Однажды, в далекой-далекой галактике, была фирма, давно выросшая из стартапа, но которая по прежнему оставалась довольно компактной и эффективной. Фирма хостила (на своем железе) сотни Windows-серверов, и это надо было как то мониторить. Еще до того, как я в нее пришел, в качестве решения была выбрана система NetIQ.
Настраивать NetIQ поручили мне, и тот, кто это делал до меня, не сказал о ней ни единого слова. Печатного. Вскоре я понял, почему. Стив Джобс наверное вертится в могиле, глядя на подобный интерфейс:
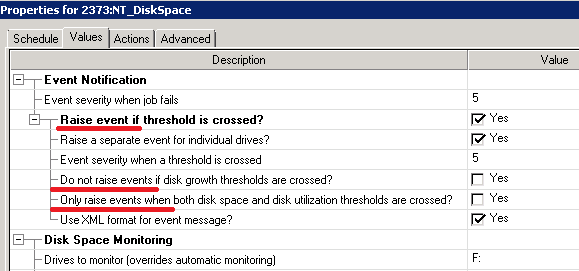
В одной строчке логика «птички» положительная (Raise event). В другой отрицательная (Do not raise event). Как работает «Only raise events when» с разным набором галочек я вообще понял только экспериментально (и уже забыл).
Впрочем, значительно более плохой чертой NetIQ была ее ломкость. Ее агент, который устанавливался на каждый сервер, был значительно более уязвим, чем сама Windows. Мало памяти? Агент вылетел. CPU 100%? Агент не отвечает. На диске осталось 0 байт — что бы вы думали? Чтобы отправить сообщение, агент вначале должен его сформировать на диске, в виде файла… Ну, вы поняли.
Тем не менее с этим кое как жили, пока эту компанию не купила компания еще больше. Когда монстр съедает крошечную фирму, то эта фирма растворяется, как капля в море. В нашем случае мы сами по IT меркам были лишь ненамного меньше тех, кто нас купил, и сразу было очевидно, что процесс слияния будет очень сложным. Настолько сложным, что какое то время нас вообще не трогали и внутренне все процессы оставались теми же. Это состояние было похоже на момент, когда Кольцо Всевластья упало на лаву, но еще не начало плавиться:

Тем временем я отапгрейдил NetIQ с версии 7 на 8 и далее на 9, когда и начались наши проблемы. NetIQ мониторила всего несколько вещей: доступность самого сервера, память, CPU, диск и главное — сервисы. Если наши самописные сервисы были в «Automatic», то они должны были работать. Вот такого быть не должно:

Вот эти события в большинстве случаев и перестала мониторить NetIQ. После недели экспериментов и недели работы с саппортом, мы выяснили, что «это не бага, это фича» и что алерт создается только при определенном exit code. А наши сервисы иногда падали с любыми кодами.
Прошло много времени и откатываться назад было поздно. Как вы понимаете, обнаружив, что наша критическая инфраструктура не мониторится, мы немедленно… ээээ… ничего не сделали. Потому что к этому времени «растворение» нашей фирмы в бОльшей вошло в активную фазу, и выглядело это примерно так:

До меня долетали далекие раскаты грома, крики, молнии, и выглядело это так, что решаются судьбы мира, а я лезу с какой то мелкой технической проблемой… А я не мог спокойно спать, зная, что наш мониторинг наполовину ослеп.
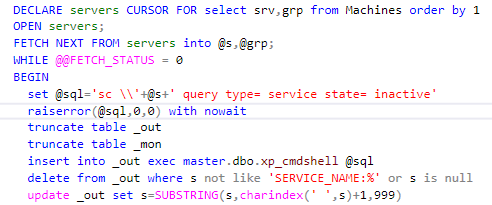
Поняв, что помощи ждать некуда, я решил быстренько написать сканнер сервисов, который бы обходил все сервера и посылал бы письмо, если что не так, как это делала NetIQ. Вы наверное думаете, что я использовал Powershell? Нет. Если у вас в руках молоток, то все вокруг — гвозди, а если вы DBA и работали с SQL с версии 6.0 — то… Небольшая выдержка из кода, чтобы вы поняли, о чем идет речь:
Сделал я это за несколько часов. В течение нескольких следующих дней появился аудит сообщений, параметры и другие вкусности. Почитав про команду WMIC я уже не смог остановиться. Дальше пара недель как в тумане. Очнулся я, когда все то, что мы использовали в NetIQ, было переписано и работало на ура.
Функциональность была не просто скопирована — я реализовал все свои фантазии, все, чего я хотел бы от такой системы. LOWDISK — вы получаете еще и график, как вело себя свободное место на диске последнее время — нормальный ли это рост или чтото пошло не так. Мало памяти — вот и график, и список процессов и сколько они занимают, а для w3wp.exe мы еще дорисуем имя application pool, умные reminders и многое другое. Кстати, список серверов система умела самостоятельно брать из VMware. Одного беглого взгляда на subjects алертов в телефоне хватало, чтобы понять, что происходит:

Современные программисты настолько приучены мыслить абстрактно, что не могут написать мониторинговую систему иначе как 'для сервера мы запускаем набор абстрактных мониторинговых скриптов, и нас не волнует, что внутри', тогда как мониторинг каждого состояния — диск, память, CPU, сервисы — по своему уникальны. Реализуя это «абстрактно», вы делаете одинаково убого для каждого случая, и происходит вот это: (Это скриншот из email от SCOM. Наверняка выполнено строго по ТЗ)

Огромный плюсом новой системы было то, что она была agentless, соответсвенно, не было никаких проблем с установкой агента, его падениями — там просто нечему было падать. Система была проста и надежна как молоток.
Следующие несколько месяцев я приходил утром на работу, становился перед своим детищем, как художник перед полотном и наносил пару штрихов, делая его еще идеальнее. Так как у меня не было никаких дедлайнов, то и technical debt был сведен к минимуму. В какой то момент я все таки заставил себя остановиться.
NetIQ все еще работала, но новый вид алертов всем нравился больше, и постепенно я всех перевел на алерты от новой системы, не выключая, однако, старую. Тем временем, процесс «расплавления» вступил в заключительную стадию:

Что же, сказка должна была закончиться. Я еще сам удивлялся, что смог столько развлекаться в крупной забюрократизированной компании. После месяца подготовки мне сказали, что через неделю все, гасим NetIQ, переходим на SCOM. Я выключил NetIQ (признаюсь, я так его ненавидел что мне это было очень приятно) и стал ждать SCOM. Но в назначенное время его не было. Не было и через неделю, и через месяц.
SCOM появился только через шесть месяцев — ктото забыл, сколько у нас серверов и сколько нужно лицензий для SCOM. За шесть месяцев столько систем стали зависеть от моей системы, которая стала вести и инвентории, метрики, и многое другое, что спокойно осталась второй — неофициальной. Для аудиторов есть SCOM, а все реально полезное — во второй системе.
Иногда менеджеры разного уровня задавились вопросом — а откуда идут вот эти автоматизированные emails? Недавно я подробно им описал историю, которую изложил в этой статье, и они весело посмеялись. Хотя мне до сих пор иногда и самому забавно, как в большой бюрократизированной компании можно «тихой сапой» протащить многие вещи. Да и приятно просто пописать код, как в старые добрые времена.
Настраивать NetIQ поручили мне, и тот, кто это делал до меня, не сказал о ней ни единого слова. Печатного. Вскоре я понял, почему. Стив Джобс наверное вертится в могиле, глядя на подобный интерфейс:
В одной строчке логика «птички» положительная (Raise event). В другой отрицательная (Do not raise event). Как работает «Only raise events when» с разным набором галочек я вообще понял только экспериментально (и уже забыл).
Впрочем, значительно более плохой чертой NetIQ была ее ломкость. Ее агент, который устанавливался на каждый сервер, был значительно более уязвим, чем сама Windows. Мало памяти? Агент вылетел. CPU 100%? Агент не отвечает. На диске осталось 0 байт — что бы вы думали? Чтобы отправить сообщение, агент вначале должен его сформировать на диске, в виде файла… Ну, вы поняли.
Тем не менее с этим кое как жили, пока эту компанию не купила компания еще больше. Когда монстр съедает крошечную фирму, то эта фирма растворяется, как капля в море. В нашем случае мы сами по IT меркам были лишь ненамного меньше тех, кто нас купил, и сразу было очевидно, что процесс слияния будет очень сложным. Настолько сложным, что какое то время нас вообще не трогали и внутренне все процессы оставались теми же. Это состояние было похоже на момент, когда Кольцо Всевластья упало на лаву, но еще не начало плавиться:
Тем временем я отапгрейдил NetIQ с версии 7 на 8 и далее на 9, когда и начались наши проблемы. NetIQ мониторила всего несколько вещей: доступность самого сервера, память, CPU, диск и главное — сервисы. Если наши самописные сервисы были в «Automatic», то они должны были работать. Вот такого быть не должно:
Вот эти события в большинстве случаев и перестала мониторить NetIQ. После недели экспериментов и недели работы с саппортом, мы выяснили, что «это не бага, это фича» и что алерт создается только при определенном exit code. А наши сервисы иногда падали с любыми кодами.
Прошло много времени и откатываться назад было поздно. Как вы понимаете, обнаружив, что наша критическая инфраструктура не мониторится, мы немедленно… ээээ… ничего не сделали. Потому что к этому времени «растворение» нашей фирмы в бОльшей вошло в активную фазу, и выглядело это примерно так:
До меня долетали далекие раскаты грома, крики, молнии, и выглядело это так, что решаются судьбы мира, а я лезу с какой то мелкой технической проблемой… А я не мог спокойно спать, зная, что наш мониторинг наполовину ослеп.
Поняв, что помощи ждать некуда, я решил быстренько написать сканнер сервисов, который бы обходил все сервера и посылал бы письмо, если что не так, как это делала NetIQ. Вы наверное думаете, что я использовал Powershell? Нет. Если у вас в руках молоток, то все вокруг — гвозди, а если вы DBA и работали с SQL с версии 6.0 — то… Небольшая выдержка из кода, чтобы вы поняли, о чем идет речь:
Сделал я это за несколько часов. В течение нескольких следующих дней появился аудит сообщений, параметры и другие вкусности. Почитав про команду WMIC я уже не смог остановиться. Дальше пара недель как в тумане. Очнулся я, когда все то, что мы использовали в NetIQ, было переписано и работало на ура.
Функциональность была не просто скопирована — я реализовал все свои фантазии, все, чего я хотел бы от такой системы. LOWDISK — вы получаете еще и график, как вело себя свободное место на диске последнее время — нормальный ли это рост или чтото пошло не так. Мало памяти — вот и график, и список процессов и сколько они занимают, а для w3wp.exe мы еще дорисуем имя application pool, умные reminders и многое другое. Кстати, список серверов система умела самостоятельно брать из VMware. Одного беглого взгляда на subjects алертов в телефоне хватало, чтобы понять, что происходит:
Современные программисты настолько приучены мыслить абстрактно, что не могут написать мониторинговую систему иначе как 'для сервера мы запускаем набор абстрактных мониторинговых скриптов, и нас не волнует, что внутри', тогда как мониторинг каждого состояния — диск, память, CPU, сервисы — по своему уникальны. Реализуя это «абстрактно», вы делаете одинаково убого для каждого случая, и происходит вот это: (Это скриншот из email от SCOM. Наверняка выполнено строго по ТЗ)
Огромный плюсом новой системы было то, что она была agentless, соответсвенно, не было никаких проблем с установкой агента, его падениями — там просто нечему было падать. Система была проста и надежна как молоток.
Следующие несколько месяцев я приходил утром на работу, становился перед своим детищем, как художник перед полотном и наносил пару штрихов, делая его еще идеальнее. Так как у меня не было никаких дедлайнов, то и technical debt был сведен к минимуму. В какой то момент я все таки заставил себя остановиться.
NetIQ все еще работала, но новый вид алертов всем нравился больше, и постепенно я всех перевел на алерты от новой системы, не выключая, однако, старую. Тем временем, процесс «расплавления» вступил в заключительную стадию:
Что же, сказка должна была закончиться. Я еще сам удивлялся, что смог столько развлекаться в крупной забюрократизированной компании. После месяца подготовки мне сказали, что через неделю все, гасим NetIQ, переходим на SCOM. Я выключил NetIQ (признаюсь, я так его ненавидел что мне это было очень приятно) и стал ждать SCOM. Но в назначенное время его не было. Не было и через неделю, и через месяц.
SCOM появился только через шесть месяцев — ктото забыл, сколько у нас серверов и сколько нужно лицензий для SCOM. За шесть месяцев столько систем стали зависеть от моей системы, которая стала вести и инвентории, метрики, и многое другое, что спокойно осталась второй — неофициальной. Для аудиторов есть SCOM, а все реально полезное — во второй системе.
Иногда менеджеры разного уровня задавились вопросом — а откуда идут вот эти автоматизированные emails? Недавно я подробно им описал историю, которую изложил в этой статье, и они весело посмеялись. Хотя мне до сих пор иногда и самому забавно, как в большой бюрократизированной компании можно «тихой сапой» протащить многие вещи. Да и приятно просто пописать код, как в старые добрые времена.
