
Хочешь узнать, какая ситуация на рынке труда, особенно в области "дата-сайенс"?
Если знаешь Python и Pandas, парсинг Хедхантера это кажется один с самый надежных и легких способов.
Код работает на Python3.6 и Pandas 0.24.2
Ipython можно скачать здесь.
Чтобы проверить версию Pandas(Linux/MacOS) console:
ipython
И потом в командной строке
#ipython import pandas as pd pd.__version__
#Если нет подходящей версии(консоль) pip install pandas==0.24.2
Уже все настроили? Поехали!
Парсим на Python
HH позволяет найти работу в России. Данный рекрутинговый ресурс обладает самой большой базой данных вакансий. HH делится удобным api.
Немного погуглил и вот получилось написать парсер.
#код в ссылке https://gist.github.com/fuwiak/9c695b51c33b2e052c5a721383705a9c #код с ссылки запускаем так(BASH) python3 hh_parser.py import requests import pandas as pd number_of_pages = 100 #number_of_ads = number_of_pages * per_page job_title = ["'Data Analyst' and 'data scientist'"] for job in job_title: data=[] for i in range(number_of_pages): url = 'https://api.hh.ru/vacancies' par = {'text': job, 'area':'113','per_page':'10', 'page':i} r = requests.get(url, params=par) e=r.json() data.append(e) vacancy_details = data[0]['items'][0].keys() df = pd.DataFrame(columns= list(vacancy_details)) ind = 0 for i in range(len(data)): for j in range(len(data[i]['items'])): df.loc[ind] = data[i]['items'][j] ind+=1 csv_name = job+".csv" df.to_csv(csv_name)
В итоге мы получили файл csv с названием указанным в job_title.
В указанном будет загружен один файл с вакансиями с фразой
«Data Analyst» и «data scientist». Если хотите отдельно поменяйте строку на
job_title=['Data Analyst', 'Data Scientist']
Тогда вы получаете 2 файла с этими названиями.
Что интересно, есть и другие операторы кроме «and». С их помощью можно искать точные совпадения. Подробнее по ссылке.
What time is it? Its Pandas Time!
Собранные таким образом объявления будут разделены на группы в соответствии с информацией содержащейся в них или описанием их метаданных. Например: город; позиция; вилка зарплаты; категория вакансии. В этом случае одно объявление может принадлежать нескольким категориям.
Сейчас займусь данным, которые связанны с позицией "data scientist", используя jupyter-notebook. https://jupyter.org/
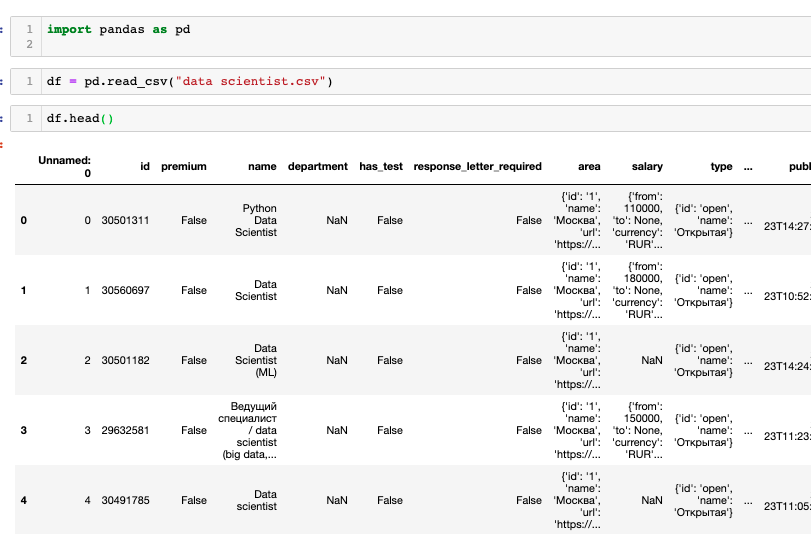
Что делать, чтобы поменять название колонки “Unnamed”?
Самый главный вопрос — ЗП
import ast # run code from string for example ast.literal_eval("1+1") salaries = df.salary.dropna() # remove all NA's from dataframe currencies = [ast.literal_eval(salaries.iloc[i])['currency'] for i in range(len(salaries))] curr = set(currencies) #{'EUR', 'RUR', 'USD'} #divide dataframe salararies by currency rur = [ast.literal_eval(salaries.iloc[i]) for i in range(len(salaries)) if ast.literal_eval(salaries.iloc[i])['currency']=='RUR'] eur = [ast.literal_eval(salaries.iloc[i]) for i in range(len(salaries)) if ast.literal_eval(salaries.iloc[i])['currency']=='EUR'] usd = [ast.literal_eval(salaries.iloc[i]) for i in range(len(salaries)) if ast.literal_eval(salaries.iloc[i])['currency']=='USD']
Получилось разделить зарплаты на валюты, самостоятельно сможете попробовать сделать анализ например только для евро. Я займусь сейчас только рублевыми зарплатами
fr = [x['from'] for x in rur] # lower range of salary fr = list(filter(lambda x: x is not None, fr)) # remove NA's from lower range [0, 100, 200,...] to = [x['to'] for x in rur] #upper range of salary to = list(filter(lambda x: x is not None, to)) #remove NA's from upper range [100, 200, 300,...] import numpy as np salary_range = list(zip(fr, to)) # concatenate upper and lower range [(0,100), (100, 200), (200, 300)...] av = map(np.mean, salary_range) # convert [(0,100), (100, 200), (200, 300)...] to [50, 150, 250,...] av = round(np.mean(list(av)),1) # average value from [50, 150, 250,...] print("average salary as Data Scientist ", av, "rubles")
Наконец-то узнали, около 150 тыс рублей, как ожидаемо.
Для средней зарплаты у меня были такие условия:
- не считал вакансии, в которых нет указанной зарплаты (df.salary.dropna)
- взял только зарплаты в рублях
- если была вилка, тогда взял среднее значение (например, вилка от 10000 rub до 20000 rub → 15000 rub).
Троллям, слабоумным и любителям искать тайный смысл скажу следующее: я не являюсь сотрудником компании hh.ru; эта статья не является рекламой; я не получил за неё ни копейки. Всем удачи.
Бонус
Как востребованы в области "Data Science" джуны?
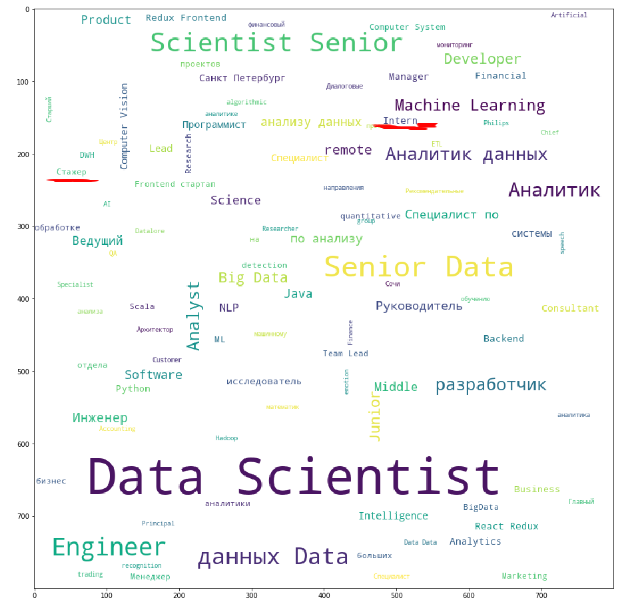
from collections import Counter vacancy_names = df.name # change here to change source of data/words etc cloud = Counter(vacancy_names) from wordcloud import WordCloud, STOPWORDS stopwords = set(STOPWORDS) cloud = '' for x in list(vacancy_names): cloud+=x+' ' wordcloud = WordCloud(width = 800, height = 800, stopwords = stopwords, min_font_size = 8,background_color='white' ).generate(cloud) import matplotlib.pylab as plt plt.figure(figsize = (16, 16)) plt.imshow(wordcloud) plt.savefig('vacancy_cloud.png')
[REPO] (https://github.com/fuwiak/HH)
EDIT:
Версия пользователя zoldaten
Парсер hh
Код не авторский, кроме некоторых костылей.
# !/usr/bin/python3 # -*- coding: utf-8 -*- import sys import xlsxwriter # pip install XlsxWriter import requests # pip install requests from bs4 import BeautifulSoup as bs # pip install beautifulsoup4 headers = {'accept': '*/*', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'} vacancy = input('Укажите название вакансии: ') base_url = f'https://hh.ru/search/vacancy?area=1&search_period=30&text={vacancy}&page=' # area=1 - Москва, search_period=3 - За 30 последних дня pages = int(input('Укажите кол-во страниц для парсинга: ')) #Юрист+юрисконсульт jobs =[] def hh_parse(base_url, headers): zero = 0 while pages > zero: zero = str(zero) session = requests.Session() request = session.get(base_url + zero, headers = headers) if request.status_code == 200: soup = bs(request.content, 'html.parser') divs = soup.find_all('div', attrs = {'data-qa': 'vacancy-serp__vacancy'}) for div in divs: title = div.find('a', attrs = {'data-qa': 'vacancy-serp__vacancy-title'}).text compensation = div.find('div', attrs={'data-qa': 'vacancy-serp__vacancy-compensation'}) if compensation == None: # Если зарплата не указана compensation = 'None' else: compensation = div.find('div', attrs={'data-qa': 'vacancy-serp__vacancy-compensation'}).text href = div.find('a', attrs = {'data-qa': 'vacancy-serp__vacancy-title'})['href'] try: company = div.find('a', attrs = {'data-qa': 'vacancy-serp__vacancy-employer'}).text except: company = 'None' text1 = div.find('div', attrs = {'data-qa': 'vacancy-serp__vacancy_snippet_responsibility'}).text text2 = div.find('div', attrs = {'data-qa': 'vacancy-serp__vacancy_snippet_requirement'}).text content = text1 + ' ' + text2 all_txt = [title, compensation, company, content, href] jobs.append(all_txt) zero = int(zero) zero += 1 else: print('error') # Запись в Excel файл workbook = xlsxwriter.Workbook('Vacancy.xlsx') worksheet = workbook.add_worksheet() # Добавим стили форматирования bold = workbook.add_format({'bold': 1}) bold.set_align('center') center_H_V = workbook.add_format() center_H_V.set_align('center') center_H_V.set_align('vcenter') center_V = workbook.add_format() center_V.set_align('vcenter') cell_wrap = workbook.add_format() cell_wrap.set_text_wrap() # Настройка ширины колонок worksheet.set_column(0, 0, 35) # A https://xlsxwriter.readthedocs.io/worksheet.html#set_column worksheet.set_column(1, 1, 20) # B worksheet.set_column(2, 2, 40) # C worksheet.set_column(3, 3, 135) # D worksheet.set_column(4, 4, 45) # E worksheet.write('A1', 'Наименование', bold) worksheet.write('B1', 'Зарплата', bold) worksheet.write('C1', 'Компания', bold) worksheet.write('D1', 'Описание', bold) worksheet.write('E1', 'Ссылка', bold) row = 1 col = 0 for i in jobs: worksheet.write_string (row, col, i[0], center_V) worksheet.write_string (row, col + 1, i[1], center_H_V) worksheet.write_string (row, col + 2, i[2], center_H_V) worksheet.write_string (row, col + 3, i[3], cell_wrap) # worksheet.write_url (row, col + 4, i[4], center_H_V) worksheet.write_url (row, col + 4, i[4]) row += 1 print('OK') workbook.close() hh_parse(base_url, headers)
