В последнее время на фондовых рынках наблюдается высокая волатильность, когда, например, стабильная бумага известной компании может враз потерять сразу несколько процентов на новостях о санкциях против ее руководства или наоборот взлететь до небес на позитивном отчете и ожиданиях инвесторов о сверхприбыльных дивидендах.
Как же определить, принесло ли владение данной ценной бумагой доход или одни лишь убытки и разочарование?
 (Источник)
(Источник)
В этой статье я расскажу Вам как определять и визуализировать скорректированный финансовый результат по ценным бумагам.
На примере клиентской отчетности Открытие Брокер мы рассмотрим парсинг и консолидацию брокерских отчетов для фондового рынка, построение архитектуры облачной отчетной системы с последующим простым и удобным анализом в AWS Quicksight.
Многие тренинги и обучающие уроки твердят нам о необходимости ведения трейдерского журнала, где фиксируются все параметры сделки для дальнейшего анализа и подведения итогов работы торговой стратегии. Согласен, что такой подход работы на Бирже позволяет дисциплинировать трейдера, повысить его сознательность, но может и здорово утомить от нудного процесса.
Признаюсь, поначалу и я пробовал старательно следовать совету ведения журнала, скрупулёзно записывал каждую сделку с ее параметрами в таблицу Excel, строил какие-то отчеты, сводные диаграммы, планировал будущие сделки, но… мне все это быстро надоело.
Зачастую, брокерские компании — это высокотехнологичные организации, которые предоставляют своим клиентам довольно качественную аналитику практически по всем интересующим вопросам. Справедливо заметить, что эта отчетность с каждым обновлением становится все лучше и лучше, но даже у самых продвинутых из них может не быть той кастомизации и консолидации, которую хотят видеть требовательные и пытливые клиенты.
К примеру, Открытие Брокер позволяет получать в личном кабинете брокерские отчеты в формате XML, но если у вас есть ИИС и обычный брокерский счет на Московской фондовой бирже (MOEX) – это будут два разных отчета, а если у вас есть еще счет на Санкт-Петербургской фондовой бирже (SPB), то к первым двум добавится еще один.
Итого, для получения консолидированного журнала инвестора, необходимо будет обработать три файла в формате XML.
Вышеупомянутые отчеты на MOEX и SPB немного отличаются своими форматами, что необходимо будет учесть в процессе имплементации маппинга данных.
На диаграмме ниже представлена модель архитектуры разрабатываемой системы:

Получим в Личном кабинете отчеты по всем трем счетам за максимально возможный период (можно разбить на несколько отчетов за каждый год), сохраняем их в формате XML и складываем в одну папку. В качестве тестовых данных для исследования будем использовать вымышленный клиентский портфель, но с максимально приближенными параметрами к рыночным реалиям.

Предположим, что у рассматриваемого нами инвестора Мистера Х небольшой портфель из пяти бумаг:
По нашим пяти бумагам могут быть сделки по покупке/продаже, выплата дивидендов и купона, может изменяться цена и т.д. Мы же хотим увидеть ситуацию на текущий момент, а именно: финансовый результат с учетом всех выплат, сделок и текущей рыночной стоимости.
И тут в дело вступает Python, считываем в один массив информацию из всех отчетов:
Несколько слов о том, что из себя представляют эти словари.
Обработаем массив XML-документов и заполним эти словари соответствующими данными:
Вся обработка идет в цикле по всем XML-данным из отчетов. Информация о торговой площадке, клиентском коде – одинаковая во всех отчетах, поэтому можно смело извлекать ее из одинаковых тегов без применения маппинга.
Но дальше приходится применять специальную конструкцию, которая обеспечит получение необходимого псевдонима для тега исходя из отчета (SPB или MOEX), т.к. одинаковые по своей сути данные в этих отчетах называются по-разному.
Функция get_allias возвращает наименование необходимого тега для обработки, принимая на вход наименование торговой площадки:
За обработку информации о состоянии клиентского портфеля отвечает функция get_briefcase:
Далее, с помощью функции get_deals извлекается информация о сделках:
Кроме обработки массива с информацией о параметрах сделки, здесь также выполняется расчет средней цены открытой позиции и реализованного PNL методом FIFO. За этот расчет отвечает класс PnlSnapshot, для создания которого с небольшими модификациями был принят за основу код представленный здесь: P&L calculation
И, наконец, самая сложная по реализации — функция получения информации о неторговых операциях — get_nontrade_operation. Сложность ее заключается в том, что в используемом для неторговых операций блоке отчета, нет четкой информации о виде операции и ценной бумаги, к которой эта операция привязана.
Соответственно, без регулярных выражений обойтись будет трудно, поэтому задействуем их по полной. Другая сторона вопроса в том, что не всегда в назначении платежа наименование компании совпадает с наименованием в портфеле или в сделках. Поэтому полученное наименование эмитента из назначения платежа нужно дополнительно соотнести со словарем. В качестве словаря будем использовать массив сделок, т.к. там наиболее полный перечень компаний.
Функция get_company_from_str извлекает наименование эмитента из комментария:
Функция get_company_from_briefcase приводит наименование компании �� словарю, если находит соответствие среди компаний, которые принимали участие в сделках:
И, наконец, итоговая функция сбора данных по неторговым операциям — get_nontrade_operation:
Результатом сбора данных из отчетов будут три DataFrame, которые представляют собой примерно следующее:
Итак, все, что нам остается сделать – это выполнить внешнее объединение таблицы сделок с таблицей информации о портфеле:
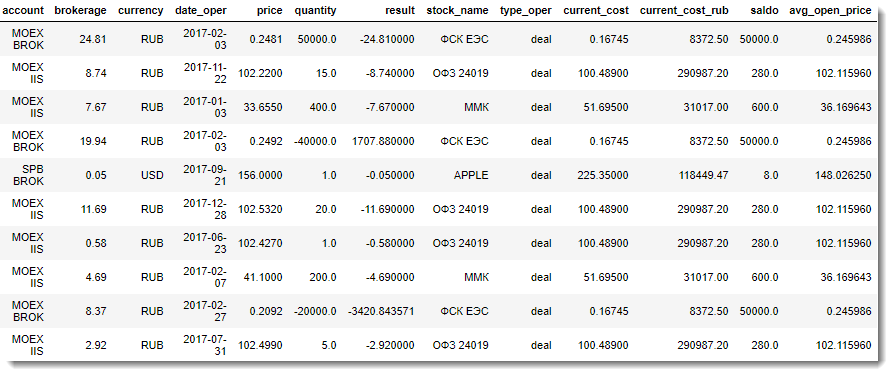
И, наконец, финальная часть обработки массива данных – это слияние полученного на предыдущем шаге массива данных с DataFrame для неторговых сделок.
Итог проделанной работы – одна большая плоская таблица со всей необходимой информацией для анализа:
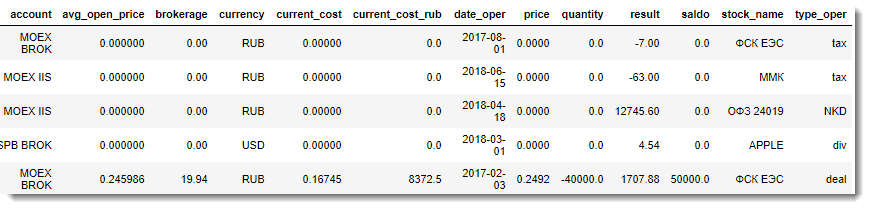
Результирующий набор данных (Финальный отчет) из DataFrame легко выгружается в CSV и далее может использоваться для детального анализа в любой BI-системе.
Прогресс не стоит на месте и сейчас большую популярность в обработке и хранении данных завоевывают облачные сервисы и бессерверные модели вычисления. Во многом это связано с простотой и дешевизной такого подхода, когда для построения архитектуры систем для сложных вычислений или обработки больших данных не надо покупать дорогостоящее оборудование, а Вы лишь арендуете на нужное вам время мощности в облаке и разворачиваете нужные ресурсы достаточно быстро за относительно небольшую плату.
Одним из самых крупных и известных на рынке поставщиков облачных технологий является компания Amazon. Рассмотрим на примере среды Amazon Web Services (AWS) построение аналитической системы для обработки данных по нашему инвестиционному портфелю.
В AWS обширный выбор инструментов, но мы будем пользоваться следующими:
С документацией у Amazon все в порядке, в частности, существует неплохая статья Best Practices When Using Athena with AWS Glue, где описано как создавать и пользоваться таблицами и данными, посредством AWS Glue. Давайте и мы воспользуемся основными идеями этой статьи и применим их для создания своей архитектуры аналитической отчетной системы.
Подготовленные нашим парсером отчетов CSV-файлы будем складывать в S3 bucket. Планируе��ся, что соответствующая папка на S3 будет пополняться каждую субботу – по завершении торговой недели, поэтому не обойтись без секционирования данных по дате формирования и обработки отчета.
Помимо оптимизации работы SQL-запросов к таким данным, этот подход позволит нам проводить дополнительный анализ, например, получать динамику изменения финансового результата по каждой бумаге и т.д.
Рассмотрим сформированную таблицу более подробно.
Если щёлкнуть по названию созданной таблицы, то мы перейдем на страницу с описанием метаданных. Внизу расположена схема таблицы и самым последним идет столбец, которого не было в исходном CSV-файле — date_report. Этот столбец AWS Glue создает автоматически на основе определения секций исходных данных (в бакете S3 мы специальным образом именовали папки — date_report=YYYY-MM-DD, что позволило использовать их как секции, разделенными по дате).
Имея в своем распоряжении загруженные обработанные данные, можем с легкостью приступить к их анализу. Для начала, рассмотрим возможности Amazon Athena как самого простого и быстрого способа выполнения аналитических запросов. Для этого переходим в сервис Amazon Athena, выбираем нужную нам базу данных (financial) и пишем такой SQL-код:
Этот запрос выведет нам чистый финансовый результат по каждой бумаге за все отчетные даты. Т.к. мы закачали трижды один и тот же отчет за разные даты, то и результат не будет меняться, что, конечно же, в условиях реального рынка будет по-другому:
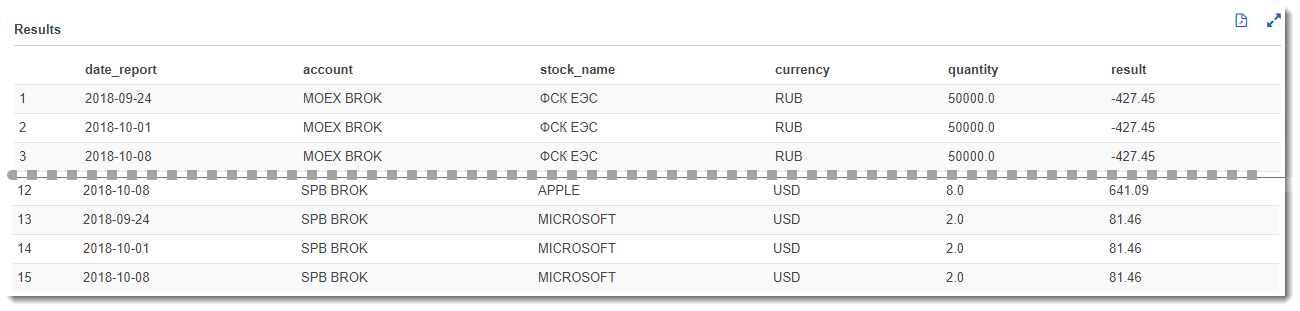
А что, если мы хотим визуализировать полученные данные в виде гибких таблиц или диаграмм? Тут на помощь приходит сервис Amazon QuickSight, с помощью которого можно настроить гибкую аналитику практически так же быстро, как и написать SQL-запрос. Перейдем в сервис Amazon QuickSight (если Вы там еще не зарегистрировались, то необходима регистрация).
Нажимаем на кнопку New analyses -> New dataset и в появившемся окне выбора источников для датасета, щелкаем на Athena:
Придумаем название нашему источнику данных, например «PNL_analysis» и нажимаем на кнопку «Create data source».
Следом откроется окно Choose your table, где необходимо выбрать базу данных и таблицу-источник данных. Выберем базу данных – financial, и таблицу в ней: my_traider_diary. По умолчанию используется таблица целиком, но при выборе «Use custom SQL» можно кастомизировать и тонко настроить нужную Вам выборку данных. Для примера воспользуемся таблицей целиком и нажмем на кнопку Edit/Preview Data.
Откроется новая страница, где можно провести дополнительные настройки и обработку имеющихся данных.
Теперь необходимо в наш датасет добавить дополнительные вычисляемые поля: квартал и год выполнения операции. Внимательный читатель может заметить, что подобные манипуляции легче было проделать на стороне парсера перед сохранением Финального отчета в CSV. Бесспорно, но моя цель сейчас продемонстрировать возможности и гибкость настроек BI-системы «на лету». Продолжим создание вычисляемых полей, нажимая на кнопку «New field».
Для выделения года выполняемой операции и квартала используются простые формулы:

Когда вычисляемые поля успешно созданы и добавлены в выборку, даем название нашему датасету, например, «my_pnl_analyze» и нажимаем на кнопку «Save and visualize».
После этого переносимся на основную доску Amazon QuickSight и первое, что мы должны сделать – это настроить фильтр для даты отчета (с учетом того, что одни и те же данные были собраны из трех секций). Выбираем отчетную дату 2018-10-01 и нажимаем на кнопку Apply и переходим на закладку Visualize.
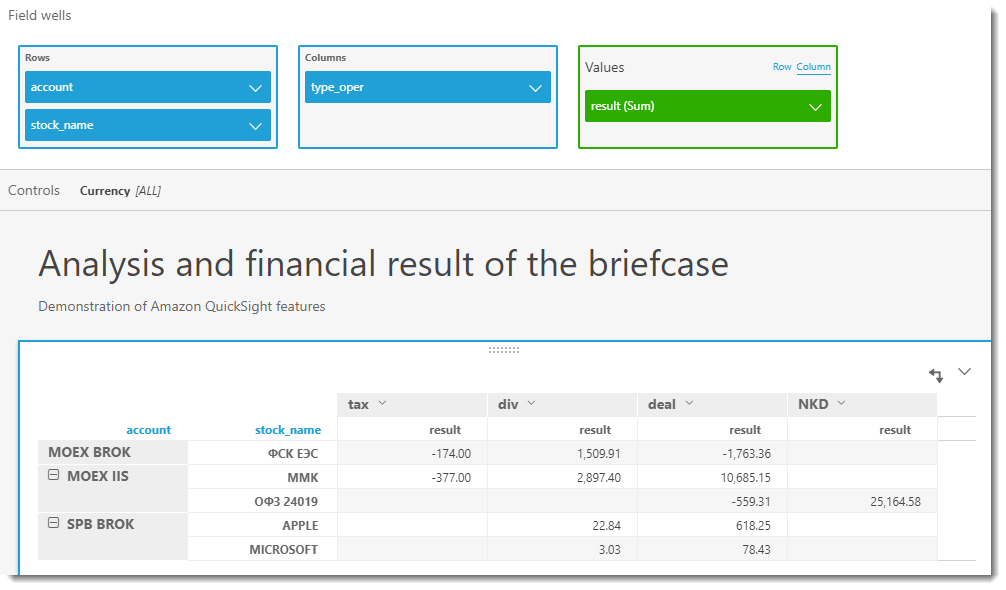
Теперь мы можем визуализировать результат по портфелю в любой плоскости, например, по каждой ценной бумаге внутри торгового счета, и разделенную в свою очередь по валютам (т.к. результат в разных валютах не сопоставим) и типам операций. Начнем с мощнейшего инструмента любого BI – сводных таблиц. Для экономии места и гибкости отображения, я вынес валюты в отдельный контрол (аналог среза в MS Excel)
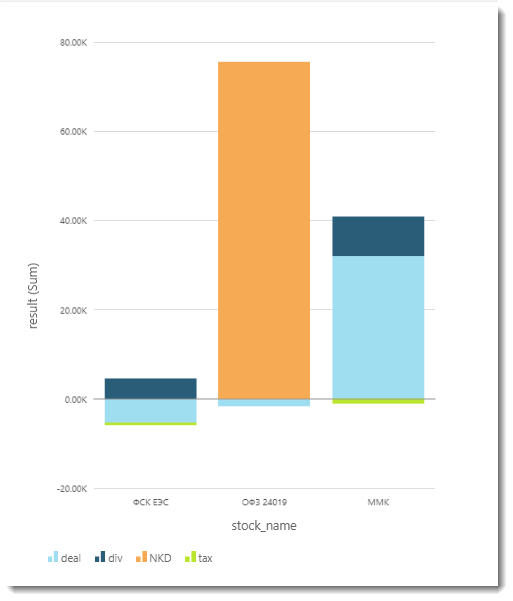
Следующий график – столбчатая диаграмма:
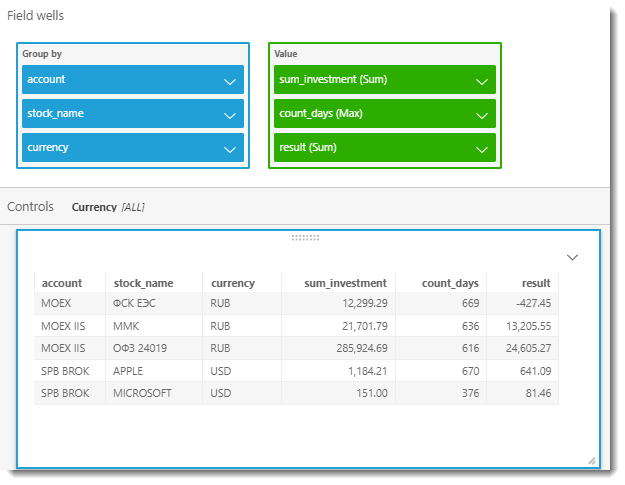
А теперь сформируем таблицу, которая покажет нам, сколько мы вложили в каждую бумагу, сколько дней она находится у нас в портфеле и какова доходность за весь период владения. Для этого добавим два новых вычисляемых поля: sum_investment и count_days.
Итоговая таблица представлена на скриншоте ниже:
Мы рассмотрели с Вами реализацию парсера отчетов и способы анализа подготовленных им данных «на лету» при помощи сервисов Amazon. Также затронули некоторые бизнесовые и фундаментальные аспекты анализа инвестиционного портфеля, т.к. эта тема практически необъятная и уместить ее в одной статье довольно сложно, думаю, что есть смысл поместить ее в отдельную публикацию или даже, цикл публикаций.
Что касается использования инструмента обработки отчетов брокера и задействованных в нем подходов и алгоритмов, то они могут применяться (с соответствующей модификацией) для обработки отчетности других Брокеров. В любом случае, если Вы соберетесь адаптировать код под свои нужды, я готов дать несколько советов, так что не стесняйтесь задавать вопросы – обязательно постараюсь на них ответить.
Уверен, что данная система найдет свое применение и будет иметь дальнейшее развитие. Например, планируется добавить в расчет полного PNL по портфелю учет депозитарной и иной комиссии (например, за вывод денежных средств), а так же погашение облигаций и т.д… Вычисляемые поля на стороне Quicksight были использованы с демонстрационной целью, в следующей версии парсера, все эти дополнительные столбцы будут перенесены в Python и будут рассчитываться на стороне парсера.
Как архитектор и главный бизнес-заказчик данного решения, я вижу дальнейшую модернизацию следующим образом: ну не хочу я каждый раз вручную запрашивать эти XML-отчеты! Конечно, пока иной возможности нет, но API Брокера с передачей токена и диапазона выборки идеально подошло бы для еженедельного получения сырой отчетности. Последующая полная автоматическая обработка на стороне Amazon: от срабатывания ETL-job на AWS Glue до получения готовых результатов в виде графиков и таблиц в Amazon QuickSight позволят полностью автоматизировать процесс.
Полный исходный код можно найти в моем репозитории на GitHub
Как же определить, принесло ли владение данной ценной бумагой доход или одни лишь убытки и разочарование?
В этой статье я расскажу Вам как определять и визуализировать скорректированный финансовый результат по ценным бумагам.
На примере клиентской отчетности Открытие Брокер мы рассмотрим парсинг и консолидацию брокерских отчетов для фондового рынка, построение архитектуры облачной отчетной системы с последующим простым и удобным анализом в AWS Quicksight.
Описание задачи
Многие тренинги и обучающие уроки твердят нам о необходимости ведения трейдерского журнала, где фиксируются все параметры сделки для дальнейшего анализа и подведения итогов работы торговой стратегии. Согласен, что такой подход работы на Бирже позволяет дисциплинировать трейдера, повысить его сознательность, но может и здорово утомить от нудного процесса.
Признаюсь, поначалу и я пробовал старательно следовать совету ведения журнала, скрупулёзно записывал каждую сделку с ее параметрами в таблицу Excel, строил какие-то отчеты, сводные диаграммы, планировал будущие сделки, но… мне все это быстро надоело.
Почему вести журнал трейдера вручную - это неудобно?
- ручное заполнение журнала (даже с использованием частичной автоматизации, в виде выгрузки из торгового терминала сделок за день) быстро утомляет;
- высок риск возникновения ошибки или опечатки при ручном вводе;
- может случиться так, что активный трейдер становится пассивным инвестором и он все реже и реже возвращается к этому журналу, а потом и вовсе забывает о нем (мой случай); ну, и наконец,
- мы умеем программировать, почему бы этим не воспользоваться и не автоматизировать весь процесс? Итак, погнали!
Зачастую, брокерские компании — это высокотехнологичные организации, которые предоставляют своим клиентам довольно качественную аналитику практически по всем интересующим вопросам. Справедливо заметить, что эта отчетность с каждым обновлением становится все лучше и лучше, но даже у самых продвинутых из них может не быть той кастомизации и консолидации, которую хотят видеть требовательные и пытливые клиенты.
К примеру, Открытие Брокер позволяет получать в личном кабинете брокерские отчеты в формате XML, но если у вас есть ИИС и обычный брокерский счет на Московской фондовой бирже (MOEX) – это будут два разных отчета, а если у вас есть еще счет на Санкт-Петербургской фондовой бирже (SPB), то к первым двум добавится еще один.
Итого, для получения консолидированного журнала инвестора, необходимо будет обработать три файла в формате XML.
Вышеупомянутые отчеты на MOEX и SPB немного отличаются своими форматами, что необходимо будет учесть в процессе имплементации маппинга данных.
Архитектура разрабатываемой системы
На диаграмме ниже представлена модель архитектуры разрабатываемой системы:
Реализация парсера
Получим в Личном кабинете отчеты по всем трем счетам за максимально возможный период (можно разбить на несколько отчетов за каждый год), сохраняем их в формате XML и складываем в одну папку. В качестве тестовых данных для исследования будем использовать вымышленный клиентский портфель, но с максимально приближенными параметрами к рыночным реалиям.
Предположим, что у рассматриваемого нами инвестора Мистера Х небольшой портфель из пяти бумаг:
- В отчете по бирже SPB будет две бумаги: Apple и Microsoft;
- В отчете по бирже MOEX (брокерский) одна бумага: ФСК ЕЭС;
- В отчете по бирже MOEX (ИИС) две бумаги: ММК и ОФЗ 24019;
По нашим пяти бумагам могут быть сделки по покупке/продаже, выплата дивидендов и купона, может изменяться цена и т.д. Мы же хотим увидеть ситуацию на текущий момент, а именно: финансовый результат с учетом всех выплат, сделок и текущей рыночной стоимости.
И тут в дело вступает Python, считываем в один массив информацию из всех отчетов:
my_files_list = [join('Data/', f) for f in listdir('Data/') if isfile(join('Data/', f))]
my_xml_data = []
# Считывание отчетов из каталога
for f in my_files_list:
tree = ET.parse(f)
root = tree.getroot()
my_xml_data.append(root)Для аналитики, из отчетов нам потребуется несколько сущностей, а именно:С целью подготовки выборки, будем использовать четыре словаря для описания вышеупомянутых множеств.
- Позиции бумаг в портфеле;
- Заключенные сделки;
- Неторговые операции и прочие движения по счету;
- Средние цены открытых позиций
dict_stocks = {'stock_name': [], 'account': [], 'currency': [], 'current_cost': [], 'current_cost_rub': [], 'saldo' : []}
dict_deals = {'stock_name': [], 'account': [], 'date_oper': [], 'type_oper': [], 'quantity': [], 'price': [], 'currency': [], 'brokerage': [], 'result': []}
dict_flows = {'stock_name': [], 'account': [], 'date_oper': [], 'type_oper': [], 'result': [], 'currency': []}
dict_avg_price = {'stock_name': [], 'account': [], 'avg_open_price' : []}Несколько слов о том, что из себя представляют эти словари.
Словарь dict_stocks
Словарь dict_stocks необходим для хранения общей информации по портфелю:
- Наименование бумаги (stock_name);
- Наименование счета (SPB, MOEX BROK, MOEX IIS) (account);
- Валюта, используемая для расчетов по данной бумаге (currency);
- Текущая стоимость (на момент формирования отчета в Личном кабинете Открытие Брокер) (current_cost). Здесь хочу заметить, что для сверхтребовательных клиентов, можно в будущем внести дополнительную доработку и использовать динамическое получение котировки ценной бумаги из торгового терминала или с сайта соответствующей биржи;
- Текущая стоимость позиции ценной бумаги на момент формирования отчета (current_cost_rub)
Аналогично вышеупомянутому пункту, здесь можно так же получать курс ЦБ на текущий момент или биржевой курс, кому как нравится. - Текущий остаток ценных бумаг (saldo)
Словарь dict_deals
Словарь dict_deals необходим для хранения следующей информации по совершенным сделкам:
- Наименование бумаги (stock_name);
- Наименование счета (SPB, MOEX BROK, MOEX IIS) (account);
- Дата совершения сделки, т.е. Т0 (date_oper);
- Тип операции (type_oper);
- Объем бумаг, участвующих в сделке (quantity);
- Цена, по которой была исполнена сделка (price);
- Валюта, в которой была совершена операция (currency);
- Брокерская комиссия за сделку (brokerage);
- Финансовый результат по сделке (result)
Словарь dict_flows
Словарь dict_flows отражает движение средств по клиентскому счету и используется для хранения следующей информации:
- Наименование бумаги (stock_name);
- Наименование счета (SPB, MOEX BROK, MOEX IIS) (account);
- Дата совершения сделки, т.е. Т0 (date_oper);
- Тип операции (type_oper). Может принимать несколько значений: div, NKD, tax;
- Валюта, в которой была совершена операция (currency);
- Финансовый результат операции (result)
Словарь dict_avg_price
Словарь dict_avg_price необходим для учета информации по средней цене покупки по каждой бумаге:
- Наименование бумаги (stock_name);
- Наименование счета (SPB, MOEX BROK, MOEX IIS) (account);
- Средняя цена открытой позиции (avg_open_price)
Обработаем массив XML-документов и заполним эти словари соответствующими данными:
# Сбор данных из соответствующих частей отчетов
for XMLdata in my_xml_data:
# Информация о Бирже и счете
exchange_name = 'SPB' if XMLdata.get('board_list') == 'ФБ СПБ' else 'MOEX'
client_code = XMLdata.get('client_code')
account_name = get_account_name(exchange_name, client_code)
# Маппинг тегов
current_position, deals, flows, stock_name, \
saldo, ticketdate, price, brokerage, \
operationdate, currency, \
current_cost, current_cost_rub, \
stock_name_deal, payment_currency, currency_flows = get_allias(exchange_name)
# Информация о состоянии клиентского портфеля
get_briefcase(XMLdata)
df_stocks = pd.DataFrame(dict_stocks)
df_stocks.set_index("stock_name", drop = False, inplace = True)
# Информация о сделках
get_deals(XMLdata)
df_deals = pd.DataFrame(dict_deals)
df_avg = pd.DataFrame(dict_avg_price)
# Информация о неторговых операциях по счету
get_nontrade_operation(XMLdata)
df_flows = pd.DataFrame(dict_flows)Вся обработка идет в цикле по всем XML-данным из отчетов. Информация о торговой площадке, клиентском коде – одинаковая во всех отчетах, поэтому можно смело извлекать ее из одинаковых тегов без применения маппинга.
Но дальше приходится применять специальную конструкцию, которая обеспечит получение необходимого псевдонима для тега исходя из отчета (SPB или MOEX), т.к. одинаковые по своей сути данные в этих отчетах называются по-разному.
Расхождения по тегам
- Комиссия брокера по сделке в отчете SBP лежит в теге brokerage, а в отчете MOEX — broker_commission;
- Дата неторговой операции по счету в отчете SPB – это operationdate, а в MOEX — operation_date и т.д.
Пример маппинга тегов
tags_mapping = {
'SPB': {
'current_position': 'briefcase_position',
'deals': 'closed_deal',
'flows': 'nontrade_money_operation',
...
'stock_name_deal': 'issuername',
'paymentcurrency': 'paymentcurrency',
'currency_flows': 'currencycode'
},
'MOEX': {
'current_position': 'spot_assets',
'deals': 'spot_main_deals_conclusion',
'flows': 'spot_non_trade_money_operations',
...
'stock_name_deal': 'security_name',
'paymentcurrency': 'price_currency_code',
'currency_flows': 'currency_code'
}
}
Функция get_allias возвращает наименование необходимого тега для обработки, принимая на вход наименование торговой площадки:
Функция get_allias
def get_allias(exchange_name):
return(
tags_mapping[exchange_name]['current_position'],
tags_mapping[exchange_name]['deals'],
tags_mapping[exchange_name]['flows'],
...
tags_mapping[exchange_name]['stock_name_deal'],
tags_mapping[exchange_name]['paymentcurrency'],
tags_mapping[exchange_name]['currency_flows']
)
За обработку информации о состоянии клиентского портфеля отвечает функция get_briefcase:
Функция get_briefcase
def get_briefcase(XMLdata):
# В отчете ФБ СПБ портфель находится под тегом briefcase_position
briefcase_position = XMLdata.find(current_position)
if not briefcase_position:
return
try:
for child in briefcase_position:
stock_name_reduce = child.get(stock_name).upper()
stock_name_reduce = re.sub('[,\.]|(\s?INC)|(\s+$)|([-\s]?АО)', '', stock_name_reduce)
dict_stocks['stock_name'].append(stock_name_reduce)
dict_stocks['account'].append(account_name)
dict_stocks['currency'].append(child.get(currency))
dict_stocks['current_cost'].append(float(child.get(current_cost)))
dict_stocks['current_cost_rub'].append(float(child.get(current_cost_rub)))
dict_stocks['saldo'].append(float(child.get(saldo)))
except Exception as e:
print('get_briefcase --> Oops! It seems we have a BUG!', e) Далее, с помощью функции get_deals извлекается информация о сделках:
Функция get_deals
def get_deals(XMLdata):
stock_name_proc = ''
closed_deal = XMLdata.find(deals)
if not closed_deal:
return
# Отчет по SPB имеет иную сортировку - только по дате сделки,
# тогда как отчеты MOEX: по бумаге, а потом по дате сделки
# Отсортируем сделки по бумаге:
if exchange_name == 'SPB':
sortchildrenby(closed_deal, stock_name_deal)
for child in closed_deal:
sortchildrenby(child, stock_name_deal)
try:
for child in closed_deal:
stock_name_reduce = child.get(stock_name_deal).upper()
stock_name_reduce = re.sub('[,\.]|(\s?INC)|(\s+$)|([-\s]?АО)', '', stock_name_reduce)
dict_deals['stock_name'].append(stock_name_reduce)
dict_deals['account'].append(account_name)
dict_deals['date_oper'].append(to_dt(child.get(ticketdate)).strftime('%Y-%m-%d'))
current_cost = get_current_cost(stock_name_reduce)
# В отчете по SPB один тег на количество - quantity,
# а на MOEX целых два: buy_qnty и sell_qnty
if exchange_name == 'MOEX':
if child.get('buy_qnty'):
quantity = float(child.get('buy_qnty'))
else:
quantity = - float(child.get('sell_qnty'))
else:
quantity = float(child.get('quantity'))
dict_deals['quantity'].append(quantity)
dict_deals['price'].append(float(child.get('price')))
dict_deals['type_oper'].append('deal')
dict_deals['currency'].append(child.get(payment_currency))
brok_comm = child.get(brokerage)
if brok_comm is None:
brok_comm = 0
else:
brok_comm = float(brok_comm)
dict_deals['brokerage'].append(float(brok_comm))
# Доходность по каждой сделке и средняя цена позиции
if stock_name_proc != stock_name_reduce:
if stock_name_proc != '':
put_avr_price_in_df(account_name, stock_name_proc, \
pnl.m_net_position, pnl.m_avg_open_price)
current_cost = get_current_cost(stock_name_proc)
pnl.update_by_marketdata(current_cost)
if len(dict_deals['result']) > 0:
if exchange_name != 'SPB':
dict_deals['result'][-1] = pnl.m_unrealized_pnl * 0.87 -dict_deals['brokerage'][-2]
else:
dict_deals['result'][-1] = pnl.m_unrealized_pnl - dict_deals['brokerage'][-2]
stock_name_proc = stock_name_reduce
pnl = PnlSnapshot(stock_name_proc, float(child.get('price')), quantity)
dict_deals['result'].append(-1 * brok_comm)
else:
pnl.update_by_tradefeed(float(child.get('price')), quantity)
# Продажа бумаг, фиксация результата
if quantity < 0:
if pnl.m_realized_pnl > 0 and exchange_name != 'SPB':
pnl_sum = pnl.m_realized_pnl * 0.87 - brok_comm
else:
pnl_sum = pnl.m_realized_pnl - brok_comm
dict_deals['result'].append(float(pnl_sum))
else:
pnl.update_by_marketdata(current_cost)
dict_deals['result'].append(-1 * brok_comm)
put_avr_price_in_df(account_name, stock_name_proc, \
pnl.m_net_position, pnl.m_avg_open_price)
current_cost = get_current_cost(stock_name_proc)
pnl.update_by_marketdata(current_cost)
if len(dict_deals['result']) > 0:
if exchange_name != 'SPB':
dict_deals['result'][-1] = pnl.m_unrealized_pnl * 0.87 -dict_deals['brokerage'][-2]
else:
dict_deals['result'][-1] = pnl.m_unrealized_pnl - dict_deals['brokerage'][-2]
except Exception as e:
print('get_deals --> Oops! It seems we have a BUG!', e) Кроме обработки массива с информацией о параметрах сделки, здесь также выполняется расчет средней цены открытой позиции и реализованного PNL методом FIFO. За этот расчет отвечает класс PnlSnapshot, для создания которого с небольшими модификациями был принят за основу код представленный здесь: P&L calculation
И, наконец, самая сложная по реализации — функция получения информации о неторговых операциях — get_nontrade_operation. Сложность ее заключается в том, что в используемом для неторговых операций блоке отчета, нет четкой информации о виде операции и ценной бумаги, к которой эта операция привязана.
Пример назначений платежа по неторговым операциям
Выплата дивидендов или накопленного купонного дохода может быть указана так:
- Выплата дохода клиент <777777> дивиденды <APPLE INC-ао> --> выплата дивидендов из отчета SPB;
- Выплата дохода клиент <777777> дивиденды <MICROSOFT COM-ао>
- Выплата дохода клиент 777777i (НКД 2 ОФЗ 24019) налог к удержанию 0.00 рублей --> выплата купона из отчета MOEX;
- Выплата дохода клиент 777777 дивиденды ФСК ЕЭС-ао налог к удержанию XX.XX рублей --> выплата дивидендов из отчета MOEX. и т.д.
Соответственно, без регулярных выражений обойтись будет трудно, поэтому задействуем их по полной. Другая сторона вопроса в том, что не всегда в назначении платежа наименование компании совпадает с наименованием в портфеле или в сделках. Поэтому полученное наименование эмитента из назначения платежа нужно дополнительно соотнести со словарем. В качестве словаря будем использовать массив сделок, т.к. там наиболее полный перечень компаний.
Функция get_company_from_str извлекает наименование эмитента из комментария:
Функция get_company_from_str
def get_company_from_str(comment):
company_name = ''
# Шаблоны для случаев дивиденды/купон
flows_pattern = [
'^.+дивиденды\s<(\w+)?.+-ао>$',
'^.+дивиденды\s(.+)-а.+$',
'^.+\(НКД\s\d?\s(.+)\).+$',
'^.+дивидендам\s(.+)-.+$'
]
for pattern in flows_pattern:
match = re.search(pattern, comment)
if match:
return match.group(1).upper()
return company_nameФункция get_company_from_briefcase приводит наименование компании �� словарю, если находит соответствие среди компаний, которые принимали участие в сделках:
Функция get_company_from_briefcase
def get_company_from_briefcase(company_name):
company_name_full = None
value_from_dic = df_deals[df_deals['stock_name'].str.contains(company_name)]
company_arr = value_from_dic['stock_name'].unique()
if len(company_arr) == 1:
company_name_full = company_arr[0]
return company_name_fullИ, наконец, итоговая функция сбора данных по неторговым операциям — get_nontrade_operation:
Функция get_nontrade_operation
def get_nontrade_operation(XMLdata):
nontrade_money_operation = XMLdata.find(flows)
if not nontrade_money_operation:
return
try:
for child in nontrade_money_operation:
comment = child.get('comment')
type_oper_match = re.search('дивиденды|НКД|^.+налог.+дивидендам.+$', comment)
if type_oper_match:
company_name = get_company_from_str(comment)
type_oper = get_type_oper(comment)
dict_flows['stock_name'].append(company_name)
dict_flows['account'].append(account_name)
dict_flows['date_oper'].append(to_dt(child.get(operationdate)).strftime('%Y-%m-%d'))
dict_flows['type_oper'].append(type_oper)
dict_flows['result'].append(float(child.get('amount')))
dict_flows['currency'].append(child.get(currency_flows))
except Exception as e:
print('get_nontrade_operation --> Oops! It seems we have a BUG!', e) Результатом сбора данных из отчетов будут три DataFrame, которые представляют собой примерно следующее:
- DataFrame с информацией по средним ценам открытых позиций:
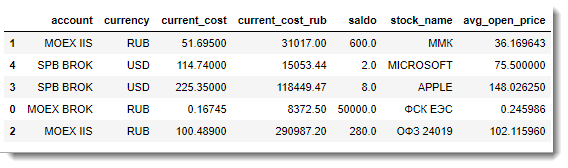
- DataFrame с информацией о сделках:
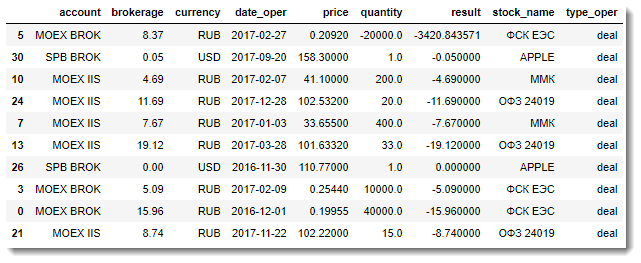
- DataFrame с информацией о неторговых операциях:
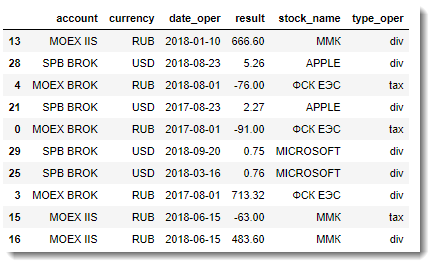
Итак, все, что нам остается сделать – это выполнить внешнее объединение таблицы сделок с таблицей информации о портфеле:
df_result = pd.merge(df_deals, df_stocks_avg, how='outer', on=['stock_name', 'account', 'currency']).fillna(0)
df_result.sample(10)И, наконец, финальная часть обработки массива данных – это слияние полученного на предыдущем шаге массива данных с DataFrame для неторговых сделок.
Итог проделанной работы – одна большая плоская таблица со всей необходимой информацией для анализа:
df_result_full = df_result.append(df_flows, ignore_index=True).fillna(0)
df_result_full.sample(10).head()Результирующий набор данных (Финальный отчет) из DataFrame легко выгружается в CSV и далее может использоваться для детального анализа в любой BI-системе.
if not exists('OUTPUT'): makedirs('OUTPUT')
report_name = 'OUTPUT\my_trader_diary.csv'
df_result_full.to_csv(report_name, index = False, encoding='utf-8-sig')Загрузка и обработка данных в AWS
Прогресс не стоит на месте и сейчас большую популярность в обработке и хранении данных завоевывают облачные сервисы и бессерверные модели вычисления. Во многом это связано с простотой и дешевизной такого подхода, когда для построения архитектуры систем для сложных вычислений или обработки больших данных не надо покупать дорогостоящее оборудование, а Вы лишь арендуете на нужное вам время мощности в облаке и разворачиваете нужные ресурсы достаточно быстро за относительно небольшую плату.
Одним из самых крупных и известных на рынке поставщиков облачных технологий является компания Amazon. Рассмотрим на примере среды Amazon Web Services (AWS) построение аналитической системы для обработки данных по нашему инвестиционному портфелю.
В AWS обширный выбор инструментов, но мы будем пользоваться следующими:
- Amazon S3 – объектное хранилище, которое позволяет хранить практически неограниченные объемы информации;
- AWS Glue – мощнейший облачный ETL-сервис, который может сам определять по заданным исходным данным структуру и генерить ETL-код;
- Amazon Athena – serverless сервис интерактивных запросов SQL, позволяет быстро анализировать данные из S3 без особой подготовки. Еще он имеет доступ к метаданным, которые подготавливает AWS Glue, что позволяет сразу после прохождения ETL обращаться к данным;
- Amazon QuickSight – serverless BI-сервис, можно строить любую визуализацию, аналитические отчеты «на лету» и т.д..
С документацией у Amazon все в порядке, в частности, существует неплохая статья Best Practices When Using Athena with AWS Glue, где описано как создавать и пользоваться таблицами и данными, посредством AWS Glue. Давайте и мы воспользуемся основными идеями этой статьи и применим их для создания своей архитектуры аналитической отчетной системы.
Подготовленные нашим парсером отчетов CSV-файлы будем складывать в S3 bucket. Планируе��ся, что соответствующая папка на S3 будет пополняться каждую субботу – по завершении торговой недели, поэтому не обойтись без секционирования данных по дате формирования и обработки отчета.
Помимо оптимизации работы SQL-запросов к таким данным, этот подход позволит нам проводить дополнительный анализ, например, получать динамику изменения финансового результата по каждой бумаге и т.д.
Работа с Amazon S3
- Создадим бакет на S3, назовем его «report-parser»;
- В этом бакете «report-parser» создадим папку под названием «my_trader_diary»;
- В каталоге «my_trader_diary» создадим каталог с датой текущего отчета, например, «date_report=2018-10-01» и поместим в него CSV-файл;
- Только ради эксперимента и лучшего понимания секционирования создадим еще два каталога: «date_report=2018-09-27» и «date_report=2018-10-08». В них положим тот же CSV-файл;
- Итоговый S3 бакет «report-parser» должен иметь вид как показано на картинки ниже:

Работа с AWS Glue
По большому счету, можно обойтись лишь Amazon Athena чтобы создать внешнюю таблицу из данных, лежащих на S3, но AWS Glue – более гибкий и удобный для этого инструмент.
- Заходим в AWS Glue и создаем новый Crawler, который будет из разрозненных по отчетным датам CSV-файлов собирать одну таблицу:
- Задаем имя нового Crawler;
- Указываем хранилище, откуда брать данные (s3://report-parser/my_trader_diary/)
- Выбираем или создаем новую IAM роль, которая будет иметь доступ к запуску Crawler и доступ к указанному ресурсу на S3;
- Далее, необходимо задать частоту запуска. Пока ставим по требованию, но в дальнейшем, думаю, это изменится и запуск станет еженедельным;
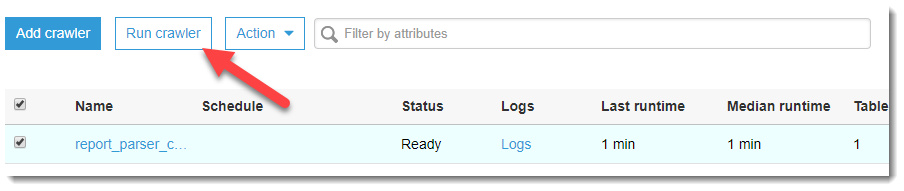
- Сохраняем и ждем, когда Crawler создастся.
- Когда Crawler перейдет в состояние Ready, запускаем его!
- Как только он отработает, в закладке AWS Glue: Database -> Tables появится новая таблица my_trader_diary:
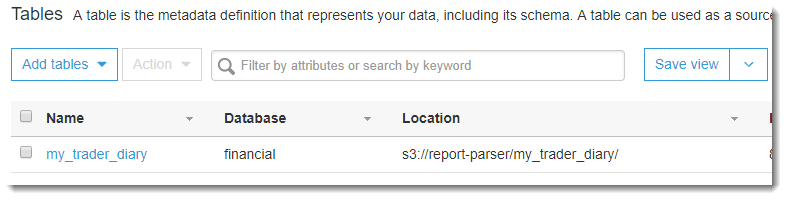
Рассмотрим сформированную таблицу более подробно.
Если щёлкнуть по названию созданной таблицы, то мы перейдем на страницу с описанием метаданных. Внизу расположена схема таблицы и самым последним идет столбец, которого не было в исходном CSV-файле — date_report. Этот столбец AWS Glue создает автоматически на основе определения секций исходных данных (в бакете S3 мы специальным образом именовали папки — date_report=YYYY-MM-DD, что позволило использовать их как секции, разделенными по дате).
Секционирование таблицы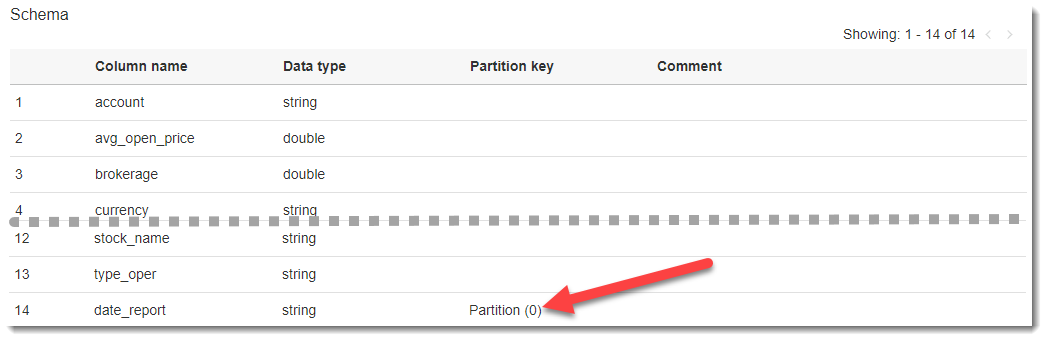
На той же странице в верхнем правом углу есть кнопка View partitions, нажав на которую, мы можем увидеть из каких секций состоит наша сформированная таблица:
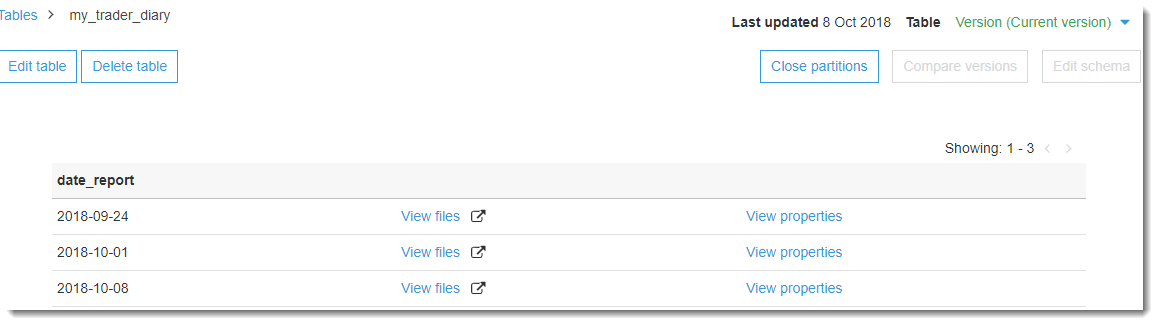
На той же странице в верхнем правом углу есть кнопка View partitions, нажав на которую, мы можем увидеть из каких секций состоит наша сформированная таблица:
Анализ данных
Имея в своем распоряжении загруженные обработанные данные, можем с легкостью приступить к их анализу. Для начала, рассмотрим возможности Amazon Athena как самого простого и быстрого способа выполнения аналитических запросов. Для этого переходим в сервис Amazon Athena, выбираем нужную нам базу данных (financial) и пишем такой SQL-код:
select
d.date_report, d.account,
d.stock_name, d.currency,
sum(d.quantity) as quantity,
round(sum(d.result), 2) as result
from my_trader_diary d
group by
d.date_report, d.account,
d.stock_name, d.currency
order by
d.account, d.stock_name,
d.date_report;Этот запрос выведет нам чистый финансовый результат по каждой бумаге за все отчетные даты. Т.к. мы закачали трижды один и тот же отчет за разные даты, то и результат не будет меняться, что, конечно же, в условиях реального рынка будет по-другому:
А что, если мы хотим визуализировать полученные данные в виде гибких таблиц или диаграмм? Тут на помощь приходит сервис Amazon QuickSight, с помощью которого можно настроить гибкую аналитику практически так же быстро, как и написать SQL-запрос. Перейдем в сервис Amazon QuickSight (если Вы там еще не зарегистрировались, то необходима регистрация).
Нажимаем на кнопку New analyses -> New dataset и в появившемся окне выбора источников для датасета, щелкаем на Athena:
Придумаем название нашему источнику данных, например «PNL_analysis» и нажимаем на кнопку «Create data source».
Следом откроется окно Choose your table, где необходимо выбрать базу данных и таблицу-источник данных. Выберем базу данных – financial, и таблицу в ней: my_traider_diary. По умолчанию используется таблица целиком, но при выборе «Use custom SQL» можно кастомизировать и тонко настроить нужную Вам выборку данных. Для примера воспользуемся таблицей целиком и нажмем на кнопку Edit/Preview Data.
Откроется новая страница, где можно провести дополнительные настройки и обработку имеющихся данных.
Теперь необходимо в наш датасет добавить дополнительные вычисляемые поля: квартал и год выполнения операции. Внимательный читатель может заметить, что подобные манипуляции легче было проделать на стороне парсера перед сохранением Финального отчета в CSV. Бесспорно, но моя цель сейчас продемонстрировать возможности и гибкость настроек BI-системы «на лету». Продолжим создание вычисляемых полей, нажимая на кнопку «New field».
Создание нового поля
Для выделения года выполняемой операции и квартала используются простые формулы:
Заполнение формул для нового поля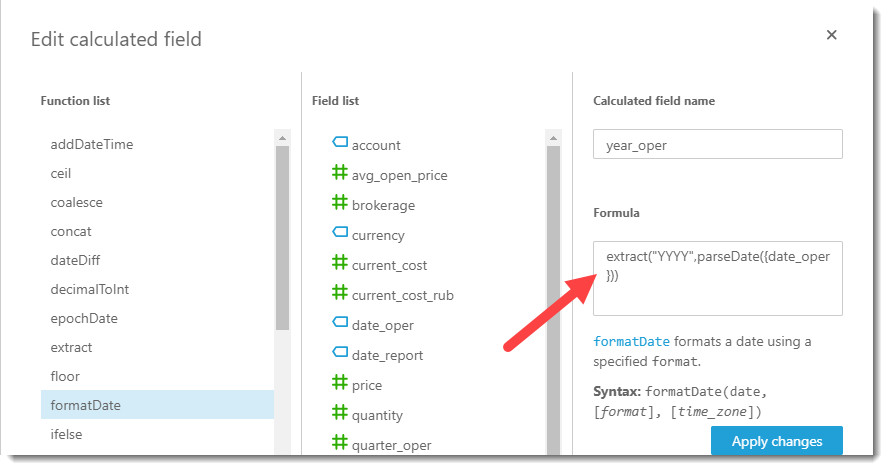
Когда вычисляемые поля успешно созданы и добавлены в выборку, даем название нашему датасету, например, «my_pnl_analyze» и нажимаем на кнопку «Save and visualize».
После этого переносимся на основную доску Amazon QuickSight и первое, что мы должны сделать – это настроить фильтр для даты отчета (с учетом того, что одни и те же данные были собраны из трех секций). Выбираем отчетную дату 2018-10-01 и нажимаем на кнопку Apply и переходим на закладку Visualize.
Установка фильтра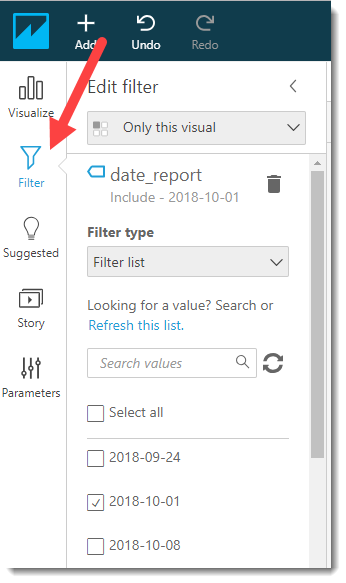
Теперь мы можем визуализировать результат по портфелю в любой плоскости, например, по каждой ценной бумаге внутри торгового счета, и разделенную в свою очередь по валютам (т.к. результат в разных валютах не сопоставим) и типам операций. Начнем с мощнейшего инструмента любого BI – сводных таблиц. Для экономии места и гибкости отображения, я вынес валюты в отдельный контрол (аналог среза в MS Excel)
В приведенной выше таблице видно, что если инвестор решит продать сейчас все акции ФСК ЕЭС, то он тем самым зафиксирует убыток, т.к. выплаченные дивиденды в размере 1 509.91 р. не покрывают его издержки (1 763.36 р. – отрицательная курсовая разница и 174 р. – НДФЛ на дивиденды). Есть смысл повременить и дождаться лучших времен на Бирже.
Следующий график – столбчатая диаграмма:
А теперь сформируем таблицу, которая покажет нам, сколько мы вложили в каждую бумагу, сколько дней она находится у нас в портфеле и какова доходность за весь период владения. Для этого добавим два новых вычисляемых поля: sum_investment и count_days.
Поле sum_investment
Вычисляемое поле sum_investment (сумма инвестиций) будем определять так:
ifelse({stock_name} = 'ОФЗ 24019',{avg_open_price} * quantity * 10,{avg_open_price} * quantity)
Такой подход к обработке расчета суммы вложений по облигациям обусловлен тем, что по ним всегда указывается цена – как процент от номинала (номинал в данном случае – 1000р).
ifelse({stock_name} = 'ОФЗ 24019',{avg_open_price} * quantity * 10,{avg_open_price} * quantity)
Такой подход к обработке расчета суммы вложений по облигациям обусловлен тем, что по ним всегда указывается цена – как процент от номинала (номинал в данном случае – 1000р).
Поле count_days
Вычисляемое поле count_day (количество дней владения бумагой) мы определим как разницу между датой операции и отчетной датой и в сводной таблице возьмем максимум:
dateDiff(parseDate({date_oper}),parseDate({date_report}))
dateDiff(parseDate({date_oper}),parseDate({date_report}))
Итоговая таблица представлена на скриншоте ниже:
Выводы и итоги
Мы рассмотрели с Вами реализацию парсера отчетов и способы анализа подготовленных им данных «на лету» при помощи сервисов Amazon. Также затронули некоторые бизнесовые и фундаментальные аспекты анализа инвестиционного портфеля, т.к. эта тема практически необъятная и уместить ее в одной статье довольно сложно, думаю, что есть смысл поместить ее в отдельную публикацию или даже, цикл публикаций.
Что касается использования инструмента обработки отчетов брокера и задействованных в нем подходов и алгоритмов, то они могут применяться (с соответствующей модификацией) для обработки отчетности других Брокеров. В любом случае, если Вы соберетесь адаптировать код под свои нужды, я готов дать несколько советов, так что не стесняйтесь задавать вопросы – обязательно постараюсь на них ответить.
Уверен, что данная система найдет свое применение и будет иметь дальнейшее развитие. Например, планируется добавить в расчет полного PNL по портфелю учет депозитарной и иной комиссии (например, за вывод денежных средств), а так же погашение облигаций и т.д… Вычисляемые поля на стороне Quicksight были использованы с демонстрационной целью, в следующей версии парсера, все эти дополнительные столбцы будут перенесены в Python и будут рассчитываться на стороне парсера.
Как архитектор и главный бизнес-заказчик данного решения, я вижу дальнейшую модернизацию следующим образом: ну не хочу я каждый раз вручную запрашивать эти XML-отчеты! Конечно, пока иной возможности нет, но API Брокера с передачей токена и диапазона выборки идеально подошло бы для еженедельного получения сырой отчетности. Последующая полная автоматическая обработка на стороне Amazon: от срабатывания ETL-job на AWS Glue до получения готовых результатов в виде графиков и таблиц в Amazon QuickSight позволят полностью автоматизировать процесс.
Полный исходный код можно найти в моем репозитории на GitHub
