В продолжении серии постов о конвертации текстовых файлов в xml с использованием С# предлагаю перейти к конвертации файлов формата rtf.
Казалось бы, данный формат довольно древний, причем весьма распространенный и, если для него и нет какой-то библиотеки для преобразования всех данных в формат xml путем вызова одного метода, то уж какое-то решение от Microsoft точно должно быть, хотя бы аналогичное OpenXML. Однако, если бы было оно так, то данная статья не была бы написана.
Итак, что из себя представляет файл формата ReachTextFile (rtf)? По большому счету, содержимое файла уже структурировано и синтаксически чем-то даже напоминает смесь json, xml и xpath. В этом легко убедиться сохранив какой-нибудь вордовский документ в формате rtf, а потом попробовать его прочитать в текстовом редакторе типа Notepad++:

Я выделил красным кусок файла, в котором содержится информация о кодировке: в общем, теги зашифрованы кодировкой ansi, а сам текст кодировкой ansicpg1251. Сам же текст выглядит так:
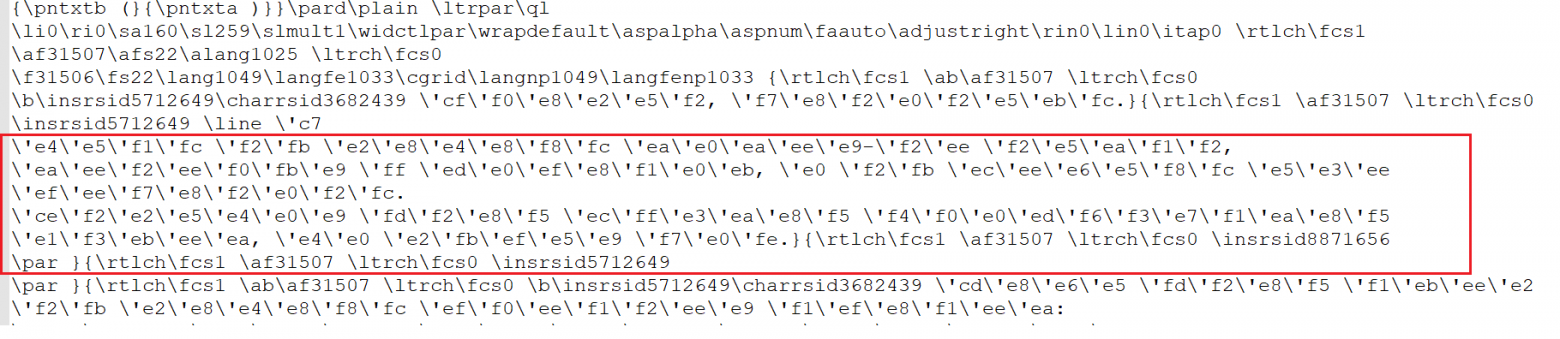
Короче, конечно, по тегам возможно понять, где начинается нужный текст, потом его посимвольно обработать… И, в принципе, даже есть очень хорошая и подробная статья, в которой описано как это можно сделать, правда на php.
В общем, при наличии достаточного количества свободного времени, чугунного сидалища, капель Визин и этилосодержащего пойла, разобраться, конечно, можно, но вряд ли бизнес предоставит Вам все необходимые условия для этого. Поэтому давайте посмотрим в сторону каких-нибудь готовых решений.
Первое, что приходит на ум, и что подсказывает гугол, это открытие rtf с помощью RichTextBox, однако этот подход имеет ряд недостатков:
- Во-первых, это заставляет нас подключать
Windows.Forms, что совершенно не нужным образом раздувает наше приложение. - Во-вторых, такой подход не позволит нам полноценно работать с документом. Так,
RichTextBoxвсе содержимое документа приведет к простому тексту, а ячейки таблицы разделит не тегами, а табами и пробелами.
Поэтому, предлагаю через nuget подключить библиотеку RtfPipe. Подробно изучить эту либу можно здесь.
Библиотека RtfPipe призвана решать одну единственную задачу. Она конвертирует содержимое rtf в html. После этого нам остается только почистить получившуюся строку от ненужных тегов, что делается достаточно легко с помощью того же HtmlAgilityPack.
Спросите, зачем так все усложнять и почему нельзя как-то попроще? На что я отвечу: я устал, я ухожу а вот нет более простых бесплатных решений, ну или, во всяком случае, я их не нашел. А писать свою собственную библиотеку, которая будет считывать каждый rtf-файл посимвольно, проверяя, что за тег встретился и не является ли он полезным символом, дешифровывать его в нужной кодировке, а потом еще и оборачивать в нужные теги — это, извините, уж совсем не тривиальная задача, требующая совершенно других, и скорее всего совершенно не обоснованных, затрат времени и денег.
Итак, перейдем к коду.
public string Convert(Stream stream)
{
stream.Position = 0;
string rtf = string.Empty;
using (StreamReader sr = new StreamReader(stream))
{
rtf = sr.ReadToEnd();
}
// Эта строчка необходима для работы RtfPipe в Core
Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);
// С помощью либы RtfPipe создаем html
var html = Rtf.ToHtml(rtf);
// очищаем html от лишних тегов и атрибутов, возвращем готовую xml
return ClearHtml(html);
}- Считываем данные из потока в переменную типа string. Это необходимо для работы с библиотекой
RtfPipe. К сожалению, в ней не реализована возможность передать поток в качестве аргумента - Далее, если наше приложение собирается под .Net Core обязательно вставляем вот эту строку
Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);. Об этом прямо написано в репозитории библиотеки RtfPipe. Можете убедиться перейдя по ссылке.
Если Вы используете .Net Framework, то от наличия или отсутствия данной строки ничего не изменится. var html = Rtf.ToHtml(rtf);— в этом месте мы получаем строку с вполне приличной html разметкой. Однако, если посмотрите в отладчике, то увидите большое количество информации в тегах, которая не только не нужна (если необходимо получить только структурированное содержимое), но и может затруднять восприятие.
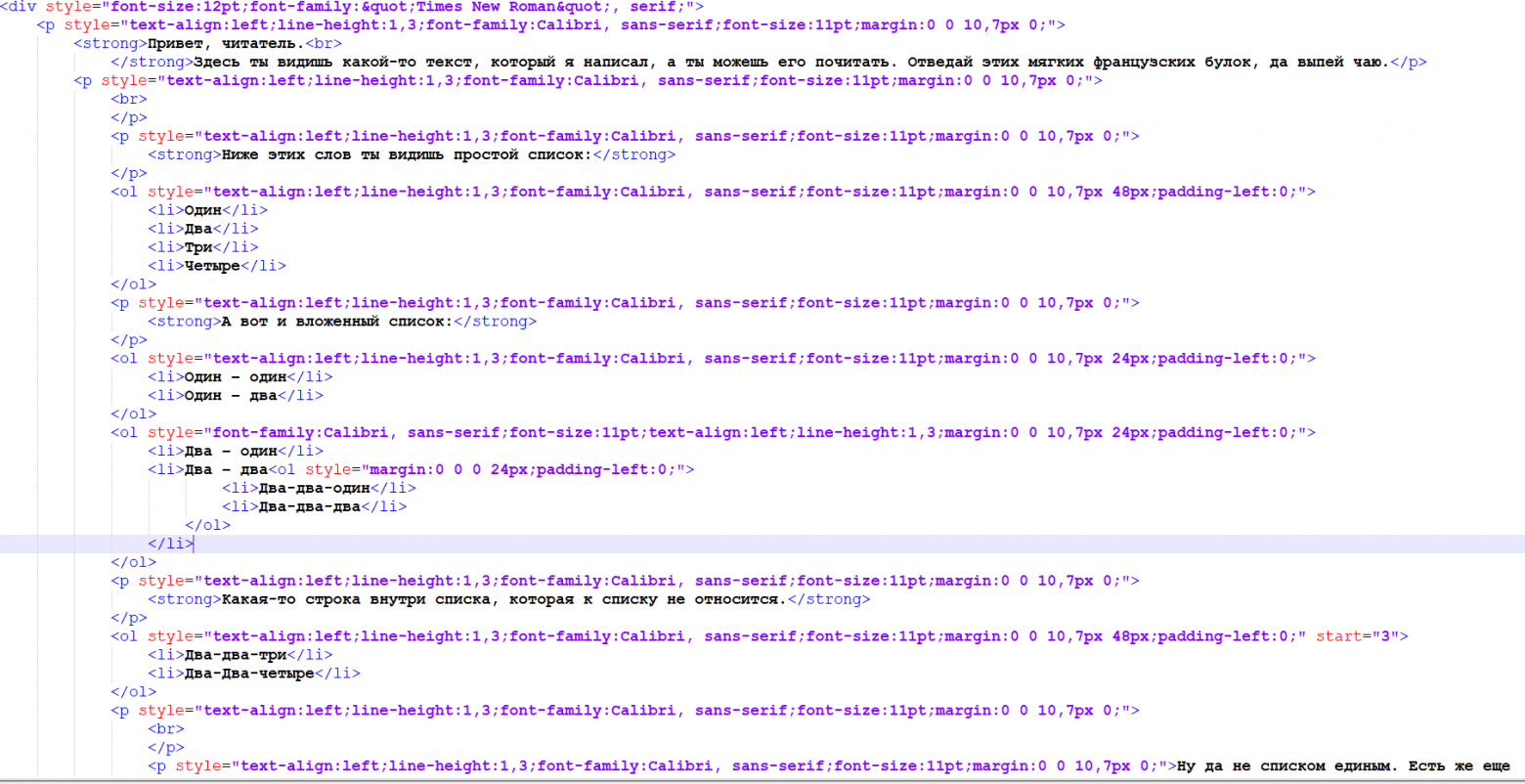
Поэтому полученную строку мы передаем в метод string ClearHtml(string html), который вернет нам чистенький xml:
string ClearHtml(string html)
{
// Разбираем html с помощью HtmlAgilityPack
HtmlDocument doc = new HtmlDocument();
doc.LoadHtml(html);
// Формируем коллекцию элементов (тегов), у которых есть атрибут style
var elementsWithStyleAttribute = doc.DocumentNode.SelectNodes("//@style");
// формируем коллекцию тегов, которые не нужны
var excessNodes = doc.DocumentNode.SelectNodes("//b|//u|//strong|//br");
// удаляем лишние элементы в html
foreach (var element in excessNodes)
{
element.ParentNode.InnerHtml = element.InnerText;
element.Remove();
}
foreach (var element in elementsWithStyleAttribute)
{
element.Attributes["style"].Remove();
}
// сохраняем изменения в html
using (StringWriter writer = new StringWriter())
{
doc.Save(writer);
html = writer.ToString();
}
// пишем отфильтрованный html в xml
StringBuilder xml = new StringBuilder();
xml.Append("<?xml version=\"1.0\"?><documents><document>");
xml.Append(html);
xml.Append("</documents></document>");
return xml.ToString();
}- Для начала, не забываем подключить HtmlAgilityPack через nuget
- Создаем переменную
docтипаHtmlDocumentи загружаем нашу строкуhtml - Формируем коллекции из тегов, которые, по нашему мнению являются лишними. Я решил, что это теги с атрибутом
style, у которых мы удалим этот атрибут, а также теги формативрования, которые мы удалим полностью, но оставив содержимое. - Cохраняем полученный результат в строку и, с помощью
StringBuilderоформляем в виде xml, обернув результат в соответствующие теги.
Вот такое коротенькое решеньице, которое, как ни странно, довольно трудно гуглится.
Ознакомиться с полным исходным кодом можно здесь
Почитать о конвертации docx и xlsx вы можете здесь
