На заре карьеры я работал в компании, которая выпускала систему управления контентом. Эта CMS помогала отделам маркетинга самостоятельно управлять сайтами, а не полагаться на разработчиков при каждом изменении. Система помогла клиентам сократить операционные расходы, а мне — научиться создавать веб-приложения.
Хотя сам продукт имел очень общее назначение, клиенты обычно использовали его для конкретных задач. Эти задачи выжимали максимум из CMS, а разработчикам приходилось искать решение проблем. После десяти лет работы в таком окружении я узнал огромное число способов, как может сломаться веб-приложение в продакшне. Некоторые из них обсудим в этой статье.
Один из уроков, усвоенных за эти годы — отдельные инженеры обычно очень глубоко погружаются в интересующую их область, а всё остальное изучают до опасного поверхностно. Схема нормально работает в команде инженеров с хорошей коммуникацией, где знания перекрываются и заполняют отдельные пробелы у каждого из них. Но в командах с небольшим опытом или у отдельных инженеров происходит сбой.
Если вы начали работу в таком окружении, а затем приступили к созданию и развёртыванию веб-приложения с нуля, то очень быстро узнаете, что такое «до опасного поверхностные знания».
В отрасли существует ряд решений для решения этой проблемы: управляемые веб-приложения (Beanstalk, AppEngine и т. д.), управление контейнерами (Kubernetes, ECS и т. д.) и многие другие. Они хорошо работают из коробки и могут отлично решить проблему. Но это излишняя сложность при запуске веб-приложения, и обычно такие решения «просто работают».
К сожалению, не всегда они «просто работают». Если возникает какой-то нюанс, то хочется чуть больше знать об этом зловещем чёрном ящике.
В статье мы возьмём ненадёжную систему и доработаем её до разумного уровня надёжности. На каждом шагу используется реальная проблема, решение которой переносит нас на следующий этап. Я считаю, что эффективнее не анализировать все части окончательного дизайна, а использовать именно такой поэтапный подход. Он лучше демонстрирует, когда и в каком порядке принимать определённые решения. В конце концов, мы построим с нуля базовую структуру сервиса хостинга управляемых веб-приложений, и, надеюсь, подробно объясним причины существования каждой его части.
Представьте, что ваш бюджет на хостинг $500 в год, поэтому вы решили арендовать один сервер t2.medium на Amazon AWS. На момент написания статьи это около $400 в год.
Вы заранее знаете, что у вас будет система авторизации и что понадобится хранить информацию о пользователях, поэтому нужна база данных. Из-за ограниченного бюджета разместим её на нашем единственном сервере. В конечном итоге получаем такую инфраструктуру:

Рис. 1
Пока этого достаточно. На самом деле такая система может проработать довольно долго. Сервис маленький, менее 10 посещений в день. Возможно, и маленького инстанса было достаточно, но мы с оптимизмом смотрим на рост компании, поэтому предусмотрительно взяли t2.medium.
Ценность бизнеса — в базе данных, поэтому она очень важна. Нужно убедиться, что если сервер выходит из строя, вы не потеряете данные. Вероятно, следует убедиться, что содержимое базы не хранится на временном диске. Ведь если инстанс удалят, вы потеряете свои данные. Это очень страшная мысль.
Также следует убедиться, что у вас есть резервные копии на внешнем хранилище. S3 кажется хорошим местом для них, и относительно недорогим, поэтому давайте также настроим и это. И нужно обязательно проверить, что бэкап работает, периодически восстанавливая резервную копию.
Теперь система выглядит примерно так:

Рис. 2
Вы повысили надёжность базы данных, и пришло время подготовиться к «хабраэффекту», прогнав на сервере нагрузочный тест. Всё идет вроде нормально, пока не появляются ошибки 500, а затем поток ошибок 404, поэтому вы изучаете, что произошло.
Оказывается, вы понятия не имеете, что произошло, потому что писали логи в консоль и не направляли выдачу в файл. Вы также видите, что процесс не работает, так что можно с большой вероятностью предположить, что именно поэтому появляются ошибки 404. Накатывает волна облегчения, что вы грамотно запустили локальный нагрузочный тест, а не вызвали реальный хабраэффект в качестве тестовой нагрузки.
Вы исправляете проблему с автоматическим перезапуском, создав службу
И опять видим ошибки 500 (к счастью, без 404). Вы проверяете логи. Обнаруживается, что пул подключений к базе данных заполнен, потому что было установлено маленькое ограничение в 10 подключений. Обновляете ограничение, перезапускаете БД и снова запускаете нагрузочный тест. Всё идёт хорошо, поэтому вы решаете рассказать о своём сайте на Хабре.
Матерь божья! Ваш сервис мгновенно становится хитом. Вы попали на главную страницу и получаете 5000 просмотров за первые 30 минут — и видите комментарии. Что там пишут?
В безумной спешке вы настраиваете Nginx в качестве обратного прокси-сервера для своего приложения и настраиваете там статическую страницу 404. Вы также изменяете процедуру деплоя, чтобы отправлять статические файлы в S3: это необходимо для работы CloudFront CDN, чтобы сократить время загрузки в Австралии.
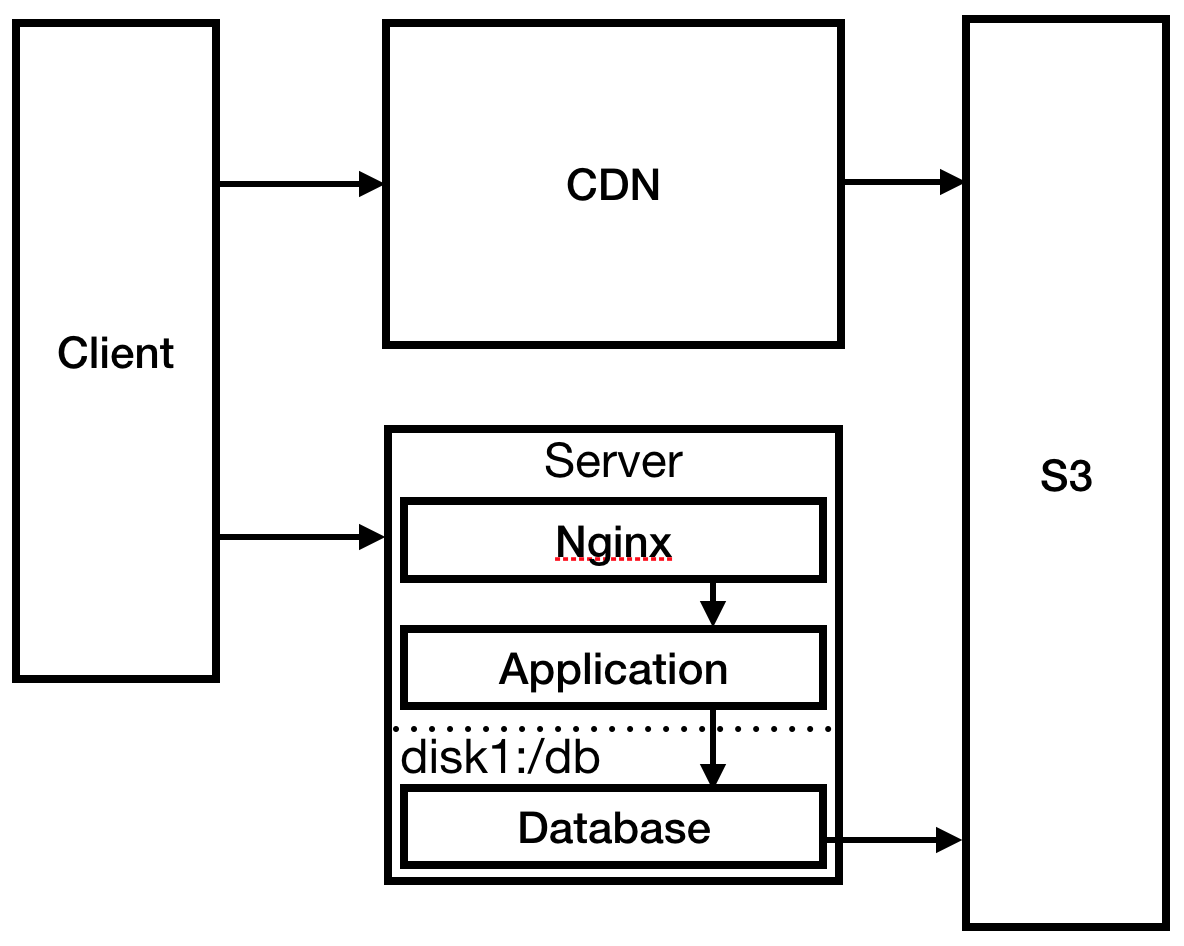
Рис. 3
Вы решили самую насущную проблему, идёте на сервер и проверяете логи. Ваше соединение SSH необычно лагает. После некоторого изучения вы видите, что файлы логов полностью израсходовали дисковое пространство, что привело к сбою процесса и предотвращению его повторного запуска. Создаёте диск гораздо большего размера и монтируете туда логи. Настраиваете
Проходят месяцы. Аудитория растёт. Сайт начинает тормозить. Вы заметили в мониторинге CloudWatch, что это происходит только между 00:00 и 12:00 UTC. Из-за одинакового времени начала и окончания лагов вы догадываетесь, что это связано с запланированной задачей на сервере. Проверяете crontab и понимаете, что одно задание запланировано на полночь: резервное копирование. Конечно, резервное копирование занимает двенадцать часов и приводит к перегрузке базы данных, вызывая значительное замедление работы сайта.
Вы читали об этом раньше — и решаете запускать резервные копии в подчинённой БД (slave). Затем вспоминаете: у вас же нет подчинённой базы данных, поэтому её нужно создать. Не имеет большого смысла запускать базу данных slave на том же сервере, поэтому вы решаете расширяться. Создаёте два новых сервера: один для базы данных master и один для базы данных slave. Изменяете резервное копирование для работы с подчинённой БД.
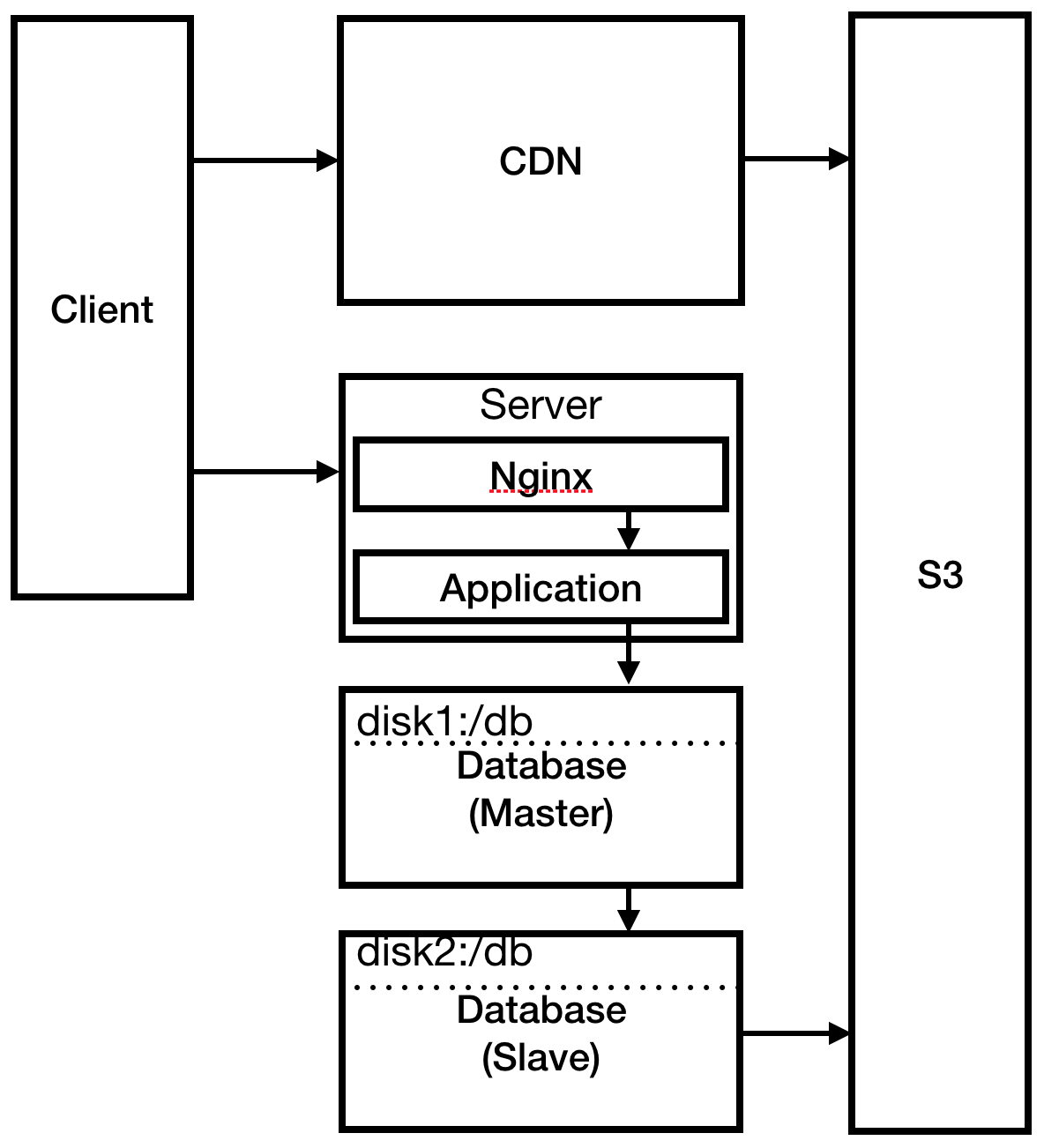
Рис. 4
Некоторое время всё идёт гладко. Проходят месяцы. Вы нанимаете разработчиков. Один из новичков вносит баг, который валит производственный сервер. Разработчик обвиняет среду разработки, которая отличается от продакшна. В его словах есть доля правды. Поскольку вы разумный человек с хорошим характером, то воспринимаете это событие как урок.
Пришло время создать дополнительные окружения: промежуточное (staging), QA и продакшн. К счастью, вы с первого дня автоматизировали создание инфраструктуры, так что всё проходит гладко и просто. У вас также с первого дня налажены хорошие практики непрерывной доставки, поэтому вы легко собираете конвейер из новых веток.
Отдел маркетинга настаивает на выпуске версии 2.0. Вы не совсем понимаете, что значит 2.0, но соглашаетесь. Пора готовиться к очередному всплеску трафика. Вы уже близки к пику на текущем сервере, так что пришло время для балансировки нагрузки. Amazon ELB легко делает это. Примерно в это время вы замечаете, что многоуровневые диаграммы в этой статье должны показывать слои сверху вниз, а не слева направо.
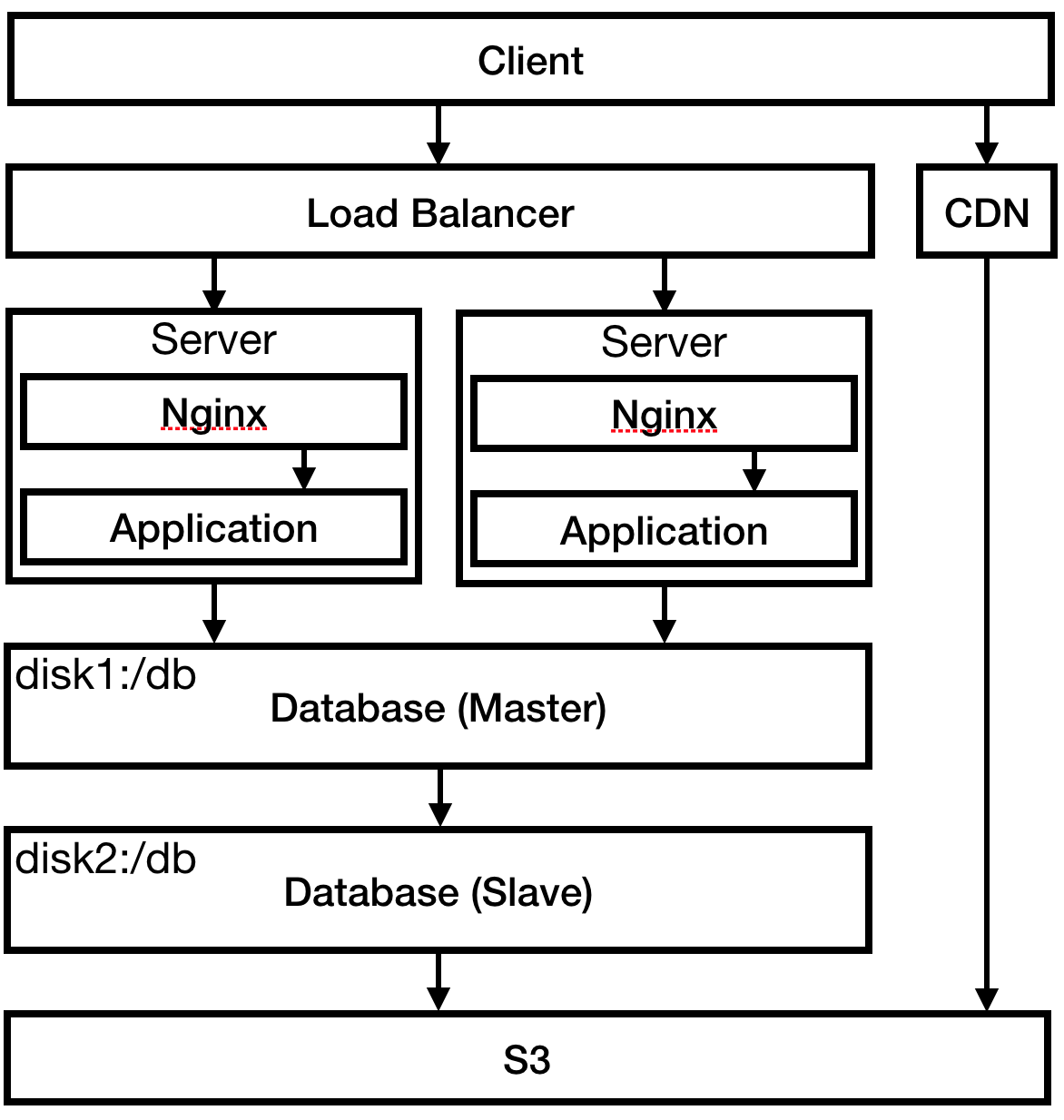
Рис. 5
Уверенный в том, что вы справитесь с нагрузкой, вы снова упоминаете свой сайт на Хабре. О чудо, он выдерживает трафик. Большой успех!
Всё вроде шло хорошо, пока вы не пошли проверять логи. На проверку 12 серверов ушёл час (по четыре сервера в каждом окружении). Настоящая нервотрёпка. К счастью, денег хватает на покупку стека ELK (ElasticSearch, LogStash, Kibana). Вы развёртываете его и направляете туда серверы со всех окружений.

Рис. 6
Теперь, можно снова обратиться к логам, вы смотрите их — и замечаете что-то странное. Они полны таких записей:
Вы не используете PHP или WordPress, так что это довольно странно. Вы замечаете похожие подозрительные записи в логах серверов БД и удивляетесь, как они вообще подключились к интернету. Пришло время внедрять публичные и частные подсети.

Рис. 7
Ещё раз проверьте логи. Попытки взлома остались, но теперь они ограничены портом 80 на балансировщике нагрузки, что немного утешает, потому что серверы приложений, серверы БД и стек ELK больше не в открытом доступе.
Несмотря на централизованные логи, вам надоело искать даунтаймы, проверяя логи вручную. Через Amazon CloudWatch вы настраиваете оповещения по электронной почте, когда диск, CPU и сеть достигают 80% утилизации. Отлично!
Просто шучу! В программном обеспечении нет такого понятия, как бесперебойная работа. Что-то обязательно сломается. К счастью, теперь у вас много инструментов, чтобы справиться с ситуацией.
Мы создали масштабируемое веб-приложение с бэкапами, откатами (с использованием синих/зелёных деплоев между продакшном и промежуточным этапом), централизованные логи, мониторинг и оповещение. Дальнейшее масштабирование, как правило, зависит от конкретных потребностей приложения.
На рынке много вариантов хостинга, которые берут на себя бóльшую часть упомянутых задач. Вместо самостоятельной разработки вы можете положиться на Beanstalk, AppEngine, GKE, ECS и т. д. Большинство этих сервисов автоматически настраивают разумные разрешения, подсистемы балансировки нагрузки, подсети и т. д. Это устраняет существенную часть нервотрёпки при запуске веб-приложения на быстром и надёжном бэкенде, который работает в течение длительного времени.
Несмотря на это, я считаю полезным понять, какую функциональность предоставляет каждая из этих платформ и почему они её предоставляют. Это облегчает выбор платформы на основе ваших собственных потребностей. Размещая приложение на такой платформе, вы уже будете знать, как работают эти модули. Когда что-то пойдёт не так, полезно знать инструментарий для решения проблемы.
В этой статье опущено много деталей. В ней не описывается, как автоматизировать создание инфраструктуры, как подготовить и настроить серверы. Не рассматривается создание сред разработки, настройка конвейеров непрерывной доставки, а также выполнение развёртываний и откатов. Мы не затронули сетевую безопасность, разделение ключей и принцип минимальных привилегий. Не рассказали о важности неизменной (immutable) инфраструктуры, stateless-серверов и миграций. Каждая из тем требует отдельной статьи.
Цель этого поста — общий обзор, как должно выглядеть разумное веб-приложение в продакшне. Будущие статьи могут ссылаться сюда и расширять тему.
На данный момент это всё.
Спасибо за чтение и удачного кодирования!
Примечание: не принимайте буквально последовательность из этой иллюстративной статьи. По отдельности все эти события действительно происходили со мной, но в разное время, в совершенно разных окружениях и на разных задачах.
Хотя сам продукт имел очень общее назначение, клиенты обычно использовали его для конкретных задач. Эти задачи выжимали максимум из CMS, а разработчикам приходилось искать решение проблем. После десяти лет работы в таком окружении я узнал огромное число способов, как может сломаться веб-приложение в продакшне. Некоторые из них обсудим в этой статье.
Один из уроков, усвоенных за эти годы — отдельные инженеры обычно очень глубоко погружаются в интересующую их область, а всё остальное изучают до опасного поверхностно. Схема нормально работает в команде инженеров с хорошей коммуникацией, где знания перекрываются и заполняют отдельные пробелы у каждого из них. Но в командах с небольшим опытом или у отдельных инженеров происходит сбой.
Если вы начали работу в таком окружении, а затем приступили к созданию и развёртыванию веб-приложения с нуля, то очень быстро узнаете, что такое «до опасного поверхностные знания».
В отрасли существует ряд решений для решения этой проблемы: управляемые веб-приложения (Beanstalk, AppEngine и т. д.), управление контейнерами (Kubernetes, ECS и т. д.) и многие другие. Они хорошо работают из коробки и могут отлично решить проблему. Но это излишняя сложность при запуске веб-приложения, и обычно такие решения «просто работают».
К сожалению, не всегда они «просто работают». Если возникает какой-то нюанс, то хочется чуть больше знать об этом зловещем чёрном ящике.
В статье мы возьмём ненадёжную систему и доработаем её до разумного уровня надёжности. На каждом шагу используется реальная проблема, решение которой переносит нас на следующий этап. Я считаю, что эффективнее не анализировать все части окончательного дизайна, а использовать именно такой поэтапный подход. Он лучше демонстрирует, когда и в каком порядке принимать определённые решения. В конце концов, мы построим с нуля базовую структуру сервиса хостинга управляемых веб-приложений, и, надеюсь, подробно объясним причины существования каждой его части.
Начало
Представьте, что ваш бюджет на хостинг $500 в год, поэтому вы решили арендовать один сервер t2.medium на Amazon AWS. На момент написания статьи это около $400 в год.
Вы заранее знаете, что у вас будет система авторизации и что понадобится хранить информацию о пользователях, поэтому нужна база данных. Из-за ограниченного бюджета разместим её на нашем единственном сервере. В конечном итоге получаем такую инфраструктуру:
Рис. 1
Пока этого достаточно. На самом деле такая система может проработать довольно долго. Сервис маленький, менее 10 посещений в день. Возможно, и маленького инстанса было достаточно, но мы с оптимизмом смотрим на рост компании, поэтому предусмотрительно взяли t2.medium.
Ценность бизнеса — в базе данных, поэтому она очень важна. Нужно убедиться, что если сервер выходит из строя, вы не потеряете данные. Вероятно, следует убедиться, что содержимое базы не хранится на временном диске. Ведь если инстанс удалят, вы потеряете свои данные. Это очень страшная мысль.
Также следует убедиться, что у вас есть резервные копии на внешнем хранилище. S3 кажется хорошим местом для них, и относительно недорогим, поэтому давайте также настроим и это. И нужно обязательно проверить, что бэкап работает, периодически восстанавливая резервную копию.
Теперь система выглядит примерно так:
Рис. 2
Вы повысили надёжность базы данных, и пришло время подготовиться к «хабраэффекту», прогнав на сервере нагрузочный тест. Всё идет вроде нормально, пока не появляются ошибки 500, а затем поток ошибок 404, поэтому вы изучаете, что произошло.
Оказывается, вы понятия не имеете, что произошло, потому что писали логи в консоль и не направляли выдачу в файл. Вы также видите, что процесс не работает, так что можно с большой вероятностью предположить, что именно поэтому появляются ошибки 404. Накатывает волна облегчения, что вы грамотно запустили локальный нагрузочный тест, а не вызвали реальный хабраэффект в качестве тестовой нагрузки.
Вы исправляете проблему с автоматическим перезапуском, создав службу
systemd, запускаете веб-сервер, который одновременно решает проблему с записью логов. Затем запускаете ещё один нагрузочный тест для проверки.И опять видим ошибки 500 (к счастью, без 404). Вы проверяете логи. Обнаруживается, что пул подключений к базе данных заполнен, потому что было установлено маленькое ограничение в 10 подключений. Обновляете ограничение, перезапускаете БД и снова запускаете нагрузочный тест. Всё идёт хорошо, поэтому вы решаете рассказать о своём сайте на Хабре.
День запуска
Матерь божья! Ваш сервис мгновенно становится хитом. Вы попали на главную страницу и получаете 5000 просмотров за первые 30 минут — и видите комментарии. Что там пишут?
У меня ошибка 404, поэтому пришлось открыть кэшированную версию страницы. Вот ссылка, если кому надо: ……
Ничего не открывается. Кроме того, у меня отключен Javascript. Почему люди считают, что я хочу грузить их Javascript на 2 МБ……
Загрузка домашней страницы занимает 4 секунды. Traceroute из Австралии показывает, что сервер размещен где-то в Техасе. Кроме того, почему первая страница загружает 2 мегабайта Javascript?
В безумной спешке вы настраиваете Nginx в качестве обратного прокси-сервера для своего приложения и настраиваете там статическую страницу 404. Вы также изменяете процедуру деплоя, чтобы отправлять статические файлы в S3: это необходимо для работы CloudFront CDN, чтобы сократить время загрузки в Австралии.
Рис. 3
Вы решили самую насущную проблему, идёте на сервер и проверяете логи. Ваше соединение SSH необычно лагает. После некоторого изучения вы видите, что файлы логов полностью израсходовали дисковое пространство, что привело к сбою процесса и предотвращению его повторного запуска. Создаёте диск гораздо большего размера и монтируете туда логи. Настраиваете
logrotate, чтобы файлы логов больше не разрастались до таких размеров.Проблемы с производительностью
Проходят месяцы. Аудитория растёт. Сайт начинает тормозить. Вы заметили в мониторинге CloudWatch, что это происходит только между 00:00 и 12:00 UTC. Из-за одинакового времени начала и окончания лагов вы догадываетесь, что это связано с запланированной задачей на сервере. Проверяете crontab и понимаете, что одно задание запланировано на полночь: резервное копирование. Конечно, резервное копирование занимает двенадцать часов и приводит к перегрузке базы данных, вызывая значительное замедление работы сайта.
Вы читали об этом раньше — и решаете запускать резервные копии в подчинённой БД (slave). Затем вспоминаете: у вас же нет подчинённой базы данных, поэтому её нужно создать. Не имеет большого смысла запускать базу данных slave на том же сервере, поэтому вы решаете расширяться. Создаёте два новых сервера: один для базы данных master и один для базы данных slave. Изменяете резервное копирование для работы с подчинённой БД.
Рис. 4
Рост команды
Некоторое время всё идёт гладко. Проходят месяцы. Вы нанимаете разработчиков. Один из новичков вносит баг, который валит производственный сервер. Разработчик обвиняет среду разработки, которая отличается от продакшна. В его словах есть доля правды. Поскольку вы разумный человек с хорошим характером, то воспринимаете это событие как урок.
Пришло время создать дополнительные окружения: промежуточное (staging), QA и продакшн. К счастью, вы с первого дня автоматизировали создание инфраструктуры, так что всё проходит гладко и просто. У вас также с первого дня налажены хорошие практики непрерывной доставки, поэтому вы легко собираете конвейер из новых веток.
Отдел маркетинга настаивает на выпуске версии 2.0. Вы не совсем понимаете, что значит 2.0, но соглашаетесь. Пора готовиться к очередному всплеску трафика. Вы уже близки к пику на текущем сервере, так что пришло время для балансировки нагрузки. Amazon ELB легко делает это. Примерно в это время вы замечаете, что многоуровневые диаграммы в этой статье должны показывать слои сверху вниз, а не слева направо.
Рис. 5
Уверенный в том, что вы справитесь с нагрузкой, вы снова упоминаете свой сайт на Хабре. О чудо, он выдерживает трафик. Большой успех!
Всё вроде шло хорошо, пока вы не пошли проверять логи. На проверку 12 серверов ушёл час (по четыре сервера в каждом окружении). Настоящая нервотрёпка. К счастью, денег хватает на покупку стека ELK (ElasticSearch, LogStash, Kibana). Вы развёртываете его и направляете туда серверы со всех окружений.
Рис. 6
Теперь, можно снова обратиться к логам, вы смотрите их — и замечаете что-то странное. Они полны таких записей:
GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1
Вы не используете PHP или WordPress, так что это довольно странно. Вы замечаете похожие подозрительные записи в логах серверов БД и удивляетесь, как они вообще подключились к интернету. Пришло время внедрять публичные и частные подсети.
Рис. 7
Ещё раз проверьте логи. Попытки взлома остались, но теперь они ограничены портом 80 на балансировщике нагрузки, что немного утешает, потому что серверы приложений, серверы БД и стек ELK больше не в открытом доступе.
Несмотря на централизованные логи, вам надоело искать даунтаймы, проверяя логи вручную. Через Amazon CloudWatch вы настраиваете оповещения по электронной почте, когда диск, CPU и сеть достигают 80% утилизации. Отлично!
Бесперебойная работа
Просто шучу! В программном обеспечении нет такого понятия, как бесперебойная работа. Что-то обязательно сломается. К счастью, теперь у вас много инструментов, чтобы справиться с ситуацией.
Мы создали масштабируемое веб-приложение с бэкапами, откатами (с использованием синих/зелёных деплоев между продакшном и промежуточным этапом), централизованные логи, мониторинг и оповещение. Дальнейшее масштабирование, как правило, зависит от конкретных потребностей приложения.
На рынке много вариантов хостинга, которые берут на себя бóльшую часть упомянутых задач. Вместо самостоятельной разработки вы можете положиться на Beanstalk, AppEngine, GKE, ECS и т. д. Большинство этих сервисов автоматически настраивают разумные разрешения, подсистемы балансировки нагрузки, подсети и т. д. Это устраняет существенную часть нервотрёпки при запуске веб-приложения на быстром и надёжном бэкенде, который работает в течение длительного времени.
Несмотря на это, я считаю полезным понять, какую функциональность предоставляет каждая из этих платформ и почему они её предоставляют. Это облегчает выбор платформы на основе ваших собственных потребностей. Размещая приложение на такой платформе, вы уже будете знать, как работают эти модули. Когда что-то пойдёт не так, полезно знать инструментарий для решения проблемы.
Заключение
В этой статье опущено много деталей. В ней не описывается, как автоматизировать создание инфраструктуры, как подготовить и настроить серверы. Не рассматривается создание сред разработки, настройка конвейеров непрерывной доставки, а также выполнение развёртываний и откатов. Мы не затронули сетевую безопасность, разделение ключей и принцип минимальных привилегий. Не рассказали о важности неизменной (immutable) инфраструктуры, stateless-серверов и миграций. Каждая из тем требует отдельной статьи.
Цель этого поста — общий обзор, как должно выглядеть разумное веб-приложение в продакшне. Будущие статьи могут ссылаться сюда и расширять тему.
На данный момент это всё.
Спасибо за чтение и удачного кодирования!
Примечание: не принимайте буквально последовательность из этой иллюстративной статьи. По отдельности все эти события действительно происходили со мной, но в разное время, в совершенно разных окружениях и на разных задачах.
