Здравствуйте, коллеги! Готова очередная публикация из неформальной «Книги знаний» ОСРВ МАКС.
Просьба к постоянным читателям отнестись ко мне лояльно и не минусить за небольшое повторение части материала из предыдущей статьи (про защиту стека) — здесь оно оказалось логичней. А там я уже удалил.
Общее содержание (опубликованные и пока неопубликованные статьи):
Часть 1. Общие сведения
Часть 2. Ядро ОСРВ МАКС
Часть 3. Структура простейшей программы
Часть 4. Полезная теория (настоящая статья)
Часть 5. Первое приложение
Часть 6. Средства синхронизации потоков
Часть 7. Средства обмена данными между задачами
Часть 8. Работа с прерываниями
Многие программисты почему-то считают, что операции new и delete достаточно легковесны и просты. Поэтому код часто изобилует выделением и освобождением динамической памяти. Это более-менее приемлемо на мощных системах (гигабайты ОЗУ и гигагерцы тактовой частоты), но при ограниченных ресурсах может создавать некоторые проблемы, особенно для программ, работающих в режиме 24/7.
Из всего этого следует, что выделять память на куче следует с крайней осторожностью. В идеале, это следует делать на этапе инициализации программы. Если же требуется выделять память по ходу работы, то лучше это делать как можно реже. Не стоит увлекаться постоянным выделением и освобождением. Также стоит опасаться операций, которые выделяют память неявно, внутри себя. Меня коробит от кода подобного вида, особенно если учесть, что он исполняется в системе, где на всё про всё выделено 50 килобайт ОЗУ:
С моей точки зрения гораздо спокойней, если код имеет подобный вид (хоть это и чуть менее красиво, зато — не теребит функции выделения и освобождения памяти):
Этот код специально сделан «в лоб», чтобы чётко показать, что после его добавления, не стало опасности фрагментации адресного пространства, а также было бы точно видно, что на что заменено. Но, до совершенства ему ещё далеко. Начнём с того, что в нём в угоду наглядности попраны принципы ООП, а продолжим тем, что функция strcat каждый раз перебирает строку-приёмник с начала, что отрицательно сказывается на быстродействии. Чисто теоретически, строка-приёмник также может переполниться (хотя в данном конкретном примере, защита от переполнения находится в функции entry.getName).
Приведём вариант, предложенный comdiv, лишённый указанных недостатков.
Опишем класс для работы со статической строкой, содержащий, среди прочего, указание текущей длины, что позволит не начинать осмотр строки каждый раз с начала. Для простоты, реализуем в этом классе только оператор "+=". Именно на этот класс ляжет смысловая нагрузка нового варианта примера.
А основной код снова примет знакомый вид, отличающийся только объявлением переменной output, «оборачивающей» строку xml:
Но за счёт применения другого класса, опасность фатальной фрагментации адресного пространства — миновала. И в отличие от «лобового» решения — оптимизировано быстродействие и устранена опасность переполнения буфера строки.
Совершенствовать класс можно долго (сейчас в нём перекрыт только один вариант оператора "+="), но это уже скорее относится к руководствам по программированию вообще, а не к руководству по ОСРВ МАКС. А пока — просто отмечу, что какой бы из вариантов замены («на скорую руку, но наглядный» или «правильный, но более сложный») ни был бы выбран, они иллюстрируют одну и ту же идею:
Если можно отказаться от постоянного обращения к new/delete, то лучше это сделать.
Мне часто приходилось встречаться с программистами, которые не знают, как именно реализуются локальные переменные в языках Си и С++. При этом, те программисты прекрасно осведомлены, что такое стек, а также — о том, как в него сохраняется содержимое регистров (которые будут испорчены) и адреса возврата из подпрограмм (правда, в архитектуре ARM адрес возврата попадает в регистр LR). Возможно, это связано с тем, что все эти программисты закончили один и тот же ВУЗ (чего уж греха таить, я сам закончил его же, и ещё лет 10 назад тоже до конца не представлял себе, что такое стековый кадр). Тем не менее, будет полезным кратко обрисовать, как же эти загадочные локальные переменные хранятся. В конце раздела, будет раскрыта интрига, каким образом это относится к ОСРВ МАКС.
Итак. Оказывается, стек используется не только для хранения адресов возврата (правда, не у ARM) и временного сохранения содержимого регистров процессора. Стек используется также для хранения локальных переменных.
Посмотрим, как выглядит типичная преамбула функции, у которой этих локальных переменных настолько много, что они не помещаются в регистрах
Первая инструкция PUSH — с нею всё ясно. Она как раз сохраняет регистры в стеке, чтобы перед выходом их восстановить. А что это за вычитание константы 0x1C из SP? А это как раз выделение стекового кадра. Из курса информатики известно, что стек — это такая вещь, которая адресуется не непосредственно, а относительно указателя на вершину стека. Рассмотрим графически, что сделают эти две строки.
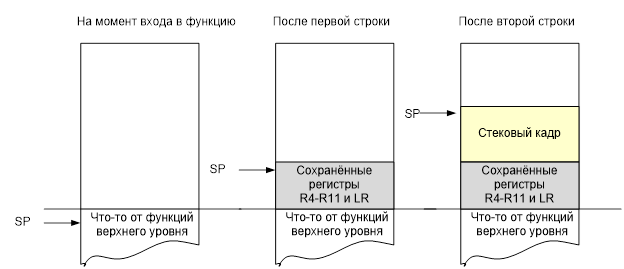
Рис. 2. Влияние преамбулы функции на стек
Что это за стековый кадр? Всё просто. Его размер таков, чтобы в нём уместились все локальные переменные функции (кроме тех, которые оптимизатор положит в регистры). Размер стекового кадра вычисляется компилятором. Каждая переменная получает своё смещение относительно начала кадра, а обращение к ним идёт примерно так:
Очевидно, что переменная BufferSize имеет смещение относительно начала кадра на 0x18 байт.
А переменная SrcAddr — смещение 0x14
Ну, и так далее. Переменная же LayerIndex явно помещена не в стековый кадр, а в регистр R4.
Само собой, в конце своей работы, компилятор всё быстренько восстанавливает (а также помещает бывшее содержимое LR в PC, тем самым, переходя на адрес возврата)
Из всего этого, становятся ясны некоторые вещи:
Самый главный вывод — после некоторых тренировок, программист сможет начать прикидывать, какой объём стека будет необходим задаче (исходя из прикидок о самой глубокой вложенности взаимного вызова функций и набора их локальных переменных). ОС Windows по умолчанию выделяет каждому потоку по мегабайту стека. При работе с микроконтроллерами, речь идёт о килобайтах. Причём эти килобайты выделяются на куче, поэтому уменьшают объёмы свободной динамической памяти и глобальных переменных, так что знание физики не просто полезно, а часто жизненно необходимо.
При создании задачи, определяется размер стека для неё. После этого, размер не может быть динамически изменён. Если он был выбран неудачно (по ходу работы образовалась большая вложенность вызовов, либо число локальных переменных оказалось высоко, что могло произойти уже при сопровождении программы), данные могут выскочить за выделенные пределы, повредив данные в стеках других задач, в куче, либо иные данные и производя прочие непредсказуемые действия. Такую ситуацию желательно выявить и сообщить разработчику, что она требует устранения.
Идеальным методом предотвращения такой ситуации была бы проверка на уровне компилятора, без участия ОС, но к сожалению, такой механизм как минимум, создаёт большие накладные расходы. Основная задача для контроллеров — не проверять программиста, а производить управление. При тактовой частоте в районе ста-двухсот мегагерц (а иногда — и десятков мегагерц), такой метод контроля уже неприемлем.
На уровне ОС также можно производить контроль стека на переполнение. В ОСРВ МАКС используются следующие методы защиты:
Детали для работы с защитой стека можно найти среди констант, заданы в классе Task (в файле MaksTask.h). Изучая комментарии к этим константам, можно понять конкретные величины параметров «минимальный стек», «защищаемая область» и т.п. При желании, этим параметры можно и изменить. Следует только помнить, что размер защищаемой области должен быть степенью двойки.
Всё, наконец-то необходимый минимум теории, без которой невозможно начинать практические опыты, закончен.
Вообще, обычно авторы сначала описывают всё про предметную область, а уже в последней главе (или вообще, в приложении) приводят сведения о практической работе. Видимо, они считают, что читатели сначала всё запомнят, а уже потом — начнут эксперименты. Наивно предполагать, что средний человек запомнит всю массу вываленных на него знаний. Удобнее пробовать все знания постепенно.
Поэтому перед тем, как начать пичкать читателя дальнейшей теорией, стоит немного попрактиковаться. Но для этого следует рассмотреть, как же правильно начать работу с ОСРВ МАКС. Давайте будем считать, что читатель знаком с тем, как скомпилировать и запустить программу под имеющийся у него микроконтроллер, иначе текст будет сильно перегружен.
Если это не так, то крайне рекомендую ознакомиться с замечательными руководствами от среды разработки Keil по работе с отладочными платами ST (к сожалению, на английском языке, но многое понятно и из рисунков):
http://www.keil.com/appnotes/files/apnt_253.pdf
http://www.keil.com/appnotes/files/apnt_261.pdf
И в следующей статье мы приступим к первому практическому опыту.
Просьба к постоянным читателям отнестись ко мне лояльно и не минусить за небольшое повторение части материала из предыдущей статьи (про защиту стека) — здесь оно оказалось логичней. А там я уже удалил.
Общее содержание (опубликованные и пока неопубликованные статьи):
Часть 1. Общие сведения
Часть 2. Ядро ОСРВ МАКС
Часть 3. Структура простейшей программы
Часть 4. Полезная теория (настоящая статья)
Часть 5. Первое приложение
Часть 6. Средства синхронизации потоков
Часть 7. Средства обмена данными между задачами
Часть 8. Работа с прерываниями
Некоторые неочевидные сведения о данных
Несколько фактов о куче
Многие программисты почему-то считают, что операции new и delete достаточно легковесны и просты. Поэтому код часто изобилует выделением и освобождением динамической памяти. Это более-менее приемлемо на мощных системах (гигабайты ОЗУ и гигагерцы тактовой частоты), но при ограниченных ресурсах может создавать некоторые проблемы, особенно для программ, работающих в режиме 24/7.
- Самая очевидная проблема — фрагментация адресного пространства. В современной среде .NET массивы выделяются на куче по ссылке. Поэтому в любой момент времени, система может остановить работу программы и заняться сборкой мусора. При этом массивы вполне могут быть сдвинуты внутри памяти, ведь обращение к ним будет идти по ссылке, а таблица ссылок будет скорректирована. Язык С++, на котором чаще всего пишут для микроконтроллеров (как, собственно, и чистый Си, да и ассемблер) работает с массивами через указатели. Сколько указателей имеется в памяти — никто не знает (программа пользователя имеет право их копировать, передавать в качестве аргументов, даже складывать и вычитать). Значит данные двигать нельзя. Где массив или структура были выделены, там они и будут закреплены до самого удаления. Ну, и дальше возникает классический случай, когда в результате выделений и освобождений куча примет, скажем, такой вид:
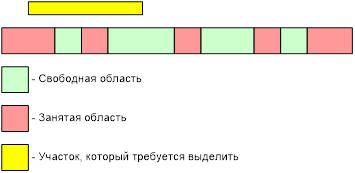
Рис. 1. Иллюстрация классического случая проблем, возникающих из-за фрагментации адресного пространства
В этом случае, суммарный объём свободной памяти больше, чем требуется для выделения, но выделить его невозможно — нет фрагмента требуемого размера. И дефрагментацию произвести невозможно; - Однако, есть более серьёзная проблема. На самом деле, для того, чтобы выделить память, следует перебрать достаточно большое количество таблиц (будем называть это таблицами, хотя разумеется, реализация менеджера памяти может быть и на списках), чтобы найти фрагмент подходящей длины (само собой, речь идёт о случае, когда система работает давно, а выделения и удаления происходят часто — чем больше фрагментов, тем больше элементов таблицы следует перебрать). То есть, операция выделения памяти не такая и дешёвая как по быстродействию, так и по ресурсоёмкости — таблицу выделения памяти где-то следует хранить;
- Более того, операцию выделения памяти нельзя отнести к операциям реального времени. Её быстродействие невозможно предсказать. Возможно, она выполнится достаточно быстро (требуемая запись будет найдена быстро), но может быть — и достаточно медленно, а системы реального времени подразумевают гарантированное быстродействие. Само собой разумеется, это не проблема операционной системы, это проблема плохо спроектированной прикладной программы, так как её автор не учёл этого стороннего эффекта;
- Наконец, на время выделения памяти блокируется переключение потоков, чтобы обеспечить потокобезопасность операции.
Из всего этого следует, что выделять память на куче следует с крайней осторожностью. В идеале, это следует делать на этапе инициализации программы. Если же требуется выделять память по ходу работы, то лучше это делать как можно реже. Не стоит увлекаться постоянным выделением и освобождением. Также стоит опасаться операций, которые выделяют память неявно, внутри себя. Меня коробит от кода подобного вида, особенно если учесть, что он исполняется в системе, где на всё про всё выделено 50 килобайт ОЗУ:
String output; if (cnt > 0) output = ','; output += "{\"type\":\""; output += (entry.isDirectory()) ? "dir" : "file"; output += "\",\"name\":\""; output += entry.name(); output += "\""; output += "}";
С моей точки зрения гораздо спокойней, если код имеет подобный вид (хоть это и чуть менее красиво, зато — не теребит функции выделения и освобождения памяти):
char xml [768]; ... xml[0] = 0; if (cnt > 0) { strcat (xml,","); } strcat (xml,"{\"type\":\""); if (entry.isSubDir()) { strcat (xml,"dir"); } else { strcat (xml,"file"); } strcat (xml,"\",\"name\":\""); entry.getName(xml+strlen(xml),255); strcat (xml,"\"}");
Этот код специально сделан «в лоб», чтобы чётко показать, что после его добавления, не стало опасности фрагментации адресного пространства, а также было бы точно видно, что на что заменено. Но, до совершенства ему ещё далеко. Начнём с того, что в нём в угоду наглядности попраны принципы ООП, а продолжим тем, что функция strcat каждый раз перебирает строку-приёмник с начала, что отрицательно сказывается на быстродействии. Чисто теоретически, строка-приёмник также может переполниться (хотя в данном конкретном примере, защита от переполнения находится в функции entry.getName).
Приведём вариант, предложенный comdiv, лишённый указанных недостатков.
Опишем класс для работы со статической строкой, содержащий, среди прочего, указание текущей длины, что позволит не начинать осмотр строки каждый раз с начала. Для простоты, реализуем в этом классе только оператор "+=". Именно на этот класс ляжет смысловая нагрузка нового варианта примера.
class StaticString { protected: char* m_buf; // Указатель на строку int m_size; // Максимальный размер строки int m_len; // Текущий размер строки public: StaticString (char* buf,int size) { _ASSERT(NULL != buf); _ASSERT(size > 0); m_buf = buf; // Указатель на статический буфер buf[0] = '\0'; // Терминатор m_size = size; // Размер буфера m_len = 0; // Пока длина строки - нулевая } StaticString& operator+=(const char *str) { int i = 0; // Пока есть, куда складывать и пока в источнике не терминатор while ((m_len < m_size - 1) && (str[i] != '\0')) { // Скопировали очередной символ m_buf[m_len++] = str[i++]; } // Терминировали, ведь у нас всё-таки сишная строка m_buf[m_len] = '\0'; return *this; } };
А основной код снова примет знакомый вид, отличающийся только объявлением переменной output, «оборачивающей» строку xml:
char xml [768]; ... StaticString output (xml,sizeof(xml)); if (cnt > 0) output += ','; output += "{\"type\":\""; output += (entry.isDirectory()) ? "dir" : "file"; output += "\",\"name\":\"";
Но за счёт применения другого класса, опасность фатальной фрагментации адресного пространства — миновала. И в отличие от «лобового» решения — оптимизировано быстродействие и устранена опасность переполнения буфера строки.
Совершенствовать класс можно долго (сейчас в нём перекрыт только один вариант оператора "+="), но это уже скорее относится к руководствам по программированию вообще, а не к руководству по ОСРВ МАКС. А пока — просто отмечу, что какой бы из вариантов замены («на скорую руку, но наглядный» или «правильный, но более сложный») ни был бы выбран, они иллюстрируют одну и ту же идею:
Если можно отказаться от постоянного обращения к new/delete, то лучше это сделать.
Кратко про стековые переменные
Мне часто приходилось встречаться с программистами, которые не знают, как именно реализуются локальные переменные в языках Си и С++. При этом, те программисты прекрасно осведомлены, что такое стек, а также — о том, как в него сохраняется содержимое регистров (которые будут испорчены) и адреса возврата из подпрограмм (правда, в архитектуре ARM адрес возврата попадает в регистр LR). Возможно, это связано с тем, что все эти программисты закончили один и тот же ВУЗ (чего уж греха таить, я сам закончил его же, и ещё лет 10 назад тоже до конца не представлял себе, что такое стековый кадр). Тем не менее, будет полезным кратко обрисовать, как же эти загадочные локальные переменные хранятся. В конце раздела, будет раскрыта интрига, каким образом это относится к ОСРВ МАКС.
Итак. Оказывается, стек используется не только для хранения адресов возврата (правда, не у ARM) и временного сохранения содержимого регистров процессора. Стек используется также для хранения локальных переменных.
Посмотрим, как выглядит типичная преамбула функции, у которой этих локальных переменных настолько много, что они не помещаются в регистрах
;;;723 static void _CopyRect(int LayerIndex, int x0, int y0, int x1, int y1, int xSize, int ySize) {
000000 e92d4ff0 PUSH {r4-r11,lr}
000004 b087 SUB sp,sp,#0x1c
Первая инструкция PUSH — с нею всё ясно. Она как раз сохраняет регистры в стеке, чтобы перед выходом их восстановить. А что это за вычитание константы 0x1C из SP? А это как раз выделение стекового кадра. Из курса информатики известно, что стек — это такая вещь, которая адресуется не непосредственно, а относительно указателя на вершину стека. Рассмотрим графически, что сделают эти две строки.
Рис. 2. Влияние преамбулы функции на стек
Что это за стековый кадр? Всё просто. Его размер таков, чтобы в нём уместились все локальные переменные функции (кроме тех, которые оптимизатор положит в регистры). Размер стекового кадра вычисляется компилятором. Каждая переменная получает своё смещение относительно начала кадра, а обращение к ним идёт примерно так:
;;;728 BufferSize = _GetBufferSize(LayerIndex);
000016 4620 MOV r0,r4
000018 f7fffffe BL _GetBufferSize
00001c 9006 STR r0,[sp,#0x18]
Очевидно, что переменная BufferSize имеет смещение относительно начала кадра на 0x18 байт.
;;;730 SrcAddr = Offset + (y0 * _xSize[LayerIndex] + x0) * _BytesPerPixel[LayerIndex];
000030 4816 LDR r0,|L8.140|
000032 f8500024 LDR r0,[r0,r4,LSL #2]
000036 fb076000 MLA r0,r7,r0,r6
00003a 4915 LDR r1,|L8.144|
00003c 5d09 LDRB r1,[r1,r4]
00003e fb005001 MLA r0,r0,r1,r5
000042 9005 STR r0,[sp,#0x14]
А переменная SrcAddr — смещение 0x14
Ну, и так далее. Переменная же LayerIndex явно помещена не в стековый кадр, а в регистр R4.
Само собой, в конце своей работы, компилятор всё быстренько восстанавливает (а также помещает бывшее содержимое LR в PC, тем самым, переходя на адрес возврата)
00007e b007 ADD sp,sp,#0x1c
000080 e8bd8ff0 POP {r4-r11,pc}
Из всего этого, становятся ясны некоторые вещи:
- Понятно, почему локальные переменные видны только внутри функции. Они адресуются относительно регистра SP, а во вложенных функциях (как и в функциях более верхнего уровня) SP будет другой.
- Понятно, почему отладчик среды разработки KEIL не отображает некоторые переменные — почему-то разработчики не умеют показывать содержимое переменных, размещённых в регистрах.
- Понятно, почему выход за границы массива, размещённого в локальных переменных может привести к полной неработоспособности программы — адрес возврата из функции хранится в том же стеке и вполне может быть испорчен.
- Понятно, что рекурсивные функции тратят стек не только на адреса возврата, но и на стековые кадры. Чем больше локальных переменных, тем больше стека расходуется при рекурсивных вызовах. Этого лучше избегать при работе в условиях ограниченной памяти.
Самый главный вывод — после некоторых тренировок, программист сможет начать прикидывать, какой объём стека будет необходим задаче (исходя из прикидок о самой глубокой вложенности взаимного вызова функций и набора их локальных переменных). ОС Windows по умолчанию выделяет каждому потоку по мегабайту стека. При работе с микроконтроллерами, речь идёт о килобайтах. Причём эти килобайты выделяются на куче, поэтому уменьшают объёмы свободной динамической памяти и глобальных переменных, так что знание физики не просто полезно, а часто жизненно необходимо.
Защита стека задачи от переполнения
При создании задачи, определяется размер стека для неё. После этого, размер не может быть динамически изменён. Если он был выбран неудачно (по ходу работы образовалась большая вложенность вызовов, либо число локальных переменных оказалось высоко, что могло произойти уже при сопровождении программы), данные могут выскочить за выделенные пределы, повредив данные в стеках других задач, в куче, либо иные данные и производя прочие непредсказуемые действия. Такую ситуацию желательно выявить и сообщить разработчику, что она требует устранения.
Идеальным методом предотвращения такой ситуации была бы проверка на уровне компилятора, без участия ОС, но к сожалению, такой механизм как минимум, создаёт большие накладные расходы. Основная задача для контроллеров — не проверять программиста, а производить управление. При тактовой частоте в районе ста-двухсот мегагерц (а иногда — и десятков мегагерц), такой метод контроля уже неприемлем.
На уровне ОС также можно производить контроль стека на переполнение. В ОСРВ МАКС используются следующие методы защиты:
- Проверка текущего положения указателя стека при переключении задач. Почти не влияет на производительность, но обладает низкой надежностью. Во-первых, разрушение стека уже произошло, а во-вторых – за время системного такта программа могла не только войти в функцию, вызвавшую переполнение, но и выйти из неё, а значит — указатель мог успеть вернуться обратно в разрешенный диапазон.
- Если установлен размер стека больше минимального, то к нему автоматически добавляется одно слово на вершине, куда записывается «magic number» — 32 разрядное число случайного вида, которое вряд ли встретится при работе программы. При переполнении стека это число будет затерто данными приложения, что почти наверняка позволит зафиксировать факт переполнения стека даже после возвращения указателя в рабочую область.
- В том случае, когда процессор содержит блок MPU (Memory Protection Unit), сразу за границей стека помещается область памяти минимально допустимого размера с защитой от доступа. Это самый совершенный способ контроля, так как при любом обращении к защищённой области, произойдет аппаратное прерывание. Следует, однако, помнить, что в некоторых случаях, защитная зона может оказаться не тронутой. Например, если часть локальных переменных, которые попали именно в эту зону, зарезервированы, но не используются. Защита сделана для самоконтроля и не должна идти в ущерб основным задачам.
Детали для работы с защитой стека можно найти среди констант, заданы в классе Task (в файле MaksTask.h). Изучая комментарии к этим константам, можно понять конкретные величины параметров «минимальный стек», «защищаемая область» и т.п. При желании, этим параметры можно и изменить. Следует только помнить, что размер защищаемой области должен быть степенью двойки.
Всё, наконец-то необходимый минимум теории, без которой невозможно начинать практические опыты, закончен.
Вообще, обычно авторы сначала описывают всё про предметную область, а уже в последней главе (или вообще, в приложении) приводят сведения о практической работе. Видимо, они считают, что читатели сначала всё запомнят, а уже потом — начнут эксперименты. Наивно предполагать, что средний человек запомнит всю массу вываленных на него знаний. Удобнее пробовать все знания постепенно.
Поэтому перед тем, как начать пичкать читателя дальнейшей теорией, стоит немного попрактиковаться. Но для этого следует рассмотреть, как же правильно начать работу с ОСРВ МАКС. Давайте будем считать, что читатель знаком с тем, как скомпилировать и запустить программу под имеющийся у него микроконтроллер, иначе текст будет сильно перегружен.
Если это не так, то крайне рекомендую ознакомиться с замечательными руководствами от среды разработки Keil по работе с отладочными платами ST (к сожалению, на английском языке, но многое понятно и из рисунков):
http://www.keil.com/appnotes/files/apnt_253.pdf
http://www.keil.com/appnotes/files/apnt_261.pdf
И в следующей статье мы приступим к первому практическому опыту.
