
Не так давно я презентовал синтаксического чат-бота по имени Ваня Разумный («Создание ИИ методом «глокой куздры». Интеллектуальная одиссея»). Последующий очевидный этап, который, подобно другим создателям искусственного разума, захотелось пройти – даровать детищу голос. Казалось бы, чего проще?
Пришлось, однако, помучиться. Некоторые проблемы решить так и не удалось – безусловно, по причине дилетантизма. А впрочем, сомневаюсь, что и профессионалам интересно решать сопутствующие задачки. Никому это не интересно, вот и мне не хотелось. Я надеялся по-быстрому прикрутить звук и перейти к последующим задумкам…
Но обо всем по порядку.
(Пишу в надежде, что мои страдания на ниве озвучки помогут кому-нибудь из подобных мне любителей. Айтишным зубрам данный пост ни к чему).
Понятно, что задача озвучивания разделяется на два не связанных между собой раздела:
- Синтез текста,
- Распознавание речи.
Берусь на пункт первый, как легчайший. Сразу натыкаюсь на код для начинаюших, всего несколько строк.
Синтез предустановленного голоса
using System.Speech.Synthesis; public static void getSpeech(string text) { SpeechSynthesizer speaker = new SpeechSynthesizer(); speaker.SetOutputToDefaultAudioDevice(); string selectedVoice = Properties.Settings.Default.Voice; speaker.SelectVoice("Microsoft Irina Desktop"); speaker.Rate = 1; speaker.Volume = 100; speaker.Speak(text); speaker.Dispose(); }
Вставляю в исходники, и, представьте себе, машина говорит! Я от радости слегка ошалеваю. Так просто?!!!
Остается ерунда: прицепить мужской голос. К сожалению, в виндах предустановлен один русский голос – женский: «Microsoft Irina Desktop». А у меня чат-бот мальчик, а не девочка, делать ему операцию по изменению пола я не планирую.
Гуглю снова, через некоторое время убеждаюсь, что мужских русских голосов немного. Имеется в виду, бесплатных голосов, потому что платные услуги не для моих поющих романсы финансов. Но имеются, имеются и бесплатные мужские голоса, к примеру голос «Александр» отечественной библиотеки RHVoice. Хорошо, пусть будет Александр.
К сожалению, установка (для меня) какая-то сложная. Зато имеются готовые сборки. Скачиваю одну из сборок, инсталлирую, лезу в настройки виндов (Распознавание речи / Преобразование текста в речь) и – о чудо! – обнаруживаю рядом с «Microsoft Irina Desktop» голос «Aleksandr». С замиранием сердца запускаю…
В виндах все работает!
Заменяю в исходниках «Microsoft Irina Desktop» на «Aleksandr» и… Ни черта уже не работает! Печально, но не смертельно. Щас поправим.
Изучаю проект RHVoice, в особенности описание конфигурационного файла, экспериментирую так и сяк… Результат тот же: вместо звуков Александр издает неразборчивое рычание либо вообще ничего, при том что майкрософтовская Ирина зачитывает, как диктор на телевидении.
Пару дней еще на что-то надеюсь и копошусь, но потом сдаюсь. Да, руки у меня кривые. Ну не знаю я, почему «Aleksandr» отказывается разговаривать, не знаю, и на форумах ответа не находится.
Ладно, изучаю другие бесплатные голоса, благо их не более десятка.
Тут до меня доходит, что, если я желаю, чтобы пользователи Вани Разумного слышали тот же голос, который слышу я, то в пакет придется вмонтировать инсталлятор голоса. Это мне не под силу, да и заниматься неохота, поэтому пункт первый «Синтез текста в речь» завершается позорной капитуляцией.
Я принимаю принципиальное решение:
- Пошли все к чертям собачьим! Пусть пользователи чат-бота сами инсталлируют голоса, какие захотят, и выбирают из списка. Прицепить список предустановленных голосов – это посильная задача.
- Я озвучиваю Ваню Разумного женским голосом, потому что Ваня юн и голос его еще не сломался. «А вовсе не потому, что у меня руки растут из задницы», — уговариваю себя в порядке психотерапии.
С чистым сердцем перехожу к пункту № 2: Распознавание речи.
Второй пункт решающий. Кому нужен чат-бот, умеющий воспроизводить голосом собственные фразы, но не понимающий голоса собеседника?! В случае неуспеха затея с озвучкой рушится.
Опять гугление, на этот раз исступленное, на последнем дыхании.
Что выясняется? Варианты в основном платные: бесплатные имеются, но для русского языка их единицы.
В качестве простейшего в сети фигурирует SpeechKit от Яндекса, но его я приберегаю на потом, если более сложные варианты не сработают. Мне предпочтительней получить распознавалку оффлайн.
Вот совершенно бесплатное решение от CMUSphinx. Изучаю отзывы:
- во-первых, не слышится залихватских возгласов: братцы, все работает!
- во-вторых, описание установки для меня совершенно заумное. Кажется, после установки библиотеку еще и обучать надо!
Отпадает.
Далее. Microsoft Speech Platform, бесплатно.
Гуглю и нахожу ссылку с доступным описанием плюс исходник примера. Скачиваю исходник, компилирую. Произношу «Раз, два», и программа выдает распознанный текст. Рабо-о-отает!..
Немного смущает то обстоятельство, что текст не сам по себе распознается, а предварительно его необходимо добавить в словарь. Но не страшно: вместо «один, два» прицеплю объемный файл с орфографией.
Переношу код из исходника примера в свои исходники, пытаюсь добиться того же эффекта… Не компилирует, вываливается в ексепшн.
Тут левым глазом вчитываюсь в комментарии и обнаруживаю, что решение пригодно для распознавания команд, а работать с непрерывным текстом не позволяет. Проверяю по исходному примеру. Ага, «раз, два» распознает, а «раз, два, три» уже не полностью: тройку не слышит. Правым глазом нахожу в комментариях что-то вроде: «Непрерывный текст распознается за плату», — и Microsoft Speech Platform перестает для меня существовать.
Слышал, что Google предоставляет свою распознавалку бесплатно на год, надо бы проверить.
Проверяю. Уже нет, насколько могу судить.

Не исключаю, что гуглил неправильно, но не обессудьте: делюсь с начинающими тем личным опытом, который приобрел.
Иду сдаваться Яндексу. Здесь возгласов «Братцы, все работает!» хватает, и частные лица, по индивидуальному запросу, могут получить сервис бесплатно, своими глазами объявление видел. Подключиться к SpeechKit по API я смогу, инструкции имеются.
Прихожу сдаваться и что вижу? Фирма только что презентовала Яндекс.Облако, куда перенесла сервис речевых технологий. Я не гордый, зарегистрируюсь в Облаке: вероятно, там все то же самое, что было раньше…
И тут меня подстерегает жутчайший облом:
- Во-первых, о бесплатном пользовании распознавалкой уже не слыхать. Правда, дают грант, которым можно оплачивать сервис какое-то время. Ладно, продолжаю регистрацию…
- А это что за дела?! Для работы с сервисом от меня требуют указания реквизитов банковской карты. Выдержка из письма, присланного мне как создателю профиля в Облаке:

Где-то я такое видел: по-моему, в Google. Следовательно, Яндекс взял пример со старшего товарища.
Удивляюсь отсутствию возмущенных постов на Хабре. Они ж не просто требуют денег за услуги, а просят ключ от квартиры, где деньги лежат! Меня и так бесит, что с некоторых пор банк может не выдать мои собственные деньги согласно решению банковского менеджера, а тут второй дяденька требует по сути аналогичного права. Причем, до того, как я согласился перейти на платную версию. Я никакого договора с этим дяденькой еще не заключил, а ключи от квартиры уже подавай, на всякий случай. Ай, какой добрый и предусмотрительный!
Знаете, дяденька Яндекс, я против вас ничего не имею, и сервисами вашими пользуюсь с удовольствием, но, извините, пока у меня будет возможность выбора, пароля от моей банковской карты вы не получите. А специально под вас оформлять карту с двумя рублями мне недосуг, да и накладно.
Тут на глаза попадается заметка о несовершенстве технологий распознаваний речи. Смысл тот, что на текущий момент ничего путного в области распознавания речи не произвели, и пользоваться распознавалками не стоит. Матерюсь и смиряюсь с мыслью, что в ближайшее время Ваня Разумный не заговорит.
Пунктом ниже идет следующая статейка, об онлайн-сервисах распознавания речи. Онлайн-сервисы не подходят, разумеется. Мне ж звук в winforms распознавать, а не на сайте… Без малейшей надежды кликаю по ссылке и…
На следующий день чат-бот обретает голос.
Представляю палочку-выручалочку: speechpad.ru. Предупреждаю, что сервис работает только в Хроме. Меня это не останавливает: я по любому Хромом пользуюсь. А движок у него от Google: видимо, какие-то неведомые мне возможности использовать сервис бесплатно остаются.
Speechpad имеет незамысловатый, но вполне себе работоспособный интерфейс:
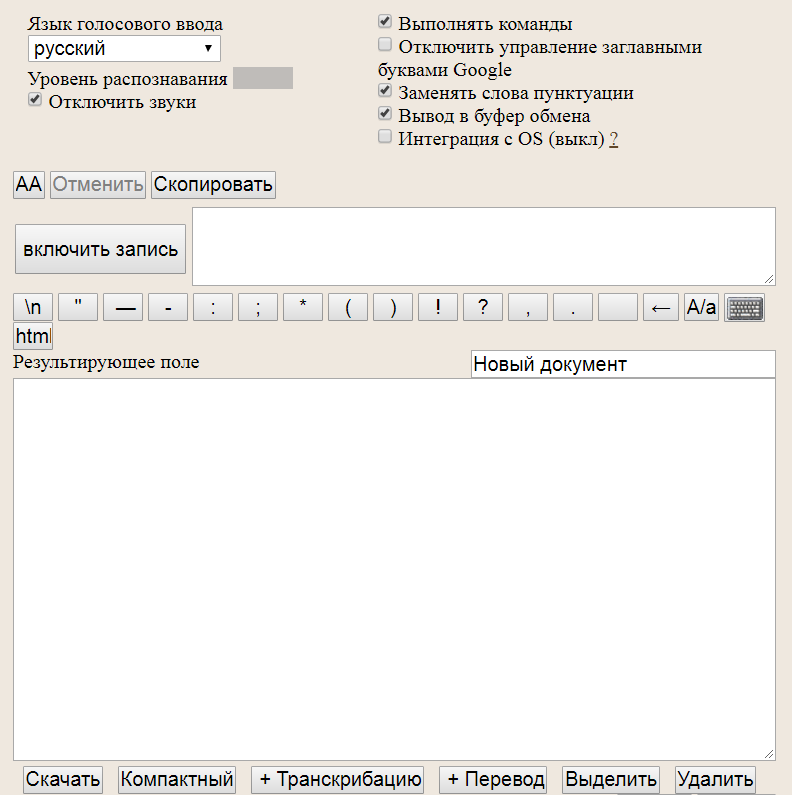
Подключение распознавалки занимает минимум времени.
Ознакомившись с инструкцией, первым делом берусь интегрировать сервис с OS. Правда, интеграция платная, но 100 рублей в месяц независимо от объема распознавания – это ж другое дело! Это не драконовские тарифы за каждый распознанный кусок. Тем более что на ознакомление дается пробный период в два дня.
Регистрируюсь на сайте, нажимаю кнопку включения тестового периода, за минуту инсталлирую пару указанных в инструкции приблуд, и все работает. Принцип действия – распознанный текст добавляется по месту нахождения курсора. Действительно распознается и действительно добавляется. Распознается не без ошибок, но, с моей точки зрения, удовлетворительно.
Через пару часов тестирования прихожу к выводу, что рациональней использовать буфер обмена, причем данная фича бесплатная. Тут, конечно, на любителя:
- при интеграции с OS курсор должен находиться на определенном поле чат-бота. Во время тестирования я несколько раз забываюсь и перехожу с чат-бота в VS, в результате чего распознанный текст вбивается в исходники;
- при пользовании буфером обмена соответственно запрещено пользоваться буфером обмена, иначе скопированный в буфер из сторонней программы текст мигом окажется в чат-боте. Пару раз я также на этом попадаюсь, но вскоре осваиваюсь.
В конце концов останавливаюсь на буфере обмена.
Все, задача решена.
Больше времени, чем подключение распознавалки от speechpad, занимает нераспознавание фраз, произносимых чат-ботом. Изрядно потею, пока до меня не доходит, что проще всего отключать микрофон. Нагугливаю код отключения микрофона.
Код включения-отключения микрофона
* — комментарии не мои, а скопипастенные. Ссылку не даю, так как ее владелец признается, что сам нагуглил код в недрах англоязычного интернета.
** — мной внесены в код несущественные изменения.
using NAudio.CoreAudioApi; //выключить-включить микрофон public static void Mute(bool start) { CoreAudioMicMute CAMM = new CoreAudioMicMute(); CAMM.SetMute(start); } internal class CoreAudioMicMute { private MMDevice[] rgMicDevice; //Для записи найденных для нас устройств int MaxMicro = 0; public CoreAudioMicMute() { try { MMDeviceEnumerator DevEnum = new MMDeviceEnumerator(); MMDeviceCollection devices = DevEnum.EnumerateAudioEndPoints(DataFlow.Capture, DeviceState.Active); // DataFlow.Capture - Микрофоны(или устройства в которые поступает звук), //DeviceState.Active - Активные устройства // Поиск активных устройств(для нас микрофонов) MaxMicro = 0; for (int i = 0; i < devices.Count; i++) // devices.Count - количество устройств(активные микрофоны) { MMDevice deviceAt = devices[i]; if (deviceAt.DataFlow == DataFlow.Capture && deviceAt.State == DeviceState.Active) //Ваш - искать(ставим контрольную точку на поле выше, где начинается //"if(...", ну а далее ищем в deviceAt, стринг переменную - DeviceFriendlyName //можно и FriendlyName, поскольку в ней уникальное имя нашего девайса( //микрофона наушников и тд.) { ++MaxMicro; } } // Заносим в массив (все) найденный(ые) микрофон(ы) или другие устройства(динамики, наушники или др) rgMicDevice = new MMDevice[MaxMicro]; MaxMicro = 0; for (int i = 0; i < devices.Count; i++) { MMDevice deviceAt = devices[i]; if (deviceAt.DataFlow == DataFlow.Capture && deviceAt.State == DeviceState.Active) //Меняем на свое устройство(а) { MaxMicro++; rgMicDevice[MaxMicro - 1] = deviceAt; } } } catch (Exception) { } } public void SetMute(bool mute) //Функция, отключающая звук устройств записанных в массив private MMDevice[] rgMicDevice { try { for (int i = 0; i < MaxMicro; i++) { rgMicDevice[i].AudioEndpointVolume.Mute = mute; //= true - выключить звук устройства(для нас микрофона) } } catch (Exception) { } } }
* — комментарии не мои, а скопипастенные. Ссылку не даю, так как ее владелец признается, что сам нагуглил код в недрах англоязычного интернета.
** — мной внесены в код несущественные изменения.
Перед фразой чат-бота отключаю микрофон, после фразы включаю, в результате сервис слышит только мои фразы, но не слышит чат-бота.
Вот итоговый результат:
Для полноты впечатлений просматриваю еще с десяток сайтов с распознаванием речи. В принципе, все друг на дружку похожи, и движки на большинстве от Google, но возможность явным образом получать текст в буфер обмена не находится. Судя по комментариям, кое-где присутствует возможность озвучки сайтов, но в данную тему не углубляюсь. Как говорится, от добра добра не ищут.
Теперь другая проблема: думаю, неплохо бы прикрутить анимацию, проговаривающую произносимую речь. Хочется чего-нибудь попроще: библиотеку для C# с выбором персонажа. Но мне сказали, в .NET таких нет…
Собственно, все на этом. У юноши остается женский голос, но в целом голосовой режим функционирует.
Надеюсь в скором времени представить Ваню Разумного в более презентабельном виде. За прошедшее время он сильно обновился и поумнел: перешел с Access на PostgreSQL, алгоритмы усовершенствовались, удалось подключить словари, наколотить начальную базу типовых ответов – другой человек, короче.
