Как оценивать качество тестов? Многие полагаются на самый популярный показатель, известный всем, — code coverage. Но это количественная, а не качественная метрика. Она показывает, какой объём вашего кода покрыт тестами, но не то, как хорошо эти тесты написаны.
Один из способов разобраться в этом — мутационное тестирование. Этот инструмент, внося небольшие правки в исходный код и заново прогоняя после этого тесты, позволяет выявить бесполезные тесты и низкокачественное покрытие.
На Badoo PHP Meetup в марте я рассказывал, как организовать мутационное тестирование для PHP-кода и с какими проблемами можно столкнуться. Видео доступно по ссылке, а за текстовой версией добро пожаловать под кат.

Чтобы объяснить, что я имею в виду, покажу пару примеров. Они простые, местами утрированные и могут казаться очевидными (хотя реальные примеры обычно довольно сложные и глазами их не увидеть).
Рассмотрим ситуацию: у нас есть элементарная функция, которая утверждает, что некий человек совершеннолетний, и есть тест, который её проверяет. У теста есть dataProvider, то есть он тестирует два случая: возраст 17 лет и возраст 19 лет. Я думаю, для многих из вас очевидно, что isAdult имеет 100%-ное покрытие. Единственная строчка. Тестом она выполняется. Всё замечательно.

Но при более внимательном рассмотрении выяснится, что наш провайдер неудачно написан и не тестирует граничные условия: возраст 18 лет как граничное условие не протестирован. Можно заменить знак > на >=, и тест не поймает такое изменение.
Ещё один пример, чуть более сложный. Есть функция, которая строит некий простой объект, содержащий сеттеры и геттеры. У нас есть три поля, которые мы устанавливаем, и есть тест, который проверяет, что функция buildPromoBlock действительно собирает тот объект, который мы ожидаем.

Если посмотреть внимательнее, у нас также есть setSomething, который ставит какое-то свойство в true. Но в тесте у нас такого ассерта нет. То есть мы можем эту строчку удалить из buildPromoBlock — и наш тест это изменение не поймает. При этом мы имеем 100%-ное покрытие в функции buildPromoBlock, потому что все три строчки были исполнены во время теста.
Эти два примера подводят нас к тому, что такое мутационное тестирование.
Прежде чем разбирать алгоритм, дам короткое определение. Мутационное тестирование — это механизм, который позволяет нам, внося мелкие изменения в код, имитировать действия злобного Буратино или джуниора Васи, который пришёл и начал целенаправленно его ломать, знаки > заменять на <, = на !=, и так далее. Для каждого такого изменения, сделанного нами в благих целях, мы прогоняем тесты, которые должны покрывать изменённую строку.
Если тесты нам ничего не показали если они не упали, то, вероятно, они недостаточно эффективны. Они не тестируют граничные случаи, не содержат ассерты: возможно, их надо улучшить. Если же тесты упали, значит, они классные. Они правда защищают от таких изменений. Следовательно, наш код сложнее сломать.
Теперь давайте разберём алгоритм. Он довольно простой. Первое, что мы делаем для осуществления мутационного тестирования, — берём исходный код. Дальше мы получаем code coverage, чтобы знать, какие тесты выполнять для какой строки. После этого мы пробегаемся по исходному коду и генерируем так называемых мутантов.
Мутант — это единичное изменение кода. То есть мы берём некую функцию, где был знак > в сравнении, в if, меняем этот знак на >= — и получаем мутанта. После этого мы прогоняем тесты. Вот пример мутации (мы заменили > на >=):

При этом мутации делаются не хаотично, а по определённым правилам. Ответ мутационного тестирования идемпотентен. Сколько бы раз мы ни запускали на одном и том же коде мутационное тестирование, оно выдаёт одинаковые результаты.
Последнее, что мы делаем, — прогоняем тесты, которые покрывают мутировавшую строчку. Вытаскиваем это из coverage. Есть инструменты неоптимальные, которые гоняют все тесты. Но хороший инструмент будет прогонять только те, которые необходимо.
После этого мы оцениваем результат. Тесты упали — значит, всё хорошо. Если же не упали, значит, они не очень эффективны.
Какие метрики даёт нам мутационное тестирование? К code coverage оно добавляет ещё три, о которых мы сейчас поговорим.
Но для начала разберём терминологию.

Есть понятие убитых мутантов: это те мутанты, которых «прибили» наши тесты (то есть они их отловили).

Есть понятие escaped mutant (выживших мутантов). Это те мутанты, которым удалось избежать кары (то есть тесты их не поймали).

И есть понятия covered mutant — мутант, покрытый тестами, и обратный ему uncovered мутант, который вообще никаким тестом не покрыт (т.е. у нас есть код, в нём есть бизнес-логика, мы можем её менять, но ни один тест эти изменения не проверяет).
Основной показатель, который нам даёт мутационное тестирование, — MSI (mutation score indicator), отношение количества убитых мутантов к их общему количеству.
Второй показатель — это mutation code coverage. Он как раз является качественным, а не количественным, потому что показывает, какой объём бизнес-логики, которую можно ломать и делать это на регулярной основе, наши тесты отлавливают.
И последний показатель — это covered MSI, то есть более мягкий MSI. В этом случае мы рассчитываем MSI только для тех мутантов, которые были покрыты тестами.
Почему меньше половины программистов слышали об этом инструменте? Почему его не применяют повсеместно?
Первая проблема (одна из главных) — это скорость выполнения мутационного тестирования. В коде, если у нас десятки мутационных операторов, даже для простейшего класса мы можем сгенерировать сотни мутаций. На каждую мутацию нужно будет прогнать тесты. Если у нас, скажем, 5000 юнит-тестов, которые бегают десять минут, мутационное тестирование может занять часы.
Что можно сделать, чтобы это нивелировать? Запускайте тесты параллельно, в несколько потоков. Раскидывайте потоки на несколько машин. Это работает.
Второй способ — инкрементальные прогоны. Незачем каждый раз считать мутационные показатели для всей ветки — можно взять branch diff. Если вы используете фича-бранчи, вам будет легко это сделать: прогнать тесты только по тем файлам, которые изменились, и посмотреть, что у вас в данный момент в мастере творится, сравнить, проанализировать.
Следующая штука, которую можно делать, — это тюнинг мутаций. Так как мутационные операторы можно изменять, можно задавать некие правила, по которым они работают, то можно прекращать выполнение некоторых мутаций, если они заведомо ведут к проблемам.
Важный момент: мутационное тестирование подходит только для юнит-тестов. Несмотря на то, что его можно запустить и для интеграционных тестов, это заведомо провальная идея, потому что интеграционные (как и end-to-end) тесты выполняются гораздо медленнее и затрагивают гораздо больше кода. Вы просто никогда не дождётесь результатов. В принципе, этот механизм придуман и разработан исключительно для модульного тестирования.
Вторая проблема, которая может возникнуть с мутационными тестами, — это так называемые бесконечные мутанты. Например, есть простой код, простой цикл for:

Если заменить i++ на i--, то цикл превратится в бесконечный. Ваш код залипнет надолго. И мутационное тестирование довольно часто генерирует такие мутации.
Первое, что можно сделать, — тюнинг мутации. Очевидно, что менять i++ на i-- в цикле for — это очень плохая идея: в 99% случаев мы будем попадать на бесконечный цикл. Поэтому мы в своём инструменте такое делать запретили.
Второе и главное, что защитит вас от таких проблем, — это тайм-аут для прогона. Например, у того же PHPUnit есть возможность завершить тест по тайм-ауту независимо от того, куда он залип. PHPUnit через PCNTL вешает колбэки и сам считает время. Если тест не выполнился за какой-то период, он просто его прибивает и такой кейс считается убитым мутантом, потому что код, сгенерировавший мутации, действительно проверяется тестом, который действительно ловит проблему, указывая на то, что код стал нерабочим.
Эта проблема существует в теории мутационного тестирования. На практике с ней сталкиваются не очень часто, но знать о ней нужно.
Рассмотрим классический пример, её иллюстрирующий. У нас есть умножение переменной А на -1 и деление А на -1. В общем случае эти операции приводят к одинаковому результату. Мы меняем знак у А. Соответственно, у нас есть мутация, которая позволяет два знака менять между собой. Логика программы такой мутацией не нарушается. Тесты и не должны ее ловить, не должны падать. Из-за таких идентичных мутантов возникают некоторые сложности.
Универсального решения нет — каждый решает эту проблему по-своему. Возможно, поможет какая-то система регистрации мутантов. Мы в Badoo сейчас о чём-то подобном думаем, будем мьютить их.
Есть два известных инструмента для мутационного тестирования: Humbug и Infection. Когда я готовил статью, хотел рассказать о том, какой из них лучше, и прийти к выводу, что это Infection.
Но когда я зашёл на страницу Humbug, то увидел там следующее: Humbug объявил себя устаревшим в пользу Infection. Поэтому часть моей статьи оказалась бессмысленной. Так что Infection — действительно хороший инструмент. Надо сказать спасибо borNfree из Минска, который его создал. Он действительно круто работает. Можно взять его прямо из коробки, через композер поставить и запустить.
Нам действительно понравился Infection. Мы хотели его использовать. Но не смогли по двум причинам. Infection требует code coverage, чтобы правильно и точечно запускать тесты для мутантов. Тут у нас есть два пути. Мы можем посчитать его прямо в рантайме (но у нас 100 000 юнит-тестов). Либо мы можем посчитать его для текущего мастера (но сборка на нашем облаке из десяти очень мощных машин в несколько потоков занимает полтора часа). Если мы будем на каждом мутационном прогоне этим заниматься, наверное, инструмент работать не будет.
Есть вариант скормить готовый, но в формате PHPUnit это куча XML-файлов. Помимо того, что там содержится ценная информация, они тащат за собой кучу структуры, каких-то скобок и прочего. Я посчитал, что в общем случае наш code coverage будет весить порядка 30 Гб, а нам нужно таскать его по всем машинам облака, постоянно читать с диска. В общем, затея так себе.
Вторая проблема оказалась ещё более существенной. У нас есть замечательная библиотека SoftMocks. Она позволяет нам бороться с легаси-кодом, который сложно тестировать, и успешно писать для него тесты. Мы ею активно пользуемся и не собираемся от неё отказываться в ближайшее время, несмотря на то, что новый код пишется у нас так, что SoftMocks нам не требуется. Так вот, эта библиотека несовместима с Infection, потому что они используют практически одинаковый подход к мутированию изменений.
Каким образом работают SoftMocks? Они перехватывают инклуды файлов и подменяют их модифицированными, то есть вместо того чтобы исполнить класс А, SoftMocks создают класс А в другом месте и вместо исходного через инклуд подключают другой. Infection действует точно так же, только он работает через stream_wrapper_register(), который делает то же самое, но на системном уровне. В результате у нас могут работать либо SoftMocks, либо Infection. Так как для наших тестов SoftMocks необходимы, то подружить эти два инструмента очень сложно. Это, наверное, возможно, но в этом случае мы так сильно влезем в Infection, что смысл от таких изменений просто теряется.
Превозмогая трудности, мы написали свой маленький инструмент. Мы позаимствовали мутационные операторы у Infection (они классно написаны и ими очень легко пользоваться). Вместо того чтобы запускать мутации через stream_wrapper_register(), мы запускаем их через SoftMocks, то есть из коробки используем наш инструмент. Наша тулза дружит с нашим внутренним сервисом code coverage. То есть она по требованию может получать coverage для файла или для строки без прогона всех тестов, что происходит очень быстро. При этом она простая. Если у Infection есть куча всяких инструментов и возможностей (например, запуск в несколько потоков), то в нашей ничего такого нет. Но мы используем нашу внутреннюю инфраструктуру, чтобы нивелировать этот недостаток. Например, тот же запуск тестов в несколько потоков мы осуществляем через наше облако.
Как мы это используем?
Первое — ручной прогон. Это первое, что надо сделать. Все тесты, которые вы пишете, вручную проверить мутационным тестированием. Выглядит это примерно так:
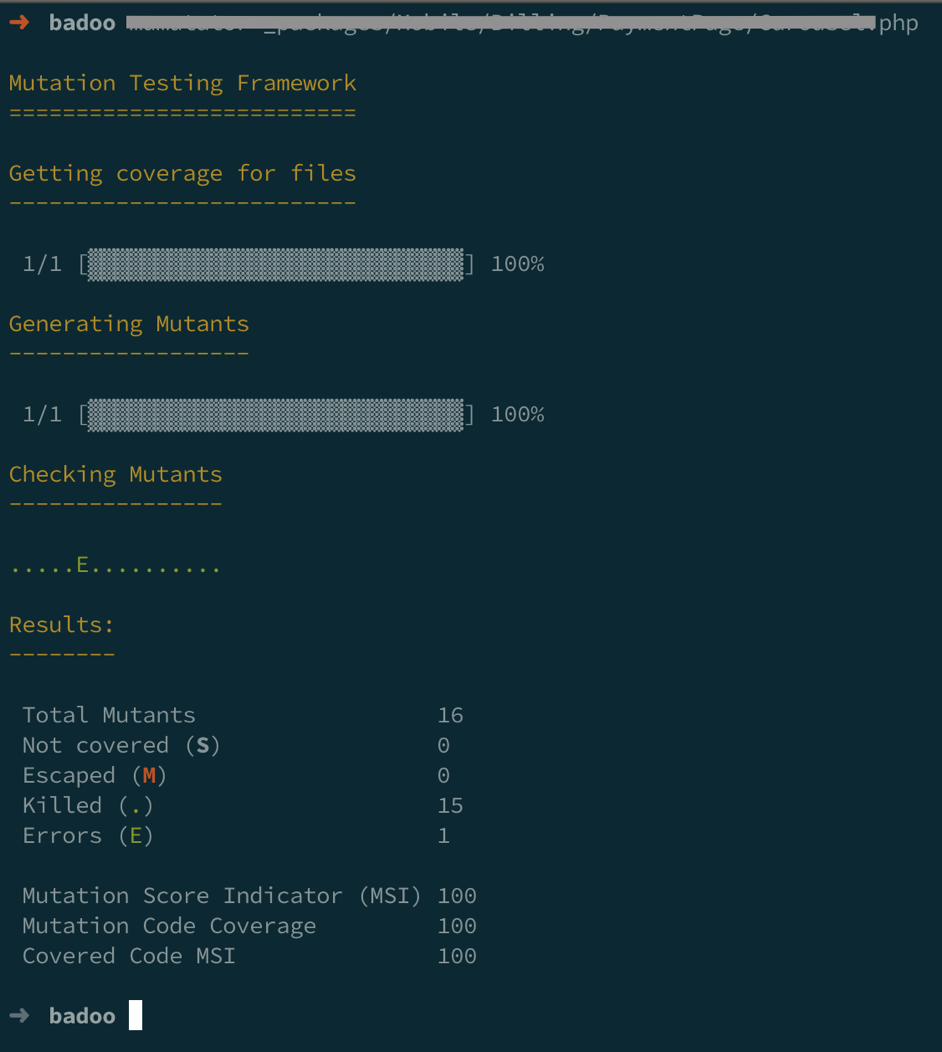
Я запустил мутационный тест для какого-то файлика. Получил результат: 16 мутантов. Из них 15 были убиты тестами, и один упал с ошибкой. Я не сказал о том, что мутации могут сгенерировать фатал. Мы легко можем что-то изменить: сделать так, чтобы возвращаемый тип стал невалиден, или ещё что-то. Такое возможно, это считается убитым мутантом, потому что наш тест начнёт падать.
Тем не менее Infection выделяет таких мутантов в отдельную категорию по той причине, что иногда на ошибки стоит обратить особое внимание. Бывает, что происходит что-то странное — и мутант не совсем правильно считается убитым.
Вторая штука, которую мы используем, — это отчёт по мастеру. Раз в сутки, ночью, когда наша девельная инфраструктура простаивает, мы генерируем отчёт по code coverage. После этого мы делаем такой же отчёт по мутационному тестированию. Выглядит это так:

Если вы хоть раз смотрели в отчёт по code coverage PHPUnit, то наверняка заметили, что интерфейс похожий, потому что мы сделали свой инструмент по аналогии. Он просто для какого-то конкретного файлика в какой-то директории посчитал все ключевые показатели. Мы также заложили определённые цели (на самом деле, мы взяли их с потолка и пока не соблюдаем, так как ещё не решили, на какие цели стоит ориентироваться по каждой метрике, но они существуют, чтобы в будущем можно было легко строить отчёты).
И последняя штука, самая важная, которая является следствием двух других. Программисты — люди ленивые. Я ленивый: я люблю, чтобы всё работало и мне при этом не надо было совершать лишних телодвижений. Мы сделали так, что, когда разработчик пушит свою ветку, автоматически инкрементально считаются показатели его ветки и бранч-мастера.
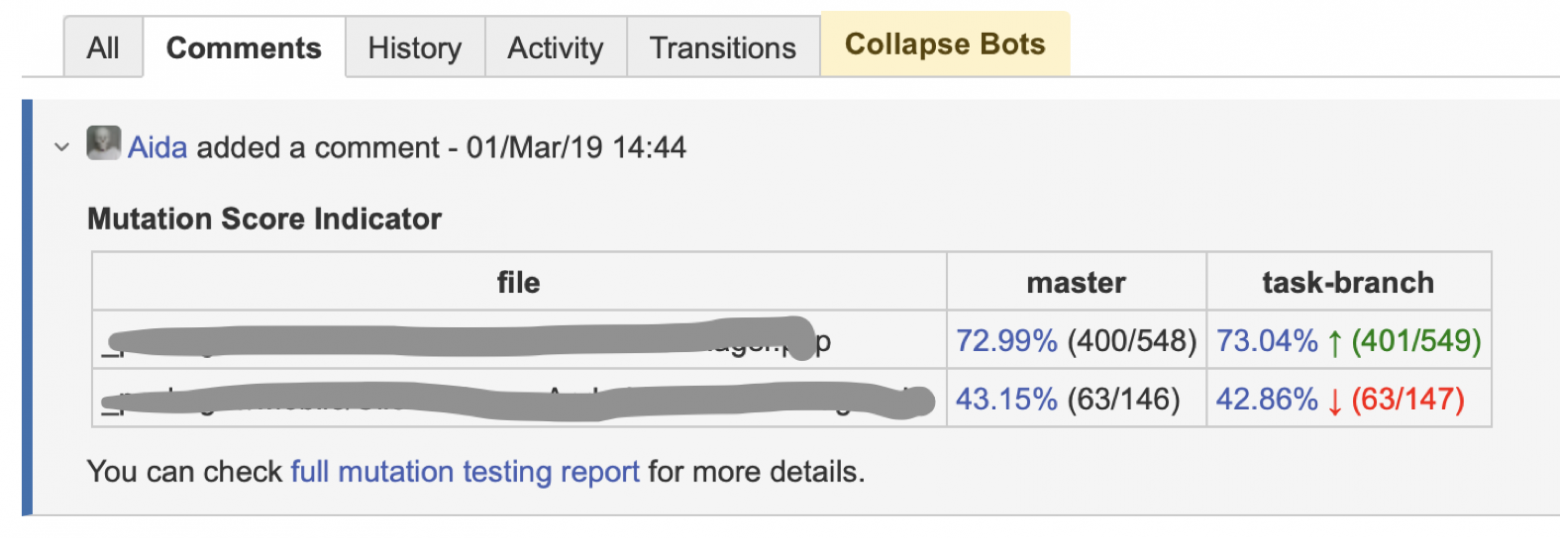
Например, я запушил два файла и получил такой результат. В мастере у меня было 548 мутантов, убито 400. По другому файлу — 147 против 63. В моей ветке количество мутантов в обоих случаях прибавилось. Но в первом файле мутант был прибит, а во втором — он сбежал. Естественно, показатель MSI упал. Такая штука позволяет даже людям, которые не хотят тратить время, запускать мутационное тестирование руками, видеть, что они сделали хуже, и обращать на это внимание (ровно так же, как это делают ревьюеры в процессе code review).
Пока сложно привести какие-то цифры: у нас не было никакого показателя, теперь он появился, но сравнивать не с чем.
Могу сказать, что мутационное тестирование даёт в плане психологического эффекта. Если вы начинаете свои тесты прогонять через мутационное тестирование, вы невольно начинаете писать более качественные тесты, а написание качественных тестов неотвратимо ведет к изменению манеры написания кода – вы начинаете думать о том, что вам нужно покрыть все кейсы, которые можно сломать, вы начинаете его лучше структурировать, делать более тестируемым.
Это исключительно субъективное мнение. Но некоторые из моих коллег давали примерно такой же фидбэк: когда они начали постоянно использовать в работе мутационное тестирование, они стали лучше писать тесты, а многие говорили и о том, что начали лучше писать код.
Code coverage — это важная метрика, её надо отслеживать. Но этот показатель ничего не гарантирует: он не говорит о том, что вы в безопасности.
Мутационное тестирование поможет сделать ваши юнит-тесты лучше, а отслеживание code coverage — осмысленнее. Для PHP уже есть инструмент, так что если у вас небольшой проект без заморочек, то прямо сегодня берите и пробуйте.
Начните хотя бы с прогона мутационных тестов вручную. Сделайте этот простой шаг и посмотрите, что вам это даст. Уверен, что вам понравится.
Один из способов разобраться в этом — мутационное тестирование. Этот инструмент, внося небольшие правки в исходный код и заново прогоняя после этого тесты, позволяет выявить бесполезные тесты и низкокачественное покрытие.
На Badoo PHP Meetup в марте я рассказывал, как организовать мутационное тестирование для PHP-кода и с какими проблемами можно столкнуться. Видео доступно по ссылке, а за текстовой версией добро пожаловать под кат.
Что такое мутационное тестирование
Чтобы объяснить, что я имею в виду, покажу пару примеров. Они простые, местами утрированные и могут казаться очевидными (хотя реальные примеры обычно довольно сложные и глазами их не увидеть).
Рассмотрим ситуацию: у нас есть элементарная функция, которая утверждает, что некий человек совершеннолетний, и есть тест, который её проверяет. У теста есть dataProvider, то есть он тестирует два случая: возраст 17 лет и возраст 19 лет. Я думаю, для многих из вас очевидно, что isAdult имеет 100%-ное покрытие. Единственная строчка. Тестом она выполняется. Всё замечательно.
Но при более внимательном рассмотрении выяснится, что наш провайдер неудачно написан и не тестирует граничные условия: возраст 18 лет как граничное условие не протестирован. Можно заменить знак > на >=, и тест не поймает такое изменение.
Ещё один пример, чуть более сложный. Есть функция, которая строит некий простой объект, содержащий сеттеры и геттеры. У нас есть три поля, которые мы устанавливаем, и есть тест, который проверяет, что функция buildPromoBlock действительно собирает тот объект, который мы ожидаем.
Если посмотреть внимательнее, у нас также есть setSomething, который ставит какое-то свойство в true. Но в тесте у нас такого ассерта нет. То есть мы можем эту строчку удалить из buildPromoBlock — и наш тест это изменение не поймает. При этом мы имеем 100%-ное покрытие в функции buildPromoBlock, потому что все три строчки были исполнены во время теста.
Эти два примера подводят нас к тому, что такое мутационное тестирование.
Прежде чем разбирать алгоритм, дам короткое определение. Мутационное тестирование — это механизм, который позволяет нам, внося мелкие изменения в код, имитировать действия злобного Буратино или джуниора Васи, который пришёл и начал целенаправленно его ломать, знаки > заменять на <, = на !=, и так далее. Для каждого такого изменения, сделанного нами в благих целях, мы прогоняем тесты, которые должны покрывать изменённую строку.
Если тесты нам ничего не показали если они не упали, то, вероятно, они недостаточно эффективны. Они не тестируют граничные случаи, не содержат ассерты: возможно, их надо улучшить. Если же тесты упали, значит, они классные. Они правда защищают от таких изменений. Следовательно, наш код сложнее сломать.
Теперь давайте разберём алгоритм. Он довольно простой. Первое, что мы делаем для осуществления мутационного тестирования, — берём исходный код. Дальше мы получаем code coverage, чтобы знать, какие тесты выполнять для какой строки. После этого мы пробегаемся по исходному коду и генерируем так называемых мутантов.
Мутант — это единичное изменение кода. То есть мы берём некую функцию, где был знак > в сравнении, в if, меняем этот знак на >= — и получаем мутанта. После этого мы прогоняем тесты. Вот пример мутации (мы заменили > на >=):
При этом мутации делаются не хаотично, а по определённым правилам. Ответ мутационного тестирования идемпотентен. Сколько бы раз мы ни запускали на одном и том же коде мутационное тестирование, оно выдаёт одинаковые результаты.
Последнее, что мы делаем, — прогоняем тесты, которые покрывают мутировавшую строчку. Вытаскиваем это из coverage. Есть инструменты неоптимальные, которые гоняют все тесты. Но хороший инструмент будет прогонять только те, которые необходимо.
После этого мы оцениваем результат. Тесты упали — значит, всё хорошо. Если же не упали, значит, они не очень эффективны.
Метрики
Какие метрики даёт нам мутационное тестирование? К code coverage оно добавляет ещё три, о которых мы сейчас поговорим.
Но для начала разберём терминологию.
Есть понятие убитых мутантов: это те мутанты, которых «прибили» наши тесты (то есть они их отловили).
Есть понятие escaped mutant (выживших мутантов). Это те мутанты, которым удалось избежать кары (то есть тесты их не поймали).
И есть понятия covered mutant — мутант, покрытый тестами, и обратный ему uncovered мутант, который вообще никаким тестом не покрыт (т.е. у нас есть код, в нём есть бизнес-логика, мы можем её менять, но ни один тест эти изменения не проверяет).
Основной показатель, который нам даёт мутационное тестирование, — MSI (mutation score indicator), отношение количества убитых мутантов к их общему количеству.
Второй показатель — это mutation code coverage. Он как раз является качественным, а не количественным, потому что показывает, какой объём бизнес-логики, которую можно ломать и делать это на регулярной основе, наши тесты отлавливают.
И последний показатель — это covered MSI, то есть более мягкий MSI. В этом случае мы рассчитываем MSI только для тех мутантов, которые были покрыты тестами.
Проблемы с мутационным тестированием
Почему меньше половины программистов слышали об этом инструменте? Почему его не применяют повсеместно?
Низкая скорость
Первая проблема (одна из главных) — это скорость выполнения мутационного тестирования. В коде, если у нас десятки мутационных операторов, даже для простейшего класса мы можем сгенерировать сотни мутаций. На каждую мутацию нужно будет прогнать тесты. Если у нас, скажем, 5000 юнит-тестов, которые бегают десять минут, мутационное тестирование может занять часы.
Что можно сделать, чтобы это нивелировать? Запускайте тесты параллельно, в несколько потоков. Раскидывайте потоки на несколько машин. Это работает.
Второй способ — инкрементальные прогоны. Незачем каждый раз считать мутационные показатели для всей ветки — можно взять branch diff. Если вы используете фича-бранчи, вам будет легко это сделать: прогнать тесты только по тем файлам, которые изменились, и посмотреть, что у вас в данный момент в мастере творится, сравнить, проанализировать.
Следующая штука, которую можно делать, — это тюнинг мутаций. Так как мутационные операторы можно изменять, можно задавать некие правила, по которым они работают, то можно прекращать выполнение некоторых мутаций, если они заведомо ведут к проблемам.
Важный момент: мутационное тестирование подходит только для юнит-тестов. Несмотря на то, что его можно запустить и для интеграционных тестов, это заведомо провальная идея, потому что интеграционные (как и end-to-end) тесты выполняются гораздо медленнее и затрагивают гораздо больше кода. Вы просто никогда не дождётесь результатов. В принципе, этот механизм придуман и разработан исключительно для модульного тестирования.
Бесконечные мутанты
Вторая проблема, которая может возникнуть с мутационными тестами, — это так называемые бесконечные мутанты. Например, есть простой код, простой цикл for:
Если заменить i++ на i--, то цикл превратится в бесконечный. Ваш код залипнет надолго. И мутационное тестирование довольно часто генерирует такие мутации.
Первое, что можно сделать, — тюнинг мутации. Очевидно, что менять i++ на i-- в цикле for — это очень плохая идея: в 99% случаев мы будем попадать на бесконечный цикл. Поэтому мы в своём инструменте такое делать запретили.
Второе и главное, что защитит вас от таких проблем, — это тайм-аут для прогона. Например, у того же PHPUnit есть возможность завершить тест по тайм-ауту независимо от того, куда он залип. PHPUnit через PCNTL вешает колбэки и сам считает время. Если тест не выполнился за какой-то период, он просто его прибивает и такой кейс считается убитым мутантом, потому что код, сгенерировавший мутации, действительно проверяется тестом, который действительно ловит проблему, указывая на то, что код стал нерабочим.
Идентичные мутанты
Эта проблема существует в теории мутационного тестирования. На практике с ней сталкиваются не очень часто, но знать о ней нужно.
Рассмотрим классический пример, её иллюстрирующий. У нас есть умножение переменной А на -1 и деление А на -1. В общем случае эти операции приводят к одинаковому результату. Мы меняем знак у А. Соответственно, у нас есть мутация, которая позволяет два знака менять между собой. Логика программы такой мутацией не нарушается. Тесты и не должны ее ловить, не должны падать. Из-за таких идентичных мутантов возникают некоторые сложности.
Универсального решения нет — каждый решает эту проблему по-своему. Возможно, поможет какая-то система регистрации мутантов. Мы в Badoo сейчас о чём-то подобном думаем, будем мьютить их.
Это теория. А что в PHP?
Есть два известных инструмента для мутационного тестирования: Humbug и Infection. Когда я готовил статью, хотел рассказать о том, какой из них лучше, и прийти к выводу, что это Infection.
Но когда я зашёл на страницу Humbug, то увидел там следующее: Humbug объявил себя устаревшим в пользу Infection. Поэтому часть моей статьи оказалась бессмысленной. Так что Infection — действительно хороший инструмент. Надо сказать спасибо borNfree из Минска, который его создал. Он действительно круто работает. Можно взять его прямо из коробки, через композер поставить и запустить.
Нам действительно понравился Infection. Мы хотели его использовать. Но не смогли по двум причинам. Infection требует code coverage, чтобы правильно и точечно запускать тесты для мутантов. Тут у нас есть два пути. Мы можем посчитать его прямо в рантайме (но у нас 100 000 юнит-тестов). Либо мы можем посчитать его для текущего мастера (но сборка на нашем облаке из десяти очень мощных машин в несколько потоков занимает полтора часа). Если мы будем на каждом мутационном прогоне этим заниматься, наверное, инструмент работать не будет.
Есть вариант скормить готовый, но в формате PHPUnit это куча XML-файлов. Помимо того, что там содержится ценная информация, они тащат за собой кучу структуры, каких-то скобок и прочего. Я посчитал, что в общем случае наш code coverage будет весить порядка 30 Гб, а нам нужно таскать его по всем машинам облака, постоянно читать с диска. В общем, затея так себе.
Вторая проблема оказалась ещё более существенной. У нас есть замечательная библиотека SoftMocks. Она позволяет нам бороться с легаси-кодом, который сложно тестировать, и успешно писать для него тесты. Мы ею активно пользуемся и не собираемся от неё отказываться в ближайшее время, несмотря на то, что новый код пишется у нас так, что SoftMocks нам не требуется. Так вот, эта библиотека несовместима с Infection, потому что они используют практически одинаковый подход к мутированию изменений.
Каким образом работают SoftMocks? Они перехватывают инклуды файлов и подменяют их модифицированными, то есть вместо того чтобы исполнить класс А, SoftMocks создают класс А в другом месте и вместо исходного через инклуд подключают другой. Infection действует точно так же, только он работает через stream_wrapper_register(), который делает то же самое, но на системном уровне. В результате у нас могут работать либо SoftMocks, либо Infection. Так как для наших тестов SoftMocks необходимы, то подружить эти два инструмента очень сложно. Это, наверное, возможно, но в этом случае мы так сильно влезем в Infection, что смысл от таких изменений просто теряется.
Превозмогая трудности, мы написали свой маленький инструмент. Мы позаимствовали мутационные операторы у Infection (они классно написаны и ими очень легко пользоваться). Вместо того чтобы запускать мутации через stream_wrapper_register(), мы запускаем их через SoftMocks, то есть из коробки используем наш инструмент. Наша тулза дружит с нашим внутренним сервисом code coverage. То есть она по требованию может получать coverage для файла или для строки без прогона всех тестов, что происходит очень быстро. При этом она простая. Если у Infection есть куча всяких инструментов и возможностей (например, запуск в несколько потоков), то в нашей ничего такого нет. Но мы используем нашу внутреннюю инфраструктуру, чтобы нивелировать этот недостаток. Например, тот же запуск тестов в несколько потоков мы осуществляем через наше облако.
Как мы это используем?
Первое — ручной прогон. Это первое, что надо сделать. Все тесты, которые вы пишете, вручную проверить мутационным тестированием. Выглядит это примерно так:
Я запустил мутационный тест для какого-то файлика. Получил результат: 16 мутантов. Из них 15 были убиты тестами, и один упал с ошибкой. Я не сказал о том, что мутации могут сгенерировать фатал. Мы легко можем что-то изменить: сделать так, чтобы возвращаемый тип стал невалиден, или ещё что-то. Такое возможно, это считается убитым мутантом, потому что наш тест начнёт падать.
Тем не менее Infection выделяет таких мутантов в отдельную категорию по той причине, что иногда на ошибки стоит обратить особое внимание. Бывает, что происходит что-то странное — и мутант не совсем правильно считается убитым.
Вторая штука, которую мы используем, — это отчёт по мастеру. Раз в сутки, ночью, когда наша девельная инфраструктура простаивает, мы генерируем отчёт по code coverage. После этого мы делаем такой же отчёт по мутационному тестированию. Выглядит это так:
Если вы хоть раз смотрели в отчёт по code coverage PHPUnit, то наверняка заметили, что интерфейс похожий, потому что мы сделали свой инструмент по аналогии. Он просто для какого-то конкретного файлика в какой-то директории посчитал все ключевые показатели. Мы также заложили определённые цели (на самом деле, мы взяли их с потолка и пока не соблюдаем, так как ещё не решили, на какие цели стоит ориентироваться по каждой метрике, но они существуют, чтобы в будущем можно было легко строить отчёты).
И последняя штука, самая важная, которая является следствием двух других. Программисты — люди ленивые. Я ленивый: я люблю, чтобы всё работало и мне при этом не надо было совершать лишних телодвижений. Мы сделали так, что, когда разработчик пушит свою ветку, автоматически инкрементально считаются показатели его ветки и бранч-мастера.
Например, я запушил два файла и получил такой результат. В мастере у меня было 548 мутантов, убито 400. По другому файлу — 147 против 63. В моей ветке количество мутантов в обоих случаях прибавилось. Но в первом файле мутант был прибит, а во втором — он сбежал. Естественно, показатель MSI упал. Такая штука позволяет даже людям, которые не хотят тратить время, запускать мутационное тестирование руками, видеть, что они сделали хуже, и обращать на это внимание (ровно так же, как это делают ревьюеры в процессе code review).
Результаты
Пока сложно привести какие-то цифры: у нас не было никакого показателя, теперь он появился, но сравнивать не с чем.
Могу сказать, что мутационное тестирование даёт в плане психологического эффекта. Если вы начинаете свои тесты прогонять через мутационное тестирование, вы невольно начинаете писать более качественные тесты, а написание качественных тестов неотвратимо ведет к изменению манеры написания кода – вы начинаете думать о том, что вам нужно покрыть все кейсы, которые можно сломать, вы начинаете его лучше структурировать, делать более тестируемым.
Это исключительно субъективное мнение. Но некоторые из моих коллег давали примерно такой же фидбэк: когда они начали постоянно использовать в работе мутационное тестирование, они стали лучше писать тесты, а многие говорили и о том, что начали лучше писать код.
Выводы
Code coverage — это важная метрика, её надо отслеживать. Но этот показатель ничего не гарантирует: он не говорит о том, что вы в безопасности.
Мутационное тестирование поможет сделать ваши юнит-тесты лучше, а отслеживание code coverage — осмысленнее. Для PHP уже есть инструмент, так что если у вас небольшой проект без заморочек, то прямо сегодня берите и пробуйте.
Начните хотя бы с прогона мутационных тестов вручную. Сделайте этот простой шаг и посмотрите, что вам это даст. Уверен, что вам понравится.
