Comments 51
1. Автодоворот картинки (при наличии регулярных ориентиров, например линейки, клеток, полей, краев листа, отверстий для сшивателя).
2. Выделение разметки (поля, линейки, клетки) и их автоприглушение, т.е. они должны остаться, но замениться неградиентным (единичным) цветом, слабым, неотвлекающим, но воспроизводимым при печати.
- Автодоворот картинки (при наличии регулярных ориентиров, например линейки, клеток, полей, краев листа, отверстий для сшивателя).
Думаю материал моей статьи "Автоматическое выравнивание горизонта на фотографиях" поможет в этом.
В своё время использовал для конспектов djvu — примерно 60кб на станицу A4 @ 400dpi. Там более продвинутое сжатие, и эта статья создаёт впечатление довольно примитивного велосипеда.
Однако png более распространён чем djvu, так что программка наверняка будет полезна.
P.S. надо бы попробовать выходные картинки сжать djvu.
Забавно, djvu позволяет сжать примеры со ~120кб до ~40кб в нормальном качестве (20..110кб в разных вариантах), но дичайше искажает цвета (часть надписей фиолетовая, когда в оригинале они красные и синие).
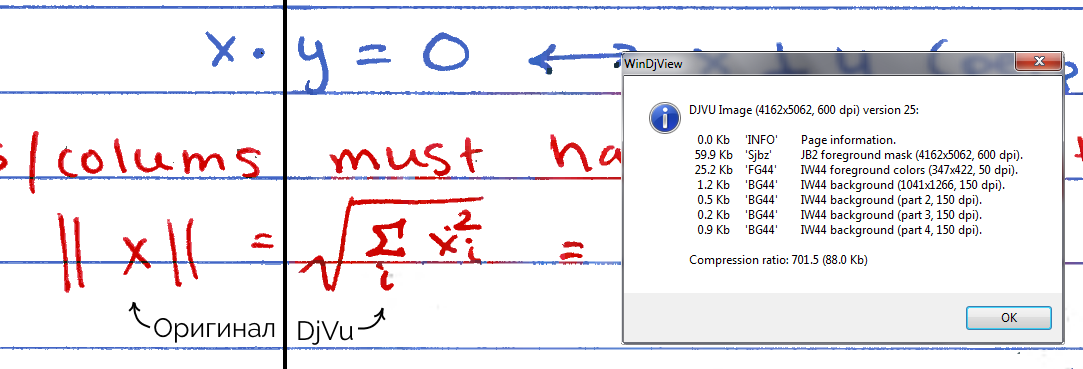
Картинка кликабельна. Если кто хочет поэкспериментировать — сжимал я это в DjVu Small в режиме «Drawn 200».
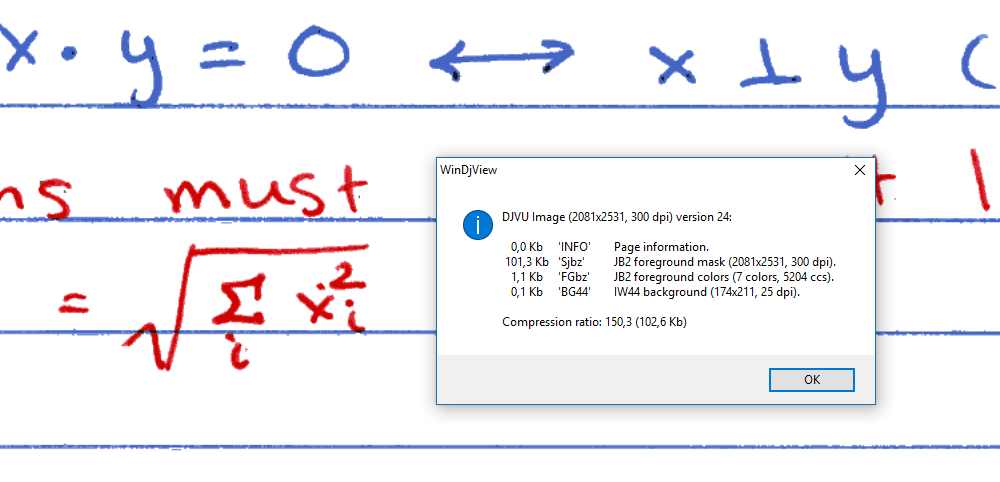
Весь конструктивный смысл DjVu — выделить в изображении условные "слои" (исходя из того, что это не фотография, а именно скан распечатанного текстового документа). И потом пожать разные картинки разными методами.
В плюсе получаем малый размер файла.
Это всё давно известно, формат был крайне актуален >10 лет назад, поскольку на тот момент был практически безальтернативным.
Очевидное: ровно так же "по слоям" можно разложить банальный PDF. Вопрос только в том, как поделить на эти самые слои изначальный скан. И второй большой вопрос — чем пожать эти самые слои (у djvu свой собственный формат сжатия для разных целей, даже несколько!).
И вот нынче ситуация весьма поменялась. Jbig + Jpeg2000, упакованный в PDF = практически аналог (по эффективности сжатия) djvu, при этом с наиболее очевидной плюшкой в виде поддержки этого самого pdf практически в каждом утюге.
Я в своё время тоже использовал djvu.
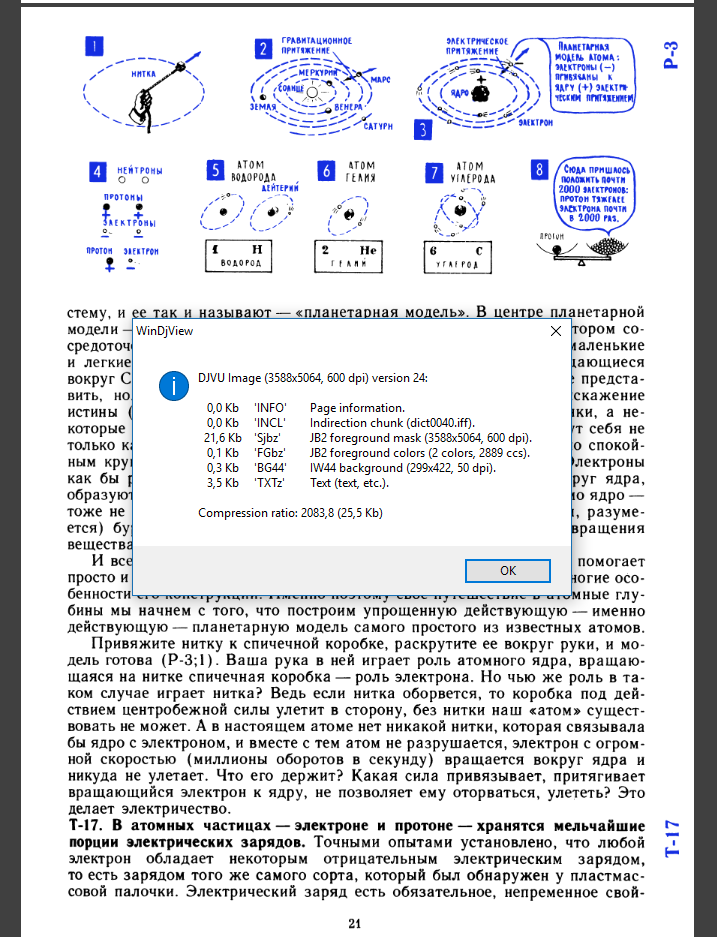
А сейчас отлаживаю скрипт, который перепаковывает djvu в pdf с сохранением всех оригинальных плюшек, насколько это возможно. (помимо упомянутой "слоистости" сейчас уже копируется структура (оглавление), а также скрытый OCR-слой (если есть)).
Эффективность (для сравнения): 600-страничный 1-битный (ч/б) скан в современном pdf занимает 18.5Мб против 16.5Мб в djvu. И при этой разнице в размерах он гоораздо удобнее!
Это лишь одна из технологий. Фон жмётся продвинутым аналогом jpeg, символьные изображения "распознаются" в словарь, причём сам словарь тоже внутри себя древовидный — например, букву "й" вполне способен сохранить не картинкой, а ссылкой на букву "и" + галочку. Кроме того, каждую букву (символ) на странице можно раскрасить в собственный цвет, и эта информация тоже очень эффективно жмётся.
Наконец, сам словарь создаётся не для каждой страницы, а для целой группы (в djvu мне в основном встречается 1 словарь на 10 страниц).
Идея такого "словарного" сжатия не нова; просто создатели djvu быстро "слепили" компрессор и начали продавать, пока никто не предложил аналог. А в то же время "гуру" создавали спецификацию для "официального" компрессора, работающего на этой идее (повезло, что lizardtech не догадались запатентовать эту идею как таковую). В итоге спецификация получилась очень большой и сложной, так что вариантов хоть какой-то реализации пришлось ждать несколько лет.
В наше время jbig-сжатие (то самое "официальное" сжатие со словарём, аналогичное djvu) уже реализовано; более того, это один из "стандартных" вариантов для pdf, поэтому поддерживается на каждой железке, понимающей соответствующую версию формата. Поэтому сейчас альтернатива есть, и она уже очень неплоха.
Иными словами — в pdf в наше время есть стандартный кодек, построенный на тех же принципах "словарного" сжатия, что и djvu. С очень близким коэффициентом сжатия. (просто подавляющее большинство интересующихся уже успокоились на том, что pdf не умеет хорошо сжимать. И очень многие просто не в курсе, что уже довольно давно, как МОЖНО!)
Именно о них и речь. Готовых "под ключ" я не нашёл.
Но нашёл, во-первых, pdfbeads (он создаёт "слоистый" pdf из заранее подготовленных картинок). + скрипт на ЛОРе для пережатия djvu (там автор взял jpeg2000 + CCIT4). Всё, что нужно — это скрестить этих "ежа и ужа". Чтоб не быть голословным: вот оригинал, вот результат. Но аппетит приходит во время еды — захотелось заодно переносить другую информацию, вроде меню навигации и OCR-слоя. Плюс — разобраться с многоцветными сканами djvu (где каждому "символу" назначается отдельный цвет — это тоже вполне жмётся в pdf, но pdfbeads делает это вроде как чрез тот же CCIT4, а хочется и это тоже переместить в jbig, если получится).
Я лучше чтоб некосноязычить, процитирую.
Результаты (все — 300 DPI):
Растровый PDF JPEG — 475 КБ — качество сжатия* — JPEG 50%.
Растровый PDF JPEG2000 — 481 КБ — качество сжатия* — JPEG2000 25%, размер частей — 1024.
Adobe ClearScan — 219 КБ — качество сжатия* картинок — JPEG 50%, текст векторизован.
FineReader PDF MRC — 335 КБ — качество сжатия* картинок — JPEG2000 25%, бинарная маска — 600 DPI.
DjVu — 195 КБ — качество сжатия* картинок в IW44 примерно равно 82 по шкале LizardTech или 34 по шкале DjVu Libre, бинарная маска — 600 DPI.
* У JPEG, JPEG2000, IW44 — разные шкалы качества, ибо это разные алгоритмы. Например JPEG2000 50% будет намного превосходить по качеству и размеру JPEG 50%. Я подобрал параметры так, чтоб размер JPEG и JPEG2000 был одинаков.
Явный победитель по параметру качество/размер с большим отрывом — DjVu.
По порядку качества:
1) Djvu, FineReader PDF MRC — примерно равны по качеству. Лучшее качество из всех.
При просмотре текст и линие четкие, гладкие. Символы (буквы) точно соответсвуют исходнику — засечки букв не повреждены и не укорочены, толщина деталей символов точна.
Картинки в хорошем качестве, качество сжатия можно регулировать. (хоть без потерь вывести, в PDF — JPEG2000 — lossless, в DjVu — IW44 — качество бэкграунда 100 (LizardTech)).
Сегментирование регулироемое. (В PDF FR — анализ и коррекция областей в самом FR, В DjVu — метод раздельных сканов. Но FR лучше, он позволяет сегментировать и текст на самих картинках. Для DjVu очень ограничено — недостаток инструментов, хотя с соответсвующим инструментом возможно.)
2) Растровый PDF JPEG2000. При просмотре текст и линие гладкие, но уже не такие четкие, но достаточно хорошие. В местах с текстом вокруг символов есть еле заметные артефакты сжатия на фоне, но они столь незначительны, что не влияют на восприятие. Картинки в хорошем качестве.
Сегментация не требуется.
3) Adobe ClearScan.
При просмотре текст и линие четкие и гладкие. Но! Символы не соответсвуют исходнику — засечки букв повреждены и укорочены, толщина деталей букв неточна, есть ужирнения в некоторых местах букв, символы заметно искажены и потеряли детали из-за сильной аппроксимации (приближения, по-другому сглаживания), необходимой для векторизации. Символы кажутся расплытыми, у всех символов с округлыми границами («О», «C» и т.п.) видны острые грани, на крупных символах это особенно критично и заметно даже при 100% масштабе!
Картинки в среднем качестве, заметны артефакты сжатия JPEG (квадратики), настроить качество сжатия и выбрать более лучший JPEG2000 нельзя.
Сегментирование полностью нерегулироемое. Это означает, что надежда полностью на автоматический сегментатор от Adobe. Т. к. сегментирование задача еще нерешенная и сложная, автомат дает много искажений. Простые картинки вроде графиков, диаграм, геометрических фигур, стрелок, даже элементов в формулах и т. п. очень часто повреждаются до неузнаваемости. Нераспознаные сегментатором картинки идут в фон, где сильно даунсэмплится и сжимаются, становясь размытыми, полностью теряя качество. В дополнение картинки и формулы вообще могут пропасть (уйти за границу страницы), правда это можно откорректировать вручную, если заметить. Если фон предварительно не почистить, то даже небольшой мусор в бекграунде расплывается до больших размеров и становится заметным. Отдельно в этом режиме нельзя отключить автоматическую геометрическую коррекцию и поворот, которая иногда полностью искажает правильную страницу. И на примере видно, что тире в самом начале текста забрало в бекграунд и размыло — то есть потеря качества текста.
4) Растровый PDF JPEG. При просмотре текст и линии размыты из-за сильных артефактов сжатия. В местах с текстом вокруг символов есть заметные артефакты сжатия на фоне, фон поврежден и замусорен. Картинки в среднем качестве, заметны артефакты сжатия JPEG.
Сегментация не требуется.
Как видно, оптимальный размер дает только DjVu и PDF ClearScan. Когда задача сегментации сложна или вообще ручной труд не рационален (временные документы), подходит и PDF JPEG2000 или однослойный (Photo или псевдо) DjVu (IW44), но не PDF с JPEG, который все до сих пор юзают по неграмотности, делая большую ошибку.
ClearScan интересная технология, но на данный момент для практического использования не доработана. Нужна возможность ручной сегментации, настройки качества сжатия и даунсемпла изображений и бекграунда, возможность отключать автоматическую коррекцию геометрии и исправления багов вроде переноса элементов за границы страницы.
Максимум она годится для исправления исправления сильно деградированых документов или старых книг, с последующим экспортом в картинки в 600 DPI и ручным исправлением всех возникших косяков графическим редактором (их обычно очень много на научной литературе, проверено много раз).
Так что DjVu с нормальными ручными настройками (без даунсемпла бекраунда или даунсемплом его только до 300 DPI, предварительной обработкой исходника и апсемплом до 600DPI интерполяцией, чтобы текст был гладкий (бинарная маска должна быть 600DPI)) и метод раздельных сканов — лучшее, что есть на сегодня.
Что значит "не даёт повлиять"?
PDF поддерживает слои! Поэтому никто не мешает жать аналогично djvu- фон с низким разрешением в jpeg2000 (кто там будет разглядывать отсканированную текстуру бумаги?). Текст (битмап) — в jbig. Один слой поверх другого.
В формате как таковом ограничений нет. Ограничения в инструментах: разделять надо уметь!
Я почему взялся за перепаковку — потому что там всё УЖЕ разделено, просто нужно извлечь из оригинального djvu эти самые слои, и пожать их правильными кодеками в pdf. Получается файл практически того же размера, но при этом существенно более дружественный ко многим устройствам.
Вот если брать свежий скан и искать программу с единственной кнопкой "сделать правильно" — там да, борьба производителей. А если потратить время и разметить вручную, то проблема качестве практически исчезает.
А еслиб прошли по ссылке, увидели бы, что автор поста, разработчик Scan Tailor Advanced. Эти тесты он делал, потому что сам изначально топил за PDF, и хотел написать даже свой PDF компрессор «по технологии MRC скорее всего c Multi-COS/CCC сегментацией». Но отказался от этого дела (если интересны мотивы и аргументы «до» и «после», можите в теме найти: «версия для печати» и ищите сообщения от «4lex4». (изначально его аргументация совпадала с вашей, там даже больше плюсов перечислялось)
Я делаю PDF, только если у меня полностью LaTeX\исходники на руках, или распознал всю книгу вычитал и плевать на типографику. Если же работа идет со сканами, по вес/качество/скорость — выигрывает DjVu. Даже при условии уже вычещеных файлов, разбитые на малоцвет и иллюстрации (SknKromsator или SkanTailor), собранный DjVu будет сделан быстрее, проще, более контролируемый в процессе и в читалках работать не так тормознуто как PDF, чем из этих же файлов сделанный PDF.
Да и каким софтом PDF собирать? У вас есть на примете хороший некомерческий которым удобно пользоваться? Если есть поделитесь, интересно послушать, я про такой не слышал.
А InDesign — это «по воробьям из пушки» (и то потом куча телодвижений еще надо сделать чтоб получить качественный выходной файл).
Я не хейтю формат, я много разных пробовал, и остановился в итоге на: fb2 — худлит, PDF — из исходников, DjVu — из сканов.
П.С.: про контроль, есть DjVu Small Mod — там есть предустановленные профили, уже подогнанные под конкретные случаи. Но программа работает с кодером, которому можно задавать просто чуть ли не любые параметры. Только тут уже разбираться долго и сложно. в DSM уже оч оптимальные профиле с возможностью доводки.
П.П.С.: Я с последними сканам сам хотел сделать вариант DjVu и PDF, но после очистки и подготовки сканов, увидел, что создать PDF это потребует усилий и времени не меньше чем я потратил уже на эти 800 страниц :).
Ну речь снова о том же — софт для создания pdf не очень хорошо умеет делить материал на эти самые слои. Создатели djvu постарались в этом плане лучше.
Сейчас пытаться сделать что-то подобное — это по сути переизобретать алгоритмы djvu (не алгоритмы сжатия, а именно алгоритмы сегментирования). И именно это собственно и есть тема вашей ветки форума.
Но! — и я снова возвращаюсь к той же теме — никто не мешает воспользоваться результатом работы софта djvu и сделать на его основе pdf. Не "тупо распечатать на ps-принтер", а именно распаковать слои и каждый пережать соответствующим кодеком (jpeg2000, jbig). Элементарные воркеры для этого давно есть (unix-way), нужно только собрать скрипт.
Сейчас пытаться сделать что-то подобное — это по сути переизобретать алгоритмы djvu (не алгоритмы сжатия, а именно алгоритмы сегментирования)
Собственно CS это и есть попытка это сделать. В чемт о удачная, а в чем то оч проблемная.
Собственно из за многих мелочей от этой идеи и отказались в пользу DjVu.
«тупо распечатать на ps-принтер»Я это никогда и не считал за «сделать PDF» :) Это прото PDF как контейнер для тяжелых картинок получится.
Остальное в лс.
del
У нас преподаватель максимум — написал программу для тестирования, которая сохраняет результат в текстовый файл, который потом ручками можно поправить
Со сканами рукописного текста никогда не работал, не приходилось, но для сканов книг мне очень понравился Scantailor — умеет в очистку изображения от шума, автоповорот изображения, выравнивание текста (например, при сканировании разворота книги текст, расположенный близко к переплету искажается) и т.д. Плюс ко всему свободное и кросплатформенное ПО.
Описанный автором алгоритм очень хорошо бы встроился в ST для обработки цветных сканов
Пообщаться можно на Ru.Board в этом топике.
Встроен. В STEX: "К-средних" на этапе "Вывод".
Жаль что без GUI.
Есть вот еще несколько программ для похожего, но они уже давно не развиваются:
http://scantailor.org
https://ru.wikipedia.org/wiki/ScanKromsator
SK — пилится, разработчик принимает багрепорты, но релизы крайне редко (всё на руборде).
Они там что, гуманитариев естественным наукам обучают, или просто тетради в клетку не завезли?
- Открываю в ней полноцветный скан.
- Уменьшаю количество цветов до 16 (Decrease color dept).
- Редактирую полученную палитру, заменив самый светлый цвет на чисто белый (Palette -> Edit palette...).
- Сохраняю в PNG.
Обратная матрица не равна транспанировонной.
Речь идет об ортогональной матрице
А также огорчает, что в примере с жёлтой бумагой сетка убрана не полностью – от качественного инструмента ожидаешь универсальности, например, чтобы можно было поставить флаг «сохранить сетку» / «удалить сетку», но никак не что-то среднее. Наверное, такие детали изображения лучше отлавливать специальным алгоритмом поиска линий…
Cжатие и улучшение рукописных конспектов