Как контролировать семейный бюджет?

У меня всегда были сложности точно следовать бюджету, особенно сейчас, когда все покупки проходят по кредитной карте. Причина проста — перед глазами нет пачки денег, которая постепенно сокращается, и в какой-то момент ты понимаешь, что тратить больше нечего. Если большая часть покупок оплачивается кредитной картой, то единственный способ узнать, сколько cредств осталось или сколько потрачено, это зайти в Интернет-банк или мобильный банк, или же использовать финансовые агрегаторы, например Mint, в которые тоже надо заходить и проверять баланс. Это возможно, но на это требуется дисциплина, а когда с той же карточки платишь не только ты, то установить её сложно.
Я подумал, что меня устроит вариант, если каждый день мне будет приходить уведомление о том, сколько денег у меня ещё осталось в этом месяце. То есть я бы устанавливал бюджет на месяц, и что-то бы считало мои траты и каждый день посылало отчёт о состоянии бюджета.
Самый очевидный вариант это использовать API банка или ходить в его Интернет-банк программно каким-нибудь headless-браузром. К сожалению, доступ к API моего банка платный, а ходить в Интернет-банк проблемно из-за двухфакторной авторизации. Однако, есть ещё один вариант. Почти все банки сегодня присылают оповещения на каждую транзакцию, информируя когда, сколько и в каком месте была совершена транзакция. Именно та информация, которая нужна для ведения бюджета. Осталось придумать, как её обрабатывать.
Мой банк может отправлять оповещения на мобильный телефон и на электронную почту. Вариант с мобильным телефоном не рассматривался ввиду сложности обработки смс-сообщений. Вариант с электронной почтой же выглядит очень заманчиво, программную обработку электронный писем можно было сделать и десятки лет назад. Но сейчас у меня дома только не всегда включённый ноутбук, а значит автоматизировать бюджет мы будем где-то в облаке, например, AWS.
Что нам понадобится в AWS?
В AWS есть множество сервисов, но нам нужно всего три: чтобы получать и отправлять электронные письма — SES, чтобы их обрабатывать — Lambda, и чтобы хранить результат DynamoDB. Плюс ещё пара вспомогательных для связки — SNS, Kinesis, CloudWatch. Это не единственный вариант обработки сообщений: вместо Lambda можно использовать EC2, вместо DynamoDB хранить данные можно в RDS (MySQL, PostgreSQL, Oracle, …), а можно и вообще написать простенький скрипт на своём маленьком сервере на перле и BerkleyDB.
Как выглядит вся обработка в общем? Приходит письмо о транзакции, мы записываем дату, сумму и место платежа в БД, и раз в день отправляем письмо с остатком для данного месяца. Вся архитектура чуть сложнее и выглядит следующим образом:
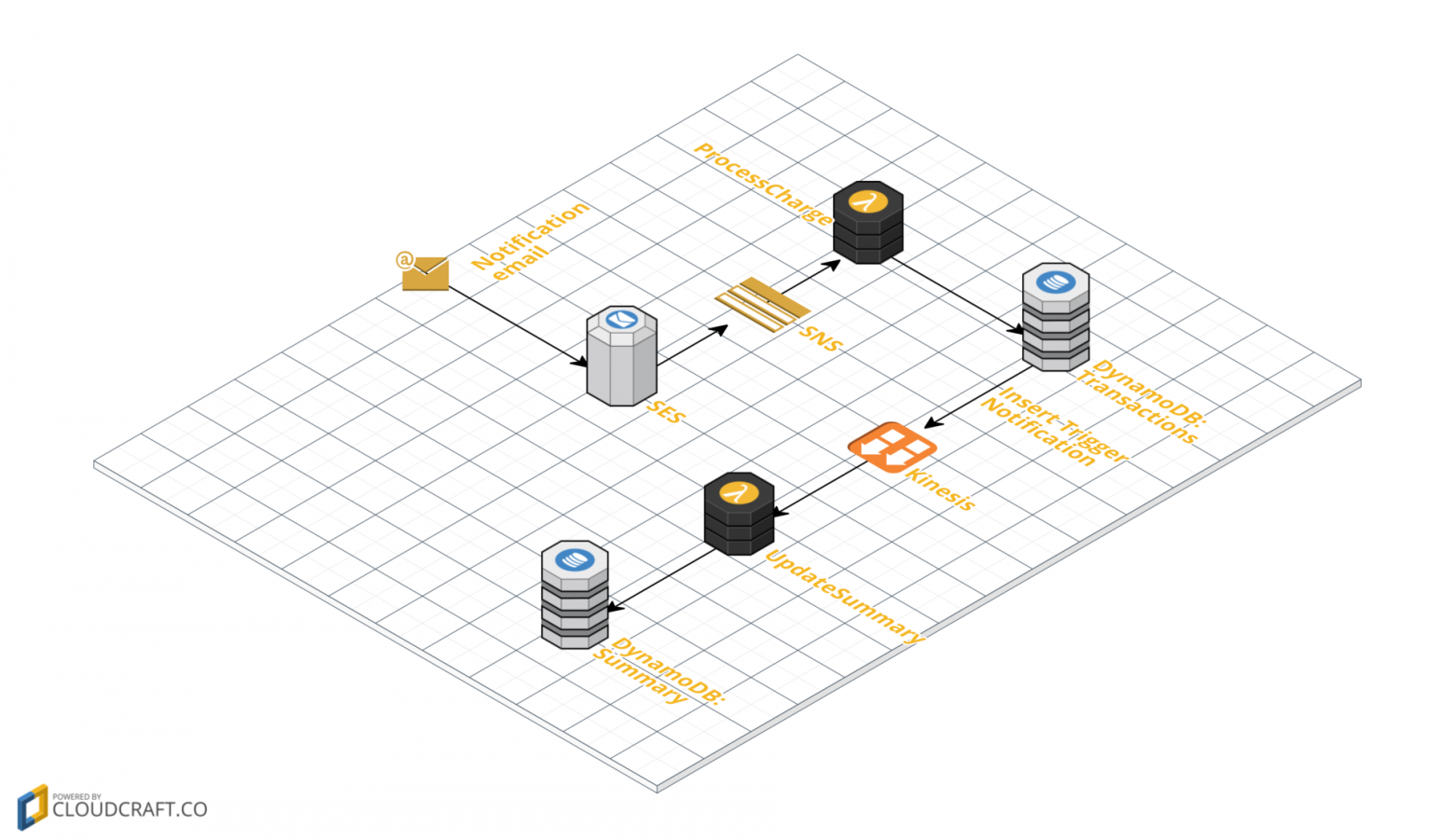
- Письмо приходит в SES.
- SES отправляет письмо в SNS топик.
- Lambda-функция ProcessCharge запускается по приходу письма по SNS, парсит письмо и записывает данные о транзакции в DynamoDB таблицу Transactions.
- Lambda-функция UpdateSummary срабатывает как триггер после записи в таблицу Transactions и обновляет данные о текущем состоянии бюджета в таблице Summary.
Рассмотрим эти шаги более подробно.
Получение письма
Simple Email Service, он же SES, это сервис для приёма и отправки писем. При получении письма можно указать, какое действие должно быть выполнено: сохранить письмо в S3, вызвать Lambda-функцию, послать письмо в SNS и другие. Для получения писем необходимо привязать свой домен, а именно указать SES сервера в MX записи домена. Своего домена у меня на тот момент не было, и я решил, что это хороший повод его зарегистрировать, воспользовавшись ещё одним AWS сервисом Route 53. Захостил я его тоже там же, в Route 53.
При привязки домена к SES требуется его проверка. Для этого SES просит добавить некоторые записи в DNS зону (MX и TXT), а затем проверяет их наличие. Если домен хостится в Route 53, то всё это делается автоматически. Когда домен проверен, можно переходить к настройке правил для получения почты. Моё единственное правило очень простое: все письма, приходящие на адрес ccalert@ нашего домена, отправлять в SNS топик ccalerts:
aws> ses describe-receipt-rule --rule-set-name "ccalerts" --rule-name "ccalert" { "Rule": { "Name": "ccalert", "Recipients": [ "ccalert@=censored=” ], "Enabled": true, "ScanEnabled": true, "Actions": [ { "SNSAction": { "TopicArn": "arn:aws:sns:us-west-2:=censored=:ccalerts", "Encoding": "UTF-8" } } ], "TlsPolicy": "Optional" } }
Обработка письма
Когда новое письмо публикуется в SNS-топик, вызывается Lambda-функция ProcessCharge. Ей нужно сделать два действия — распарсить письмо и сохранить данные в БД.
from __future__ import print_function import json import re import uuid from datetime import datetime import boto3 def lambda_handler(event, context): message = json.loads(event['Records'][0]['Sns']['Message']) print("Processing email {}".format(message['mail'])) content = message['content'] trn = parse_content(content) if trn is not None: print("Transaction: %s" % trn) process_transaction(trn)
За парсинг отвечает метод parse_content():
def parse_content(content): content = content.replace("=\r\n", "") match = re.search(r'A charge of \(\$USD\) (\d+\.\d+) at (.+?) has been authorized on (\d+/\d+/\d+ \d+:\d+:\d+ \S{2} \S+?)\.', content, re.M) if match: print("Matched %s" % match.group(0)) date = match.group(3) # replace time zone with hour offset because Python can't parse it date = date.replace("EDT", "-0400") date = date.replace("EST", "-0500") dt = datetime.strptime(date, "%m/%d/%Y %I:%M:%S %p %z") return {'billed': match.group(1), 'merchant': match.group(2), 'datetime': dt.isoformat()} else: print("Didn't match") return None
В нём мы убираем ненужные символы и с помощью регулярного выражения проверяем, содержит ли письмо информацию о транзакции, и если содержит, разбиваем её на части. Искомый текст выглядит следующим образом:
A charge of ($USD) 100.00 at Amazon.com has been authorized on 07/19/2017 1:55:52 PM EDT.
К сожалению, стандартная библиотека Питона знает мало часовых поясов, и EDT (Eastern Daylight Time) не среди них. Поэтому мы заменяем EDT на числовое обозначение -0400, и делаем такое же для основного часового пояса, EST. После этого мы можем распарсить дату и время транзакции, и преобразовать его в стандартный формат ISO 8601, поддерживаемый DynamoDB.
Метод возвращает хэш-таблицу с суммой транзакции, названием магазина и датой со временем. Эти данные передаются в метод process_transaction:
def process_transaction(trn): ddb = boto3.client('dynamodb') trn_id = uuid.uuid4().hex ddb.put_item( TableName='Transactions', Item={ 'id': {'S': trn_id}, 'datetime': {'S': trn['datetime']}, 'merchant': {'S': trn['merchant']}, 'billed': {'N': trn['billed']} })
В нём мы сохраняем данные в таблицу Transactions, генерируя уникальный идентификатор транзакции.
Обновление бюджета
Я бы хотел остановиться здесь подробнее, а именно на моменте как отслеживается состояние бюджета. Определим для себя несколько значений:
- budget — размер бюджета на месяц;
- total — сумма трат за месяц;
- available — остаток, (buget — total);
В любой момент времени мы хотим знать все эти значения. Это можно сделать двумя способами:
- Каждый раз, когда надо узнать состояние бюджета, транзакции суммируются чтобы получить total, затем available = (budget — total).
- Каждый раз, когда записывается новая транзакция, обновляется total. Когда надо узнать состояние бюджета, делается available = (budget — total).
Оба подхода имеют плюсы и минусы, и выбор сильно зависит от требований и ограничений системы. Первый подход хорош тем, что он не денормализует данные, храня отдельно сумму транзакций. С другой стороны, с ним сумму надо считать при каждом запросе. Для моих объёмов это не будет проблемой, но в моём случае у меня есть ограничение, вызванное DynamoDB. Чтобы посчитать сумму N транзакций, надо прочитать N записей, а значит потратить N read capacity units. Очевидно, это не очень масштабируемое решение, которое будет вызывать сложности (или высокую стоимость) даже при нескольких десятках транзакций.
При использовании второго подхода, total обновляется после каждой транзакции и всегда актуально, что позволяет избежать суммирования всех транзакций. Мне этот подход показался более рациональным в моём случае. Реализовать его, опять же, можно по-разному:
- Обновлять total после записи каждой транзакции в той же Lambda-функции ProcessCharge.
- Обновлять total в триггере после добавления нового элемента в таблицу Transactions.
Обновление в триггере более практично, в том числе с точки зрения многопоточности, поэтому я создал Lambda-функцию UpdateSummary:
from __future__ import print_function from datetime import datetime import boto3 def lambda_handler(event, context): for record in event['Records']: if record['eventName'] != 'INSERT': print("Unsupported event {}".format(record)) return trn = record['dynamodb']['NewImage'] print(trn) process_transaction(trn)
Нас интересуют только события о добавлении элементов в таблицу, все остальные игнорируются.
def process_transaction(trn): period = get_period(trn) if period is None: return billed = trn['billed']['N'] # update total for current period update_total(period, billed) print("Transaction processed")
В process_transaction() мы вычисляем период, в виде год-месяц, к которому относится транзакция, и вызываем метод обновления total.
def get_period(trn): try: # python cannot parse -04:00, it needs -0400 dt = trn['datetime']['S'].replace("-04:00", "-0400") dt = dt.replace("-05:00", "-0500") dt = dt.replace("-07:00", "-0700") dt = datetime.strptime(dt, "%Y-%m-%dT%H:%M:%S%z") return dt.strftime("%Y-%m") except ValueError as err: print("Cannot parse date {}: {}".format(trn['datetime']['S'], err)) return None
Этот код весьма далёк от совершенства, и в этом сыграла роль интересная особенность Питона, что он не может распарсить дату/время с часовым поясом в формате -HH:MM, который соответствует стандарту ISO 8601, и которую сам же Питон и сгенерировал (код выше, в методе parse_content()). Поэтому нужные мне часовые пояса я просто заменяю на понимаемый им формат -HHMM. Можно было воспользоваться сторонней библиотекой и сделать это более красиво, оставлю это на будущее. Возможно, ещё сказывается моё плохое знание Питона — этот проект мой первый опыт разработки на нём.
Обновление total:
def update_total(period, billed): ddb = boto3.client('dynamodb') response = load_summary(ddb, period) print("Summary: {}".format(response)) if 'Item' not in response: create_summary(ddb, period, billed) else: total = response['Item']['total']['N'] update_summary(ddb, period, total, billed)
В этом методе мы загружаем сводку (Summary) за текущий период с помощью метода load_summary(), total в котором нам надо обновить. Если сводки ещё не существует, мы создаём её в методе create_summary(), если существует, обновляем в update_summary().
def load_summary(ddb, period): print("Loading summary for period {}".format(period)) return ddb.get_item( TableName = 'Summary', Key = { 'period': {'S': period} }, ConsistentRead = True )
Так как обновление сводки может производиться из нескольких потоков, мы используем консистентное чтение, которое дороже, но гарантирует, что мы получим последнее записанное значение.
def create_summary(ddb, period, total): print("Creating summary for period {} with total {}".format(period, total)) ddb.put_item( TableName = 'Summary', Item = { 'period': {'S': period}, 'total': {'N': total}, 'budget': {'N': "0"} }, ConditionExpression = 'attribute_not_exists(period)' )
При создании новой сводки, по той же причине возможной записи из нескольких потоков, используется условная запись, ConditionExpression = 'attribute_not_exists(period)', которая сохранит новую сводку только в случае, если она не существует. Таким образом, если кто-то успел создать сводку в промежутке, когда мы попробовали её загрузить в load_summary() и её не было, и когда мы попытались её создать в create_summary(), наш вызов put_item() завершится исключением и вся Lambda-функция будет перезапущена.
def update_summary(ddb, period, total, billed): print("Updating summary for period {} with total {} for billed {}".format(period, total, billed)) ddb.update_item( TableName = 'Summary', Key = { 'period': {'S': period} }, UpdateExpression = 'SET #total = #total + :billed', ConditionExpression = '#total = :total', ExpressionAttributeValues = { ':billed': {'N': billed}, ':total': {'N': total} }, # total is a reserved word so we create an alias #total to use it in expression ExpressionAttributeNames = { '#total': 'total' } )
Обновления значения total в сводке производится внутри DynamoDB:
UpdateExpression = 'SET #total = #total + :billed'
Скорее всего, этого достаточно для безопасного обновления, однако я решил поступить консервативно и добавил условие, что запись должна произойти, только если сводку не успели обновить в другом потоке, и она до сих пор содержит значение, которое есть у нас:
ConditionExpression = '#total = :total',
Так как total является ключевым словом для DynamoDB, чтобы использовать его в выражениях DynamoDB надо создать синоним:
ExpressionAttributeNames = {
'#total': 'total'
}
На этом процесс обработки транзакций и обновления бюджета завершён:
| period | budget | total |
|---|---|---|
| 2017-07 | 1000 | 500 |
Отправка уведомления о состоянии бюджета
Последняя часть системы — уведомление о состояние бюджета. Как я писал в самом начале, мне достаточно получать уведомление раз в день, что я и реализовал. Однако ничего не мешает уведомлять после каждой транзакции, или после каких-то пороговых значений расходов / остатка. Архитектура отправки электронного письма с уведомлением достаточно проста и выглядит так:

- Таймер CloudWatch Timer срабатывает раз в день и вызывает Lambda-функцию DailyNotification.
- DailyNotification загружает данные из DynamoDB таблицы Summary и вызывает SES для отправки письма.
from __future__ import print_function from datetime import date import boto3 def lambda_handler(event, context): ddb = boto3.client('dynamodb') current_date = date.today() print("Preparing daily notification for {}".format(current_date.isoformat())) period = current_date.strftime("%Y-%m") response = load_summary(ddb, period) print("Summary: {}".format(response)) if 'Item' not in response: print("No summary available for period {}".format(period)) return summary = response['Item'] total = summary['total']['N'] budget = summary['budget']['N'] send_email(total, budget) def load_summary(ddb, period): print("Loading summary for period {}".format(period)) return ddb.get_item( TableName = 'Summary', Key = { 'period': {'S': period} }, ConsistentRead = True )
Сперва мы пытаемся загрузить сводку для текущего периода, и если её нет, то заканчиваем работу. Если есть — готовим и отправляем письмо:
def send_email(total, budget): sender = "Our Budget <ccalert@==censored==>" recipients = [“==censored==“] charset = "UTF-8" available = float(budget) - float(total) today = date.today().strftime("%Y-%m-%d") message = ''' As of {0}, available funds are ${1:.2f}. This month budget is ${2:.2f}, spendings so far totals ${3:.2f}. More details coming soon!''' subject = "How are we doing?" textbody = message.format(today, float(available), float(budget), float(total)) print("Sending email: {}".format(textbody)) client = boto3.client('ses', region_name = 'us-west-2') try: response = client.send_email( Destination = { 'ToAddresses': recipients }, Message = { 'Body': { 'Text': { 'Charset': charset, 'Data': textbody, }, }, 'Subject': { 'Charset': charset, 'Data': subject, }, }, Source = sender, ) # Display an error if something goes wrong. except Exception as e: print("Couldn't send email: {}".format(e)) else: print("Email sent!")
Итог
На этом всё. Сейчас, после каждой транзакции, пришедшее письмо обрабатывается и обновляется бюджет, и раз в день посылается письмо с уведомлением о состоянии бюджета. У меня ещё есть планы по добавлению функциональности, например, классификация расходов по категориям, и включение списка последних транзакций в уведомление, если получится что-то стоящее — поделюсь в другой статье. Если есть какие-то вопросы, комментарии или правки — жду в комментариях.
