
Когда мы приступали к разработке нашего профилировщика производительности, то знали, что будем выполнять почти весь рендеринг UI самостоятельно. Вскоре нам пришлось решать, какой подход выбрать для рендеринга шрифтов. У нас были следующие требования:
- Мы должны иметь возможность рендерить любой шрифт любого размера в реальном времени, чтобы адаптироваться к системным шрифтам и их размерам, выбранным пользователями Windows.
- Рендеринг шрифтов должен быть очень быстрым, никаких торможений при рендеринге шрифтов не допускается.
- В нашем UI куча плавных анимаций, поэтому текст должен иметь возможность плавно перемещаться по экрану.
- Он должен быть читаемым при малых размерах шрифтов.
Не будучи в то время большим специалистом в этом вопросе, я поискал информацию в Интернете и нашёл множество техник, используемых для рендеринга шрифтов. Также я пообщался с техническим директором Guerrilla Games Михилем ван дер Леу. Эта компания экспериментировала со множеством способов рендеринга шрифтов и их движок рендеринга был одним из лучших в мире. Михиль вкратце изложил мне свою идею новой техники рендеринга шрифтов. Хотя нам вполне было бы достаточно уже имевшихся техник, меня эта идея заинтриговала и я приступил к её реализации, не обращая внимания на открывшийся мне чудесный мир рендеринга шрифтов.
В этой серии статей я подробно опишу используемую нами технику, разделив описание на три части:
- В первой части мы узнаем, как в реальном времени рендерить глифы с помощью 16xAA, сэмплированного из равномерной сетки.
- Во второй части мы перейдём к повёрнутой сетке, чтобы красивый выполнить антиалиасинг горизонтальных и вертикальных краёв. Также мы увидим, как готовый шейдер почти полностью сведётся к одной текстуре и таблице поиска.
- В третьей части мы узнаем, как растеризировать глифы в реальном времени с помощью Compute и ЦП.
Готовые результаты можно посмотреть и в профилировщике, но вот пример экрана со шрифтом Segoe UI, отрендеренный с помощью нашего рендерера шрифтов:

Вот увеличение буквы S, растеризированной размеров всего 6×9 текселов. Исходные векторные данные рендерятся как контур, а повёрнутый паттерн сэмплирования рендерится из зелёных и красных прямоугольников. Так как он рендерится с разрешением гораздо больше 6×9, оттенки серого не представлены в конечном оттенке пикселей, в нём отображается оттенок субпикселя. Это очень полезная отладочная визуализация, позволяющая убедиться, что все вычисления на субпиксельном уровне работают верно.

Идея: хранение покрытия вместо оттенка
Основная проблема, с которым нужно справиться рендерерам шрифтов — это отображение масштабируемых векторных данных шрифта в фиксированнй сетке пикселей. Способ перехода из векторного пространства к готовым пикселям в разных техниках очень отличается. В большинстве таких техник данные кривых перед рендерингом растеризируются во временное хранилище (например в текстуру) для получения определённого размера в пикселях. Временное хранилище используется в качестве кэша глифов: когда один и тот же глиф рендерится несколько раз, глифы берутся из кэша и используются заново, чтобы избежать повторной растеризации.
Разница техник хорошо заметна в том, как хранятся данные в промежуточном формате данных. Например система шрифтов Windows растеризирует глифы под конкретный размер в пикселях. Данные хранятся как оттенок на пиксель. Оттенок (shade) описывает наилучшее приближение покрытия глифом этого пикселя. При рендеринге пиксели просто копируются из кэша глифов в целевую пиксельную сетку. При преобразовании данных в пиксельный формат они плохо масштабируются, поэтому при уменьшении масштаба возникают нечёткие глифы, а при увеличении масштаба — глифы, в которых отчётливо заметны блоки. Поэтому для каждого конечного размера глифы рендерятся в кэш глифов.
В технике Signed Distanced Fields используется другой подход. Вместо оттенка для пикселя сохраняется расстояние до ближайшего края глифа. Преимущество этого метода в том, что для кривых краёв данные масштабируются гораздо лучше, чем оттенки. При увеличении масштаба глифа кривые остаются плавными. Недостаток этого подхода в том, что сглаживаются прямые и резкие края. Гораздо большего качества, чем SDF, достигают усовершенствованные решения наподобие FreeType, которые хранят данные оттенков.
В случаях, когда для пикселя сохраняется оттенок, необходимо сначала вычислить его покрытие. Например, в stb_truetype есть хорошие примеры того, как можно вычислять покрытие и оттенок. Ещё один популярный способ аппроксимации покрытия заключается в сэмплировании глифа с большей частотой, чем конечное разрешение. При этом подсчитывается количество сэмплов, попавших в глиф в целевой пиксельной области. Количество попаданий, разделённое на максимальное количество возможных сэмплов, определяет оттенок. Так как покрытие уже преобразовано в оттенок для определённого разрешения пиксельной сетки и выравнивания, размещать глифы между целевыми пикселями невозможно: оттенок не сможет правильно отразить истинное покрытие сэмплами целевого пиксельного окна. По этой, а также некоторым другим причинам, которые мы рассмотрим позже, такие системы не поддерживают субпиксельное перемещение.
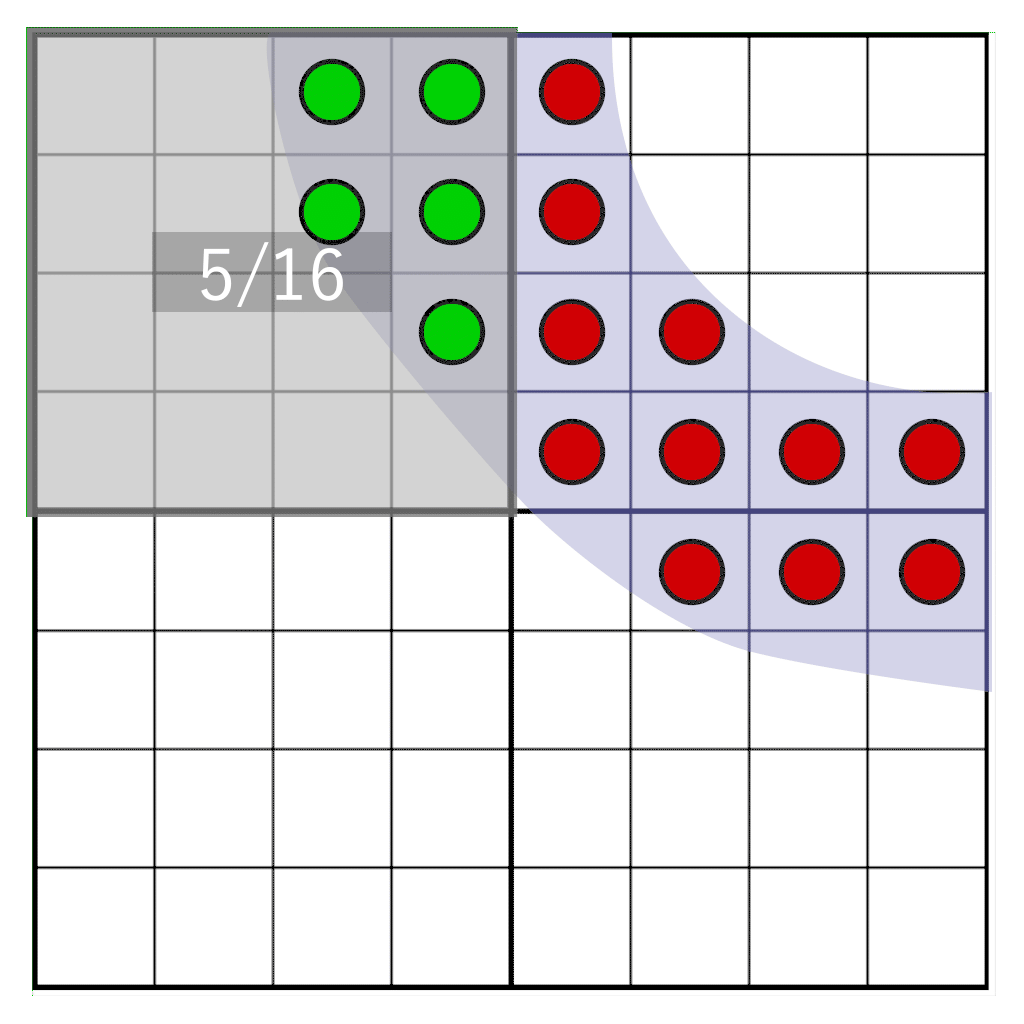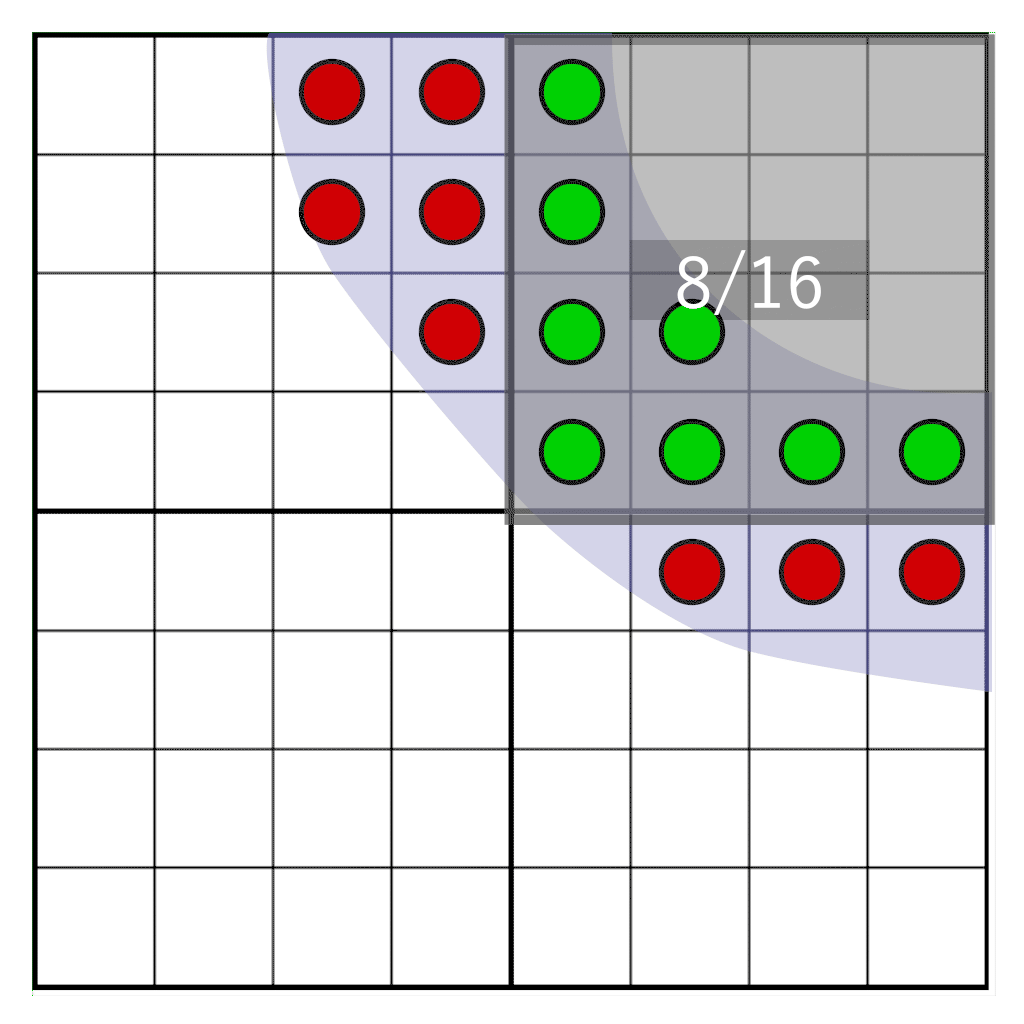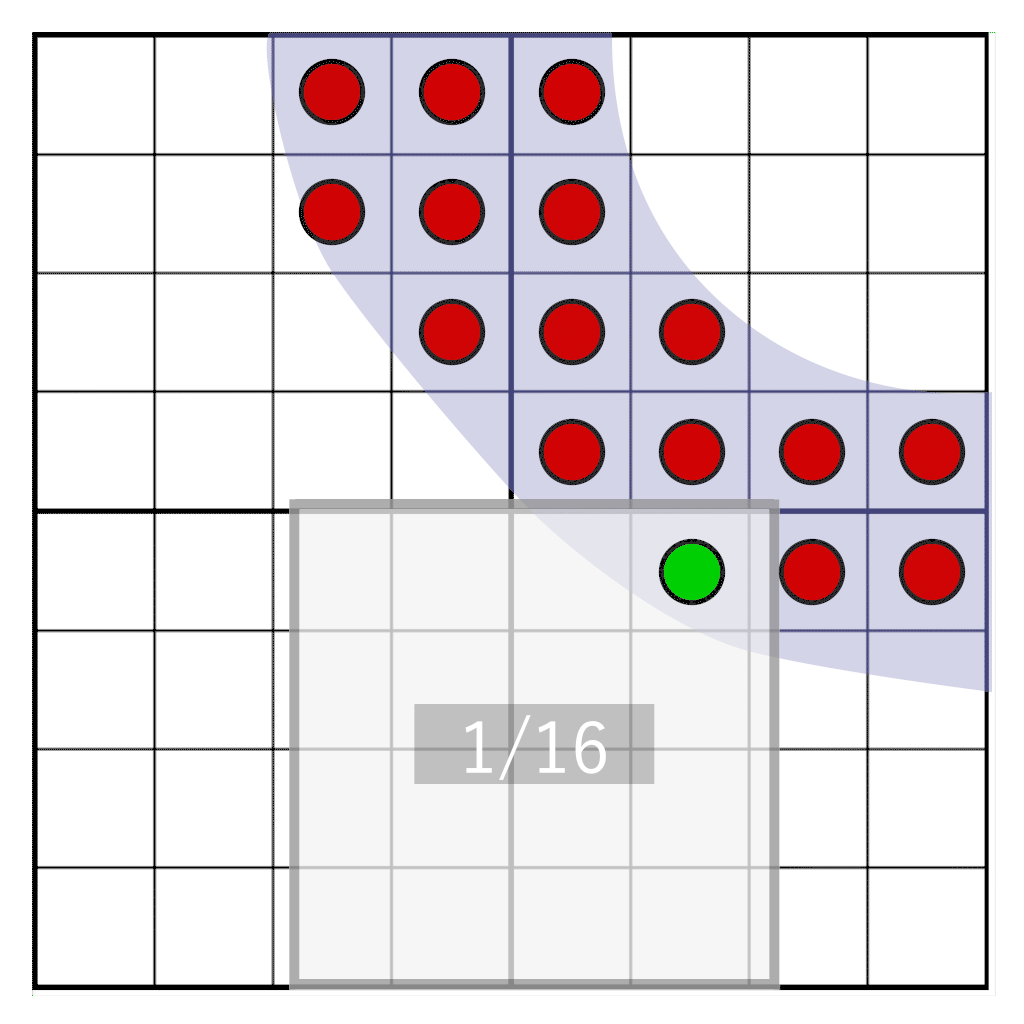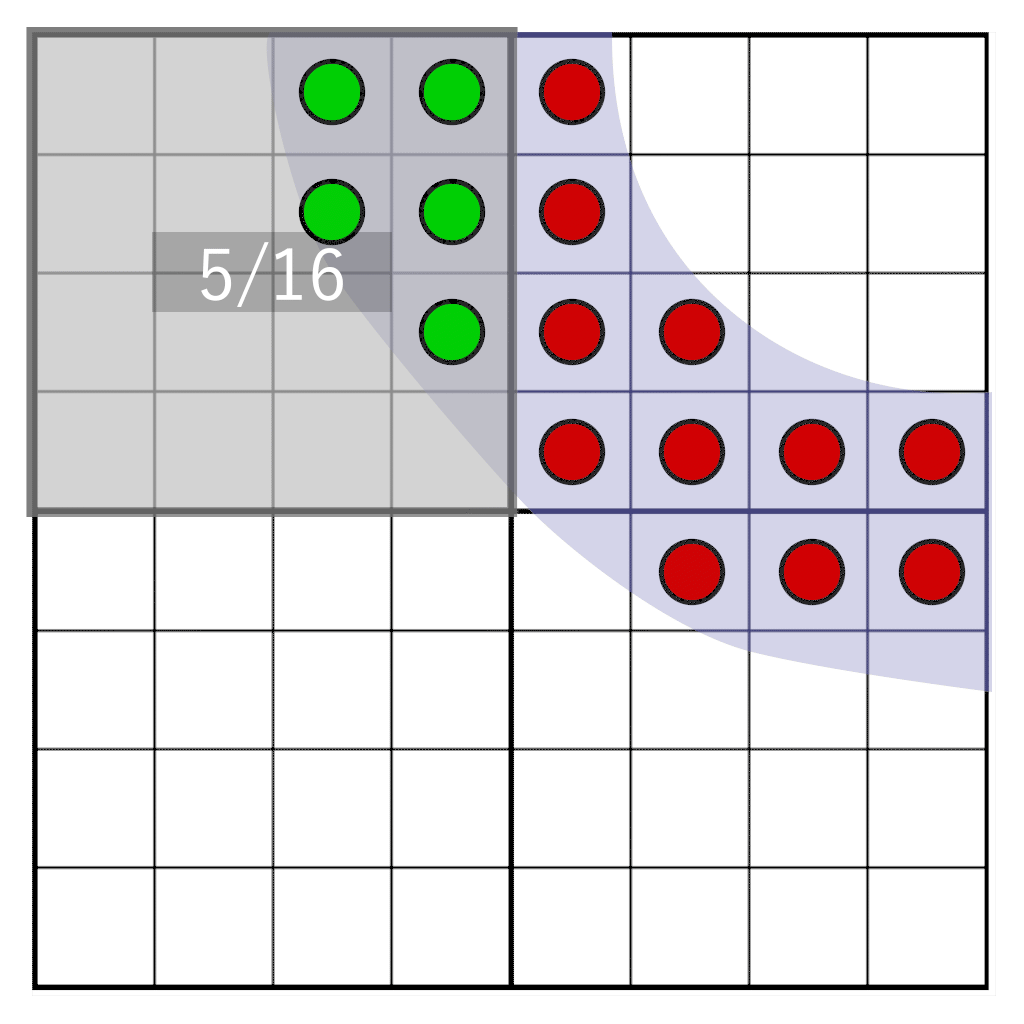
Но что, если нам нужно свободно перемещать глиф между пикселями? Если оттенок вычислен заранее, мы не можем узнать, каким должен быть оттенок при перемещении между пикселями в целевой пиксельной области. Однако мы можем отложить преобразование из уровня покрытия в оттенок на момент рендеринга. Чтобы сделать это, мы будем хранить не оттенок, а покрытие. Мы сэмплируем глиф с частотой в 16 целевого разрешения, и для каждого сэмпла сохраняем единственный бит. При сэмплировании на сетке 4×4 достаточно хранить всего 16 бит на пиксель. Это будет наше маской покрытия. Во время рендеринга нам нужно считать, сколько битов попадает в целевое пиксельное окно, имеющее то же разрешение, что и хранилище текселов, но физически не к нему не привязанное. В показанной ниже анимации демонстрируется часть глифа (голубая), растеризируемая в четыре тексела. Каждый тексел разделёна на сетку из ячеек 4×4. Серый прямоугольник обозначает пиксельное окно, динамически перемещающееся по глифу. Во время выполнения для определения оттенка подсчитывается количество сэмплов, попадающих в пиксельное окно.
Вкратце об основных техниках рендеринга шрифтов
Прежде чем переходить к обсуждению реализации нашей системы рендеринга шрифтов, я хочу вкратце рассказать об основных техниках, используемых в этом процессе: хинтинге шрифтов (font hinting) и субпиксельном рендеринге (subpixel rendering) (в Windows эта техника называется ClearType). Можете пропустить этот раздел, если вас интересует только техника с антиалиасингом.
В процессе реализации рендерера я всё больше узнавал о долгой истории развития рендеринга шрифтов. Исследования полностью сосредоточены на единственном аспекте рендеринга шрифтов — читаемости при малых размерах. Создать отличный рендерер для больших шрифтов достаточно просто, но невероятно сложно написать систему, сохраняющую читаемость при малых размерах. Изучение рендеринга шрифтов имеет многолетнюю историю, поражающую своей глубиной. Почитайте, например, о растровой трагедии. Логично, что это было для компьютерных специалистов основной проблемой, потому что на ранних этапах вычислительных машин разрешение экранов было довольно низким. Должно быть, это стало одной из первых задач, с которыми нужно было справиться разработчикам ОС: как сделать текст читаемым на устройствах с низким разрешением экрана? К моему удивлению, высококачественные системы рендеринга шрифтов очень ориентированы на пиксели. Например, глиф строится таким образом, что начинается на границе пикселя, его ширина кратна количеству пикселей, а содержимое подстраивается под пиксели. Эта техника называется привязкой к сетке. Я привык к работе с компьютерными играми и 3D-графикой, где мир построен из единиц измерения и проецируется в пиксели, поэтому меня это немного удивило. Я выяснил, что в области рендеринга шрифтов это очень важный выбор.
Чтобы показать важность привязки к сетке, давайте рассмотрим возможный сценарий растеризации глифа. Представьте, что глиф растеризируется на пиксельной сетке, но форма глифа неидеально совпадает со структурой сетки:
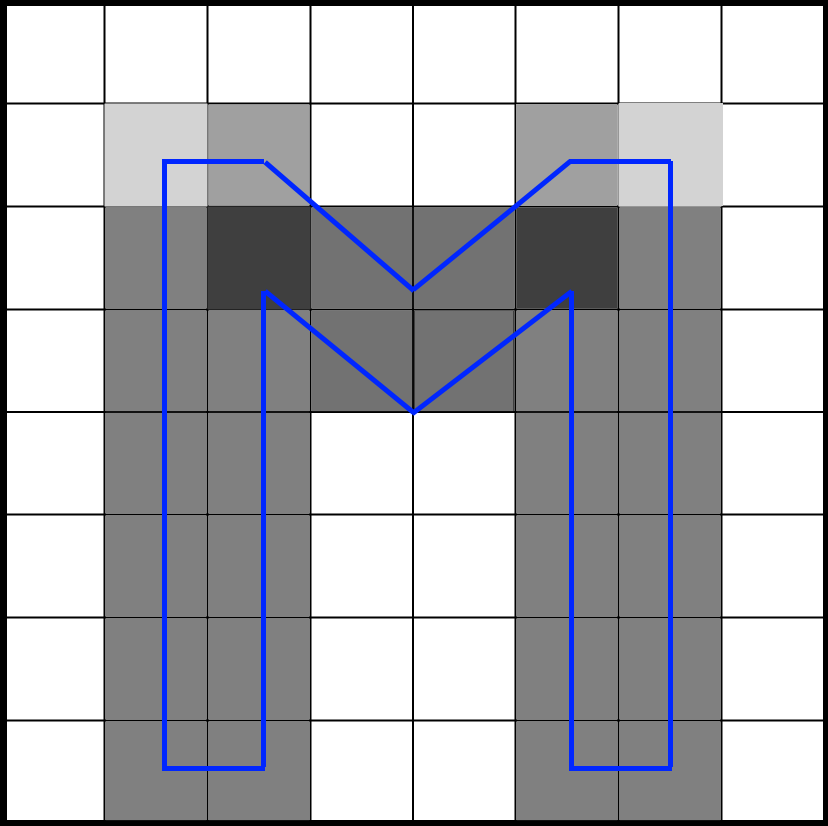
Антиалиасинг сделает пиксели справа и слева от глифа одинаково серыми. Если глиф немного сдвинуть, чтобы он лучше совпадал с границами пикселей, то будет окрашен только один пиксель, и он станет полностью чёрным:
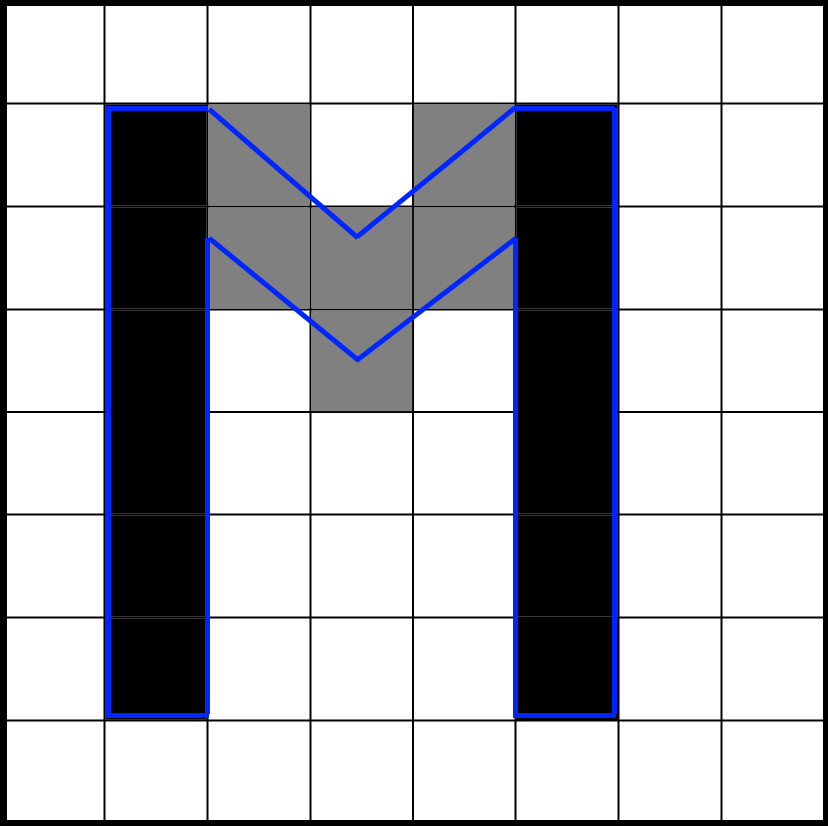
Теперь, когда глиф хорошо соответствует пикселям, цвета стали не такими смазанными. Разница в резкости очень велика. В западных шрифтах есть множество глифов с горизонтальными и вертикальными линиями, и если они плохо совпадают с пиксельной сеткой, то оттенки серого делают шрифт размытым. Даже самая лучшая техника антиалиасинга не способна справиться с этой проблемой.
В качестве решения был предложен хинтинг шрифтов. Авторы шрифтов должны добавлять в свои шрифты информацию о том, как должны глифы привязываться к пикселям, если они не совпадают идеально. Система рендеринга шрифтов искажает эти кривые, чтобы привязать их к пиксельной сетке. Это значительно увеличивает чёткость шрифта, но имеет свою цену:
- Шрифты становятся слегка искажёнными. Шрифты выглядят не совсем так, как задумано.
- Все глифы необходимо привязать к пиксельной сетке: начало глифа и ширину глифа. Поэтому анимировать их между пикселями невозможно.
Интересно, что в решении этой задачи Apple и Microsoft пошли разными путями. Microsoft придерживается абсолютной чёткости, а Apple стремится к более точному отображению шрифтов. В Интернете можно встретить жалобы людей на размытость шрифтов на машинах Apple, но многим нравится то, что они видят на Apple. То есть частично это вопрос вкуса. Вот пост Joel on Software, а здесь пост Питера Билака об этой теме, но если вы поищете в Интернете, то можете найти гораздо больше информации.
Так как разрешение DPI в современных экранах быстро увеличивается, возникает вопрос, так ли нужен будет хинтинг шрифтов в будущем, как сегодня. В нынешнем состоянии я считаю хинтинг шрифтов очень ценной техникой для чёткого рендеринга шрифтов. Однако описанная в моей статье техника в будущем может стать интересной альтернативой, потому что глифы можно свободно располагать на холсте без искажений. И так как по сути это техника антиалиасинга, её можно использовать для любых целей, а не только для рендеринга шрифтов.
Наконец, расскажу вкратце о субпиксельном рендеринге. В прошлом люди осознали, что можно утроить горизонтальное разрешение экрана, воспользовавшись отдельными красным, зелёным и синим лучами компьютерного монитора. Каждый пиксель строится из этих лучей, которые физически разделены. Наш глаз смешивает их значения, создавая единственный цвет пикселя. Когда глиф покрывает только часть пикселя, то включается только тот луч, который накладывается на глиф, что утраивает разрешение по горизонтали. Если увеличить изображение экрана при использовании техники наподобие ClearType, то можно увидеть цвета вокруг краёв глифа:
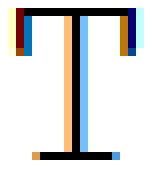
Интересно, что подход, о котором я расскажу в статье, может быть расширен и на субпиксельный рендеринг. Я уже реализовал его прототип. Единственный его недостаток в том, что из-за добавления фильтрации в техниках наподобие ClearType нам нужно брать больше сэмплов текстур. Возможно, я рассмотрю это в дальнейшем.
Рендеринг глифа с помощью равномерной сетки
Допустим, что мы сэмплировали глиф с разрешение в 16 раз больше целевого и сохранили его в текстуру. О том, как это делается, я расскажу в третьей части статьи. Паттерн сэмплирования — это равномерная сетка, то есть 16 точек сэмплирования равномерно распределены по текселу. Каждый глиф рендерится с тем же разрешением, что и целевое разрешение, мы храним по 16 бит на тексел, и каждый бит соответствует сэмплу. Как мы увидим в процессе вычисления маски покрытия, важен порядок хранения сэмплов. В целом точки сэмплирования и их позиции для одного тексела выглядят так:
Получение текселов
Мы будем сдвигать пиксельное окно по битам покрытия, сохранённым в текселах. Нам нужно ответить на следующий вопрос: сколько сэмплов попадёт в наше пиксельное окно? Его иллюстрирует следующее изображение:
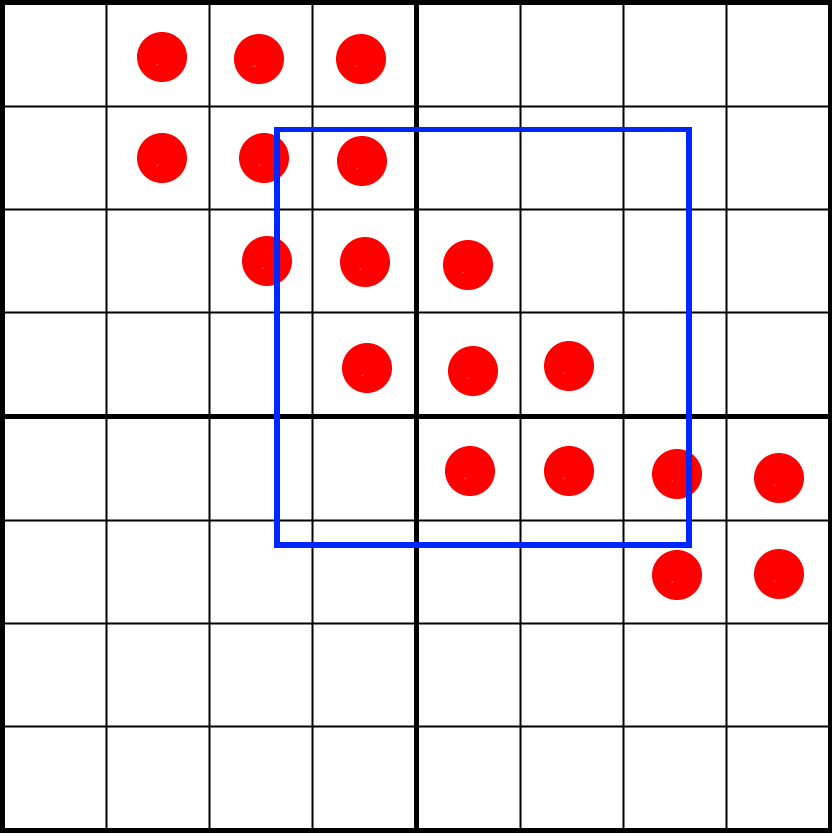
Здесь мы видим четыре тексела, на которые частично наложен глиф. Один пиксель (обозначен синим) покрывает часть текселов. Нужно определить, сколько сэмплов пересекает наше пиксельное окно. Сначала нам нужно следующее:
- Вычислить относительную позицию пиксельного окна по сравнению с 4 текселами.
- Получить текселы, с которыми пересекается наше пиксельное окно.
Наша реализация основана на OpenGL, поэтому точка начала координат пространства текстуры начинается в левом нижнем углу. Давайте начнём с вычисления относительной позиции пиксельного окна. Передаваемая в пиксельный шейдер UV-координата — это UV-координата центра пикселя. Считая, что UV нормализованы, мы можем сначала преобразовать UV в пространство текселов, умножив её на размер текстуры. Вычтя из центра пикселя 0,5, мы получим левый нижний угол пиксельного окна. Округлив это значение вниз (floor), мы вычислим левую нижнюю позицию левого нижнего тексела. На изображении показан пример этих трёх точек в пространстве текселов:
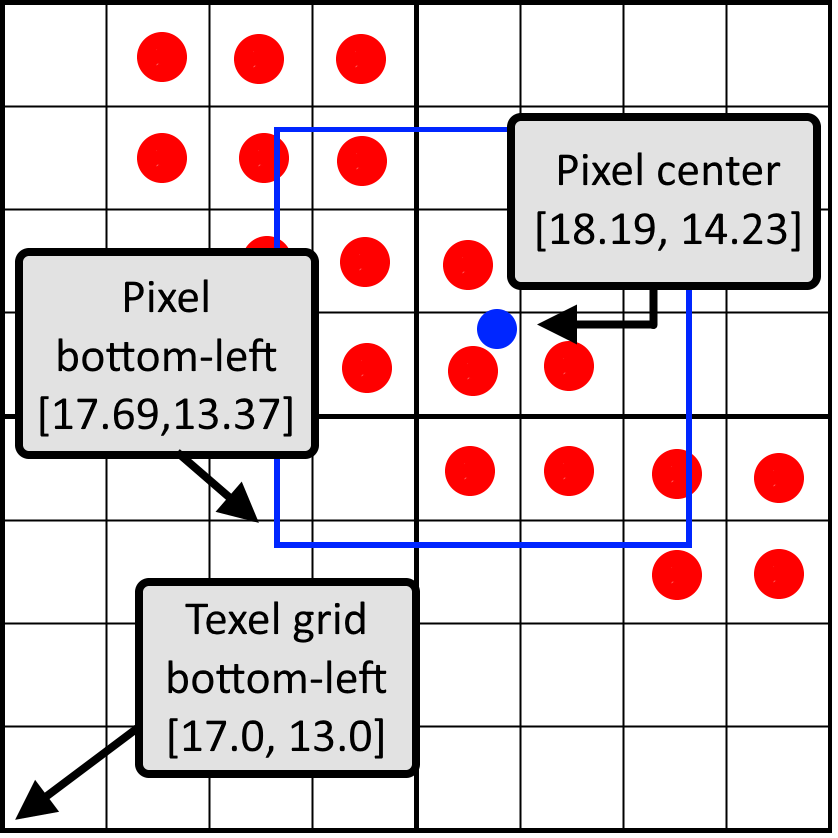
Разность между левым нижним углом пикселя и левым нижним углом тексельной сетки — это относительная позиция пиксельного окна в нормализованных координатах. На этом изображении позиция пиксельного окна будет равна [0.69, 0.37]. В коде:
vec2 bottomLeftPixelPos = uv * size -0.5;
vec2 bottomLeftTexelPos = floor(bottomLeftPixelPos);
vec2 weigth = bottomLeftPixelPos - bottomLeftTexelPos;С помощью инструкции textureGather мы можем получить четыре тексела за раз. Она доступна только в OpenGL 4.0 и выше, поэтому вместо неё можно выполнить четыре texelFetch. Если мы просто будем передавать textureGather UV-координаты, то при идеальном совпадении пиксельного окна с текселом возникнет проблема:

Здесь мы видим три горизонтальных тексела с пиксельным окном (показано синим), точно совпадающим с центральным текселом. Вычисленный вес близок к 1.0, но textureGather вместо него выбрал центральный и правый текселы. Причина в том, что выполняемые textureGather вычисления могут незначительно отличаться от вычисления веса с плавающей запятой. Разница в округлении вычислений, выполняемых в GPU, и вычислений веса с плавающей запятой приводят к глитчам вокруг центров пикселей.
Чтобы решить эту проблему, нужно сделать так, чтобы вычисления веса гарантированно совпадали с сэмплированием textureGather. Для этого мы никогда не будем сэмплировать центры пикселей, и вместо этого всегда будем выполнять сэмплирование в центре тексельной сетки 2×2. Из вычисленной и уже округлённой вниз левой нижней позиции тексела мы прибавляем полный тексел, чтобы добраться до центра тексельной сетки.

На этом изображении видно, что благодаря использованию центра тексельной сетки четыре точки сэмплирования, взятые textureGather, всегда будут находиться в центре текселов. В коде:
vec2 centerTexelPos = (bottomLeftTexelPos + vec2(1.0, 1.0)) / size;
uvec4 result = textureGather(fontSampler, centerTexelPos, 0);Горизонтальная маска пиксельного окна
Мы получили четыре тексела и все вместе они формируют сетку битов покрытия 8×8. Чтобы подсчитать биты в пиксельном окне, нам сначала нужно обнулить биты, находящиеся за пределами пиксельного окна. Чтобы сделать это, мы создадим маску пиксельного окна и выполним побитовое И между пиксельной маской и масками покрытия тексела. Горизонтальное и вертикальное маскирование выполняются по отдельности.
Горизонтальная пиксельная маска должна двигаться вместе с горизонтальным весом, как показано на данной анимации:
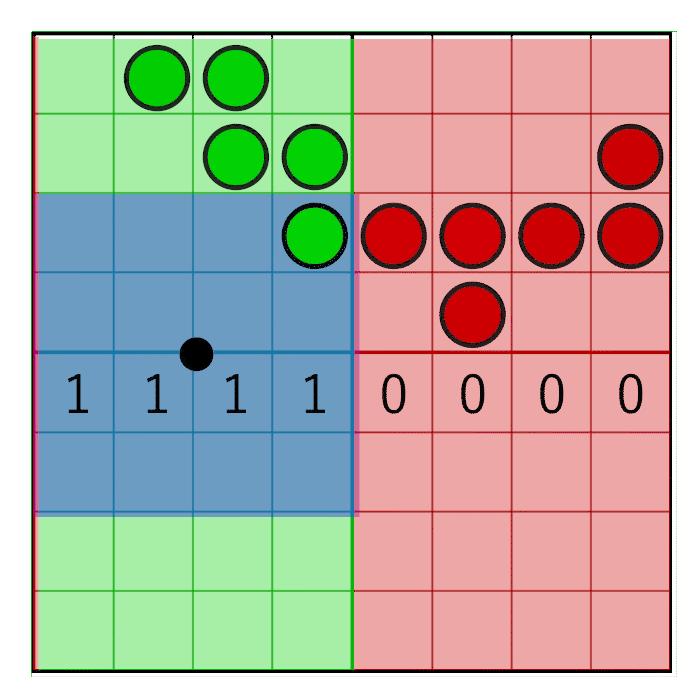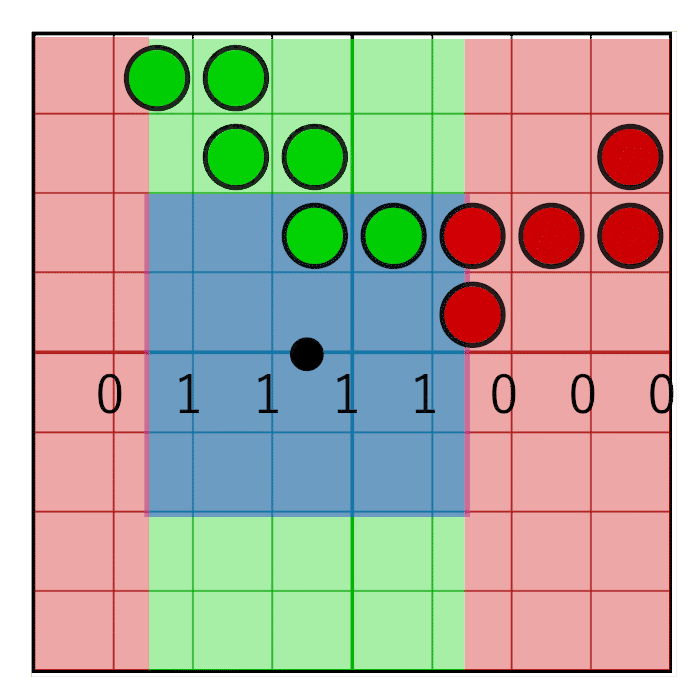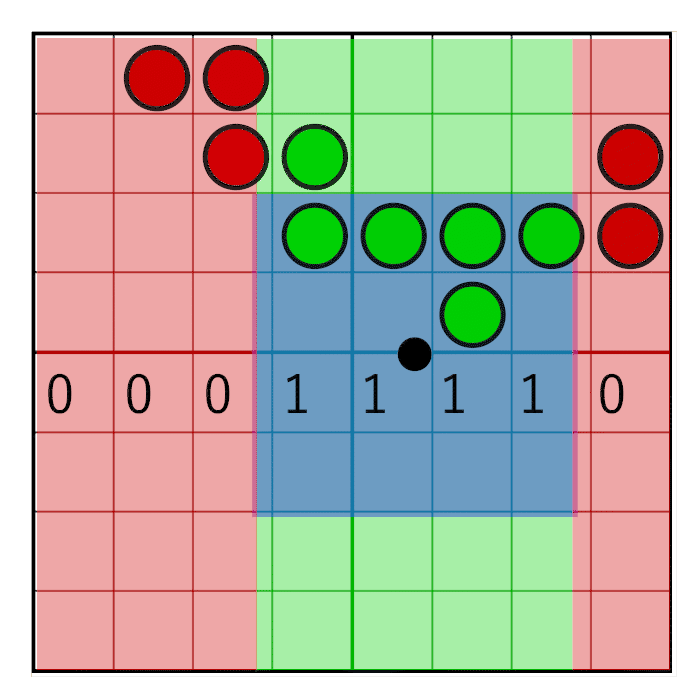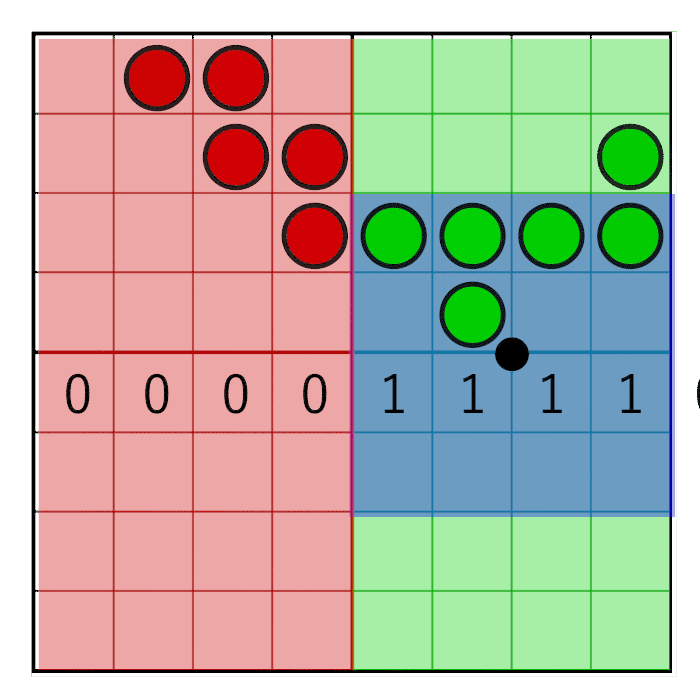
На изображении видно 8-битную маску со значением 0x0F0, сдвигающимся вправо (слева вставляются нули). В анимации маска линейно анимируется с весом, но в реальности битовый сдвиг — это пошаговая операция. Маска меняет значение, когда пиксельное окно пересекает границу сэмпла. В следующей анимации это показано красным и зелёным столбцами, анимированными пошагово. Значение меняется только при пересечении центров сэмплов:
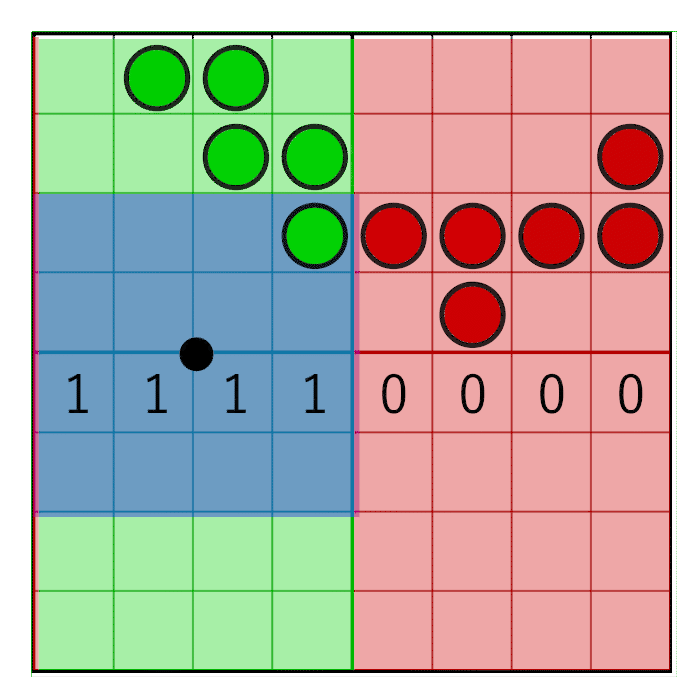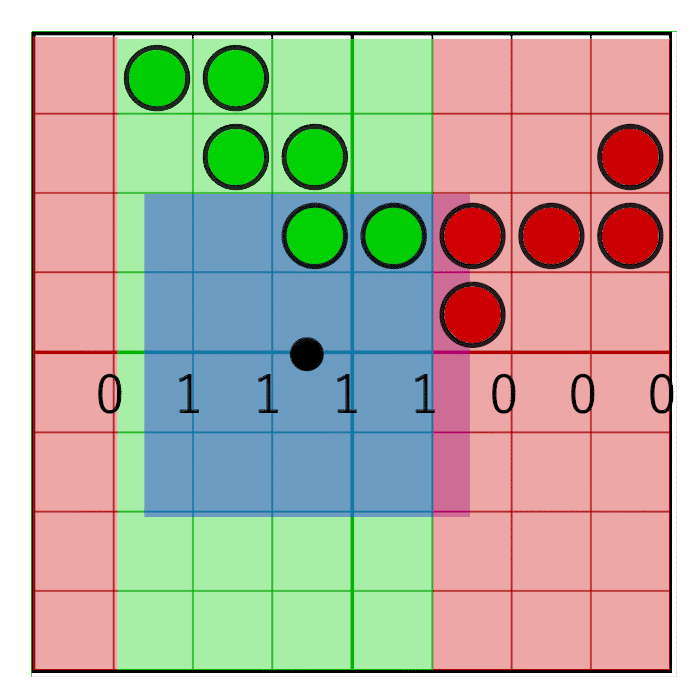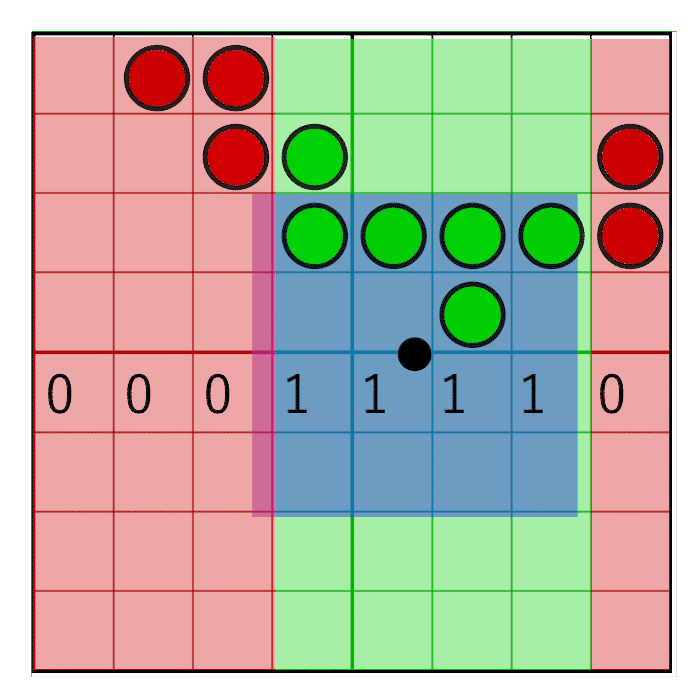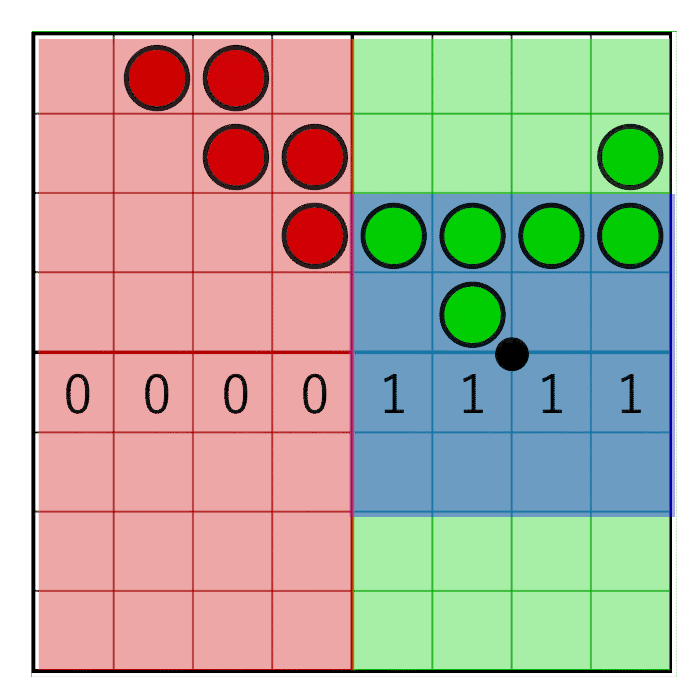
Чтобы маска двигалась только в центре ячейки, но не на её краях, достаточно будет простого округления:
unsigned int pixelMask = 0x0F0 >> int(round(weight.x * 4.0));Теперь у нас есть пиксельная маска полной 8-битной строки, занимающей два тексела. Если мы выберем правильный тип хранения в нашей 16-битной маске покрытия, то существуют способы комбинирования левого и правого тексела и выполнения горизонтального маскирования пикселей для полной 8-битной строки за раз. Однако это становится проблематичным при вертикальном маскировании, когда мы переходим к повёрнутым сеткам. Поэтому вместо этого мы скомбинируем друг с другом два левых тексела и отдельно два правых тексела, чтобы создать две 32-битных маски покрытия. Мы маскируем левые и правые результаты по отдельности.
Маски для левых текселов используют верхние 4 бита пиксельной маски, а маски для правых текселов используют нижние 4 бита. В равномерной сетке каждая строка имеет одинаковую горизонтальную маску, поэтому мы можем просто скопировать маску для каждой строки, после чего горизонтальная маска будет готова:
unsigned int leftRowMask = pixelMask >> 4;
unsigned int rightRowMask = pixelMask & 0xF;
unsigned int leftMask = (leftRowMask << 12) | (leftRowMask << 8) | (leftRowMask << 4) | leftRowMask;
unsigned int rightMask = (rightRowMask << 12) | (rightRowMask << 8) | (rightRowMask << 4) | rightRowMask;Чтобы выполнить маскирование, мы скомбинируем два левых тексела и два правых тексела, после чего замаскируем горизонтальные строки:
unsigned int left = ((topLeft & leftMask) << 16) | (bottomLeft & leftMask);
unsigned int right = ((topRight & rightMask) << 16) | (bottomRight & rightMask);Теперь результат может выглядеть так:
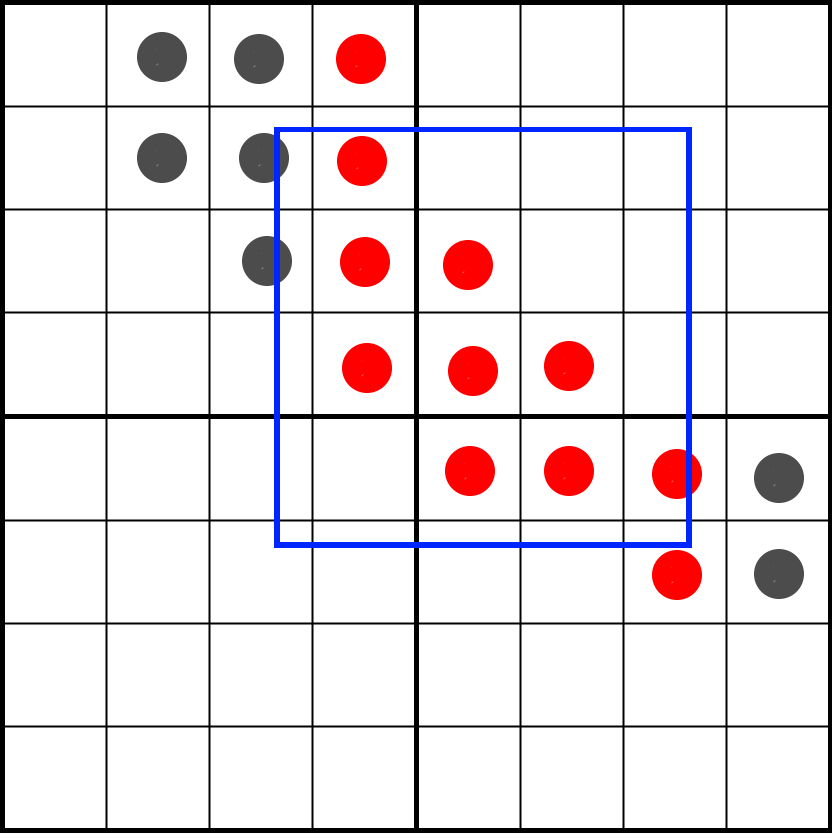
Мы уже можем подсчитать биты этого результата с помощью инструкции bitCount. Мы должны делить не на 16, а на 32, потому что после вертикального маскирования у нас всё равно может остаться 32 потенциальных бита, а не 16. Вот полный рендер глифа на этом этапе:

Здесь мы видим увеличенную букву S, отрендеренную на основе исходных векторных данных (белого контура), и визуализацию точек сэмплирования. Если точка зелёная, то она находится внутри глифа, если красная — то нет. Оттенки серого отображают вычисленные на данном этапе оттенки. В процессе рендеринга шрифтов существует множество возможностей для ошибок, начиная от растеризации, способом хранения данных в текстурном атласе и до вычислений финального оттенка. Подобные визуализации невероятно полезны для проверки правильности вычислений. Они особенно важны для отладки артефактов на субпиксельном уровне.
Вертикальное маскирование
Теперь мы готовы к выполнению маскирования вертикальных битов. Для маскирования по вертикали мы используем немного другой способ. Чтобы разобраться с вертикальным сдвигом, важно вспомнить то, как мы сохраняли биты: в построковом порядке. Нижняя строка занимает четыре наименее значимых бита, а верхняя строка — четыре наиболее значимых бита. Мы можем просто очищать одну за одной, сдвигая их на основании вертикальной позиции пиксельного окна.
Мы создадим единую маску, покрывающую всю высоту двух текселов. В результате мы хотим сохранить четыре полных строки текселов и замаскировать все остальные, то есть маской будет 4×4 бита, что равно значению 0xFFFF. На основании позиции пиксельного окна мы сдвигаем нижние строки и очищаем верхние строки.
int shiftDown = int(round(weightY * 4.0)) * 4;
left = (left >> shiftDown) & 0xFFFF;
right = (right >> shiftDown) & 0xFFFF;В результате мы также замаскировали вертикальные биты за пределами пиксельного окна:
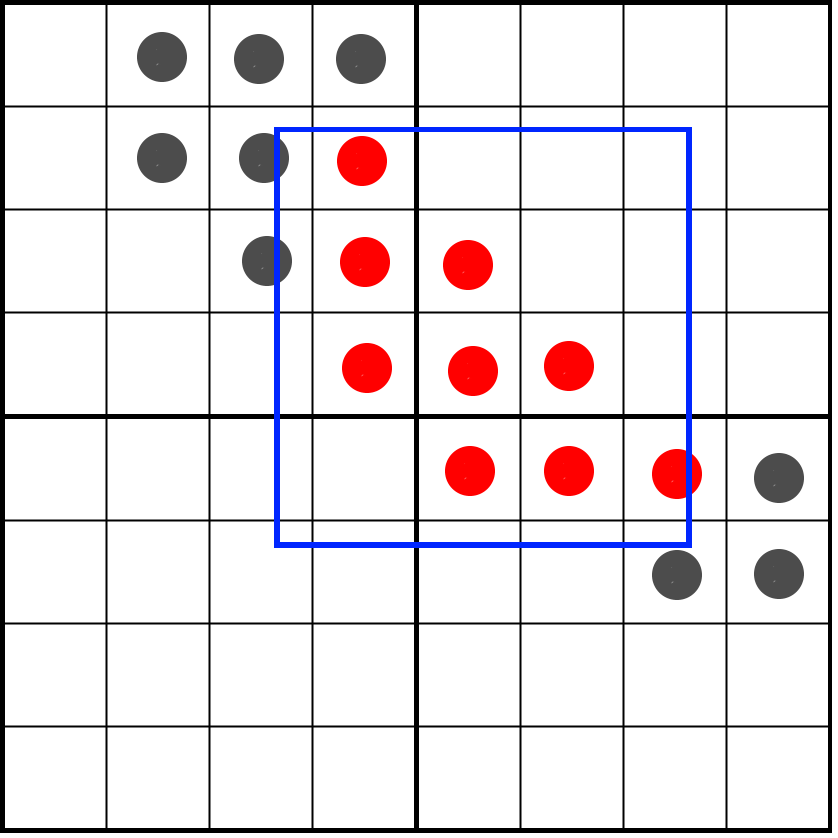
Теперь нам достаточно подсчитать биты, оставшиеся в текселах, что можно сделать операцией bitCount, потом разделить результат на 16 и получить нужный оттенок!
float shade = (bitCount(left) + bitCount(right)) / 16.0;Теперь полный рендер буквы выглядит так:
В продолжении…
Во второй части мы сделаем следующий шаг и посмотрим, как можно применить эту технику к повёрнутым сеткам. Мы будем рассчитывать вот такую схему:
И мы увидим, что почти всё это можно свести к нескольким таблицам.
Благодарю Себастьяна Аалтонена (@SebAaltonen) за его помощь в решении проблемы с textureGather и, разумеется Михиля ван дер Леу (@MvdleeuwGG) за его идеи и интересные беседы по вечерам.
