Comments 58
TmpLog operator<< (const T& data)Нет, метод
TmpLog LoggerWrap::operator<< (const T& data)должен возвращать объект по значению, в противном случае ссылка будет на объект который был создан стеке и уже разрушен.
в противном случае ссылка будет на объект который был создан стеке и уже разрушен
TmpLog& LoggerWrap::operator<< (const T& data)
{
return *this;
}
Кстати, для потока обычно перегружают вывод в него функции типа void f(ostingstream&), в которой делают всё что нужно с потоком. А в операторе перегрузки просто вызывают эту функцию для текущего потока. Это позволяет писать свои собственные функции-манипуляторы.
Посмотрите на glog, вполне возможно не придётся писать свой велосипед. Там как раз через << всё сделано.
Спасибо за совет. Но велосипед писать все равно надо по нескольким причинам:
- Мне нужно реализовать интерфейс который требует библиотека (внутренний продукт компании).
- Наша текущая система логирования не поддерживает многопоточность, а упомянутая библиотека пишет в лог из нескольких потоков. Т.е. обертка еще и синхронизирует доступ к нашей подсистеме логирования.
- Мне нужно писать в лог информацию из места где я использую библиотеку и так, чтобы мои записи были в правильном порядке относительно записей библиотеки.
А так у нас решили попробовать использовать P7 library, но уже в другом проекте :)
Я бы настойчиво рекомендовал не использовать операторы вообще — даже если на самом деле "красивее" на первый взгляд, все только ухудшается:
- это никак не выразительнее банального
logger.warn(...) - логгер "притворяется" потоком, хотя в этом нет никакой необходимости
- солидный кусок нетривиального кода без серьезной отдачи
LOG(WARN) << «Unexpected blah: » << blah << " instead of " << expected_blah;
А с logger.warn() надо же сначала сформировать строку, то есть либо stringstream с теми же операторами, либо snprintf() и пляски с выделением буфера нужного размера.
Отдача соответственно в повышении читаемости клиентского кода.
Каюсь, забыл, что в плюсах конкатенация нетривиальна.
Но все равно, разве так уж плохо logger.warn("Unexpected blah: %s instead of %s"), что оправданы кастомные операторы?
logger.warn("Unexpected blah: %s instead of %s", blah, expected_blah);то конечно да. Но это же надо как-то через varargs (или как оно в c++ называется) blah и expected_blah внутрь логгера форвардить, а внутри там опять snprintf (?) и ещё веселее с выделением буфера, т.к. заранее размер строк мы теперь не знаем…
Сам ненавижу любую возню с перегрузкой операторов, но когда кто-то добрый уже всё сделал, то пользоваться удобно.
Но это же надо как-то через varargs (или как оно в c++ называется) blah и expected_blah внутрь логгера форвардить, а внутри там опять snprintf (?) и ещё веселее с выделением буфера, т.к. заранее размер строк мы теперь не знаем…Или писать функцией, которая умеет <...>:
void Logger::logwrite(char level, const char* format, ...)
{
SYSTEMTIME st;
GetLocalTime(&st);
// write prefix...
fprintf(stream, "%04d-%02d-%02d %02d:%02d:%02d [%c] ",
st.wYear, st.wMonth, st.wDay, st.wHour, st.wMinute, st.wSecond, level);
// write message
{
va_list argptr;
va_start(argptr, format);
vfprintf(stream, format, argptr);
va_end(argptr);
}
fprintf(stream, "\n");
fflush(stream);
}да, недопечатал оставшиеся аргументы.
Не очень понял, как в вашем примере значения вместо %s будут подставляться. Если бы можно было
logger.warn(«Unexpected blah: %s instead of %s», blah, expected_blah);
то конечно да. Но это же надо как-то через varargs (или как оно в c++ называется) blah и expected_blah внутрь логгера форвардить, а внутри там опять snprintf (?) и ещё веселее с выделением буфера, т.к. заранее размер строк мы теперь не знаем…
У Вас же не C, C++ и есть шаблоны. Вполне можно написать безопасный аналог printf. Как отправную точку, можно рассмотреть пример из Википедии:
void printf(const char *s)
{
while (*s) {
if (*s == '%' && *(++s) != '%')
throw std::runtime_error("invalid format string: missing arguments");
std::cout << *s++;
}
}
template<typename T, typename... Args>
void printf(const char *s, T value, Args... args)
{
while (*s) {
if (*s == '%' && *(++s) != '%') {
std::cout << value;
++s;
printf(s, args...); // продолжаем обработку аргументов, даже если *s == 0
return;
}
std::cout << *s++;
}
throw std::logic_error("extra arguments provided to printf");
}
разве так уж плохо logger.warn(«Unexpected blah: %s instead of %s»), что оправданы кастомные операторы?Приходится следить за соответствием аргумента и спецификатора формата, а если хочешь включить в сообщение
std::string, не забывать .c_str(), что частенько приводит к ошибкам Всякие статические анализаторы свободно ловят ошибки в таком коде:
std::string msg;
snsprintf(buf, _countof(buf), "message: %s", msg);
snsprintf(buf, _countof(buf), "message: %s, length=%d", msg.c_str());std::string msg;
applog.logwrite('W', "message: %s, isEmpty=%s, length=%d", msg, msg.empty());Да, аргумент.
Коллеги, спасибо, понял, что в плюсах есть дополнительные причины для использования операторов, с их учетом уже минимум не так однозначно выглядит ситуация.
но не ловят в таком:Я, наверное, ничего не понимаю в колбасных обрезках, но вы, разумеется, добавили к опиcанию
std::string msg; applog.logwrite('W', "message: %s, isEmpty=%s, length=%d", msg, msg.empty());
logwrite __attribute__ ((format (printf, 2, 3))), да? И какой же у вас дрянной анализатор после этого не словил ошибку?Для Visual C++
stackoverflow.com/questions/2354784/attribute-formatprintf-1-2-for-msvc
Причём, в первом случае это можно понять — диагностики, входящие в стандартый /analyze, не в приоритете.
Но вот R# позиционируется как визуальный ассистент, поэтому подсветка форматных параметров в кастомных функциях, как и в printf, была бы полезной.
#include <cstdarg>
#include <cstdio>
void my_printf(_Printf_format_string_ const char* format, ...)
{
va_list argptr;
va_start(argptr, format);
vprintf(format, argptr);
va_end(argptr);
}
int main()
{
int v = 5, d = 6;
my_printf("v=%d, d=%s\n", v, d);
printf("v=%d, d=%s\n", v, d);
return 0;
}printf подкрашивает спецификаторы и подчёркивает ошибки, а в кастомном — нет: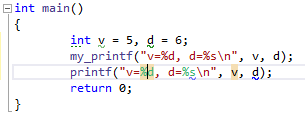
прикольно. в 99-м игрался с перегрузкой операторов, написал себе библиотечку для строк, списков и деревьев с симпатичным синтаксисом типа "на операторах") но до такого трюка не додумался.))
return std::move(tmlLog << data);move здесь не нужен и даже вреден, может помешать задействовать copy ellision.
Если бы было просто:
return TmpLog(*this, buf);то да, не нужен.
Но оператор TmpLog::opertaor<< возвращает ссылку на TmpLog, а для того, чтобы его создать нужен конструктор копирования (без него ошибка компиляции), но он удален, чтобы избежать случайного сохранения объекта. Можно сделать конструктор копирования приватным, но он полностью повторит конструктор перемещения. Так что, если я правильно понимаю, то здесь copy ellision не будет работать. А виноват во всем TmpLog::operator<< — он возвращает ссылку на объект, а не новый объект.
- не «в консоле», а «в консоли»
- «Здесь уровня логирования» — «Здесь не задаются уровни логирования» (на самом деле журналирования)
- «дополнительное желаемое использование» — ошибки нет, но сочетание жуткое
LOG(Info, "Message " << with << " some " << data);Где LOG выглядит, грубо говоря, так:
#define LOG(level, what) do { \
if (level <= currentLoggerLevel) { \
std::ostringstream ss__; \
ss__ << what; \
WriteSomewhere(ss__.str()); \
} \
} while (false)Конкретное исполнение, конечно, адаптируется с учетом наличия уровней и целей логгирования, инструментария форматирования и метода вывода сформированного сообщения.
Нередко важным плюсом является отсутствие собственно форматирования строки, если уровень логгирования недостаточен и сообщение выводиться все равно не будет.
Кстати, создание строкового потока довольно затратное мероприятие. Точных цифр я не помню, но как-то доводилось сравнивать. В итоге если создавать ostringstream каждый раз, то вывод при помощи printf был быстрее, а если при выводе только очищать, то через потоки быстрее.
Мне не нравятся оба варианта, по нескольким причинам
- Завязано на операторы вывода в поток
- Требуется явно плодить объекты.
- Энергичное вычисление всего, что отправляется в лог. Даже если сообщение будет отфильтровано по уровню.
Почему мне не нравятся большинство нынешних библиотек журналирования — они как минимум некомпактные, а как максимум монструозны. И рассчитаны на то, что только Их Высочеств будут использовать по всему проекту. Надо скрестить несколько проектов, использующих разные библиотеки журналирования — развлекайтесь с их "скрещиванием".
Мои попытки причесать собственный велосипед: https://github.com/target-san/log_facade.
А по поводу скрещивания различных систем журналирования — я как раз с попыткой разрешить это и столкнулся. Обертка писалась для реализации интерфеса журналирования, который требуется библиотеке (внутрений продукт компании, но делается другим отделом), сама по себе библиотека писать лог не умеет. Непосредственно у авторов не спрашивал, но подозреваю, что такой подход был выбран из-за использования библиотеки в разных проектах с различными системами журналирования.
Мне не нужен был логер. Я неудачно выбрал название публикации.
Мне нужно было реализовать интерфейс логгера, требуемый сторонней библиотекой (ее делает соседний отдел). И синхронизовать обращение к нашей подсистеме логирования, так как она не расчитана на работу в многопоточном режиме, а библиотека пишет в лог из нескольких потоков. Чтобы процесс синхронизации не поломал порядок вывода логов библиотеки и логов кода, который ее использует, то я стал писать в лог через обертку и в своем коде. А мне удобнее форматировать при помощи оператора <<, чем писать sprintf.
А что вы подразумеваете под "перегрузить std::ostream"?
Я понял. Мы, видимо, говорим о разных вещах. У меня не полноценный логгер, а просто обертка. Я не хотел писать каждый раз что-то типа:
std::ostringstream os;
os << "Something happened: value1 = " << value1 << "; value2 = " << value2;
logger.write(os.str());а просто написать:
logger << "Something happened: value1 = " << value1 << "; value2 = " << value2;лично мне намного удобнее написать и особенно прочитать
logger->warn("unexpected values {} {:.2f}", val1, val2)чем
logger->warn() << "unexpected values " << val1 << " " << std::setw(2) << val2 << std::endl;"Явное лучше, чем неявное".
На первый взгляд, вариант 2 удобнее. Но что, если нужно вызывать flush() не в каждой строке, а например 1 раз после нескольких циклов? Если не ошибаюсь, в этом случае можно получить экземпляр TmpLog и работать с ним. Но, вероятно, некоторые разработчики будут забывать это делать, и ваша система логгирования начнёт тормозить из-за слишком частых flush(). А ещё с несколькими экземплярами TmpLog (при неправильном применении RAII) можно сильно перепутать порядок вывода лога.
Спасибо за замечания. Мне как-то в голову не пришло, что можно захотеть сохранить ссылку и потом еще раз создать TmpLog. Я у себя в голове видел только одно применение. Так как нет конструктора копирования, а конструктор перемещения приватный, то экземпляр TmpLog за пределы области видимости, где он был создан — не вывести. Это позволяет локализовать перемешивание лога одной областью видимости, но проблема все равно остается.
Чтобы не перепутались потоки при одновременной работе с несколькими экземплярами, можно хранить в каждом TmpLog свой ostringstream. Еще, как вариант, завести счетчик TmpLog и создавать новый поток только, если существует больше одного TmpLog.
TmpLog нужен, чтобы сформировать одну строку и передать ее система логирования. Flush, здесь, и явлется такми сигналом. На то как строка будет буфферезирована системой логирования это никак не влияет. С названиями у меня здесь, конечно, беда получилась. В целом оператор << нужен, что не писать каждый раз, что-то типа:
std::ostringstream os;
os << "Something happened: value1 = " << value1 << "; value2 = " << value2;
logger.write(os.str());Так как это не система логирования, а небольшая обертка, которая будет иметь ограниченное применение, я надеюсь, что не случится казусов с созданием нескольких объектов TmpLog.
И небольшое дополнение к вашему коду: если помечаете конструкторы как удаленные, то делайте это в публичной секции, тогда при попытке их использовать в ошибке компиляции будет указано, что этот конструктор удален, а если в приватной секции, то компилятор пишет, что нет доступа, так как он приватный. По крайней мере у меня так было.
Варианты operator<< для логгера