
6-7 декабря в Москве состоялась пятая по счёту конференция «Гейзенбаг».
Её слоган — «Тестирование. Не только для тестировщиков!», и за два года регулярного посещения «Гейзенбагов» мне (прежде Java-разработчику, ныне — техническому лиду в маленькой компании, никогда не работавшему в QA) удалось многому научиться в области тестирования и многое внедрить в нашей команде. Я хочу поделиться субъективным обзором запомнившихся мне на этот раз докладов.
Disclaimer. Безусловно, это лишь маленькая фракция (8 из 30) докладов, отобранных исходя из моих личных предпочтений. Практически все эти доклады так или иначе связаны с Java и нет ни одного про фронт-энд и мобильную разработку. Кое-где я позволю себе полемику с докладчиком. Если вас интересует более полный и нейтральный обзор, по традиции он должен появиться в блоге организаторов. Но, возможно, кому-то будет интересно узнать как раз про те доклады, на которые сходить не довелось.
Фотографии в статье — из официального твиттера конференции.
Барух Садогурский. У нас DevOps. Давайте уволим всех тестировщиков

(На фото — ажиотаж при раздаче Барухом книги Liquid Software)
Тем, кто занимается Java и посещает конференции JUGRU Group, Барух Садогурский в представлении не нуждается. Однако на «Гейзенбаге» он выступил впервые.
В двух словах — это был обзорный доклад про основные идеи DevOps. Потребность аудитории в таких докладах сохраняется, поскольку на вопрос в зал «дайте определение DevOps» люди всё ещё в первую очередь отвечают «это такой человек…»
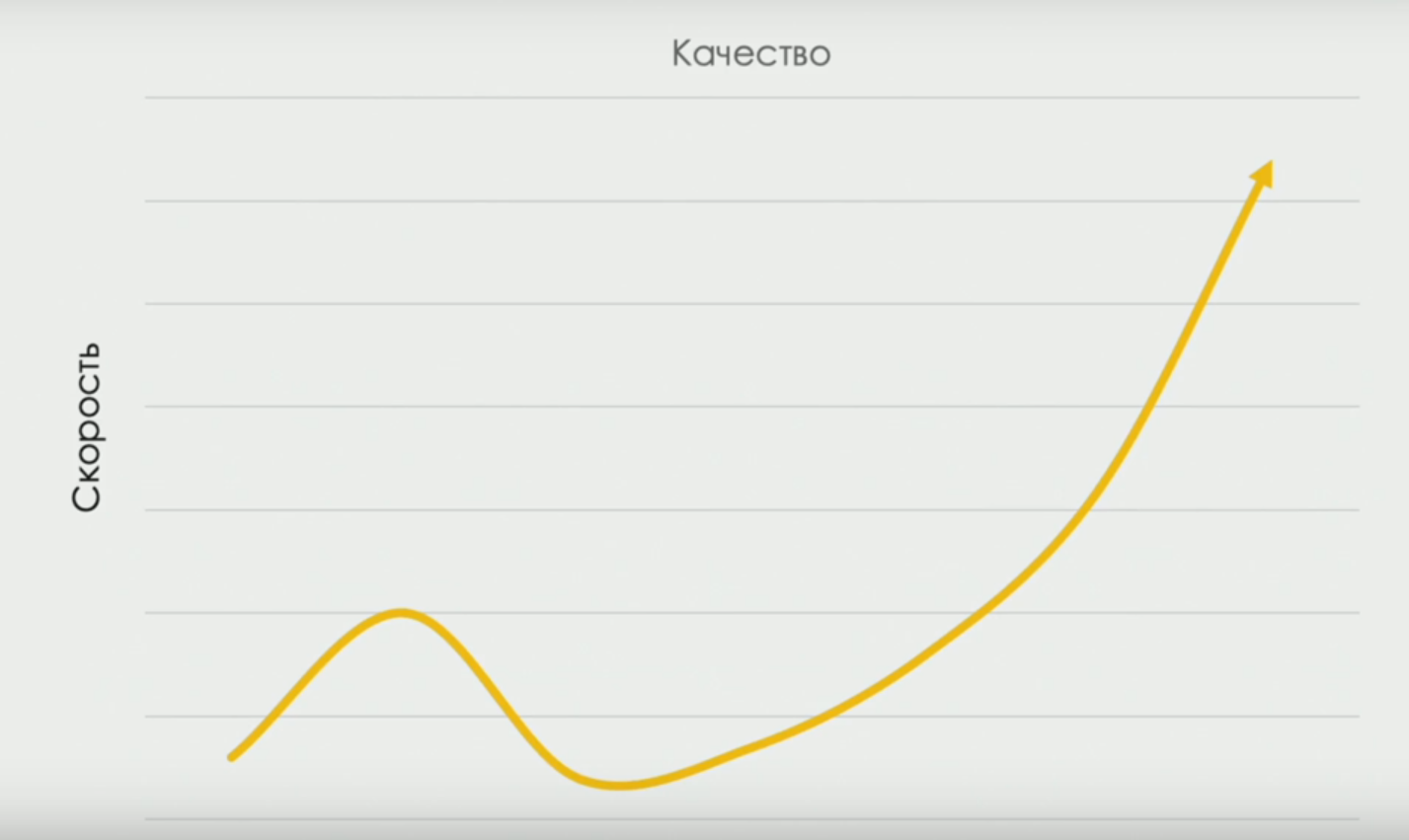
Но даже тем, кто уже кое-что усвоил по данной теме, будет очень интересно узнать про исследования ассоциации DORA devops-research.com, получившей процентные отношения разновидностей ручной работы в командах с разной производительностью. И про кривую, связывающую скорость поставки и качество (в какой-то момент скорость снижается, т. к. нам нужно время, чтобы «лучше потестировать», но по мере развития команды корреляция становится прямой):
Хотя название доклада было провокационным, а в расписании доклад пометили категорией «будет подгорать», его содержание, на мой взгляд, было вполне мейнстримовым. Речь шла, конечно, не об увольнении тестировщиков в условиях Devops-трансформации, а об изменении характера работы тестировщиков. Про эти вещи много говорили год назад и Алан Пейдж, и Николай Алименков. И об изменении ролей, и о «горизонтальном» развитии «T-shaped skills» год назад шла речь на круглом столе "что должен знать тестировщик в 2018 году".
«Разумеется, если вы не хотите меняться, работа найдётся и для вас, пусть и не такая интересная. Находится же до сих пор работа для тех, кто хочет поддерживать системы, написанные на COBOL в 70-х годах,» — иронизировал Барух.
Артём Ерошенко. Нужно сделать рефакторинг проекта? Есть IDEA!

Артём участникам Гейзенбага знаком по докладам о репортинг-системе Allure (например, вот его доклад о появившихся в 2018 году возможностях Allure с предыдущего «Гейзенбага» в СПб). Сам по себе Allure родился в условиях проектов с тысячами, десятками тысяч и даже более сотни тысяч тестов и призван упростить взаимодействие между разработчиками и тестировщиками. Он имеет возможность связывать тесты с внешними ресурсами типа тикетинг-систем и коммитами в системе контроля версий. В нашей микро-команде, пока счёт тестам шёл всего лишь на десятки, мы вполне справлялись стандартными средствами. Но по мере того, как в одном из продуктов число тестов дошло до 700 и в целом стоит задача создания отчётов высокого качества для заказчиков, я начал посматривать в сторону Allure.
Впрочем, этот доклад был не про Allure, хотя и про него тоже.
Артём убедил публику, что писать плагины к IntelliJ IDEA — это простое и увлекательное занятие. Для чего такое может потребоваться? Для автоматизации массовой модификации кода. Например, для перевода большого количества исходных кодов из JUnit4 на JUnit5. Или от использования Allure 1 к Allure 2. Или для автоматизации проставления тэгов на тестах со связью с тикетинг-системой.
Те, кто работают с IDEA, знают, какие «фокусы» она умеет делать с кодом (например, автоматически транслировать код с использованием for-циклов в код с использованием Java Streams и обратно, ну или моментально транслировать Java в Kotlin). Тем интереснее было посмотреть на то, как завеса тайны над преобразованиями кода в IDEA приоткрывается, нас приглашают принять в этом участие и создать собственные плагины для своих уникальных нужд. В ближайший раз, когда мне потребуется сделать что-то с большой кодовой базой, я вспомню про этот доклад и посмотрю, как это можно автоматизировать при помощи самописного плагина в IDEA.
Кирилл Меркушев. Проект на Java и Reactor — а как же тесты?

Этот доклад, как мне кажется, вполне мог бы состояться на Java-конференциях Joker или JPoint. Кирилл рассказывал о том, как использует фреймворк projectreactor.io в микросервисной архитектуре с единым логом событий (Kafka), немного про суть кодирования на «реактивных стримах» и в том числе — о том, как приложения с использованием этого фреймворка можно отлаживать и тестировать.
Нашу команду жизнь тоже подталкивает к использованию архитектуры с единым логом событий, и мы тоже смотрим на Kafka. Правда, для потоковой обработки событий мы экспериментируем с Kafka Streams API (где, как мне кажется, больше вещей типа stateful-процессинга реализовано «из коробки» прозрачно для разработчика), а не Reactor. Впрочем, как всегда бывает с новыми технологиями, «грабли» и «подводные камни» заранее неизвестны. Поэтому важно было послушать рассказ специалиста, уже работающего с технологией.
Леонид Руденко. Управление кластером Selenoid с помощью Terraform

Если предыдущий доклад был напоминал о конференции JPoint, то этот — безусловно, о DevOops. Леонид рассказал о том, как с помощью спецификаций Terraform поднимать и настраивать кластер Selenoid. О том, что такое сам Selenoid, был доклад на прошлогоднем Гейзенбаге — это богатая возможностями распределённая система, работающая как эластичный сервис и позволяющая запускать большое количество Selenium-тестов в различных браузерах. Как и всякую систему, требующую развертывания на нескольких машинах, вручную Selenoid поставить сложно. Тут на помощь и приходят современные Configuration-as-Code системы.
Леонид сделал достаточно подробный обзор возможностей Terraform — системы, которая, вероятно, была незнакома большинству из аудитории, но вообще-то уже хорошо известна DevOps-автоматизаторам (например, на конференции Devoops-2018 был отличный доклад Антона Бабенко про лучшие практики создания и поддержки кода на Terraform). Далее было показано, как с помощью Terraform-скриптов описать параметры докер-контейнеров с Selenoid для каждой из машин в кластере и сами параметры виртуальных машин кластера.
Хотя конкретный случай, рассмотренный Леонидом, безусловно способен облегчить задачу развёртывания Selenoid, я с докладчиком не во всём согласен. По сути, он использует Terraform для двух разных задач: создания ресурсов и их конфигурации. И это приводит к тому, что Леонид вынужден запустить Terraform один раз для создания виртуальных машин и ещё по одному разу для каждой из виртуальных машин для поднятия докер-контейнеров на них. По моему убеждению, Terraform, хорошо решающий задачу создания ресурсов, не очень хорошо решает задачу конфигурации. Избежать размножения terraform-проектов и многократного их запуска можно было бы с помощью специальных конфигурационных систем, например Ansible, или иных решений.
Но в целом, как «ликбез» для тестировщиков в области Infrastructure as Code, это доклад очень полезный.
Андрей Маркелов. Элегантное интеграционное тестирование зоопарка микросервисов с помощью TestContainers и JUnit 5 на примере глобальной SMS-платформы

И снова о микросервисах! В этот раз разговор шёл о том, как выполнить тесты, требующие запуска и взаимодействия нескольких сервисов одновременно. В качестве основы решения предлагались JUnit5 с его системой Extension-ов и хорошо известный (и прекрасный) фреймворк TestContainers (см., например, прошлогодний доклад Сергея Егорова).
Если вы пишете что-то на Java и всё ещё не знаете, что такое TestContainers — срочно рекомендую изучить. TestContainers позволяет, используя технологию Docker, непосредственно в коде тестов поднимать настоящие базы данных и прочие сервисы, связывать их по сети и, как результат, выполнять интеграционное тестирование в окружении, которое создаётся на момент запуска тестов и уничтожается сразу после него. При этом всё работает непосредственно из кода на Java, подключается как Maven-зависимость и не требует установки на машину разработчика / CI сервер ничего, кроме Docker. Мы сами используем TestContainers уже больше года.
Андрей показывал довольно впечатляющий пример того, как можно прописывать конфигурацию тестового окружения для end-to-end тестов, используя JUnit5 Extensions, собственные аннотации и TestContainers. Например, надписав над своим тестом (код условный) аннотации
@Billing @Messaging
мы можем, условно говоря, написать
@Test void systemIsDoingRightThings(BillingService b, MessagingService m) {...}
в параметры которого будут переданы Java-интерфейсы, через которые вы можете общаться с реальными сервисами, поднятыми (незаметно для разработчика теста) в контейнерах.
Эти примеры выглядят очень элегантно. Для меня, как активного пользователя TestContainers и JUnit 5, они понятны и относительно легко реализуемы.
Но в целом при таком подходе остаётся нерешённым большой вопрос, связанный с тем, что способ конфигурирования тестовой и production системы коренным образом различаются.
Осуществлять быстрые релизы в production, не опасаясь всё сломать, можно лишь если в процессе end-to-end тестирования протестирована не только система целиком, но и способ её конфигурирования. Если бы мы многократно запускали скрипт развёртывания системы в процессе разработки и тестирования, у нас не было бы сомнений в том, что этот скрипт отработает и при запуске в production. Роль кода, конфигурирующего тестовое окружение, в примере Андрея выполняют аннотации. Но в production мы выкладываем систему с помощью совсем другого кода — Ansible, Kubernetes, чего угодно — никак не задействованного при подобном тестировании системы. И это ограничивает данные тесты, которые получаются не совсем end-to-end.
Андрей Глазков. Тестирование систем с внешними зависимостями: проблемы, решения, Mountebank

Тем, для кого тема этого доклада актуальна, я очень рекомендую также посмотреть яркий доклад Андрея Солнцева о принципиальном подходе к тестированию систем, зависимых от внешних сервисов. Солнцев очень убедительно говорит о необходимости использования моков внешних систем для всестороннего тестирования. А Андрей Глазков в своём докладе описывает одну из систем для такого мокирования — Mountebank, написанную на NodeJS.
Mountebank можно поднять как сервер и «обучить» ответам на запросы по сети способом, похожим на то, как мы при написании модульных тестов «обучаем» моки интерфейсов. С той только разницей, что это мок работающего в сети сервиса. Любопытным случаем использования Mountebank является возможность использовать его как прокси — отправляя часть запросов на реальную внешнюю систему.
Здесь следует оговориться, что Java-разработчикам я бы рекомендовал (и Андрей в дискуссионной зоне согласился с этим) также посмотреть в сторону библиотеки WireMock, которая создана на Java и может запускаться в embedded-режиме, т. е. прямо из тестов без установки каких-либо сервисов на машину разработчика или CI-сервер (хотя может работать и как standalone сервер). Как и Mountebank, WireMock поддерживает режим проксирования. У нас есть небольшой позитивный опыт использования WireMock.
Преимуществом Mountebank, однако, является поддержка более низкоуровневых протоколов (WireMock работает только для HTTP) и возможность работать в «зоопарке» разных технологий (для Mountebank имеются библиотеки для разных языков).
Кирилл Толкачев. Тестируем и плачем вместе со Spring Boot Test

И снова Java, микросервисы и JUnit 5. Кирилл — ещё один хорошо известный Java-сообществе докладчик конференций Joker и JPoint, в первый раз выступивший на Гейзенбаге.
Этот доклад является модифицированной версией прошлогоднего доклада "Проклятие Spring Test", с примерами, модифицированными под JUnit5 и Spring Boot 2. Глубоко рассмотрены разные практические проблемы, связанные с конфигурированием Spring Boot тестов в компонентных/микросервисных тестах. Меня, например, впечатлил пример с использованием пустой
@SpringBootConfiguration StopConfiguration в нужном месте дерева исходников, чтобы остановить процесс сканирования конфигураций, а также возможность использования @MockBean и @SpyBean вместо моков. Как и другие доклады Кирилла и Евгения Борисова, это материал, к которому имеет смысл возвращаться в процессе практического использования Spring Framework.Андрей Карпов. Что могут статические анализаторы, чего не могут программисты и тестировщики

Статический анализ кода — полезная штука. По канонам Continuous Delivery он должен являться самой первой фазой конвейера поставки, отсеивая код с проблемами, которые могут быть обнаружены путём «вычитывания» кода. Статический анализ хорош тем, что быстр (гораздо быстрее выполнения тестов), а также дёшев (не требует дополнительных усилий от команды в виде написания тестов: все проверки уже написаны авторами анализатора).
Андрей Карпов, один из основателей проекта PVS-Studio (хорошо знакомого своим блогом читателям Хабра) построил доклад на примерах того, какие баги при анализе кода известных продуктов были найдены при помощи PVS-Studio. Сам PVS Studio — продукт-полиглот, он поддерживает языки C, С++, С# и, с недавних пор, Java.
Несмотря на то, что приведённые примеры были интересными и польза статического анализа из них очевидна, на мой взгляд, доклад Андрея имел недочеты.
Во-первых, доклад был построен исключительно на рассмотрении продукта PVS-Studio (на который, по словам докладчика, «средний ценник — 10000$»). А ведь стоило упомянуть о том, что, вообще-то, во многих языках есть много развитых OpenSource систем статического анализа. В одной лишь Java — бесплатные Checkstyle и SpotBugs (наследник замороженного проекта FindBugs), а также огромного прогресса достиг анализатор IntelliJ IDEA, который можно запускать отдельно от IDE и получать отчёт.
Во-вторых, говоря о статическом анализе, мне кажется, всегда стоит упоминать о принципиальных ограничениях этого метода. Не все проходили в университете теорию алгоритмов и знакомы с «проблемой останова», например.
Ну и наконец, совсем не были затронуты проблемы внедрения статического анализа в существующую кодовую базу, что до сих пор останавливает многих от регулярного использования анализаторов на проектах. Например, мы прогнали анализатор на большом legacy-проекте и нашли 100500 «ворнингов». Исправлять их прямо на месте нет сил и времени, да и массово изменять что-то в коде — риск. Что с этим делать, как заставить работать статический анализ как quality gate? В дискуссионной зоне с Андреем обсуждалась эта проблема, но в самом докладе этот вопрос не рассматривался.
В целом же я желаю Андрею и его команде успехов. Их продукт интересен и задумка занять свою нишу в этой области — очень смелая.
***
Пожалуй, не буду ничего говорить про завершающие кейноуты первого и второго дней: они оба были авторскими шоу, которые нужно просто смотреть. Рассказывать о них — всё равно что пересказывать словами, например, выступление рок-группы.
В своём отчёте год назад я уже пытался передать общую атмосферу конференции и рассказывал о том, что происходит в дискуссионных зонах, в обед и на вечеринке, поэтому не буду повторяться.
В заключение я хотел бы поблагодарить организаторов за ещё одну прекрасно проведённую конференцию. Насколько я понял, интерес к конференции несколько превысил ожидания, произошёл некоторый overbooking и даже не всем хватило сувениров. Но совершенно точно всем хватило более важных вещей: интересных докладов, пространства для обсуждения, еды и напитков. С нетерпением жду новых встреч!
