Привет, Хабр! Представляю вам перевод статьи.

Это Вегас с предоставленной разметкой, тестовым датасетом и вероятно белые квадраты — это отложенная валидация (приват). Выглядит прикольно. Правда эта панорама лучшая из всех четырех городов, так вышло из-за данных, но об этом чуть ниже.
0. TLDR
Ссылка на соревнование и подробное описание.

Мы закончили предварительно на 9-м месте, но позиция может измениться после дополнительного тестирования сабмитов организаторами.
Также я потратил некоторое время на написание хорошего читаемого кода на PyTorch и генераторов данных. Его можно без застенчивости использовать для своих целей (только поставьте плюсик). Код максимально простой и модульный, плюс читайте дальше про best practices для семантической сегментации.
Кроме того, не исключено, что мы напишем пост про понимание и разбор Skeleton Network, которую в итоге использовали все финалисты в топе соревнования для преобразования маски изображения в граф.

Суть соревнования на 1 картинке
1. Соревнование
Как вы можете знать из моих прошлых записей, мы иногда участвуем в соревнованиях (1 и 2) и имеем специфический набор критериев выбора таких соревнований — во-первых, достойный уровень конкуренции (обычно хорошо распиаренные контесты на кегле привлекают орды стакеров и не являются очень сложным), во-вторых, наш общий интерес к теме, и в-третьих, челлендж.
В этом соревновании были все критерии:
- Жесткий челлендж и высокая вероятность того, что команда ods.ai будет стоящим соперником (они участвовали в 3-4 соревнованиях со спутниками в 2017 году).
- Соревнование требовало не только построить подходящую семантическую сегментацию изображения, но и построить граф из предсказанных масок. Это породило запутанную и интересную метрику (пост про нее раз, два, репа). Люди, которые пробовали код из репозитория, говорили мне, что тот питоновский код как-то сильно расходился у них с leaderboard, так что все в итоге использовали их тулзу для визуализации, написанную на Java.
- Интересная область — спутниковые изображения с обильным количеством информации, примерно 4000 HD изображений из 4 городов в разных каналах (в основном у нас были хайрезы в чб, 8 канальные MUL изображения, pan-sharpened MUL изображения и обычные RGB).
- Интересный данные (графы, geojson, спутниковые снимки) и новая область поисследовать (TLDR — можно использовать skimage и rasterio — все остальные библиотеки из списка, предоставленного хостами — УЖАСНЫ). Также выяснилось, что skimage неплохо работает с 16-битными изображениями, tiff и другими странными форматами.
- Я не могу понять, хорошо это или плохо, но платформа TopCoder требует от участников высокого уровня профессионализма (все ваши решения должны быть докеризированы, что очень скучно для меня, не по��ому что мне не нравится докер, а по сути потому, что орги хотят, чтобы мы за них еще и юнит тесты написали). Но сама платформа просто ужасна, и качество кода предоставленного ими мне показалось мягко говоря спорным. Меня это сильно раздражало — после того, как ты потратил кучу времени на собственно решение задачи, они просят тебя потратить еще больше времени на упаковку этого решения, когда само описание конкурса и код очень тяжело читать.
- Kaggle — куча стакерщиков, и в основном бизнес ориентированные задачи, по крайней мере в 2017 году.
- TopCoder — иногда очень интересные и сложные нишевые задачи, но в целом платформа страшновата и требования к участникам высокие.
- DrivenData — самая маленькая, но самая лучшая. Интересные области, отличные организаторы, которые делают свою работу и не требуют от тебя лишнего.
2. Быстро про первоначальный анализ данных и интересные краевые случаи


Видно, что земля и асфальт не имеют на самом деле резких пиков на графике отражательной способности. Так что я потратил некоторое время на тестирование комбинации разных каналов
Вы можете видеть входные данные на картинке выше, но есть пару интересных моментов и заслуживающих внимание краевых случаев, которые объясняют, что же на са��ом деле происходит.

Гистограмма оригинала 16-битной картинки

Гистограмма 8-битной картинки, некоторая информация потерялась

Асфальтированные дороги против неасфальтированных

Пример асфальтированных дорог вместе с неафсальтированными плюс перекрестки

Комбинация дорожных полос — заметьте несколько 12 полосных дорог — на пропускных пунктах границ, я полагаю

Типичная разметка в Париже — не очень хорошая
3. Полезное чтение
Вот лист лучших материалов по теме, что я изучил во время соревнования.
- Пост компании Тинькофф на хабре с базовой информацией о спутниковых снимках
- Информация о каналах спутниковых снимков и pan sharpening
- Нашелся только один релевантный пейпер в этой области
- Релевантные работы по семантической сегментации изображений:
- Репа тулзы по переводу маски изображения в граф — sknw
- Amazon Jungle competiton. Всякие детали и опыт. 1, 2, 3.
- Фичеринг. Раз. Два.
- Удаление тумана: пейпер и пара репозиториев. раз. два. (они работают, но медленно)
- Semantic Segmentation Architectures Implemented in PyTorch
- Материалы с соревнования Carvana competition:
Если суммировать все архитектуры и эксперименты, то выйдет что-то типа:
- UNET + Imagenet неплохо, но LinkNet лучше (2 раза быстрее и легче с небольшой потерей точности);
- Transfer learning обязателен и приводит к лучшему результату;
- Skeleton Network лучшая тулза для превращения маски в граф, но требует некоторой настройки;

Unet + transfer learning

LinkNet

Некоторые ученые все еще используют MSE...
4. Начальные варианты архитектур и косячные кейсы
Очки на лидерборде начинались с 0 и до почти 900k для примерно 900 тестовых изображений, каждому изображению присваивалось 0 — 1. Финальная метрика считалась как среднее между городами, что было не очень, так как Париж опускал скор вниз очень существенно.
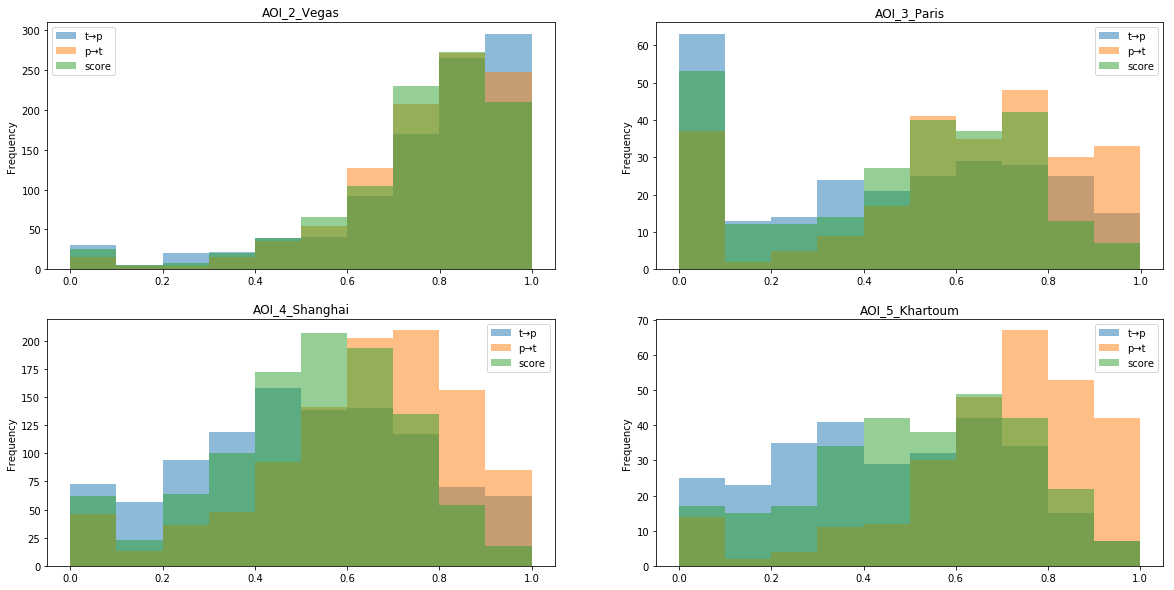
Распределение скора по тайлам для некоторых из наиболее эффективных моделей. В Париже много растительности и пригородных тайлов с плохой разметкой, которые влияют на скор. Кроме того, у Шанхая и Хартума более высокие расхождения между оценками t-p и p-t, то есть для модели намного проще убедиться, что все ребра графа верны, но гораздо труднее найти ВСЕ ребра графа, которые есть в природе
Я попробовал множество идей и архитектур, и к моему удивлению, лучше всех или, по крайней мере, не хуже остальных работала самая простая и наивная модель (все остальные участники тоже юзали именно ее с вариациями).
Loss функция
- BCE + DICE / BCE + 1 — DICE — показали себя более менее одинаковож
- Clipping loss функции тут показал себя ужаснож
- N BCE + DICE, BCE + N DICE — не работало в моем случае. Потом коллеги из чата подсказали, что мониторить надо не DICE, а hard DICE (по сути процент угаданных пикселей) и хорошо заходит 4 * BCE + DICE, с учетом того, что брать надо лучшую эпоху по hard DICE;
CNN
- LinkNet34 (Resnet34 + Decoder) — было лучшим по скорости и точности;
- Linknet50, LinkNext101 (ResNeXt + LinkNet), VGG11-Resnet — все показали себя одинаково, но требовали в 2-4 раза больше ресурсов;
- Все энкодеры были предобучены на ImageNet, ессно;
- Для 8-канальной сетки я просто заменил первый слой, но она вела себя более менее так же как и 3-канальная (но ела больше ресурсов CPU);
Обработка
- Бинаризация маски;
- Я сделал ablation анализ всех разумных комбинаций каналов — лучшими были растительность, rgb, 8 каналов, urban (смотрите чему они соответствовали в коде /src/presets.py) — но разница была минимальна (3-5%);
- Естественно HD изображения показали себя лучше;
- 8 и 16-битные изображения также показали себя более менее одинаково;
- Нормализация изображения — экстракция среднего и стандартного отклонения Imagenet дали +2-3% уменьшения функции потерь, но никакой разницы на лидерборде особо не было;
Маски
- Маска из APLS репы. 10% масок не создавалось, т.к. код организаторов не содержал обработки ошибок и там не было дорог. Сначала я не стал париться и включать их в тренировку, но потом вероятно это было моей ошибкой, хотя нормально это проверить я так и не смог;
- Просто загрузить линии в skimage и допилить примерно 10% пустых изображений — давало уменьшение loss-а, но влияние на итоговый результат было неясным;
- Тоже самое давали маски, где ширина дороги соответствовала ее реальной ш��рине — вроде лосс сходится лучше, но графы получаются не лучше. Вероятно hard DICE бы решил эту проблему;
- Модели для неасфальтированных дорог работали гораздо хуже, из-за плохих данных;
- Многослойные маски также не сработали (1 слой для перекрестков, 1 слой для грунтовых дорог, 1 слой для асфальтированных дорог);
Метамодели
Сиамские сети для уточнения предсказаний моделей на "широких" и "узких" масок тоже не сработали. Что интересно — предсказания моделей на "широких" масках выглядели гораздо лучше, но графы получались хуже.
Пайплайны
- 3 или 8 канальные изображения показали себя более менее одинаково;
- Развороты на 90 градусов, горизонтальные и вертикальные перевороты, небольшие аффинные преобразования снижали лосс еще на 15-20%;
- Моя лучшая модель была на полном разрешении, но случайные кропы 800x800 отрабатывались тоже хорошо;
Ансамблирование
3x фолда + 4x TTA ни дало никакого прироста в моем случае.
Еще всякие идеи, которые по видимому давали буст на LB моим конкурентам
- LinkNet34 (LinkNet + Resnet) => Inception encoder — +20-30k (я хотел попробовать Inception Resnet, но после ряда неудач отчаялся и не попробовал);
- На трейне — обучение на полном разрешении. На inference: downsize => predict => upsize => ensemble — +10-20k;
- Пост обработка графов и доведение их до краев тайлов — +20-30k;
- RGB изображения (в противовес MUL) — +10-15k из-за того что исходные данные были неконсистентными;
- 4 BCE + 1 DICE, мониторинг hard DICE в качестве метрики — +10-30k.

Главный косяк. Никто так и не решил эту проблему, насколько я знаю. Широкие маски возможно решили бы — но графы из них получались не очень.

Основная причина почему широкие маски косячат — они производят полипы и осьминогов =)

Та же проблема

Париж — плохая разметка. Лесные области — также косячный кейс

Многоуровневые дороги — предсказание широкой модели против узкой

Модель придумала дороги поверх парковки =)

Иногда PyTorch глючил и рождал на свет такие артефакты
5. Построение графов и основные косячные кейсы
Ключевой ингредиент это Skeleton Network + добавить ребра графа для кривых дорог (спасибо Dmytro за его совет!). Одно это скорее всего гарантировало, что вы будете в топ-10.


Без этих шагов все маски выглядели вот так
Альтернативные пайплайны, которые я попробовал
- Скелетонизация+ corner detection из skimage
- Некоторая вариация dilation отсюда
- Все это производило какие-то ребра, но Skeleton Network все равно гораздо лучше
Дополнительные штуки, что иногда помогали другим участникам
- Dilation как пред и пост обработка;
- Доводить ребра графа до краев клеток;

Тулза для визуализации от оргов
6. Конечное решение

По сути замена для TLDR
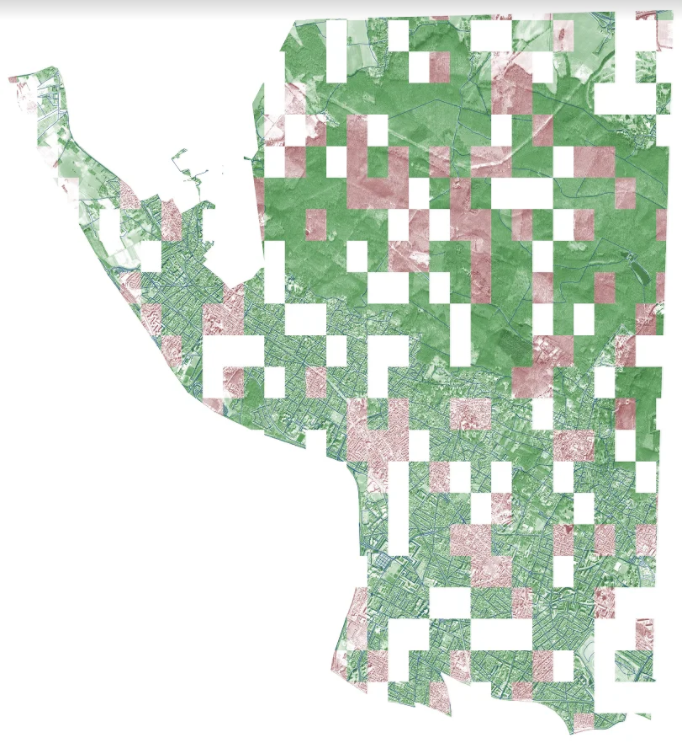
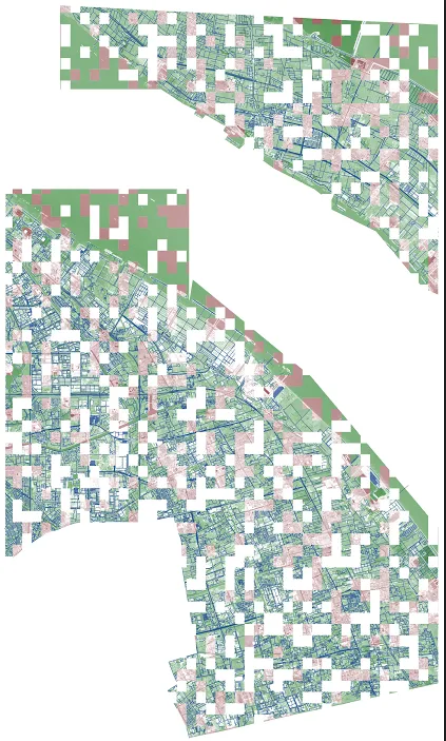
7. Красивая визуализация — тайлы для всех городов собранные вместе
Следуя традиции из последнего соревнования, один человек из чата сделал полноразмерные картинки города из геоклеток, используя геоданные из tif изображений.
Рассмотреть их в высоком разрешении можно по клику на них.
Vegas
Paris
Shanghai
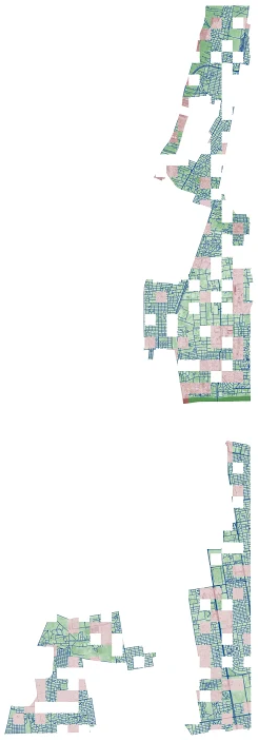
Khartoum
- Cайт соревнования
- Skeleton Network — библиотека преобразования маски в граф
- SpaceNet Road Detection and Routing Challenge — длинный пост про метрики соревнования
- Part II — вторая часть про метрики
- https://github.com/CosmiQ/apls — репозиторий для оценки метрики
- Pan Sharpening Images. — Rose G.
- Космическая съёмка Земли — habr
- Road Extraction by Deep Residual U-Net. — Zhengxin Zhang, Qingjie Liu, Yunhong Wang
- Focal Loss for Dense Object Detection. — Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, Piotr Dollár
- LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation. — Abhishek Chaurasia, Eugenio Culurciello
- Kaggle: анализ местности Амазонки по спутниковым снимкам — habr
- Dstl Satellite Imagery Competition, 1st Place Winner's Interview: Kyle Lee
- Planet: Understanding the Amazon from Space, 1st Place Winner's Interview
- Two Sigma Financial Modeling Challenge, Winner's Interview: 2nd Place, Nima Shahbazi, Chahhou Mohamed
- Two Sigma Financial Modeling Code Competition, 5th Place Winners' Interview: Team Best Fitting | Bestfitting, Zero, & CircleCircle
- Single Image Haze Removal Using Dark Channel Prior. — Kaiming He, Jian Sun, Xiaoou Tang
- Semantic Segmentation using Fully Convolutional Networks over the years
