В мире PHP хорошо известны инструменты миграций структуры БД — Doctrine, Phinx от CakePHP, от Laravel, от Yii — это то первое, что пришло в голову. Наверняка, есть еще с десяток. И большинство из них работают с миграциями — командами для внесения инкрементных изменений в схему базы данных.
Я не буду описывать зачем это, на хабре много постов на эту тему. Например:
- Версионная миграция структуры базы данных: основные подходы — хоть и старая статья, но принципы не стареют
- Эволюционный дизайн баз данных — перевод статьи Мартина Фаулера, хорошее описание [инкрементного подхода]
- Опыт 1440 миграций баз данных — практичный пост по работе с PostgesSQL
Далее, развитие моего опыта работы в команде с постоянным изменением структуры БД в разных ветках.
raw SQL vs PHP api
Мы пишем миграции на чистом SQL. Многие инструменты предоставляют PHP-api для написания инструкций транслируемых в SQL-код. Теперь я вообще не понимаю зачем это? Такой инструмент всегда будет ограничен своими возможностями. Специфические инструкции для конкретного движка они не позволяют написать, приходится все равно использовать чистый SQL. Я уже не говорю про написание процедур и вьюх.
Кто-то жаловался, что не хочет учить синтаксис ALTER-команд… Ну, не знаю, открыл справочник и написал, примеров гора, в большом проекте особенно.
Миграции данных (INSERT, UPDATE), тоже всегда пишутся на SQL. Потому что никогда нельзя положиться на текущую версию ОРМ и Моделей. В одной ревизии они есть, в другой уже нет.
Например:
Rollback Country::delete()->where(....)->execute();
Хотите откатить состояние базы. А этого PHP-класса уже нет в репо. Нужно искать последний коммит, где он был и откатываться от-туда. Бррр…
Поэтому SQL — все просто и надежно:
--TRANSACTION --UP ALTER TABLE authors ADD COLUMN code INT; ALTER TABLE posts ADD COLUMN slug TEXT; UPDATE authors SET ... --DOWN ALTER TABLE authors DROP COLUMN code; ALTER TABLE posts DROP COLUMN slug;
Транзакции в DDL
С переходом на PostgreSQL забыл о сломанных миграциях как страшный сон — миграция упала в середине, что-то накатилось, что-то нет, сиди и правь ручками… Это вынуждало писать атомарные однострочные команды и запускать их по одной. С транзакциями все просто: если что-то сломалось — все откатывается назад (ну почти все ))). Просто чинишь и запускаешь заново. Автоматическая сборка работает на ура, если что и упало, то быстро исправляется и поднимается.
Вьюхи (представления) и функции
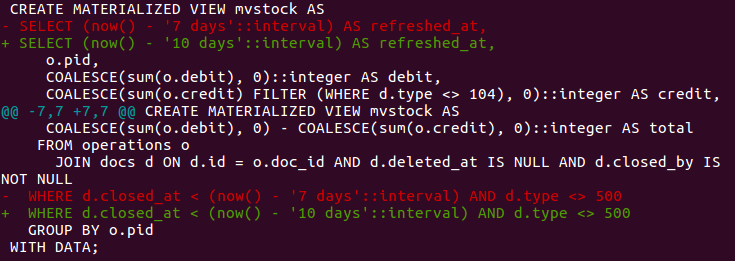
Здесь проблема в том, что они не могут быть обновлены инкрементно, как ALTER в таблицах. Нужно DROP и CREATE. Т.е. по дифу (тексту миграции) совсем не понятно, что же поменялось в итоге. Особенно когда логика накручена, это довольно неудобно. Например:
--UP DROP VIEW ... CREATE VIEW mvstock AS SELECT (now() - '7 days'::interval) AS refreshed_at, o.pid, COALESCE(sum(o.debit), 0)::integer AS debit, COALESCE(sum(o.credit) FILTER (WHERE d.type <> 104), 0)::integer AS credit, COALESCE(sum(o.debit), 0) - COALESCE(sum(o.credit), 0)::integer AS total FROM operations o JOIN docs d ON d.id = o.doc_id AND d.deleted_at IS NULL WHERE d.closed_at < (now() - '7 days'::interval) AND d.type <> 500 GROUP BY o.pid WITH DATA; --DOWN DROP VIEW ... CREATE VIEW mvstock AS SELECT (now() - '10 days'::interval) AS refreshed_at, o.pid, COALESCE(sum(o.debit), 0)::integer AS debit, COALESCE(sum(o.credit) FILTER (WHERE d.type <> 104), 0)::integer AS credit, COALESCE(sum(o.debit), 0) - COALESCE(sum(o.credit), 0)::integer AS total FROM operations o JOIN docs d ON d.id = o.doc_id AND d.deleted_at IS NULL WHERE d.closed_at < (now() - '10 days'::interval) AND d.type <> 500 GROUP BY o.pid WITH DATA;
Вот что здесь изменилось?
Остановились на том, что рядом с миграциями лежит папочка, где хранится текущий код вьюх и процедур, который обновляется и копипастится в rollback миграции.
И теперь дифф становится похож на:
Еще в Авито сделали интересное решение для версионирования кода хранимых процедур
В целом, этот кейс поднимает хорошую проблему — как посмотреть историю изменений конкретного объекта структуры БД. По каждой таблице хочется посмотреть историю изменений в связи с решением конкретных задач.

Нашел на Хабре интересный подход для автоматизации фиксации изменений структуры базы данных.
Работа с ветками
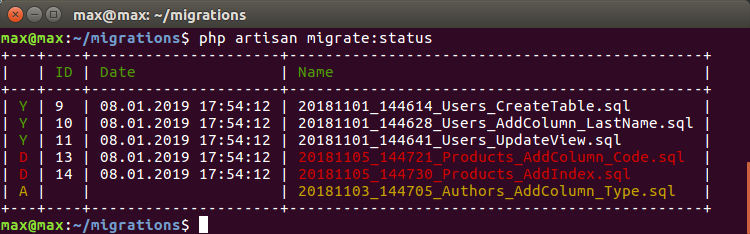
Моя вечная боль — как переключиться между двумя А- и В-ветками, в каждой из которых есть правки по структуре БД.
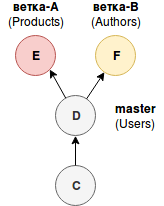
Надо откатить миграции в А-ветке (надо еще помнить какие и сколько), потом переключиться в В-ветку и накатить новые миграции. Ладно еще, если наши правки совместимы и я могу просто переключиться на вторую ветку и накатить дополнительные миграции из B.
А если нет? А если у меня не одна такая ветка? А потом откатить все эти review-состояние? Всегда это ненавидел…
Теперь при переключении на чужую ветку я могу автоматически удалить чужие миграции и накатить текущие:
где:
D — А-миграции, которые были запущены в А-ветке, но их нет в текущей ветке, и их рекомендуется удалить
А — B-миграции, которые появились в новой ветке и их надо накатить
Это становится безумно удобно при тестировании и автосборке на одной базе. Когда нет смысла или возможности для каждой ветки создавать базу с нуля. Переключаешься на ветку и автоматом синхронизируется состояние БД.
Нумерация и очередность выполнения
Все известные мне инструменты нумеруют миграции таймстампом — хорошее решение. Если я пишу несколько миграций, то сохраняется необходимая очередность. У другого разработчика в другой ветке может стоять любая дата, даже моя — но это уже не важно в каком порядке мы с ним накатимся, наши изменения не зависят друг от друга. Даже, если мы работаем с одной и той же таблицей (добавляем по колонке), то все необходимые изменения пройдут в любом порядке. Главное, что соблюдается очередность моих зависимых правок.

Я не рассматриваю случаи, когда нам нужно править одно и тоже — эти моменты всегда согласуются. Ну, или будет фейл на этапе сборки и тестирования.
Вот интересный пример.
Мы делаем разные правки в одной вьюхе или процедуре, т.е. в тех структурах, которые обновляются через удаление. Т.е. я, например, добавил колонку col_A во вьюху, а мой коллега col_В. Соответственно, если его код выкатывается после моего, то в его версии не будет моей колонки:
CREATE VIEW vusers AS SELECT login, name, -- ....
| ветка-А | ветка-B |
|---|---|
|
|
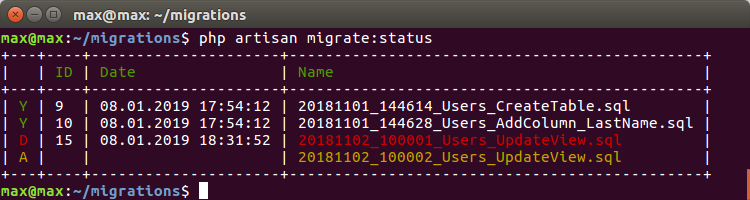
Еще один интересный случай — исправления в миграциях.
Суть в том, что миграция, которая была применена, уже не будет применяться повторно, сколько бы изменений вы не вносили в нее (надо откатить сначала, а потом снова применить). Т.е. вы отдали Миграцию на тестирование, все норм, а потом спохватились и сделали небольшую правку. Но тестовый или другой сервер, где вы ее применили, об этом уже не узнает.
В этих случаях мы переименовываем файл миграции, прибавляя новый номер версии, чтобы мигратор начал интерпретировать это как 2 команды — откатить 1 и накатить 2,
например:
Rollback
Всегда писать ROLLBACK, даже если он не может вернуть базу к исходному состоянию. Например DROP TABLE, какой там может быть ROLLBACK?
В таких случаях мы пишем пустой CREATE TABLE. Суть в том, чтобы dev-система всегда могла легко переключиться между ветками. Для PROD управление необратимыми правками решается уже на другом уровне. Я могу сделать копию таблицы, или переименовать ее вместо удаления. Но сам принцип написания миграции — ролбек ОБЯЗАН вернуть СТРУКТУРУ базы в исходный уровень, а данные уже по мере возможности.
В боевом окружении ролбек я использовал всего 1-2 раза в своей жизни. А в dev постоянно. Поэтому всегда проверяю что ролбек все возвращает в нужное состояние.
Часто разработчики могут делать ошибки в ролбеке. Т.к. они в первую очередь концентрируются на новых правках, их тестируют и с ними работают. С ролбеком работают уже другие люди и процессы. Поэтому я всегда тестирую миграции UP — ROLLBACK — UP
Интересный момент появляется на постоянной тестовой базе (база не удаляется). Написали миграцию, ролбек отлично работает, отдали на тестирование, тестировщик нагенерил данных в новом формате, пытается откатить, а новые данные не дают. Классический пример
ALTER TABLE abc ALTER COLUMN code SET NULL
Прекрасно! В базе после тестирования полно NULL значений. Делаем ROLLBACK:
ALTER TABLE abc ALTER COLUMN code SET NOT NULL
и обратно уже никак :-(
Надо добавлять команду:
DELETE FROM abc WHERE code IS NULL
Сложность в том, что это нужно держать в голове и никак это не автоматизировать, если мы не говорим о пересоздании базы с нуля каждый раз.
Немного про удаление данных
Обычно мы стараемся НЕ удалять заполненные таблицы и колонки сразу. Лучше переименовать или сделать копию, а удалить уже по-позже, когда все уляжется и данные потеряют актуальность:
ALTER TABLE user_logs RENAME TO user_logs_20190223; -- или CREATE TABLE user_logs_20190223 AS TABLE user_logs;
Мигратор
Мы сейчас работаем с Laravel — у него есть стандартный, привычный движок управления миграциями. Хочешь, пиши даже на чистом SQL, правда все равно в PHP-классе. Но мои неоднократные попытки заставить его работать так, как нам надо вылились в отдельный репо:
- Решение состоит из 2 частей — lib и реализация под конкретную консоль (Laravel, Symfony). Можно интегрировать в любою консоль, или хоть в web-морду.
- Нет своего конфига и коннекта — зачем, когда он уже есть в вашем проекте. Цепляете свой коннект к интерфейсу и вперед.
- SQL ролбека хранится в базе. Это необходимо для переключения между ветками
- Проверено на Postgesql, Mysql (без транзакций). Подходит в принципе для любых баз и структур, потому что используется raw-формат.
Ссылки
— migrations-lib
— реализация под Laravel/Artisan
— реализация под Symfony/Console
