Comments 52
Кстати, вы в чем разрабатываете? VS + R# вроде подсвечивают конфликты такого рода.
Гоовря о таких ситуациях, хотелось бы сказать что такие осмысленные названия в некоторых ситуациях создают весьма неоднозначный код в котором легко запутаться из-за одинаковых идентификаторов, и порой лучше бы они назывались одной буквой внутри метода, чем аналогично члену класса.
for(int i = 0; i < 10;i++){}
Сокращение? Да.
Осмысленное? Нет.
Условно принятое, как норма и применяемое повсеместно? Да.
Также и с лямбдами x.
Лично для себя выработал правило — если переменная «локальная» для одной функции (или даже для части функции — можно и сократить Dot до d. Но если уж сократил так в одном месте — давай точно такое-же сокращённое имя в других местах кода. Если переменная относительно глобальная (например, публичное свойство объекта класса) тут уж будь добр — дай осмысленное имя.
По второй части: однострочники имеют обыкновение дополняться со временем. И переменная-«коротышка» может жить и в разросшемся скрипте.
однострочники имеют обыкновение дополняться со временем. И переменная-«коротышка» может жить и в разросшемся скрипте
А вот это уже проблема кодинга. «Спагетти-код», «Божественный объект» и другие антипаттерны.
Если работа с «коротышкой» усложняется — изменить имя не сложно. Главное этот момент определить, вот только в состоянии «потока» это сделать сложно. Как-раз для этого и надо периодически выделять время на рефакторинг.
Это проблема того кто дополняет.
Пока область видимости переменной — одна строка, ей ни к чему быть длиннее одного символа.
Если программист расширил область видимости переменной, то подбор более подходящего имени — его и только его ответственность.
Переименовать переменную — дело минуты. Часть этих «нефактов» сразу же отпадет. Плюс вы скинете часть ответственности с того, кто будет изменять ваш код, взяв её на себя (тут я полагаю что пишущий новый код программист понимает его лучше того, кто будет этот код изменять, а значит и ответственность на нем).
В комментариях уже указали ситуации, когда хватит «коротышек». Но если противопоказаний нет — лучше использовать нормальные имена.
Но не факт, что это знает программист расширяющий область видимости. Не факт, что у него над душой не стоит менеджер и не твердит: «дедлайн, премия, дедлайн, премия». Не факт, что этот расширяющий программист не подумает «сохраню исходный стиль». Не факт, что он вообще использует имена длиннее одной буквы в LINQ\SQL. Не факт…
"Тебе это не понадобится". Я не буду отвечать за действия людей, которыми не руковожу. Я не буду писать больше кода, чем необходимо для решения моей задачи. Я не буду вводить читающего код в заблуждение о видимости моей переменной.
вы скинете часть ответственности с того, кто будет изменять ваш код, взяв её на себя (тут я полагаю что пишущий новый код программист понимает его лучше того, кто будет этот код изменять, а значит и ответственность на нем).
Это заведомо неверно и однозначно вредно. У изменяющего код будут другие задачи, о которых я здесь и сейчас ничего не знаю. И это ему проще изменить имя переменной для лучшей читаемости его кода.
Но если противопоказаний нет — лучше использовать нормальные имена.
Для переменных с однострочной видимостью нормальные имена — как раз односимвольные.
Разумеется, если одинаково подходят оба варианта — короткий заведомо лучший как более выразительный и менее шумный.
И всегда означало integer значение и/или index.
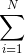
Я как-то пробовал код
for(int index = 0; index < 10; index++){}
довольно непривычно было первое время.
Всё зависит от области видимости переменной. Если это однострочник из 10 символов, то почему бы и нет? И это вполне читаемо:
IEnumerable<int> squares = Enumerable.Range(1, 10).Select(x => x * x);Никто не запрещает переименовать "короткую" переменную при "разрастании" однострочника. Это косяк не того, кто однострочник составил, а того, кто его развернул.
Зачем оставлять потенциальную проблему? Фикс занимает секунды.
Честно говоря, я не понимаю почему локальные переменные нужно именовать нормально, а параметры в запросах-однострочниках — необязательно.
почему локальные переменные нужно именовать нормально, а параметры в запросах-однострочниках — необязательно
))) как известно в программировании есть 3 основных проблемы — наименование переменных и ошибка на единицу.
Иногда проще написать условную x, d или i, которая используется в 1-2 строчках, чем тратить время на придумывание и набор осмысленного имени.
Честно говоря, я не понимаю почему локальные переменные нужно именовать нормально, а параметры в запросах-однострочниках — необязательно.
Чем дальше использование переменной находится от её объявления, тем подробнее должно быть имя переменной. В однострочниках всегда понятно, что это за переменная, потому что её прямо в этой строчке и объявили.
.
Вот когда разрастется однострочник — отрефакторите. А решать несуществующие проблемы — это преждевременная оптимизация, которая корень сами знаете чего. Или вы думали, что оптимизация бывает только по скорости?
В статье пример с SQL запросом. Сколько я видел этих самых запросов — имена таблиц всегда сокращены. Вроде бы это неправильно, потому что именна переменных должны быть осмысленными. Но почему-то пишут именно так. Со временем я поймал себя на том, что тоже так пишу. То ли потому что писать меньше, что как-то глупо, то ли потому, что букв на экране меньше и, соответственно, меньше мусора, а может быть потому, что сокращения на проекте складываются всем понятные. Не знаю точно. Но так вот выходит.
P. S. Поля у запросов поименованы потому, что они попадут в названия колонок результирующей таблицы. Псевдонимы таблиц туда не попадают.
И при изменении структуры БД удобнее рефакторить — меньше изменений делать нужно.
дело в том, что например в Oracle есть жесткие ограничения на длину идентификатора. Если использовать нормальные имена — на раз вылетаешь за ограничения.
Где-то читал (может у Макконнелла), что короткие имена дают техническим переменным, которые нужны для организации работы программы, а не для моделирования предметной области. И на мой взгляд это правильно. Чем меньше у них семантики, тем меньше они обращают на себя внимание. Алиасы таблиц в SQL относятся сюда же, они используются для указания движку, какое поле имеется в виду.
Сравните:
for (int i = 0; i < users.Count; i++)
{
var user = users[i];
...
}
foreach (var user in users)
{
...
}Поменяли тип цикла, техническая переменная ушла в движок языка.
учитывая что альяс имеет смысл только внутри запроса, и не имеет смысла внутри программы, как бы не сильно сложно на время чтения запроса в голове уложить пару сокращений.
Если не сокращать, то будет у меня имя альяса 20 символов и имя поля ещё 20 символов, итого 40 символов на ровно одно поле, это пол строки, для экрана широкоформатника — треть, на мой вкус жирно, для одного поля столько от строки отъедать.
Запросы не всегда в две строки пишутся, для меня это как правило джоины от двух до пяти таблиц, иногда с формулами во фразе SELECT, и подзапросом или двумя во фразе WHERE, раздуть всё это полными именами таблиц? ещё и так что бы альяс был говорящим в рамках запроса?
Нет я конечно очень не доволен ORACLE SQL где имя объекта ограничено в 30 символов и очень рад PostgreSQL где можно использовать аж 64 символа, но не настолько что бы в запросе повторять все 64 символа для каждого поля таблицы.
Другое дело в коде программы, там другое дело, там счётчик это counter / index / element и другие более осмысленные именования, потому что тоже вложенность бывает на пару уровней и если использовать «i», «j», «k» очень легко сбиться.
А вот сущности, описывающие объекты предметной области, не грех и обозвать подробнее, тем более, что название и придумывать не надо, оно уже есть в предметной области. Это действительно улучшает понимание кода.
зачем?
Ответ и так дан выше:
… чтобы он занимал меньше места на экране и лучшим образом показывался алгоритм/структура метода…
Тратить ресурсы на преобразование текста кода туда-обратно бессмысленно
Тратить ресурсы на раскрашивание текста кода бессмысленно — из той же оперы?
… чтобы он занимал меньше места на экране и лучшим образом показывался алгоритм/структура метода…
И каким же образом автоматическая замена осмысленных имён на всякие x, y, z улучшит читаемость кода и понимание алгоритма?
И каким же образом автоматическая замена осмысленных имён на всякие x, y, z улучшит читаемость кода и понимание алгоритма?
Просите у авторов языка APL: P←{0~¨⍨a⌽⊃⌽∊¨0,¨¨a∘!¨a←⌽⍳⍵}
И каким же образом автоматическая замена осмысленных имён на всякие x, y, z улучшит читаемость кода и понимание алгоритма?
По аналогии с тем как работает «мини-карта» кода в современных текстовых редакторах:

Она дает вам возможность взглянуть на свой код «с высоты птичьего» полета и помогает быстрее понимать структуру текущего файла.
Мне кажется нечто похожее на то что предложено выше — может позволить взглянуть на код более абстрактно.
Неправильно именуйте непеременные