Comments 358
Суть в том, что для большинства JS/DBA это не важно.
Это я не туда полез или все таки собеседующий идиот?
Ну и отдельный момент — как идя на собеседование на верстальщика UI я должен был догадаться, что от меня требуется алгоритмическая подготовка, чтобы «не лезть»?
P.S. Отдельно замечу что с алгоритмической подготовкой у меня всё приемлемо. Но речь не об этом, а о самом неуместном вопросе на рассматриваемую должность.
В результате там есть всё, что угодно, кроме одного: быстрой реакции на нажатия кнопок.
В подавляющем большинстве случаев нажатие куда угодно заставляет усомниться в том, что у тебя в руках — устройство, способное выполнять миллиарды операций в секунду. Потому что они пары-тройки простых операций за секунду, зачастую, неспособно выполнить…
Ну и отдельные момент — в современных движках UI верстается в редакторах, кода там нет от слова «вообще». Максимум есть обработчики нажатий кнопок, но они к верствке не относятся. Даже всякие анимации делаются в редакторах, с использованием минимума кода типа «запустить анимацию/остановить анимацию».
Так-то я про это знаю. И потому вообще не понимаю зачем нужен отдельный человек на подобную должность и какого масштаба должна быть игра, чтобы можно было выделить на это отдельную штатную единицу…
Может быть авторы используют «несовременный движок UI»?
UE4
зачем нужен отдельный человек
Инструментом тоже нужно уметь пользоваться. Просто рандомный человек такого наворотит…
Инструментом тоже нужно уметь пользоваться. Просто рандомный человек такого наворотит…Это понятно. Но у меня нет уверенности в том, что от вас хотели только «UI в редакторах, кода там нет от слова «вообще»».
Скорее всего было понимаение, что какой-то процент времени (не знаю сколько: день в неделю или месяц… неважно) человек должен верстать пресловутый UI — а остальное время он будет кодить что-то другое.
А если вы можете решить только часть задачи — то логично же поискать кого-то, кто сможет решить её всю.
Если примерно помнишь — то нагуглить не проблема. Если догадываешься о существовании алгоритма — то нагуглить можно. Если вообще не догадываешься о существовании алгоритмов, то такого человека можно на собеседовании определить разными способами.
Почему большинство редакторов при этом намертво зависают, а оставшиеся 5% делают это 2-3 минуты?О каких редакторах речь? Только что проверил — и vim и emacs укладываются в пару секунд. Примерно столько же, сколько открытие такого файла занимает: всякие подсветки и прочее нужно же пересчитать…
P.S. Тут правда сказывается моё нежелание в принципе работать с редакторами, которые тормозят. Но я знаю, что я почти уникален, да: когда я как-то кинул в репу автосгенерённый файл на 5 мег — вой был слышен чуть не на луне, когда народ стал на меня баллоны катить, за то, что я им всё сломал.
Если кандидат не разбирается в односвязных списках, то он, как правило, не разбирается в структурах данных вообще.
Если кандидат не разбирается в структурах данных, то он, как правило, не умеет писать эффективные реализации алгоритмов на высокоуровневых языках программирования, где эти структуры данных уже реализованы.
И пишет потом в прод:
xs = list(...)
ys = list(...)
for y in ys:
if x in xs:
...и тому подобное.
Односвязные списки – отличный фильтр, с которого можно начать блок вопросов про структуры данных.
А что не так?
Поиск в списке – O(n). Для проверки принадлежности нужно использовать множество, дающее амортизированную O(1).
Да и да! Однажды убил полчаса на собеседовании на дискуссию, что для решения задачи необходим контекст. И если она формулируется как "написать оптимальное решение", то контекст просто необходим и без него нельзя говорить, что то же решение со списком не оптимально.
Потому что «Преждевременная оптимизация — корень всех зол» (с)
На самом деле, полная цитата звучит иначе
We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil…
Yet we should not pass up our opportunities in that critical 3%…
A 12% improvement, easily obtained, is never considered marginal
Получается совсем другой смысл, не так ли?
Эта вырваная из контекста фраза часто используется как оправдание для того чтобы пропустить этап обдумывания, и зафигачить линейный поиск по большому списку там, где можно было бы спокойно использовать HashMap.
А здесь я вас поддержу. Выбор и проектирование правильных алгоритмов и структур — это фактически архитектурный вопрос, а не предварительная оптимизация.
По конкретному случаю: Ну вот использовал здесь один разраб hashMap. Времени лишнего не потратил, но и на конечный результат не повлиял. Другой не задумался на решением или не знал другого варианта и использовал List. Результат — тот же. Но ведь время более квалифицированного разраба дороже?
И другое дело, если список _действительно_ большой и результат имеет значение.
Другой не задумался на решением или не знал другого варианта и использовал List.
… и через несколько лет, когда при масштабировании этот код внезапно отожрал всю память или начал тормозить на казалось бы обычных операциях, придется потратить еще больше времени дорогих специалистов на профилирование, поиск проблемы, отладку и переписывание с учетом регрессии.
Хотелось бы писать хорошо структурированный код с хорошей архитектурой и тестами. Но реальность такова, что бизнесу нужен результат. И нужно найти золотую середину между стоимостью, качеством и временем разработки.
Ну да, хэш-таблицы.
Тогда мы все умрем.
То все равно за O(1).
Если быть чуть более дотошным, то время работы O(hashTime).
Т.е. если у нас есть N строк с длиной L, хэш-таблица отработает за O(L). Но заметьте, что поиск в отсортированном массиве был бы O(L * log(N)), а поиск в неупорядоченном массиве был бы O(L * N).
Речь в комментарии на который я отвечал шла о том "какой алгоритм быстрее", а не о том сложность какого алгоритма быстрее растет при росте n.
"хэш-таблица отработает за O(L)"
Все равно за O(1).
Дочитайте мой комментарий до конца.
Из него вполне очевидно, что по ассимптотике хэш-таблица быстрее других методов, т.к. время работы других методов так же растет линейно с ростом длины строки.
Я повторю ещё раз.
Речь в комментарии на который я отвечал шла о том "какой алгоритм быстрее", а не о том сложность какого алгоритма быстрее растет при росте n.
А дальше попрошу сходить в любую книжку по алгоритмам и разобраться с понятием амортизированной сложности алгоритма (по пути можно заглянуть в матанализ и посмотреть, что такое предел по одной переменной) и а также алгоритмами хэширования строк.
Оригинальный комментарий:
А почему, кстати, О(1)? Уже придумали алгоритм, ищущий быстрее двоичного поиска?
Да, придумали. Хэш-таблица.
Вы привели контр-пример про строки (корректный, но являющийся скорее придиркой в данном контексте) — я на него ответил.
А если хэш-таблица не влезает в оперативку?
Это не влияет на ассимптотику.
А если таблицу надо часто перестраивать?
Это не влияет на ассимптотику.
А дальше попрошу сходить в любую книжку по алгоритмам и разобраться с понятием амортизированной сложности алгоритма
Я осознаю, что в случае хэш-таблицы это сложность в среднем, а в бин. поиске — в худшем случае. Но, как вы сказали, мы обсуждаем "какой алгоритм быстрее".
Так нормально? Вы меня не отсылайте в книжки, покажите где я по вашему неправ.
Я умею хэшировать строки и писать хэш-таблицы. И теорию тоже сдавал:) Так что давайте дискутировать предметно.
Давайте подробно, по порядку.
Что по вашему такое «асимптотика функции»?
Я осознаю, что в случае хэш-таблицы это сложность в среднем, а в бин. поиске — в худшем случае. Но, как вы сказали, мы обсуждаем «какой алгоритм быстрее».
Не совсем «в среднем», это предел от «среднего» при n -> бесконечность.
В вашем примере с хэшфункцией по строке со сложностью O(L) получается:
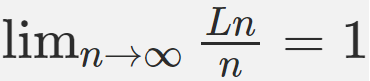
Это не говорит о том быстрее или медленнее работает хэш-таблица, это говорит о том, что при росте n хэш-таблица в общем случае не становится медленнее.
А, все, я понял о чем мы спорим.
Вы под "быстрее/медленнее" подразумеваете произваодительность в миллисекундах (измеряемую). А я подразумеваю сравнение вычислительной сложности.
Мое понимание ситуации взялось из оригинального комментария "А почему, кстати, О(1)? — тут речь шла явно именно про асимптотику.
Вы видимо зацепились за "Уже придумали алгоритм, ищущий быстрее двоичного поиска?"
Я же развернул этот вопрос так(из теории): найдется такое n0, что для любого N > n0 хэштэйбл работает быстрее двоичного поиска (в миллисекундах). При этом, из практики, находится это n0 довольно быстро:)
Вы под «быстрее/медленнее» подразумеваете производительность в миллисекундах (измеряемую).
Да, конечно, ту которую можно измерить, и которая реально влияет на пользовательский опыт.
Вы видимо зацепились за «Уже придумали алгоритм, ищущий быстрее двоичного поиска?»
Именно так.
Вообще, я хотел высказать идею, что принимать решение о выборе алгоритма только на основании его асимптотик (как часто просят на «неправильных» собеседованиях поклонники карго-культа и зубрежки) — неправильно.
Ок, тут согласен на все 100%.
Если есть априорное понимание того, что список объектов будет коротким нужно писать на списке. Хотя лучше написать реализацию ArraySet, чтобы каждый раз самому не писать:)
В случае же сомнений обычно стоит выбирать вариант с наилучшей асимптотикой (о выборе коллекций с адекватным трейд-оффом между ассимтотикой и константой за нас обычно заботятся разработчики коллекций. Вы врядли встретите упомянутое ниже дерево Ван Эмде Боаса, из-за его ужасной константы).
За 5 лет разработки игр я 1 раз видел в профайлере OrderedSet, который надо было заменить на массив чтобы стало быстрее. Ни разу я не видел в такой роли HashSet. И я видел с сотню раз линейный/бинарный поиск, который надо было заменить на HashSet.
От реализации правда зависит, количества элементов, их распределения. Может доходить и до логарифмической сложности.
меньше только если с ключами повезло и она не выродилась в список
а если не повезло, то выходит так ocert.org/advisories/ocert-2011-003.html
По ссылке описана атака на отказ в обслуживании через подбор и засылку данных, которые заранее известной хешфункцией дают коллизии, в связи с чем поиск вырождается в линейный для разрешения коллизий цепочками, логарифмический для цепочек лежащих в дереве поиска, линейный для хеширования с открытой адресацией с линейным/квадратичным пробированием и хз для двойного хеширования.
Т.е. не будет разницы между поиском по массиву по связному списку и по хештаблице с любым типом разрешения коллизий.
если вашей структурой может пользоваться только секюрити эксперт после оборачивания ее несколькими рядами костылей
Какой структурой, хештаблицей?
А чем еще пользоваться-то, сбалансированными деревьями поиска? Ну, они при такой атаке покажут амортизированную логарифмическую сложность поиска, но также будут неплохо сдыхать на перебалансировке.
Ну, и вне данной атаки производительность будет хуже.
Хэш-таблицы имеют хорошую амортизированную асимптотику, но это совсем не значит, что в общем случае они ищут быстрее или медленнее.
Как выбор значения «по ключу» может быть нe быстрее поиска по списку? Особенно учитывая что про сам список нам никакие особые условия не даны.
Последовательный перебор хорошо локализованного списка влезшего в кэш процессора легко может оказаться быстрее поиска в размазанной по куче или вообще выгруженной в своп хэш-таблице.
Сравните:
- Вы держите книгу в руках и ищете страницу 100 последовательно переворачивая страницы.
- Вы пишете письмо другу в другой город с просьбой прислать страницу 100 и неделю ждёте ответа с одной страницей.
Асимптотики алгоритмов знать безусловно надо, но они нужны не столько для сравнения скорости алгоритмов сколько для сравнения их способности к масштабированию. А оценить именно скорость без учёта окружения и особенностей реализации невозможно.
Скорее всего, среднестатистическому программисту на интерпретируемых языках это вообще никогда не понадобится.
Например, зачем мне на python или javascript знать как организовывать связанные списки(за исключением саморазвития и расширения кругозора)?
Например, для того, чтобы делать осознанный выбор, в каком случае для хранения данных использовать список, в каком — хеш-таблицу, а в каком массив, чтобы ваше приложение из пары форм нормально работало, а не еле ворочалось на топовой конфигурации, как некоторые ухитряются делать.
Но опять же. Ты получаешь то что контролируешь. Хочешь чтобы кандидат знал структуры данных, спрашивай его про структуры данных. Если ты спрашиваешь у кандидата решение задачи про «мышей и яд» то он это ответит, но не факт что он будет знать структуры данных
использовать список, в каком — хеш-таблицу, а в каком массив
Не будем забывать что в js "настоящего" связного списка нет, он будет делатся через объект(который хеш таблица).
Также не будем забывать что на фронтенде объем данных редко превышает 200 единиц, почти никогда 2000.
А на таких объемах условныйn log n против n выиграет всего-то навсего в 10 раз. И не исключенно что упущенные константы будут 1 * n * log n против 20 * n
А на таких объемах условныйn log n против n выиграет всего-то навсего в 10 раз. И не исключенно что упущенные константы будут 20 n log n против 1 * n
Но ведь лучше это явно понимать.
Лучше находишь бутылочное горлышко и учится писать качественный, а не производительный код. Лучшее враг хорошего, а преждевременная оптимизация зло.
На фронтенде производительность очень редко будет упиратся в структуры данных или алгоритмы. Пример простой и распространненой задача на фронтенде это получить данные от бекенда -> отобразить эти данные. ё
А сложные задачи возникают так редко что их может тех лид / сто помочь решить / отловить на ревью
Удачи вам, без структур данных и алгоритмов )
И вы уверены, что узкое место тут именно данные, а не рендеринг?
Про структуры данных вообще никто не вспоминал.
Хорошие структуры данных однозначно полезны и на фронте, но совсем даже не для оптимизации (я за 10+ лет фронтэндерства местами на довольно больших объемах данных про big O вспоминал примерно один раз, да и то в целях «а не стоит ли этот момент отдать на бэк?»), а для читаемости кода.
Вы рассказываете, как это все надо было сделать правильно, и это все конечно так. А я — как это было первоначально сделано по разным причинам (начиная от полного игнорирования пункта про саначала анализ требований, а потом их выполнение, заканчивая чуток загадочным подходом менеджмента к процессам).
Плохо сделанную вещь надо делать нормально — и это начинается не с замен структур данных.
И еще раз, «правильно» — понятие сильно относительное.
Для Вас, правильно — это корректно работающее приложение с логичной структурой.
Для менеджера (да, есть исключения, но в больших конторах эти исключения редко задерживаются), правильно — это проект на котором задействовано максимально большое количество людей на максимально длительный срок.
И возвращаясь к изначальной теме — угадайте, кто влияет на методики подбора кандидатов больше? Вы, или менеджер?
Если у нас «проект, на котором задействовано максимально большое количество людей на максимально длительный срок» — то структуры данных вам точно не помогут. Просто получайте ваши сотни обновлений данных в секунду и как-нибудь показывайте их на фронте. Желательно силами большой скрам-команды со всеми песнями, плясками, эпиками, доской, и всем таким. Желательно долго. Начните с тормозного варианта, а потом в течении десятка лет оптимизируйте по паре процентов в месяц. Все будут довольны (особенно менеджер). Ну а уж если вам таки хорошие структуры данных в итоге будут нужны, то за этот десяток лет будет время самообразоваться.
А зачем вам фронтенд, всё равно человек на такое смотреть не сможет чисто физически, а роботу через API какое всяко удобнее…
Но тут у нас имеют место быть ньюансы работы эффектывных аутсорсинговых компаний. Которым надо работу работать, и как можно дольше, особенно если можно прикрытся требованиями от заказчика. Так что вышенаписанное год пилили, пока все не поняли, что это будет невозможно использовать на практике…
Вот вам «всё равно человек на такое смотреть не сможет чисто физически» это очевидно. И мне очевидно.
Это очевидно любому человеку, ну обычный здравый смысл.
надо работу работать, и как можно дольше
Это называется «попил бабла», к алгоритмам и структурам данных отношения не имеет.
И на самом деле большинству достаточно по профилировать свои программы пару раз. чтобы понять какие решения работают медленно а какие быстро и в следующий раз они уже так делать не будут. Не будет больше решений в стиле «а давайте создадим 10 млн экземпляров классов на python» или «давайте сделаем цикл в цикле для поиска уникальных элементов связанного списка на javascript»
На фронтенде производительность очень редко будет упиратся в структуры данных или алгоритмы.Зайдите на популярный Patreon (хотя бы сюда), отмотайте ленту, скажем, на пару лет назад… а потом возвращайтесь сюда и мы сможем продолжить дискуссию.
Лучше находишь бутылочное горлышко и учится писать качественный, а не производительный код.Лучше — не создавать «бутылочных голышек» в количестве 100500 штук.
Да, это плохо влияет на KPI: вы не сможете рапортовать о том, что ускорили Frontend на 50% каждый год 10 лет подряд… но зато то, что вы сотворили — не будет вызывать у пользователя ненависти.
P.S. И да, тот факт, что Patreon — при всей его жутчайшей убогости — весьма популярен… говорит не о том, что на фронте не нужны люди со знанием алгоритмов. А о том, что вообще качество программистов для фронта — дело вообще десятое. Маркетинг и дизайнеры — важнее. Нет никакой дихотомии между написанием «качественного» и «производительного» кода. Возможно при выжимании последних 2-3-5% производительности… но никак не при добавлении трёх кнопочек на веб-страницу. Вы либо пишите качественный и производительный код, либо… дешёвый. И то и другое бывает нужно — но только не надо рассказывать сказок про качественный, но не производительный код. Не на фронте.
Зайдите на популярный Patreon (хотя бы сюда), отмотайте ленту, скажем, на пару лет назад… а потом возвращайтесь сюда и мы сможем продолжить дискуссию.
Это всего лишь потому, что сценарий достаточно долгого проматывания модной бесконечно скроллящейся ленты в подавляющем большинстве случаев использования этих самых модных лент никого не интересует.
Просто потому, что так пойдет делать ничтожно малый процент пользователей, на интересы которых дешевле наплевать, чем что-то делать.
И структуры данных тут опять же не при чём, кстати.
Это всего лишь потому, что сценарий достаточно долгого проматывания модной бесконечно скроллящейся ленты в подавляющем большинстве случаев использования этих самых модных лент никого не интересует.А с чего вы так решили, извините? И как вообще добраться до первый страниц комикса, про который вы только что узнали?
Там сейчас вообще забавная вещь происходит: творчество некоторых авторов увидеть целиков вообще нельзя, в принципе, потому что при попытки домотать туда примерно через пару часов сайт просит обновить куку… и забывает про всё, что вы успели намотать.
И структуры данных тут опять же не при чём, кстати.Что значит «не при чём»? Тот факт, что каждое нажатие на «Load more» отрабатывает дольше, чем предыдущее (до такой степени, что Firefox начинает предлагать «убить вкладку») — просто орёт про то, что кто-то где-то куда-то вкрутил, в очередной раз, алгоритм маляра Шлемеля.
Просто потому, что так пойдет делать ничтожно малый процент пользователей, на интересы которых дешевле наплевать, чем что-то делать.Вот только не надо рассказывать мне — что это был сознательный выбор. Просто при написании этого кода учитывалась что угодно, кроме, собственно, эффективности и реального удобства пользования.
А с чего вы так решили, извините?
Предлагайте свои варианты. Я не настаиваю.
И как вообще добраться до первый страниц комикса, про который вы только что узнали?
Никак? Вы всерьез что ли думаете, что я не в курсе типичных проблем убогой реализации бесконечной ленты, и что я лично с этим не сталкивался? Я в курсе и сталкивался. И жаловался на это. И в конце концов плюнул и получил нужную мне инфу через прямой запрос к бекэнду.
В Спортлото напишите.
Тот факт, что каждое нажатие на «Load more» отрабатывает дольше, чем предыдущее (до такой степени, что Firefox начинает предлагать «убить вкладку») — просто орёт про то, что кто-то где-то куда-то вкрутил, в очередной раз, алгоритм маляра Шлемеля.
А, ну у кого-то очень кривые руки. Как будто что-то новое. Учитывая, что на патреоне с бэком вроде бы всё в порядке, насколько я могу видеть, а тормоза проявлятся на самом onclick, еще даже до того момента, как будут сделаны запросы на бэк — это один из случаев криворукого построения фронтэнда. Сказать, что там дело именно в структурах данных — я бы очень сильно поостерегся. Может быть именно и в них, но проблемы там явно не от структур данных начались, а от непонимания того, что происходит со страницей, когда на ней пара тысяч постов.
Вот только не надо рассказывать мне — что это был сознательный выбор.
Нет, сознательный выбор — это ничего не делать, когда неизбежно придут те 2.5 человека, которым это надо, и начнут жаловаться. И это опять же только лишь гипотеза, основанная на наблюдении. С радостью её отброшу, как только где-нибудь кто-то починит свою убогую ленту по жалобам пользователей.
Может быть именно и в них, но проблемы там явно не от структур данных начались, а от непонимания того, что происходит со страницей, когда на ней пара тысяч постов.Погодите — а как вы поймёте «что происходит со страницей, когда в ней пара тысяч постов» если вы про алгоритмы и структуры данных не в курсе?
Вы вообще — на каком языке будете это своё понимание описывать? Я вот, извините, не могу просто себе представить человека, который понимает «что происходит со страницей, когда на ней пара тысяч постов» — но при этом не умеет «в алгоритмы и структуры данных».
Ну просто потому что у человека же даже словаря не будет в голове со словами, которые нужны, чтобы это вот всё описать!
Сказать, что там дело именно в структурах данных — я бы очень сильно поостерегся.В алгоритмах и стурктурах данных. 100%. Задача — добавить на страницу несколько картинок ну никак не должна требовать триллионов операций (именно столько CPU исполняет за то время, пока отрабатывает onclick). Никак. Она может это делать только когда кто-то что-то сделал не думаю о сложности от слова «совсем».
На фронтенде производительность очень редко будет упиратся в структуры данных или алгоритмы.
— вот с ним и спорьте (но едва ли в этом много пользы, потому что написанное им просто бессмысленно; производительность всегда будет упираться в алгоритмы).
Скачать его с ресурса, на котором он выложен с нормальной постраничной разбивкой :-)Этот ресурс, конечно, хорош — но там много всякого премиум-контента недоступно. Только сам комикс.
acomics.ru/~LwHG например
Да и вопрос не в том, как это в принципе сделать (можно, в конце-концов, понять какие запросы фронт Patreon'а шлёт на сервере), а в качестве кода. Дерьмо это, а не код — и мне для того, чтобы сделать это высказывание совершенно даже не нужно на него смотреть.
А с чего вы так решили, извините? И как вообще добраться до первый страниц комикса, про который вы только что узнали?
Неужели… нужно включить фильтрацию по месяцу? Или сортировку от старых к новым?
Зайдите на популярный Patreon (хотя бы сюда), отмотайте ленту, скажем, на пару лет назад… а потом возвращайтесь сюда и мы сможем продолжить дискуссию.
Ну да, ну пролистал, ну рендер начинает дохнуть от такого количество нод (один только значок замочка — 4 вложенных друг в друга дива, что вообще-то делать нельзя).
Это всё конечно классно, но я не понимаю как тут могут помочь алгоритмы? Тут может помочь только нормальная вёрстка, а не использование react styled components на каждом новом посте.
Решение, которое тут сработает — виртуальные списки, которые уменьшают количество нод для отрисовки, и в них тоже никакими алгоритмами не пахнет, ну просто потому что не пахнет, это простейшая штука, которая давно сделана по несколько раз в разных библиотеках.
Это всё конечно классно, но я не понимаю как тут могут помочь алгоритмы? Тут может помочь только нормальная вёрстка, а не использование react styled components на каждом новом посте.Понимаете какая история. Отмотав куда-нибудь достаточно далеко (насколько дадут, к началу отмотать не получится, как я уже сказал)… можно это вот всё — со всеми четырёхвложенными Div'ами и прочим — записать в файл. А потом — прочитать его. И он откроется за пару секунд.
Что это значит? Что вся эта «ненормальная» вёрстка браузером пережёвывается нормально. Да, она ужасна. Да, у людей создавших это — руки из жопы растут. Но тормоза — не оттуда. Тормоза — из применений технологий, «цену» которым вы не знаете.
Всё что там происходит с DOM'ом — при некотором желании я могу воспроизвести на технологиях нулевых, а если немного напрячься — то и на технологиях прошлого века. И оно не будет тормозить. Это несложно. Ну вот просто тупо сделать всё на строках, а потому один раз innerHTML присвоить.
Сложно — сделать это, применяя хайпхайп современного фронтэнда. Но, чёрт побери, если вам это технологии мешают делать вещи, которые люди прекрасно делали и без них 20 лет назад — то чего вообще, вот это вот знание, которое нам предлагают оценивать вместо «разворачивания списков» — стоит?
Но, чёрт побери, если вам это технологии мешают делать вещи, которые люди прекрасно делали и без них 20 лет назад — то чего вообще, вот это вот знание, которое нам предлагают оценивать вместо «разворачивания списков» — стоит?
Я где-то на хабре давно писал, что заказчику важно не насколько качественно сделано, а насколько быстро и дёшево. Во фронте это везде. Потому что рынок такой.
Цену технологий мы знаем, прекрасно знаем. Вопрос в том, что нам не платят за правильное использование, платят за быстрое и дешёвое использование.
Тем кому важно сделать нормально, те сами сядут и сделают, а те кому нужно деньги быстро закалачивать — те будут использовать быстрые и дешёвые технологии.
Для примера "хорошо сделанного" возьмём coub.com, люди как к бизнесу так и к коду и технологиям относятся. Хотят сделать хорошо — делают. Но только у них весь бизнес — одна эта лента и от её реализации напрямую зависит количество денег, которые получает компания. В медиуме статейки являются источником бабла. Поэтому они сделаны оптимально и быстро. Там может быть сколько угодно картинок и сколько угодно анимаций, всё сделано хорошо, потому что люди знали, что делают на совесть.
В патреоне главное — переводы, на посты всем глубочайше срать, а вот лендинг, как ему и положено, грузится быстро и не зависает. В вк теперь главное — музыка, реклама и хайп, поэтому сообщения начинают безбожно лагать, официальные приложения безбожно жрать, а реклама безбожно появляться везде.
Весь фронтэнд сейчас работает на хайпе, потому что за него платят. Если вам будут платить если вы во время использования своих алгоритмов будете хиты на гитаре бренчать, то вы будете работать с гитарой под мышкой, вот и мы, работаем тем, за что платят.
Цену технологий мы знаем, прекрасно знаем. Вопрос в том, что нам не платят за правильное использование, платят за быстрое и дешёвое использование.Это всё понятно.
Весь фронтэнд сейчас работает на хайпе, потому что за него платят. Если вам будут платить если вы во время использования своих алгоритмов будете хиты на гитаре бренчать, то вы будете работать с гитарой под мышкой, вот и мы, работаем тем, за что платят.Тогда откуда обсуждаемые статьи? Если тот, кто вам платит, хочет, чтобы вы знали про работу со связанными списками — что вам мешает научиться с ними работать?
Почему довод «любой каприз за ваши деньги» работает в сторону объяснения «почему порождённый вами код — такое дерьмо», но не работает в сторону «хотите, чтобы я знал про „зайца и черепаху“ — выучу»?
но не работает в сторону «хотите, чтобы я знал про „зайца и черепаху“ — выучу»?
Я не говорил, что в эту сторону не работает, я как раз придерживаюсь именно этой позиции. Если надо будет вакансия со знанием алгоритмов, я конечно же поднатаскаюсь немного, а на работе уже буду применять выученное.
Статья то о другом, о том, что знание алгоритмов теперь "жизненно необходимо" даже тем, кто алгоритмы использовать никогда не будет. А точнее на собеседованиях задают задания, которые проверяют навыки, не требующиеся на вакансии на самом деле.
Про фронтэнд я начал потому, что вы привели пример плохого продукта из фронтэнда, который как раз сделан для закалачивания и желательно побыстрее и на аутсорсе. Если бы вы брали пример из, например, плюсов, то я бы не смог вступить в дискуссию)
Про фронтэнд я начал потому,Про фронтенд начали не вы, а совсем даже knotri вот тут:
Лучше находишь бутылочное горлышко и учится писать качественный, а не производительный код. Лучшее враг хорошего, а преждевременная оптимизация зло.Я просто показал, что это, мягко говоря, неправда. Свинья везде грязь найдёт — и незнание алгоритмов может сделать ваш фронтенд полным дерьмом. Нельзя «писать качественный, а не производительный код». Это не дихотомия. Качественный код — он же и производительный тоже. Если только вы не пытаетесь выжать «грязными трюками» уж последние 5-10% производительности.
На фронтенде производительность очень редко будет упиратся в структуры данных или алгоритмы.
вы привели пример плохого продукта из фронтэнда, который как раз сделан для закалачиванияА с чего вы так решили? «Заколачивать» они как раз вполне себе заколачивали и три и пять лет назад. У них был вполне себе шустрый сайт с реально работавшей бесконечной лентой (но без модных хайповых технологий… jQuery был, конечно, куда без него).
и желательно побыстрее и на аутсорсе.А вот это уже — классическая история: пару лет назад у них случился редизайн. Скорее всего у них появились деньги и они смогли нанять «приличную дизайн-студию». Которая, разумеется, выдала им кусок дерьма с наполнителем из дерьма, приправленный сверху дерьмом же.
В любом случае вопрос «нужен нам качественный, быстрый код» или «нам нужен дешёвый код… и побольше-побольше-побольше» — это уже другой вопрос.
Изначальный тезис был: на фронте знания алгоритмов и структур данных просто не нужны, а качество кода, магически — в чём-то другом (дальше можно произносить много разных умных слов). На самом деле — знание алгоритмов и структур данных на фронте тоже нужны… если вам нужен качественный код, конечно. Если он не нужен (а так бывает часто, на самом деле, с этим я согласен) — ну тут всё понятно.
А точнее на собеседованиях задают задания, которые проверяют навыки, не требующиеся на вакансии на самом деле.Ну тут я отчасти согласен. Сейчас время такое, дурное. Платят не за качественно сделанную работу, а за высоко поднятый хайп.
В позднем СССР тоже так было.
Свинья везде грязь найдёт — и незнание алгоритмов может сделать ваш фронтенд полным дерьмом.
Так уже) У нас есть одна большая проблема со структурами, а точнее с одним типом структур — деревом. Оно медленное и неповоротливое. Поэтому мы и придумываем разные хаки, чтобы побороть медленную плюсовую реализацию этого самого дерева.
У нас есть одна большая проблема со структурами, а точнее с одним типом структур — деревом. Оно медленное и неповоротливое.Ну нет же! Оно, как раз, работает с такой скоростью, что человек не успевает заметить как его тысячу раз поменяют. То есть — да, оно дико медленное и неповоротливое, если сравнивать его с каким-нибудь WinAPI прошлого века, но дело не в нём.
Поэтому мы и придумываем разные хаки, чтобы побороть медленную плюсовую реализацию этого самого дерева.Вашими бы устами… Увы, но эти хаки — они о другом: когда наваляли такой большой ком дерьма, что даже эффективная реализация DOM-дерева перестаёт с ним справняться — можно попроовать засунуть его под пресс и постараться сделать блин потоньше.
Если вы вместо двух-трёх операций с DOM-деревом выполняете миллион — то да, они-таки начинает тормозить «и с этим приходится что-то делать».
Почему-то, правда, «наивное детское решение» — «не выполнять миллион операций там, где нужно десять» в голову не приходит… а да, это ж «преждевременная оптимизация», на неё у нас табу, как же я мог забыть…
del
Я с вами в корне не согласен в том, что dom реализован эффективно. Он реализован по стандарту, а стандарт далеко не эффективный и никогда к этому не стремился.
*прыгаем по веткам*
Меня совершенно удивляет ваша святая вера в эффективность element.innerHTML += stringFromServer. Во-первых, это выдаёт вашу некомпитентность (ибо в js как раз для пропускания этапа парсинга html придумали DocumentFragment, который как бы перекладывает на программиста то, что вслепую делает плюсовая "эффективная" реализация), во-вторых, stringFromServer — один из самых типичных проколов, это прямо зияющий XSS.
А ещё меня уже начинает немного напрягать, что проблему большого количества списков вы причисляете к проблемам, которые "возникают из-за не знания алгоритмов". Это проблема тонкости реализации, и наша задача, как фронтэндеров, знать не алгоритмы, а решения проблем, которые появляются в нашей области. Если будут проблемы, которые решаются алгоритмами — значит они решаются алгоритмами, если решаются всеми известной либой — значит либой. Если руками — значит руками.
Алгоритмы — не серебряная пуля, так же как и библиотеки для виртуализации списков. Просто есть специфика области. И статья как раз про то, что "связные списки" начинают пихать туда, где нет такой специфики, нет задачи, которая так решается.
from del
Меня совершенно удивляет ваша святая вера в эффективность element.innerHTML += stringFromServer.Это не вера. Это знание.ибо в js как раз для пропускания этапа парсинга html придумали DocumentFragment, который как бы перекладывает на программиста то, что вслепую делает плюсовая «эффективная» реализацияВы хотя бы по ссылке-то сходить пробовали? Вот прям на той странице, куда вы ссылаетесь: Оптимизация, о которой здесь идёт речь, важна в первую очередь для старых браузеров, включая IE9-. В современных браузерах эффект от нее, как правило, небольшой, а иногда может быть и отрицательным.
Кто там говорил про некомпетентность?
во-вторых, stringFromServer — один из самых типичных проколов, это прямо зияющий XSS.Вы уж меня извините, но если вы сами со своего сервера выдаёте данные, которым не доверяете, то а каких XSS может идти речь? Да, конечно, чтобы XSS не было — нужно, чтобы сервер правильно производил обработку. Но вот беда: наматывание слоёв абстракции эту необходимость совершенно не уничтожает. Наоборот — чем больше вы добавляете «наворотов», тем больше шанс, что вы пропустите какую-нибудь банальность на стыке ваших 100500 плагинов.
А ещё меня уже начинает немного напрягать, что проблему большого количества списков вы причисляете к проблемам, которые «возникают из-за не знания алгоритмов».«Алгоритмов и структур данных» да. Известная книжка не зря именно так называется. В данном случае второе — важнее, чем первое.
Это проблема тонкости реализацииНет, чёрт побери. Это не «тонкости реализации». Вы тут почти правильно всё сказали:
Он реализован по стандарту, а стандарт далеко не эффективный и никогда к этому не стремился.DOM и CSS — это редкостное дерьмо. Иногда вообще возникает ощущение, что они задуманы так, чтобы всё происходило максимально медленно и с максимальными затратами ресурсов. Браузеры очень стараются всё сделать быстро, но поскольку ошибка там в ДНК, то их возможности ограничены.
Тем не менее, если в ответ на действия пользователя вы производите одну манипуляцию с DOM'ом (или даже десять, но не миллион) — современные браузеры всё будут делать достаточно быстро. Ваша задача — придумать, как сделать так, чтобы любые действия пользователя не требовали множества обращений к DOM'у. Если учесть, что данных там у вас на страничке будет несколько мегабайт — от силы (даже если вы откроете тысячи картинок в «ленте» за несколько лет), то скорости JS должно более, чем хватать. А дальше — да, innerHTML и скорости движка тоже должно более, чем хватать.
Если будут проблемы, которые решаются алгоритмами — значит они решаются алгоритмами, если решаются всеми известной либой — значит либой. Если руками — значит руками.Ещё раз: не бывает задач, которые не решаются правильными алгоритмами и структурами данных, но решаются «известной либой» или «руками». Потому что всё, что вы можете сделать «известной либой» или «руками» — это реализовать ту или иную структуру данных или алгоритм.
Если вы «забьёте» на всё специфику отрасли и всё сделаете на основе базовых структур — то, всего лишь, потратите время на изобретение велосипеда. Что плохо, но не смертельно. Будет несколько дороже, чем в идеальном случае — но приемлемо.
Если же вы всё делаете «SOLIDно», «идеоматично» и так далее (я уверен, что авторы этого самого ужаса на Patreon'е приведут ещё 100500 классных buzzword'ов), но вы не понимаете какие структуры данных за всем этим стоят и какие алгоритмы задействованы — то вам под силу «спалить» любой бюджет, но в результате — у вас всё равно будет глючное поделие, которое тормозит и жрёт ресурсы как не в себя.
И статья как раз про то, что «связные списки» начинают пихать туда, где нет такой специфики, нет задачи, которая так решается.Почему, чёрт побери, вы в этом так уверены? Вот где на том же самом Patreon'е что-то принципиально отличное от того, что было в GMail 2004го года выпуска? Не в смысле вёрстки (там, как раз, есть вещи, которые технологиями прошлого века не решить… мне так лично кажется, что и не очень надо, ну да ладно — я не верстальщик, туда лезть не хочу и не буду), а вот именно в смысле функциональности? Какая-такая «специфика» там выросла и почему, если там «нет задачи, которая так решается» — то результат столь убог?
Кто там говорил про некомпетентность?
Прошу прощения конечно, но я привык верить бенчмаркам (DIY), а не какому-то Кантору)
Вы уж меня извините, но если вы сами со своего сервера выдаёте данные, которым не доверяете
Между мной и сервером ещё целая цепь "людей", которым я не могу доверять:
- Браузер
- ОС клиента
- Хакер на вайфае
- Провайдер клиента
- Провайдер оборудования для сервера
- ОС сервера и прокси провайдера железяки
Они могут менять данные как захотят, и https, к сожалению, не спасает. Так что нет, я не доверяю никому, ни юзеру, ни браузеру, ни серверу — всё обманывают, все хотят меня сломать.
Тем не менее, если в ответ на действия пользователя вы производите одну манипуляцию с DOM'ом
Бизнесу нужно, чтобы при нажатии на кнопку "купить" фоточка товара "летела в корзинку", и везде менялись циферки и всё это шустро и одновременно и с анимацией.
Это 1 изменение дома — это просто идеальный случай, которых уже не существует. Нужно и анимацию и пересчёт всего и сразу.
Потому что всё, что вы можете сделать «известной либой» или «руками» — это реализовать ту или иную структуру данных или алгоритм.
Так зачем, если в либе уже реализовано, а руки не отсохнут пару строчек написать? Почему вы эти алгоритмы превозносите в абсолют и приравниваете к сакральным знаниям?
то результат столь убог?
В РФ вроде живём, на вопрос "почему результат столь убог" принято отвечать "ну он хотя бы есть")
А если серьёзно, то результат убог потому, что деньги дали, а когда очухались, что подсовывают говно, обратно деньги уже не вернуть. Ну и выкатили то, что получилось, ибо дешевле выкатить говно чем проходить ещё через 20 таких же компаний и в каждой оставлять кругленькую сумму за один и тот же кусок творчества.
Кто там говорил про некомпетентность?Бенчмарки показывают то, что и должны были показывать:
Прошу прощения конечно, но я привык верить бенчмаркам (DIY), а не какому-то Кантору)
appendChild работает куда быстрее и innerHTML и DocumentFragment, однако разница не критична. Да, когда вы говорим о том, что операция, которая должна занимать доли секунды, на самом деле исполняется за минуты трёхкраная разница не критична.Вот когда то, что должно исполняться за доли секунды — будет-таки исполняться за доли секунды… можно уже и об оптимизациях и бенчмарках начинать думать.
Они могут менять данные как захотят, и https, к сожалению, не спасает. Так что нет, я не доверяю никому, ни юзеру, ни браузеру, ни серверу — всё обманывают, все хотят меня сломать.И чего вы этим добиваетесь? Того, что всё получается такое феншуйно-хайповое? Если вот эти вот «все» могут что-то менять по дороге от сервера к клиенту — то они запросто могут поменять и первоначально скачиваемую страницу. И ваша игра проиграна. Если же не могут — то они и в дополнительный скачанный фрагмент ничего не смогут добавить.
Безопасность не достигается бессмысленным наворачиванием 100500 уровней защит неизвестно от чего. Вначале вы должны понимать — от какой конкретно атаки вы защищаетесь, потом — можно обсуждать — как именно нужно защищаться.
Вот где-где, а в вопросах безопасности — карго-культ точно не нужен.
Бизнесу нужно, чтобы при нажатии на кнопку «купить» фоточка товара «летела в корзинку», и везде менялись циферки и всё это шустро и одновременно и с анимацией.Расскажите где конкретно на Pantreon'е фоточки «летают в корзину». Потом — можно будет уже и обдумать как конкретно их туда отправить.
Потому что про «шустро и одновременно с анимацией» — возможно продавцы того ужаса, что мы там наблюдаем, кому-то в уши и лили. Но на практике — никакого «шустро» там нет. Нигде.
Это 1 изменение дома — это просто идеальный случай, которых уже не существует.Извините — но я вам дал вполне конкретный пример. Вот найдите там анимацию (и да — она там такие есть, хотя в глаза бросаются только бесконечно крутящиеся круги, которых, как раз, скорее хорошо, чтобы не было бы) и подумайте — нужно ли ради неё грузить шесть мегабайт JavaScript'а?
Нужно и анимацию и пересчёт всего и сразу.Ну да, конечно. А иметь возможность всем этим пользоваться — не нужно, конечно.
Так зачем, если в либе уже реализовано, а руки не отсохнут пару строчек написать?А шесть мегабайт дерьма куда при этом исчезнут?
Почему вы эти алгоритмы превозносите в абсолют и приравниваете к сакральным знаниям?Это не «сакральные» знания. Не необходимые знания. Если вы знаете алгоритмы и структуры данных, но не знаете «специфики фронтэнда» — то вы поиспользуете «устаревший» innertHTML (который да, действительно работает вдвое-втрое медленнее чем
appendChild), но вы с лёгкость скомпенсируете это тем, что ваш код будет в принципе исполнять раз в десять меньше работы.Хотя код будет писаться долго, да.
Если вы знаете алгоритмы и структуры данных, а также ещё и «специфику»… ну это ваще класс: вы сможете всё делать быстро и хорошо.
Если вы знаете только «специфику» — то вы обречены порождать исключительно тормозное и жрущее ресурсы, как не в себя, дерьмо… хотя кому-то, может быть, этого и будет достаточно…
А если серьёзно, то результат убог потому, что деньги дали, а когда очухались, что подсовывают говно, обратно деньги уже не вернуть. Ну и выкатили то, что получилось, ибо дешевле выкатить говно чем проходить ещё через 20 таких же компаний и в каждой оставлять кругленькую сумму за один и тот же кусок творчества.Ну вот если вы устраиваетесь в компанию, которая специлизируется на впаривании подобных «продуктов» — тогда вам и будет достаточно только «специфики». А списки тогда разворачивать действительно не нужно.
Бенчмарки показывают то, что и должны были показывать: appendChild работает куда быстрее и innerHTML и DocumentFragment
Вы очень странно читаете результаты этого бенчмарка, давайте я прочитаю их за вас правильно:
- DocumentFragment 49.6 ops/sec
- appendChild 36.3 ops/sec
- innerHTML 21.1 ops/sec
(more = better)
Того, что всё получается такое феншуйно-хайповое?
Причём тут хайп? Я просто сказал, что серверу доверять нельзя ни в коем случае. Чтобы потом не оказываться в ситуации, когда есть очевидный XSS, а я переложил всю ответственность на бек, а он переложил на меня. Так не делается. Если есть возможность защитить от опасности прямо сейчас, то делать это надо прямо сейчас и не полагаться на других, потому что кто-то в цепи обязательно положится на другого и это всё выльется в огромные проблемы.
Расскажите где конкретно на Pantreon'е фоточки «летают в корзину».
Я вам уже давно привёл примеры нормально реализованных лент, вы продолжаете пинать лежачий патреон, как будто это единственный и самый яркий представитель всего фронтэнда. Это далеко не показатель. Я могу вам привести в пример кучу других сервисов, которые сделаны на тех же технологиях, что и патреон, и работать они будут быстрее него, просто потому, что в них вложили больше денег и времени.
Извините — но я вам дал вполне конкретный пример.
Давайте лучше поступим иначе, вместо того чтобы обсуждать очевидное говно вы покажите пример, который сделан "на технологиях прошлого века" и даёт точно такой же функционал, при этом будет использовать только ваши алгоритмы и обычный innerHTML. Я таких примеров не знаю, потому что все, кому надо было, уже давно переписали на более быстрое решение, более поддерживаемое и в принципе более соответствующее реалиям, чем ваш гепотетический проект, который сделан профессором информатики на одних только алгоритмах.
А иметь возможность всем этим пользоваться — не нужно, конечно.
Я вам открою большущую тайну, но примерно 40% этих 6 метров js являются полифилами, которые отвечают за то, чтобы этим сайтом могли пользоваться все пользователи одинаково. Медленно и неэффективно — ну и ладно, зато люди с маком будут пользоваться патреоном и будут видеть те же самые лагающие анимации, но они их хотя бы будут видеть. А если убрать эти полифилы, то резко пропадёт целый пласт пользователей. Это так, немного жизни из фронтэнда.
Ну вот если вы устраиваетесь в компанию
Я устраиваюсь туда, где платят. А аутсорсинговые компании на то и нацелены, чтобы бизнес не тратил деньги на легион прогеров, если им нужен только один единственный сайт или одна единственная CMS.
Зайдите на популярный Patreon (хотя бы сюда), отмотайте ленту, скажем, на пару лет назад…
Отмотал на пару недель, открыл девтулз и увидел там, что ренедерятся все элементы, а не те которые отображаются(нет виртуального скроллинга)
Как эту проблему решит знание алгоритомов? Это проблема браузера и знания его api/проблем
Как эту проблему решит знание алгоритомов?
Вообще-то это всё — самые что ни на есть алгоритмы. Другое дело, что это куда более глубокая тема, чем «просто возьми хэш-таблицу».
Отмотал на пару недель, открыл девтулз и увидел там, что ренедерятся все элементы, а не те которые отображаются(нет виртуального скроллинга)А почему это проблема? Современные браузеры умеют «дропать» из памяти картинки, которые находятся не во viewport'е, умеют подгружать их «правильно», если они уходят из него, но близко к нему и так далее. Времена MS IE 6 прошли.
Проведите эксперимент: сделайте страницу с десятью тысячами картинок (вот просто картинок, без CSS и прочего), откройте её и попробуйте пролистать. Возможно для вас это будет откровением и удивлением, но её можно будет прекрасно просматривать в то время, как ваши десять тысяч картинок будут «медленно и печально» грузиться через GPRS (по крайней мере в Chrome). Firefox сейчас хуже такие вещи обрабатывает — но только вот именно загрузку страницы в которой десять тысяч картинок с самого начала присутствуют… если они туда добавляются постепенно — то и Firefox отлично всё отрабатывает.
При этом десять тысяч картинок — это больше, чем в ленте почти у всех авторов там.
Как эту проблему решит знание алгоритомов? Это проблема браузера и знания его api/проблемНет — это проблема именно знания алгоритмов. Если вы эту страницу реализуете с использованием технологий прошлого века (вот совсем прошлого века, без всяких кавычек), но, при этом, задумываясь о качестве результата — то всё будет «летать» (хотя как раз если скачать браузер прошлого века и попробовать её там открыть… эффекто может оказаться несколько другим).
А вот если применять хайпхайп технологии и не думать об этом… получите то, что получите.
P.S. И да: я не против виртуального скроллинга и вообще всячески за поддержку старых браузеров. Но это уже следующий этап! Сделайте чтобы оно, блин, не тормозило хотя бы в новых! Не можете? Ну и нечего тогда утверждать, что на «на фронтенде производительность очень редко будет упиратся в структуры данных или алгоритмы». Это не так.
Проведите эксперимент: сделайте страницу с десятью тысячами картинок (вот просто картинок, без CSS и прочего), откройте её и попробуйте пролистать. Возможно для вас это будет откровением и удивлением, но её можно будет прекрасно просматривать в то время, как ваши десять тысяч картинок будут
Но ведь проблема не в картинках, а в том, что в дом дереве постоянно рендерятся новые элементы. И если я также буду выводить 10к точек(каждая в отдельном дом-узле, в котором еще дом узел и тд) то получу туже проблему
Нет — это проблема именно знания алгоритмов.
И как это поможет пофиксить проблему? Приведите, пожалуйста, пример. И оцените сколько по времени займет его имплементация.
Сделайте чтобы оно, блин, не тормозило хотя бы в новых! Не можете? Ну и нечего тогда утверждать, что на «на фронтенде производительность очень редко будет упиратся в структуры данных или алгоритмы». Это не так.
Фикс — github.com/bvaughn/react-virtualized, github.com/aurelia/ui-virtualization и тысячи их(в ванильной или же под любой фреймворк). И если на код ревью попадет самописная реализация — ее заверну. Поэтому повторюсь, каким образом знание алгоритмов поможет быстро пофиксить это(или аналогичную) проблему?
Фикс — github.com/bvaughn/react-virtualized, github.com/aurelia/ui-virtualization и тысячи их(в ванильной или же под любой фреймворк).
Вы идеализируете сторонние решения — они не решают конкретно ваших проблем (а иногда и вообще ничего не решают), и всегда добавляют своих собственных внутренних проблем.
Возвращаясь к вашим фиксам, теперь у вас изначальная проблема (длинный список без тормозов) и вторая проблема (issues той либы, которую вы взяли). И хорошо, если первую проблему эта либа полностью решит — тогда вы «всего лишь» останетесь со второй проблемой. Но это не всегда бывает.
Для того, чтоб отделять случаи, когда сторонние либы решают проблем больше, чем создают, от тех, когда наоборот — тут и требуется понимание принципов работы фронтэнда и браузерного рендера (и это, внезапно, тоже алгоритмы).
ЗЫ: Когда вы подключите 100500 библиотек и вам кто-нибудь скажет, что ваш фронт теперь неподъемен и не грузится на плохом канале — вы что будете делать? Еще одну либу подключите?
ЗЗЫ: Я со своей колокольни предложил бы гораздо более простой фикс: нефиг показывать на одной странице столько, что браузер начинает тупить или отжирает всю память клиента (это к вопросу о всяких virtualized-либах, памяти они жрут дай боже, и вполне реально сожрать её всю, если клиент не на ПК с кучей памяти). Добавьте пажинацию и поиск, и внезапно, вам уже не надо рендерить миллионы дивов только чтоб пользователь нашел нужное ему.
ЗЫ: Когда вы подключите 100500 библиотек и вам кто-нибудь скажет, что ваш фронт теперь неподъемен и не грузится на плохом канале — вы что будете делать? Еще одну либу подключите?Маркетологов подключит. И они объяснят заказчику, что конфетка получается по рецепту «взять дерьма, нафаршировать дерьмом, посыпать сверху дерьмом и завернуть в дерьмо».
А что результат плохо пахнет — так это потому что вы неспециалист и не понимаете всех последний веяний создания фронтэндов.
И если я также буду выводить 10к точек(каждая в отдельном дом-узле, в котором еще дом узел и тд) то получу туже проблемуНе получите. Если породите их одним приcвоением innerHTML. Или даже 10.
И как это поможет пофиксить проблему? Приведите, пожалуйста, пример. И оцените сколько по времени займет его имплементация.Одна строка:
document.getElementById("mytext").innerHTML += answerFromServerНе знаю сколько потребуется на реализацию — зависит от того, сколько вы бессмысленного феншуя нагенерировали на стороне сервера.
Но знаю, что если вы добавите таким образом мегабайтный HTML с тучей нод (пусть даже 100-вложенных) — это отработает меньше, чем за секунду. Я когда-то слышал, лет 10 назад, когда был «молодой и зелёный» о том, как создатели GMail воевали с MS IE 6, который не допускал больше 255 вложенных Div'ов (и вообще любых элементов — там, похоже, «глубина дерева» как байт хранилась). Да, были проблемы. Тормозов не было. Во всяком случае таких как мы наблюдаем сегодня.
И если на код ревью попадет самописная реализация — ее заверну.Ну так в этом проблема, а не в алгоритмах.
Поэтому повторюсь, каким образом знание алгоритмов поможет быстро пофиксить это(или аналогичную) проблему?Если от требования «использовать только хайп, а ещё лучше хайпхайп» отходить нельзя — то никак, конечно. Ну тут проблема не с алгоритмами. А в том, что гланды требуется вырезать только автогеном и только через задний проход.
В этих случаях — алгоритмы бессильны, тут уже ничего не поделать.
Но знаю, что если вы добавите таким образом мегабайтный HTML с тучей нод (пусть даже 100-вложенных) — это отработает меньше, чем за секунду.
Такой хардкор (унесем всё на бэк) в подавляющем большинстве случаев опять же даже и не нужен — мегабайты HTML и реакт какой-нибудь нагенерит, и сделает это весьма быстро (по крайней мере настолько быстро, чтоб пользователь не возмутился). Всё что тут нужно — дать возможность и реакту и браузеру спокойно отработать, не нагружая их каким-нибудь безумным маразмом типа синхронного запиливания миллионов узлов в DOM, или ненужных многократных перерисовок.
Конкретно для реакта — это вообще классические грабли, например: перерисовывать весь список тогда, когда нужно перерисовать один его элемент. Сначала так пишется, потому что не тормозит и вообще «ачотакова?», а потом на боевых объемах всё дохнет. И хотя в теории и туториалах этот момент всегда разжёвывается, на практике — обычно всё миллионы раз завёрнуто одно в другое («композиция круче наследования», — говорили они), и неудивительно, что в этом оберточном цирке даже и адекватный программист пропускает неадекватно большую перерисовку.
Такой хардкор (унесем всё на бэк) в подавляющем большинстве случаев опять же даже и не нужен — мегабайты HTML и реакт какой-нибудь нагенерит, и сделает это весьма быстро (по крайней мере настолько быстро, чтоб пользователь не возмутился).В данном случае речь шла о том — можно ли сделать так, чтобы без измнения вёрстки и без использования «виртуального скроллинга» сделать так, чтобы вот эта вот «бесконечная лента» не тормозила так безбожно. Ответ: да, это возможно — и, собственно
document.getElementById("mytext").innerHTML += answerFromServerэто конструктивное доказетельство.
Нужно ли так делать? Ну — это уже второй вопрос. Да, действительно, возможны варианты и, да, очень может быть что использование полезных либ — не будет лишним.
Да собственно почти наверняка оно будет не лишним: сейчас, всё-таки на дворе не 2000й и даже не 2004й год, Pentium II на 200MHz не является типичной конфигурацией, и, в общем, MS IE 6 — тоже в прошлом. А грамотное использование библиотек позволяет достичь хорошего результата быстрее. Однако, парадоксальным образом, не уменьшает необходимости знать основы!
И хотя в теории и туториалах этот момент всегда разжёвывается, на практике — обычно всё миллионы раз завёрнуто одно в другое («композиция круче наследования», — говорили они), и неудивительно, что в этом оберточном цирке даже и адекватный программист пропускает неадекватно большую перерисовку.Но если результат — дерьмо, то зачем тогда всё это сакратльное знание, скрытое «в специфике отрасли» и почему оно должно цениться выше, чем банальное умение развернуть список?
Увы, абстракции текут — и ничего с этим поделать нельзя.
Но если результат — дерьмо, то зачем тогда всё это сакратльное знание, скрытое «в специфике отрасли» и почему оно должно цениться выше, чем банальное умение развернуть список?
Если результат приносит деньги — он не дерьмо. Наверное тут тоже играет роль моё образование (экономист, пусть и с программерским уклоном). Здесь мы как раз приходим к «если это всё говно, но тем не менее приносит прибыль, то почему бы и не продолжать в том же духе». Не говно будет еще больше прибыли приносить? Очень даже вероятно, но его сначала надо сделать, и потратить на это какие-нибудь большие деньги (потому что из «быстро, дешево, качественно» тут придётся поступиться именно «дешево»).
Вот именно поэтому кодер, который как-то там смог в реакт на уровне «почитаю Дэна и сделаю всё как пишут» для бизнеса часто интереснее того, кто знает, как сделать всё хорошо, правильно, и без явных и скрытых проблем — но и стоит дороже, да и еще дополнительно требует дорогой же команды, потому что первоначальные трудозатраты на качественные решения — существенно выше первоначальных затрат на говнокод.
Наверное тут тоже играет роль моё образование (экономист, пусть и с программерским уклоном).Ну эконмисты разные бывают. Некоторые всерьёз верят, что в замкнутой подсистеме можно создать безконечно расширяющаюся подсистему.
Очень даже вероятно, но его сначала надо сделать, и потратить на это какие-нибудь большие деньги (потому что из «быстро, дешево, качественно» тут придётся поступиться именно «дешево»).Как раз этот вариант и невозможен. Бизнес очень-очень часто хочет «быстро и качественно» (и обычно, хотя и не всегда, даже готов за это платить). Но получает всегда «быстро и плохо». Потому что качественный софт создаётся десять лет. Ну или не создаётся — ну это если его некому создавать.
Не говно будет еще больше прибыли приносить?«Не говно» будет кому-то нужно через десять лет. Про говно все забудут.
Если ваш горизонт планирования — два-три года, то вам ни алгоритмы, ни качественные разработчики, на самом деле, не нужны. Пролема в том, что сейчас, на волне хайпа, даже компании, которые не собираются «хапнуть и разбежаться» через пару лет — тоже покупаются на обещания «серебрянной пули».
Вот именно поэтому кодер, который как-то там смог в реакт на уровне «почитаю Дэна и сделаю всё как пишут» для бизнеса часто интереснее того, кто знает, как сделать всё хорошо, правильно, и без явных и скрытых проблем — но и стоит дороже, да и еще дополнительно требует дорогой же команды, потому что первоначальные трудозатраты на качественные решения — существенно выше первоначальных затрат на говнокод.Я с этим где-то спорю? Наоборот — я ж токо за! Однако. Вся ветка началась с ответа на вот эту реплику
Лучше учится писать качественный, а не производительный код. Лучшее враг хорошего, а преждевременная оптимизация зло.Заметьте: речь идёт про качественный, не дешёвый код.
На фронтенде производительность очень редко будет упиратся в структуры данных или алгоритмы.
По моему дискуссия себя давно исчерпала: кажется все согласны с тем, что если ваша цель — дешёвый код (пусть и дерьмовый), то отказ от знания алгоритмов и структур данных и многих других «излишеств» — оправдан. Меня просто покоробило предложение писать «качественный, а не производительный код» опираясь на то, что «производительность очень редко будет упиратся в структуры данных или алгоритмы». Это притом, что мы видим везде и всюду как именно это она и делает.
Ну вот нет у фронтенда никакой специфики. Вы можете в банальной утилите поиска подстроки в файле создать процедуру сравнения букв без учёта регистров, добавить пару индирекций — и получить такое же замедление, как ваши классические грабли с перерисовкой всего списка, вместо одного элемента. А можете в билд-системе устроить O(N²) — ровно по той же схеме.
Потому если вас волнует качество результата — вы должны уметь «в алгоритмы и стурктуры данных». Если нет — то нет.
Вот только почему-то у разработчиков в других областях эта банальщина не вызывает отторжения, а фронтэндеры — воспринимают эту банальную истину «в штыки».
Как раз этот вариант и невозможен. Бизнес очень-очень часто хочет «быстро и качественно» (и обычно, хотя и не всегда, даже готов за это платить). Но получает всегда «быстро и плохо».
О нет. Этот вариант очень даже возможен в огромном количестве случаев, просто бизнес часто очень плохо представляет, насколько дорого это всё выйдет. Ну и да, конечно же, вещи с некоторого уровня сложности и выше имеют свою цену не в деньгах или не только в деньгах. Не всё параллелится, не всё делается с первого раза, да и всегда есть досадная загвоздка в виде невозможности нарушить законы физики, даже если залить это всё деньгами.
«Не говно» будет кому-то нужно через десять лет. Про говно все забудут.
А если еще точнее — некоторое отдельное «не говно» будет кому-то нужно и через десять лет. Множество другого, не менее хорошего «не говна» всё равно не будет нужно. Нужность через N лет не определяется качественностью, качественность тут — всего лишь одно из необходимых, но не достаточных условий.
ЗЫ: Ну и да, я согласен, что ветка комментов себя исчерпала — я еще где-то выше сказал, что комментировать вот это вот «производительность будет очень редко упираться в структуры данных или алгоритмы» я считаю излишним; это ж просто глупость написана. Многие места в UI упираются в производительности в юзера, но никакой даже очень примитивный UI никогда полностью не упирается в производительность юзера (вторая сторона, сам код, тоже как бы должен отрабатывать). На счётах тоже считают со скоростью юзера, но если счёты у вас заржавеют, то проблема будет не на стороне юзера.
Проведите эксперимент: сделайте страницу с десятью тысячами картинок (вот просто картинок, без CSS и прочего), откройте её и попробуйте пролистать. Возможно для вас это будет откровением и удивлением, но её можно будет прекрасно просматривать в то время, как ваши десять тысяч картинок будут «медленно и печально» грузиться через GPRS (по крайней мере в Chrome).
Проводили такой эксперемент… Не прекрасно там ничего, и картинок там было меньше десяти тысяч, и комп был нормальный, на нём видео обычно рендерят, и браузеры разные были, и человек, писавший это является ярым противником js, и было это год назад… Пока оно всё грузилось, а оно реально долго грузилось, потому что фото были хорошие, наваристые, страницу прокручивать было просто невозможно. И фоточек там была наверное тысяча. Как ни странно, но JQ + lazy load решили все проблемы разом, потому что не надо было эти самые картинки грузить и пытаться их отрисовывать кусками, уже пришедшими с сервера.
Однажды проводил похожий эксперимент. В тот раз я попытался понять, почему же тормозит Хабр на страницах с кучей комментариев. Я нажал "Ответить", открыл инструменты разработчика, и начал снимать с поля ввода все подозрительные обработчики событий.
Так вот — когда я снял все, тормоза не исчезли. Дальнейшее исследование показало, что тормозит сам браузер: при вводе любого символа он считал, что размеры textarea могли измениться, и бросался делать всему дереву DOM повторный layout и render.
Ну и чем тут могли помочь алгоритмы, "правильная" работа с HTML и прочее? Да ни чем, единственный способ предотвратить тормоза без переписывания браузера — просто не показывать столько комментариев на странице одновременно...
Ну и чем тут могли помочь алгоритмы,
Ещё как могли. Только не вам, а разработчикам браузера. Меня, например, откровенно коробит, что моя современная машина с кучей ядер, гигагерц и гигабайт тормозит на такой ерундовой задаче, как рендеринг пары тысяч абзацев. Почему двадцать с лишним лет назад Pentium-233 не тормозил при наборе документа в полторы сотни страниц со встроенной графикой в Word'е, и ему для этой задачи хватало аж нескольких мегабайт, а современный браузер уваливается, и жрет сотни мегабайт или даже гигабайты? Ах, да, ещё и сам Word при этом занимал метров 30, и разрабатывался даже меньшей командой, чем современные браузеры.
И да, признаюсь, я не знаю как составить самостоятельно связанный список. Пока ни разу не понадобились такие навыки, понадобятся — пойду и прочитаю как это делается.
Не будем забывать что в js "настоящего" связного списка нет, он будет делатся через объект(который хеш таблица).
Начиная с V8 небольшие объекты — больше не хеш-таблицы, а записи (благодаря скрытым классам). А теперь уже все основные движки так умеют.
уточните, кандидат на должность по какому языку?
Python
Например, зачем мне на python или javascript знать как организовывать связанные списки(за исключением саморазвития и расширения кругозора)?
Во-первых, как я уже упомянул, чтобы понимать как наиболее эффективно использовать структуры данных для реализации алгоритмов. Знать границы применимости, уметь предсказывать поведение кода на низком уровне.
Во-вторых, иногда и на высоком уровне приходится использовать базовые структуры данных. Реальная продуктовая задачка: для подготовки данных необходимо применить цепочку преобразований. Элемент a заменить элементом b, элемент b элементом c, элемент h элементом g и т.д. Для каждого элемента цепочка преобразований образует односвязный список. А цепочки эти комбинируются из различных источников и, чтобы исключить ошибку, перед применением необходимо проверить их на валидность – удостовериться, что в них нет циклов. А если есть, то либо целиком откинуть такую цепочку, либо поднять информативную ошибку.
Ни одна стандартная структура данных Python здесь не поможет, библиотек для такой фигни никто не станет писать. Но, понимая структуру данных и зная алгоритм, можно за 5 минут накидать его в несколько строк.
И это простейший пример. Гораздо чаще возникают деревья и графы.
Цепочка преобразований скорей всего будет записана через таблицу замены. Проверка на исключение циклов — это к алгоритмам, а не к структурам данных.
Графы и деревья в условиях скриптовых языков точно так же будут записаны через структуры Hash\Map. И это точно не является типичной задачей для фронтенда\веба.
Вопросы на структуры данных и алгоритмы в современных реалиях строго под специфику разрабатываемого продукта.
Как тут поможет односвязный список? Вам придётся его эмулировать на имеющихся стандартных типах, что даст только оверхэд на эмуляцию.
Можно эмулировать, можно и не эмулировать.
@dataclass(frozen=True)
class Node:
next: 'Node'
value: TПроверка на исключение циклов — это к алгоритмам, а не к структурам данных.
Алгоритмы и структуры данных настолько тесно связаны, что говорить о них отдельно совершенно не имеет смысла.
Графы и деревья в условиях скриптовых языков точно так же будут записаны через структуры Hash\Map.
Ну почему же? Я вот так всегда деревья записываю:
@dataclass(frozen=True)
class Node:
left_child: 'Node'
right_child: 'Node'
value: Tэто точно не является типичной задачей для фронтенда\веба.
Человек спросил про Python / JavaScript, а не про фронтенд. В статье тоже ничего конкретно про фронтенд. Мы же с вами не фронтендщиков обсуждаем, а программирование в целом. И в программировании довольно часто появляются задачи, связанные с графами и деревьями. В backend и data science особенно.
Могу ошибаться, но кажется системщики, сетевеки, разработчики драйвером, криптографы и прочая братия тоже не слишком часто сталкиваются с необходимостью реализовать структуры данных вроде деревьев\списков, а вот других специфичных особенностей там будет навалом.
Всё таки сильно зависит от области работы.
Пожалуй.
Три примера из моей области:
1) Фильмы в Netflix со всеми метаданными образуют граф. При этом фильмов немного и граф небольшой, в графовую базу его смысла складывать нет. Поэтому они держат его в памяти процесса и, используя самописные алгоритмы на графах, быстро и эффективно отвечают на запросы.
2) Для поиска похожих фильмов удобно использовать граф, где рёбрами будут метаданные и скоры из различных моделей. На таком графе затем запускается процедура оптимизации, считающая степень похожести.
3) Ансамбли деревьев решений – мощные алгоритмы машинного обучения, но скорость предсказаний у них оставляет желать лучшего. Поэтому мы пишем компилятор таких деревьев в нативный код. Для этого, естественно, в памяти необходимо построить некое абстрактное представление таких деревьев, которое затем может быть оптимизировано и скомпилировано.
Распределенные системы и криптография. Задачи с деревьями, хитрыми структурами данных вроде crdt, фильтров Блума часты, если не повседневны.
Однако, я не считаю, что даже в эту область обязательно проверять знания вроде написания своих списков. Пришедший кандидат может оказаться полезен во множестве других задач.
А еще эта задача внезапно становится интересной в случае программирования на Rust.
А в Rust если хочется написать односвязный список лучше сразу перестать хотеть
Кому не сложно: если вы не знаете, на уровне алгоритма/псевдокода как это сделать, расскажите, на каком языке вы пишете, какими проектами занимаетесь? Ну или, предположим у вас есть знакомый, который не знает как развернуть список, расскажите о нем.
Но точно спрошу, что простите вы хотите со списком сделать? После чего видимо буду забрит как безперспективный дед =)
Связный список в общем случае не надо разворачивать. Связный список можно развернуть в массив, если считать «развернуть» синонимом «распаковать» а не «повернуть». А возможно речь вообще о Развёрнутых связных списках.
Если же исходить из задачи поменять направление — то логичный ответ — зачем? Если мне зачем-то нужно развернуть односвязный список — то я наверняка что-то делаю неправильно.
Вообще это отдельная история — терминология собеседований. У вас есть best practices и есть их названия. И если ты не знаешь названия — считается что ты не используешь практику, а если знаешь — то используешь. Что имеет весьма отдаленное отношение к реальности.
преобразовать список
a->b->… ->d->null
в
d->… ->b->a->null
, ответили бы на уточняющие вопросы по формулировки. При этом вы бы были мотивированы пройти это собеседование. Вы бы смогли придумать алгоритм/написать псевдокод?
Конечно извиняюсь что ответил на заданный вопрос, а не на подразумеваемый, хотя подразумеваемый и был очевиден, но так просто захотелось сказать, что ответ может быть «не смогу» не только из за квалификации.
но вот подумав минуту, я чтото не придумал быстрого и при этом безопасного алгоритма. Единственно что приходит в голову — использовать стэк, заполнив его адресами элементов и потом сформировать новый список.
но вот подумав минуту, я чтото не придумал быстрого и при этом безопасного алгоритма.Что значит «безопасного» в данном случае???
т.е. задача разворота однонаправленного списка — изначально из разряда сферического коня в ваккуме. Хотя нет, для времен, когда данных было мало, памяти 512 кб, а максимальный размер сегмента памяти 64 кб, идея со списками была неплоха)
Ну и на всякий случай, чтобы «два раза не вставать», образование — «прикладная математика».
Хм, кстати интересный вопрос: а много ли программистов, скажем от миддлов и выше, которые не знают как развернуть связный список?
В СНГ процентов 99%.
В СНГ процентов 99%.
Ну, выглядит как серьезное преувеличение.
То есть это не нужно спрашивать?
Отбросьте Яндекс и может еще пару компаний. В остальных без подготовки развернет список только случайный человек.
Чето вы загнули. Мнe кажется большинству разработчиков уровня middle и выше надо будет максимум немного подумать. Сама то задача тривиальная.
Отбросьте Яндекс и может еще пару компаний. В остальных без подготовки развернет список только случайный человек.
Нет, это просто неправда. Вот только что опросил провел блиц-опрос коллег — никто сложности в этой задаче не видит. Не яндекс. Когда проводил собеседования, тоже значительная часть кандидатов с задачами такой сложности справляется. Понятно, что на собеседовании под стрессом даже синтаксис цикла может выпасть из головы, но ведь необязательно создавать такую атмосферу.
Когда проводил собеседования, тоже значительная часть кандидатов с задачами такой сложности справляется.
Нет, ну если вы в свою компанию отбираете только ТЕХ КТО МОЖЕТ решить такие задачи — очевидно что и на вашем блиц-опросе они их тоже решат) Это ошибка вижившего
Цитирую человека выше
Когда проводил собеседования, тоже значительная часть кандидатов с задачами такой сложности справляется.
То есть это выглядит так
2018 год — проводит собеседования, спрашивает алгоритмические задачи, берет на работу тех кто умеет их решать
2019 год — проводит блиц-опрос, и о ЧУДО! Люди в его компании умеют решать алгоритмические задачи
Когда проводил собеседования, тоже значительная часть кандидатов с задачами такой сложности справляется.
Значительная часть (большинство) — справляется НА собеседовании, а не после него. Т.е. большинство разработчиков с улицы с этой задачей справляется.
В вашей компании не так? Повод задуматься.
Я не знаю. Наверное, если сколько-то минут подумаю, то напишу, и скорее всего, даже будет работать правильно. Но не знаю.
C#, Python, "кровавый энтерпрайз".
Но не знаю.
Ну, да, вы верно подметили разницу — педантичнее было бы сформулировать «не знают и не придумают в течение минуты-другой».
Просто для тех, кто придумывает, немедленно есть следующий вопрос: а как быть уверенным, что оно правильно. Я вот, пока вы писали ответ, придумал в голове некое решение. Сейчас-то я могу, не знаю, сесть и загнать его в ближайший интерпретатор и посмотреть, где я ошибся. Но на собеседовании я этого не смогу сделать, а в описании придумываемого алгоритма собеседующему намного проще найти дырки.
Я как-то раз на собеседовании так решал задачу "сделайте дистинкт по списку" — тоже навзлет не помнил, поэтому последовательно улучшал предыдущее решение. Собеседнику не понравилось.
Думаю хорошо, что вы туда не попали. =)
«Как бы вы протестировали свое решение?» тоже нередко спрашивают. Но понятно, что это скорее некая имитация доказательства и решения инженерной задачи в принципе
а как быть уверенным, что оно правильно.
Конкретно в случае со связным списком нужно применить структурную индукцию. Но меня берут сомнения, что хоть где-то за пределами академической среды это нужно :)
… а поскольку структурную индукцию я тоже не знаю, мои шансы пройти собеседование уменьшились на следующий порядок.
Достаточно потратить пару вечеров на доказывание классических алгоритмов на графах (которые всяко полезнее и применимее тех же сортировок, и доказывается через эту самую индукцию) и шансы резко повысятся.
… и через год упадут обратно, потому что нигде, кроме как на собеседованиях, мне этот навык что-то не пригождается.
Ты переооцениваешь сложность навыка. Или ты про алгоритмы на графах?
Что же касается шансов, то найдется куча более адекватных контор, где не надо проходить 9 кругов ада ради самого процесса трудоустройства.
И, как написано по-соседству, такие знания, не подкрепляемые постоянной практикой, очень быстро превратятся в тыкву.
2. Умение решать такие задачи открывает двери в места, где такие задачи решать нужно, можно и интересно. Не говоря уже о чисто материальных и репутационных плюшках.
Но если вам интересно в кровавом энтерпрайзе (в хорошем энтерпрайзе таких задач тоже много) или вебе (без иронии, я понимаю почему это может быть интереснее), то как бы да, выбор понятен.
Нравится проектировать системы, продумывать алгоритмы, связи и т.п. Прорабатывать логику процессов. Веб не люблю. Бардак там. Была бы возможность подался бы в разработку игрушек. Там как раз есть интересующие области вроде алгоритмизации и компьютерной графики (в свое время возился с OpenGL/Direct3D, а сейчас это уже на другом уровне), но слишком не просто перепрыгнуть. Даже банально пересесть с Delphi на Java бюрократически весьма сложно. Удача помогла. Освоился быстро, хоть и полностью новый стек технологий был. Шел бы обычным путем через собесы — фиг бы прошел.
есть следующий вопрос: а как быть уверенным, что оно правильно.
правильный реверс от половинок, собранных в обратном порядке должен совпадать с реверсом целого: rev(a+b) == rev(b) + rev(a). Эту проверку можно запустить простой рекурсией через весь список.
Спасибо, вы только что привели еще одну вещь, которую я не знаю.
Нет, не достаточно, ведь реализация, которая меняет знак у каждого элемента, удовлетворяет вашим условиям.
Правильные условия — reverse [x] = [x] и reverse (xs ++ ys) = reverse ys ++ reverse xs; они достаточны потому что исходя из них функцию можно построить конструктивно (кроме случая с пустым списком — он тоже однозначен, но найти его из этих условий можно только как решение уравнения)
rev lst = [], очевидно, удовлетворяет этому условию.
(в восхищении) вот это уровень!
а как быть уверенным, что оно правильно
Если алгоритм циклический — то надо найти инвариант цикла. Дальше, как правило, всё очевидно.
немедленно есть следующий вопрос: а как быть уверенным, что оно правильно
Ну, чисто навскидку: мне никогда не приходилось разворачивать список в указанных терминах. Писал и пишу на С, Ассемблере, Object Pascal — это из самых низкоуровневых. Решение пришло секунд за 10, еще 20 ушло, чтобы записать его на листке.
Поскольку алгоритм в каждый момент времени работает только с 3 элементами, можно считать, что если мы докажем правильность его работы чисто эмпирически на 3 элементах, то по индукции он будет работать верно и для 4..N. Здесь можно просто руками провести трассировку, указать конечное состояние тех или иных полей и переменных, а потом показать, что при таких значениях мы можем пройти от 3го элемента до 1го.
Программирую на C компиляторы, гипервизоры и т.п.
Эмбедер, сишник, лет 10 опыта. Связные списки использую, но что такое "развернуть" не знаю. Имеется в виду "сделать reverse"? Тогда это элементарно.
До этой статьи как-то даже не задумывался. Пока читал, приостановился на пару секунд, задумался, прикинул, что самое простое — берём первый объект, меняем у него местами prev и next, дальше идём по ссылке prev, и повторяем, пока prev не окажется null.
Поэтому, важно не то, знает ли человек конкретный базовый алгоритм, а знает ли о нём вообще. Поясню: в университете на письменных экзаменах нам разрешали использовать открыто любые источники, — лекции, учебники и т.д. Так как было важно, чтобы студент знал, какие есть методы и законы, где они применимы, и мог ими оперировать для достижения цели — решения задачи. Если он не знал инструментов, то поиск не сильно помогал.
Блджад, я за пять лет работы на жаве ни разу не использовал LinkedList.
Все равно, что спросить, кто из имеющих права умеет шлифовать задиры на цилиндрах.
Например, вопрос «Определите, есть ли в связном списке цикл». Предполагается, что кандидат должен придумать решение типа «черепаха и заяц», опубликованное в обильно цитируемой научной статье 1967 года. Вы просите кандидата повторить научное исследование за 30 минут!
Я бы добавил к элементам списка счетчик, который инкрементировал бы при проходе через элемент. Если бы при очередном проходе в счетчике уже была единица, то значит, цикл есть.
И да, я никогда не решал подобную задачу, я не в курсе про ту научную статью, и даже поленился заходить по вашей ссылке. Этот алгоритм я придумал в течении минуты, как только прочел процитированный абзац.
Пара вопросов:
1. Такая ли уж это сложная задачка для кандидатов, или просто обычный индикатор, умеет человек логически рассуждать, или нет?
2. Могу ли я ещё одну научную статью сделать из этой фигни?
А если менять список нельзя?
Если нельзя, то хранить идентификаторы элементов, например, их адреса, в какой-то внешней структуре, и проверять, есть ли там такой же идентификатор. Сути не меняет, задачка совершенно рядовая, с какой стороны к ней не подойди.
Как выше написали, требовать изобрести академический алгоритм на собеседовании — верх идиотизма. Требовать его знание — тоже. Слишком уж оторванный от реальных задач пример.
Нормальный подход — спросить и смотреть, как кандидат будет выпутываться. Если предложит решение с маркерами в списке, с доппамятью или с разрушение списка (использование ссылок как маркеров прохода), то уже норм.
Потому что пузырьковая сортировка — тоже была описана в научной публикации. И даже какое-нибудь банальное решение квадратного уравнения — тоже было когда-то «высокой наукой». И даже отрицательные числа и ноль! Ноль — вообще «прорывом» был… столетия назад, да… ну а какая разница?
Вот интересно: в какой момент знания перестали переходить из академической науки в практику и появилась вот эта реакция: полвека назад про это была научная статья — значит мне это «нинужна»?
Вы реально помните все алгоритмы, которые изучали 15 лет назад в институте, а потом ни разу не использовали? Прям вот все-все сможете вспомнить на собеседовании?
Но в данном-то случае мы говорим об алгоритме, который в дюжину строк реализуется и легко визуализируется…
И вообще вы разговариваете с голосами в своей голове. Никто и не говорил о ненужности, говорили о том, что подобный алгоритм, который мало применим в реальной работе, человек может и не знать или не помнить, а изобрести заново на собеседовании нереально.
Да, конечно, в природе есть экзотические структуры данных — типа каких-нибудь фибоначчиевых куч — но уж «зайца и черепаху» не знать?
Я, по неопытности, какое-то время на интервью использовал её для подсказок к другим задачам — и офигевал, когда кандидаты меня не понимали. Теперь привык.
Да, конечно, в природе есть экзотические структуры данных — типа каких-нибудь фибоначчиевых куч — но уж «зайца и черепаху» не знать?Вот представьте себе, я вроде и в универе на программиста учился, и 10 лет стажа, а про «зайца и черепаху» только из этой статьи впервые услышал. Наверное потому, что за эти 10 лет так ни разу и не возникла проблема «библиотечные функции слишком медленные».
а изобрести заново на собеседовании нереально
Это, честно говоря, не очень смешной троллинг.
Извините, если написали это всерьез. Это напоминает мне шутливый ответ Скотта Адамса (карикатуриста, автора Дилберта) на вопрос «Скажите, как вам приходят такие классные идеи?» — «Что можно сказать — я просто сижу и придумываю. Если вам не приходят в голову идеи, то вам крышка». Здесь то же самое — если человек всерьез считает нереальным на собеседовании создание такого простого алгоритма — то ему крышка.
Да там любой множитель подойдет если он больше 1, даже с иррациональным можно извратиться :-).
Весь смысл — в том, что если цикл есть, то после того как Черепаха дойдет до цикла — Заяц уже никак не сможет миновать её. Увеличение множителя ускорит завершающую фазу алгоритма (обход цикла), но замедлит начальную (пока Черепаха до цикла не дошла, любые передвижения Зайца — лишь напрасная трата времени).
Но прям сразу это было неочевидно, и я думал, возможна или невозможна ситуация, когда они будут ходить по циклу и никогда не пересекутся.
Я, видимо, имел в виду, что в общем случае, если черепаха и заяц стартуют с разных элементов списка (по какой-то странной причине), то вот тут взаимная простота необходима, иначе они легко могут никогда не пересечься. Простейший пример — список из четырех элементов, черепаха прыгает через один (шаг 2), заяц прыгает через три (шаг 4). Заяц будет прыгать на месте, черепаха между двумя элементами. И если заяц начинал не в четном элементе, то они никогда не пересекутся.
Простейший пример — список из четырех элементов, черепаха прыгает через один (шаг 2), заяц прыгает через три (шаг 4). Заяц будет прыгать на месте, черепаха между двумя элементами. И если заяц начинал не в четном элементе, то они никогда не пересекутся.А! Если заяц именно прыгает — тогда да… Но, вообще говоря, ему всё равно нужно каждый элемент проверять (иначе он «умрёт» на списке, где нет цикла, напоровшись на Null), можно и смотреть есть тут черепаха… это недолго по сравнению к обращениям в память.
2. Тут вы и по времени, и по дополнительной памяти имеете линейную сложность, а в статье время линейное, а доп.память — константа. Так что новую статью, наверное, нет смысла делать.
То, что вы придумали — это еще хороший алгоритм. Кандидат запросто может предложить линейную память и квадратичное время: хранить список указателей на пройденные вершины и на каждом шаге проверять текущую вершину на вхождение в список.
Приближая асимптотику в сторону одного мы одновременно будем отдалять асимптотику от другого,
Это понятно для худших случаев. Но в среднем у нас поиск будет лучше, чем для списка, а вставка — лучше, чем для массива.
Мы можем использовать массив с указателями на массивы разных длин, а не списков — тут можно еще поиграться. Список массивов — не суть. Кроме того, заданные длины списков/подмассивов могут быть разными. Скажем, для динамического массива самое болезненное — вставка в начало, значит, мы можем настроить длины списков так, чтобы сначала они были длиннее. Скажем, первый блок — половина общей длины, потом по принципу дихотомии.
Да, VList — пример такой структуры:
www.wisdomjobs.com/e-university/data-structures-tutorial-290/vlist-7159.html
infoscience.epfl.ch/record/52465/files/IC_TECH_REPORT_200244.pdf
Раздел 2.
Изучение и знание — разные вещи.
Если вы вызубрили quicksort, но не понимаете как он устроен и почему — толку от таких знаний нет.
Если вы понимаете как строятся divide&conquer-алгоритмы и рекурсию, то какой-нибудь quicksort вы выведете на бумажке за несколько минут.
Я бы сказал, "какой-нибудь алгоритм сортировки". Потому что мне до сих пор merge sort дается намного легче.
Я так понял из стенфордского курса по дизайну и анализу алгоритмов. А почему, собственно, нет?
Важная парадигма разработки алгоритмов, заключающаяся в рекурсивном разбиении решаемой задачи на две или более подзадачи того же типа, но меньшего размера, и комбинировании их решений для получения ответа к исходной задаче.
Ничего этого в merge sort нету — ну по крайней мере у меня в голове, в «merge sort на 4 лентах» нету. Есть маленькие «капельки» отсортированных данных, которые, после каждого прохода, удваиваются в объёмах, растут… а в конце получается одна большая «суперкапля» — и все данные отсортированы.
Но да, в принциме, если смотреть на него как на алгоритм типа «разделяй и властвуй» тоже можно… и даже Wikipedia такой вариант как канонический приводит… буду знать теперь — хотя мне всё равно кажется, что моё понимание более правильное: в реальном STL используется как раз описанный мною подход… только что проверит.
Ничего этого в merge sort нету — ну по крайней мере у меня в голове, в «merge sort на 4 лентах» нету.
Есть у меня подозрение, что у вас в голове совсем не тот merge sort, который у меня. Потому что тот, который у меня, это "подели входные данные пополам, каждую половину отсортируй, результаты слей поэлементно". И по вашему определению это D&C.
Есть у меня подозрение, что у вас в голове совсем не тот merge sort, который у меня.Похоже на то. У меня в голове, как я уже сказал, алгоритм «с четырьмя лентами» и фиксированным объёмом оперативной памяти. Чего-то «делить» тут не получится: памяти-то нет!
Потому что тот, который у меня, это «подели входные данные пополам, каждую половину отсортируй, результаты слей поэлементно». И по вашему определению это D&C.Да, такой алгоритм как раз Wikipedia и описывает. Но это не тот алгоритм, который придумал Кнут (хотя у него их там много разных, может и такой есть) и не тот алгоритм, который в реальных библиотеках используется.
Рекурсивное разбиение задачи на подзадачи вовсе не означает, что алгоритм в итоге получается тоже рекурсивный.
А что он тогда по вашему?
Ну, как бы, что бы merge'ить что-то, надо это что-то иметь. Получить его как раз разделением и можно. Слияние — это conquer часть.
Это получается поредельный случай деления — сразу на N частей =)
На самом деле, тут просто совпало, что можно так по частям сливать от 1 элемента и в итоге получить сложность за n log n.
Потому что можно, например, сливать всегда первые 2 отсортированых списка, что будет n^2.
Но если же сливать 2 самых маленьких всегда, то получается именно схема разделить на 2 части и слить, только развернутая.
Я как-то сразу про ленты вспоминаю, если речь идёт о merge sort. Ибо «RAM Locality is King» — все остальные алгоритмы плохо дружат с реальной памятью (особенно Heap Sort). Если же мы начинаем «сортировать на месте», то тут, понятно, уже нужно, чтобы данные влазили в кеш (иначе чего мы мучаемся), а там уже другие алгоритмы рулят…
Я к тому, что 20+ лет изучал в вузе, причём не чтобы просто сдать зачёт, но напишу или расскажу разве что пузырёк. Ассемблер 8080, наверное, лучше помню.
Я вот могу и пузырек и квиксорт и слияние и поразрядную. Но в продакшене я скорее всего буду использовать что-то штатно-библиотечное, чтобы потом коллеги не размышляли что это такое и почему.
Пару раз только пришлось писать свои варианты. И то, в одном случае — потому что учет специфики данных позволял ускорить работу сортировки на два порядка (и даже больше), а в другом — нужна была специфическая устойчивость сортировки.
Многие уже забыли зачем на самом деле спрашивают про сортировки.
Хуже, что большинство просто зубрит. И в какой-то момент это стало нормой и тот, кто не вызубрил уже выглядит как разработчик второго сорта. Можно, конечно, попытаться придумать в процессе собеседования что-то, но в условиях нервяка выглядеть это будет менее вразумительно, чем заученный ответ.
Самое обидное, что потом кандидат на месте работы ни разу не пользуется плодами своей зубрежки, а использует сортировку из коробки на SQL или Java (и это еще хорошо).
Короче, впечатление от вопросов про сортировку примерно такое же как от вопросов Гугла (почему люки круглые, сколько будет стоить помыть все окна и т.д.). Там тоже про умение мыслить и все такое, но сейчас от них отказались.
Мне кажется умение написать алгоритмы на память нужно спрашивать на позиции, где есть хоть какая-то вероятность, что их придется реализовывать с нуля. Если алгоритмы только используются, то должно быть достаточно, чтобы кандидат знал их особенности и как выбрать правильный. Детали реализации можно и в книге/гугле глянуть.
Я уверен, что любой свежий выпускник CS специальности, с нормальным баллом, заткнет за пояс по алгоритмам большинство специалистов с богатым опытом разработки. Для кандидатов на разные позиции и с разным опытом вопросы должны быть разные.
На своих собеседованиях я стал давать задичи с описанием логики решения, мне больше интересует, чтобы кандидат показал как он пользуется языком, чтобы реализовать логику. Если человек умеет ли человек написать quick sort из головы, скорее всего он просто впустую потратил время, чтобы его зазубрить прямо перед собеседованием.
PS: Список развернуть смогу :-)
Поддерживаю. Тоже эмбедер, списки и деревья приходилось использовать чуть больше, но все же редко. И да, после института я бы смотрелся на собеседовании в вопросах алгоритмов гораздо лучше, чем сейчас. Только на свой код того времени я без слез смотреть не могу.
Я никогда не зубрил сортировки, но могу написать квиксорт из головы. ЧЯДНТ?
Это точно мне вопрос? Вы наверно лучше меня знаете, а я так понятия не имею, что вы делаете так или не так.
Раньше перед каждым собеседованием просматривал и освежал в памяти эти сортировки. В итоге никто никогда не просил их писать и на работе никогда не требовалось. И сейчас я сходу и не вспомню всю суть квиксорта.
Если алгоритмы только используются, то должно быть достаточно, чтобы кандидат знал их особенности и как выбрать правильный.А как вот это вот работает? Вы зазубриваете все особенности всех алгоритмов? Там перепутаете же рано или поздно.
Даже если вы человек долждя и можете запоминать миллионы фактов и никогда их не путать — то как с вами работать? Вы ж будете их предъявлять, когда вас о чём-то спросят — а объяснить не сумеете. И? Что дальше? Всю вашу работу перепроверять? Так проще самому всё сделать.
Для кандидатов на разные позиции и с разным опытом вопросы должны быть разные.Разумеется.
Я уверен, что любой свежий выпускник CS специальности, с нормальным баллом, заткнет за пояс по алгоритмам большинство специалистов с богатым опытом разработки.Конечно. Потому им — задаются другие вопросы и оцениваются другие навыки.
«Развернуть список» — это лёгкая разминочная задачка, показывающая что человек, руководящий разработкой, ешё в состоянии три указателя у себя в голове не перепутать и один цикл написать.
Не знаю чего к ней так придрались.
PS: Список развернуть смогу :-)А скопировать список с дополнительными связями? 100% практическая задача, между прочим. JIT-компилятор: превращаем байткод в последовательность инструкций, где каждая команда ссылается на следующую… но некоторые могут ссылаться куда-то ещё (ветвления, да). Вот как эту структуру скопировать? Без дополнительной памяти, пжлста.
А работать вообще очень просто. Есть задача, собрались, обсудили детали, разбили на тикеты. Назначили иполнителей. Если нужно использовать какие-то алгоритмы, отдельно обсудили, что именно важно. Далее идет имплементация, ревью и валидация. Тут и важно, чтобы человек знал особенности, и если ему нужна сортировка то выбрал ту, которая лучше подходит в условиях конкретной задачи.
Придрались не к самой задачке. Вопрос с тоит в плоскости, что важнее на собеседовании, то как человек логику решения изобретает или как он реализует ее. Эта задача не совсем показательна, там логика тривиальная. А вот часто спрашивают на собеседованиях, как найти, что список в цикле и разорвать его. Даже в статье написано, что решение было опубликованно в научной работе очень давно. Понятно же, что все, кто изображает умственные муки и потом рожает это решение прямо на собеседовании показывают только актерское мастерство. Я сразу людям говорю, что делается это через два указателя и прошу написать имплементацию. Все это именно, чтобы проверить, что человек знает, как указателями оперировать.
Т.к. в вашей задаче входных условий мало, то я решаю ее исходя из того что есть. Отсутствующие условия трактую в свою пользу.
Я решил, что данные у нас лежат компактно в выделенной для них области памяти. Достаточно определить их границы, и перепрограммировать контроллер виртуальных страниц, чтобы он отобразил эти же данные в другую область памяти. Если планируется скопированные данные менять, то пометим страницы, как Copy On Write.
Все, задача решена и заметьте сложность O(1). Затрат дополнительной памяти ноль. Более того, мое решение так же работает при копировании между процессами.
Вы даже не знаете в чем моя работа заключается, а уже вам проще ее самому сделать.А зачем мне знать в чём заключается ваша работа? Я ж не беру вас на работу, чтобы вы решали задачи, которые вам понравятся. Мне нужно решить какие-то мои задачи, про которые, очевидно, я знаю лучше вас…
Если нужно использовать какие-то алгоритмы, отдельно обсудили, что именно важно.Что значит «если нужно использовать какие-то алгоритмы»? Какую вообще программу можно написать без использования алгоритма? Упомянутые тут вот две строчки — это уже алгоритм (прочём плохой). Если вы на каждые две строчки совещание собираете… то я даже представить себе боюсь что вы такое разрабатываете, что можете себе это позволить…
Тут и важно, чтобы человек знал особенности, и если ему нужна сортировка то выбрал ту, которая лучше подходит в условиях конкретной задачи.В этот момент — уже поздно. Хотя бы потому что важные решения явно уже были приняты до того. Например можно было использовать tree set и иметь данные всегда отсортированными. А может быть priority queue, если отсортированность данных не нужно, но элементы нужно «вынимать» и обрабатывать по одному. А может и вообще — нам ничего не интересно, потому что элементов будет 3-5 штук и нам вообще неважно когда их сортировать.
Когда вы дошли до валидации — уже поздно что-то обсуждать.
Понятно же, что все, кто изображает умственные муки и потом рожает это решение прямо на собеседовании показывают только актерское мастерство.Если дать какие-то подсказки — то не обязательно.
Я сразу людям говорю, что делается это через два указателя и прошу написать имплементацию. Все это именно, чтобы проверить, что человек знает, как указателями оперировать.Далеко не все готовы реализовывать алгоритм, о котором они никакого понятия не имеют. Вот после подобного озарения — дело другое.
Т.к. в вашей задаче входных условий мало, то я решаю ее исходя из того что есть. Отсутствующие условия трактую в свою пользу.Принято. Я буду исходить из того, что вы ответили так же, как и на собеседовании.
Я решил, что данные у нас лежат компактно в выделенной для них области памяти. Достаточно определить их границы, и перепрограммировать контроллер виртуальных страниц, чтобы он отобразил эти же данные в другую область памяти. Если планируется скопированные данные менять, то пометим страницы, как Copy On Write.Гениально! Вот действительно очень клёво. Я порадовался. А теперь посмотрим на всем известные критерии.
Все, задача решена и заметьте сложность O(1). Затрат дополнительной памяти ноль. Более того, мое решение так же работает при копировании между процессами.
Толковый? Несомненно: набор знаний налицо. Доводит дело до конца? Категорически нет. Применил все свои знания ради того, чтобы уклониться от решения задачи. Типичный пример человека, который «просиживает ученую степень в больших компаниях, где их никто не слушает из-за их полной непрактичности». Вывод: не брать. Ни на какую должность и ни при каких условиях.
Вот видите: одна простенькая задача даёт более, чем достаточно данных для того, чтобы оценить человека — хотя, возможно, совсем не в той области, о которой хотели говорить изначально.
P.S. И да, я знаю историю про Нильса Бора. Иногда людям действительно хочется постебаться и они готовы поставить свою судьбу на кон… но как по мне — лучше пропустить одного Бора, чем набрать кучу идиотов. Бор и без вас как-нибудь пробъётся, а вам с набранными идиотами придётся работать…
Никогда не поздно что-то обсуждать. Не важно это ревью или валидация, если выявляется какой-то фактор, который был не учтен, логика должна быть скорректирована. Я не делаю веб или десктоп приложений, у нас safety critical решения. Мы сертифицируемся и проходим код ревью на безопастность для людей. Не может быть такого, что что-то поздно поменять. Количество необходимых изменений в случае проблемы достигается грамотным проектированием решения.
Далеко не все готовы реализовывать алгоритм, о котором они никакого понятия не имеют. Вот после подобного озарения — дело другое
Я же про это и пишу, мне нужны люди которые способны написать имплементацию получив описание алгоритма. Не нужно его придумывать или помнить все наизусть. Не разу не слышал про возможное решение, подойди и спроси, только не надо велосипедить.
Принято. Я буду исходить из того, что вы ответили так же, как и на собеседовании.
Вы даже не представляете, что я говорил на собеседованиях. Важно понимать, что нужно людям. А нужно им тоже самое, что и мне, когда я нанимаю. Нужен специалист, способный решать проблемы и делать «delivery» (извените не знаю, как по русски это правильно). Выбор алгоритмов по пути, конечно важно, но далеко не первично.
Я написал выше, что по результатам обсуждения задача разбиывается на тикеты и назначаются исполнители. По-моему можно представить уровень задач, когда это нужно.Нет, нельзя. Потому я, в разных компаниях, видел как ситуацию, когда целые компоненты, которые нужно месяца два-три писать, создавались без «разбиения на тикеты», так и ситуацию, когда, буквально, все циклы больще, чем в три строки — описывались Архитектором и «макаки» просто кодили их по блок-схеме.
Самое смешное, что при этом я видел как дерьмовый код, проходивший 15 review, так и «жуткий код» (обычно мой), который успешно отрабатывал долгие годы — без сбоев и обнаружения в нём ошибок.
Я не делаю веб или десктоп приложений, у нас safety critical решения.Ну тут — можно поверить, что требования будут другими. И, кстати, как раз в этом варианте людям без знания алгоритмов, но аккуратным и исполнительным, можно применение найти… то есть это ближе к шкале, где каждая строчка проверяется трижды…
Нужен специалист, способный решать проблемы и делать «delivery» (извените не знаю, как по русски это правильно). Выбор алгоритмов по пути, конечно важно, но далеко не первично.Возможно. Не участвовал в написании safety critical решений.
А вот часто спрашивают на собеседованиях, как найти, что список в цикле и разорвать его. Даже в статье написано, что решение было опубликованно в научной работе очень давно. Понятно же, что все, кто изображает умственные муки и потом рожает это решение прямо на собеседовании показывают только актерское мастерство. Я сразу людям говорю, что делается это через два указателя и прошу написать имплементацию. Все это именно, чтобы проверить, что человек знает, как указателями оперировать.
Мне кажется, что не стоит ограничивать творчество кандидата. Решение с 2-мя указателями не единственно возможное. Можно перевернуть(reverse) список. При наличии цикла голова не поменяется.
PS: Когда я впервые услышал о нахождении цикла в списке, засомневался в практическом применении. Не может же такого быть, чтобы ошибка вкралась в операции со списками. Однако буквально через год мне довелось чинить баг связанный ровно с этим :)
Можно перевернуть(reverse) список. При наличии цикла голова не поменяется.Очень красивое решение. Практически бесполезное (даже не могу придумать случай, когда оно было бы быстрее). Но красивое.
Вот только оно не работает, если перед циклом есть какой-то незацикленный отрезок. Еще встает вопрос, а как алгоритм разворота должен остановиться, ведь если цикл есть, то до конца не дойти никак.
Как я сказал: безумно красиво, но абсолютно непрактично.
Работает оно в этом случае, причем не повреждая структуру списка (можно развернуть все еще раз и получить исходный список обратно).
А вот, по слухам, когда надо обработать гигабайты тех же самых записей за доли секунды, и занимается этим специально спроектированная лично для вашего проекта железка, и миллисекунды задержек это прямые потери в финансах сопоставимые с бюджетом исторической родины, то вопросы сортировок и прочих списков, внезапно, становятся достаточно актуальными…
Т.е. все упирается в производительность и эффективность при работе с большими объемами данных, распределенных по нескольким местам. И далеко не всегда удается решить задачу в лоб, одним скулевым запросом. Была такая ситуация — проверка наличия строки в таблице. Но строки там хранятся группами в виде набора слов. Лобовое решение через listagg работает, но время примерно 2.5сек. А по ТЗ надо укладываться в 150-200мс. Вот и приходится мудрить с высокоселективными предвыборками, частотным словарем и т.д. и т.п.
А еще в банке баланс сводится каждый день. Так называемый EOD (End-Of-Day). А если АБС (Автоматизированная Банковская Система) работает в режиме реального времени, то там совсем весело — перед переходом в EOD создается т.н. «юнит ночного ввода» где продолжают идти все операции. А по окончании EOD производится «накат» — перенос всех изменений из ночного юнита в дневной (который уже перешел на следующий день). И попутно формируются различные отчеты и т.п.
А еще проверки операций для комплаенса, проверки пользователей на всякие риски и много-много чего.
В результате на сервере одновременно крутится огромное количество задач с конкурентным доступом к данным.
Любой сбой приводит к финансовым потерям и репутационным убыткам. В результате каждая новая задача проходит многоэтапное тестирование
1. Компонентное — на соответсвие ТЗ и отсутствие грубых ошибок, приводящих к падению задачи.
2. Бизнес — на соответствие заявки на разработку (т.е. это тест ТЗ + его реализации)
3. Интеграционное — на непротиворечивость взаимодействия со всеми остальными компонентами системы и отсутствия конфликтов в работе
4. Для регулярно запускаемых задач (те же отчеты, к примеру) еще обязательно нагрузочное тестирование — сколько ресурсов потребляет задача и насколько она оптимальна.
По факту казалось бы ничего сложного в разработке нет — обычная работа с БД. А на практике постоянная голована боль о том, чтобы каждую операцию пытаться сделать максимально эффективной. Не злоупотреблять «тяжелыми» операциями, по возможнсти вынося их из цикла. Там где можно сократить количество обращений к БД — кешировать все что можно. Задачи с большим количеством вычислений распараллеливать на мастера, выдающего задания и фиксирующего результаты и исполнителей (5-10 параллельных задач), обрабатывающих выданные блоки информации. Тут сразу встает вопрос эффективного межпроцессного взаимодействия (обмена данными) и контроля мастера за исполнителями… И т.д. и т.п.
Так что скучать не приходится :-)
связный список это единственная структура данных динамического размера, операции с которой требуют изменение лишь одного указателя (т.е. и до и после изменения указателя структура в корректном состоянии), а в cpu есть атомарные инструкции по работе с ними
Нам нужно изменить два указателя — в элементе который вставляем и в предыдущем. Так что коллизии получатся возможными
Так что на практике их стоит, елико возможно, избегать — и применять в тех случаях, когда ну вот совсем-совсем «край». Просто очень высока вероятность ошибки. Алгоритм в 100 строк может «доводиться до ума» месяц.
Коллизии легко избегаются потому что есть специальная атомарная инструкция en.wikipedia.org/wiki/Compare-and-swap (я именно это имел в виду под «в cpu есть атомарные инструкции по работе с ними»)
Порядок действий если надо вставить элемент между a и b (a->b):
— Создаем новый элемент c (никто о нем не знает, так что синхронизироваться не нужно)
— Выставляем указатель c -> b
— если a все еще a->b то меняем указатель a->c (через compare-and-swap), иначе кто-то влез перед нами и надо что-то передумать или просто повторить
a -> b -> c ->и разворачиваешь
<- ɔ <- q <- ɐКак только вы нашли какой-то элемент в цикле, то достаточно еще 2 раза пройти по списку, чтобы найти весь цикл. Сначала пройдитесь вперед, пока не вернетесь к известному элементу, узнав таким образом длину цикла. Затем пустите 2 указателя с разницей в длину цикла — они встретятся на первом элементе цикла.
Ибо правильный алгоритм не скажет, где именно находится цикл (а в реальности это надо, например, чтобы выплюнуть сообщение об ошибке), и не очень эффективен по скорости.Почему не скажет? Скажет. Вторым проходом.
и не очень эффективен по скорости.Бенчмарки есть? Я могу себе представить ситуацию, когда какой-нибудь другой алгоритм даст бо́льшую скорость — но это её ещё организовывать достаточно долго придётся.
Условно — список их 100500 элементов и цикл в хвосте. В результате заяц будет наматывать круги, пока черепаха не дойдёт до него.
Чисто технически, помечать пройдённые элементы будет проще и быстрее, но это требует доп.память, что в реальности, а не в абстрактном алгоритме для данной задачи не проблема.
Условно — список их 100500 элементов и цикл в хвосте. В результате заяц будет наматывать круги, пока черепаха не дойдёт до него.Вам что — жалко зайца? Заметьте, что не так он и много тех кругов намотает: не больше 100500 «лишних» элемнтов.
Чисто технически, помечать пройдённые элементы будет проще и быстрее, но это требует доп.память, что в реальности, а не в абстрактном алгоритме для данной задачи не проблема.Проблема-проблема. Я ведь не зря говорил про бенчмарки. Вот мои:
#include <iostream>
#include <time.h>
struct List {
List* next;
bool mark;
};
bool is_cycle1(List *p) {
while (p != nullptr) {
if (p->mark) {
return true;
}
p->mark = true;
p = p->next;
}
return false;
}
bool is_cycle2(List *p) {
while (p != nullptr) {
if (!p->mark) {
return true;
}
p->mark = false;
p = p->next;
}
return false;
}
constexpr std::size_t array_size = 10050000;
List array[array_size];
int main() {
for (auto& element : array) {
element.next = &element + 1;
}
std::end(array)[-1].next = std::end(array) - 1;
struct timespec begin_time;
clock_gettime(CLOCK_MONOTONIC, &begin_time);
std::size_t count;
for (int i = 0; i < 100; i++) {
count += is_cycle1(array);
count += is_cycle2(array);
}
struct timespec end_time;
clock_gettime(CLOCK_MONOTONIC, &end_time);
std::cout << "Found: " << count << " times." << std::endl;
std::cout << (end_time.tv_sec * 1000000000ULL + end_time.tv_nsec -
begin_time.tv_sec * 1000000000ULL - begin_time.tv_nsec)
* 0.000000001 << std::endl;
}#include <iostream>
#include <time.h>
struct List {
List* next;
};
bool is_cycle(List *p) {
if (p == nullptr)
return false;
List *turtle = p;
List *rabbit = p->next;
while (turtle != rabbit) {
if (rabbit == nullptr)
return false;
rabbit = rabbit->next;
if (rabbit == nullptr)
return false;
rabbit = rabbit->next;
turtle = turtle->next;
}
return true;
}
constexpr std::size_t array_size = 10050000;
List array[array_size];
int main() {
for (auto& element : array) {
element.next = &element + 1;
}
std::end(array)[-1].next = std::end(array) - 1;
struct timespec begin_time;
clock_gettime(CLOCK_MONOTONIC, &begin_time);
std::size_t count;
for (int i = 0; i < 100; i++) {
count += is_cycle(array);
count += is_cycle(array);
}
struct timespec end_time;
clock_gettime(CLOCK_MONOTONIC, &end_time);
std::cout << "Found: " << count << " times." << std::endl;
std::cout << (end_time.tv_sec * 1000000000ULL + end_time.tv_nsec -
begin_time.tv_sec * 1000000000ULL - begin_time.tv_nsec)
* 0.000000001 << std::endl;
}Но вот тот факт, что для того, чтобы «пометки» хотя бы приблизились по скорости к классическому алгоритму мне пришлось помучиться (память под пометки у меня выделена статически, я не очищал пометки, а сделал два алгоритма и так далее) и что попытки использовать упоминавшиеся тут hashset'ы (да даже если хотя бы заставить функцию
is_cycle вернуть всё в исходное состояние и сбросить пометки) и прочее приведут к существенному проигрышу — говорит о многом.Хотя бы о том, что в 1967м году люди не были идиотами и не нужно считать что тот факт, что вы знаете «современные технологии», а Флойд их не знал — основанием для «изобретения велосипеда».
что за бред?
Смысл связного списка в том чтобы просто так его полностью не обходить каждый раз, и то что в списке нет недолжного цикла в первую очередь определяется его использованием в программе.
Второе, чтобы не болтаться туда сюда несколько раз, цикл проходим один раз с эффективным хешированием узлов, например по мере создания присваиваем узлу номера 0,1,2,3 и т.п. и составляем битовую лукап-таблицу из известных номеров узлов с флагами 1<< номер, смотрим туда в местах когда вы хотите контролировать что цикл не будет создан.
Второе, чтобы не болтаться туда сюда несколько раз, цикл проходим один раз с эффективным хешированием узлов, например по мере создания присваиваем узлу номера 0,1,2,3 и т.п. и составляем битовую лукап-таблицу из известных номеров узлов с флагами 1<< номер, смотрим туда в местах когда вы хотите контролировать что цикл не будет создан.А почему вы так уверены, что это точно будет быстрее, чем проверить — нет ли в списке циклов?
Видел одну статью, от которой у меня волосы дыбом встали. Там один погромист открыл для себя что в Java существует не только ArrayList, который он до этого использовал всегда, в независимости от решаемой задачи, но и другие структуры данных. В отличии List, Map и Set он вроде разобрался, хотя разницу между HashMap и TreeMap по-моему так и не осилил. Самое же прекрасное было во фразе, что теперь, когда ему в коде нужен список, он иногда, чтобы не повторяться (sic!), использует LinkedList. Т.е. человек просто так, по велению левой пятки, выбирает структуру данных, которую использует.
Соответственно, на собеседовании я обычно задавал 2 вопроса. Знает ли кандидат отличие ArrayList (по сути resizable array) от LinkedList (нормальный связный список). Если говорил, что знает и мог как-то это отличие описать, то просил пошагово объяснить, как будет происходить get(5) для списка из 10 элементов в одно и во втором случае по его мнению.
К сожалению, людей которые могли это сказать можно было пересчитать по пальцам.
Справедливости ради, этот вопрос не являлся решающим, скорее для понимания общего уровня кандидата.
опубликованное в обильно цитируемой научной статье 1967 года. Вы просите кандидата повторить научное исследование за 30 минут!
Не «научное исследование», а научное исследование 1967 года в 2019. В 2019 это не нечто новое, а уже давно — общее место. И это нормально — знание становится сложнее. Целая куча всего, что тогда было научными исследованиями в наши дни кажется (даже не зная решения) тривиальными (ладно, ладно. Решаемыми) задачками. Тогда это было исследованием лишь потому что это было впервые.
Я писал выше: «Тогда это было исследованием лишь потому что это было впервые.» «Это» здесь — не о конкретном единичном алгоритме.
Добавить — нечего.
Нам, например, ни в техникуме, ни в институте его не давали.
Нам тоже, это как-то не помешало с ходу придумать решение, которое потом оказалось общепринятым.
Ещё одна мораль: из истории можно многому научиться.
Здесь не поспоришь. Вопрос в том, учатся ли?
Любая программа это алгоритм, и даже при написании простых веб формочек возникают ситуации когда это алгоритм становиться не совсем тривиальным. Если человек вообще ничего не понимает в алгоритмах и структурах данных он может там наворотить такого…
И дело не только в производительности, это и о умении декомпозировать сложность.
Это хороший вопрос чтобы понять интересовался ли человек структурами данных и алгоритмами хоть немного.
Почему на собеседованиях так часто спрашивают про связные списки