Comments 164
Более того, точки с запятыми тоже писать не надо. Видали?
Я сомневаюсь, что внутри несомненно любимого автором функциональненького React найдется так много map/reduce вместо циклов. Проблема в том, что безблагодатные императивные циклы существенно быстрее красивых трансдьюсеров, а, значит, в узких местах будут применяться они.
break это не goto, он не отправляет тебя в неизвестное произвольное место.
Конечно, глубоко внутри все сплошная императивщина, но ее уже написали для нас, давайте этим пользоваться и писать красивый, декларативный код :)
Теоретически можно транслировать map в for на лету, при загрузке модуля, не затратив практически ничего, если вдруг нет возможности изменить реализацию map.
Вот интересно, почему map/reduce медленнее циклов?
Да просто вызов функции это относительно дорого.
А еще все эти map/reduce/forEach делают кучу дополнительных проверок на каждом шагу, потому что должны работать с разреженными массивами, с массивами, в которых кто-то напихал кастомных свойства и прочими граничными случаями. Я не помню, как называлась либа, но там были на порядок более быстрые реализации всего этого дела — но которые работали только с «нормальными» массивами.
Ведь любой map можно разложить в эквивалентный ему цикл for
Теоретически можно транслировать map в for на лету
Мне кажется, это возможно только если итератор — чистая функция...
Ну ладно, map мы разложили в for автоматом, а если гений типа автора написал filter().map()? В общем, по хорошему, нужна поддержка частых ФП-паттернов, всяких там трансдьюсеров, и, возможно, у авторов движков дойдут до этого руки, если это станет достаточно частым сценарием.
- Плохо не глобальное состояние, а глобальные переменные. Глобальным состоянием можно управлять, держать в одном месте и оно в целом может быть неизменяемым или мало изменяемым. С переменными так не получится.
- Причем тут ФП к циклу for? Side эффект от цикла for — это только переменная цикла, которая окажется снаружи.
- Первый пример — чем он лучше?
const isKitten = cat => cat.months < 7
const getName = cat => cat.name
const kittens =
cats.filter(isKitten)
.map(getName)У вас тут:
- Две лишних lambda функции
- Вместо одного цикла, у вас их тут два (в зависимости от реализации, но скорее всего).
И в чем выгода?
Пропаганда ФП это круто, но ФП далеко не везде и не всегда влазит.
Also, goto так не плох, плохо его неконтроллирумое использование в коде. Просто он позволяет слишком много.
Ну а break плох только в запутанных внутренних циклах с кучей логики, но такие циклы всегда выглядят или плохо, или не оптимизировано.
Лишние лямбды кушать не просят, а если вас волнуют лишние циклы используйте трансдьюсеры.
ФП — инструмент, выбирайте инструмент исходя из задачи. Вопрос применимости конкретных инструментов обсуждался уже тысячу раз :)
Лишние лямбды кушать не просят, а если вас волнуют лишние циклы используйте трансдьюсеры.
Очень зависит от. Но в целом лишние лямбды всегда едят больше, чем просто условия и циклы. И они не поддаются оптимизации.
В Android появилась эта странная мода на retrolambda, которые еще очень как тормозят. Они проигрывают где-то в 20 раз по скорости обработки вызовов.
А потом мы получаем сайты, которые поедают все CPU и грузятся по пять минут.
Дело не в нескольких лишних функций, дело в подходе.
"Несколько" лишних функций в большом проекте превращаются в 500-1000 и это уже заметно везде.
А вот что бы на количестве функций экономить, это я от вас первый раз услышал рекомендацию, спасибо :)
Остановитесь, сайты жрут все cpu и грузятся долго не потому что ФП, map, filter или reduce, а потому что разработчик раздолбай. Говно код можно писать в любой парадигме и на любом языке.
Говнокод обычно заметно, и с ним можно боротся. А вот боротся с выбранным уровнем абстракции нельзя.
Каждый дополнительный уровень сверху — это оверхед. ФП такой же оверхед, который может привести к увеличению времени работы от 2 до 100 раз, если вычисления не ленивые, что вполне возможно.
Иногда бывает и наоборот. Допустим, есть какая-то операция со списком. Через некоторое время нужно сделать еще одну почти такую же, но с некоторыми изменениями.
В случае цепочки map/filter переиспользовать часть коллбеков намного проще, чем в императивном коде с for, где все написано единым куском кода.
В императивном коде такое можно легко поправить, завернув цикл for в функцию и просто в одном месте добавить флаг, который будет отвечать за это изменение.
Другое дело, что ФП штуки работают гораздо лучше и проще в случае работы с данными, но, в языках, в которых они для этого нужны.
Если у вас работа с данными не основная часть (а для сайта это врядли так), то я сомневаюсь, что ФП покажет себя лучше.
Представьте, что у вас на входе 10 000 котят. Миллион котят. Для цикла for нет вообще никакой проблемы вывести не всех, а только текущих видимых, в позициях с 12345-ого по 12435-го.
Что там у вас внутри filter/map и как это оптимизировать — а крен его знает.
http://stackoverflow.com/questions/3978492/javascript-fastest-way-to-duplicate-an-array-slice-vs-for-loop
Кстати, специально пробовал заменить while на for — в 3 раза медленней.
Только мне не понятно почему до сих пор не начали говорить что код в статье это не фп, ведь в фп вообще нет переменных, а то фп где есть переменные, это ооп. В фп не может быть объявлений const, var, или let.
Действительно, основополагающие принципы у обеих парадигм одинаковые, но их реализация имхо ортогональна, поэтому говорить что ООП впитал ФП не совсем корректно
p.s. А как бы вы переписали код из статьи на JS?
Переменная объявленная как неизменяемая вряд ли переменной остается.
Так же лисп функциональный, но переменные в нем все равно есть
Зато, возвращаясь к теме статьи, в нём самый шикарный цикл for из всех языков, что я видел (точнее конструкция loop и библиотека iter как развитие этой идеи). Там решение задачи типа «найти такой элемент массива A, что функция F от следующего за ним элемента примет максимальное значение» будет выглядеть примерно как сам текст этой задачи. В чистом ФП же тут будет жонглирование zip, map, filter, etc. А в условном C или императивном js будет куча вспомогательных переменных и манипуляций с ними. Оба варианта как-то так себе.
Можно поинтересоваться почему в ФП не может быть const и let?
Const в них используются неявно, а let есть ничто иное как псевдоним, для некоторого выражения, наподобии того как в математики вводят дополнительные переменные
const isKitten = cat => cat.months < 7 const getName = cat => cat.name const kittens = cats.filter(isKitten).map(getName)
Красиво, но, вероятно, раза в 2 медленнее. Критичные части приходится переписывать в императивщину.
Преждевременная оптимизация — корень всех зол.
Эх, как же надоела эта вырванная из контекста цитата.
Поэтому, вместо вызова у списка метода sort вы каждый раз пишите два цикла сортировки вставкой?
Но ведь вы не пишите сначала свою сортировку пузырьком, что бы потом менять ее в хорошо написанном коде, правильно?
Если мы знаем, что у нас каждая такая цепочка порождает еще один цикл и мы получаем переизбыток циклов и не особо то и выигрываем в читаемости — зачем?
Уже приводили контрпример немного ниже.
Как только названия фильтров начинают превращатся в "isValid" или что-то такое, то все превращается в кашу. Далеко не всегда по фильтру можно понять, что конкретно он делает, а в случае с циклом for + if практически всегда.
А если так не делать, то получается гиганская цепочка фильтров, которую тоже сложно читать.
Константирую тот факт, что в иных проектах узкие места встречаются столь часто, что даже написание сразу циклов не будет преждевременной оптимизацией.
Но, естественно, если котят в списке значительно меньше десятков миллионов, пара лишних созданных в map-filter массивов не сильно повлияют на скорость.
cats.filter(isKitten).map(getName)
Ну сколько можно то? Еще примитивней пример нельзя привести? Или только для таких основ и годятся все эти тренды? Да, на однострочниках ФП выигрывает. Ну вот на однострочниках его и можно применять. А чем длинеее — тем более трудноподдерживаемым код становится
А я вот противоположной точки зрения
Глядя на композицию map, filter, reduce можно сразу выделить структуру даже не вникая в детали (банально если заканчивается reduce — значит результат одиночное значение, иначе — массив). С циклом же нужно полностью изучить весь код, чтобы выявить какую-то структуру.
Смысл map в том что производится трансформация над каждым элементом (можете считать что это групповая операция) и кол-во элементов на входе и на выходе обязано быть одинаковым
По идее, нужно просто фильтр перед map сделать для такого.
Сформулируйте задачу детальнее, пожалуйста.
В случае, если ФП сделано правильно, через ленивые вычисления, то можно сделать фильтр после. Что-то в духе:
map(тут ваши вычисления).filter(тут ваше условие выхода).any()
Должно помочь получить нужные данные.
Это если брать задачу "нужно найти первый такой элемент в цикле". Если задача другая, то надо будет выкручиватся по другому.
В случае, если ФП сделано правильно
А если ФП у нас JS?
21 очко на колоде карт?
Объясните
В этом момент мы прекращаем назвать его или результат его работы редьюсером и не нарываемся на грубости на хабре. Если вам нужен фолдинг — делаем редьюсер и делаем полный проход. Если полный проход не нужен — делаем рекурсию или итерацию но не называем это фолдингом. Либо называем фолдингом но тогда меняем структуру и берем не массив а список, в котором после получения результата не применяем редьюсер к остатку. На массиве редьюсер подразумевает полный проход, изначально мы говорили за массив. Для преобразования его в нужную структуру нужно применить логику в которую и перекочует логика выхода (трансформированная но тем не менее) которую вы пытаетесь запихнуть в редьюсер.
Вы говорили про трансдьюсер. Трудно упомянуть трансдьюсер и не ввести при этом в контекст обсуждения редьюсеры.
Беда и хейтеров и хипстеров как правило просто в непонимании предназначения инструмента. Конкретно редьюсер нужен для того что бы не хвостовую рекурсию сделать хвостовой, это его предназначение, это то куда он ложится красиво.
То есть имеем:
f(a) {
return a == 0? 0: a + f(a-1);
}
это нехвостовая рекурсия, не соптимизируешь. Выносим вычисления в передачу аргумента:
f(a, prev){
return a == 0? prev: f(a-1, a+prev);
}
внезапно рекурсия стала хвостовой а функция — редьюсером. Для этого финта надо иметь нулевой элемент определенный на последней операции, для сложения это ноль. Значит первый вызов будет
func(a, 0);
Все, теперь можно делать фолдинг на ком угодно, это нормально оптимизится.
Ты предлагаешь такую функцию написать в императивном стиле с умершим for?
Да нет, ее можно в функциональном написать, просто нужно еще состояние добавить аргументом (текущую суму), а реализацию трансдьюсера через фор делать, так быстрее.
Статьи эти смешные конечно, они на самом деле не о функ программировании а как-то вообще не о чем. Функ программирование по моему это скорее про структуры данных, тут ни слова о функторах и фолдебл, зато много пафоса про фор мертв.
Из реальных примеров все что генерируется компилятором удобнее писать в функ стиле так как оно тупо менее многословно и подчиняется простым правилам. А вот реализация этого функ стиля уже делается этими самыми мертвыми фор =)
Да вариантов много, зависит от взглядов автора библиотеки. К примеру в lodash есть transform. Это такой мутабельный reduce, которые помимо мутабельности итогового значения умеет выходить из цикла за счёт return false.
Вот map — да, подразумевает обход всех элементов.
reduced в clojureScript, по большому счету — дополнительный внутренний флаг isReduced по которому происходит выход из reduce.
Как только вы вводите флаг reduced, ваше fp перестает быть правильным и становится пародией на императивное программирование.
А если ФП у нас JS?
Я думаю, вам сюда. Как я понял, ленивые вычисления в фп называются трансдьюсеры и точно что-то такое там есть. К сожалению, я знаком с такой штукой для Java, которую они добавили в восьмой версии.
В случае, если использовать их синтаксис, задачи будут выглядит так:
stream.filter(x => x.state == "ok").findAny()Второе будет выглядить так:
stream.filter(x => x.state == "ok").limit(5)Думаю, что вполне можно было бы ограничиться сведениями, в которых map хорош и удобнее, чем for, но в задачах определённого класса, в которых конструкция for достаточно громоздка.
Мне вот не очень понятно, зачем вводить map в стандарт, когда эту функцию можно написать в прототип массива и без всяких стандартов и выглядеть она будет точно так же?
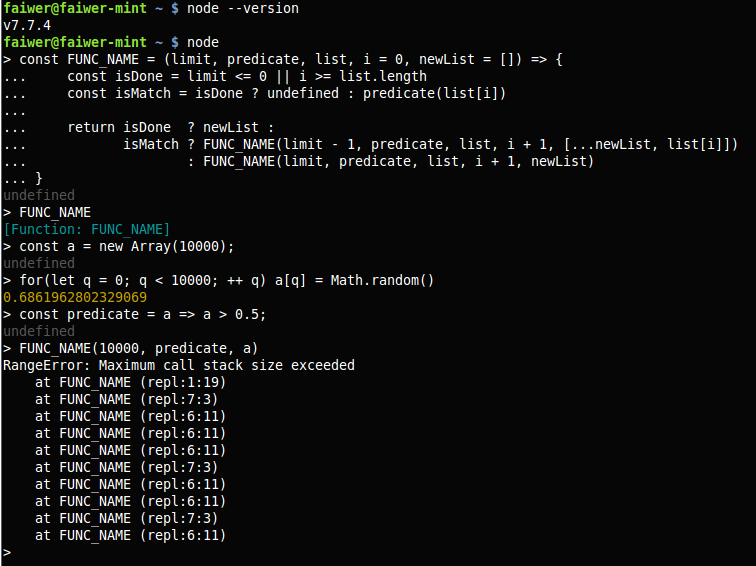
const FUNC_NAME = (limit, predicate, list, i = 0, newList = []) => {
const isDone = limit <= 0 || i >= list.length
const isMatch = isDone ? undefined : predicate(list[i])
return isDone ? newList :
isMatch ? FUNC_NAME(limit - 1, predicate, list, i + 1, [...newList, list[i]])
: FUNC_NAME(limit, predicate, list, i + 1, newList)
}
А потом сравните с промышленным, а не хипстерским кодом:
const FUNC_NAME = (limit, predicate, list) => {
const newList = []
for (var i = 0; i < list.length; i++) {
if (predicate(list[i])) {
newList.push(list[i])
if (newList.length >= limit) {
break
}
}
}
return newList
}
Боже ж ты мой. Главное чтобы это потом не приснилось. Второй кусок кода предельно очевиден: отфильтровать из list только то, что проходит predicate, но не более limit элементов. А первое?
- Рекурсия… Представим что limit около 10'000… и всё это в стек. Кошмар
[...newList, list[i]]в рамках рекурсии для аккумулируемого значения. Какая там асимптотика будет у такого решения?O(n^2)?- Даёшь тернарный оператор внутри тернарного оператора, чтобы ты мог написать терна...
Я вот не могу понять. Это издержки фанатизма? Или человек действительно не понимаешь, что за дичь он пишет? А ведь потом это ещё и переводят, т.е. это "популярно" и "востребовано".
Именно рекурсия не проблема, т.к. соптимизируется.
Но это, конечно, не отменяет превышение нормы СЭС по показателю hipsterity/line)
const a = new Array(10000);
for(let q = 0; q < 10000; ++ q) a[q] = Math.random()
const predicate = a => a > 0.5;
FUNC_NAME(10000, predicate, a)
// Uncaught RangeError: Maximum call stack size exceededВ ES2015 ввели правильную хвостовую рекурсию.
Только что проверил на массиве из 10000 элементов.
node 7.7.2
Хм, странно, но я запустил тот же самый код на v7.7.4 и снова получил RangeError: Maximum call stack size exceeded. Может быть я неправильно понимаю суть хвостовой рекурсии?
{kind=link}
Попробуйте с --harmony.
Если верить node.green, то должно оптимизироваться, если флаг стоит.
Попробовал c --harmony — у меня снова Maximum call stack size exceeded. Код запускал тот же, что и на прошлом скриншоте. Перешёл на node.green и вытащи оттуда тест. Запустил в Chrome — падает с переполнением стека. Запустил в node ― работает. Т.е. оптимизация и правда есть. Почему она не может пережевать код Joel Thoms не знаю. Надо будет поковыряться.
Вероятно, дело в тернарном операторе. Из-за того, что вложенный вызов является частью выражения, оптимизатор не видит возможности применить TCO.
Интересная статья про tail call optiomization в JS.
Очень показательно, спасибо.
const isKitten = cat => cat.months = 7
И никакой const не поможет
Поэтому в условиях невозможности гарантировать отсутвие сайд-эффекта, можно только договорится, что его не будет. Но в таком случае разница между
const getKittenNames = cats =>
cats.filter(isKitten)
.map(getName)
И
const getKittenNames = cats => {
const kittens = []
for (let cat of cats) {
if (isKitten(cat)) {
kittens.push(getName(cat))
}
}
return kittens
}
Только в количестве строк и скорости выполнения. Или в читаемости, кому-то больше filter-map/reduce нравится, а кому-то for-of
Если я хочу число пи, то ИМХО должно быть const pi = 3.14; и все это константа!
Может я чего то не понимаю?
Попробую побухтеть про читабельность.
Вариант с циклом: пройтись по всем котам, если возраст кота меньше заданного (вот тут бы константу) — запомнить имя кота.
Вариант без цикла: пройтись по всем котам, и если кот удовлетворяет условию(сходить узнать условие) то пометить кота. Затем взять помеченных котов и сделать с ними что-то ( надо сходить куда-то за действием). Результатом будет список котят.
Чот как то много бегать придется, и выше справедливо заметили про сложность прерывания данного процесса.
Но это я так бухчу ;-)
Это скорее непривычно поначалу, записи типа
const sum = a => b => a + b
console.log(sum(2)(3))
мне первое время давались с трудом, а теперь жить без них не могу :)
var validUsers = users.map(isValid);
Но isValid, оказывается, проверяет
user.name !== 'Vasek', а не user.access.contains(ADMIN). Но вы слишком горды, чтобы пользоваться типизацией, вы ведь модны и молодежны, а типизация — для старперов и теперь только Васек и не имеет доступ к вашей админ-панели.А отвратительные названия — это одно из проклятий ФП в ЖС. Ведь
canUserAccessAdminPanel пишут только джависты, по-молодежному надо написать is_ok.Вот некоторые названия функций из модных и молодежных библиотек:
- pipe
- it
- connect
- put
- dispatchДа-да, это именно те «емкие и понятные» названия, в которые не нужно заходить, чтобы понять, что они делают. А ведь это библиотечные. А еще сколько будет локальных для приложения.
Как использовать map/forEach/filter вместе с async/await?
for (const foo of bar) {
const result = await doSomethins(foo);
}Нет, это будет требовать больше памяти, чем async/await из-за того, что вы заранее строите длинную "сосиску" из продолжений — так что async/await все же лучше.
Но при отсутствии возможности вставить async/await или библиотеку прямо сейчас так действительно можно делать.
const result = await Promise.all(bar.map(doSomething)
В качестве бонуса — параллельное выполнение. Если нужно именно последовательное — пригодится reduce
const results = await Promise.all(bar.map(doSomething))
Я дико извиняюсь, но почему ничего не сказано про скорость работы этих вариантов?
Код в примере использует map и filter, вместо одного for, вероятно, что он работает в 2 раза медленнее.

Не стоит серьёзно относится к подобным тестам на jsperf. jsperf не чурается модифицировать предоставленный код, изменяя его порой, весьма существенно. Бенчмарки сами по себе редко бывают объективны, но если уж хочется с ними поиграть, то лучше запускать их за пределами таких площадок (скажем в node или просто используя профилирование/console.time браузера).

Я лишь стараюсь убедить, что утверждение ложно:
Код в примере использует map и filter, вместо одного for, вероятно, что он работает в 2 раза медленнее.
Основной источник увеличения нагрузки не три цикла for вместо одного (это как раз совершенно не страшно), а «три тяжеловесных вызова функции + три операции» вместо «три операции» на каждую итерацию. То есть у нас сам вызов функции занимает в сто раз больше времени, чем операция, которую эта функция выполняет.
И это особенность именно JS, а не FP в целом.
Отдельно стоит заметить, что если даже написать свои собственные map и filter, они зачастую будут работать быстрее. Потому что встроенные методы реализованы на сишке, и вызываются через FFI, с соответствующими затратами на маршаллинг аргументов и возвращаемого значения.
const numbers = [];
for (let i = 0; i < 1000000; i++) {
numbers.push(i);
}
function classic() {
console.time('classic');
let result = 0;
const mapped = [];
for (let i = 0; i < numbers.length; i++) {
mapped.push(numbers[i] + 1);
}
const filtered = [];
for (let i = 0; i < mapped.length; i++) {
const value = mapped[i];
if (value % 3 === 0) {
filtered.push(value);
}
}
for (let i = 0; i < filtered.length; i++) {
result += filtered[i];
}
console.timeEnd('classic');
return result;
}
function fp() {
console.time('fp');
let result = numbers.map(n => n + 1).filter(n => n % 3 === 0).reduce((acc, n) => acc + n, 0);
console.timeEnd('fp');
return result;
}
console.log(classic());
console.log(fp());
console.log('---');
console.log(fp());
console.log(classic());
console.log('---');
console.log(classic());
console.log(fp());
console.log('---');
console.log(fp())
console.log(classic());
console.log('---');
console.log(classic());
console.log(fp());
console.log('---');
console.log(fp())
console.log(classic());
console.log('---');
console.log(classic());
console.log(fp());
/*
VM3953:30 fp: 336.918701171875ms
VM3953:34 166666833333
VM3953:23 classic: 259.02001953125ms
VM3953:35 166666833333
VM3953:37 ---
VM3953:30 fp: 294.345947265625ms
VM3953:38 166666833333
VM3953:23 classic: 188.5771484375ms
VM3953:39 166666833333
VM3953:41 ---
VM3953:23 classic: 233.133056640625ms
VM3953:42 166666833333
VM3953:30 fp: 303.2099609375ms
VM3953:43 166666833333
VM3953:45 ---
VM3953:30 fp: 273.15283203125ms
VM3953:46 166666833333
VM3953:23 classic: 232.2529296875ms
VM3953:47 166666833333
VM3953:49 ---
VM3953:23 classic: 224.306884765625ms
VM3953:50 166666833333
VM3953:30 fp: 272.4609375ms
VM3953:51 166666833333
VM3953:53 ---
VM3953:30 fp: 266.1357421875ms
VM3953:54 166666833333
VM3953:23 classic: 377.88623046875ms
VM3953:55 166666833333
VM3953:57 ---
VM3953:23 classic: 176.39013671875ms
VM3953:58 166666833333
VM3953:30 fp: 294.071044921875ms
VM3953:59 166666833333
*/
Какой-то оголтелый фанатизм. И с каждым днём таких статей всё больше. Главное заголовок сделать как можно более пафосным (смерть for). В следующий раз накал надо ещё пуще нагнать. Как насчёт хтонических исчадий из преисподней?
Фунциональное программирование интересная и полезная штука, если ваш язык позволяет из него взять что-то полезное. Императивное программирование напротив тоже очень интересная и полезная штука. Мир не делится на белое и чёрное. И задачи можно решать выбирая наиболее удобные и привычные для себя инструменты. Выбирая один набор преимуществ, вы неизбежно приобретаете к нему такой же набор недостатков.
Скажем мутабельность и иммутабельность. И то и другое может быть весьма удобным и к месту. Важно только понимать, где чего стоит избегать (умоляю — избегайте избыточных аллокаций в .reduce).
Вот скажем мои 5 копеек по сабжу:
map&reduceв качестве заменыforудобная штука, т.к. код получается несколько нагляднее, ибо синтаксис конструкцииforне позволяет красиво возвращать новый объект как результат операций над итерациямиforEachвместоfor-ofпо мне так, на мой вкус, выглядит очень… неопрятно, требует лишнего метода, фигурных скобок. В случае одиночного пробега по какой-либо коллекции я прибегаю кfor-ofкак раз в рамках читаемости. Особенно это удобно в случае 2-3 вложенныхfor.- цепочки трансформаций из ФП — очень удобная и полезная штука. Однако мы тут сталкиваемся с двумя весьма пренепреятнейшими проблемами:
- в JS нет
pipe-оператора. В итоге если цепочка какой-либо метод не умеет, то приходится либо оборачивать её всю целиком (читаемость катастрофически падает), или делить цепочку на несколько, добавляя какие-нибудь вветвления, либо делать какие-нибудь.tapметоды. Тоже касается и композиции методов, без pipe оператора выглядит это ну прямо безобразно. - в JS из коробки нет никаких удобств для работы с callback-ами в
async & *контекстах, а это бывает ну очень актуально
- в JS нет
- ФП подразумевает очень хорошее понимание работы и методов своей ФП библиотеки. Для нового человека ваш код может напоминать набор слов. А если учесть что ряд из либ ещё постоянно меняет свои сигнатуры и названия методов (камень в сторону lodash)...
В своём коде я не чураюсь использовать любые известные мне подходы, исходя из задач. Не понимаю я этого фанатизма.
Я понимаю, что
const kittens = cats.filter(isKitten).map(getName);
а) два прохода по массиву вместо одного (а может и более, если цепочку наращивать);
б) filter возвращает промежуточный массив, то есть лишняя память, лишнее инстанцирование, чаще приход GC;
в) вызов функций отнюдь не бесплатен.
Применяю такой подход только к малым массивам. Видимо, первичное обучение программированию в те времена, когда 640 кб хватало всем, наложило неизгладимый отпечаток на мою психику.
оказалось, что в ноде (последняя LTS версия) forEach на порядок медленнее.
forEach хорошо оптимизируется на реальном коде, разницы с for может и не быть, но LTS версия имеет старый оптимизатор, последний турбофан умеет намного больше
Но даже это не столь важно. Проблема микробенчмарков на js в том, что сравнивать нужно в изолированной среде. Вот например типичный микробенчмарк:
'use strict';
const iter = 1000000
const items = []
for (let i = 0; i < iter; i++) {
const obj = {}
obj.a = 'a' + i
obj.num = '1' + i
obj.random = Math.random() * 1000 | 0
items.push(obj)
}
function doSomething(item) {
if (item.random % 2 === 0) {
result += item.num | 0
}
else {
str += item.a
}
}
console.time('forEach')
var result = 0
var str = ''
items.forEach(function (item) {
if (item.random % 2 === 0) {
result += item.num | 0
}
else {
str += item.a
}
})
console.log(`result: ${result}, str len: ${str.length}`)
console.timeEnd('forEach')
console.time('for')
var result = 0
var str = ''
for (let i = 0; i < items.length; i++) {
const item = items[i]
doSomething(item)
}
console.log(`result: ${result}, str len: ${str.length}`)
console.timeEnd('for')
Результат такой:
>node fortest.js
forEach: 154.271ms
for: 42.073ms
Вроде бы for обогнал forEach в 3 раза. Но достаточно поменять местами for и forEach, сделать чтобы forEach по коду был ниже, как результат становится ровно противоположным:
>node fortest.js
for: 153.958ms
forEach: 51.414ms
То есть уже становится понятно, что в лоб тестирование не провести. Можно ухищряться по разному, но самый простой способ это изолировать 2 куска кода друг от друга. То есть удалить код относящийся к for и запустить тест отдельно для forEach, потом перезапустить node (если код из консоли запускали, а не из файла), удалить код forEach и отдельно запустить уже for. Результат будет такой:
>node fortest.js
for: 153.152ms
>node fortest.js
forEach: 146.153ms
То есть если вы хотите протестировать 2 куска кода, лучше сразу брать benchmark.js, он хоть и не идеален, но хотя бы решает вопрос с изолированным запуском:
'use strict';
const Benchmark = require('benchmark')
const suite = new Benchmark.Suite
const iter = 1000000
const items = []
for (let i = 0; i < iter; i++) {
items.push('abc' + i)
}
let result1 = ''
let result2 = ''
let result3 = ''
function doSome(item) {
if (item[3] % 2 === 0) {
return item
}
return ''
}
suite
.add('For', function () {
result2 = ''
for (let i = 0; i < items.length; i++) {
const item = items[i]
if (item[3] % 2 === 0) {
result2 += item
}
}
})
.add('For with function call', function () {
result3 = ''
for (let i = 0; i < items.length; i++) {
result3 += doSome(items[i])
}
})
.add('forEach', function () {
result1 = ''
items.forEach(function (item) {
if (item[3] % 2 === 0) {
result1 += item
}
})
})
.on('cycle', function (event) {
console.log(String(event.target))
})
.on('complete', function () {
console.log('Fastest is ' + this.filter('fastest').map('name'))
console.log(result1.length)
console.log(result2.length)
console.log(result3.length)
})
.run({ 'async': true })
Результат:
>node test.js
For x 15.70 ops/sec ±3.85% (40 runs sampled)
For with function call x 14.72 ops/sec ±3.52% (38 runs sampled)
forEach x 15.55 ops/sec ±9.37% (30 runs sampled)
Fastest is For, forEach
Жалко нет реального куска кода на котором вы тестировали, чтобы посмотреть что с ним такое)

Код так сходу сейчас не предоставлю, но могу сказать, что задачка была про вычисление convex hull на большом массиве географических координат (сотни тысяч элементов * многократные проходы).
filter и map хороши на циклах с совсем уж простенькой логикой. Если нужно что-то сложное и/или быстрое, то for может быть более к месту.
хайп вокруг const не более чем непонимание того что при ссылке на объект константой является ссылка а не объект. При const на скаляр — все ровно так как ожидалось. Но кого это сейчас интересует, 2017 год на дворе как ни как.
А как быть с yield и await внутри for? Заменять нативный синтаксис на библиотеки с npm?
Это отличный пример того, что все зависит от того под каким углом посмотреть. Нужна производительность — лучше так, нужна удобочитаемость — лучше эдак.
От себя добавлю что если бы мне пришлось тестировать этот кусок кода, то функции проще тестировать чем цикл. Взял фунцкию сунул в нее значения проверил результат. Цикл надо сперва во что-то обернуть, если обертка(метод) без возвратного значения, то ага, уже посложнее будет, возможно даже код рефакторить придется. Так что есть свои преимущества и в том и в этом подходе.
Я просто почитал, порадовался чего нового умеет яваскрипт, чего я еще не видел, подумал, что надо будет попробовать надосуге. Как и практически все комментаторы оригинала. Тут уже на хабре как-то упоминали, мол. наша аудиотория совсем материал по другому воспринимает чем на западе. У нас в принципе любой намек на императив в стиле повествования обречен быть принятым в штыки. (Это замечание переводчику)
Когда читаю подобные статьи, всё время думаю: и ведь это те же самые люди ругают Perl :)
А не думали делать компиляцию из комментариев в новую статью? Есть же переводы, а будут еще компиляции.
Переосмысление JavaScript: Смерть for