Можно ли по цитате определить, кто из политиков ее автор? Украинская НКО Vox Ukraine делает проект VoxCheck, в рамках которого проверяет высказывания наиболее рейтинговых политиков. Недавно они выложили всю базу проверенных цитат. Я как раз слушаю курсы по NLP и решила проверить, насколько точно по тексту цитаты можно определить ее автора.
Disclaimer. Эта статья написана из интереса к теме и желания опробовать изученный материал на практике, без претензий на максимально точный и детальный анализ.
Для анализа был использован python, код доступен на github.
База сейчас содержит 1952 цитаты со следующим распределением по политикам:
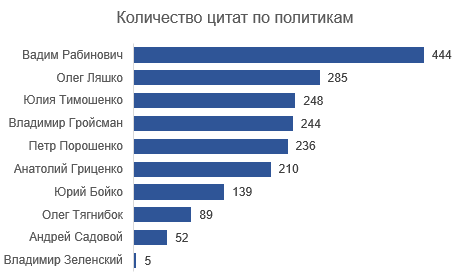
Для целей анализа я выбрала людей с > 200 цитатами. Соответственно, выпали из анализа Юрий Бойко, Олег Тягнибок, Андрей Садовой и Владимир Зеленский. В массиве осталось 1667 цитат. Из шести оставшихся спикеров четверо (кроме Гройсмана и Рабиновича) — зарегистрированные кандидаты на ближайшие президентские выборы.
Цитаты бывают разные, от коротких, порядка 30 знаков («Я подал уже 112 законопроектов.») до длинных, около 1200 знаков. Средняя длина цитаты — около 200 знаков (это, например, «Скоро наші діти корову бачитимуть лише у музеї поряд із динозавром чи в підручниках із природознавства – у результаті тієї політики, яку проводить нинішня влада. Поголів’я скота — менше 2-х мільйонів.»)
Для начала посмотрим, какие слова являются более характерными для тех или иных спикеров. Вот топ-10 слов с самым большим значением TF-IDF для каждого кандидата:

Зеленым выделены те слова, которые я хотела бы прокомментировать по каждому спикеру, чтобы дать немного контекста.
Олег Ляшко:
Порошенко и Гриценко много говорят о военном конфликте, что довольно логично: Порошенко президент и соответственно верховный главнокомандующий, а Гриценко военный и был министром обороны.
Гройсман премьер-министр, и в основном говорит об экономике, в т.ч.о государственном долге.
В цитатах Вадима Рабиновича специфической тематики не прослеживается, возможно потому что он говорит очень много (444 цитаты из 1952, у всех остальных — менее 300 цитат).
Юлия Тимошенко много говорит о газотранспортной системе Украины, о ликвидации банков, а также о низких экономических показателях страны.
Итак, у нас получается 6 классов (спикеров). Для классификации я использовала наивный Байесовский классификатор. Из текста исключены стоп-слова русского и украинского языков (с помощью пакета stopwords). Включены n-граммы длиной до 2-х (варианты с длиной до 3-х тоже тестировался, но показал оверфиттинг). Тестовая выборка взята в пропорции 20% от общей.
Итоговая точность модели (доля правильно классифицированных цитат) на тренинговой выборке — 74,8%, на тестовой — 75,7%
Перекрестные результаты по авторам:

Выше всего точность для Вадима Рабиновича (97%) — скорее всего потому, что он единственный русскоязычный спикер из шести. Высокая точность классификации Гройсмана и Ляшко (78% и 77%).
Чуть выше 60% показатели точности определения цитат Порошенко и Тимошенко. Их обоих модель чаще определяет как Гройсмана. Гройсман как премьер-министр часто говорит на тему экономики в форме «отчета о проделанной работе», и неправильно классифицированные цитаты Порошенко и Тимошенко тоже об этом (только у Порошенко как представителя власти это позитив, а у Тимошенко наоборот).
Например, вот цитата Порошенко, определенная моделью как цитата Гройсмана:
5 млрд грн, (тобто) 4 млрд грн того року і 1 млрд грн цього року спрямовані на сільську медицину
А также цитата Тимошенко, определенная как цитата Гройсмана:
В наступному бюджеті на утримання тюрем виділили вдвічі більше грошей, ніж на науку, яка робиться в Академії наук України.
Ниже всего точность (57%) у цитат Анатолия Гриценко. Его модель часто определяет как Порошенко (что логично, учитывая военную тематику их цитат), а также как Ляшко. В случае с Ляшко неправильная классификация — это цитаты с критикой власти, в т.ч., например, о миграции: Я не кажу про те, що той же член вашого уряду, Володимире Борисовичу, пан Клімкін сказав, що мільйон щороку покидає країну.
В целом, как мне кажется, для таких коротких цитат схожего формата (устные выступления политиков) и тематики (украинская политика) результат неплохой. Кстати, на этих же данных я пробовала сделать модель, определяющую категорию цитаты (правда / неправда / манипуляция), но точность получилась очень низкая. Что в принципе логично: глядя на цитату по типу «Столько-то денег было потрачено на вот это, а в вот такой стране на это тратят вот столько-то» сложно определить правдивость изложенных в ней данных :)
Disclaimer. Эта статья написана из интереса к теме и желания опробовать изученный материал на практике, без претензий на максимально точный и детальный анализ.
Для анализа был использован python, код доступен на github.
Данные
База сейчас содержит 1952 цитаты со следующим распределением по политикам:
Для целей анализа я выбрала людей с > 200 цитатами. Соответственно, выпали из анализа Юрий Бойко, Олег Тягнибок, Андрей Садовой и Владимир Зеленский. В массиве осталось 1667 цитат. Из шести оставшихся спикеров четверо (кроме Гройсмана и Рабиновича) — зарегистрированные кандидаты на ближайшие президентские выборы.
Цитаты бывают разные, от коротких, порядка 30 знаков («Я подал уже 112 законопроектов.») до длинных, около 1200 знаков. Средняя длина цитаты — около 200 знаков (это, например, «Скоро наші діти корову бачитимуть лише у музеї поряд із динозавром чи в підручниках із природознавства – у результаті тієї політики, яку проводить нинішня влада. Поголів’я скота — менше 2-х мільйонів.»)
TF-IDF
Для начала посмотрим, какие слова являются более характерными для тех или иных спикеров. Вот топ-10 слов с самым большим значением TF-IDF для каждого кандидата:
Коротко о TF-IDF
TF-IDF (term frequency — inverse document frequency) — это показатель, оценивающий важность слова в контексте документа. TF-IDF слова пропорционален частоте употребления этого слова в документе и обратно пропорционален частоте употребления слова во всех документах коллекции. В контексте наших данных высокий TF-IDF означает, что политик часто употребляет это слово, а другие политики — относительно реже.
Для подсчета TF-IDF был применен стемминг (stemming) — приведение слова к основе.
Для подсчета TF-IDF был применен стемминг (stemming) — приведение слова к основе.
Зеленым выделены те слова, которые я хотела бы прокомментировать по каждому спикеру, чтобы дать немного контекста.
Олег Ляшко:
- Польша: Ляшко часто упоминает Польшу в связи с рабочей миграцией туда украинцев, а также сравнивает доходы в Польше и Украине
- Зерновые: Ляшко говорит о том, что Украина экспортирует зерно и теряет на этом, потому что могла бы дороже эспортировать муку
- Онкология, лекарства: Ляшко ярый противник нынешней медицинской реформы и часто говорит о том, что расходы на онкологию почти не покрывается государством
Порошенко и Гриценко много говорят о военном конфликте, что довольно логично: Порошенко президент и соответственно верховный главнокомандующий, а Гриценко военный и был министром обороны.
Гройсман премьер-министр, и в основном говорит об экономике, в т.ч.о государственном долге.
В цитатах Вадима Рабиновича специфической тематики не прослеживается, возможно потому что он говорит очень много (444 цитаты из 1952, у всех остальных — менее 300 цитат).
Юлия Тимошенко много говорит о газотранспортной системе Украины, о ликвидации банков, а также о низких экономических показателях страны.
Классификация цитат
Итак, у нас получается 6 классов (спикеров). Для классификации я использовала наивный Байесовский классификатор. Из текста исключены стоп-слова русского и украинского языков (с помощью пакета stopwords). Включены n-граммы длиной до 2-х (варианты с длиной до 3-х тоже тестировался, но показал оверфиттинг). Тестовая выборка взята в пропорции 20% от общей.
Итоговая точность модели (доля правильно классифицированных цитат) на тренинговой выборке — 74,8%, на тестовой — 75,7%
Перекрестные результаты по авторам:
Выше всего точность для Вадима Рабиновича (97%) — скорее всего потому, что он единственный русскоязычный спикер из шести. Высокая точность классификации Гройсмана и Ляшко (78% и 77%).
Чуть выше 60% показатели точности определения цитат Порошенко и Тимошенко. Их обоих модель чаще определяет как Гройсмана. Гройсман как премьер-министр часто говорит на тему экономики в форме «отчета о проделанной работе», и неправильно классифицированные цитаты Порошенко и Тимошенко тоже об этом (только у Порошенко как представителя власти это позитив, а у Тимошенко наоборот).
Например, вот цитата Порошенко, определенная моделью как цитата Гройсмана:
5 млрд грн, (тобто) 4 млрд грн того року і 1 млрд грн цього року спрямовані на сільську медицину
А также цитата Тимошенко, определенная как цитата Гройсмана:
В наступному бюджеті на утримання тюрем виділили вдвічі більше грошей, ніж на науку, яка робиться в Академії наук України.
Ниже всего точность (57%) у цитат Анатолия Гриценко. Его модель часто определяет как Порошенко (что логично, учитывая военную тематику их цитат), а также как Ляшко. В случае с Ляшко неправильная классификация — это цитаты с критикой власти, в т.ч., например, о миграции: Я не кажу про те, що той же член вашого уряду, Володимире Борисовичу, пан Клімкін сказав, що мільйон щороку покидає країну.
В целом, как мне кажется, для таких коротких цитат схожего формата (устные выступления политиков) и тематики (украинская политика) результат неплохой. Кстати, на этих же данных я пробовала сделать модель, определяющую категорию цитаты (правда / неправда / манипуляция), но точность получилась очень низкая. Что в принципе логично: глядя на цитату по типу «Столько-то денег было потрачено на вот это, а в вот такой стране на это тратят вот столько-то» сложно определить правдивость изложенных в ней данных :)
