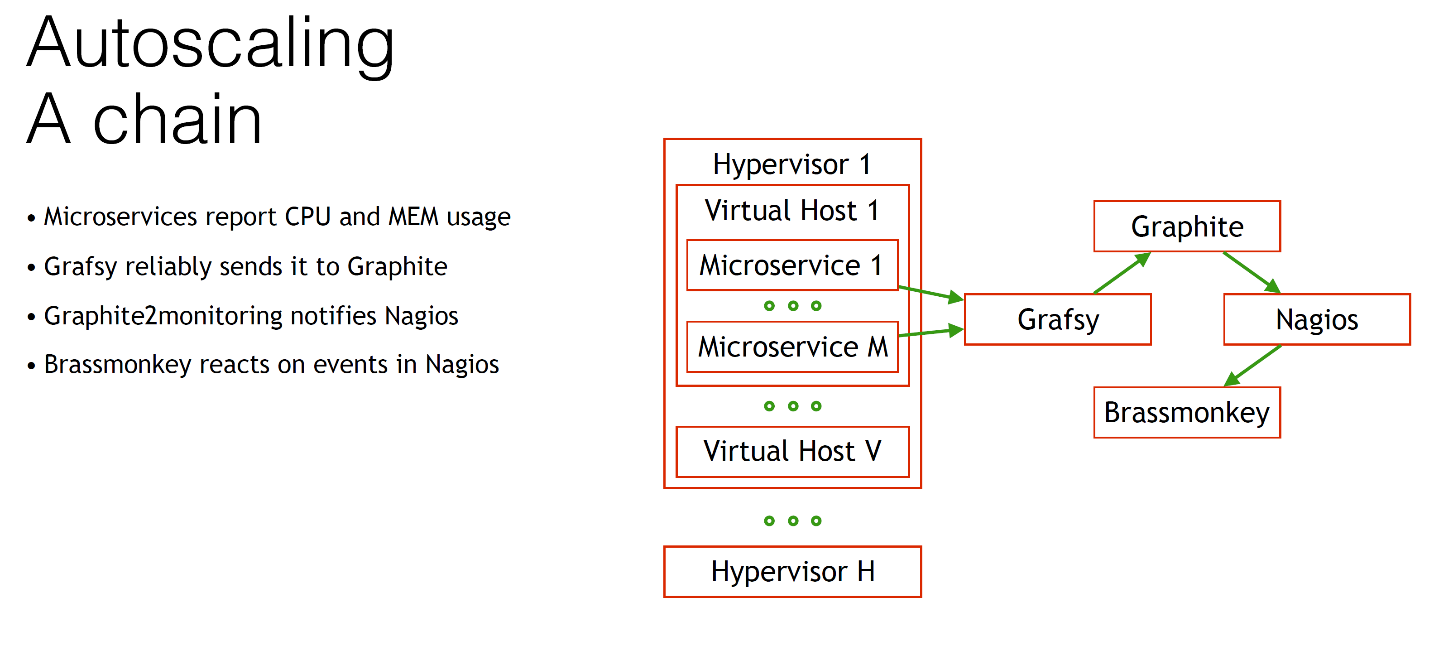
Он уже давно использовался у нас для решения рутинных задач. Например, перезагрузка сервера. Посреди ночи зависла виртуальная машина непонятно по какой причине. Вместо того, чтобы получать звонок, BrassMonkey просто идёт и перезагружает эту виртуальную машину — и никаких проблем.
То же самое происходит с перезапуском демонов, какими-то рутинными задачками. Алгоритм его работы очень простой. Он идет в Nagios и говорит: «Слушай, товарищ, а есть у тебя хоть что-нибудь для меня?» Если есть, уведомляем системных администраторов и собственно делаем какие-то действия. Но, естественно, он может сделать гораздо больше: autoscaling!
Когда BrassMonkey вступает в дело, например, он реагирует на какое-то событие уровня увеличения количества потребления процессорного времени, то он соединяется с нашим Serveradmin — это то самое облачное решение, которое я упоминал недавно.

На самом деле этот Serveradmin управляет вообще всем в нашей инфраструктуре. Самое главное, что он может сделать, — это создать новую виртуальную машину без каких-либо проблем, при помощи одной команды или, например, добавить компонент на существующую виртуальную машину. Единственное, что нам нужно — это чтобы BrassMonkey попросил Serveradmin что-то сделать.
Так выглядит наш Serveradmin.

Там гораздо больше атрибутов, но вам незачем их видеть. Самая главная его задача — быть единым источником правды. Все информация, которая в нём, содержит все нашу инфраструктуру. Если есть какой-то хост, то всё про него описано там. В нём всегда должна быть актуальная информация.
Если вы хотите изменить роль хоста, вы меняете Puppet classes прямо там же в атрибутах через веб-интерфейс. То есть вы говорите: «Окей, ты больше не веб-сервер, ты теперь база данных». Просто меняешь один атрибут, и всё готово.
Разумеется, он управляет такими тривиальными вещами, как DNS, он управляет тем, под какими балансировщиками находится наш сервер. И, что самое интересное, он управляет расположением виртуальной машины. Можно зайти в веб-интерфейс, изменить там расположение виртуальной машины. Атрибут называется xen_host — исторически так сложилось, у нас использовался Xen. Вы меняете атрибут, и он автоматически мигрирует вам машину при помощи той самой KVM live migration, без какого-либо downtime вообще. У вас память синхронизируется на лету, шикарно. Ну и разумеется, он управляет такими базовыми вещами, как проверки в Nagios, графики в Graphite.
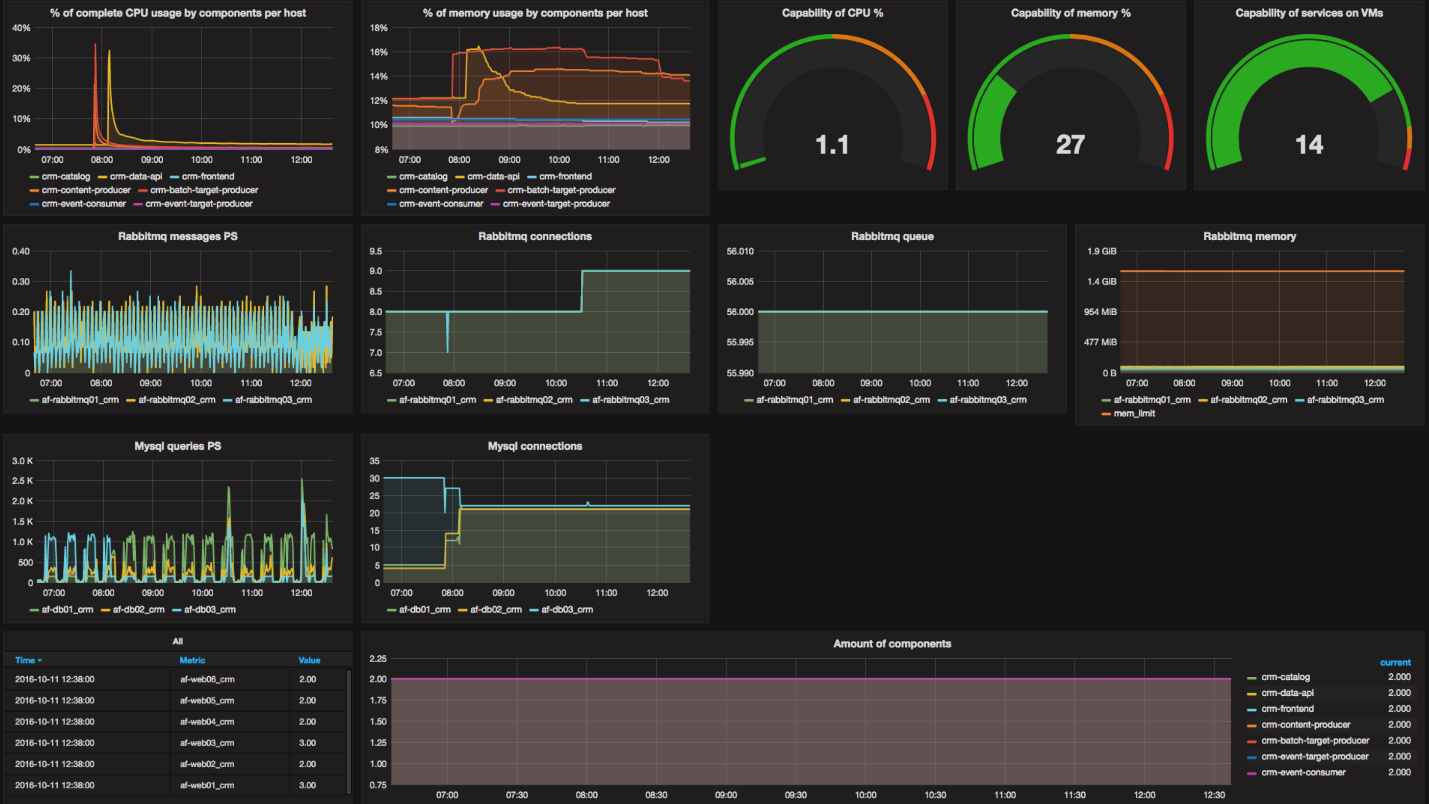
Примерно вот так выглядит наш dashboard по мониторингу того самого autoscaling и нашего CRM. Много графиков, интересные для вас графики — наверху три правых. Они показывают вместимость нашей системы. Вы можете увидеть, что у нас есть использование процессоров (в данный момент вообще не используется процессор), использование памяти и количество слотов на виртуальных машинах, чтобы стартануть компоненты.
Мы её всю мониторим, это всё отправляется в Graphite, всё это через Nagios, BrassMonkey, всё красиво. Давайте посмотрим, как это все работает. Настоящий пример.
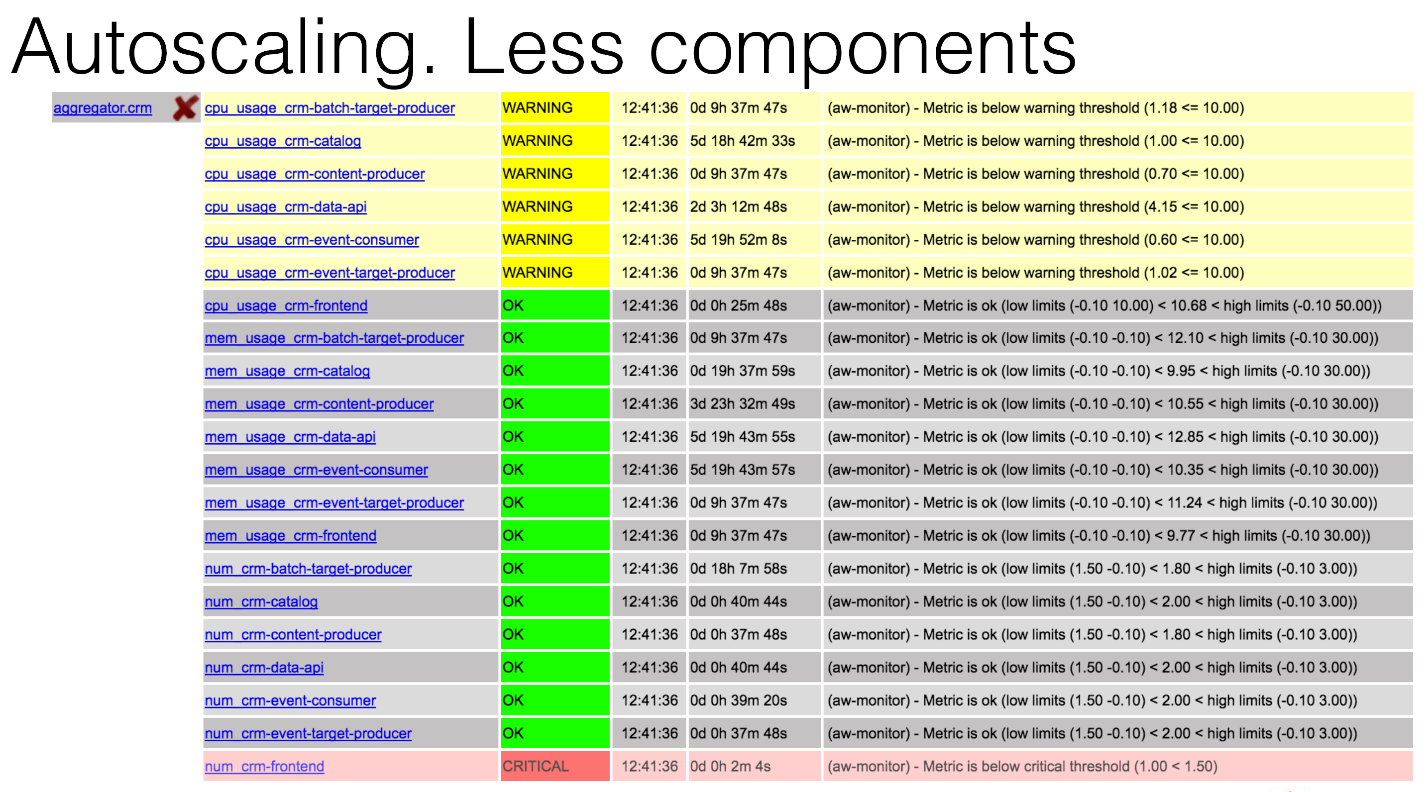
Вот так будет выглядеть aggregator, тот самый виртуальный хост в нашем Nagios, в котором вы можете увидеть, что у вас critical по компоненту CRM-frontend. По какой-то причине один из компонентов умер, может, посреди ночи. Что произойдет?

BrassMonkey вступит в игру, проведёт какой-то анализ и напишет, что он добавил новый компонент на один из хостов, который уже существует, никаких проблем.
Следующий случай. У нас повысилась нагрузка. Нам из Kafka прилетела куча событий, и у нас на CRM-event-consumer увеличилась средняя нагрузка на компоненты примерно на 70%. Это больше критического порога.
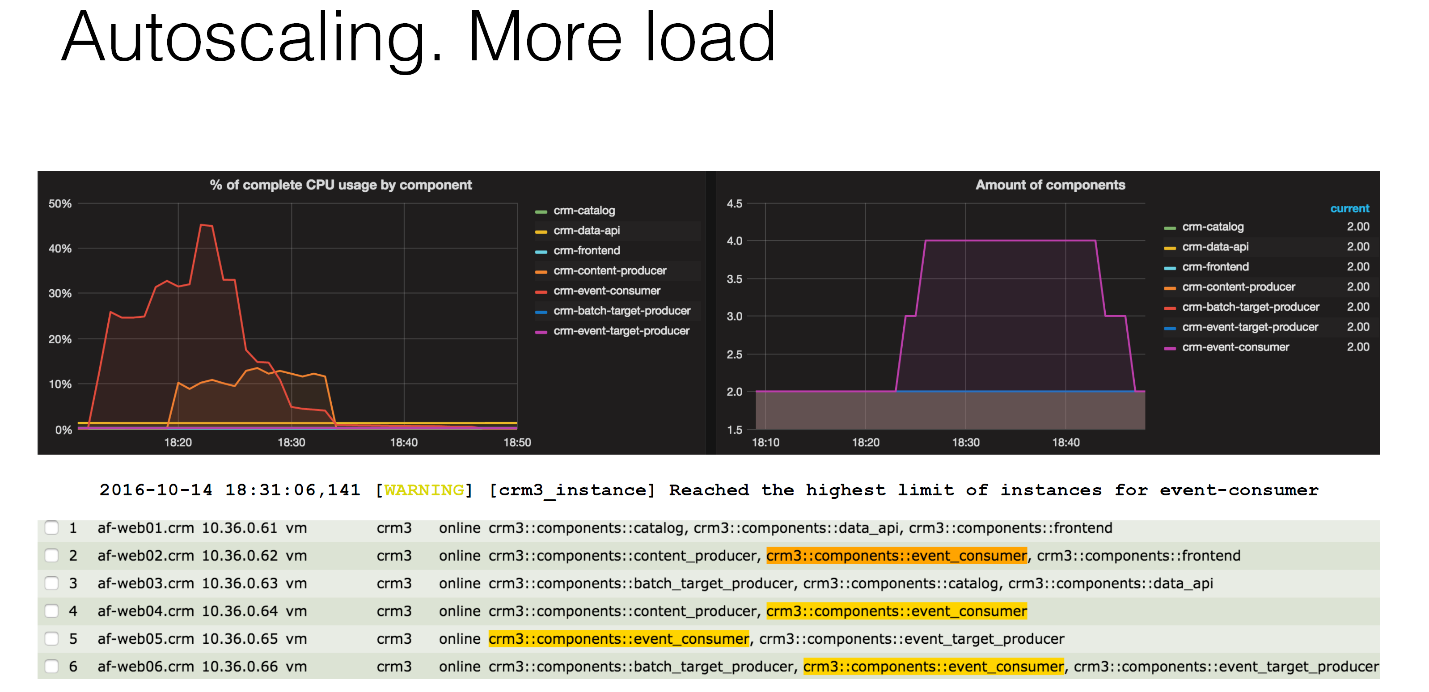
Опять же, мы можем это увидеть на графиках в Graphite. Вы сейчас видите два графика: слева — потребление процессора компонентом на всех виртуальных машинах, справа — количество тех самых компонентов. Вы можете видеть, что примерно в 18:10 у нас сильно начала расти нагрузка, какие-то данные начали прилетать, наши компоненты начали работать. Она оставалась на каком-то приемлемом положении, мы ничего не стали делать. Затем эта нагрузка перевалила критический порог, и примерно в 18:23 у нас был добавлен первый дополнительный компонент. Далее у нас нагрузка продолжает расти, и система добавляет второй компонент. И на этом останавливается, потому что ситуация решена. Нагрузка идет вниз.
Некоторое время понадобилось, мы ещё придерживали те самые компоненты на случай увеличения нагрузки. Это достаточно хорошая практика, Facebook тоже советует. Если почитать статьи, как Netflix делает их autoscaling, они тоже говорят: предсказывай заранее и потом уменьшай количество компонентов медленно. Придерживай их на всякий случай.
Также вы можете видеть на графике потребления процессора, что у нас сначала нагрузка увеличилась на consumer, на потребителе событий, но потом увеличилась на producer. То есть Producer тоже вступил в игру через какое-то время, потому что нам понадобилось фильтрование событий, дополнение их, какая-то магия происходила. Но мы ничего не сделали с producer, потому что он не преодолел наши пороги.
Если вы посмотрите логи BrassMonkey, то вы увидите, что BrassMonkey решил в какой-то момент остановиться, потому что у каждого компонента есть свои лимиты того, сколько он нам нужен. Нам нужно потреблять намного больше процессоров этом компоненте, в другом нужно больше памяти, в третьем — больше диска.
У нас есть какие-то лимиты, чтобы система не сошла с ума, чтобы мы с утра не проснулись, и там не было проблем. У нас была такая ситуация, когда наш BrassMonkey работал для увеличения диска на виртуальной машине. Виртуальная машина по умолчанию занимала 10 гигабайт. С утра мы проснулись, а она была 400 гигабайт. Это было очень неприятно, потому что XFS легко увеличивается, но совсем не уменьшается.
Если вы посмотрите в наш любимый Serveradmin, вы увидите, что те самые атрибутах, которые Puppet classes, которыми в том числе управляет наш Serveradmin, — это тоже 4 компонента. Мы не врем.

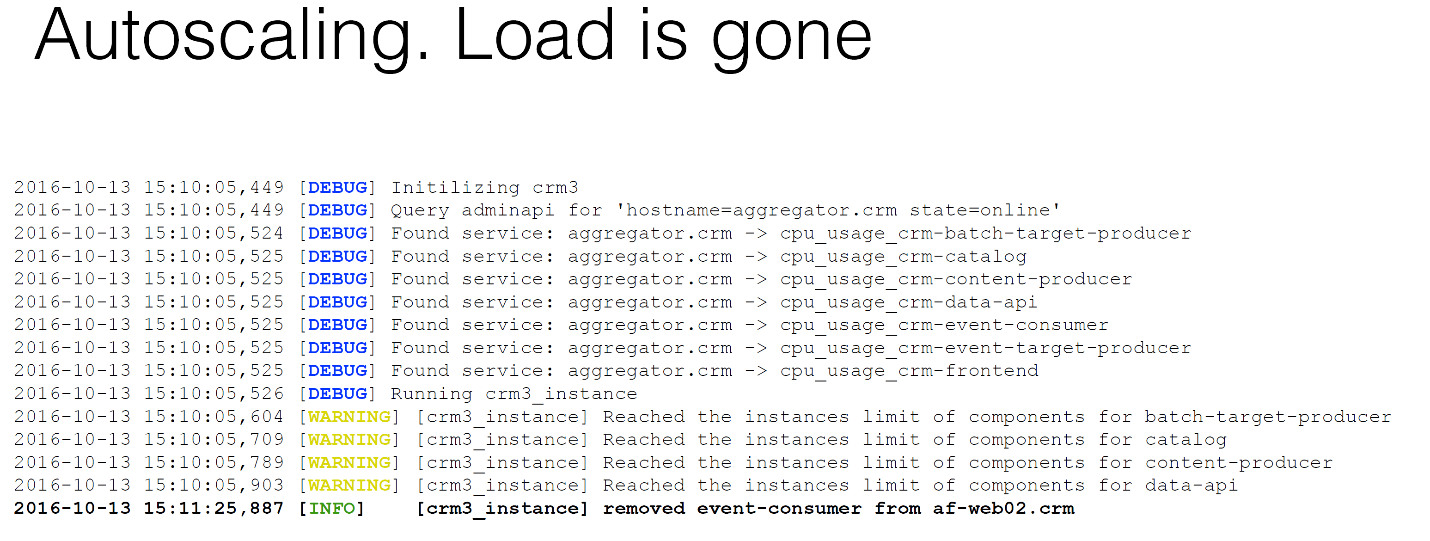
Что же произойдет дальше, когда нагрузка спадёт? Как мы видели на картинке, в какой-то момент она спала. Мы видим warning том, что у нас минимальный лимит по потреблению процессов. Мы ничего условно не делаем, мы просто расходуем, греем воздух. Если вы посмотрите логи BrassMonkey, то увидите, что он тоже сказал: «А давай пришибем парочку компонентов после анализа».
Что нужно сделать, чтобы работал вот такой autoscaling?

Помимо тех Open Source решений, которые вы можете найти где угодно, вам всё-таки нужно что-то написать.
Клиент Grafsy нам нужен для того, чтобы доставлять метрики надёжно. Если мы ломаем наш Graphite по какой-то причине — к примеру, мы используем Whisper, с репликацией достаточно тяжко — мы просто останавливаем его, и Grafsy будет несколько дней, а то и недель, если вы хотите, копить те самые метрики, а потом их все дружно отправит. Так что мы их не потеряем никогда.
Нам всё-таки нужно написать тот самый notifier. Но он уже написан, слава богу, как говорится. Он будет уведомлять вас, вы можете его использовать для различных мониторинговых систем, там всё достаточно просто.
Я не рассказал об этом, но как вы помните, у нас есть кластеры баз данных и кластеры очереди, в нашем случае RabbitMQ. Нам тоже нужно проверять, что нода в кластере живая. Мы не должны на нее балансировать нагрузку, когда она неживая. Но как поступить с MySQL, с MariaDB? Вы просто подключаетесь к ней telnet или любой вашей любимой утилитой, и она говорит: «Эта нода запущена».
Что делать, если на ней данные не актуальны? ClusterHC интересен тем, что он уже модульная система. Можете легко добавить даже свои модули. Он умеет проверять MySQL и RabbitMQ на предмет того, что кластер синхронный. Всё очень красивенько.
Для того же MySQL у нас используется менеджер пользователей. Мы пробовали модуль Puppet, он ужасен, не используйте его, попробуйте вот mmdu. Чтобы включить хост в кластер, вам нужна какая-то начальная настройка, нужно, чтоб какие-то пользователи существовали. Это очень легко делается при помощи этой утилиты. Она вам всё легко создаст из конфигурационного файла.
Все эти утилиты написаны на Go. Вы можете вспомнить, что у нас есть BrassMonkey, для которого нужен модуль, который говорит, что делать и в каких случаях. Он написан на Python.
В архитектурных решениях нам тоже пришлось кое-что сделать. Нам нужно было определить, по какому пути мы хотим измерять, что нам нужно увеличить: количество компонентов или виртуальных машин. Есть 2 пути: интегральный и дифференциальный. Можем предсказывать увеличение нагрузки, а можем говорить: «Окей, средняя нагрузка за такое-то время равна такому-то».
Мы пробовали дифференциальный путь. Очень плохо, потому что у вас постоянно идет предсказание. У вас поток данных, с которыми система возможно уже справилась, вам не нужно ничего уже скейлить, у вас постоянные ложные срабатывания. Это очень некрасиво, мы решили остаться на интегральном пути.
Вам нужно создать виртуальную машину всего лишь при помощи одной команды. Звучит просто, но те, кто использует Puppet, знают, что иногда приходится по 5—6 раз запускать Puppet, чтоб это начало работать хоть как-то. Нужно привести это к очень хорошему виду.
Ну и очень важный момент. Это больше к разработчикам. Вам нужно, чтобы у вас больше чем 1 компонент мог работать в одно и то же время. Потому что первое, на что я наткнулся, когда я со своими разработчиками начал работать, — это то, что у нас постоянно валились deadlocks, потому что компоненты просто дрались за ресурсы.
Это всё достаточно очевидные вещи, никакой магии здесь нет. Вам просто нужно держать систему в порядке.
Итоги
Какой бы мне хотелось сделать из всего этого вывод?
На самом деле не так сложно сделать свой собственный autoscaling. Вам не нужно использовать супер-дорогой Amazon, Google или Microsoft Azure. Это всё минимум в 3 раза дороже, чем использование своих собственных ресурсов. Вам не нужно бежать за трендами.
Я, можно сказать, призываю: подумайте, может быть, у вас уже всё для этого есть. Вам скорей всего даже не придётся мигрировать на другую какую-то систему или технологию. Вы просто используйте вашу текущую виртуализацию. Это всё делается.
Вы можете сэкономить ресурсы компании. Помимо того, что вы экономите банальное электричество, дисковое пространство и слоты на hardware-машинках, вы экономите свои собственные ресурсы. Потому что вам не придётся посреди ночи всё это чинить. Системный администратор будет счастлив, потому что система сама себя чинит.
Ну и важный момент для меня, у меня с этим прямо вот боль. Это то, что разработчики должны писать правильные приложения. Это предыдущая презентация была о правильном коде. Сейчас у нас о правильных приложениях. Звучит довольно очевидно, ну и хорошо.
У меня все, вы можете найти все упомянутые утилиты на GitHub.
→ GitHub нашей компании
→ Мой GitHub
Для большей информации посетите наш сайт, может, что интересного найдете. Спасибо.
Как сделать высоконагруженный сервис, не зная количество нагрузки
