Несколько недель назад я обнаружил пост "Окисляем Source Maps с Rust и WebAssembly"
распространяющийся по Твиттеру и расказывающий о выигрыше в производительности от замены обычного JavaScript в библиотеке source-map на Rust, скомпилированный в WebAssembly.
Пост возбудил мой интерес не потому, что я большой фанат Rust или WASM, скорее потому что я всегда интересовался фичами языков и оптимизациями, которых не хватает Javascript для того чтобы достичь аналогичной производительности.
Так что я скачал библиотеку с GitHub и отправился в небольшое исследование производительности, которое я документирую здесь практически дословно.
Содержание
- Получение кода
- Профилируем версию на чистом JavaScript
- Оптимизируем сортировку – Адаптация аргументов
- Оптимизируем сортировку — Мономорфизация
- Оптимизируем разбор — Удаляем кэш сегментов
- Оптимизируем сортировку – Улучшения в алгоритмах
- Оптимизируем сортировку generatedMappings
- Оптимизируем разбор – Уменьшаем нагрузку на GC
- Оптимизируем разбор – Использование Uint8Array вместо строки
- Общие улучшения по сравнению с началом
- Сравнение с "окисленной" версией source-map
- Усвоенные уроки
- Послесловие
Получение кода
Для своих исследований я использую почти стандартную x64.release сборку V8, с коммита 69abb960c97606df99408e6869d66e014aa0fb51 от 20 января. Мое расхождение со стандартной конфигурацией заключается лишь в том, что я включил дизассемблер через GN-флаги, чтобы погружаться глубже в сгенерированный машинный код, если будет нужно.
╭─ ~/src/v8/v8 ‹master› ╰─$ gn args out.gn/x64.release --list --short --overrides-only is_debug = false target_cpu = "x64" use_goma = true v8_enable_disassembler = true
Затем я получил исходники модуля source-map от:
- коммит c97d38b, который был последним, обновившим
dist/source-map.jsперед началом внедрения Rust/WASM; - коммит 51cf770, который был последним коммитом на момент проведения исследования;
Профилируем версию на чистом JavaScript
Запуск бенчмарка для чистой JS-версии был прост:
╭─ ~/src/source-map/bench ‹ c97d38b› ╰─$ d8 bench-shell-bindings.js Parsing source map console.timeEnd: iteration, 4655.638000 console.timeEnd: iteration, 4751.122000 console.timeEnd: iteration, 4820.566000 console.timeEnd: iteration, 4996.942000 console.timeEnd: iteration, 4644.619000 [Stats samples: 5, total: 23868 ms, mean: 4773.6 ms, stddev: 161.22112144505135 ms]
Первой вещью, что я сделал, было выключение сериализационной части бенчмарка:
diff --git a/bench/bench-shell-bindings.js b/bench/bench-shell-bindings.js index 811df40..c97d38b 100644 --- a/bench/bench-shell-bindings.js +++ b/bench/bench-shell-bindings.js @@ -19,5 +19,5 @@ load("./bench.js"); print("Parsing source map"); print(benchmarkParseSourceMap()); print(); -print("Serializing source map"); -print(benchmarkSerializeSourceMap()); +// print("Serializing source map"); +// print(benchmarkSerializeSourceMap());
Затем я закинул это в линуксовый perf профилировщик:
╭─ ~/src/source-map/bench ‹perf-work› ╰─$ perf record -g d8 --perf-basic-prof bench-shell-bindings.js Parsing source map console.timeEnd: iteration, 4984.464000 ^C[ perf record: Woken up 90 times to write data ] [ perf record: Captured and wrote 24.659 MB perf.data (~1077375 samples) ]
Заметьте, что я передаю --perf-basic-prof флаг в бинарник d8, который заставляет V8 генерировать вспомогательный файл маппингов /tmp/perf-$pid.map. Этот файл позволяет perf report понимать JIT-генерированный машинный код.
Вот что я получаю от perf report --no-children после при просмотре основного потока исполнения:
Overhead Symbol 17.02% *doQuickSort ../dist/source-map.js:2752 11.20% Builtin:ArgumentsAdaptorTrampoline 7.17% *compareByOriginalPositions ../dist/source-map.js:1024 4.49% Builtin:CallFunction_ReceiverIsNullOrUndefined 3.58% *compareByGeneratedPositionsDeflated ../dist/source-map.js:1063 2.73% *SourceMapConsumer_parseMappings ../dist/source-map.js:1894 2.11% Builtin:StringEqual 1.93% *SourceMapConsumer_parseMappings ../dist/source-map.js:1894 1.66% *doQuickSort ../dist/source-map.js:2752 1.25% v8::internal::StringTable::LookupStringIfExists_NoAllocate 1.22% *SourceMapConsumer_parseMappings ../dist/source-map.js:1894 1.21% Builtin:StringCharAt 1.16% Builtin:Call_ReceiverIsNullOrUndefined 1.14% v8::internal::(anonymous namespace)::StringTableNoAllocateKey::IsMatch 0.90% Builtin:StringPrototypeSlice 0.86% Builtin:KeyedLoadIC_Megamorphic 0.82% v8::internal::(anonymous namespace)::MakeStringThin 0.80% v8::internal::(anonymous namespace)::CopyObjectToObjectElements 0.76% v8::internal::Scavenger::ScavengeObject 0.72% v8::internal::String::VisitFlat<v8::internal::IteratingStringHasher> 0.68% *SourceMapConsumer_parseMappings ../dist/source-map.js:1894 0.64% *doQuickSort ../dist/source-map.js:2752 0.56% v8::internal::IncrementalMarking::RecordWriteSlow
Действительно, как и говорилось в посте "Окисляем Source Maps ...", этот бенчмарк в основном нагружет сортировку: функция doQuickSort появляется на вершине профиля, а также несколько раз ниже по списку (что означает, что она была оптимизирована и деоптимизирована несколько раз).
Оптимизируем сортировку – адаптация аргументов
Один момент, который выделяется в профайлере – подозрительные записи, а именно Builtin:ArgumentsAdaptorTrampoline и Builtin:CallFunction_ReceiverIsNullOrUndefined, которые, похоже, являются частью имплементации V8. Если мы попросим perf report раскрыть ведущие к ним цепочки вызовов, мы заметим, что эти функции в основном вызываются из кода сортировки:
- Builtin:ArgumentsAdaptorTrampoline + 96.87% *doQuickSort ../dist/source-map.js:2752 + 1.22% *SourceMapConsumer_parseMappings ../dist/source-map.js:1894 + 0.68% *SourceMapConsumer_parseMappings ../dist/source-map.js:1894 + 0.68% Builtin:InterpreterEntryTrampoline + 0.55% *doQuickSort ../dist/source-map.js:2752 - Builtin:CallFunction_ReceiverIsNullOrUndefined + 93.88% *doQuickSort ../dist/source-map.js:2752 + 2.24% *SourceMapConsumer_parseMappings ../dist/source-map.js:1894 + 2.01% Builtin:InterpreterEntryTrampoline + 1.49% *SourceMapConsumer_parseMappings ../dist/source-map.js:1894
А вот и время взглянуть на код. Реализация быстрой сортировки располагается в lib/quick-sort.js и вызывается из кода парсера в lib/source-map-consumer.js.
Функции сравнения (компараторы), используемые для сортировки, – это compareByGeneratedPositionsDeflated и compareByOriginalPositions.
Глядя на определения этих функций сравнения и на способ их вызова в реализации быстрой сортировки, оказывается, что места вызовов имеют несовпадающую арность (arity):
function compareByOriginalPositions(mappingA, mappingB, onlyCompareOriginal) { // ... } function compareByGeneratedPositionsDeflated(mappingA, mappingB, onlyCompareGenerated) { // ... } function doQuickSort(ary, comparator, p, r) { // ... if (comparator(ary[j], pivot) <= 0) { // ... } // ... }
Просмотр исходников библиотеки показывает, что вне тестов quickSort вызывается лишь только с этими двумя функциями.
А что если мы исправим арность?
diff --git a/dist/source-map.js b/dist/source-map.js index ade5bb2..2d39b28 100644 --- a/dist/source-map.js +++ b/dist/source-map.js @@ -2779,7 +2779,7 @@ return /* **** */ (function(modules) { // webpackBootstrap // // * Every element in `ary[i+1 .. j-1]` is greater than the pivot. for (var j = p; j < r; j++) { - if (comparator(ary[j], pivot) <= 0) { + if (comparator(ary[j], pivot, false) <= 0) { i += 1; swap(ary, i, j); }
[Примечание: Я делаю правки напрямую в dist/source-map.js потому что не хотел тратить время на разбирательство с процессом сборки]
╭─ ~/src/source-map/bench ‹perf-work› [Fix comparator invocation arity] ╰─$ d8 bench-shell-bindings.js Parsing source map console.timeEnd: iteration, 4037.084000 console.timeEnd: iteration, 4249.258000 console.timeEnd: iteration, 4241.165000 console.timeEnd: iteration, 3936.664000 console.timeEnd: iteration, 4131.844000 console.timeEnd: iteration, 4140.963000 [Stats samples: 6, total: 24737 ms, mean: 4122.833333333333 ms, stddev: 132.18789657150916 ms]
Простым исправлением несовпадения арности мы улучшили значения V8 в бенчмарке на 14% с 4774 мс до 4123 мс. Если мы запрофилируем бенчмарк снова, то мы обнаружим, что ArgumentsAdaptorTrampoline полностью исчез оттуда. Так почему он там был в первый раз?
Оказывается, что ArgumentsAdaptorTrampoline — это механизм V8 для поддержки джаваскриптовой вариантивности вызовов: вы можете вызвать функцию от трех аргументов всего с двумя — в этом случае третий аргумент будет заполнен значением undefined. V8 делает это созданием нового фрейма в стеке, копируя туда аргументы, затем вызывает целевую функцию:

[Если вы никогда не слышали о стеке исполнения, то ознакомьтесь с Википедией и постом Франциски Хинкельманн.]
В то время как такие затраты могут быть незначительны для холодного кода, здесь comparator был вызван миллионы раз в течение запуска бенчмарка, что вызвало дополнительные расходы на адаптацию аргументов.
Внимательный читатель также может заметить, что мы явно передаем значение false туда, где раньше использовалось неявное undefined. Это, кажется, тоже вносит вклад в улучшение производительности. Если мы заменим false на void 0, то мы получим немного худшие значения:
diff --git a/dist/source-map.js b/dist/source-map.js index 2d39b28..243b2ef 100644 --- a/dist/source-map.js +++ b/dist/source-map.js @@ -2779,7 +2779,7 @@ return /* **** */ (function(modules) { // webpackBootstrap // // * Every element in `ary[i+1 .. j-1]` is greater than the pivot. for (var j = p; j < r; j++) { - if (comparator(ary[j], pivot, false) <= 0) { + if (comparator(ary[j], pivot, void 0) <= 0) { i += 1; swap(ary, i, j); }
╭─ ~/src/source-map/bench ‹perf-work U› [Fix comparator invocation arity] ╰─$ ~/src/v8/v8/out.gn/x64.release/d8 bench-shell-bindings.js Parsing source map console.timeEnd: iteration, 4215.623000 console.timeEnd: iteration, 4247.643000 console.timeEnd: iteration, 4425.871000 console.timeEnd: iteration, 4167.691000 console.timeEnd: iteration, 4343.613000 console.timeEnd: iteration, 4209.427000 [Stats samples: 6, total: 25610 ms, mean: 4268.333333333333 ms, stddev: 106.38947316346669 ms]
Как бы то ни было, адаптация аргументов кажется очень специфичной для V8. Когда я запускал бенчмарк для SpiderMonkey, я не увидел никакого значительного прироста производительности от совпадающей арности:
╭─ ~/src/source-map/bench ‹ d052ea4› [Disabled serialization part of the benchmark] ╰─$ sm bench-shell-bindings.js Parsing source map [Stats samples: 8, total: 24751 ms, mean: 3093.875 ms, stddev: 327.27966571700836 ms] ╭─ ~/src/source-map/bench ‹perf-work› [Fix comparator invocation arity] ╰─$ sm bench-shell-bindings.js Parsing source map [Stats samples: 8, total: 25397 ms, mean: 3174.625 ms, stddev: 360.4636187025859 ms]
[Оболочка SpiderMonkey теперь очень проста в установке, спасибо Матиасу Байенсу за инструемент jsvu]
Давайте вернемся обратно к коду сортировки. Если мы попрофилируем бенчмарк снова, то мы заметим что ArgumentsAdaptorTrampoline исчез из профиля, но CallFunction_ReceiverIsNullOrUndefined все еще здесь. Это не удивительно, ведь мы все еще вызываем comparator.
Оптимизируем сортировку — Мономорфизация
Что обычно исполняется быстрее, чем вызов функции? Его отсутствие!
Очевидный вариант здесь, это попытаться встроить функцию сравнения в doQuickSort. Однако, у нас на пути встает тот факт, что doQuickSort вызывается с разными функциями.
Чтобы это обойти, мы попробуем мономорфизировать doQuickSort путем клонирования. Вот как мы это сделаем.
Начнем с оборачивания doQuickSort и других вспомогательных утилит в функцию SortTemplate:
function SortTemplate(comparator) { function swap(ary, x, y) { // ... } function randomIntInRange(low, high) { // ... } function doQuickSort(ary, p, r) { // ... } return doQuickSort; }
Затем мы сможем производить клоны наших сортировочных процедур путем конвертации SortTemplate в строку, передачи и разбора обратно в функцию через конструктор Function:
function cloneSort(comparator) { let template = SortTemplate.toString(); let templateFn = new Function(`return ${template}`)(); return templateFn(comparator); // Invoke template to get doQuickSort }
Теперь мы можем использовать cloneSort, чтобы производить функцию сортировки для каждого используемого компаратора:
let sortCache = new WeakMap(); // Cache for specialized sorts. exports.quickSort = function (ary, comparator) { let doQuickSort = sortCache.get(comparator); if (doQuickSort === void 0) { doQuickSort = cloneSort(comparator); sortCache.set(comparator, doQuickSort); } doQuickSort(ary, 0, ary.length - 1); };
Перезапуск бенчмарка выдает нам:
╭─ ~/src/source-map/bench ‹perf-work› [Clone sorting functions for each comparator] ╰─$ d8 bench-shell-bindings.js Parsing source map console.timeEnd: iteration, 2955.199000 console.timeEnd: iteration, 3084.979000 console.timeEnd: iteration, 3193.134000 console.timeEnd: iteration, 3480.459000 console.timeEnd: iteration, 3115.011000 console.timeEnd: iteration, 3216.344000 console.timeEnd: iteration, 3343.459000 console.timeEnd: iteration, 3036.211000 [Stats samples: 8, total: 25423 ms, mean: 3177.875 ms, stddev: 181.87633161024556 ms]
Мы видим, что среднее время опустилось с 4268 мс до 3177 мс (25% улучшения).
Профилирование показывает следующую картину:
Overhead Symbol 14.95% *doQuickSort :44 11.49% *doQuickSort :44 3.29% Builtin:StringEqual 3.13% *SourceMapConsumer_parseMappings ../dist/source-map.js:1894 1.86% v8::internal::StringTable::LookupStringIfExists_NoAllocate 1.86% *SourceMapConsumer_parseMappings ../dist/source-map.js:1894 1.72% Builtin:StringCharAt 1.67% *SourceMapConsumer_parseMappings ../dist/source-map.js:1894 1.61% v8::internal::Scavenger::ScavengeObject 1.45% v8::internal::(anonymous namespace)::StringTableNoAllocateKey::IsMatch 1.23% Builtin:StringPrototypeSlice 1.17% v8::internal::(anonymous namespace)::MakeStringThin 1.08% Builtin:KeyedLoadIC_Megamorphic 1.05% v8::internal::(anonymous namespace)::CopyObjectToObjectElements 0.99% v8::internal::String::VisitFlat<v8::internal::IteratingStringHasher> 0.86% clear_page_c_e 0.77% v8::internal::IncrementalMarking::RecordWriteSlow 0.48% Builtin:MathRandom 0.41% Builtin:RecordWrite 0.39% Builtin:KeyedLoadIC
Накладные расходы связанные с вызовом comparator теперь полностью исчезли из профиля.
В этот момент мне стало интересно, насколько больше времени мы тратим на разбор маппингов по сравнению с их сортировкой. Я перешел к коду разбора и добавил несколько вызовов Date.now():
[Я бы хотел добавить performance.now(), но оболочка SpiderMonkey этого не поддерживает.]
diff --git a/dist/source-map.js b/dist/source-map.js index 75ebbdf..7312058 100644 --- a/dist/source-map.js +++ b/dist/source-map.js @@ -1906,6 +1906,8 @@ return /* **** */ (function(modules) { // webpackBootstrap var generatedMappings = []; var mapping, str, segment, end, value; + + var startParsing = Date.now(); while (index < length) { if (aStr.charAt(index) === ';') { generatedLine++; @@ -1986,12 +1988,20 @@ return /* **** */ (function(modules) { // webpackBootstrap } } } + var endParsing = Date.now(); + var startSortGenerated = Date.now(); quickSort(generatedMappings, util.compareByGeneratedPositionsDeflated); this.__generatedMappings = generatedMappings; + var endSortGenerated = Date.now(); + var startSortOriginal = Date.now(); quickSort(originalMappings, util.compareByOriginalPositions); this.__originalMappings = originalMappings; + var endSortOriginal = Date.now(); + + console.log(`${}, ${endSortGenerated - startSortGenerated}, ${endSortOriginal - startSortOriginal}`); + console.log(`sortGenerated: `); + console.log(`sortOriginal: `); };
Получился такой результат:
╭─ ~/src/source-map/bench ‹perf-work U› [Clone sorting functions for each comparator] ╰─$ d8 bench-shell-bindings.js Parsing source map parse: 1911.846 sortGenerated: 619.5990000000002 sortOriginal: 905.8220000000001 parse: 1965.4820000000004 sortGenerated: 602.1939999999995 sortOriginal: 896.3589999999995 ^C
А так времена разбора и сортировки выглядят в V8 и SpiderMonkey на каждую итерацию запуска бенчмарка:
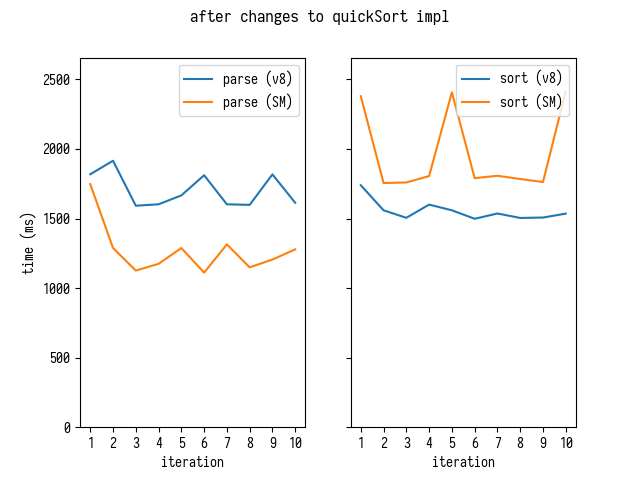
В V8 мы, кажется, тратим примерно столько же времени на разбор маппингов, как и на их сортировку. В SpiderMonkey разбор значительно быстрее, — но медленнее сортировка. Это сподвигло меня посмотреть на код разбора.
Оптимизируем разбор — Удаляем кэш сегментов
Давайте посмотрим на профиль еще раз:
Overhead Symbol 18.23% *doQuickSort :44 12.36% *doQuickSort :44 3.84% *SourceMapConsumer_parseMappings ../dist/source-map.js:1894 3.07% Builtin:StringEqual 1.92% v8::internal::StringTable::LookupStringIfExists_NoAllocate 1.85% *SourceMapConsumer_parseMappings ../dist/source-map.js:1894 1.59% *SourceMapConsumer_parseMappings ../dist/source-map.js:1894 1.54% Builtin:StringCharAt 1.52% v8::internal::(anonymous namespace)::StringTableNoAllocateKey::IsMatch 1.38% v8::internal::Scavenger::ScavengeObject 1.27% Builtin:KeyedLoadIC_Megamorphic 1.22% Builtin:StringPrototypeSlice 1.10% v8::internal::(anonymous namespace)::MakeStringThin 1.05% v8::internal::(anonymous namespace)::CopyObjectToObjectElements 1.03% v8::internal::String::VisitFlat<v8::internal::IteratingStringHasher> 0.88% clear_page_c_e 0.51% Builtin:MathRandom 0.48% Builtin:KeyedLoadIC 0.46% v8::internal::IteratingStringHasher::Hash 0.41% Builtin:RecordWrite
Удаление JavaScript-кода, который мы уже знаем, оставляет нам следующее:
Overhead Symbol 3.07% Builtin:StringEqual 1.92% v8::internal::StringTable::LookupStringIfExists_NoAllocate 1.54% Builtin:StringCharAt 1.52% v8::internal::(anonymous namespace)::StringTableNoAllocateKey::IsMatch 1.38% v8::internal::Scavenger::ScavengeObject 1.27% Builtin:KeyedLoadIC_Megamorphic 1.22% Builtin:StringPrototypeSlice 1.10% v8::internal::(anonymous namespace)::MakeStringThin 1.05% v8::internal::(anonymous namespace)::CopyObjectToObjectElements 1.03% v8::internal::String::VisitFlat<v8::internal::IteratingStringHasher> 0.88% clear_page_c_e 0.51% Builtin:MathRandom 0.48% Builtin:KeyedLoadIC 0.46% v8::internal::IteratingStringHasher::Hash 0.41% Builtin:RecordWrite
Когда я начал смотреть на цепочки вызовов для отдельных записей, я обнаружил, что немало из них проходит через KeyedLoadIC_Megamorphic в SourceMapConsumer_parseMappings.
- 1.92% v8::internal::StringTable::LookupStringIfExists_NoAllocate - v8::internal::StringTable::LookupStringIfExists_NoAllocate + 99.80% Builtin:KeyedLoadIC_Megamorphic - 1.52% v8::internal::(anonymous namespace)::StringTableNoAllocateKey::IsMatch - v8::internal::(anonymous namespace)::StringTableNoAllocateKey::IsMatch - 98.32% v8::internal::StringTable::LookupStringIfExists_NoAllocate + Builtin:KeyedLoadIC_Megamorphic + 1.68% Builtin:KeyedLoadIC_Megamorphic - 1.27% Builtin:KeyedLoadIC_Megamorphic - Builtin:KeyedLoadIC_Megamorphic + 57.65% *SourceMapConsumer_parseMappings ../dist/source-map.js:1894 + 22.62% *SourceMapConsumer_parseMappings ../dist/source-map.js:1894 + 15.91% *SourceMapConsumer_parseMappings ../dist/source-map.js:1894 + 2.46% Builtin:InterpreterEntryTrampoline + 0.61% BytecodeHandler:Mul + 0.57% *doQuickSort :44 - 1.10% v8::internal::(anonymous namespace)::MakeStringThin - v8::internal::(anonymous namespace)::MakeStringThin - 94.72% v8::internal::StringTable::LookupStringIfExists_NoAllocate + Builtin:KeyedLoadIC_Megamorphic + 3.63% Builtin:KeyedLoadIC_Megamorphic + 1.66% v8::internal::StringTable::LookupString
Такая сортировка стеков вызова просигналила мне, что код исполняет множество сопоставлений по ключу в виде obj[key], где key — это динамически сформированная строка. Когда я глянул в исходник, то обнаружил следующий код:
// Because each offset is encoded relative to the previous one, // many segments often have the same encoding. We can exploit this // fact by caching the parsed variable length fields of each segment, // allowing us to avoid a second parse if we encounter the same // segment again. for (end = index; end < length; end++) { if (this._charIsMappingSeparator(aStr, end)) { break; } } str = aStr.slice(index, end); segment = cachedSegments[str]; if (segment) { index += str.length; } else { segment = []; while (index < end) { base64VLQ.decode(aStr, index, temp); value = temp.value; index = temp.rest; segment.push(value); } // ... cachedSegments[str] = segment; }
Этот код отвечает за раскодирование Base64 VLQ-кодированных последовательностей, то есть строка A будет раскодирована как [0], а UAAAA раскодируется в [10,0,0,0,0]. Я предлагаю посмотреть этот пост про внутренности source maps, если вы желаете лучше понять сам процесс кодировки.
Вместо того чтобы раскодировать каждую последовательность независимо, этот код пытается кэшировать расшифрованные сегменты: смотрит вперед до разделителя (, или ;), затем извлекает подстроку от текущей позиции до разделителя и проверяет, есть ли у нас уже такой сегмент в кэше — и если таковой нашелся, то вернет закэшированный сегмент, в противном случае, он разбирает его и кладет в кэш.
Кэширование (оно же мемоизация) – это очень сильная техника оптимизации — однако, она имеет смысл только если обслуживание самого кэша и поиск там результатов оказывается дешевле, чем собственно сам расчёт заново.
Абстрактный анализ
Давайте попробуем абстрактно сравнить эти две операции:
С одной стороны чистый разбор:
Разбирая сегмент, мы смотрим на каждый символ по одному разу. Для кадого символа производится несколько сравнений и арифметических операций, чтобы сконвертировать base64 символ в целочисленное значение. Затем производится несколько побитовых операций, чтобы объединить эти численные значения в одно большое. Затем раскордированное значение сохраняется в массив и мы переходим к следующей части сегмента. Сегменты ограничены пятью элементами.
С другой стороны кэширование:
- Чтобы найти закэшироваенное значение, мы обходим все символы сегмента один раз чтобы найти его конец;
- Мы извлекаем подстроку, которая требует размещения и, возможно, копирования, в зависимости от того, как строки реализованы в JS VM.
- Мы используем эту строку как ключ для словаря, который:
- Сначала требует от VM рассчитать хэш для этой строки (проходя её ещё раз и выполняя различные побитовые операции на символах), это также может потребовать от VM интернализовать строку (в зависимости от реализации).
- Затем VM должна выполнить сопоставление хэша по таблице, что требует обращения и сравнения ключа по значению с другими ключами (это может потребовать просмотра отдельных символов еще раз);
В целом это выглядит так, что прямой разбор будет быстрее, подразумевая, что JS VM хорошо работает с отдельными арифметическими и побитовыми операциями, просто потому, что он смотрит на каждый символ только раз, в то время как кэширование требует обхода сегмента 2-4 раза, просто чтобы установить, попали ли мы в кэш или нет.
Профилирование похоже подтверждает это тоже: KeyedLoadIC_Megamorphic используется в V8 для реализации обращения по ключу, вроде cachedSegments[str] в коде сверху.
Основываясь на этих наблюдениях, я провел несколько экспериментов. Во-первых я проверил, насколько большой кэш cachedSegments в конце разбора. Чем он меньше, тем более эффективным могло бы быть кэширование.
Оказывается, что он вырастает довольно сильно:
Object.keys(cachedSegments).length = 155478
Отдельные микробенчмарки
Теперь я решил написать маленький отдельный бенчмарк:
// Генерируем строку с [n] сегментами, сегменты повторяются в цикле длиной [v], // т.е. сегменты 0, v, 2*v, ... равны, так же как и 1, 1 + v, 1 + 2*v, ... // [base] используется как базовое значение сегмента - этот параметр позволяет // делать сегменты длинными // // Примечание: чем больше [v], тем больше кэш [cachedSegments] function makeString(n, v, base) { var arr = []; for (var i = 0; i < n; i++) { arr.push([0, base + (i % v), 0, 0].map(base64VLQ.encode).join('')); } return arr.join(';') + ';'; } // Запустить функцию [f] для строки [str]. function bench(f, str) { for (var i = 0; i < 1000; i++) { f(str); } } // Измерить и сообщить прозводительность [f] для [str]. // Это делается для [v] разных сегментов function measure(v, str, f) { var start = Date.now(); bench(f, str); var end = Date.now(); report(`${v}, ${f.name}, ${(end - start).toFixed(2)}`); } async function measureAll() { for (let v = 1; v <= 256; v *= 2) { // Создать строку с 1000 сегментов в целом и [v] уникальных, // так что [cachedSegments] будет иметь [v] зашекированных значений. let str = makeString(1000, v, 1024 * 1024); let arr = encoder.encode(str); // Запустить 10 итераций для каждого способа декодирования. for (var j = 0; j < 10; j++) { measure(j, i, str, decodeCached); measure(j, i, str, decodeNoCaching); measure(j, i, str, decodeNoCachingNoStrings); measure(j, i, arr, decodeNoCachingNoStringsPreEncoded); await nextTick(); } } } function nextTick() { return new Promise((resolve) => setTimeout(resolve)); }
Здесь даны три различных способа декодировать сегменты Base64 VLQ, которые я тестировал.
Первый — decodeCached это то же самое, что и стандартная реализация в source-map — которую я уже показал выше:
function decodeCached(aStr) { var length = aStr.length; var cachedSegments = {}; var end, str, segment, value, temp = {value: 0, rest: 0}; const decode = base64VLQ.decode; var index = 0; while (index < length) { // Because each offset is encoded relative to the previous one, // many segments often have the same encoding. We can exploit this // fact by caching the parsed variable length fields of each segment, // allowing us to avoid a second parse if we encounter the same // segment again. for (end = index; end < length; end++) { if (_charIsMappingSeparator(aStr, end)) { break; } } str = aStr.slice(index, end); segment = cachedSegments[str]; if (segment) { index += str.length; } else { segment = []; while (index < end) { decode(aStr, index, temp); value = temp.value; index = temp.rest; segment.push(value); } if (segment.length === 2) { throw new Error('Found a source, but no line and column'); } if (segment.length === 3) { throw new Error('Found a source and line, but no column'); } cachedSegments[str] = segment; } index++; } }
Следующий участник — это decodeNoCaching. В основном то же самое, что и decodeCached, но без кэширования. Каждый сегмент декодируется независимо. Также я заменил Array на Int32Array для хранилища segment.
function decodeNoCaching(aStr) { var length = aStr.length; var cachedSegments = {}; var end, str, segment, temp = {value: 0, rest: 0}; const decode = base64VLQ.decode; var index = 0, value; var segment = new Int32Array(5); var segmentLength = 0; while (index < length) { segmentLength = 0; while (!_charIsMappingSeparator(aStr, index)) { decode(aStr, index, temp); value = temp.value; index = temp.rest; if (segmentLength >= 5) throw new Error('Too many segments'); segment[segmentLength++] = value; } if (segmentLength === 2) { throw new Error('Found a source, but no line and column'); } if (segmentLength === 3) { throw new Error('Found a source and line, but no column'); } index++; } }
И, наконец, третий вариант decodeNoCachingNoString пробует избежать работы с JavaScript-строками вообще, путем конвертирования строки в utf8-кодированный Uint8Array. Эта оптимизация вдохновлена тем, что, скорее всего, JS VM оптимизируют загрузку массива в единое место в памяти. Оптимизация String.prototype.charCodeAt до такого же уровня будет сложнее, ввиду сложности иерархии различных представлений строк, используемых JS VM.
Я измерил производительность обоих версий: той что раскодирует в строку в utf8 в рамках итерации, так и той что использует заранее раскодированную строку. С это второй "оптимистичной" версией я стараюсь оценить, как много мы могли бы выиграть, если бы смогли пропустить круг typed array ⇒ string ⇒ typed array. Что было бы возможно, если бы мы загружали source map напрямую в array buffer и разбирали её прямо из этого буфера, вместо того чтобы сначала раскодировать в строку.
let encoder = new TextEncoder(); function decodeNoCachingNoString(aStr) { decodeNoCachingNoStringPreEncoded(encoder.encode(aStr)); } function decodeNoCachingNoStringPreEncoded(arr) { var length = arr.length; var cachedSegments = {}; var end, str, segment, temp = {value: 0, rest: 0}; const decode2 = base64VLQ.decode2; var index = 0, value; var segment = new Int32Array(5); var segmentLength = 0; while (index < length) { segmentLength = 0; while (arr[index] != 59 && arr[index] != 44) { decode2(arr, index, temp); value = temp.value; index = temp.rest; if (segmentLength < 5) { segment[segmentLength++] = value; } } if (segmentLength === 2) { throw new Error('Found a source, but no line and column'); } if (segmentLength === 3) { throw new Error('Found a source and line, but no column'); } index++; } }
Вот результаты, что я получил запуская свой микробенчмарк в Chrome Dev
66.0.3343.3 (V8 6.6.189) и Firefox Nightly 60.0a1 (2018-02-11):
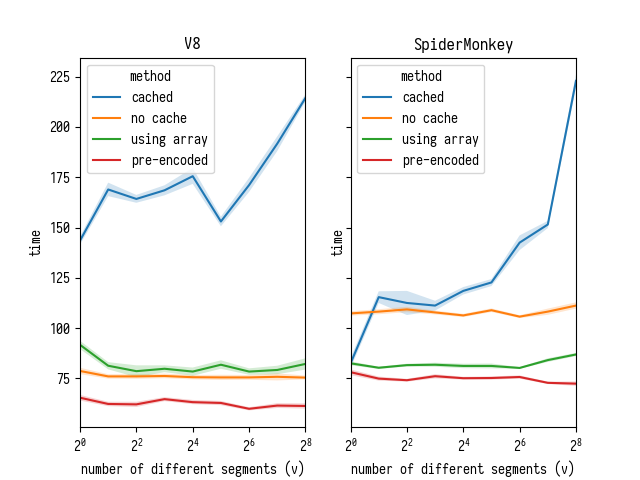
Здесь можно заметить два момента:
- Версия, которая использует кэширование, медленнее всех и в V8, и в SpiderMonkey. Её производительность круто проседает с ростом записей в кэше — в то время как прозводительность версий без кэша от этого не зависит;
- В SpiderMonkey окупается конвертация строки в типизированный массив как часть разбора, однако, в V8 доступ к символам достаточно быстр — так что это окупится только если мы вынесем преобразование "строка-в-массив" за пределы бенчмарка (т.е. вы загружете свои данные в типизированный массив с самого начала);
Мне стало интересно, не делала ли команда V8 недавно каких-то улучшений в скорости charCodeAt – как я ясно помню, Crankshaft никогда не пытался специализировать charCodeAt на конкретном представлении строки в месте вызова, используя вместо этого расширенный charCodeAt, обрабатывающий множество различиных представлений, делая загрузку символов из строк медленнее, чем элементов из типизированных массивов.
Я пробежался по баг-трекеру V8 и нашел несколько активных репортов:
- Issue 6391: StringCharCodeAt slower than Crankshaft;
- Issue 7092: High overhead of String.prototype.charCodeAt in typescript test;
- Issue 7326: Performance degradation when looping across character codes of a string;
Некоторые из комментариев там ссылаются на коммиты от конца января 2018 года и свежее, что свидетельствует о том, что производительность charCodeAt активно улучшается. Из любопытства я решил перезапустить свой бенчмарк в Chrome Beta и сравнить с Chrome Dev.
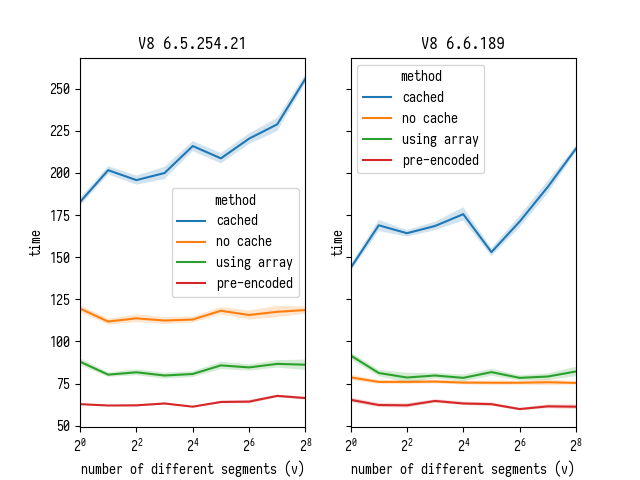
Это сравнение фактически подтверждает, что все эти коммиты от команды V8 были не зря: производительность charCodeAt кардинально улучшилась от версии 6.5.254.21 к 6.6.189. Сравнивая линии "no cache" и "using array", мы можем видить, что charCodeAt в старом V8 вел себя намного хуже, что это имело смысл конвертировать строку в Uint8Array, просто чтобы сделать обращение быстрее. Однако, накладные расходы от этого преобразования внутри разбора больше не окупаются в более новом V8.
Однако, использование массива вместо строки все ещё окупается, если нам не нужно тратиться на конвертацию. Почему так? Чтобы это выяснить, я запустил следующий код внутри V8:
function foo(str, i) { return str.charCodeAt(i); } let str = "fisk"; foo(str, 0); foo(str, 0); foo(str, 0); %OptimizeFunctionOnNextCall(foo); foo(str, 0);
╭─ ~/src/v8/v8 ‹master› ╰─$ out.gn/x64.release/d8 --allow-natives-syntax --print-opt-code --code-comments x.js
Команда произвела гинантский листинг ассемблера, подтверждающий мое подозрение, что V8 всё ещё не специализирует charCodeAt на конкретное представление строки. Снижение, кажется, приходит из этого кода в исходниках V8, который раскрывает тайну, почему доступ к массиву всё ещё быстрее чем строковый charCodeAt.
Улучшения в разборе
В свете этих открытий, давайте удалим кеширование разобранных сегментов из кода source-map и измерим эффект.
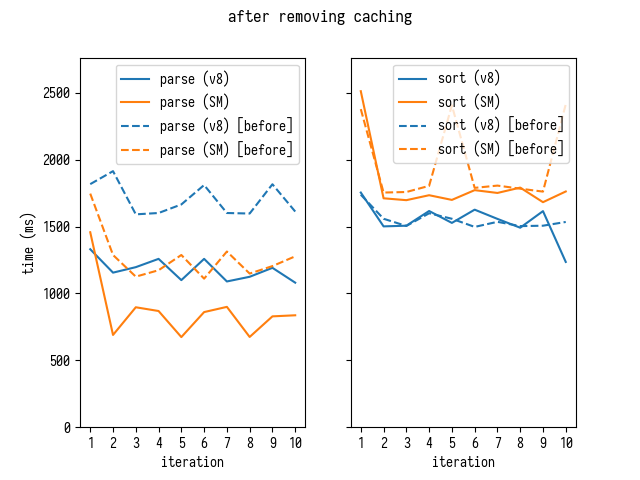
Прямо как наш микробенчмарк и предсказал, кэширование скорее вредило общей производительности, чем помогало: его удаление в самом деле значительно улучшило времена разбора.
Оптимизируем сортировку – Улучшения в алгоритмах
После того как мы улучшили скорость разбора, давайте глянем еще раз на сортировку.
Тут сортируются два массива:
originalMappingsсортируется с использованием компаратораcompareByOriginalPositions;generatedMappingsсортируется с использованиемcompareByGeneratedPositionsDeflated.
Оптимизируем сортировку originalMappings
Сперва я взглянул на compareByOriginalPositions.
function compareByOriginalPositions(mappingA, mappingB, onlyCompareOriginal) { var cmp = strcmp(mappingA.source, mappingB.source); if (cmp !== 0) { return cmp; } cmp = mappingA.originalLine - mappingB.originalLine; if (cmp !== 0) { return cmp; } cmp = mappingA.originalColumn - mappingB.originalColumn; if (cmp !== 0 || onlyCompareOriginal) { return cmp; } cmp = mappingA.generatedColumn - mappingB.generatedColumn; if (cmp !== 0) { return cmp; } cmp = mappingA.generatedLine - mappingB.generatedLine; if (cmp !== 0) { return cmp; } return strcmp(mappingA.name, mappingB.name); }
Я заметил, что маппинги упорядочены сперва по source компоненте, а затем уже по всем остальным. source обозначает, с какого исходного файла пришел маппинг. Приходит очевидная идея, что вместо использования гигантского плоского массива originalMappings, который смешивает маппинги от разных исходных файлов, мы можем превратить originalMappings в массив массивов: originalMappings[i] будет массивом маппингов из исходного файла под номером i. Таким образом, мы сначала отсортируем маппинги в различные массивы originalMappings[i] по источнику, по мере разбора, а затем отсортируем отдельные меньшие массивы.
[В принципе, это – блочная сортировка]
Вот что мы сделаем в цикле разбора:
if (typeof mapping.originalLine === 'number') { // Раньше этот код просто делал originalMappings.push(mapping). // Теперь он сортирует исходные маппинги по источнику сразу же во время разбора. let currentSource = mapping.source; while (originalMappings.length <= currentSource) { originalMappings.push(null); } if (originalMappings[currentSource] === null) { originalMappings[currentSource] = []; } originalMappings[currentSource].push(mapping); }
Затем еще здесь:
var startSortOriginal = Date.now(); // Код сортировал целый массив: // quickSort(originalMappings, util.compareByOriginalPositions); for (var i = 0; i < originalMappings.length; i++) { if (originalMappings[i] != null) { quickSort(originalMappings[i], util.compareByOriginalPositionsNoSource); } } var endSortOriginal = Date.now();
Компаратор compareByOriginalPositionsNoSource почти такой же как и compareByOriginalPositions за исключением того, что он не больше не сравнивает source компоненту — они гарантированно равны ввиду способа, которым мы собираем каждый массив originalMappings[i].
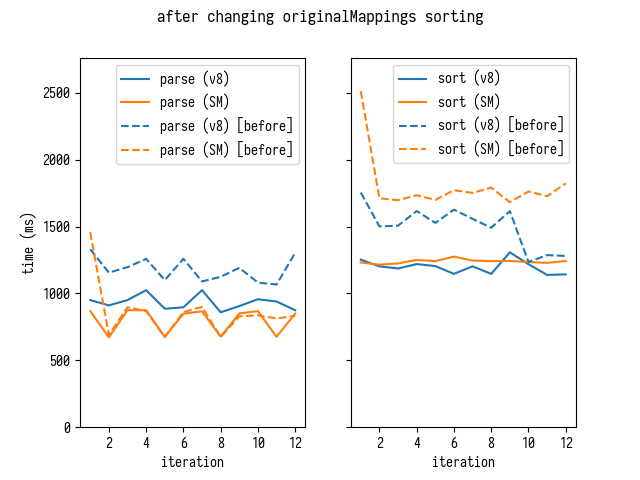
Это изменение алгоритма улучшает времена сортировки и в V8, и в SpiderMonkey, а также дополнительно улучшает время разбора в V8.
[Улучшение времени разбора скорее всего вызвано уменьшением затрат на управление массивом originalMappings: выращивать один гигантский массив originalMappings будет дороже, чем растить меньшие массивы originalMappings[i] по отдельности. Однако это всего лишь моя догадка, которая не подтверждена никаким надежным анализом.]
Оптимизируем сортировку generatedMappings
Давайте взглянем на generatedMappings и его компаратор compareByGeneratedPositionsDeflated.
function compareByGeneratedPositionsDeflated(mappingA, mappingB, onlyCompareGenerated) { var cmp = mappingA.generatedLine - mappingB.generatedLine; if (cmp !== 0) { return cmp; } cmp = mappingA.generatedColumn - mappingB.generatedColumn; if (cmp !== 0 || onlyCompareGenerated) { return cmp; } cmp = strcmp(mappingA.source, mappingB.source); if (cmp !== 0) { return cmp; } cmp = mappingA.originalLine - mappingB.originalLine; if (cmp !== 0) { return cmp; } cmp = mappingA.originalColumn - mappingB.originalColumn; if (cmp !== 0) { return cmp; } return strcmp(mappingA.name, mappingB.name); }
Здесь мы сперва сравниваем маппинги по generatedLine. Здесь, скорее всего, значительно больше сгенерированных строк, чем исходных файлов, так что это не имеет смысла разделять generatedMappings на множественные отдельные массивы.
Однако, затем я глянул на код разбора и заметил следующее:
while (index < length) { if (aStr.charAt(index) === ';') { generatedLine++; // ... } else if (aStr.charAt(index) === ',') { // ... } else { mapping = new Mapping(); mapping.generatedLine = generatedLine; // ... } }
Это единственные вхождения generatedLine в этом коде, что означает, что generatedLine монотонно растет, а зная, что generatedMappings уже отсортирован по generatedLine, не имеет смысла сортировать массив целиком. Вместо этого мы может сортировать каждый отдельный подмассив. Мы изменим код вот так:
let subarrayStart = 0; while (index < length) { if (aStr.charAt(index) === ';') { generatedLine++; // ... // Сортируем подмассив [subarrayStart, generatedMappings.length]. sortGenerated(generatedMappings, subarrayStart); subarrayStart = generatedMappings.length; } else if (aStr.charAt(index) === ',') { // ... } else { mapping = new Mapping(); mapping.generatedLine = generatedLine; // ... } } // Отсортируем оставшийся хвост sortGenerated(generatedMappings, subarrayStart);
Вместо использования быстрой сортировки для маленьких подмассивов я также решил взять сортировку вставками, похожую на гибридную стратегию, используемую некоторыми VM для Array.prototype.sort.
[Примечание: сортировка вставками также значительно быстрее чем быстрая сортировка, если входной массив уже отсортирован… и оказывается, что маппинги используемые в бенчмарке фактически отсортированы. Если мы ожидаем, что generatedMappings будет почти всегда отсортирован после разбора, то будет ещё более эффективно просто проверить, отсортирован ли generatedMappings, перед тем как пытаться его отсортировать.]
const compareGenerated = util.compareByGeneratedPositionsDeflatedNoLine; function sortGenerated(array, start) { let l = array.length; let n = array.length - start; if (n <= 1) { return; } else if (n == 2) { let a = array[start]; let b = array[start + 1]; if (compareGenerated(a, b) > 0) { array[start] = b; array[start + 1] = a; } } else if (n < 20) { for (let i = start; i < l; i++) { for (let j = i; j > start; j--) { let a = array[j - 1]; let b = array[j]; if (compareGenerated(a, b) <= 0) { break; } array[j - 1] = b; array[j] = a; } } } else { quickSort(array, compareGenerated, start); } }
Это выдает следующий результат:
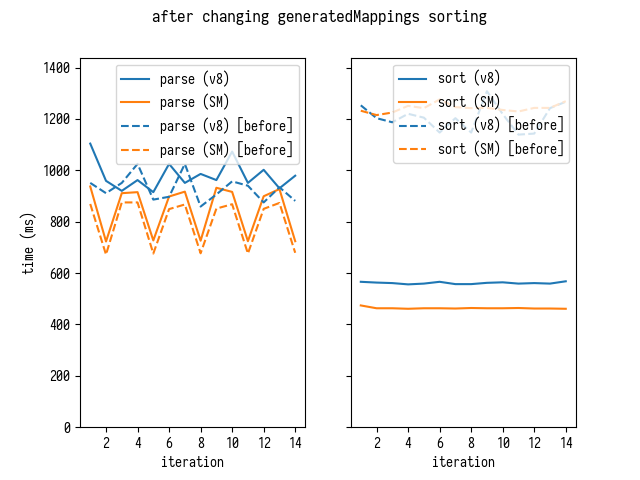
Времена сортировки падают значительно, в то время как времена разбора слегка увеличиваются – так получается, потому что код сортировки generatedMappings теперь часть цикла разбора, делая такое разделение немного бессмысленным. Давайте проверим суммарные времена (разбор и сортировка вместе)
Улучшения к общему времени
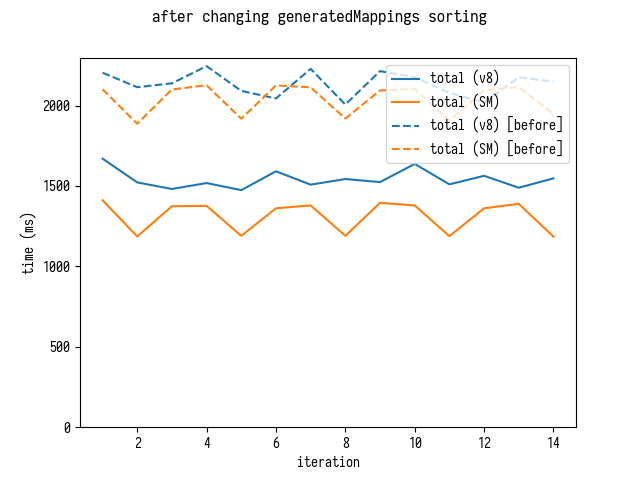
Теперь это очевидно, что мы значительно улучшили общую прозиводителньость разбора маппингов.
Есть ли здесь что-то еще, что мы можем сделать для улучшения прозиводительности?
Оказывается, да: мы можем стянуть один приём из книги рецептов asm.js / WASM, без перехода целиком на Rust в нашем JavaScript коде.
Оптимизируем разбор – уменьшаем нагрузку на GC
Мы размещаем сотни тысяч объектов Mapping, которые создают ощутимую нагрузку на сборщик мусора (GC) – однако, нам не нужны эти объекты в виде объектов – мы можем упаковать их в типизированный массив. Вот как я это сделал.
[Несколько лет назад я был в полном восторге от предложения типизированных объектов, которые позволили бы JavaScript-разработчикам определять структуры и массивы структур и другие замечательные вещи, которые могли бы оказаться нереально полезными. К сожалению, авторы, работающие над этим предложением, переключились на работу над другими вещами, оставив нас перед выбором: либо писать вручную, либо через C++ :-(]
Сначала я поменял Mapping с обычного объекта на обертку, которая указывает на гигантский типизированный массив, содержащий все наши маппинги.
function Mapping(memory) { this._memory = memory; this.pointer = 0; } Mapping.prototype = { get generatedLine () { return this._memory[this.pointer + 0]; }, get generatedColumn () { return this._memory[this.pointer + 1]; }, get source () { return this._memory[this.pointer + 2]; }, get originalLine () { return this._memory[this.pointer + 3]; }, get originalColumn () { return this._memory[this.pointer + 4]; }, get name () { return this._memory[this.pointer + 5]; }, set generatedLine (value) { this._memory[this.pointer + 0] = value; }, set generatedColumn (value) { this._memory[this.pointer + 1] = value; }, set source (value) { this._memory[this.pointer + 2] = value; }, set originalLine (value) { this._memory[this.pointer + 3] = value; }, set originalColumn (value) { this._memory[this.pointer + 4] = value; }, set name (value) { this._memory[this.pointer + 5] = value; }, };
Затем я подстроил код разбора и сортировки, чтобы использовать его вот так:
BasicSourceMapConsumer.prototype._parseMappings = function (aStr, aSourceRoot) { // Выделить 4 МБ буфер в памяти. Значение может быть пропорциональным // размеру aStr для сохраниния памяти в случае меньших маппингов this._memory = new Int32Array(1 * 1024 * 1024); this._allocationFinger = 0; let mapping = new Mapping(this._memory); // ... while (index < length) { if (aStr.charAt(index) === ';') { // Весь код, который мог до этого обращаться к маппингам напрямую, // теперь должен обращаться к ним косвенно через память sortGenerated(this._memory, generatedMappings, previousGeneratedLineStart); } else { this._allocateMapping(mapping); // ... // Массивы маппингов теперь хранят "указатели" вместо реальных маппингов. generatedMappings.push(mapping.pointer); if (segmentLength > 1) { // ... originalMappings[currentSource].push(mapping.pointer); } } } // ... for (var i = 0; i < originalMappings.length; i++) { if (originalMappings[i] != null) { quickSort(this._memory, originalMappings[i], util.compareByOriginalPositionsNoSource); } } }; BasicSourceMapConsumer.prototype._allocateMapping = function (mapping) { let start = this._allocationFinger; let end = start + 6; if (end > this._memory.length) { // Do we need to grow memory buffer? let memory = new Int32Array(this._memory.length * 2); memory.set(this._memory); this._memory = memory; } this._allocationFinger = end; let memory = this._memory; mapping._memory = memory; mapping.pointer = start; mapping.name = 0x7fffffff; // Instead of null use INT32_MAX. mapping.source = 0x7fffffff; // Instead of null use INT32_MAX. }; exports.compareByOriginalPositionsNoSource = function (memory, mappingA, mappingB, onlyCompareOriginal) { var cmp = memory[mappingA + 3] - memory[mappingB + 3]; // originalLine if (cmp !== 0) { return cmp; } cmp = memory[mappingA + 4] - memory[mappingB + 4]; // originalColumn if (cmp !== 0 || onlyCompareOriginal) { return cmp; } cmp = memory[mappingA + 1] - memory[mappingB + 1]; // generatedColumn if (cmp !== 0) { return cmp; } cmp = memory[mappingA + 0] - memory[mappingB + 0]; // generatedLine if (cmp !== 0) { return cmp; } return memory[mappingA + 5] - memory[mappingB + 5]; // name };
Как вы видите, читабельность слегка пострадала. В идеале я бы предпочел выделить временный объект Mapping, каждый раз, когда мне понадобилось бы работать с его полями. Однако такой стиль кода сильно зависел бы от способности VM убирать размещенные временные объекты путем allocation sinking, scalar replacement и других похожих оптимизаций. К сожалению, в моих экспериментах SpiderMonkey не смог работать с таким кодом достаточно хорошо, так что я пошел более многословным и ошибкоопасным путем.
[Такой вид почти ручного управления памятью выглядит чуждо для JS. Поэтому я думаю, здесь стоит заметить, что "окисленная" source-map на самом деле требует от пользователей управлять вручную её временем жизни, чтобы удостовериться в освобождении ресурсов WASM]
Перезапуск бенчмарка подтверждает, что облегчение нагрузки на GC выдает неплохое улучшение:
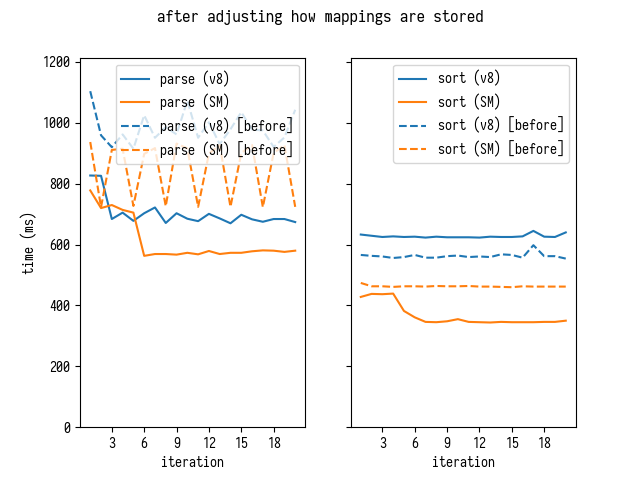
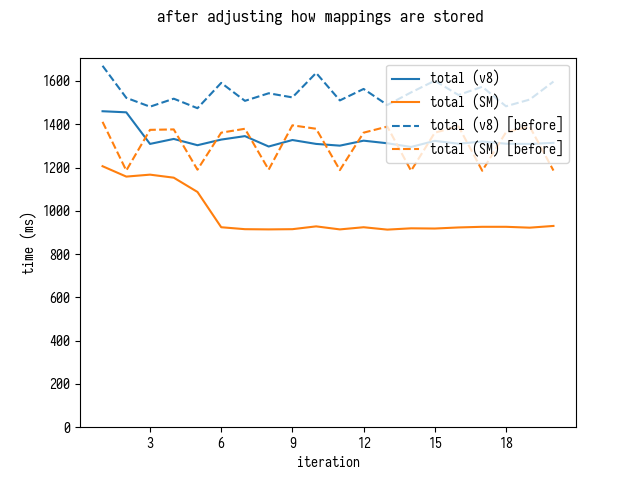
Довольно интересно, что SpiderMonkey при этом подходе улучшает время и разбора, и сортировки, что оказалось для меня сюрпризом.
Уступ производительности в SpiderMonkey
Играясь с кодом, я также обнаружил смущающий уступ в производительности SpiderMonkey: когда я увеличивал размер предразмещенного буфера в памяти с 4 до 64 МБ, чтобы откалибровать затраты на переразмещение, бенчарк показал мне внезапное падение производительности на 7й итерации.
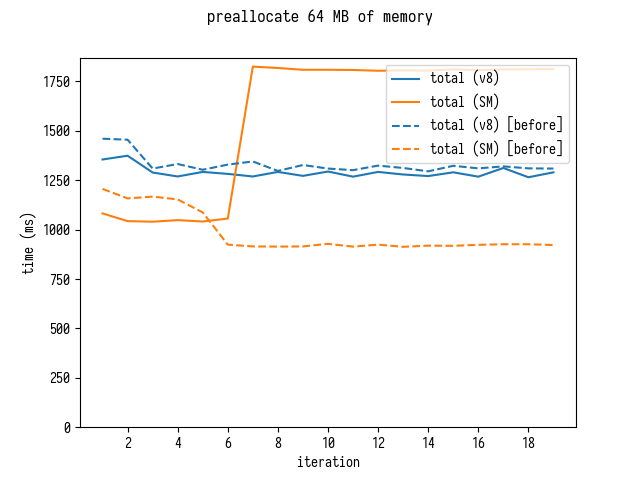
Это казалось мне каким-то видом полиморфизма, но я не смог сразу же установить, как изменение размера массива смогло привести к полиморфному поведению.
Озадаченный я связался с разработчиком SpiderMonkey Jan de Mooij, который очень быстро определил виновника – связанную с asm.js оптимизацию от 2012 года… позже он взял и удалил её из SpiderMonkey, так что никто больше не споткнется об этот смущающий уступ.
Оптимизируем разбор – Использование Uint8Array вместо строки.
В конце концов, раз уж мы начали использовать Uint8Array вместо строк для разбора, мы можем получить еще одно маленькое улучшение.
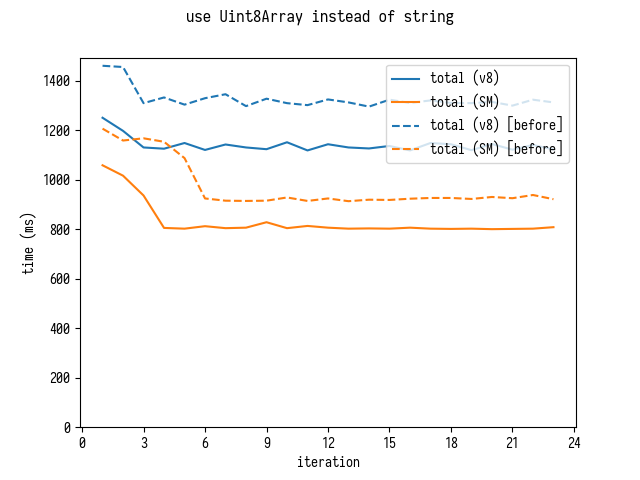
[Это улучшение основано на переписывании source-map на разбор маппингов напрямую из типизированных массивов, вместо использования JavaScript-строк и разбора их с помощью JSON.decode. Я не делал такого переписывания, но не ожидаю здесь никаких промблем.]
Общие улучшения по сравнению с начальным состоянием
Вот где мы начали:
$ d8 bench-shell-bindings.js ... [Stats samples: 5, total: 24050 ms, mean: 4810 ms, stddev: 155.91063145276527 ms] $ sm bench-shell-bindings.js ... [Stats samples: 7, total: 22925 ms, mean: 3275 ms, stddev: 269.5999093306804 ms]
и вот где мы заканчиваем
$ d8 bench-shell-bindings.js ... [Stats samples: 22, total: 25158 ms, mean: 1143.5454545454545 ms, stddev: 16.59358125226469 ms] $ sm bench-shell-bindings.js ... [Stats samples: 31, total: 25247 ms, mean: 814.4193548387096 ms, stddev: 5.591064299397745 ms]
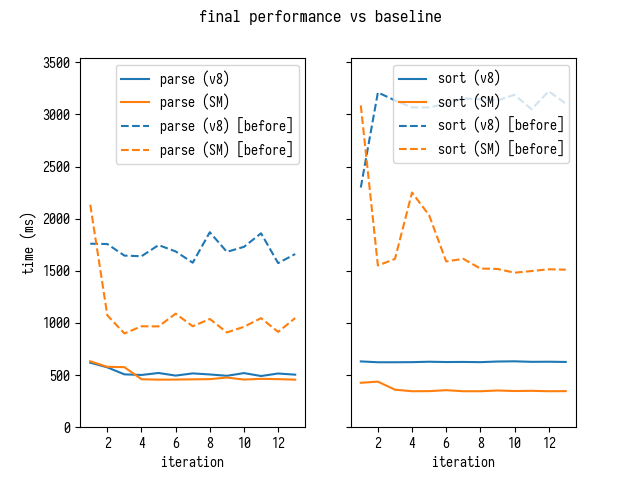
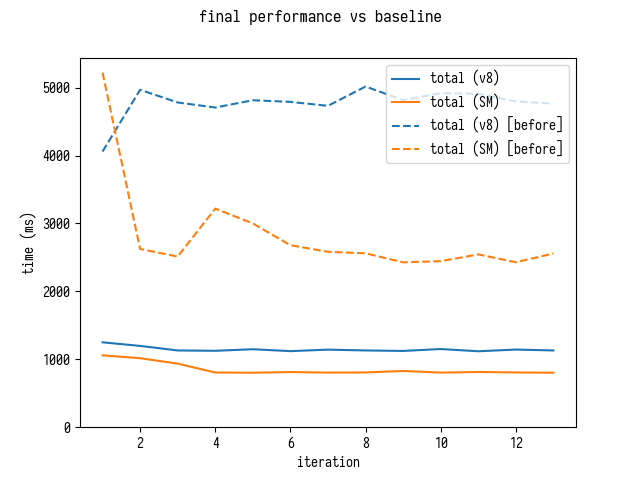
Это улучшение в 4 раза!
Может быть, также стоит заметить, что мы все ещё сортируем все массивы originalMappings, даже если это на самом деле не нужно. Тут есть только две операции, которые используют originalMappings:
allGeneratedPositionsFor, которая возвращает все сгенерированные позиции для данной строки в исходном коде;eachMapping(..., ORIGINAL_ORDER), которая обходит все маппинги в их изначальном порядке.
Если мы допустим, что allGeneratedPositionsFor является самой основной операцией и что мы только ищем внутри небольших массивов originalMappings[i], то мы можем значительно улучшить время разбора, лениво сортируя массивы только когда мы в самом деле что-то ищем в одном из них.
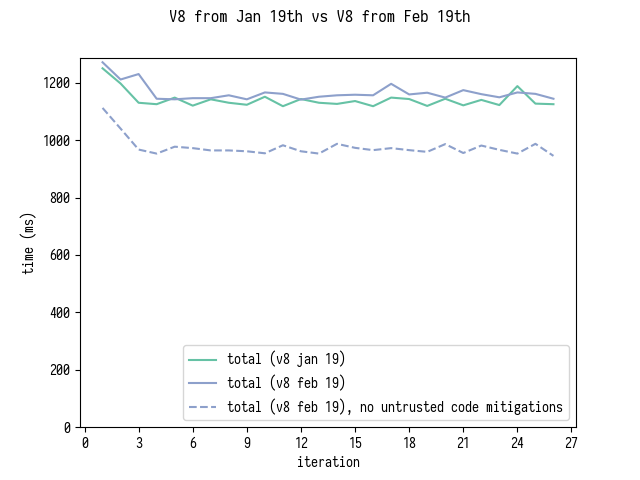
И наконец, сравнение V8 от 19 января, с V8 от 19 февраля с использованием и без ограничений для недоверенного кода (untrusted code mitigations).
Сравнение с "окисленной" версией source-map
После публикации этого поста 19 февраля, я получил несколько просьб сравнить source-map с моими правками с основной веткой source-map, которая использует Rust и WASM.
Беглый просмотр исходного кода на Rust для parse_mappings обнаружил, что Rust-версия не собирает исходные маппинги заранее, а производится и сортируется только эквивалент generatedMappings. Для сопоставления этого поведения я подправил свою JS-версию, закомментировав сортировку массивов originalMappings[i].
Вот результаты бенчмарка для только разбора (который также включает сортировку generatedMappings) и для разбора с последующим обходом всех generatedMappings.
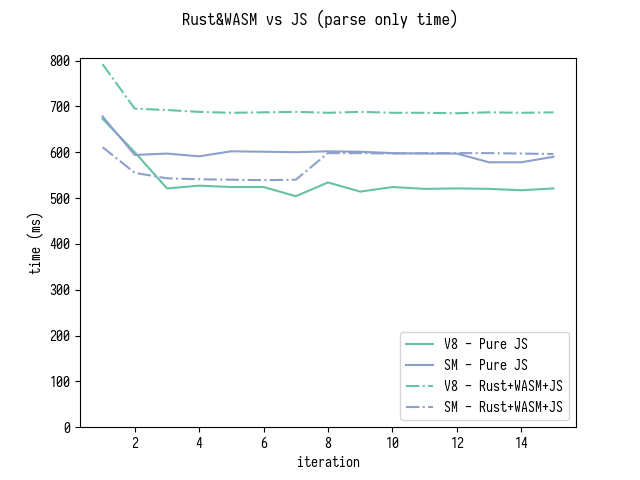
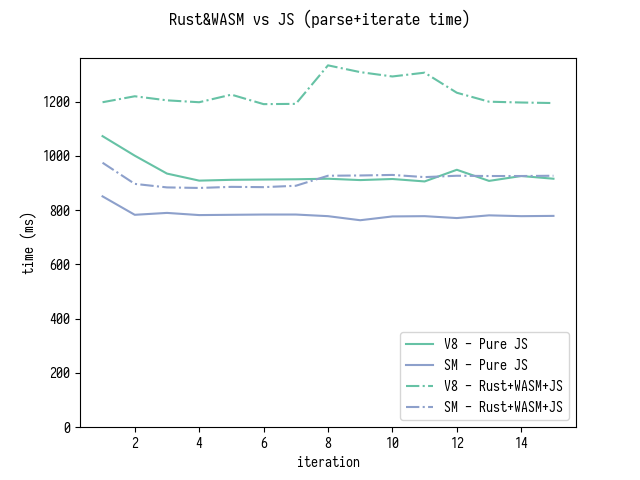
Заметьте, что сравнение немного не корректно, потому что Rust-версия не оптимизирует сортировку generatedMappings таким же образом, как это делает моя JS-версия.
Тем самым я не собираюсь здесь объявлять что "мы успешно достигли паритета с Rust+WASM версией". Однако, на таком уровне отличий в производительности имеет смысл пересмотреть, оправданы ли затраты на использование Rust в source-map.
Обновление (27-02-2018)
Ник Финцджеральд, автор source-map обновил версию на Rust+WASM, и добавил алгоритмические улучшения описанные в этой статье. Вот так выглядит дополненный график производительности для бенчмарка разбор и итерирование:
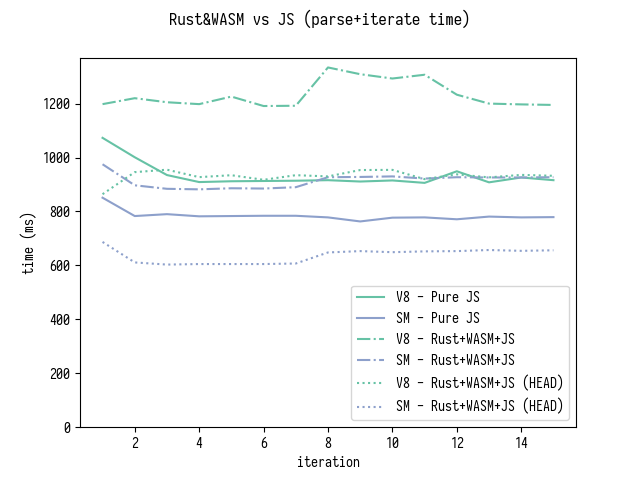
Как вы можете видеть, теперь версия на WASM+Rust примерно на 15% быстрее в SpiderMonkey и примерно на такой же скорости в V8.
Усвоенные уроки
Для JavaScript разработчика
Профилировщик – твой друг
Профилирование и точечное отслеживание производительности в различных формах – это лучший способ оставаться на пике скорости. Это позволяет вам определять горячие точки своего кода и выявляет потенциальные проблемы в нижележащем рантайме. По этой конкретной причине я не постесняюсь использования низкоуровневых профилирующих инструментов типа perf – "дружественные" инструменты могут не рассказать вам полную историю, поскольку они скрывают нижний уровень.
Различные проблемы производительности требует различных подходов к профилированию и визуализации собранных профилей. Убедитесь, что вы знакомы с широким спектром доступных инструментов.
Алгоритмы важны
Способность рассуждать о своем коде в терминах абстрактной сложности – это важное умение. Что лучше, сортировать быстрой сортировкой один массив на 100 тысяч элементов, или 3333 подмассива из 30 элементов?
Кусочек наколенной математики покажет нам что  в 3 раза больше чем
в 3 раза больше чем  – и чем больше ваши данные, тем более важно быть способным сделать эти небольшие вычисления.
– и чем больше ваши данные, тем более важно быть способным сделать эти небольшие вычисления.
В дополнение к знанием логарифмов вам нужно обладать чувством здравого смысла и быть способным проверять, как ваш код будет использоваться в среднем и худшем случае: какие операции основные, как можно сгладить затраты дорогих операций, какие будут недостатки у этого сглаживания?
VM ещё в процессе разработки. Доставайте разработчиков!
Не стесняйтесь обращаться к разработчикам и обсуждать странные проблемы производительности. Не все на свете может быть решено правками вашего собственного кода. Как говорит русская поговорка: "не боги горшки обжигают!". Разработчики виртуальных машин (VM) –тоже люди и, как и все остальные, они могут допускать ошибки. Также они довольно хороши в исправлении этих ошибок, когда вы о них сообщаете. Одно письмо или сообщение в чате или в личку сможет сохранить вам дни копания в чужом C++ коде.
VM все еще нужно немного помощи
Иногда вам нужно писать низкоуровневый код или знать низкоуровневые детали, чтобы выжать последние капли производительности из JavaScript.
Некоторые предпочтут языки другого уровня с другими возможностями, чтобы этого достичь, но это еще только предстоит выяснить, если мы когда-либо до этого доберемся.
Для разработчика/дизайнера языка
Умные оптимизации должны быть диагностируемы
Если ваш рантайм имеет некоторые встроенные умные оптимизации, то вам нужно предоставить простой инструмент для диагностики, когда эти оптимизации ломаются, и показывать разработчикам полезные сообщения.
В контексте языков вроде JavaScript это значит как минимум, что инструменты типа профайлера должны также давать возможность просмотреть отдельные операции, чтобы выяснить, хорошо ли их обрабатывает VM, а если нет – в чем причина этого.
Такой вид интроспекции не доджен требовать сборки особых версий VM с магическими флагами, а затем копания в мегабайтах недокументированного отладочного вывода. Такой вид инструментов должен быть прямо здесь, когда вы открываете окно DevTools.
Язык и оптимизации должны быть друзьями
И наконец, как дизайнер языка вы должны пытаться предвидеть, где языку недостает возможностей, которые могли бы сделать проще написание высокопроизводительного кода. Ваши пользователи ищут способ располагать и управлять памятью вручную? Я уверен, что да. Если ваш язык даже слегка популярен, то в конечном счете пользователи добьются успеха в написании кода с плохой производительностью. Измеряйте стоимость добавления возможностей языка, которые исправляют проблемы производительности против решения той же проблемы скорости другими путями (т.е. путем более сложных оптимизаций или прося пользователей переписать их код на Rust).
Это работает и обратную сторону тоже: если в вашем языке есть какие-то возможности, удостоверьтесь, что они работают достаточно хорошо и их производительность хорошо понятна пользователям, а также может быть легко диагностирована. Инвестируйте в становление вашего языка оптимизированным в целом, вместо того, чтобы иметь быстрое ядро и низкопроизводительные редко используемые фичи на периферии.
Послесловие
Большинство оптимизаций, найденных в этом посте попадают в три различные группы:
- алгоритмические улучшения;
- обходные пути для проблем, независимых от имплементации, но потенциально зависимых от языка;
- обходные решения проблем, специфичных для V8.
Неважно, на каком языке вы пишете, вам все еще нужно думать об алгоритмах. Легче заметить, когда вы используете худшие алгоритмы в по определению "медленных" язках, но простое переписывание тех же алгоритмов на "быстрый" язык не решит проблемы, даже если устранит симптомы. Большая часть этого поста уделена оптимизациям из этой группы:
- улучшения сортировки путем сортировки подмассивов вместо целого массива;
- дискуссия пользы кэширования или его отсутствия.
Вторая группа представлена приёмом мономорфизации. Страдание производительности от полиморфизма не является специфичной для V8 проблемой. Также это не специфичная для JS проблема. Вы можете применять мономорфизацию во многих реализациях и даже языках. Некоторые языки (Rust, например) применяют её в некоторой форме под капотом.
Последняя и самая спорная группа представлена адаптацией аргументов.
И наконец, оптимизация, которую я сделал для представления маппингов (упаковка отдельных объектов в единый типизированный массив) является оптимизацией всех трех групп. Это про понимание ограничений и стоимости систем со сборщиком мусора в целом. Также это про понимание силы существующих JS VM и использование их для нашей пользы.
Итак… Почему я выбрал такой заголовок? Это потому, что я думаю, что третья группа представляет все проблемы, которые должны быть исправлены со временем. Остальные группы представляют универсальное знание, которое подходит к разным реализациям и языкам.
Очевидно, каждый разработчик и каждая команда вольна выбирать между тратой N часов на тщательное профилирование, чтение и размышления об их JavaScript коде, или тратой M часов на переписывание своего хозяйства на язык X.
Однако: (а) каждый должен полностью отдавать отчет, что выбор на самом деле существует; и (б) дизайнеры языка и исполнители должны работать вместе, чтобы сделать этот выбор менее и менее очевидным – что значит работу над возможностями язка и инструментами и уменьшениие необходимости в "группе #3" оптимизаций.
