Привет! Недавно я натолкнулся на довольно интересное описание архитектуры Pusher Channels и решил его перевести для вас. На мой взгляд, автор очень доступно описал подходы к построению высоконагруженной и масштабируемой архитектуры. Скорее всего, статья будет полезна новичкам, а также специалистам из смежных областей.
В офисе компании Pusher у нас висит небольшой счетчик с постоянно увеличивающейся цифрой. Он показывает количество доставленных сообщений за всё время существования Pusher Channels. В пятницу в 22:20 по UTC число увеличилось на один разряд и достигло 10.000.000.000.000. В нём 13 нулей — 10 трлн.

Вы можете подумать, что счётчик общего количества сообщений — бесполезная кичливая метрика. Но это число — ключевой индикатор успеха Pusher Channels, нашего продукта для коммуникации в режиме реального времени. Во-первых, данный счётчик отражает доверие, оказанное нам пользователями. Во-вторых, он измеряет масштабируемость нашей системы. Чтобы цифра увеличивалась, мы в Pusher должны сделать так, чтобы пользователи доверяли отправку сообщений нашему сервису, и мы должны быть уверены в том, что наша система способна обработать эти сообщения. Но что нам стоит доставить 10 трлн сообщений? Давайте посмотрим.
В секунду через Pusher Channels отправляют около 200.000 сообщений, в пиковые моменты — миллионы. Например, когда New York Times использовала сервис, чтобы держать своих читателей в курсе хода выборов президента США.
Давайте сначала посмотрим на Pusher Channels как на большой чёрный ящик, через который проходят все эти сообщения:
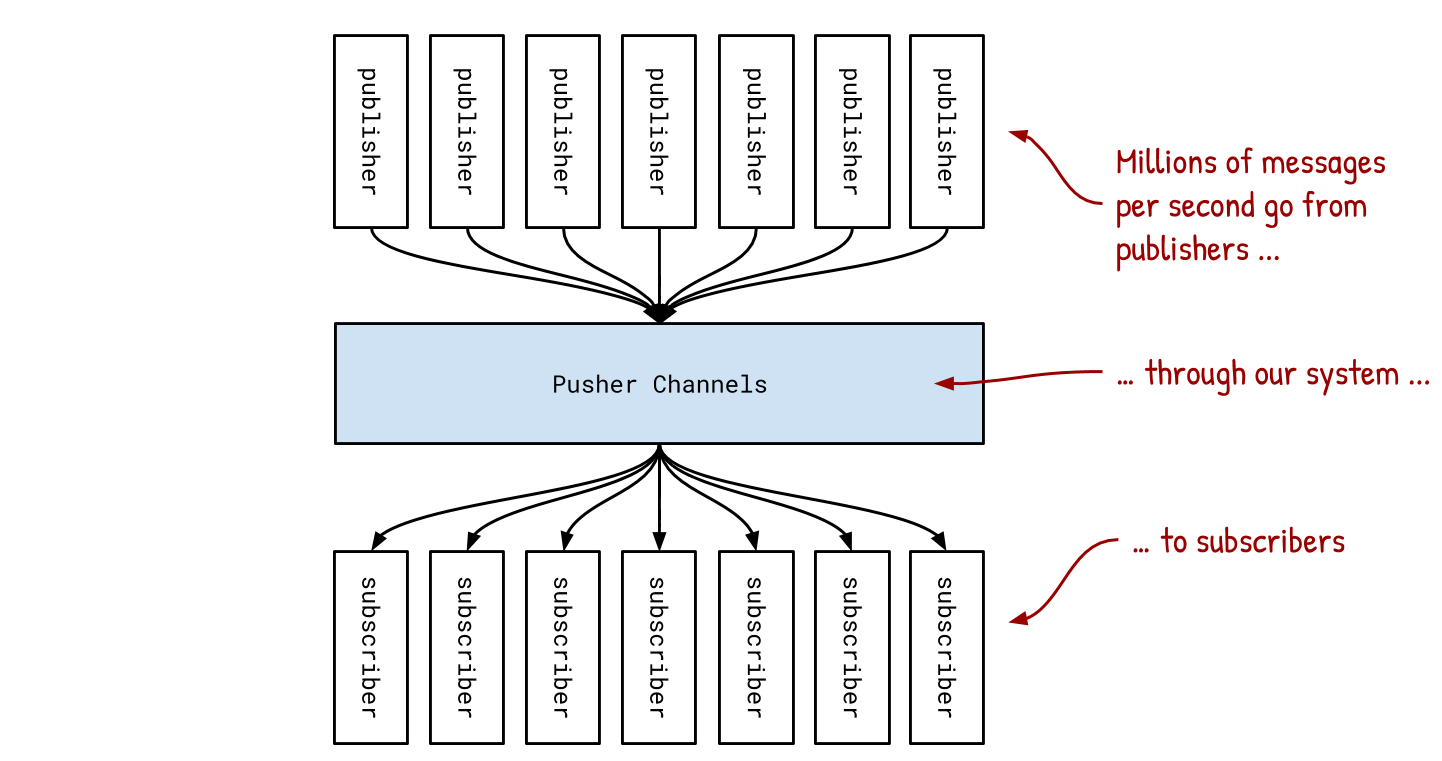
Pusher Channels — это система типа publish—subscribe. Клиенты подписываются на каналы (например, “btc-usd” или “private-user-jim”), а другие клиенты отправляют в них сообщения. Если миллион человек подписан на канал “btc-usd” и кто-то отправит туда актуальную стоимость биткоина, то Pusher Channels нужно будет доставить миллио�� сообщений. Мы делаем это за несколько миллисекунд.
Один сервер не может доставить такое количество сообщений сообщений за столь короткое время. Поэтому мы используем три проверенных временем приёма: fan-out, шардинг и балансировку нагрузки. Давайте посмотрим, что там в чёрном ящике.
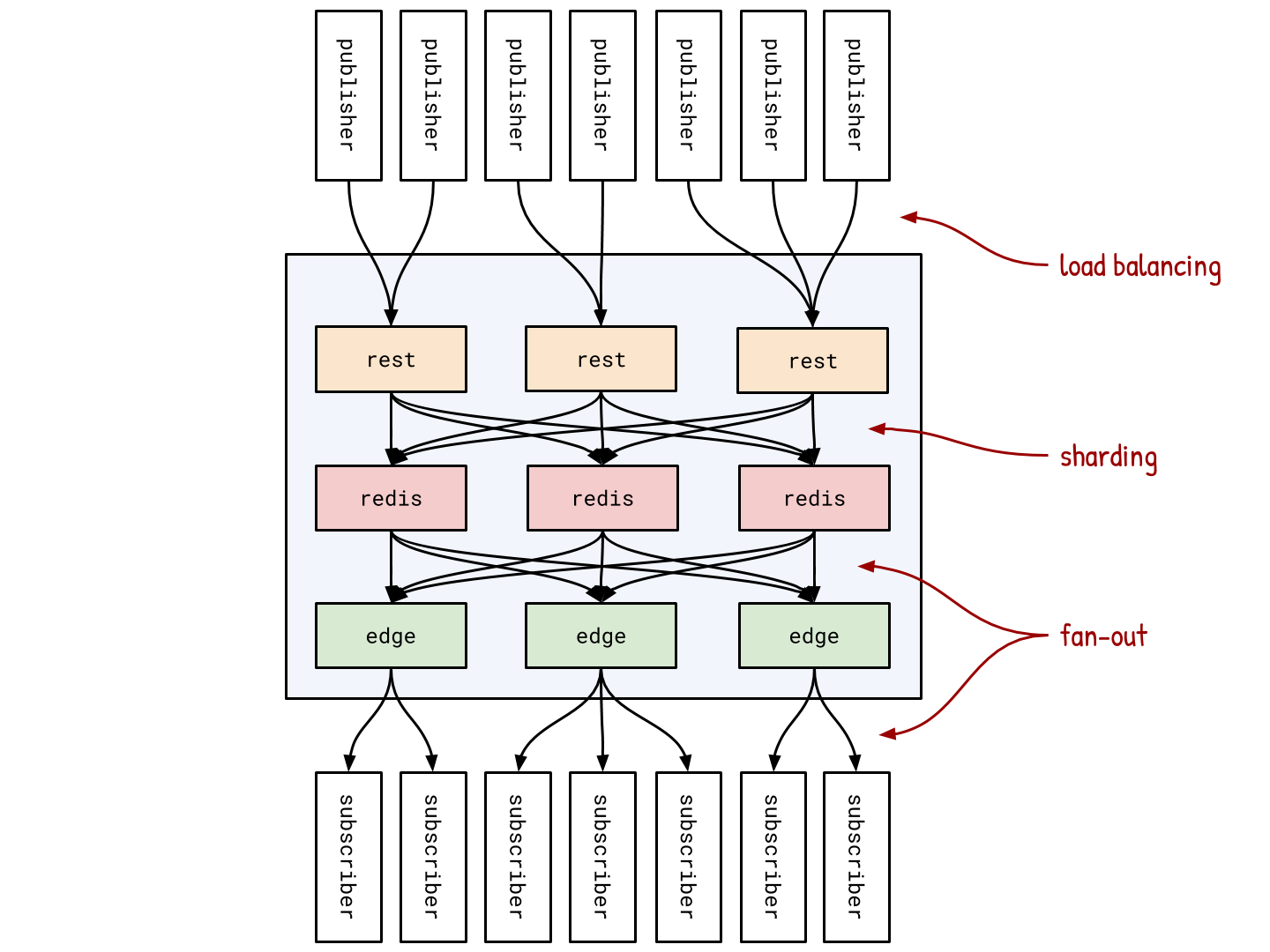
Миллионы подписчиков распределены по примерно 170 мощным edge-серверам, каждый из которых держит примерно 20.000 соединений. Каждый такой сервер помнит список каналов, которые интересны его клиентам, и подписывается на них в центральном Redis-сервисе. Даже если на edge-сервере 2000 клиентов заинтересованы в “btc-usd”, ему нужно подписаться на него всего один раз. Таким образом, когда в канал приходит новое сообщение, Redis отправляет 170 сообщений на edge-серверы, которые уже отправляют 20.000 сообщений своим подписчикам. Этот подход называется fan-out.
Но только fan-out нам недостаточно, поскольку всё равно есть один центральный Redis-компонент, через который проходят все, кто отправляет сообщения. Такая централизованность ограничивает количество отправляемых сообщений в секунду. Чтобы обойти это ограничение, центральный Redis-сервис состоит из многих Redis-шардов. Каждый канал, в свою очередь, прикреплён к Redis-шарду путём хеширования своего имени. Когда клиент хочет отправить сообщение, он идёт в rest сервис. Последний хеширует имя канала и по результату определяет необходимый Redis-шард, на который следует отправить сообщение. Такой подход называется шардинг.
Звучит так, будто мы просто сдвигаем централизацию с Redis-сервиса на rest-сервис. Но это не так, поскольку rest-сервис сам состоит из около 90 серверов, которые выполняют одинаковую работу: принимают запросы на публикацию, вычисляют Redis-шарды и отправляют на них сообщения. Когда паблишер хочет отправить сообщение, он идёт на один из многих rest-серверов. Этот подход называется балансировка нагрузки.
Вместе fan-out, шардинг и балансировка нагрузки позволяют добиться отсутствия у системы одного центрального компонента. Это свойство является ключевым для достижения горизонтальной масштабируемости, которая позволяет осуществлять отправку миллионов сообщений в секунду.
Мы рассмотрели центральные компоненты сервиса Pusher Channels, но есть и другие части, такие как метрики (как мы получаем это число в 10 трлн), webhooks (как мы сообщаем клиентам об интересных событиях), авторизация (ограничение доступа к каналам), данные об активных пользователях, rate limiting (как мы убеждаемся, что наши клиенты используют именно столько ресурсов, за сколько они заплатили, и что они не мешают другим клиентам). Весь этот дополнительный функционал должен быть реализован без ущерба пропускной способности, времени доставки сообщений и доступности нашего сервиса в целом.
