Comments 1205
Однако от признаных экспертов я ожидаю взвешенного освещения ситуации, которое, как минимум, не содержит грубых фактических ошибок
И напрасно.
Эксперты — они потому и эксперты, что узкая специализация.
Чем больше времени потрачено на что-то одно, тем меньше его на всё остальное.
Чем больше набито шишек, тем больше предубеждение, что «там» всё еще хуже и нежелание набивать их еще раз. Всяк кулик своё болото хвалит.
В качестве канонічного примера можно почитать спичи Линуса о C++.
Я так понял, что Роман выступает не «за» или «против» а за профессионализм и за научный подход.
Аргументы Линуса вполне осмысленны, потому что многие плюсовые абстракции не zero cost все же, но это все вполне решаемо адекватным стайл гайдом. Другое дело, что он явно не хочет с этим заморачиваться. Впрочем, не помню, чтобы он хейтил раст в этом же контексте.
Другое дело, что он явно не хочет с этим заморачиваться.Не то, что «не хочет». Он «не может».
Подавляющий по объёму (но, конечно, не по важности) объём кода Linux написан людьми, которые имеют слабое представление о C и C++ в прицнипе — они вообще железячники, из просто драйвера нужны, чтобы железяку продать.
Когда они карго-култят драйвер дёргая куски C кода — результат получается слегка вменяемым и его можно, итерационно, довести до чего-то разумного.
Когда они чего-то напишут с полным игнорированием Style Guide на C++ — это можно будет только выкинуть и переписать с нуля. Кто будет это делать?
Очень сильное заявление, особенно, что люди имеют слабое представление о Си. Пример, приведёте из кода?
Memory leak в драйвере megaraid. Могли быть устранены в зародыше — при внимательном и вдумчивом написании кода. Либо прогоне kmemleak на рабочей системе. Пришлось патчить самому
Отлично, баги есть, есть откровенный говнокод. Но вы тоже будете обобщать, что среди разработчиков Linux люди не понимают Си.
P/S. Я не согласен с утверждением: «людьм, которые имеют слабое представление о Си»Я даже не спорю о их представлениях о С++ или rust или python.
Погодите. Вы просили пример. Я привел. Если бы разработчики этого конкретного драйвера были чуточку "умнее среднего" — проблемы не было. Но она есть. Никаких обобщений я не делал. Вы меня с кем-то перепутали
Т.е вы мне предлагаете посмотреть дискуссию, где обсуждаются конкретные проблемы драйвера exfat. Но при этом утверждаете, что люди не понимают в Си?
И смысл у него в том, что чем больше человек знает, тем более осторожны его суждения в своей и особенно в смежных областяхНет, всё вообще не так. Оригинальное исследование не утверждает того, чего ему приписывают.
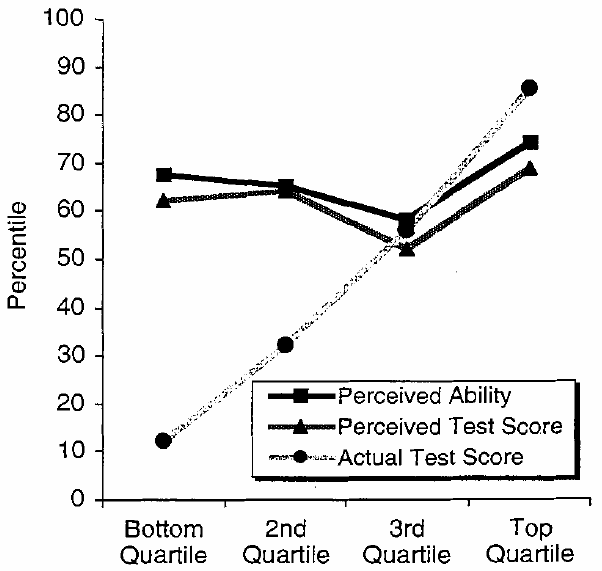
Начнём с того, что мужика звали не «Даннинг-Крюгер». Это два разных исследователя, их фамилии пишутся через тире с пробелами: «эффект Даннинга — Крюгера».
Оригинальное исследование 1999 года заключалось в следующем: студентам раздали опросники на разные темы. Также студенты оценили, насколько хорошо они ответили.
Студентов разбили на квартили по успешности ответов. Получилось что-то такое:

То есть всё полностью наоборот: чем лучше себя человек оценивал, тем лучше он себя проявил. При этом в среднем первая квартиль пусть и отвечала хуже второй, но оценила себя ниже, вторая — хуже третьей, но и оценила себя ниже третьей, и так далее.
Да, первая, квартиль отвечала куда хуже, чем ожидала сама. Но это не даёт право в Интернете затыкать рты всем, демонстрирующим уверенность в чём-либо: «У вас Даннинг-Крюгер, азаза».
Само исследование невнятное: какие-то статистические выкладки с регрессией к среднему. Выше был дан график для опросника по юмору. График для опросника по логике выглядит более непонятно:
Каких-то больших различий нет: 5—10 процентов. При этом хорошо себя оценили как те, кто плохо ответил, так и лучшие. Получается, что если человек в себе уверен, то это либо профан, либо эксперт?
Я тут разве что могу заключить, что все люди себя оценивают выше среднего. Вот это интересно.
В 2006 году исследование повторяли. Результаты совсем невнятные. Люди себя оценивают хуже, если тест был сложный?
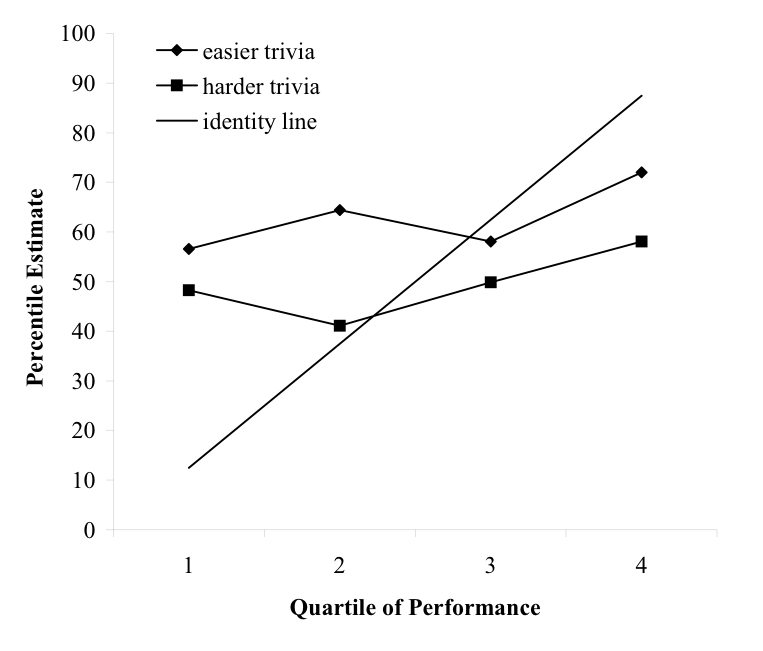
Нет никаких эффектов. Если вы с кем-то не согласны, то нужно опровергать чужую точку зрения.
Rust убьёт C++ и, возможно, C в перспективе 10 лет, это уже просматривается сейчас. Даже если Rust проигрывает в каких-то микробенчмарках, это ничего не значит. Миру слишком давно нужен такой язык как Rust, с богатыми. типами, с ручной, но безопасной памятью, с системой пакетов/библиотек, близкий к железу. Единственное, что может помешать Rust, это появление аналогичного по характеристикам языка, с поддержкой от крупного вендора, с более простой семантикой управления памятью.
А зачем кому-то переписывать мегатонны существующего кода? Вот в один день бизнес примет решение: мы писали свой софт 10 лет на c++, а давайте потратим ещё 10 лет на переписывание на другой язык, чтобы через 10 лет получить тот же функционал, что у нас есть сегодня, но собирающийся из другого языка.
Давайте будем немного реалистами.
Язык хороший. В своей ниже отличный. Но переписывать на него legacy — кому это надо и чем это в деньгах выгодно?
Хотите действительно безопасности? Тогда пропагандируйте Idris/Agda/Coq и DeepSpec. Но все мы живём в реальном мире и понимаем, что это на данном этапе развития невозможно :)
Вообще любой продукт, от которого зависит пол мира, очень даже имеет смысл переписать. OpenSSL приводят часто как хороший пример. Был бы он на расте мы, как минимум, избежали бы пачки уязвимостей, которые поставили эти пол мира на уши. Имеет смысл? Я думаю да.
И это не пропаганда раста, на котором я даже не пишу. Это просто здравый смысл. Нужно использовать лучший инструмент там, где это важно. Какой-нить игровой движок переписывать на раст? Там это не важно. Драйвер сетевой карты? Очень важно.
Я бы предпочёл переписывание на С++, на котором также ошибки подобного уровня не допускаются. Не хочешь переполнений — используй арифметику без UB на переполнениях. Не хочешь отрыва конечностей при работе с памятью — без проблем, просто не работай с сырой памятью. Не получается? Оберни в безопасные с как можно более низким оверхедом обёртки.
И да, Rust достаточных гарантий не предоставляет. Например, многопоточка. Посмотрите, что происходит при двойном локе мьютекса (происходит unspecified behaviour. А что это такое на самом деле — вы инфы, кроме предположений на гитхабе, не найдёте).
Не хочешь переполнений — используй арифметику без UB на переполнениях.И где вы в C++ нашли «арифметику без UB на переполнениях»? Или вы при -trapv? Так он во-первых не работает в GCC уже больше 10 лет, а во-вторых при попытке включить его для уже существующего кода в Clang тот начинает «сыпаться». Потому что оказывается что там реально происходят переполнения, просто результат работа никем не используется и потому «всем пофиг».
Каждую строчку перепроверить и убедиться что там всё хорошо? Так в этом случае уже и на Rust можно перевести всё.
Посмотрите, что происходит при двойном локе мьютексаА что для таких случаев предоставляет C++?
И где вы в C++ нашли «арифметику без UB на переполнениях»? Или вы при -trapv?
Не, я про обычные вещи уровня safe_int
А что для таких случаев предоставляет C++?
Ровно то же самое, что и Rust. Чёрт пойми что.
Ровно то же самое, что и Rust. Чёрт пойми что.
Не совсем. Гарантируется, что функция не вернёт после второго лока:
However, this function will not return on the second call (it might panic or deadlock, for example).
Тут скорее platform specific behaviour, которое для большинства популярных платформ означает deadlock, что не нарушает гарантий Раста (т.е. memory safety и отсутствие data races).
А можно небольшую просьбу от человека, знакомого с C, Rust, но плюсы знающего исключительно на уровне "Си с классами"?
В дискуссиях "C++ vs Rust" регулярно используется довод, что в C++ можно делать всё не менее безопасно, чем на Rust, и наверняка хорошо известно, что именно для этого требуется. Скорее всего, и компиляторы / линтеры это должны уметь.
Не могли бы вы (в значении "эксперты по языку C++", не обязательно лично Вы) показать пример конфигурации открытого компилятора и/или открытых линтеров, обеспечивающих адекватную степень безопасности? Чтобы была возможность начать проект на C++, включить их в этой конфигурации и быть уверенным, что они дадут мне по рукам, когда я случайно использую malloc вместо make_unique / напишу код с ошибкой инвалидации итератора / сделаю какую-нибудь ещё глупость, про которую я просто не в курсе. Потому что за себя я уверен, что даже если я прочитаю от корки до корки C++ Core Guidelines, как минимум поначалу такие ошибки всё равно будут.
Вот, например, clang-tidy --checks=cppcoreguidelines-*,modernize-* — это адекватно, избыточно или недостаточно?
Так в том-то и дело, что меня вполне устроит в качестве ответа линтер, который банит потенциально корректный код. Если он скажет "написанный так код потенциально опасен, так нельзя, пользуйтесь абстракцией такой-то" — оно и к лучшему. Если мне действительно будет нужно — найду в документации, как разрешить данное конкретное нарушение правил линтера (а заодно прочитаю, чем именно оно опасно, на что именно нужно проверить код вручную и о чём нужно предупредить комментарием следующего разработчика).
Не устраивает меня ситуация, в которой "разумеется, C++ позволяет всё это безопасно написать, но чтобы быть уверенным хотя бы на 90% в безопасности написанного, обязательно необходим ревьюер с опытом в современном C++ от N лет". Новые проекты в опенсорсе нередко начинаются с одного человека (или маленькой команды), и я не понимаю, как сейчас начать проект на современном C++ без хождения по всем стандартным граблям с нуля.
[Forwarded from Denis]
блин, нашёл тут на работе в своём старом коде
std::vector<_> vec = ...; auto it = vec.begin(), end = vec.end(); while (it != end) { if (/* some conditions on `it` */) { ++it; continue; } else { // ... it = vec.erase(it); } }
[Forwarded from Denis]
это просто п**дец, как я мог так ошибиться
[Forwarded from Denis]
переписал в иммутабильном стиле, планирую грепнуть и всё нафиг переписать так
[Forwarded from Stanislav Popov]
а в чем проблема?
[Forwarded from Denis]
vec.erase(it) инвалидирует все итераторы, которые распологались «после» it, в том числе и vec.end()
[Forwarded from Denis]
а я его закэшировал какого-то хрена
[Forwarded from Denis]
еб*чие плюсы, и ни один сраный линтер из тех, что мы юзаем, не заметил х**ни :(
[Forwarded from Denis]
у меня щас горит на самом деле, потому что ни clang'овский scan-build, ни cppcheck не находят говна
[Forwarded from Denis]
придётся видимо грепать проект по .erase(
[Forwarded from Denis]
плюсы — дно
[Forwarded from Denis]
даже когда вроде вот знаешь всё х**ню и умеешь их готовить
[Forwarded from Denis]
на секунду отвлёкся/забылся — проиграл
Когда у тебя в проекте куча
unsafe — это тревожный признак, но это можно терпеть. Когда ты оборачиваешь unsafe в функцию, которой нужно «правильно» пользоваться — ты возвращаешься в ситуацию «на секунду отвлёкся/забылся — проиграл».И тогда зачем весь этот «цирк с конями»? Один такой язык у нас уже есть…
unsafe, даёт доступ к внутренностям без проверок. Вот после этого можно и в rust «в трех безобидных строчках UB можно схватить».Причём автор объяснял что всё в порядке, просто не нужно лезть в потроха, функция не публичная, так что всё Ok.
Именно после этого — можно утверждать, что в Rust — всё на порядок проще с этим. Потому что небезразличный человек, буквально со стороны, — пробежался по ансейфам и нашёл этот баг.
Люди совершают ошибки. Это не случайность, это — норма.
Rust — язык созданный для упрощения борьбы с ошибками и в этом вся его прелесть. Хотя компилятор по прежнему не может думать за человека, но довольно таки большую часть работы он с человека снимает. Остаётся выполнить свою часть.
Фишка в том, что в расте такой код "за забором". И я как-то считал, в СТД (в котором ужас-ужас сколько ансейфа) его значение порядка 0.1% от общей кодовой базы (считал очень грубо, по строчкам). Это значит, что у вас не миллион строк кода где можно "на секунду отвлечь/забыться", а тысяча. А теперь допустим что программист в среднем "забывает/отвлекается" раз на тысячу строк кода. В итоге в одной программе будет тысяча багов из-за этого, а в другой — один.
Это грубо, без претензии на точные выкладки. Просто это та выгода, которую люди получают за "ублажение компилятора", который ни что иное, как по сути кланг с некоторыми обязательными линтами, за которые так ратовал кто-то в комментариях тут.
Фишка в том, что в расте такой код «за забором».Когда он за забором, то всё в порядке. А когда у вас вот такое вот:
pub(crate) fn get_mut(&mut self) -> &mut T {
unsafe { &mut *self.inner.as_ref().get() }
}
Это реальный код, из реального проекта.
Такими методами я вам могу в любом проекте достичь ультрабезопасности: будет у меня всего две
unsafe функции. peek и poke. Каждая в одну строку. И всё. Всё остальное — «офигеть как безопасно».Если на этом проекте был хотя бы 1 ревьювер этот код бы не прошел ревью.
Такими методами я вам могу в любом проекте достичь ультрабезопасности
Такими темпами я могу вам в любом коде любую хрень сделать: bool тип в сишарпе которые не true и не false, монаду в хаскелле которая не монада, и всё остальное. Если вы написали unsafe и нагородили ерунды, то это вы виноваты, а не язык.
И да, то что в огромном проекте как актикс смогли за полчаса найти все места которые могут вызывать УБ это и есть польза от этого unsafe.
Кстати, два момента
- с этой функцией нет проблем, потому что из &mut self можно возвращать &mut на дочерние элементы
- если её нарочно сломать (например, вместо &mut self использовать &self), то мири скажет, что код невалидный и починили бы вы свои ансейфы, дорогие товрищи:

Почему тогда столько шума было от этой функции?!
Посмотрите здесь. UnsafeCell используется вроде бы правильно, но прикол в том что там оно завёрнуто в Rc, и нарушается контракт Rc!
Кароче уб в расте такое же не очевидное как и в плюсах
Вот плейграунд c демонстрацией. Я скопировал весь код из actix/cell.rs, чтобы показать уб
Кстати miri ловит, но естественно только при использовании. Т.е. сама библиотека для мири выглядит вполне ок, а вот её использование через сейф апи приводит к уб (которое мири ловит).
Да, согласен, проглядел, в оригинальном исполнении тоже есть ошибка.
Кароче уб в расте такое же не очевидное как и в плюсах
Не совсем — мне неизвестен тул, который ловит УБ в плюсах. Есть всякие санитайзеры, но они такие, ненадёжные товарищи. А если закинуть этот код в MIRI то можно получить замечание от машины:
error: Undefined Behavior: trying to reborrow for SharedReadWrite, but parent tag <4320> does not have an appropriate item in the borrow stack
--> src/main.rs:50:5
|
50 | v1.push(4); //v2 mutated through v1
| ^^ trying to reborrow for SharedReadWrite, but parent tag <4320> does not have an appropriate item in the borrow stack
|Впрочем, я сторонник не писать unsafe вообще и дать это на откуп популярным библиотекам и std.
Кстати miri ловит, но естественно только при использовании. Т.е. сама библиотека для мири выглядит вполне ок, а вот её использование через сейф апи приводит к уб (которое мири ловит).
Не так, скороее МИРИ это интерпретатор который ловит уб который происходит. То есть оно может найти УБ если оно триггерится где-то в программе, но оно не найдет потенциальное УБ которое не эксплуатируется. Ситуация похожа с тестами.
В своём проекте подобный саботаж полностью перекрывается #![forbid(unsafe_code)] в корне проекта.
Я думаю, что проблема с актикс следующая:
У чела в голове было полуинтуитивное понимание того как это работает и почему оно сейф (оказалось в итоге не полностью правильным). Ему нужно было напрототипировать производителый веб сервер, а доказывать все компилятору лень. Выносить ансейф вверх по стеку в публичное апи, тоже не хочется. В итоге получаем такой говнокод (по меркам раста) как приведен в комментарии выше. Не все же такие фанатики как уважаемый 0xd34df00d, которые пишут доказательство корректности gcd на 200 строк.
и камень в огород с++ => если бы компиляторы умели сами когда можно кешировать .end(), .size() и прочее — никому бы в голову не пришло руками выносить их из цикла. а так — после того как вынос i< vec.size() ускоряет цикл и позволяет его векторизовать — начинаешь на автомате везде это делать. ну и провтыкиваешь в вышеприведенном случае.
Забавно, но в данном случае виновата как раз недооптимизация. Если бы алгоритм был выбран не квадратичный, а линейный — ошибки бы не было...
Надо просто бежать двумя итераторами, а не одним:
auto i = vec.begin(), j = vec.begin(), end = vec.end();
for (; j != end; ++j) {
if (/* some conditions on `j` */) {
if (i != j) *i = std::move(*j); // или swap
++i;
continue;
} else {
// ...
}
}
vec.erase(i, end);Как-то так, если я ничего не напутал.
На любой баг всегда найдется ответ "а вот в той книжке/той статье/5пункте 6 главы спеки сказано, что вот так делать не надо". Вопрос не в том, что человек так написал, вопрос в том, что кмк это вполне себе могло бы быть ошибкой компиляции. К слову, раст в таком случае выдаст ошибку компиляции, оно и понятно, он ведь не разрешает две мутабельных ссылки, как раз по схожим соображениям.
Tmad PsyHaSTe я нормальный и здоровый человек. Я не хочу думать о том, где мне компилятор С++ подсунет очередную жирную свинью. Я хочу сконцентрироваться на решении бизнес задачи. Тупо. Дешево. Сердито. Надежно. Без этих выкрутасов. Пускай меня компилятор страхует от ошибок. А не тупо молчит как партизан.
Помню, я купил книжку про умные указатели и всю дичь, что с ними вытворяли . Это был далекий 2000. Я просто тащился с того, что эти ребята с Саттером, Александреску творили. Но тащить это в прод. За ради чего ?
В Rust две мутабельные (исключительные) ссылки на одно и то же — не могут быть валидным кодом. И попытка их создать — это всегда UB. Поэтому нет смысла и в ослаблении ошибки до предупреждения.
Тогда, получается, невозможность присвоить строку целочисленной переменной — это проблема С++? Это же совершенно валидный код, только не компилируется :-)
Ну так и в расте можно — если сделать дереф в какой-нибудь Rc, и практика тоже так себе.
Я всеми руками за безопасность, но имхо это — перебор.
Во-первых нужно понять что &mut это не "мутабельный", а уникальный. Да, надо было изначально нормально назвать, были пропозалы чтобы это переделать, но оставили как есть в угоду обратной совместимости. По понятным причинам, уникальная ссылка должна быть уникальной.
Во-вторых различать уникальность и мутабельность нужно не так уж часто: на графовых структурах, и подобных случаях. В хаскелле вон вообще никакой мутабельности нет, и отлично живут, иногда даже плюсы аутперформят.
Уточнение: только не в Rc, а в Cell
Я просто хочу получить ссылку, а не использовать новые абстракции.
> Во-первых нужно понять что &mut это не «мутабельный», а уникальный.
И что даст это понимание?
> В хаскелле вон вообще никакой мутабельности нет
Хаскелль — функциональщина со сборщиком мусора. Rust же претендует на другую нишу.
Ну так и гипотетический я в С++ хочу присвоить строку целочисленной переменной, а не писать неявное преобразование (видимо, вместе со своим классом строки).
И что даст это понимание?
Понимание того, почему Cell, RefCell, мьютекс и атомарные типы можно мутировать по "неизменяемой" ссылке и при этом всё в порядке и никакие гарантии не нарушаются.
В С++ можно присвоить строку целочисленной переменной, если определить соответствующее неявное преобразование.
В Rust тоже можно так сделать через явные преобразования. Напишите мне код на C++, дам вам код на Rust.
То есть вы предпочтёте иметь в своей программе возможность обратиться к разделяемой переменной из разных, не захватив при этом предварительно блокировку? Ну ок.
Вот те абстракции, которые я перечислил, как раз и дают те специальные способы обращения, которые гарантируют защиту от гонки. И их там много не просто так, а потому что у каждого способа свои компромиссы.
А умный лок-фри контейнер это не абстракция?
Centimo, на мой взгляд, указывал на то, что в случае lock-free программирования подстроиться под гарантии Rust'а не получится — придется все писать на unsafe'е. Но это всего лишь моя интерпретация, конечно.
Вы не правы. Вот например https://github.com/xacrimon/dashmap отличный пример как lock-free структура данных спокойно живет с гарантиями Rust. Реализовано это через внутренюю мутабельность и имея immutable ссылку на непосредственно словарь (обычно разделяемую через Arc) можно удобно обращаться к ней из многих потоков. Понятно что внутри реализации есть определенный процент магии атомик переменных и страшных вещей, но при этом внешний интерфейс простой и удобный для прикладного программиста
с гарантиями Rustс типичными гарантиями, я бы сказал =)
github.com/xacrimon/dashmap/blob/master/src/iter.rs:238
unsafe {
let k = util::change_lifetime_const(k);
let v = &mut *v.as_ptr();
return Some(RefMutMulti::new(guard, k, v));
}
...
let mut guard = unsafe { self.map._yield_write_shard(self.shard_i) };
let sref: &mut HashMap<K, V, S> = unsafe { util::change_lifetime_mut(&mut *guard) };vec.erase(std::remove_if(vec.begin(), vec.end(), [](auto&& item){return !some_condition(item);}), v.end());Я ещё в свою библиотеку велосипедов-обёрток над std добавил шаблон remove_if(container, predicate), чтоб не писать begin()/end() (и не писать end() два раза). Думаю, с появлением концептов и рейнджей в С++ это будет так же легко делаться из коробки, без обёрток.
Ага, абсолютно логичный и понятный синтаксис. Понятно, что это устойчивая remove-erase idiom, но она все равно очень многословна. Что мешало в стандартную библиотеку добавить такой вариант:
std::remove_if(vec, [](auto&& item) { return !some_condition(item); });В C++20 у всех контейнеров появится метод erase_if: http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2018/p1209r0.html
ЧЯДНТ?
Пишите на плюсах.
Всегда вопрос в системе типов. Чем она мощнее, тем меньше нужда в дебаггере, но тем лучше нужно читать, что за ошибку компилятор пишет. У меня например до сих пор ошибки в хаскель коде иногда вызывают оторопь — непонятно, что не так. Хуже, чем дебажить то, что если ошибка непонятна то просто "пройтись по строчкам и сравнить ожидаемое поведение с реальным" нельзя. Из плюсов — вы доказываете работоспособность в общем случае, а не тот сценарий который протыкан. Ну и навык понимать ошибки компиляции и избегать частых проблем — нарабатывается, а дебажить меньше не приходится. Встречал в хаскель чате людей, которые много лет в прод на нём пишут, а дебажиться не умеют вообще, не слышали про watch window и вот это всё. Забавно, но факт.
Имеет смысл переписать это на языке, который предоставит гарантии защиты от таких ошибок?
Проблем я вижу две
- Переписывание на Rust не убережет от логических ошибок
- Железо тоже имеет тенденцию подводить. Rust не поможет от того, что благодаря сбою на аппаратном уровне случится флип бита. А между прочим такое случается реально постоянно.
Знаете, если язык будет беречь от логических ошибок, то зачем ему вообще программист?
Так наоборот — максимальный уровень verbosity компилятора, а еще лучше — обработка ворнингов как ошибок компиляции и пускай разработчик дорабатывает )
За 10 лет продакшн работы я встречал наверное тысячи баги, из которых ноль связанных с железом. По-вашему, стоит забить всё же на техники, уменьшающие баги в софте, ведь железо все равно глючит?
Вы сделали неправильный вывод ) баги в железе — это объективная реальность. Вот недавно была статье на Хабре, где рассказывались разные кейсы. Например, при передаче по сети бьётся бит и запрос уходит на другой домен, отличающийся одним символом. Или при чтении с диска. Или в памяти. В половине случаев — это все решается валидацией параметров. Немного помогают контрольные суммы.
В общем, это все не означает, что Раст плохой язык, но беда может прийти оттуда, откуда не ждёшь )
Может, но как верно сказали ниже, нужно предполагать корректную работу железа, математики, ОС и остального чтобы не сойти с ума и сделать хоть что-то полезное.
Но пока у вас на 100 (а то и 1000) багов в софте случается один такой аппаратный баг… нужно фиксить софт. А с железом потом уже бороться. Когда в софте не будет столько «косяков».
P.S. В том случае, кстати, софт фиксить не стали. Написали прогу, которая за день прогона определяет — есть бага в CPU или нет и если бага в наличии — выключает Turbo. Ну а потом эти процы по гарантии поменяли.
Вы только что своими словами пересказали историю fdiv bug'а из pentium. Первых которых. Не ммх ещё. Это какой год? 1993?
Или вот опять, снова по тем же граблям ?
(Кстати, мне интересно, у них там по-прежнему SRT, или хотя бы Goldsmith применили?)
Или вот опять, снова по тем же граблям ?Глабли похожие, но другие. В FDIV-баге всё было детерминировано. Тут же — всё зависело от температуры процессора. Что делало, конечно, баг очень весёлым для поимки. В итоге эта модификация «в свободную продажу» не пошла, насколько я знаю. Если вы не Amazon/Facebook/Google (которые получают новые процессоры до их официального объявления да ещё и со скидкой — именно чтобы «в случае чего» такие баги отловить), то вам на эту бяку без разгона нарваться не грозит.
За 10 лет продакшн работы я встречал наверное тысячи баги, из которых ноль связанных с железомПовезло. За почти 20 лет Delphi видел: битую память, битые сидюки (этих штук 10), битые сети — то постоянно. Переразозногнанные процы, несколько раз. Первое вот что вспоминается.
Напомню, что хороший программист на фортране может писать на фортране на любом языке. И с приличной вероятностью при переписывании на раст будет ощутимая доля разработчиков, которые будут фигачить get_unchecked оборачивая в unsafe не задумываясь о соблюдении необходимых инвариантов, как они делали в си, или, с обоснованием что так быстрее, сделают свой RefCell, позволяющий получить &mut T дважды и рассказывая потом что нигде в коде его дважды не дёргают.
С переписыванием криптографии всё очень непросто (хотя есть rustls/ring, как пример), но получение гарантированного поведения (в том числе по влиянию на кэши, предсказатель переходов и т. п.) даже в случае шифров использующих банальный ARX или проверки MAC может быть нетривиально из-за оптимизаций.
> Хотите действительно безопасности?
Мы хотим адекватного компромисса.
То есть любой возможный будущий репорт стоит 100% ресурсов и полной заморозки проекта на срок равный его прошлой разработке? И у нас точно нет других, чуть менее дорогостоящих, способов с этим жить?
Вы ещё спросите, зачем нужен рефакторинг. Можно ведь хяк-хяк и в продакшн
А какая разница, если в результате код становиться лучше и удобнее для использования, расширения и масштабирования в будущем? Ну кроме наверное переучивания программистов.
При рефакторинге кодовая база та же, процесс улучшений контролируемый и итеративный. Как бы… Отличия фундаментальны.
В одном случае, речь о более-менее протестированном и известном коде с известными нюансами и особенностями работы, в другом — о подобии черного ящика, который еще тестировать-не_перетестировать… И, что самое забавное, в итоге получить примерно то же самое и это еще в лучшем случае.
Параллельно. Итого мне теперь надо не 100% ресурсов, а 200%. Плюс "старая" команда, поддерживающая продукт будет демотивирована постоянно и бонусом мы получаем внутренний конфликт в компании.
Кроме этого, новый код будет постоянно отставать от плюсового. Не получим ли мы не 10 лет на разработку, а 15?
Кто это оплатит?
Продукты часто переписывают даже в рамках одного и того же языка. Например, в сишарпе я вот переписывал недавно с фулл фреймворка на неткор. Зачем? Чтобы переехать с виндовых виртуалок на линуксовые и сэкономить приличную сумму на этом.
Уменьшение багов и увеличение скорости внедрения новых фич тоже вполне себе переводится на $$. Если мозилла даже четверть браузера смогла переписать (и если кто помнит это изначальная причина почему раст вообще появился), то наверное какой-то смысл в этом есть, не так ли?
Беда только… Ну не наблюдается роста доли раста в Firefox.
расширения на могильных платформах
Понимаю, что опечатка, но не могу не спросить — это на Windows Phone, что ли?..
висящий в фоне и играющий музыку плеер?
у меня не убивает — что я делаю не так? А, точно — это ж у меня в фоне ютуб премиум фигачит
Есть мнение, что Раст уже перерос давно мозиллу.
Ну так даже если МС от него откажется, то он и правда останется жить, разве нет?
Как у классика: Ничего не будет. Ни
Когда проект Windows Phone «накрылся медным тазом» и стало понятно, что аргумент «C# отлично работает на Windows и за будьте про всё остальное», скорее, заставляет разработчиков выбирать Java (Python и прочее) и уходить с Windows — произошёл разворот на 180 градусов, Visual Studio начала поддерживать вот это вот всё… и C# начали птытаться сделать «кроссплатформенным».
Но… поздно метаться: слишком много вещей, которые считаются «само собой разумеющимися» в C#-мире по прежнему привязаны к Windows.
Так что сегодня C# добрался только лишь до стадии: «хорошо под Windows и, если очень надо, можно чуть-чуть для чего-то ещё».
Этот статус позволяет ему жить, но если Microsoft от C# откажется — смысл в нём исчезнет немедленно.
Но… поздно метаться: слишком много вещей, которые считаются «само собой разумеющимися» в C#-мире по прежнему привязаны к Windows.
Это каких таких в контексте .net core? Если убрать UI (WPF/WinForms) составляющую
Это каких таких в контексте .net core? Если убрать UI (WPF/WinForms) составляющую.Понятия не имею какую там нужно составляющую убирать и откуда, но у меня несколько знакомых (не программистов) искали хостинг для своих ASP.NET проектов — на дешёвых хостингах с Linux не заработал ни один.
Что там технически происходит — я не в курсе, но связь «C# = Windows, а C# под Linux — для тех, кому нужно приключений на свою задницу» это поддерживает устойчиво.
Я не знаю, что там на дешевых хостингах, но в контейнерах все работает прекрасно у кучи компаний (из российский на слуху озон, додо, каспер и т.д)
А у энтузиастов бюджета нету: если у вас выбор, условно, платить $10 в месяц или $20, но перед этим заплатить программисту $300-$500 для адаптации… то простая логиика подсказывает, что вы таки будете платить $20.
В Java, к примеру, этого нет, потому что все пакеты изначально проектировались и затачивались, в том числе, под Linux.
Если пилить проект изначально под .net core, то все прекрасно будет работать под Linux.
Ну так пусть живут не под Linux. Выгодно будет переписать — перепишут. Это не так и сложно, если нет компонент, прибитых к винде. Но это уже не относится к .net
До праздников переписал последний проект который оставался в компании с фулл фреймворка на кор. Да, пришлось страдать, потому что там архитектура была Г (как часто бывает в легаси), библиотечные проекты напрямую лазили в конфигурационный файл (которых вообще нет в коре, и этот функционал замёнён специальным механизмом опций), но в итоге всё заработало, и не очень дорого оказалось.
Можно было бы обойтись куда меньшими правками и перенести вообще в несколько раз быстрее. Но решили попутно еще пару проблем с архитектурой порешать.
В общем, кор жив, и все компании которые пишут на шарпе и не хотят остаться за бортом либо переписывают на кор, либо уже переписали свои основные продукты. Кто-то даже на питон переписывает (не спрашивайте меня, почему, я сам задал тот же вопрос), но на виндовом фреймворке оставаться не желает никто.
В общем, кор жив, и все компании которые пишут на шарпе и не хотят остаться за бортом либо переписывают на кор, либо уже переписали свои основные продукты. Кто-то даже на питон переписывает (не спрашивайте меня, почему, я сам задал тот же вопрос), но на виндовом фреймворке оставаться не желает никто.По-моему вы яростно соглашетесь со мной. Вот смотрите — сейчас ситуация такая, что «на виндовом фреймворке оставаться не желает никто», но при этом часть «переписывают на кор», а часть «даже на питон переписывает».
Что будет если Microsoft, ну вот прям завтра скажет: «всё, мы передумали, нам играться в кор более не интересно, проворачиваем фарш назад, мясо — корове в зад… возвращаемся на Windows»?
Скорее всего тех, кто будет продолжать «переписывать на кор» — станет резко меньше, а тех кто будет «даже на питон» — резко больше.
И всё. И кончится C#, который, якобы, давно перерос Microsoft.
Вот лет через 5-10, когда на версии для Windows останется только небольшая часть сурового Legacy. И когда разработчиков C# вне Microsoft будет больше чем внутри… да, тогда можно будет сказать «да, C# уже перероc Microsoft».
А сейчас — ещё нет. Да, движение в этом направлении идёт… но пока ещё — C# очень сильно завязан на Microsoft…
По-моему вы яростно соглашетесь со мной. Вот смотрите — сейчас ситуация такая, что «на виндовом фреймворке оставаться не желает никто», но при этом часть «переписывают на кор», а часть «даже на питон переписывает».
Понятное дело что есть процент легаси всегда. В тех проектах, на которых я работал и они были мне интересны цифра виндвого фреймворка была 5-30%.
А сейчас — ещё нет. Да, движение в этом направлении идёт… но пока ещё — C# очень сильно завязан на Microsoft…
Я нигде не говорил что C# будет отвязан от майкрософта, скорее наоборот. Это как котлин и жетбрейнс, умрут последние — котлин резко потеряет в коммьюнити. Умрёт гугл — скорее всего го резко исчезнет с радаров.
C# отвязан от винды, уже давно и это так. Но он совсем не отвязан от майкрософта, и скорее всего, никогда не будет.
Так что сегодня C# добрался только лишь до стадии: «хорошо под Windows и, если очень надо, можно чуть-чуть для чего-то ещё».
Вот с этим утверждением.
С ним можно было бы спорить, если бы массовый переход на core уже состоялся
Состоялся. О чем я уже не раз говорил. Сидят всякие легаси-монстры, которым и COM нужен, и AD, и прочие. Все b2b SAAS — уже там.
Но нет — он в самом разгаре «у компаний в теме». А «мелочь пузатая» подтянется лет через 5-10.
Всё наоборот, мелочь пузатая как раз быстро и чутко адаптирует новые стеки, а догоняющими являются "компании в теме".
Всё наоборот, мелочь пузатая как раз быстро и чутко адаптирует новые стеки, а догоняющими являются «компании в теме».В данном случае я имею в виду не стартапы какие-нибудь, а булошные и кафешки. Которые вообще своего IT-отдела не имеют и заказывают переработку своего сайта/бухгалтерии раз 3-5-10 лет. Ну те, которые плачут горючими слезами про то, что поддержка Windows 7 закончилась (а некоторые — так и с Windows XP не слезли). Они ещё даже не почесались со времени появления .NET core, не то, что не перешли.
В данном случае я имею в виду не стартапы какие-нибудь, а булошные и кафешки.
ну компании у которых айти не является основным направлением мне и правда не интересны, и я их не считаю.
А те булошные и кафешки что с нами работают, например, получают от нас мобильные приложеньки или веб-морду и не знают, что работают на кор2.0-3.1
Wiki:
Как было объявлено, следующая версия будет называться .NET 5 (без использования «Core» в названии). В .NET Core 3.0 был почти полностью устранен разрыв в возможностях с .NET Framework 4.8. Новая версия станет единой платформой для .NET разработки, заменяя Mono и .NET Framework.
Последние 3-4 года пишу исключительно под докер (и сооветственно, линукс). Ни с одной софтиной никаких проблем не было (прям линух-специфических), ни на одном из 3 мест которые я за это время сменил.
основной причиной переписывания Firefox на Rust является популяризация Rust
Не только, ты же знаешь что в Rust есть несколько вещей, которые позволяют компилятору лучше генерировать код и вот прямо сейчас это уже работает правда пока ещё не так идеально как если бы работало в полную силу, но ничего, frontend допилят, особенно после того как древние баги clang на middlend починят.
Mozilla foundation преследует вполне понятные цели: обезопасить код, работающий с пользовательскими данными (код сайтов для них ведь тоже пользовательские данные) именно поэтому у них многослойные тесты на всё и всех для участков кода на всех используемых языках. Rust тут помогает некоторую, вполне конкретную, часть дыр прикрыть на корню, что явно на пользу. В общем то было бы удивительно что если бы новый системный язык (дефакто это 3 системный язык после C и C++) с первой спецификацией в 15 году не был бо лучше предшественников.
Да и я бы не сказал что в Mozilla не осилили C++, наоборот. Они просто выбрали альтернативный вариант. Они могли бы переписать однопоточный и даже одно процессный свой старый движок тоже на C++, но поскольку очевидно, что архитектура проекта будет принципиально иная много где они решили эти места написать на Rust. По мне это довольно разумное решение. Кроме того, насколько я вижу они сейчас переписывают разный код который «по быстрому адаптировали» в интерфейсе браузера за последние несколько лет с JS на C++. В общем по мне всё у них всё последовательно и логично.
Уменьшение багов? Я вот, ради интереса, перевёл проект с Mono на Net Core и с удивлением обнаружил, что багов стало больше. Пришлось писать workaround-ы.
Есть подозрение, что это скорее перестали работать хаки, которые работали под моно.
Не поделитесь ссылкой, какие баги там где всплывают и в какой версии рантайма?
1. Приложение — мультиплексирующий прокси, который держит единственное соединение с сервером по https и несколько клиентских. Сервер иногда дропает соединение, приложение это отлавливает и переподключается.
Так вот: SslStream не всегда ловит ситуацию, когда соединение было закрыто, вместо этого уходит в бесконечное ожидание. Дальнейший анализ проблемы показал, что он висит на Socket.ReceiveAsync. Причём асинхронщина используется, даже если используются только синхронные вызовы в SslStream.
Но при этом он зависает не намертво. Если при этом отключатся все клиенты, то после этого таки происходит завершение Socket.ReceiveAsync.
Проблема устойчиво воспроизводится в Net Core 3.1.201 под Ubuntu. Под Mono и в Windows она не возникает.
Более детально разбираться не стал, решил проблему использованием велосипеда — библиотеки для оптимизированной работы с сокетами, которую я написал пару лет назад, когда реализация асинхронщины в Mono был сделана через одно место.
2. Проблема при использовании SafeHandle и interop. Дело в том, что в Linux дескриптор имеет тип int (32 bit), а внутри SafeHandle используется IntPtr (64 bit в 64-битных системах). Mono об этом знает, и если функция выдаёт значение -1 (некоррекный дескриптор), то делает знаковое расширение до 64 bit, а вот NetCore делает беззнаковое расширение, в итоге функция SafeHandle.IsInvalid работает некорректно.
Как раз пример того, что может случитс на платформе, на которой мало кто из разработчиков работает…
- Нужно проверять в одинаковых условиях, работа моно под винду совсем не гарнатирует работу того же моно под убунту
- А вот на это я бы заводил issue, выглядит как серьёзная проблема.
Вы правы, legacy переписывать не очень выгодно. Тем не менее COBOL и FORTRAN практически исчезли, уйдёт и C++ по тем же причинам. Rust тоже исчезнет, но C++ грозит упадок гораздо раньше.
Не уверен, c++ развивается. И это заметно среди c++ разработчиков. Лично знаю нескольких, которые крепко думали о переводе проектов на rust, но c++ 20 в итоге перевесил.
Поймите правильно, я вообще golang разработчик, который для себя изучает rust и я не сильно тут предвзят, мне просто интересно, как развиваются языки программирования.
- Он ещё официально не вышел
- Поддержка компиляторов всё ещё совсем такая себе (имхо — недостаточно стабильно для серьезного прода)
Или это проекты в пару единиц трансляции и не являющиеся серьёзным продом?
Думаю имеется в виду "хотели начинать/переводить проект на Rust из-за недовольства C++, но новые фичи из C++20 потенциально делают C++ менее раздражающим, а значит можно продолжать писать пока на нём".
Поддержка компиляторов всё ещё совсем такая себе
Через год-другой, думаю можно будет уже постепенно тащить в прод.
Раст может позволить себе выкатывать фичи и опробывать их на смелых пользователях, после чего вкатывание фичи происходит только после успешной перекомпиляции всех публичных крейтов.
Я рад, что Rust может позволить себе перекомпилировать все крейты, только это всё равно ничего не гарантирует, хоть и увеличивает шанс, что всё хорошо :)
К счастью, Российской Федерацией мир не ограничивается.
В Яндексе, может быть, и не добавят Rust в список разрешённых языков. Не успеют…
Причем раст они не добавят именно стараниями Полухина, судя по всему.
Интересно, что же начнется, если например гугл решит юзать в хроме куски servo и это дойдет до яндекс браузера.
Все ведь потихоньку в этом направлении и движется, тот же микрософт вот уже сапера на расте пару дней назад выложил.
В определённый момент Яндекс превратился из инновационной компании в оплот консерватизма.
Почему? Потому что я не вижу смысла в переходе на этот язык и дроблении экосистемы на ещё один ЯП. И если растоманы постоянно его везде рекламируют — что же, пора просто начинать пропаганду в обратном направлении, чтобы компании меньше переходили на Rust и больше думали о том, что будет с их кодом через 20 лет.
Здесь тоже самое, только в случае ЯП.
Ну так звёздочки на гитхабе это вполне объективный способ выбора библиотеки.
Чем больше звёздочек => тем больше юзеров => больше гайдов.
Причём если у тебя появляется какая-то проблема, то с 99% вероятностью её решение ты найдёшь только для той либы, которая имеет тысячу звёздочек а не 10.
Вторая же сразу начала активно пиарится, но при этом уступает первой по всем вышеперечисленным параметрам. По моим наблюдениям звёздочек у первой будет больше. Хотя скорее всего вам бы больше понравилась первая либа.
Ну а дробление экосистем — в C++ экосистема и так уже раздроблена. Есть-буст-нет-буста, есть-исключения-нет-исключений, такая-система-сборки-другая-система сборки. Не говоря уж о куче версий языка C++. И если возникнут реальные потребности (а они возникают всё больше и больше), то индустрия безжалостно перейдёт на другой язык, не задумываясь о дроблении экосистемы.
И если вам приходится отвечать на рекламу пропагандой — ну, видать дела у вас совсем плохи :)))
А что с их кодом будет через 20 лет? А что сейчас с кодом, которому даже не 20, а хотя бы 10 лет?
Сейчас C++ по отношению к Rust оказывается в том же положении, в каком был C по отношению к С++. И даже аргументы те же. Скажите, вот что в вашем комментарии не применимо к переходу с C на С++? И где теперь этот C?
То есть вы не видите смысла для себя, и прикладываете усилия для того, чтобы проект не начинали другие люди? :)
Да, совершенно верно. Потому что мне с их кодом потенциально работать.
И если вам приходится отвечать на рекламу пропагандой — ну, видать дела у вас совсем плохи
Это ровно то же самое, что делает Rust. Не вижу ничего зазорного отвечать в той же манере :)
А что с их кодом будет через 20 лет? А что сейчас с кодом, которому даже не 20, а хотя бы 10 лет?
А что, там все либы Rust, написанные за какие-то там 5 лет, успешно собираются последними релизами?
Сейчас C++ по отношению к Rust оказывается в том же положении, в каком был C по отношению к С++. И даже аргументы те же. Скажите, вот что в вашем комментарии не применимо к переходу с C на С++? И где теперь этот C?
Не применим относительно «бесшовный» переход. Потому что С++ хоть и не является полным надмножеством С, но очень-очень с ним совместим. И это значительно облегчает переезд. А где С? Он везде. Ровно там, где ему и место :) Никто в здравом уме не потянет С++ или Rust в код, который испокон веков был написан на С и будет дальше на нём писаться.
Потому что С++ хоть и не является полным надмножеством С, но очень-очень с ним совместим.Ага, конечно. Есть только C программа не испольщует
malloc/calloc и работу с памятью.Дурацкий вопрос: вы вообще много C-программ без
malloc/calloc видели?А вообще и ваши истерики и статьи Полухина — это не просто хорошо, это прекрасно.
Потому что такое уже случалось в истории много раз. Когда представители платоформы-лидера начинают выпускать статьи и телепередачи «да не нужен вам XXX, бросьте каку» — это значит что всоре они будут уже называться «бывшим лидером». И неважно — речь идёт о переходе с Lotus 1-2-3 на Excel или с Microsoft IIS на Apache. Результат один и тот же.
Никто ведь не выпускает статей на тему «почему вам не стоит переписывать ваш код с C++ на C#»… а почему? А потому что тот код, который можно перевести с C++ на C# — уже перевели, переписали, а тому, который не переписали — это и не грозит.
А выдеоролики, подобные обсуждаемому, появляются… то значит пора, по крайней мере, начинать играться с Rust.
P.S. Впрочем как показал опыт перехода с C на C++… никуда C++ не денеться. И через 10 и через 20 лет будут люди, который будут на нём писать. Так что в этом смысле вам ничего не грозит.
Ага, конечно. Есть только C программа не испольщует malloc/calloc и работу с памятью.
А если использует, то что, она совсем иной становится? Да, я знаю про начала лайфтаймов и различие в этом плане между new/malloc. Но даже учитывая это, я считаю эти два ЯП сильно похожи.
А выдеоролики, подобные обсуждаемому, появляются… то значит пора, по крайней мере, начинать играться с Rust.
Так это наоборот правильное решение! Я настоятельно рекомендую многим людям попробовать Rust. Это действительно полезный опыт. Например, хорошо людей приучает, чтобы всё было константным by-design. И много чего ещё полезного.
P.S. Впрочем как показал опыт перехода с C на C++… никуда C++ не денеться. И через 10 и через 20 лет будут люди, который будут на нём писать. Так что в этом смысле вам ничего не грозит.
Я за это не переживаю. Я прекрасно понимаю, что сейчас рождено столько кодовой базы, что мне до моей смерти хватит работы. Я не хочу, чтобы люди на ровном месте бросались переписывать всё на Rust, вот и всего. Также как и начинали писать что-то новое на технологии, которая не показала такой уровень стабильности, как C++.
Я не хочу, чтобы люди на ровном месте бросались переписывать всё на Rust, вот и всего
это хорошее замечание. И действительно — не нужно тратить силы на переписывание чего-то, если их можно направить на создание чего-то принципиально нового. А если силы остались — начать то что называют housekeeping.
Также как и начинали писать что-то новое на технологии, которая не показала такой уровень стабильности, как C++.
ну, это фанатизм. По мне там C# и Java куда более стабильные, чем C++
А если силы остались — начать то что называют housekeeping.
Да! Это абсолютно верная стратегия.
ну, это фанатизм. По мне там C# и Java куда более стабильные, чем C++
А я ничего плохого в их сторону и не говорил. Я слабо знаком с их миром, но насколько я знаю — они тоже достаточно стабильны. Но точной инфы у меня нет.
А если использует, то что, она совсем иной становится?А если использует, то она не скомпилируется. Потому что в C++ нельзя написать
struct S s = malloc(sizeof s);. Надо struct S s = (S*)malloc(sizeof s); как минимум. Но кто-то может «для красоты» и в S s = new S; превратить. Оставив, по прежнему, в точке деаллокации free(s);.Опять-таки в C11 вы можете написать
struct S s = {0}; и потом сравнить две такие структуры через memcmp. А в C++ — не можете.В общем переход с C на C++ — это большая работа. Не просто опии компилятора поменять.
Согласно текущим стандартам C++, недостаточно просто скастовать. См. http://wg21.link/p0593r6, там первым примером идет объяснение того, почему так. Если/когда этот документ будет принят, то будет можно — в C++20 или С++23.
А пока для полного соответствия стандарту надо писать
S* s = new(malloc(sizeof S)) S;Миф про то, что переход с C на C++ тривиален, был показательно развенчан в видео https://www.youtube.com/watch?v=0dkzLdqH9V4, где автор 10 часов потратил на то, чтобы только скомпилировать исходный код Chocolate Doom (причесанный портабельный С-код) в режиме C++
Я не знаю, что в C++ стабильно, кроме job security на некоторых кодовых базах.
отличный троллинг! А еще, наверное, и не только job security, но и з/п выше среднего по рынку? Ну, с++ники — же элита и все как один с 10+ лет синьорского опыта
Ну, с++ники — же элита и все как один с 10+ лет синьорского опыта
Кто вам такое сказал? :) Это ровно такие же работяги, как и условные фронтендщики. Пришёл на завод, смену отпахал за gcc-станком, ушёл. Насчёт ЗП — да хз, вроде вполне себе средне\медианная по рынку.
когда о поддержке C++98/03 можно было говорить лет через 7 после его релиза
В тоже самое время С++20 ещё до своего выхода очень неплохо поддержан GCC 10. Времена меняются. Но это не касается всяких проприетарных компиляторов.
когда компиляторы учатся адекватно оптимизировать новые конструкции через 3-7 лет после их релиза в языке
Тут я тоже не знаю, что ответить. Потому что практически все известные мне оптимизации происходят там, где от С++ кода уже ничего не осталось.
Я не знаю, что в C++ стабильно, кроме job security на некоторых кодовых базах.
Совместимость.
Совместимость.
Ну давайте, расскажите мне про совместимость того же манглинга в минорных версиях одного компилятора, к примеру, гцц))
Ну ё-моё.
Всё верно. Для прода — не годится. Пробовать фичи — годится. Вон кому-то Nightly версии компилятора нормально. Кому-то грейдить страшно компилятор до выхода нескольких патчей. Так что нет никакого противоречия.
Что не мешает хорошо оптимизировать std::min({ a, b, c }) в изолированных примерах, но спиллить регистры, когда окружающий код не столь тривиален.
Репорты на перф-дефекты отправлены? Каков ответ?
Это было бы так, если бы компиляторы не переставали принимать код, который они ранее некорректно принимали.
Баги есть везде :) Это очевидно, вроде как.
В шланге 10 починили, но этой фиче, блин, 9 лет.Недочинили, кажется. Чуть-чуть усложняем… и получаем занесение константы в регистр с плясками и бубном.
-stdlib=libc++, то это фигни не будет.Разница в том что в
libstdc++ tuple — non-trivial for the purposes of calls, а в libc++ — как раз trivial (сравните). Соответственно когда этот самый tuple оказывается в одном регистре дальнейшая попытка это распутать обламывается.Тут, как бы, проблема даже не в том, что такое имеет место быть, а в том, что это, блин, банальный инлайниг. Без какого-то сложного control flow. С которым, как нам говорили, уже много лет назад «всё хорошо». И вот — регулярно вылазят такие косяки… в 2020м году, блин.
P.S. Или если увеличить результат, так чтобы он перестал влазить в регистр… то крабс-бамс-бемс… всё перестало влазить в регистр, «расклеилось» и свернулось.
Это было бы так, если бы компиляторы не переставали принимать код, который они ранее некорректно принимали.
Справедливости ради, в Rust это тоже есть — при переходе со старого borrow checker-а на NLL выловили несколько мест, которые в переходный период (около года, если не ошибаюсь) выдавали предупреждение, а потом стали ошибками. Но — единичный случай ввиду крупной перестройки, и, да, с предупреждением за несколько версий до слома.
Причем раст они (яндекс) не добавят именно стараниями Полухина, судя по всему.ваше утверждение основано на большом количестве спекуляций. Например на том, что мнение Полухина имеет решающий вес будет ли принят раст, на том, что раст экономически целесообразен для яндекса, на том, что профит от переписывания десятков тысяч человеколет плюсового кода на раст превзойдет затраты…
Все ведь потихоньку в этом направлении и движется, тот же микрософт вот уже сапера на расте пару дней назад выложил.тут такое «потихоньку», что к тому времени когда раст станет полноценной заменой с++ разовьется достаточно чтобы смысла писать на расте не было…
Например на том, что мнение Полухина имеет решающий вес будет ли принят раст, на том, что раст экономически целесообразен для яндекса, на том, что профит от переписывания десятков тысяч человеколет плюсового кода на раст превзойдет затраты…
Выше предложили еще отличный аргумент, что не хотят дробить экосистему еще одним языком. Я поддерживаю такой подход. Не хотите, не дробите.
Но когда люди стоят перед выбором "а не начать ли нам новый проект на Rust?", а им попадается доклад Антона, тогда получается уже не очень хорошо.
… тогда получается уже не очень хорошо.
Получается хорошо. Чтобы люди брали проверенные временем и поддерживаемые десятилетиями технологии. Всё так.
А наколенные вещи можно действительно писать на чём угодно, хоть на Rust, хоть на Python.
Получается хорошо. Чтобы люди брали проверенные временем и поддерживаемые десятилетиями технологии.
То есть вы поддерживаете позицию "ложь во благо"? Ну, не очень инженерный подход, прямо скажем.
Прочитал. Все еще придерживаюсь позиции, что по большей части, все перечисленное в статье — так.
А про дезинформацию: возьмем конкретный пункт "Плюсы Rust только в анализе времени жизни объектов." Это откровенная, явная неправда в такой формулировке, потому что как минимум раст похволяет не только контролировать лайфтаймы, но и отсутствие 2-х мутабельных ссылок на данные (ownership), в отличии от C++. Более того, ниже автор доклада явно повторил эту формулировку "Поэтому да — только lifetime", так что вопросы некорректной интепретации видео снимаются.
Так что да, я все еще считаю, что здесь есть "ложь во благо". И я считаю ее неприемлемой для технической дискуссии, даже если это всего лишь один раз за все выступление.
Я никакой лжи в своей речи не вижу. Я вижу только то, что как Rust-community насаждает Rust, так и я, как представитель C++-community, насаждаю С++. И своими словами я нигде, вроде как, ложь про Rust как про ЯП, не сказал пока что.
Я просто говорю о том, чтобы и дальше продолжали писать на С++, а не на Rust, так как толку от переезда сильного нет (если он вообще будет в долгосрочной перспективе).
"Все" действительно лишнее, вы правы.
Я никакой лжи в своей речи не вижу
А вас я во лжи и не обвинял нигде. Давайте восстановим, как было дело:
Но когда люди стоят перед выбором "а не начать ли нам новый проект на Rust?", а им попадается доклад Антона, тогда получается уже не очень хорошо.
Переформулирую: плохо, когда люди будут делать выбор, основываясь на неточной информации (и здесь я сделал вывод, что неточность в докладе была намеренная, так что — ложь).
Далее вы пишите:
Получается хорошо. Чтобы люди брали проверенные временем и поддерживаемые десятилетиями технологии. Всё так.
То есть поддерживаете позицию, что можно говорить что угодно, главное — чтобы выбрали вашу любимую ("проверенную временем") технологию. И вот эту позицию я не разделяю.
Rust-community насаждает Rust
Вы преувеличиваете. Люди просто рассказывают про хороший инструмент. Но вы воспринимаете это как-то в штыки, будто вас насильно заставляют на нем писать. Просто многим зашел этот инструмент, поэтому складывается ощущение, что "он везде". Возможно, это как раз свидетельство того, что он "взлетел" и действительно не так плох. А может и нет, не знаю.
То есть поддерживаете позицию, что можно говорить что угодно, главное — чтобы выбрали вашу любимую
Ну нет, такой вывод тут не следует ни разу, вы что. Я всего лишь придерживаюсь позиции, что если они останутся на С++, то это с моей точки зрения хорошо. По какой причине они останутся — это меня уже не касается. Если из-за неточностей других людей — да, будет совсем некрасиво, но конечный итог меня устраивает. Я повторюсь — я ни в коем случае не пропагандирую намеренное введение в заблуждение.
Вы преувеличиваете
Я был бы рад ошибаться. Но когда налетают коршуны со словами «Переписывайте на Rust» вместо дальнейшего поддержания существующего кода и допиливания в него новых фичей вместо тупого переписывания — мне это очень и очень не нравится. Лучше пусть пилят что-то новое (как хороший пример — самый адекватный Matrix сервер сейчас пишется как раз на Rust и это круто).
Я всего лишь придерживаюсь позиции, что если они останутся на С++, то это с моей точки зрения хорошо.
зачем? Цель какая? Типа все, кто не на С++ пишут — не развивают экосистему? Ну, так и те кто пишут — не все развивают. Не понимаю
Но когда налетают коршуны со словами «Переписывайте на Rust» вместо дальнейшего поддержания существующего кода и допиливания в него новых фичей вместо тупого переписывания
ну, тролли есть всегда и везде )
зачем? Цель какая? Типа все, кто не на С++ пишут — не развивают экосистему? Ну, так и те кто пишут — не все развивают. Не понимаю
Да, совершенно верно. Если они останутся, то шанс развития экосистемы выше, чем они не останутся. Да, я понимаю, что далеко не все развивают экосистему (и это абсолютно нормально).
ну, тролли есть всегда и везде )
Так ладно если б тролли — троллинг это хорошо. Так не троллинг ведь зачастую. Потроллить и я могу, зайдя в условный diesel и сказать, что чот медленно как-то, го перепишем на нормальный быстрый бумерский С++ :)
Ну так и пусть тогда пишут на С++98.
У меня для вас два слова: MSVC и шаблоны. Ну и где-то эхом разносится "зависимостии-и-и".
msvc как реализация давно славился своей «интересной» трактовкой Стандарта. На это можно только сказать, что все претензии к вендору :) Сейчас и сам msvc исправляется очень быстро, и Clang на винде уже доступен. Если у вас msvc-specific код — что ж, тогда больно будет (но и тут мб поможет clang-cl).
А почему не COBOL или не C или не Java или не Lisp и т.д.
Но когда люди стоят перед выбором «а не начать ли нам новый проект на Rust?», а им попадается доклад Антона, тогда получается уже не очень хорошо.то есть вы считаете что люди не должны обладать полной информацией и не должны иметь доступ к обеим точкам зрения по поводу раста?
Этот доклад не претендует на полноту информации, а скорее пропаганда "раст плохой, бросьте бяку". Притягиванием за уши каких-то сценариев и откровенной ложью.
Этот доклад не претендует на полноту информацииточка зрения «раст огонь я не буду слушать контраргументы» не претендует ни на полноту, ни на адекватность
Притягиванием за уши каких-то сценариеваргументы за раст всегда основаны на «притягивании за уши каких-то сценариев». Почему-то вам ок
откровенной ложью.примеры в студию
примеры в студию
unsafe не отключает борровчекер, в статье есть ссылка на статью которая так и называется «Вы не можете ансейфом отключить борровчекер», где подробно объясняется, почему это так.
Есть и другие моменты, но чтобы доказать что в статье есть прямая ложь мне достаточно одного примера.
unsafe не отключает борровчекерна это вам ответил сам автор утверждения. А вообще если бы в расте нельзя было отключить borrow checker, невозможно было бы написать большинство контейнеров эффективно (как минимум список и мапу)
Это возражение переносится один-в-один на С++: "Один UB может убить все проверки С++, так что С++ не даёт никаких преимуществ перед C."
если бы в расте нельзя было отключить borrow checker
Borrow checker в Rust не отключается. То есть не отключается в том же смысле, что в С++ не отключается RAII. Да, можно написать код, который borrow checker не будет проверять (с использованием raw pointers и unsafe), но это не значит, что borrow checker в этом коде отключен.
Да, можно написать код, который borrow checker не будет проверять (с использованием raw pointers и unsafe), но это не значит, что borrow checker в этом коде отключен.borrow checker в таком коде не работает, «но это не значит что borrow checker в этом коде отключен»? Противоречие
Он работает, но не проверяет лайфтаймы сырых указателей.
Только ансейф и нужен чтобы работать с сырыми указателями. Все ансейф блоки которые я встречал работали внутри на 95% именно с сырыми указателями. То что 5% ансейф кода прочекается — это сомнительное достижение. С учетом того что уб сделанное в ансейф коде может выстрелить абсолютно в любой момент, уже после ансейф.
Он работает, но не проверяет лайфтаймы сырых указателей.ну сами посудите. unsafe в большинстве случаев нужен либо для того чтобы работать с сырыми указателями, либо чтобы вызывать unsafe функции которые вызывают unsafe функции… которые работают с сырыми указателями. Итак, вопрос: если я пишу unsafe чтобы поработать с сырыми указателями вместо ссылок/Box'ов, отключаю ли я borrow checker?
Итак, вопрос: если я пишу unsafe чтобы поработать с сырыми указателями вместо ссылок/Box'ов, отключаю ли я borrow checker?
Нет, не отключаете ¯\_(ツ)_/¯
Да какой пример то? Отключить borrow checker нельзя. Вам уже сказали — borrow checker продолжает работать в unsafe секциях, но он не предназначен для указателей by design. Но при этом продолжает проверять ссылки. Хотите пример — держите https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=29e9aef02a12d840b81919c83166a31f. А ваша аргументация — это что-то в стиле "я отключил ПДД, так как лечу на самолете".
Какой-то бестолковый спор. Суть в том что я написал выше. От ошибок с памятью в ансейф блоках борроу чекер не спасает никак.
Акценты не так расставлены. Борроу чекер не занимается спасением от ошибок при работе с сырыми указателями (и некоторыми другими), для спасения от которых он не предназначен. Такие ошибки можно совершить только в unsafe блоке.
Борроу чекер не занимается спасением от ошибок при работе с сырыми указателями (и некоторыми другими), для спасения от которых он не предназначенА. борроу чеккер не покрывает сырые указатели
Б. работать с сырыми указателями можно только в unsafe блоке
Складываем А и Б, делаем вывод: в unsafe блоке можно нарушить гарантии borrow checker'а (используя сырые указатели), о чем я и писал выше.
А если бы это было невозможно, невозможно было бы например передать в сишную либу объект во владение по указателю.
работать с сырыми указателями можно только в unsafe блоке
Кто сказал?
fn ptr_is_null<T>(p: *const T) -> bool {
p.is_null()
}
fn main() {
let x = 42;
let is_null = ptr_is_null(&x as *const _);
dbg!(is_null);
}А если бы это было невозможно, невозможно было бы например передать в сишную либу объект во владение по указателю.
Поправлю. Передать без unsafe можно (если не учитывать unsafe для вызова внешней функции): Box::leak(). А вот забрать владение без unsafe действительно нельзя, так как нет компилятор не может гарантировать, что возвращается валидный указатель.
То есть не отключается в том же смысле, что в С++ не отключается RAII. Да, можно написать код, который borrow checker не будет проверять
Можно пожонглировать определениями, только какой в этом смысл?
Времена жизни ссылок всегда проверяются. Времена жизни указателей всегда не проверяются (но учитываются, см. stacked borrows). Нужно как-то сильно пожонглировать определением слова "отключается", чтобы назвать это отключением.
stacked borrows — это какой-то пропозал или эвритстика miri или что это?
По поводу второй части я написал выше
Формализация семантики unsafe кода (в частности). https://plv.mpi-sws.org/rustbelt/stacked-borrows/paper.pdf
Ох очередная пдф-ка в мой to read лист. Лайфтаймы в расте доказывают что программа коректна по памяти. Что делает эта штука? Она ничего не доказывает но частично ловит ошибки, правильно? Вообщем-то как это делает другие анализаторы из miri? Значит ли это что то что в расте везде навешаны лайфтаймы то их проще вывести и для указателей* из окружающего кода? Потому что явных лайфтаймов в указателях я что то не помню.
Про алгоритмы MIRI можно еще тут почитать: https://www.ralfj.de/blog/2018/11/16/stacked-borrows-implementation.html
Ох очередная пдф-ка в мой to read лист.
Ссылка что я дал — куда меньше, там минут на 15 чтения.
Спасибо, но 15 минут, это вы слишком хорошего мнения обо мне. Конечно если речь про скорочтение как в 1ом классе то в 15 минут я уложился :)
Я то понял что это эвристика MIRI. Но, хмм, вроде там ограничения такие же как у борроу чекера, хотя по идее должно быть более "flexible".
Нет, у них разные алгоритмы. Борровчекер не использует stacked borrows, он вообще игнорирует сырые указатели, а мири — нет.
Да я прочёл но ещё не до конца. Вроде как для обычных референсов они тэгаются полностью через Unique(t), и пофиг stacked или не stacked оба в результате дают правило вложенности. А вот для сырых там какой то SharedRW(bottom), который не тегается. У меня сложилось впечатление что это хорошо сработает на границах safe-unsafe но не внутри unsafe. Если честно мне пдф-ка понравилась больше чем блог, там больше разжёвано.
Но когда люди стоят перед выбором «а не начать ли нам новый проект на Rust?», а им попадается доклад Антона, тогда получается уже не очень хорошо.
Что не хорошо то? Люди хотят начать новый проект в продакшене на Rust. Это означает что его потребуется поддерживать. При всём уважении к Rust и моей радостью что его активно развивает Mozilla, подавляющее большинство компаний это не осилят ибо язык слишком сырой, а самое главное нет вообще никаких гарантий, что не выйдет новая версия которая потребует переписать всё.
Э-э-э, а какого рода гарантии дают другие языки?
Мне нравится Rust, но у себя (не в pet проекте) использовать я его буду очень не скоро ибо это очень большие риски для компании.
На C++ у меня есть проекты с кодовой базой в т. ч. по 15+ лет и они работают и потихоньку переписываются на свежее, благо, что С++20 уже везде поддерживается, за исключением нескольких мест в Embedded. Когда в конце 10х участвовал в разработке FlylinkDC++ там тоже были места родом ещё из середины 90х и это работало «из коробки».
Ну так какие гарантии, что комитет C++ внезапно не решит всё ломать? (:
Или этого не случится потому что противоречит здравому смыслу и никому не нужно? Ну так и с растом такая же ситуация.
Как это отражается на дизайне языка — легко отследить по тем же модулям и спорам вокруг них.
Вон как модули завезли, то как я понимаю в С++ становится реально завезти механизм эпох (аналог Editions из Rust, за что им спасибо).
Вон как модули завезли, то как я понимаю в С++ становится реально завезти механизм эпох (аналог Editions из Rust, за что им спасибо).Я надеялся на это, как на способ выхода из тупика… но пообщавшись с людьми, участвующими в стандартизации C++, выяснил, что они в этом направлении даже и не думают.
Комитет C++ активно «блюдёт» возможность «не сломать всем всё».
Это на бумаге так.
А разработчики компилятора раста могут позволить перекомпилировать все публичные крейты, чтобы проверить, что новое изменение ничего не поломает.
Не забываем еще про двустороннюю совместимость редакций, когда крейт 2015 редакции может иметь зависимость крейта с редакцией 2018. Плюсам такой стабильности никогда не добиться.
Это на бумаге так.
А это разве не так?
Плюсам такой стабильности никогда не добиться.
А не добиться почему? Что мешает сделать это с потенциальным механизмом эпох на основе С++ модулей?
Так давно уже ломают совместимость: https://stackoverflow.com/questions/6399615/what-breaking-changes-are-introduced-in-c11
Что мешает сделать это с потенциальным механизмом эпох на основе С++ модулей?
В C++30? Посмотрим.
В C++30? Посмотрим.
Конечно посмотрим :)
Комитет C++ активно «блюдёт» возможность «не сломать всем всё
Простите, но чем это отличается от раста? С первой версии (вышла пять лет назад) у раста такой же подход.
Простите, но С++ даже 3 года не продержался. Первый результат: https://twitter.com/timur_audio/status/1055771081993269248?s=20
because the lexer now eats <=> as a single token:Видимо его личный гипотетический лексер, а не настоящий. В реальном мире это будет перевариваться не хуже чем такой побитовый сдвиг:
vector<vector<int>>В ответах к твиту скинули код, который компилируется по разному в C++17 и предварительном режиме C++20
<=> встречаются настолько редко (буквально одна-две коллизии на миллион строк по исследованиям), что ни в компиляторах поддержки нет, ни в страндарте не будет, скорее всего.struct Foo {
Foo() = delete;
};
Foo foo = {};
Комитет, принимающий простые изменения по несколько лет ¯_(ツ)_/¯
Скорее всего не потребует. Rust специально проектировался так, чтобы можно было развивать язык, не ломая старый код. Уже сейчас сущестуют две редакции языка: Rust 2015 и Rust 2018. И вы спокойно можете использовать crate одной редакции с программой другой.
раст станет полноценной заменой с++
Он уже стал.
с++ разовьется достаточно чтобы смысла писать на расте не было…
В рамках С++ без того, чтобы напрочь сломать обратную совместимость (и в таком случае это будет уже не С++), можно с уверенностью сказать, что это невозможно.
Он уже стал.
Он не стал
В рамках С++ без того, чтобы напрочь сломать обратную совместимость (и в таком случае это будет уже не С++), можно с уверенностью сказать, что это невозможно.
А невозможно что именно? :) Вон С++ развивается семимильными шагами и новые фичи постоянно завозят. Так чего там невозможного то, а? Или так хочется, чтобы в С++ сломали обратную совместимость и конкурента точно убрали?
Он не стал
К счастью стал и интерес со стороны системных программистов к нему все выше и выше. Браузеры профит от него получили. Настал черед драйверов и ядер ОС, где расту самое место.
Так чего там невозможного то, а?
Невозможно заставить компилятор ругаться на небезопасный код, потому что для С++ он является корректным. До тех пор, пока С++ на уровне семантики (читай стандарта) не начнет давать гарантии, безопасным он не станет.
К счастью стал
К счастью не стал. Интерес пусть будет. Я приложу все усилия, чтобы он только интерес и вызывал, а прод как писали так и продолжат писать на С++. Не знаю, черёд чего там настал.
Невозможно заставить компилятор ругаться на небезопасный код, потому что для С++ он является корректным. До тех пор, пока С++ на уровне семантики (читай стандарта) не начнет давать гарантии, безопасным он не станет.
Именно поэтому и нужно развитие, чтобы если не весь C++, но хоть какая-то его часть сделалась безопасной и могла давать гарантии.
Именно поэтому и нужно развитие, чтобы если не весь C++, но хоть какая-то его часть сделалась безопасной и могла давать гарантии.
Уже давно ходит шутка, что Rust это C++2050.
А можно по пунктам, из счего это развитие состоит? Только не надо про "100500 библиотек и поддержку от гцц", это уже следствие, если язык хороший. Речь про уровень языка.
Так вот, что надо расту ещё развить? Можно перечень?
Перечень. И я там, кстати, забыл про placement new ещё упомянуть.
Ну тут много чего полезного, половины из этого перечня и в плюсах нет, значит ли это что на них нельзя писать пока не сделают (те же генерики, хоть higher-kind, хоть каких)?
половины из этого перечня и в плюсах нет
Какой половины? Из всего перечисленного в C++ нет разве что генераторов.
Ну в плюсах нет генериков, например (шаблоны это не генерики, как нам любезно подсказывает тот же msdn), значит нет и всех связанных с ними фичей.
Или написать можно, но компилятор ничего не проверяет во время компиляции шаблона, только после подстановки?
это да. Но не любой шаблон из С++ перенесёшь в раст. Т.е. различия немого ортогнальны.
В расте есть asm! макрос, где-то его вроде я даже слышал что используют. У нас, правда, стараются писать переносимый код, и влиять на ассемблер путём манипуляций с атрибутами и инстринками, так что лично не сталкивался.
Вот тут ошибочка, встроенный ассемблер отсутствует в стандарте Си или плюсов, это все вендорные расширения.
То есть ситуация не особо отличается от llvm_asm! макроса в nightly rust.
В рамках С++ без того, чтобы напрочь сломать обратную совместимость (и в таком случае это будет уже не С++), можно с уверенностью сказать, что это невозможно.способы развивать язык поддерживая обратную совместимость существуют, а вот поддерживать обратную совместимость на языке, который её не гарантирует, несколько сложнее
Можно их написать на раст без оборачивания в с++? можно ли на раст писать под микроконтроллеры там где нет ОС? Голый раст и компиляция под конкретное железо. AtMega, PIC, STM?
Да. Да. Да. STM.
Вот коммент с примером, чтобы не повторяться: https://habr.com/post/467901/#comment_20638103
Раст самодостаточен? На раст можно раст написать?Написать можно, но пока никто не сделал. Впрочем и LLVM далеко не в 2003м стало возможным для компиляции LLVM использовать.
Так что этот факт меня меньше всего напрягает.
можно ли на раст писать под микроконтроллеры там где нет ОС? Голый раст и компиляция под конкретное железо. AtMega, PIC, STM?Да, этим разные безбашенные люди занимаются. Почему безбашенные? Потому что там нужны фичи, которых в стабильном Rust нету, есть только Nightly.
Написать можно, но пока никто не сделал.
Cranelift-бэкенд потихоньку прогрессирует, кстати.
можно ли на раст писать под микроконтроллеры там где нет ОС? Голый раст и компиляция под конкретное железо. AtMega, PIC, STM?Да, этим разные безбашенные люди занимаются. Почему безбашенные? Потому что там нужны фичи, которых в стабильном Rust нету, есть только Nightly.
Если я ничего не путаю, базовый embedded на стабильной версии работает.
Если я ничего не путаю, базовый embedded на стабильной версии работает.В стабильной версии нет ассемблера. А в embedded без этого очень тяжело. Там ещё каких-то вещей не хватает, проде бы, но уже не столь критичных.
Справедливости ради, в случае сообщество Rust серъезно прорабатывает вопрос с embedded, есть специальная рабочая группа, в то время как в случае с плюсами есть лишь вендорные экстеншены для того, чтобы плюсы или сишка могли в embedded.
Ну в самом деле, за все годы существования как плюсов так и Си так и не появилось никакого стандарта на inline asm.
До тех пор, пока они локализованы, можно обойтись крейтами, собирающими и подключающими отдельные ассемблерные файлы. Quickstart для ARM не требует ночника.
Вот для чего потребуется nightly-версия — так это для тех архитектур, для которых недоступен собранный крейт core. Вот для его сборки, в первом приближении, обязательна nightly-версия.
Но без этапа «поиграться» я бы вооще никакую технологию не рекомендовал использовать, так что если вы хотите использовать Rust в embedded — можно уже пробовать.
Выход LLVM почти наверняка будет быстрее, потому что cranelift заточен под быструю компиляцию, а не под быстрый результирующий код.
Замену в чём именно? В идеале предполагается заменить им LLVM для дебаг-билдов, потому что производительность LLVM — один из ключевых факторов, ограничивающих скорость их сборки.
Можно ли написать на Расте бэкенд с производительностью кода не хуже, чем у LLVM? Зависит от того, сколько человеко-лет в него вложить...
Я к тому, что внутри можно создать safe подмножество. Точно также, как это сделано в Rust. Только весь старый код считать как unsafe C++. А новый на этом подмножестве — safe C++. Возможно это или нет — действительно хороший вопрос.
Для такого подмножества весь внешний код будет unsafe, причем многие вещи тупо не пролезут через границу подмножеств напрямую. А в таком случае это подмножество не имеет никаких преимуществ перед rust.
К тому же, как мне кажется, что начать делать несовместимые edition'ы языка нужны модули, когда они будут? В 27 году?
Модули уже в С++20. Или вы про то, когда они появятся в реальных проектах?
Чаще всего пользователю нужна безопасность в целом, иначе бы и на расте все по всюду расставляли unsafe. В итоге какой смысл начинать новый проект на плюсах, если раст безопаснее и удобнее.
Rust первого пока что не показал. Если покажет и докажет временем, что он также умеет — можно и на Rust начинать новые проекты :)
Обратная совместимость это ОЧЕНЬ важно. И это касается всей существующей на сегодняшний момент кодобазы в мире.
(чтобы не бояться за код через условные 10 лет)
давайте честно — с дефолтными флагами код через 10 лет тупо не скомпилируется. Да, наверняка, можно подобрать параметры компиляции, да, обернуть код какими-то обертками — возможно, что он заработает, но будет ли он после этого корректен и исходное поведение соблюдено? А вот не факт. Поэтому… Ну, не знаю — может ли это быть аргументом.
Да, я таскал код еще в 2003-2007 между версиями C++ и это была боль найти общее подмножество, чтобы все работало идентично, собиралось под разными средами и все такое. Но не у всех есть такая задача — тот же Яндекс наверняка МОЖЕТ себе позволить выбрать некий стандартный для себя тулинг и потихоньку со временем его менять. Но это специфика веб-разработки в противовес системному программированию (разработка ОС, драйверов, библиотеки и пр) или коробочному (те же игры, например)
давайте честно — с дефолтными флагами код через 10 лет тупо не скомпилируется.
Я уже тут не согласен. Я компилировал такой код с дефолтными для всей С++ инфры флагами код с 1989 года емнип (компилил на gcc 5, msvc какой-то там, кто идёт в Visual Studio 2017). Не могу припомнить боли. Скомпилировался, работал, хоть и было очень много предупреждений. Больше опыта сборки такого доисторического кода не имел.
но будет ли он после этого корректен и исходное поведение соблюдено
Такой гарантии строго говоря нельзя всё равно дать без покрытия тестами, чтобы мы не использовали.
Мне кажется или лет 10 назад культура разработки была хуже, чем сейчас? Тесты — согласен — без них никуда, но есть языки, в которые тесты более нативные, их проще едлать, чем в с++. Тот же голанг.
Это в с чего бы раст не показал обратную совместимость? Был только переход на 2018 edition, будет и 2021 edition с какими-то изменениями, но всегда можно остаться на старом edition и продолжить себе спокойно жить.
То что разрабы крейтов иногда забивают на semver бывает, но увы, это неразрешимая проблема. К тому же, всегда можно составить lock файл, который бы юзал именно нужные версии депенденсей, чтобы все собиралось.
Лок версии зависимостей это понятно — это везде так делают, в том числе и в С++.
Типа должно пройти еще десять лет, чтобы в гарантии поверили? Как-то повеяло Коболом.
Мне кажется, что пары лет соблюдения гарантии вполне достаточно, а так-же наличия достаточно серъезных проектов на языке.
Лок версии зависимостей это понятно — это везде так делают, в том числе и в С++.
Только вот вчера ещё не было нормального менеджмента зависимостей в с++. Как это выглядело? Тупо клонируем к себе код зависимости и билдим как библиотекой. Прямо вендоринг. И потом надеемся, что это у заказчика/пользователя будет после компиляции работать.
А сегодня у плюсов есть аналог cargo?
Ну, вроде есть подвижки в этом направлении. Но я не крестовик. Поэтому особо не слежу. По крайне мере ясно одно — кучу кода, который Легаси, который создан за все время существования с++ придется импортить по старому, пока его не приведут к "ещё одному новому стандарту"
Но он же не система сборки, а скорее обертка. В итоге получается, что его когнитивная сложность и хрупкость априори куда круче, чем у связки cargo + build.rs.
система сборки
bazel? но это не с/с++ специфично
cmake? фу
что там еще есть?
cmake лучше, чем autotools, но кажется на этом его преимущества заканчиваются, да захавает его Ктулху.
Блин, так подумать, то идея со скриптами сборки прямо на самом Rust'е в build.rs файле для cargo не такая уж и плохая.
Наверное, можно было бы родить что-то похожее и на плюсах, дабы не городить еще какие-то дополнительные DSL'и. А в случае если не нужны сложности, обходится декларативным конфигом аля Cargo.toml
А через 10 лет вы будете говорить, что по сравнению с 40 годами стабильности С++… Ну вы поняли.
При этом в комитете, по-видимому, куча людей которые ни капли не смыслят в практическом применении тех фич, которые они утверждают — в результате получаем такой ужас как enum class, из которого невозможно достать хранящиеся в нём значения без ручного вызова cast'a, или deprecate побитных операций для enum'ов разного типа, что ломает классические трюки вроде QT'шной проверки на флаги:
enum PolicyFlag {
GrowFlag = 1,
ExpandFlag = 2,
ShrinkFlag = 4,
IgnoreFlag = 8
};
enum Policy {
Fixed = 0,
Minimum = GrowFlag,
Maximum = ShrinkFlag,
Preferred = GrowFlag | ShrinkFlag,
MinimumExpanding = GrowFlag | ExpandFlag,
Expanding = GrowFlag | ShrinkFlag | ExpandFlag,
Ignored = ShrinkFlag | GrowFlag | IgnoreFlag
};
Qt::Orientations expandingDirections() {
return ( (verticalPolicy() & ExpandFlag) ? Qt::Vertical : Qt::Orientations() )
| ( (horizontalPolicy() & ExpandFlag) ? Qt::Horizontal : Qt::Orientations() ) ;
}
такой ужас как enum class, из которого невозможно достать хранящиеся в нём значения без ручного вызова cast'a
А что, это прям настолько плохо?
Например, в enum class хранились значения не больше 255, поэтому под него выделили 8 бит. Везде, где надо, его значения преобразуют при помощи static_cast в соответствующий тип.
Потом требования изменились и его размер изменили на 32 бита.
Все места использования сломались (потому что запихивают 32 бита в 8 бит) — при этом без каких-либо намёков со стороны компилятора что что-то не так.
enum class Enumeration : int32_t {First, Second, Third};
void foo(Enumeration e)
{
auto el = static_cast<std::underlying_type_t<decltype(e)>>(e);
static_assert(std::is_same<decltype(el), int32_t>::value, "type must be int32_t");
}
Или вы «прям так» через static_cast в условный char хреначите? Ну так делать не надо, потому что когда компилятор видит narrowing conversion через static_cast, то он считает, что программист в данном месте знает, что делает.
А, и вы дважды писали название конвертируемого элемента «e», что тоже чревато ошибками.
Способность сконвертировать Enum в его тип должна быть встроена в сам Enum, а не требовать костылей из библиотеки шаблонов.
enum class Enumeration : int32_t {First, Second, Third};
template <typename T, typename = std::enable_if_t<std::is_enum<T>::value>>
auto enum_to_underlying(T arg)
{
return static_cast<std::underlying_type_t<T>>(arg);
}
void foo(Enumeration e)
{
auto el = enum_to_underlying(e);
static_assert(std::is_same<decltype(el), int32_t>::value, "type must be int32_t");
}
Это не «костыль» из библиотеки шаблонов, а просто один из стандартных type traits, они все так оформлены.
Вы действительно считаете, что это чем-то лучше чего-нибудь вроде добавления оператора enum class::to_type(e), или разрешения прямого использование этих данных как константы с соответствующим типом — как это было в enum до всех этих нововведений?
Эта шаблонная функция пишется один раз, добавляется в какой-нибудь util.h и работает с любыми enum class. Если вам нужны "константы с соответствующим типом", то вам не нужен enum class, вам нужен просто enum. Весь смысл enum class как раз в отсутствии автокаста к numeric types, чтобы различные enum class нельзя было приводить друг к другу и к int без явного static_cast. Если вы хотите, чтобы приводить было можно, осуществлять битовые операции между элементами разных enum и так далее — не используйте enum class, он не для этого, используйте обычный enum.
Весь смысл enum class как раз в отсутствии автокаста к numeric typesНе соглашусь. Главный смысл enum class — в очищении пространства имён от элементов enum'а, чтобы не было путаницы когда у вас есть что-нибудь вроде Page::Normal и View::Normal.
не присваивали, не складывали и не сравнивали длину и ширину
1) это можно было бы запретить для случаев, когда элементам enum class не присвоены значения вручную, или сделав специальный underlying integer type для которого удалены эти операторы — причём по умолчанию в enum class использовался бы именно он.
2) Это не означает, что у enum class не должно быть возможности нормально, штатным оператором достать из него эти значения, не теребя библиотеку шаблонов.
Плохое решение: появляется излишнее имя (namespace'а), плюс внутри этого namespace'а получаем конфликт имён во всей красе.
Отдельный namespace делается для каждого enum, поэтому откуда там может взяться «конфликт имен во всей красе» — непонятно. Внутри enum конфликт имен не возникает, а внутри namespace возникнет?
Это не означает, что у enum class не должно быть возможности нормально, штатным оператором достать из него эти значения, не теребя библиотеку шаблонов.
Еще раз, этот «штатный оператор» пишется за 1 минуту и работает с любыми enum. Этак можно и до leftpad докатиться. А cтандартные type_traits (с помощью которых и пишутся такие «операторы») предоставляют такие механизмы, которым этот оператор и в подметки не годится.
Плохое решение: появляется излишнее имя (namespace'а), плюс внутри этого namespace'а получаем конфликт имён во всей красе.Namespace, как бы, каши не просят. Никто не мешает вам заводить по штуке на каждый enum. Можно макрос сделать, если уж так хочется.
Всё остальное — это рассуждения на тему «а как нам поддержать ещё пару экзотических вариантов добавив ещё пять страниц в описание языка». Комитет по стандартизации с этим старается, по возможности, бороться. Потому что ровно те же люди, которые просят добавить ещё 2-3-5-10 хитрозаворочанных случаев для поддержки вот именно их use case… стонут потом о том, что стандарт языка — слишком велик.
2) Это не означает, что у enum class не должно быть возможности нормально, штатным оператором достать из него эти значения, не теребя библиотеку шаблонов.Означает. Каждый раз когда рассматривается какая-то фича комитет по стандартизации сравнивает пользу от её реализации в языке в сравнении с реализацией её же конкретным Васей Пупкиным для конкретного проекта.
Как вам показали —
enum_to_underlying пишется элементарно. А в стандартную библиотеку он попадёт если будет выяснено, что люди им активно пользуются. Если не пользуются — значит и не надо.Namespace, как бы, каши не просят.Почему? Просят.
Вместе с полезным доступом к элементам ты получаешь внагрузку необходимость указывать этот namespace и при объявлении самих enum-переменных.
Как вам показали — enum_to_underlying пишется элементарноРади интереса глянул код QT — вместо enum_to_underlying они везде пишут прямую конвертацию uint(ProfileClass::Input), причём там вполне возможна потеря в точности, потому что type там quint_32.
Единственное место, где используется enum_to_underlying — это в сериализаторе (потому что там иначе вообще нельзя).
Аналогичная ситуация в LLVM (а уж кто должен бы знать всю эту библиотеку типов как свои пять пальцев!) — элементы из enum class SymbolRole: uint32_t достаются оператором (unsigned).
Так что про «элементарно» — вы загнули.
Вместе с полезным доступом к элементам ты получаешь внагрузку необходимость указывать этот namespace и при объявлении самих enum-переменных.
Не получаешь:
namespace EnumN {
enum Enum {First, Second, Third};
}
using Enum = EnumN::Enum;
Enum foo = Enum::First;
Про Qt — этот код возможно у них остался еще со времен до C++11, это же довольно матерый проект уже.
Про Qt — этот код возможно у них остался еще со времен до C++11, это же довольно матерый проект уже.Код не мог остаться со времён до C++11 так как enum class появился в C++11.
И могу поспорить, что возьми я любой другой популярный проект с открытым кодом — то ни в одном из них, использующих enum class для хранения констант для их получения практически никогда не будет использоваться underlying_type — если уж у создателей компилятора на это не поднялись руки, то у всех остальных и подавно.
Ну, тогда теперь вы знаете больше, чем разработчики qt и llvm :)
И могу поспорить, что возьми я любой другой популярный проект с открытым кодом — то ни в одном из них, использующих enum class для хранения констант для их получения практически никогда не будет использоваться underlying_type — если уж у создателей компилятора на это не поднялись руки, то у всех остальных и подавно.Что и указывает на уровень «востребованности» этой фичи. Во всех известных мне проектах для «потенциально расширяемых»
enumов используется int и никто не парится со всем тем ужасом, который вы сами себе насоздавали. Ну а если вы хотите выстрелить себе в ногу… в C++ богатейший арсенал и в других местах.Проблема же с увеличением размера необходимого underlying type — это не фича, а крайне неприятный побочный эффект из-за отсутствия такой штатной возможности.
И судить о её частоте невозможно из-за того, что будущие требования к программе никогда нельзя точно знать заранее.
Проблема же с увеличением размера необходимого underlying type — это не фича, а крайне неприятный побочный эффект из-за отсутствия такой штатной возможности.Вот только вы перевернули всё с ног на голову. Проблема с незафиксированным размером
enum — идёт ещё с C89. Вот это вот — проблема. И для её решения приходится применять разного рода костыли. В C++11 вы можете указать этот тип — чем проблема и решается. А для «вытаскивания» можно всегда использовать «достаточно большой» тип (скажем
unsigned) и не парить людям мозг.Если же вы выбрали размер настолько неправильно, что вам приходится его менять, да ешё и так, что
enum перестаёт влазить в unsigned — то вы ССЗБ и заслуживаете то, что получаете. Если же ваш дизайн, почему-то, на это завязан — то C++ предоставляет средства для того, чтобы эту, редкую на практике проблему — это тоже можно разрешить.И судить о её частоте невозможно из-за того, что будущие требования к программе никогда нельзя точно знать заранее.Нельзя. Но можно предсказать последствия от наличия идиотов среди разработчиков. И они таковы, что если вы не можете предотвратить их появление — то лучше с проекта просто уйти.
У KDE есть специально policy в котором, среди прочего, описано как расширять
enum. Если вы будете ему следовать никаких, вот совсем никаких, проблем с C++11 у вас не будет.Бинарная совместимость отнюдь не всегда важна, а вот возможность получить ошибку от компилятора (вместо неправильной работы программы из-за обрезания данных от того, что «достаточно большой» — недостаточен) — бесценна.
Бинарная совместимость отнюдь не всегда важна, а вот возможность получить ошибку от компилятора (вместо неправильной работы программы из-за обрезания данных от того, что «достаточно большой» — недостаточен) — бесценна.Если вы исповедуете этот принцип, то вы зря, в принципе, выбрали C++. Для вас есть вские Idris'ы и Haskell'и, или, может быть, даже Rust — но никак не C++. Тут и
float может в char «влезть» без каких-либо жалоб со стороны компилятора.Так что про «элементарно» — вы загнули.То, что что-то пишется элементарно не обозначает, что оно будет написано и использовано. Менять размер
enum — очень плохая затея по многим причинам. А если этого не делать — то и проблемы нет.Единственное место, где используется enum_to_underlying — это в сериализаторе (потому что там иначе вообще нельзя).Ну то есть люди про эту возможность знают — но предпочитают не использовать. Это их выбор…
Способность сконвертировать Enum в его тип должна быть встроена в сам Enum, а не требовать костылей из библиотеки шаблонов.Это почему вдруг? Есть куча способов использовать
enumы без такой возможности. В Java такой возможности нет вообще, в принципе… и ничего — никто не вопит, что этими enumами пользоваться нельзя.К тому же стандартые
enum, которые не enum class никто не отменял, если вам они полходят больше — пользуйтесь ими. Или вы как сорока — тянете в гнездо всё, что новое, блестящее?Вопрос в том, зачем хранить в enum class конкретные значения, если этих самых конкретных значений из него не получить без анального секса с трёхэтажными шаблонами из стандартной библиотеки, про которые ещё и откуда-то надо узнать?
которые не enum class никто не отменял, если вам они подходят больше — пользуйтесь ими.Вообще-то вторая часть поста как раз про то, что стандартные enum они тоже испортили. Оставлять deprecated код не есть гуд.
Вообще-то вторая часть поста как раз про то, что стандартные enum они тоже испортили.Ссылку на то место в стандерте, где ко-то что-то в стандартных
enum вам испортил.reviews.llvm.org/D71576
Место в стандарте
www.open-std.org/jtc1/sc22/wg21/docs/papers/2018/p1120r0.html
про которые ещё и откуда-то надо узнать?
Свой инструмент все-таки надо знать. Просто странно выглядят жалобы, что он там как-то плохо сделан, а в комитете сидят одни дураки, когда эти «дураки» на самом-то деле предусмотрели инструментарий для решения довольно типичной проблемы, с которой вы столкнулись, просто вы об этом не знаете. Причем этот инструментарий гораздо шире, чем просто «добавление оператора», поскольку позволяет узнать именно ТИП, что позволяет, например, объявлять переменные и члены структур именно того типа, который является underlying type для конкретного enum'а, или делать на этой основе специализации функций.
А то, что вы можете выстрелить себе в ногу… так в этом весь C++. Он везде так устроен.
В Rust такой ситуации нет. Да и в C++ в подобной ситуации можно было бы унаследовать этот несчастный enum class от std::uint8_t.
P.S. Кстати, выше я привел пример, как можно узнать underlying type у enum в C++, а как в подобном случае это сделать в расте?
Проблема в ущербности enum class в C++. Сделали отличную штуку, но в типичном для C++ стиле, то есть не до конца. Для него не определены битовые операторы, поэтому enum class попросту невозможно использовать для хранения флагов, т.е. перечислений со значениями — степенями двойки.
И в итоге приходится либо костылять свои операторы, либо делать приведение типов, либо использовать не менее ущербный C-шный enum.
И в итоге приходится либо костылять свои операторы, либо делать приведение типов, либо использовать не менее ущербный C-шный enum.Не очень понятно ни что в нём ущербного, ни что вы, собственно от него хотите. Всё, что требуется — он умеет:namespace FooProtector {
enum Foo {
Foo1 = 1, Foo2 = 2, Foo3 = 4
};
}
using Foo = FooProtector::Foo;
int foo = Foo::Foo1 | Foo::Foo2;
Вот как раз то, что умеет
enum class без него сделать нельзя…Не очень понятно ни что в нём ущербного
Слабая типизация же.
int foo = Foo::Foo1 | Bar::Bar1 | 42;А тем временем в Rust есть сильно типизированные флаги с битовыми операциями и возможностью достать нижележащее значение.
Ну так а как хотя бы из этих флагов underlying type достать?
type UnderlyingType = u8;
bitflags! {
pub struct Flags: UnderlyingType {
// etc
}
}Или
type SizedAsFlags = [u8; std::mem::size_of::<Flags>()];Другое дело, что непонятно, для чего это нужно, потому что если требуется
поле, размер которого точно соответствует размерности нижележащего значения, скажем, для его сериализации
, то проще сделать сам тип флагов сериализуемым.
Правда, что делать, если этот Flags нам приходит в качестве генерика, все равно непонятно.
Так Rust — это не C++, вы просто не можете толком ничего сделать с обобщённым типом, не навесив на него никаких ограничений. Если вы ожидаете, что обобщённый тип — это именно набор флагов, то это в коде выражается в виде соответствующего ограничения, что-то вроде
fn some_generic_funce<F: FlagSet>(flags: F, ...) { ... }, где FlagSet — это трейт, в который можно и положить нижележащий тип как ассоциированный тип:
trait FlagSet {
type UnderlyingType;
fn into_underlying(self) -> Self::UnderlyingType;
// ...
}enumов в одной конструкции использовать. Собственно class enum дал ровно две вещи:- Невозможность преобразования типов без явного
castа. - Невозможность обращения к элементам без указания имени типа.
Так вот второе — отлично делается в любом C++98 без всяких
enum class. А первое — не делается. То, что enum class реализовали варинант, который без них не делается… мне кажется логичным.См magic_enum
#if defined(MAGIC_ENUM_SUPPORTED) && MAGIC_ENUM_SUPPORTED
# if defined(__clang__)
constexpr std::string_view name{__PRETTY_FUNCTION__ + 34, sizeof(__PRETTY_FUNCTION__) - 36};
# elif defined(__GNUC__)
constexpr std::string_view name{__PRETTY_FUNCTION__ + 49, sizeof(__PRETTY_FUNCTION__) - 51};
# elif defined(_MSC_VER)
constexpr std::string_view name{__FUNCSIG__ + 40, sizeof(__FUNCSIG__) - 57};
# endif
Взорваться при обновлении компилятора это может прекрасно…
А почему? Он молча глотал сужающее преобразование даже без ворнинга?
warningов. Новичики на эти грабли наступают постоянно, и даже для некоторых разработчиков со стажем это часто является открытием…— усекаем до младших битов (и не волнует изменение значения)
— ставим thread-local флаг в 1
— генерируем C++ исключение
Хотя, если по аналогии с GCC __builtin_add_overflow будет __builtin_convert_overflow с отдельным результатом «ой переполнилось», остальные можно будет выразить из него просто шаблонной функцией.
Хотя, если по аналогии с GCCКазалось бы…__builtin_add_overflowбудет__builtin_convert_overflowс отдельным результатом «ой переполнилось», остальные можно будет выразить из него просто шаблонной функцией.
__builtin_convert_overflow тривиально порождается из __builtin_add_overflow. Да, странно, что более простая функция делается из более сложно… но это как раз стиль C++. Компиляторы «просекают фишку» и никакого «лишнего» сложения, конечно, не происходит — даже в древнючих, как говно мамонта, версиях.Ага. Вчитался в тонкие формулировки — раньше то ли пропустил, то ли забыл это про три разных типа и про «If the stored result is equal to the infinite precision result...»
Спасибо. Приятно видеть, что хоть и поздно, но грамотно сделано :)
...
char x = 555;
...
tst017.cpp:11:12: warning: implicit conversion from 'int' to 'char' changes value from 555 to 43 [-Wconstant-conversion]
char x = 555;
Интересно, что же начнется, если например гугл решит юзать в хроме куски servo и это дойдет до яндекс браузера.
Этого кстати вполне можно ожидать в обозримом будущем.
В ChromeOS, например, раст уже используется — crosvm.
Или COBOL в сфере финансов тоже устали убивать.
Оптимизм это хорошо, но человеческая лень всегда сильнее, так как переписывать это все чисты энтузиазм, никто не будет тратить миллионы, чтобы получить тоже самое, просто красивее.
Rust убьёт C++ и, возможно, C в перспективе 10 лет, это уже просматривается сейчас.
Ага, щазз. Аж два раза.
Тут кобол уже сколько десятилетий похоронить никак не могут. А вы уже на С и С++ замахнулись.
Синтаксис вам не нравится или непонятна семантика? Можно пример "ужасного синтаксиса"?
github.com/xacrimon/dashmap/blob/master/src/iter.rs :227
impl<'a, K: Eq + Hash, V, S: 'a + BuildHasher + Clone, M: Map<'a, K, V, S>> Iterator
for IterMut<'a, K, V, S, M>А как по-вашему в идеальном языке пролграммирования должна выглядеть такая запись?
Посмотрим на итератор в неидеальном Nim, к сравнению
iterator filter*[T](s: openArray[T], pred: proc(x: T): bool {.closure.}): T =
## Iterates through a container `s` and yields every item that fulfills the
## predicate `pred` (function that returns a `bool`).
пример вызова
bar = toSeq(1..10).mapIt(it*2).filterIt(it mod 6 != 0)
А причём тут filter? Эта функция и на Rust не сильно-то и сложно выглядит.
Вы привели реализацию итератора для хеш-таблицы, которую можно использовать из разных потоков.
В принципе я дал ссылку на исходники всех итераторов на Nim, там такого ада, как в Расте нет нигде.
Итераторы в nim какие-то убогие: можно использовать нормально только в цикле for, имеют пространство имён, отдельное от процедур (и это не будут фиксить), итерирование вручную требует использовать system.finished… Я даже не могу понять, ленивость-то там вообще есть? И почему настолько сложно сделать zip на ленивых итераторах?
Прочитал по диагонали, но похоже на то, что в языке есть один алгоритм хеширования, который, по задумке, должен одинаково хорошо работать для вообще любых типов данных. Вы это сравниваете в мапой, в которой могут храниться произвольные типы данных с произвольной функцией хеширования и произвольным алгоритмом рандомизации и hash combine. Ну разумеется это требует большего количества бюрократии. Если хочется, сделайте мапу, которая принимает только строки и ничего из этого вам будет не нужно. Еще классная пометка в документации:
## If you are using simple standard types like ``int`` or ``string`` for the
## keys of the table you won't have any problems, but as soon as you try to use
## a more complex object as a key you will be greeted by a strange compiler
## error:
## Error: type mismatch: got (Person)
## but expected one of:
## hashes.hash(x: openArray[A]): Hash
## hashes.hash(x: int): Hash
## hashes.hash(x: float): Hash
## …
Охрененно, утиная типизация в 2020, в лучших традициях плюсовых шаблонов.
То есть я правильно понимаю, что filter можно вызвать только на openArray, который обеспечивает произвольный доступ по индексу?
В идеальном ЯП не надо настолько подробно описывать абстракцию.
То есть идеальный ЯП настолько слаб, что в нём не выразить концепцию генериков или хэшируемости?
Все остальные можно вывести из этого объекта.
А не ДЕВЯТЬ, как в примере на Расте.
А не ДЕВЯТЬ, как в примере на Расте.
Давайте вместе посчитаем, сколько их:
- 'a время жизни итератора
- тип ключа K
- тип значения V
- тип хэшера (мы можем хэшировать разными алгоритмами) S
- результирующий тип на который маппим M — единственный, от которого можно было бы отказаться.
Так сколько их? И что тут лишнее?
результирующий тип на который маппим M — единственный, от которого можно было бы отказаться.Ну так Siemargl и пишет что K, V и S можно вывести из M. Ну либо отказываться от M
Так сколько их? И что тут лишнее?
Ну так неельзя, потому что смотрим на сигнатуру:
pub struct IterMut<'a, K, V, S, M>
M никак не связан с остальными переменными, и чтобы показать что нас интересует сценарий когда он на самом деле связан это нужно явно писать.
Ну да, с фундепами было бы короче, этот момент можно было бы опустить. Но, мне кажется один-единственный лишний генерик (который так и так нужен, просто он мог бы выводиться автоматически) не такая уж страшная вещь, чтобы кричать "ужас ужас". И никаких 9 генериков тутнет.
Лайфтайм выводится кога может. Там есть пяток правил, если код под них попадает то он выводит. Если не выводит то иногда спасает анонимный лайфтайм '_. Ну и если и он не помогает, то тогда уже приходится писать явные именованные самому. Технология несовершенна :dunno:
Но даже если бы он умел выводить, от 5 параметров не избавиться, если вы хотите эти 5 параметров контролировать (а в системном языке мы этого хотим). Если у вас есть гц — то не нужны лайфтаймы, если нам плевать на динамический диспатч то не нужен М, и так далее. Но это не про раст, не про системный язык.
Но даже если бы он умел выводить, от 5 параметров не избавиться, если вы хотите эти 5 параметров контролировать (а в системном языке мы этого хотим)c++ вполне себе системный язык, где итератор выводится из мапы… А еще в нём мапы в аллокаторы умеют
Так в С++ у вас если что шаблон не сойдется, а генерики проектируются чтобы такого не было. Поэтому им надо явно описывать требования, в отличие от шаблонов. Если вам нравятся "подразумеваемые" требования которых никак не видно в типах, то возможно языки вроде питона или JS будут вам привлекательнее.
Так в С++ у вас если что шаблон не сойдется, а генерики проектируются чтобы такого не былов с++ уже стоит говорить в категориях концептов. Они конечно предоставляют меньше гарантий чем раст дженерики*, но являются более гибким механизмом*.
*Т.к. чтобы удовлетворять дженерику пользовательский тип должен указать это явно
в с++ уже стоит говорить в категориях концептов.Те концепты, которые что-то меняли и которые выпилили из C++11 — да, было бы разумно. Сегодняшние? Нет, они только для выбора нужной реализации используются. Проверок того, что концепта достаточно, не производится.
Проверок того, что концепта достаточно, не производится.с другой стороны, дженерики раста не умеют ни требовать, ни проверять, ни обращаться к полям, только к методам объекта. Разумеется, для обхода такого ограничения можно написать геттеры/сеттеры для каждого поля/структуры (а точнее, объявления геттеров/сеттеров в трейте и реализация их для структуры), но это бойлерплейт.
Скорее всего, просто сделали по аналогии C#.
Любой бойлерплейт обходится #[derive_property(foo, HasFoo)], и никаких проблем.
А в чем будет разная реализация? В сишарпе int Foo {get;set;} тоже предполагает определенную реализацию. Проперти со всякой валидацией — во-первых можно сгенерировать тоже (написать еще один макрос), во-вторых для меня это всегда запашок не очень чистого кода.
А в чем будет разная реализация?ну вот рассмотрим такую композицию: есть структура Foo с полем bar типа Bar, внутри которого baz типа Baz. Тогда метод GetBaz() для Bar будет реализован тривиально, а для Foo это будет bar.GetBaz().
Хтя и не уважаю особо закон деметры, но лезь в чужие проперти не очень хорошо. Куда лучше вернуть bar, и дальше пусть кто хочешь вызывает там что угодно. Тогда будет foo.bar().baz().
Если же вы хотите лезть прямо в чужой объект, то да, придется писать этот бойлерплейт, только я не вижу как его получится избежать в других языках.
только я не вижу как его получится избежать в других языках.наследование
То есть у вас наследуются классы, в которой есть пропертя, которая причем не в свои поля лезет, а в поля своих полей? И всё это образует какую-то иерархию?
Мне страшно представить, как такое вообще может понадобиться.
Нет, "такая пропертя" появляется после замены наследования на агрегирование "в лоб". Очевидно же!
Мне страшно представить, как такое вообще может понадобиться.ну например я хочу чтобы для доступа к Window::width() не надо было писать window->...->widget->...->rect.width()
Ну лично я не вижу тут ничего плохого, если дублировать в вышестоящем классе все апи которые предоставляют дети то никаких сил не хватит и это описывать, и потом этим пользоваться. Ещё хуже, когда разработчики выделяют некоторое "поппулярное" апи, типа width пусть будет на верхнем уровне, а без Rectangle обойдутся. Уходит прилично времени, чтобы понять, что к чему относится, и что — самостоятельное свойство, а что алиас для чего-нибудь другого. Особенно если язык нае контролирует мутабельность, и можно случайно по ссылке поменять одно, а заодно случайно и кучу другого.
К сожалению, у меня хром на 16-ядерной машинке уже не выдерживает этой страницы, я ждал минуту пока текст отрендерится в окне ответа, поэтому просто предложу написать очередной макрос:
#[derive_property_path("width", "self.widget.rect", type = "getset")]
struct Window {}или более банально, для одноразового применения
macro_rules! implement_widget_rect {
($name:ty) => {
impl $name {
fn width(&self) -> usize {
self.widget.width()
}
}
}
}
struct Window { ... }
implement_widget_rect!(Window);у меня хром на 16-ядерной машинке уже не выдерживает этой страницы
Переходи на лису)
Не, не помогает.
Хром ещё умудряется ронять вкладку с SIGILL. И имеет дикий лаг как при загрузке/рендере страницы (больше минуты на i7-7700HQ с 32G RAM и NVMe), так и при попытке ввода комментария с задержками от 2-5 секунд до 30-40 в зависимости от того сколько текста успеешь набрать… Собственно, если набрать больше пары-тройки десятков символов он и падает)
Впрочем и сказать, что редактировать текст очень приятно и удобно — я тоже немогу. Тормозит-с.
Наверное так и сделаю — в ней проблем никаких не наблюдается.
Эх, в очередной раз терять всю историю, интеграции, плагины… Впрочем, растоманить, так по полной (хотя я скорее идрисман на текущем этапе развития).
Если бы еще в мобильной вресии это работало так же хорошо.
или более банально, для одноразового примененияа если там не widget а тот же rect?
self.widget.width()
К сожалению, у меня хром на 16-ядерной машинке уже не выдерживает этой страницыа что не на лисе с движком на излюбленном расте?
а если там не widget а тот же rect?
Тогда пишите менее примитивный вариант. Впрочем, как я уже говорил, за много тысяч KLOC что я и мои коллеги на расте написали ни разу ничего подобного не пригодилось. Но если вдруг так хочется — вот, никто не запрещает
а что не на лисе с движком на излюбленном расте?
- во-первых потому что я не воинствующий фанатик, и пользуюсь инструментами на основании их объективных качеств, а не том, на какой технологии и кем они написаны
- во-вторых по причинам выше я обычно раз в несколько лет перехожу с FF на хром или обратно. Сейчас пятая итерация, и я на хроме сижу. Видимо, придется все же на FF переходить. Почему раньше этого не сделал? Ну, потому что
тот же гугл-календарь в FF почему-то не может отрендерить попап-окошки. Полагаю, это не случайно, но производительность браузера в общем мне куда важнее, чем работоспособность отдельных страниц гуглового авторства, так что видимо
пришла пора собирать ~чемоданы~ плагины и закладки.
Впрочем, как я уже говорил, за много тысяч KLOC...KLOC это уже «тысяча строк кода»
… что я и мои коллеги на расте написали ни разу ничего подобного не пригодилосьочевидно вам не может пригодиться инструмент, которого у вас нет. Ну или который настолько неудобен, что вы всё равно не будете его использовать.
KLOC это уже «тысяча строк кода»
Ок, за много десятков (сотен?)
очевидно вам не может пригодиться инструмент, которого у вас нет. Ну или который настолько неудобен, что вы всё равно не будете его использовать.
В сишарпе он есть, но почему-то тоже не пользуемся такими вещами в нем :dunno:
И как я уже сказал, код с таким подходом у нас стал только чище. Вообще, раз за разом получаю подтверждение, что чем больше языков и подходов знаешь, тем лучше получается код.
А вот если человек выучил первым языком ООП джаву и везде ему теперь видятся гвозди, то это как раз-таки грустно.
И да, в расте такого инструмента нет, но я же в курсе про его существование. И вот хоть бы раз я страдал "Блиин, вот как я бы хотел щас тут вот это отнаследовать". Нет, хотя в сишарпе
из-за отстуствия всяких опшнов и кривых not-null я так делаю регулярно.
traits. Ну было бы лишних 100 строк кода. В проекте на 300 KLOC — это не слишком страшно.А вот если человек выучил первым языком ООП джаву и везде ему теперь видятся гвозди, то это как раз-таки грустно.Такого человека ещё можно чему-то научить, благо в Java сейчас появляются заимствования их функциональных языков.
А вот если человек «запал» на динамический язык — то это, часто, уже клиника: не то, что нормального, вменяемого кода, но даже нормального описания задачи, которую он пытается решить, зачастую от него получить невозможно…
Проблема будет решена, когда реализуют делегаты хоть в каком-нибудь виде. Например, в таком:
https://github.com/elahn/rfcs/blob/delegation2018/text/0000-delegation.md
наследованиеВот здесь хочется вспомнить о сообщениях в Smalltalk.
О да, то-то __cтандартная_библиотека так читемо __выглядит.
А вывести из ссылочного параметра, что лайфтайм итератора не может превышать лайфтайм мапы это вообще рокет сайнс, надо указать отдельно…
И какаое решение предлагают новые "прогрессивные" языки?
И как он будет работать для trait bounds?
И почему вы привели openarray[t] который аналогичен Vec<T> вместо многопоточной HashMap?
… при дизайне языка было принято решение, что автоматический вывод типов будет останавливаться на границах функций. В дальнейшем это ограничение было ослаблено введением функций, возвращающих impl Trait.
Иногда вывод типов не работает из-за неоднозначности типов промежуточных значений. Например: let a = 1u8; let b: u32 = a.into().into(); не компилируется, так как конверсия из u8 в нечто в u32 может осуществляться несколькими способами.
Есть ещё неприятный момент с конверсией из &T в &dyn Trait, которую можно было бы выводить, но приходится писать вручную.
Не знаю уж, что тут такого, стоящего многозначительного многоточия.
Если итератор ссылается на "внешние" данные то он легко может жить меньше, чем данные на которые он ссылается. А может и нет.
Как это долнжо выводиться?
лайфтайм итератора не может превышать лайфтайм мапы
Давайте пример, как локальный итератор переживет глобальные данные.
Да легко и просто.
Допустим, у нас есть MyStruct<'a> { arr: &'a [u8] }. Тогда MyStruct.iter() может пережить MyStruct, т.к. он будет итерироваться по arr — по внешним данным.
void ProcessRPCForFunc(RPCData& data) {
auto [x, y, z] = RPCDataParser<Func>(data);
...
Func(x, y, z);
...
}
RPCDataParser<Func>::get()), но идея та же: временный объект исчезает, ссылки остаются. Причём исчезает он «с концами», на самом деле — в сгеренированном коде он даже не создаётся…Да ладно? В C# так весь LINQ работает (с поправкой на наличие сборщика мусора).
Это не совсем то, но вот моя экспериментальная либа. Есть итератор. Он не должен пережить объект под названием «Курсор». Но этот итератор возвращает указатели на узлы графа. Эти указатели, очевидно, валидны дольше, чем валиден сам итератор и валиден курсор. Как вы предлагаете это вывести компилятору, я вообще не представляю. Особенно учитывая, что дополнительно компилятор проверяет, что указатели, которые пытаемся скормить графу, действительно принадлежат этому графу.
А можно пример, максимально простой, на лайфтаймы, 2 варианта объявления, когда они расставлены по разному, оба случая устраивают компилятор, но программа ведет себя по разному?
Такой пример, насколько я знаю, невозможен в принципы. Лайфтаймы не задают поведение программы, они только описывают его. И вывести их в общем случае нельзя по указанной выше причине — вывод типов строго локальный, а указание лайфтаймов требует, в общем случае, анализа всей программы.
Заметьте: вопрос был не про функцию, которую можно использовать в той же самой программе, чтобы изменить её поведение, вопрос про функции, которые можно было бы применять в разных программах, но которые бы, в точке объявления функции, отличались только лайфтаймами.
Чтобы показать что их указание вообще имеет ну хоть какой-то смысл.
А ваше рассуждение показывает почему эти две функции будут требовать и разных программ тоже, только и всего.
Ответ Cerberuser верный, но я распишу немного подробнее.
Самое главное: время жизни переменных определяется только структурой программы, а не объявленными лайфтаймами.
Лайфтаймы в объявлениях функций говорят компилятору какие отношения между временами жизни переменных нам нужны, и ссылки на какие переменные мы вернём.
Например: fn assign<'a>(to: &mut &'a u32, what: &'a u32)
Это объявление говорит, что мы хотим получить эксклюзивную ссылку на переменную, содержащую ссылку на переменную, доступную в блоке кода 'a (to), и ссылку на переменную, доступную в том же блоке кода 'a (what).
То есть такой код скомпилируется, поскольку a и b доступны в одном блоке кода.
let a = 1;
let mut a_ref = &a;
let b = 2;
assign(&mut a_ref, &b);
println!("{}", a_ref);А такой код не скомпилируется, так как b доступна не во всём блоке кода в котором доступна a.
let a = 1;
let mut a_ref = &a;
{
let b = 2;
assign(&mut a_ref, &b);
// ^^ borrowed value does not live long enough
}
println!("{}", a_ref);Если мы объявим assign как
fn assign(to: &mut &u32, what: &u32)
, то есть не требуя связи между временами жизни переменных, на которые указывают ссылки, то второй пример скомпилируется, но мы не сможем сделать *to = what; внутри assign().
но вот почему их нельзя вывести автоматически не понимаю
Наверно можно. По крайней мере не придумывается сходу пример, где с помощью анализа тел функций нельзя было бы вывести лайфтаймы.
Но сообщения об ошибках будут ещё непонятнее: "Проанализировав эту цепочку вызовов, мы вывели, что foo<'a, 'b: 'a>, а проанализировав вот эту цепочку, мы вывели, что foo<'a: 'b, 'b>. Пожалуйста поправьте что-нибудь где-нибудь."
Собствено необходимый и достаточный ответ у вас в последней строке: ссылка на пример с двумя разными (но валидными!) функциями, отличающимися только лайфтаймами.
Ваша же функция
fake_assign что-то делает? Программа валидна? Не падает. Всё: у вас есть требуемый пример программы, где есть две разные функции, агрументы которых отличаются только лайфтаймами. А значит существование сущности «лайфтайм» в языке — не лишнее.Дальше можно уже рассуждать, что можно поступить как в
C++ последних версий, где при указании auto типы выводятся автоматически… но это уже следующий этап и другая история: ситуация, когда, внезапно, прототип функции меняется в зависимости от того, что там у функции внутри — имеет свои проблемы и потому все распространённые Style Guide использование auto ограничивают.P.S. И вы и Cerberuser потеряли за деревьями лес. Начали обсуждать зачем нужны указания лайфтаймов в данном конкретном случае — вместо того, чтобы объяснить зачем они нужны в принципе. А они нужны не компилятору. Они нужны программисту. Потому что если предположить, что вы пишите на «идеальном языке» и забыли вписать вот это вот присваивание в
fake_assign… то может оказаться так, что вам, для исправления этой ошибки, нужно будет исправить миллион строк кода. Которые оказались возможными только из-за того, что в каком-то участке коды вы забыли вписать вот это вот одно присваивание. Это, извините, не «идеальный язык», а «идеальное наказание». Пользоваться таким языком невозможно. Указания лайфтаймов, как и указания типов в каком-нибудь Pascal позволяют локализовать ограничения и сообщать о проблемах до того, как вы напишите миллион строк, которые, потом, придётся выкинуть. И да — так же как и с типизацией: вам будет хотеться, чтобы в простых случаях компилятор вычислял лайфтаймы сам. И он это делает. В простых случаях.Если я правильно понимаю, суть P.S. сводится к тому, что при нелокальном выводе типов (а лайфтаймы — часть типов) ошибка в коде в одном месте может привести к ошибке типов в совсем другом, тогда как при локальном (который и выбран в Rust) все ошибки будут на границе функции. Я, честно говоря, исходил из того, что это в нынешнем контексте и так понятно.
Я, честно говоря, исходил из того, что это в нынешнем контексте и так понятно.Кому-то, возможно, и понятно, но вашему оппоненту, любителю мифического «идеального языка» — явно нет.
Чем это всё кончается — наглядно иллюстрирует C++98, где в шаблонах, никаких типов, описывающих типы, нету, но, тем не менее корректность кода проверяется статически.
Нечитабельные сообшения об ошибках в этом языке превратились, по-моему, в легенду — и начиная с C++11 эту проблему начали решать. В частности есть в C++11 такой вот инструмент, который, как всем известно ничего, вот совсем ничего, АБСОЛЮТНО НИЧЕГО не добавляет в корректную программу — но, тем не менее, существует.
И, заметьте, его в C++ изначально не было, его туда добавили. Удалив, теоретически, от «идеала», про который тут говорится — но сделав его гораздо более удобным…
Вообще, я бы сказал на первый взгляд, что лишнее здесь всё, кроме 'a и M — просто потому, что трейт Map определён неправильно. K, V, S должны бы быть ассоциированными типами, а не параметрами.
Параметры имеют смысл в основном тогда, когда реализаций с несколькими параметрами может быть несколько… но я очень сильно сомневаюсь в структуре, для которой имели бы смысл реализации Map с разными K, V, S.
Смысл не в реализации с разными K/V/S, а чтобы в реализации мы имели возможноть на них ссылаться. В частности вот эта строка в реализации IterMut:
type Item = RefMutMulti<'a, K, V, S>;Если мы ничего не знаем про K/V/S (они как-то магически вывелись), как мы запишем тип Item?
Не "магически вывелись", а прописаны как ассоциированные типы в трейте Map и его реализации. Примерно вот так:
type Item = RefMutMulti<'a, M::Key, M::Value, M::S>;если вообще не сделать параметром тип M, а не эти три по отдельности.
Еще раз, как оно должно выглядеть? impl<'a, M: Map<'a, K,V,S>>? Ну так тут же получается "использование необъявленной переменной". Если такое разрешить, то наличие или отсутствие struct S {} строкой выше будет полностью менять смысл написанного.
...exists K, V, S?
Примерно вот так
impl<'a, 'i, M: Map<'a>> Iterator for Iter<'a, 'i, M>
{
type Item = RefMulti<'a, M::Key, M::Value, M::State>;если там дальше пробем не возникнет.
Map<'a>
Но это невалидная запись, Map принимает 4 параметра, а вы передали только один.
Вот потому я и говорю, что у трейта изначально неоптимальное определение, на мой взгляд.
А какое оптимальное? Насколько я могу судить без остальных параметров Map не реализовать никак.
pub trait Map<'a, K: 'a + Eq + Hash, V: 'a, S: 'a + Clone + BuildHasher> {
fn _shard_count(&self) -> usize;
...
}
impl<'a, K: 'a + Eq + Hash, V: 'a, S: 'a + BuildHasher + Clone> Map<'a, K, V, S>
for DashMap<K, V, S>
{
#[inline]
fn _shard_count(&self) -> usize {
self.shards.len()
}
...
}pub trait Map<'a> {
type Key: 'a + Eq + Hash;
type Value: 'a;
type RandomState: 'a + Clone + BuildHasher;
fn _shard_count(&self) -> usize;
[...]
}
impl<'a, K: 'a + Eq + Hash, V: 'a, S: 'a + BuildHasher + Clone> Map<'a>
for DashMap<K, V, S>
{
type Key = K;
type Value = V;
type RandomState = S;
#[inline]
fn _shard_count(&self) -> usize {
self.shards.len()
}
[...]
}Ок, а если делаем так:
pub trait Map<'a, K: 'a + Eq + Hash, V: 'a> {
fn _shard_count(&self) -> usize;
...
}
pub trait Map<'a, K: 'a + Eq + Hash> {
fn _shard_count(&self) -> usize;
...
}
pub trait Map<'a> {
fn _shard_count(&self) -> usize;
...
}то какой тип должен резолвиться в
impl<'a, K: 'a + Eq + Hash, V: 'a, S: 'a + BuildHasher + Clone> Map<'a>?
Я не вполне понял постановку вопроса. Это три разных варианта того, как можно было бы сделать один и тот же трейт?
Просто раст не запрещает объявление типов с одинаковым именем. В итоге можно подключить совершенно случайно совсем не тот, что имелся в виду.
В общем, если отвечать на вопросс, лучше стало или хуже, то на мой взгляд — хуже. Сэкономили три запятых, зато теперь нельзя сразу понять, сколько параметров. Кроме того, теперь запись
impl<'a, K: 'a + Eq + Hash, V: 'a, S: 'a + BuildHasher + Clone> Map<'a>
for DashMap<K, V, S>и
impl<'a, Key: 'a + Eq + Hash, V: 'a, S: 'a + BuildHasher + Clone> Map<'a>
for DashMap<Key, V, S>Это совершенно разные вещи, и переименование генериков в библиотеке становится ломающим изменением (по этим же причинам).
Просто раст не запрещает объявление типов с одинаковым именем.
Вообще-то запрещает, можете проверить сами :-)
Кроме того, теперь запись (...) и (...) это совершенно разные вещи...
Нет, не разные, по-прежнему Key (K) в скоупе и Self::Key — это независимые типы (хотя да, строчка type Key = Key; будет выглядеть забавно).
… и переименование генериков в библиотеке становится ломающим изменением (по этим же причинам).
Во-первых, это не генерики, а ассоциированные типы. Во-вторых, да, в отличие от генериков они именованные и это не бага, это фича. Использование вместо них генериков — это как out-параметры: порой так делают, но обычно это считается не особо идеоматичным.
И разница как раз в том, что
… зато теперь нельзя сразу понять, сколько параметров.
Понять можно и параметров здесь — кроме типа, для которого он реализован — нет. И на мой взгляд так правильнее, чем вводить искусственные параметры, которые для заданного целевого типа всё равно обязаны иметь одно-единственное значение.
Для сравнения давайте посмотрим в стандартную библиотеку на пару похожих трейтов: AsRef и Deref. У обоих есть единственный метод с одинаковой сигнатурой fn(&Self) -> &Something. Тем не менее, они принципиально отличаются.
AsRef имеет параметр типа, что позволяет ему иметь много реализаций. Один и тот же строковый тип String удовлетворяет сразу многим конкретным реализациям: AsRef<[u8]>, AsRef<str>, AsRef<OsStr>, AsRef<Path> — и это только в стандартной библиотеке.
Deref же параметров не имеет, а имеет взамен ассоциированный тип. Для каждого типа, реализующего Deref, жёстко задано, в какой именно тип он переводит (и в случае String это именно str). У пользователя нету выбора, какую именно реализацию использовать.
Вот этот служебный трейт Map, на мой взгляд, ближе ко второму варианту. Логика его использования не предусматривает вариант, в котором один и тот же тип имеет несколько реализаций, различающихся параметрами, из которых пользователь выбирает нужную — а именно в этом и есть разница.
Вообще-то запрещает, можете проверить сами :-)
А по-моему разрешает.
https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=dc09476ecce1ae6ce4e6a68926b95e67 Да, вывод типов обламывается, но ничто не мешает их допилить, фундаментальных ограничений на это нет, итот же хаскель например с этим справляется… Да даже сишарп.
Понять можно и параметров здесь — кроме типа, для которого он реализован — нет. И на мой взгляд так правильнее, чем вводить искусственные параметры, которые для заданного целевого типа всё равно обязаны иметь одно-единственное значение.
Если вы и правда считаете что это лишняя ифнормация и можно сделать лучше, откройте pre-RFC обсуждение на IRLO, я думаю там вам смогут привести куда более веские аргументы.
А по-моему разрешает.
Все же нет: https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=e6690ffdf48151444096187c2efbfde0
Только вот использовать их в такой комбинации невозможно в принципе. Если точнее:
- два явных импорта с одним именем конфликтуют;
- если конфликтует явный импорт и
use module::*;, всегда используется явный; - если явного нет, а глоб-импортов, содержащих это имя, больше одного, всегда выдаётся ошибка.
Что в совокупности значит, что в любой точке программы имя типа/трейта всегда однозначно сопоставляется конкретному трейту, и сигнатура для этого сопоставления значения не имеет.
Если вы и правда считаете что это лишняя ифнормация и можно сделать лучше, откройте pre-RFC обсуждение на IRLO, я думаю там вам смогут привести куда более веские аргументы.
А при чём здесь, собственно, internals и pre-RFC? Мы же обсуждаем не изменение языка, а то, как имеющимися фичами языка наиболее точно выразить трейт Map крейта dashmap, нет? Если уж здесь что-нибудь и имело бы смысл открывать, так это PR в dashmap, рефакторящий его на другой вариант… но я не уверен, стоит ли лезть со внутренним рефакторингом без намерения становиться долгосрочным контрибьютором.
Только вот использовать их в такой комбинации невозможно в принципе.
Если хаскель с этим справляется, значит, в принципее возможно. что я и сказал сразу — нужно только подпилить вывод типов.
А при чём здесь, собственно, internals и pre-RFC?
Изначально обсуждался "идеальный" язык и "лишние генерики". В данном конкретном случае, возможно, можно было бы задизайнить немного по-другому Map чтобы ему не надо было эти паарметры передавать, но в общем случае это ведь не работает.
iterator foo(std::instance_of<std::map> auto&& map);
Не идеальный С++20
И где тут информация что типы должны быть хэшируемыми/клонируемыми/… ?
А зачем лишний раз повторять эту информацию, если она проверена самой мапой???
А в самой хэшмапе таких требований и нет:
https://doc.rust-lang.org/stable/src/std/collections/hash/map.rs.html#209-211
Ну и даже если бы они там были, делать неявные типопеременные зависящии от аргумента плохая идея. Даже не знаю языка, где оно бы так работало.
Кто-то не любит where-блоки, хорошим стилем это трудно назвать. Лучше так:
impl<'a, K, V, S, M> Iterator for IterMut<'a, K, V, S, M>
where
K: Eq + Hash,
S: 'a + BuildHasher + Clone,
M: Map<'a, K, V, S>,
{
...
}Спасибо. Крутая статья. Небольшой вопрос по одному моменту:
Давайте сравним два кода и ассемблер. В примере на Rust мне пришлось дополнительно извратиться с extern "Rust" и unsafe, чтобы компилятор не заинлайнил вызовы
Разве нельзя было просто #[inline(never)] воспользоваться?
Можно было(link:godbolt), но тогда бы оно еще сильнее оптимизировало. Моей целью было показать сравнение Box vs std::unique_ptr.
TL;DR — очень провокационный заголовок, можно было саму суть вынести в preface статьи?
Ну, и название — "C++ быстрее и безопаснее Rust, Yandex сделала замеры" — если статья про обратное (развенчание отзыва Яндекса) — ну, так и напишите (фейспальм десять раз)
Считайте это сиквелом моей же статьи Go быстрее Rust, Mail.Ru Group сделала замеры.
В Раст встроили)
ожидание работы на архитектуре с two's complement как единственной поддерживаемойВ C++20 вроде уже тоже: «The range of representable values for a signed integer type is −2^(N−1) to 2^(N−1)−1 (inclusive), where N is called the width of the type»
Оффтоп, не про раст: зачем константы и деления, когда в GCC есть built in функции. Думаю, у других компиляторов тоже есть что-то аналогичное.
Затем, что вся это фигня платформо- и компиляторозависима. На худой конец есть boost.
В GCC появилось только в 5.0. До сих пор много где основные компиляторы — старше.
В GCC появилось только в 5.0. До сих пор много где основные компиляторы — старше.Вы уж определитесь — для вас важна поддержка чего-то в C++ в принципе или вы только фичи, которые были в него в прошлом веке привнесены, готовы использовать.
Если последнее — то какая для вас будет разница что, кто и куда встроит?
_Мне_ проблемы уже нет: у меня код только под Unix, и пока под ним речь идёт о двух конкретных компиляторах — это устраивает. Но вот прыжок 4.8 -> 8.0 по отношению к одному из ключевых компонентов мы смогли продавить только две недели назад, и то только потому, что 8.0 потребовался другим компонентам из соседнего отдела :)
А вот тем, кому нужна реальная кроссплатформенность, включая, прости господи, Windows, могу только соболезновать (хотя это далеко не главная грабля из тех, с чем они сталкиваются).
> Вы уж определитесь — для вас важна поддержка чего-то в C++ в принципе или вы только фичи, которые были в него в прошлом веке привнесены,
В кого встроены? В C++ или в GCC C++? Разница принципиальная, и вы зря её тут игнорируете.
В кого встроены? В C++ или в GCC C++? Разница принципиальная, и вы зря её тут игнорируете.В C++. Дело в том, что поддержку C++ в GCC «пилили» долго и полноценная поддржка C++11 появилась только в GCC 5+.
Соотвественно если вы используете более старые версии, то у вас есть только C++98 (в C++03 новых фич нету, только исправление ошибок). Соотвественно никаких фич, повившихся в C++ в этом веке… это грустно. Вот реально грустно.
Поддержка C++11 в 4.8 нас устраивала, несмотря на лейбу «мы ещё не всё сделали». Я не знаю ваши критерии полноценности — вероятно, они жёстче наших — но это нам не влияет.
С другой стороны, в книге написано
C++11 contains several changes to the C++ language, most of which have been implemented in an experimental C++11 mode in GCC.
а формально они это про experimental сняли только в 6.0.
Вы не боитесь за свой продукт на 5ке?
Просто хочу спросить. 99.9% кода сейчас исполняется на архитектурах, имеющих аппаратные флаги арифметического переноса (integer overflow).
Такова философия C/C++: язык позиционируется как мультиплатформенный, поэтому никаких платформенно-специфичных вещей в нём нет и не будет. Стандарт C++ разрешает любое представление знаковых целых чисел.
https://en.m.wikipedia.org/wiki/C%2B%2B20
signed integers are now defined to be represented using two's complement (signed integer overflow remains undefined behavior)[28]
Таки нет, сдались)
Стандарт C++ разрешает любое представление знаковых целых чисел.Таки они позволял только ones-complement and twos-complement.
При этом я даже не знаю когда последняя ones-complement архитекртура сошла со сцены.
Сильно подозреваю, что в прошлом веке.
Types bool, char, char16_t, char32_t, wchar_t, and the signed and unsigned integer types are collectively called integral types. A synonym for integral type is integer type. The representations of integral types shall define values by use of a pure binary numeration system. [ Example: This International Standard permits two’s complement, ones’ complement and signed magnitude representations for integral types. — end example ](из N4659)
1. Уже нет, если мы говорим про C++20.
2. Даже если не ограничиваться этим нововведением — в C и C++ нет никакого запрета на возможность ввести функцию типа «умножить два числа и выдать, не было ли переполнение, и младшие биты независимо от факта переполнения». C, C++ уже определены с данными в терминах битов, значит, такое определение возможно. Средства проверки есть на любой платформе, где-то дороже, где-то дешевле, где-то через флаги процессора, где-то через иные средства, но есть (иначе бы на такой платформе не работал бы C). Значит, такую функцию ввести возможно. Платформенно-специфичной по сути она не будет, а то, что эти самые урезанные младшие биты платформенно-специфичны, возможности не испортит.
То, что это было введено только в GCC5 и только 5 (а не 30) лет назад, показывает уровень наплевательства индустрии на проблемы.
> язык позиционируется как мультиплатформенный, поэтому никаких платформенно-специфичных вещей в нём нет и не будет.
То есть и на системе без поддержки многонитевости его не сделать, вы считаете?
То есть и на системе без поддержки многонитевости его не сделать, вы считаете?Ещё раз: язык позиционируется для написания переносимых программ и только переносимых программ.
Многонитевость (не путать с защитой памяти), можно реализовать на любой платформе. Вопрос в нужности этого мероприятия — это уже второй вопрос.
Если вы из
embedded, то долгое время была странная ситуация: C/C++ активно использовался в embedded мире… но при этом ни в комитете по стандартизации, ни где-либо ещё представители этого сообщества не появлялись.Не слишком удивительно, что их мнение игнорировалось…
99.9% кода сейчас исполняется на архитектурах, имеющих аппаратные флаги арифметического переноса (integer overflow). Почему в язык не встроили механизм их проверки?
А в чем проблема? Напишите, а скорее всего уже есть такие ф-ции, которые проверяют эти флаги и обрабатывайте их результат.
C, C++ — есть функции в GCC и Clang. В стандартах, увы, нет — не продавили ещё. C++20 с его обязательным «дополнительным кодом» (twoʼs complement) позволяет легко решить эту проблему для сложения и вычитания, но не для умножения.
C# — есть checked режим (генерирует исключение, это дороговато, но лучше, чем ничего). Java — аналогично (через модуль Math).
Swift — исключение по умолчанию.
Go — вся арифметика только по модулю, для эффективной проверки надо извращаться (сложение, вычитание — проще, умножение — сложно).
Миф №5. C → С++ — noop, C → Rust — PAIN!!!!!!!
Всё становится ещё веселее, когда захочется подключить динамическую библиотеку.
В Rust ничего не меняется — просто берётся заголовочник с extern-ами. В C#, кстати, внешние нативные библиотеки подключаются так же просто и ненавязчиво.
А вот в C++ уже начинаются танцы с бубнами. Язык в принципе не предоставляет никаких средств по подключению dll/so-шек, поэтому механизм получается крайне костыльный и неудобный.
Распространённые в плюсах системы сборки, конечно, далеки от идеала, но с задачей подключения библиотек справляются хорошо. Не хватает качественного и общепринятого пакетного менеджера, но это уже другой вопрос.
А причём тут системы сборки, когда речь идёт о подключении внешних dll/so, которые не привязаны к проекту?
В C++, чтобы подключить внешнюю dll/so, вам, помимо хедера, нужен ещё клей в виде lib/a файла. А теперь, внимание, вопрос: что вы будете лежать, если этого файла не будет? Или он будет сгенерирован несовместимым компилятором? Писать руками LoadLibrary, GetProcAddress?
Ну и даже если dll генерится внутри проекта, все равно будет просто куча костылей в виде атрибутов и условной компиляции:
https://gcc.gnu.org/wiki/Visibility
А, понял, речь о загрузке во время работы. Да, для этого стандартного решения нет и надо либо писать свою реализацию для каждой платформы, либо пользоваться библиотеками, в которых это уже сделано (Boost, Qt etc.).
В C++, чтобы подключить внешнюю dll/so, вам, помимо хедера, нужен ещё клей в виде lib/a файла.Всё смешалось в доме Облонских.
Во-первых причём тут
.so и .a, если вы описываете Windows-специфичную проблему?Во-вторых — в каком-нибудь Microsoft C/C++ 7.0 прошлого века этой проблемы нет тоже, она появилась при переходе на Win32.
Так что причём тут вообще язык, если речь идёт о проблеме созданной (причём специально созданной!) одним вендором на одной платформе?
Так что причём тут вообще язык, если речь идёт о проблеме созданной (причём специально созданной!) одним вендором на одной платформе?
Потому что, блин, в языке нет средств для подключения библиотек.
Во-первых причём тут .so и .a, если вы описываете Windows-специфичную проблему?
Да, немного ошибся. Ну мало у меня опыта в программировании под Linux.
Но в Linux эта проблема тоже есть. Да, там вместо .lib/.dll будет один .so и не такой геморрой с dllimport/dllexport, но подать на вход линкеру .so все равно придётся.
Да, там вместо .lib/.dll будет один .so и не такой геморрой с dllimport/dllexport, но подать на вход линкеру .so все равно придётся.Ну если он у вас есть, то вы его можете без проблем использовать, а если нету — то как вы собрались потом этот бинарник использовать?
Потому что, блин, в языке нет средств для подключения библиотек.В языке и понятия «библиотека» нету, не то, что «средств подключения».
Ну, например, когда его нужно скомпилировать на одной машине, а запускать на другой.
> В языке и понятия «библиотека» нету, не то, что «средств подключения».
Это и есть проблема. Вот я указал в заголовочном файле, что функция будет extern. Где именно её будет искать линкер? А где найдёт. Собственно, из-за того, что нет возможности указывать явно, откуда функцию брать, линкеру и приходится подсовывать все библиотеки, что имеются в наличии.
Во-первых причём тут .so и .a, если вы описываете Windows-специфичную проблему?
Уточнение: это не Windows-специфичная проблема, а VC-специфичная проблема. Тот же GCC в MINGW-версии этой проблемы не имеет. Да и в VC тоже альтернативные пути существуют...
Это немного не то — фактически, кроссплатформенный вариант LoadLibrary, GetProcAddress. То есть подключение руками в рантайме.
Я же хотел бы, чтобы описание это было декларативным, а связи с DLL формировались на этапе линковки, а не в рантайме.
Ну вот смотрите: есть DLL. Всё, что про неё известно — это имена экспортируемых символов, соглашение о вызовах и информация о параметрах функций. А теперь предложите способ её удобного использования в C++ проекте.
Boost.DLL — хорошо. Можно создать класс-обёртку, который в рантайме всё подцепит, пусть это не так удобно. А есть ещё варианты? Как именно это делается в билд-системе?
А boost.dll — это чисто виндовс специфичная штука? Сорри, просто не в курсе
Ну вот смотрите: есть DLL. Всё, что про неё известно — это имена экспортируемых символов, соглашение о вызовах и информация о параметрах функций. А теперь предложите способ её удобного использования в C++ проекте.
Ну я не настоящий плюсовик но я просто положил длл в папочку рядом с бинарником (кстати скомпиленым под линуксом)
Язык в принципе не предоставляет никаких средств по подключению dll/so-шек, поэтому механизм получается крайне костыльный и неудобный.Зато в C++ вы таки-можете использовать C++-интерфейс в таком случае, а в Rust — только C.
Хрен редьки не слаще, если честно.
https://crates.io/crates/cxx в процессе.
Зато в C++ вы таки-можете использовать C++-интерфейс
Я бы не рискнул. Начать с того, что манглинг в с++ разный в зависимости от компилятора. Короче, вызов с++ кода из dll — возможно, но выглядит как очередное потенциальное путешествие по обильно расставленным граблям.
Последний раз libstdc++ менялась несовместимым образом в GCC 3.4. Это 2004й год. С тех пор — она только расширялась.
Манглинг и, вообще, С++ ABI — зафиксированы в оффициальном документе (и да, в названии там ест слово Itanium… но это не мешает на него ссылаться ARMовскому, к примеру, документу). Там, правда, несовместимые изменения были, но они настолько экзотичны, что в реальном мире я с ними никогда в жизни не сталкивался (ну вот просто не понимаю я зачем экспортировать функцию, принимающую
std::nullptr_t… теоретически это возможно, а практически… никогда не видел).Потому в GNU/Linux использовать C++-интерфейсы — нормально, а в Windows… чур меня, чур. Ну просто потому что… если я вот просто переменную заведу… простою такую… целую — я уже могу в Windows её экпортировать и использовать или нет? Как это будет работать?
Если там до сих пор нет даже этого, то о каком мало-мальски сложном C++ интерфейсе можно говорить?
Почему казуистика? Первый пример был про переполнение знаковых. В той статье было переполнение знаковых в строчке h += h * 27752 + x[i];.
push rax / pop rcx - избыточны, как ни крутиХотя это не те проблемы, которые действительно есть у Раста. И мало смысла это обсуждать.
Скорость у раста на уровне, а вот юзабилити — на дне.
push rax / pop rcx — избыточны, как ни крути
Которые добавляются и компиляторами C/С++. Их мы же не ругаем за лишние инструкции?
То есть про птиц вы не слышали?
А динозавры — вымерли. Вы хотите с этим поспорить?
В C++ тоже иногда несовместимые изменения делают. А в C++20 даже есть одно предложение специально ломающее совместимость.
Да, процесс происходит небыстро… но на то, чтобы птицы из динозавров «сделать» миллионы лет потребовались.
А вымершие динозавры — это скорее про Objective C++ — и то он может только вместе с Apple вымереть (Apple может сколько угодно рассказывать про красоту Swift, но как-то модули на C++ прикручивать-то нужно).
А если птицы и динозавры совместимые — ну, тогда и все хородовые совместимые, и все клеточные организмы совместимые.
Но смысл моего комментария был не в том, какие тупые динозавры, а в том, что жадные алгоритмы («на каждом шаге всё делаем наилучшим способом») могут заводить в тупик. А вместо этого вы пытаетесь со мной обсуждать эволюция и систематику, уходя из-за пределов применимости аналогии (что не делает аналогию менее применимой, поэтому что любая аналогия ограничена)?
Но смысл моего комментария был не в том, какие тупые динозавры, а в том, что жадные алгоритмы («на каждом шаге всё делаем наилучшим способом») могут заводить в тупик.А смысл моего комментария в том, что никаких других алгоритмов у нас нет. И проблемы «захода в тупик» несколько преувеличены. Да, у жирафов есть многометровый возвратный нерв, который в идеальном-то мире был бы весьма короток… Ну и что?
А вместо этого вы пытаетесь со мной обсуждать эволюция и систематику, уходя из-за пределов применимости аналогии (что не делает аналогию менее применимой, поэтому что любая аналогия ограничена)?Я, вместо этого, хочу сказать, что нельзя заранее узнать — какой язык у нас «динозавр», а какой — «жираф».
Все выжившие языки — это результат эволюции. И те языки, которые отказывают следовать «жадному» алгоритму просто умирают очень быстро — и тот факт, что они могут, вдруг, внезапно, оказаться весьма похожими, по заложенным в них идеях, на то, чем люди будут пользоваться через 50 или 100 лет — их ни разу не спасёт.
И точно также, как, в результате эволюции, динозавр может превратится в птицу нигде по дороге не отказываясь от совместимости — так и в случае с языками програмирования можно постепенно превратить C в C++98, потом в C++20, а потом и вообще в дрйгой язык программирования…
Единственный способ для диплодока полететь — спрыгнуть с обрыва. Для того, чтобы какие крылья могли его поднять, ему нужно стать хотя бы размером с орла или альбатроса (я не знаю, какая самая большая летающая птица, это совершенно не важно), что уже не является обратно совместимым…
Подумайте над тем, что при сохранении обратной совместимости спецификация будет только расти, и язык всё больше и больше будет походить на диплодока, чем на альбатроса…
Алгоритмов, конечно, нет, но в отличии от природы, мы можем позволить себе осмыслить полученый опыт и начать с начала.Нет, не можем. Можем, собственно, только в том случае если наша попытка закончилась полным обломом.
Как только ей начинают пользоваться — тут же врезаемся в Hyrum's Law, происходит оссификация и что-либо изменить становится проблематично.
Подумайте над тем, что при сохранении обратной совместимости спецификация будет только расти, и язык всё больше и больше будет походить на диплодока, чем на альбатроса…Только в том случае, если мы будем поддерживать совместимость на бесконечно длительном промежутке времени.
Как диплодок может полететь — нам показывает, внезапно,
Rust. Который явно и девусмысленно говорит: разные версии языков — носовместимы, но… вы их можете совмещать в своём коде.Сейчас в комитете по стандартизации C++ начинают думать об этом.
Не знаю, почему на осознание этой тривиальной идеи потребовалось столько лет. Людям не нужен язык, который не меняется. Людям нужно, чтобы можно было использовать, без изменений, существующий код! Лет 5-10 обычно, редко дольше — но нужно.
Потому что если вы этот код кому-то отдали (наважно — продали вы его или просто скомпилировали бинарники и отослали в другое подразделение), то дальше вы должны будете, какое-то время его поддерживать. И вот этот вот код, вы уж извините, но меняться не должен. Там могут только ошибки правиться.
А новый код — вы вполне можете и на новой версии языка написать и даже на другом языке… но вот это вот всё должно стыковаться с существующим кодом! Иначе вам придётся иметь дело не только с ограничениями двух версий языка, а и с двумя, совершенно разными исходниками для одного и того же компонента! Ну и кто на это согласится?
Разработчики Rust эту фишку просекли весьма хорошо — и в результате язык с совершенно вырвиглазным синтаксисом и весьма таки тяжёлый для освоения — уже подбирается к 20е обогнав таких известных старичков как Delphi, или Scala (про Haskell я вообще молчу). На GitHub — он ещё выше.
За счёт этого же — поднимается Kotlin достаточно уверенно.
При этом такой язык, как D и близко к 20 не приблизился и не приблизится никогда.
Именно из-за желания стать альбатросом «в ускоренном режиме»…
Именно из-за желания стать альбатросом «в ускоренном режиме»…
правильно. Это именно то самое желание «лучшего», которое убивает «хорошее». В чем проблема не улучшать существующее, а параллельно строить новый храм? В общем, модель раста действительно полезная. Минусом является возможность фрагментации, но кого это волнует — в том же с++ фрагментация просто колоссальная, что между 100500 версий стандарта, что между разными имплементациями.
Пожалуйста, хватит ругать синтаксис, ну очень прошу. Просто надоело каждый раз читать одно и то же. Или разберитесь и предложите альтернативы, или осознайте где вы не правы, если таких альтернатив не найдете.
Пожалуйста, хватит ругать синтаксис, ну очень прошу.А почему, собственно?
Или разберитесь и предложите альтернативы, или осознайте где вы не правы, если таких альтернатив не найдете.Да сколько угодно таких альтернатив. Та же Ada или Oberon.
Они просто менее популярны — но тут, как бы, беда не в плохом синтаксисе.
Или вы про то, что раз
Rust стал популярен, то его синтаксис, внезапно, стал красив?Ну бред же: вы же не называете Джеффа Безоса или Билла Гейтса красавцами потому что у них денег много… почему в языках программирования, внезапно, красота должна хоть как-то кореллировать с популярностью?
В конце концов я на работе использую не Object Pascal, синтаксис которого мне нравится больше, а C++, уродливость которого признают даже и те, кто этот синтаксис разрабатывал.
А почему, собственно?
Потому что это утверждения из разряда "на Java нельзя написать производительное решение" или там "хаскель в прод никто не пишет". Такое говорят те, кто не пытался даже разобраться в теме.
Да сколько угодно таких альтернатив. Та же Ada или Oberon.
Они просто менее популярны — но тут, как бы, беда не в плохом синтаксисе.
Или вы про то, что раз Rust стал популярен, то его синтаксис, внезапно, стал красив?
Я вот не считаю Ada или Oberon красивым. Куда лучше ML, с ним раст был бы красивее. Только вот подозреваю, что будь раст ML-языком, вы ба ещё больше ругались, какой он сложный и непонятный.
Вот есть сиподобный раст. Покажите, что поменять, чтобы стало лучше. Не обязательно полную спеку измененного синтаксиса, просто пример: вот зщас пишут так, а вот если писать так. то смотрите как круто и удобно.
И тогда мы сможем предметно оценить, как круто и удобно стало или некруто и не очень удобно. Общие слова про аду и оберон это хорошо, давайте конкретику. А то есть подозрение, что ада или оберон издалека лучше, а если начать кокнертно применять, окажется что они в 2 раза меньше информации в коде содержат (есть аллокации/нет, какие лайфтаймы, уникальные/шаред ссылки, ...).
Потому что это утверждения из разряда "на Java нельзя написать производительное решение" или там "хаскель в прод никто не пишет". Такое говорят те, кто не пытался даже разобраться в теме.
Извините, не согласен. Красота синтаксиса — вещь субъективная. Почему мы не можем ее обсуждать? Обсуждают же красивых парней или девушек в отдельных сообществах? Другой вопрос как синтаксис влияет на продуктивность программиста, но это совсем другой вопрос. И, да, с самым ужасным синтаксисом тоже можно жить, если этот язык дает какие-то определенные бенефиты
Извините, не согласен. Красота синтаксиса — вещь субъективная.
Местами вполне объективная. Например, приоритет операций && и == в С++ источник кучи багов. И это чисто синтаксическая вещь. Есть субъективная часть синтаксиса, из разряда какого цвета подсветка, а есть вот такая. Даже за вопросами "писать скобки или нет/писать точки с запятыми или нет" стоят ресерчи с кучей фактов. Эргономика изучает в том числе и это. Или они шарлатаны, раз рассказывают, когда шрифт с засечками лучше, а когда — рубленый? Потому как мне кажется что аналогия очень подходящая.
Например, приоритет операций && и == в С++ источник кучи багов.
Это не красота в общем понимании этого слова. Но согласен, что отдельные нюансы в синтаксисе могут … вот так вот влиять на качество кода. Об этом и вторая часть моего месседжа:
Другой вопрос как синтаксис влияет на продуктивность программиста, но это совсем другой вопрос. …
Одного воротит от отступов, другого от begin end, третьего от таких скобок "(" и ")", но зато он фанатеет от "{" и "}";
один ценит краткость, другой информативность; один привык воспринимать код как плоский текст, другой же и шагу не ступит без нормальной IDE, и т.д и т.п. Любой аргумент одного будет восприниматься других в штыки.
И вот это Ваше: «Пожалуйста, хватит ругать синтаксис» — это неуважение к собеседнику с мнением отличным от вашего.
Получается, что все вокруг дураки одни вы умные. И чем с таким отношение к собеседнику, вы отличаетесь от с++ шников?
Там тоже считают, что все решения, которые принимает комитет, все они продиктованы реальной постребностью, а все попытки обойтись без этих решений наивны и смешны.
И да текущий синтаксис раста, это то что бывает когда начинаешь как исследовательский ml-подобный проект, а потом на середине переправы понимаешь, что с и с++ ники такой синтаксис не примут и надо подстраиваться под них.
Для меня, красноречивым стал спор коллег какой синтаксис лучше reason с заискиванием с js, или классический occaml.
Вот прям идеальная иллюстрация того, что у людей разные представления о хорошем.
И вот это Ваше: «Пожалуйста, хватит ругать синтаксис» — это неуважение к собеседнику с мнением отличным от вашего.
У синтаксиса есть объективные измеримые характеристики. Не всегда легко взвесить все за и против, бывают вкусовщинные критерии, но вот "вырвиглазность" это уже ближе к объективным из разряда "скорость чтения незнакомого кода"/"скорость восприятия и построения когнитивной модели из текста"/… И я вот в корне не согласен, что у растового синтаксиса с этим хуже чем у "невырвиглазных" джав или сишарпов каких-нибудь.
Не обязательно полную спеку измененного синтаксиса, просто пример: вот зщас пишут так, а вот если писать так. то смотрите как круто и удобно.Ну, напимер, если не называть уникальную ссылку
mut, а использовать что-то, связанное с уникальностью — то код будет понятнее, согласитесь?А то есть подозрение, что ада или оберон издалека лучше, а если начать кокнертно применять, окажется что они в 2 раза меньше информации в коде содержат (есть аллокации/нет, какие лайфтаймы, уникальные/шаред ссылки,Конечно. Но та информация, что есть — описана человеческим языком. Не вот это вот тт тк прнт пст и не загадочными значками как в ML или Haskell, а обычными человеческими словми. Да, длинно — но зато читаемо.
А если уж идти в сторогу сокращений, то можно было бы всякие λ и ⩴ приспособить к дело — получилось бы немного на математик похоже.
А то, что в
Rust — это, извиняюсь, ни богу свечка, ни чёрту кочерга. Даже после C/C++ синтаксис уродским кажется, а ведь когда-то казалось, что ничего ужаснее придумать нельзя, даже если постараться… оказалось — можно! Легко!Но та информация, что есть — описана человеческим языком. Не вот это вот тт тк прнт пст и не загадочными значками как в ML или Haskell, а обычными человеческими словми. Да, длинно — но зато читаемо.Справедливости ради, это называется не «вырвиглазный синтаксис», а сложный в освоении ЯП по причине избыточной выразительности.
Вот пример, две функции на Rust:
fn foo<'a>(s1: &'a str, s2: &'a str) -> &'a str { ... }
fn bar<'a>(s1: &str, s2: &'a str) -> &'a str { ... }Тип первой функции говорит нам о том, что возвращаемая строка является первой или второй строкой либо подстрокой одной из этих строк. Тип второй функции говорит нам, что возвращаемое значение — это вторая строка либо её подстрока и никак не связано с первой строкой. Если, по вашему, это информация избыточна, как вы предлагаете выводить её компилятору?
В данном примере нет никакого смысла в явном указании лайфтаймов, возможно нужен другой пример.
На основании чего они будут вычислены?
OMG, оказывается такая конструкция невозможна…
fn easybar(s1: &str, s2: & str) -> &str
{
return Box::new("sss")
}
Ну так каким образом компилятор выведет зависимость лайфтама результата от лайфтайма параметра, если убрать лайфтаймы из сингатуры?
Или вы предлагаете анализировать тело функции?
Ну так каким образом компилятор выведет зависимость лайфтама результата от лайфтайма параметра, если убрать лайфтаймы из сингатуры?полную сигнатуру функции можно препроцессить из тела
Или вы предлагаете анализировать тело функции?
И получить время компиляции как на известной картинке?
Интересно, а у трейтов вы тоже хотите выводить лайвтаймы по телу функции?скажем так: в декларации функции нас могут интересовать не только лайфтаймы и мутабельность ссылочных аргументов. Например, оптимизатору может быть полезно знать является ли функция чистой. А если нет, то какие объекты она может менять. А в языках с исключениями оптимизатор захочет знать может ли функция кидать исключения, и, если да, какие (кстати, panic! в расте это то же самое исключение, со всеми соответствующими спецэффектами). И в итоге мы придем к одному из: А. просто забьем на полезную для компилятора инфу и смиримся с просадкой производительности, Б. декларациям простейших функций, не влазящим в новенькие 27" экраны и состоящие преимущественно из закорючек, В. автогенерации всей этой мишуры. Кажется, вариант В является наиболее желанным. То есть мыслить надо в направлении «как реализовать автогенерацию полной декларации функции» а не «почему это не получится».
Искусственный интеллект и нейроинтерфейсы еще недостаточно развиты. Да и вы не находите, что будет некоторая дискриминация программистов, не желающих, чтобы машина лезла в их мозг?
</sarcasm>
Искусственный интеллект и нейроинтерфейсы еще недостаточно развиты. Да и вы не находите, что будет некоторая дискриминация программистов, не желающих, чтобы машина лезла в их мозг?вы не понимаете как можно из тела функции вывести её объявление?
вы не понимаете как можно из тела функции вывести её объявление?
Автовывод это опасно. Ручная дефиниция объявления — это доп страховка для программиста, чтобы он не пострелял себе по ногам +1 раз. Да, за счет многословности
Автовывод это опасно. Ручная дефиниция объявления — это доп страховка для программистапогодите. Автовывод не отменяет явные декларации программиста, а может лишь дополнить их на случай если программисту лень их прописывать, если они зависят от параметров шаблона, ну или если просто хочется оставить код почище. Плюс, автовывод чаще будет корректнее программиста.
Нет. Я вы в нобелевском комитете давно были? Патент зарегистрировали? Мне пора искать другую работу? А то через пару лет компиляторы, глядишь, начнут сами из простыни операторов функции выделять. Нет? А-а-а, понял. Вы первую проблему программирования еще не решили… ну, та, которая с именованием. Что ж, будем ждать дальше...
В языках с сильными системами типов идут от обратного — и это тело функции выводится по типам аргументов и результата. Попытка двигаться в обратном направлении в 99% случаев это неправильное понимание роли системы типов в языках. Я статью про это недавно переводил, она отлично объясняет, почему типчики важны, а вот тело функций — нет.
Не понимаю. Научите, пожалуйста, делать это в общем случае (подсказка: у вас заведомо не получится).а нам и необязательно в совсем «общем случае», закон Парето никто не отменял. В сложных случаях (а-ля циклы в графе вызовов) компилятор может принять дефолтные значения (например, посчитает функцию потенциально кидающей) и/или попросить явной аннотации.
Проблема скорее в том, что это потребует пару дополнительных проходов компилятора с нелинейной ассимптотикой…
Да и вы не находите, что будет некоторая дискриминация программистов, не желающих, чтобы машина лезла в их мозг?
Равенство возможностей. Если никому не запрещают ставить нейроинтерфейс, то всё в порядке. Не хочешь — не ставь, работай как Джон Генри и будешь конкурентноспособен на рынке труда.
var x;
var result;
result = f(x) { y = x; memcpy(result, y) } ;даже лучше так
f(x) { &result = y }Это вы сейчас рассказали как работает возврат по значению. Вот только &str — это ссылка!
но лайфтайм х и результ (тоже будет &str) — одинаков
в чем проблема?
Ну так для случая "один ссылочный параметр на входе + ссылка на выходе" раст как раз позволяет опускать лайфтаймы.
Конечно, нельзя отдать ссылку на локальное хначение которое будет уничтожено внутри скоупа. Ссылка висячей окажется.
mayorovp
Или вы предлагаете анализировать тело функции?
На самом деле оно и сейчас анализируется (иначе не работали бы экзистенциальные типы), но да, лайфтаймы должны выводиться чисто из сигнатуры.
Конечно, нельзя отдать ссылку на локальное хначение которое будет уничтожено внутри скоупа. Ссылка висячей окажется.Не окажется, мы же ее вернем как результат. Какой то бред в Расте
Ссылка в рантайме — просто указатель. Если бы компилятор позволил её вернуть, то это был бы указатель на содержимое невалидного фрейма стека.
Как-то попахивает такое техническое решение сами знаете чем.
Но ниже привели неплохой контрпример, так что надо подумать.
Если мы выводим лайвтаймы по реализации функции, то получается мы можем сломать код изменив немного тело функции внутри и не меня сигнатуру функции. И мы не можем сделать заглушку для функции, а потом ее реализовать иначе потенциально может потребоваться переписывать весь внешний код. По вашему это нормально?
Нет, не передано, потому что Box это не &str, у вас типы разъехались.
Вот только &str не владеет строкой, на которую ссылается, а потому и "принять" владение от Box ну никак не может.
Вам выше уже написали что ССЫЛКА — это ссылка, а результат — это возврат по значению.
Кстати отличный пример, с такой функцией компилятор ну никак не может вывести лайфтаймы автоматически, ему нужно это объяснить руками:
fn easybar<'a, 'b, 'c>(s1: &'a str, s2: &'b str) ->
Box<&'c str>
{
Box::new("sss")
}Как это вы предлагаете выводить — не представляю
А так работает
fn easybar<'a, 'b, 'c>(s1: &'a str, s2: &'b str) ->
&'c str
{
"sss"
}fn easybar<'c>(s1: &str, s2: &str) ->
&'c str
{
"sss"
}
А вот так — нет, что напоминает простую фелляцию компилятору
fn easybar(s1: &str, s2: &str) -> &str
{
"sss"
}Так не работает, потому что компилятор не имеет понятия, должна ли строка формироваться из первой строки, второй, или обеих.
Это может означать:
fn easybar1<'a, 'b, 'c>(s1: &'a str, s2: &'b str) ->
&'c str
{
"sss"
}
fn easybar2<'a, 'b>(s1: &'a str, s2: &'b str) ->
&'b str
{
"sss"
}
fn easybar3<'a, 'b>(s1: &'a str, s2: &'b str) ->
&'a str
{
"sss"
}
fn easybar4<'a>(s1: &'a str, s2: &'a str) ->
&'a str
{
"sss"
}Какой из этих вариантов должен вывестись и почему?
Аналогичный "бред" из С++:
std::string_view easybar()
{
return std::string("sss");
}Та же самая ошибка, но уже нет гарантии что компилятор её заметит (хотя clang как-то замечает).
std::string& easybar()
{
return *new std::string("sss");
}Ну уж нет, str в Rust не владеет памятью, он никак не может быть аналогом владеющего памятью std::string.
И оператор new никоим образом не является аналогом Box::new, потому что Box::new создаёт умный указатель, а не обычный.
std::unique_ptr<std::string_view> easybar()
{
return std::make_unique<std::string_view>("sss");
}str в Rust не владеет памятьюСтранно, какого тогда фига
fn whystr() -> str {
"123"
}error[E0277]: the size for values of type `str` cannot be known at compilation time
Не уверен, что это можно назвать владением памятью. Но если вы настаиваете, уточню: str в Rust не выделяет память динамически.
Тут
/// A `&str` is made up of two components: a pointer to some bytes, and aПотому причина ошибки мне непонятна
/// length. You can look at these with the [`as_ptr`] and [`len`] methods:
error[E0277]: the size for values of type `str` cannot be known at compilation time
`&str` — это строковый слайс
&str содержит указатель на данные. str никакого указателя не содержит — это и есть данные, последовательность байт, длина которой будет записана рядом с указателем на неё.
Внутри функции foo/bar эта информация бесполезна
Не согласен, они нужны точно также, как и любая информация о типах. Скажем, foo может быть функцией, которая возвращает более короткую строку, а bar — функцией, которая возвращает строку без указанного префикса. Допустим, я писал функцию bar == cut_prefix, в процессе задумался и случайно написал неправильно — ну, с кем не бывает:
fn cut_prefix<'a>(prefix: &str, s: &'a str) -> &'a str {
if s.starts_with(prefix) {
&s[prefix.len()..]
} else {
prefix
}
}В этом случае из-за того, как я расставил лайфтаймы, функция не скомпилируется.
снаружи — при их вызове времена жизни и так будут вычислены.
Не будут. Вот пример:
fn example(n: u32, string: &str) -> &str {
let n_str = n.to_string();
return funcname(&n_str, string);
}Эта функция скомпилируется, если вместо funcname подставить bar, и не скомпилируется, если вместо funcname подставить foo — и совершенно правильно, потому что функция пытается вернуть ссылку на локальную переменную. Корректность самой функции example проверяется исключительно с опорой на её текст и сигнатуры функций foo и bar, как и должно быть для нормальной проверки типов. Пытаться анализировать логику самих функций бесполезно — что в foo, что в bar у меня вместо нормальной реализации стоит заглушка, которая запаникует в рантайме.
Пример1. (cut_prefix) Ну не скомпилируется из-за придирчивого компилятора, но на что это влияет по факту? Лайфтаймы должны быть вычислены при вызове
Пример2. (example) Тут никаких сомнений, Раст однозначно защищает меня от возвращения ссылки на локальную переменную вне живого стека. Но исходного моего утверждения, что лайфтаймы вычисляются при вызове по сигнатуре, не меняет, да и практическую ценность несет небольшую — детские ошибки
fn bar<'a>(_s1: &str, s2: &'a str) -> &'a str { s2 }
fn foo<'a>(s1: &'a str, _s2: &'a str) -> &'a str { s1 }
fn easybar<'c>(_s1: &str, _s2: &str) -> &'c str {
"sss"
}
fn example(n: u32, string: &str) -> &str {
let n_str = n.to_string();
// return foo(&n_str, string); // bar is OK, foo - fail
return easybar(&n_str, string);
}
fn main() {
let s : &str = "666";
println!("{}", example(42, s));
}Собственно, DFA анализ в GCC10, D и линтерах такую проблему (escaping pointers) отлавливает на раз, так что траходром с явным указанием лайфтаймов можно считать уже устаревшим.
Пример1. (cut_prefix) Ну не скомпилируется из-за придирчивого компилятора, но на что это влияет по факту?
Ага, всего лишь "не скомпилируется из-за ошибки несоответствия типов, которые не ловят компиляторы других ЯП". Всего лишь вот такая вот мелочь.
Лайфтаймы должны быть вычислены при вызове
А ничего, что времена жизни — это обобщённые параметры и потому при каждом конкретном вызове могу быть разные? И как быть, если вычисления требований лайфтаймов привели к противоречивым требованиям? Это ошибка на стороне вызывающего кода или вызываемого? И ещё:
fn example(n: u32, string: &str) -> &str {
let n_str = n.to_string();
if n > 200 {
cut_prefix(&n_str, string)
} else {
cut_prefix(string, &n_str)
}
}Можно ли тут лайфтаймы вывести для каждого вызова? Пожалуй, можно. Но в целом всё равно фигня получается.
Пример2. (example) Тут никаких сомнений, Раст однозначно защищает меня от возвращения ссылки на локальную переменную вне живого стека. Но исходного моего утверждения, что лайфтаймы вычисляются при вызове по сигнатуре, не меняет, да и практическую ценность несет небольшую — детские ошибки
Так пример специально утрированный, чтобы ошибка сразу была видна. В реальных проектах подобная ошибка охватывала бы код куда большего объёма, где ошибка не столь очевидна. К тому же, как подсказывает опыт компании PVS-Studio, опытность программистов может снизить количество подобных глупых ошибок, но отнюдь не убрать их вовсе. Глупые ошибки делают все, и я бы предпочёл иметь возможность отлавливать их пораньше. Здравый смысл также подсказывает, что серьёзность ошибки не зависит от того, насколько она глупая.
Собственно, DFA анализ в GCC10, D и линтерах такую проблему (escaping pointers) отлавливает на раз, так что траходром с явным указанием лайфтаймов можно считать уже устаревшим.
Не знаю, о каких линтерах вы говорите, и не знаю, как сделать аналог на D, но насчёт GCC 10 — это лол, он нихера не ловит, и экспериментальная ветка Clang с -Wlifetime тоже нихера не ловит.
Для D надо писать цепочку ф-ций с атрибутом @ live
Я переводил, как оно должно работать, но сам не пробовал.
На самом деле тут есть два момента.
Во-первых явная аннотация очевидно нужна в случаях когда компилятор не может вывести сам ничего принципиально. Такие как: вызов стороннего кода, указательная арифметика, cобственные аллокаторы и прочие штуки которые завязаны на внутреннюю логику программы и используют ансейф. В С++ анализаторах эти аннотации вешаются как минимум на методы из std.
Во-вторых проблема явных аннотаций сродни проблемы явных указаний trait bounds. По сути то что предлагаете вы это тайпчек (т.е. лайфтайм чек в нашем случае) во время инстанциирования функции. Уже выше показали что в зависимости от лайфтаймов аргументов функция может компилироватся а може и нет. А именно funcname может передавтся как аргумент *fn (&str, &str) -> &str. Получаем ужас аналогичный темплейтам плюсов с киллометровыми сообщениями об ошибках. Было бы более гибко, но такой язык уже есть.
Да, я знаю: идеалы красоты меняются. И Вермеера с Хан ван Меегереном вы не спутаете именно поэтому: сегодня Марлен Дитрих уже не кажется похожей на святых.
Но, тем не менее, странно утверждать что ни красоты, ни уродства в природе не существует. Даже самые-самый «фанаты бодипозитивизма» до этого не додумываются.
И вот
Rust, синтаксически, это — страшная гремучая смесь, которая, в общем-то делит людей на два лагеря. Причём если люди из одного лагеря могут обяснить почему им function нравится больше, чем fn, то противоположный лагерь почему-то всё больше аппелирует вариациями на известную тему.Спердобейся, это, в сущности, скорее признание своей собственно неправоты. Потому что если копнуть, то фраза Или разберитесь и предложите альтернативы, или осознайте где вы не правы, если таких альтернатив не найдете автоматически запирает собеседника в рамки «уродцев, которые хотят вписать в C-подобный синтаксис совершенно не C-подобную семантику»… на зачем мне рассматривать именно эти рамки?
Я, как раз, ни разу не в восторге от синтаксиса C и с удовольствем бы пользовался языками без бесконечный заколючек ("{", "&", "}" и прочих), но если вы решили остаться в этих рамках — то да вы получите уродца, так или иначе. Это, почему-то, должно заставить меня считать, что вот этими уродцами — и ограничивается весьма мир теперь? Да и даже на их фоне
Rust со своими dyn/impl/priv выделяется особо.Хуже только C++ со своими
co_await/co_return/co_yield… но там, хотя бы, никто не пытается сделать вид, то это красиво. Удобно — да. Разумно — да. Красиво — нет! Оно именно потому и удобно и разумно, что некрасиво! Потому что любые красивые и подходящие слова приводили к конфликтам, так как создатели библиотек, знаете ли, тоже красоту любят и потому все красивые слова «разобрали».Но создателей
Rust кто заставлял ref вместо reference использовать? Это, извините, совместимость с чем?Вам уже выше пытались объяснить, что понятие «красоты синтаксиса языка» (которое вы пытаетесь ввести) слишком субъективно и разплывчато. И поэтому не имеет особого значения.
А с точки зрения скорости чтения кода и понимаемости синтаксис раста вполне нормальный. Не возникает вопросов это объявление структуры или вызов функции или что-то еще. Что тут еще обсуждать? А главное с какой целью? Совершенно не понятно.
Вам уже выше пытались объяснить, что понятие «красоты синтаксиса языка» (которое вы пытаетесь ввести) слишком субъективно и разплывчато.Нет, мне не пытались ничего объяснить. Мне пытались навязать — это другое.
А с точки зрения скорости чтения кода и понимаемости синтаксис раста вполне нормальный.Нет. Он абслютно не «нормальный». Состоит из кучи маленьких похожих закорючек и каких-то странных аббревиатур и обрезков слов.
Нормальный текст, на русском или английском языке, в таком стиле, никто, в здравой уме и твёрдой памяти удобочитаемым бы не назвал. В этом-то и проблема.
А главное с какой целью?Цель-то как раз понятна: сделать работу с программами (а читают их, в среднем, гораздо чаще, чем пишут) удобнее и приятнее. Но вместо этого предлагается обсуждать возможно запихнуть как можно больше всего в одну строку.
В этом смысле Perl — почти идеал… ну и многим его синтаксис нравится?
Кроме того вы не замечали, что наиболее часто используемые слова в языке стараются сделать (или уже сделали) короткими I, we, you, they, it, if, и т. п. Я правильно понимаю, что они какаие-то слишком короткие в английском и их хорошо бы удленнить для… эмм, написания текстов в стиле Толстого?
К тому же вы никогда не пользуетесь сокращениями? Может стоит попробовать :-)
Говорят в гос. структурах любят использовать сокращения и им норм. Почему? Да потому что они знают как эти сокращения расшифровываются и это им позволяет эффективнее общаться. Да, это напрягает обычных людей. Но языки программирования не нужны обычным людям. Они нужны программистам, которые знают что означают те или иные ключевые слова и где они могут использоваться.
И все-таки почему большинство таких фанатичных любителей подокапываться до синтаксиса языков считает, что нужно стремиться, чтобы текст на языке программирования был похож на английский текст? Они ведь разные задачи решают? И ключевые слова на языке программирования это не английские слова. Это слова на языке программирования (другом языке, не английском, с другой семантикой и другими задачами). Да ключевые слова подобраны, чтобы вызывать определенные ассоциации с английскими словами. С установлением ассоциативных связей, как мне кажется, ключевые слова справляются на ура. Да, может быть сами слова для ассоциаций не всегда выбраны абсолютно точно, но это уже другой вопрос.
> Нормальный текст, на русском или английском языке, в таком стиле, никто, в здравой уме и твёрдой памяти удобочитаемым бы не назвал. В этом-то и проблема.
Строго формальные вещи (которые в том числе описыватся на языках программирования) даже математики на естественных языках не пишут. Они для этого придумали язык теоретико-множественных обозначений. Странные эти люди — ученые… Серость. Да?
И ключевые слова на языке программирования это не английские слова.Уровень аргументации спустился ниже плинтуса, пробил дно и устремился к центру Земли, извините.
Да ключевые слова подобраны, чтобы вызывать определенные ассоциации с английскими словами.Они не «подобраны, чтобы вызывать ассоциации», извините. Они-таки являются либо словами английского языка, либо чем-то, порождённом из английского языка.
Никогда не понимал, почему любители покритиковать синтаксис какого-либо языка программирования считают эталоном английский язык? Почему не хинди или китайский (самый распростраенный)?Вот с тех случаях, когда язык сдела не на основе английского (1С, например) — логично рассматривать его с позиций того языка, откуда он был рождён. Русского, китайского, хинди — неважно. Что явилось базисом — то, как бы, базисом и является.
С установлением ассоциативных связей, как мне кажется, ключевые слова справляются на ура.Не в том случае, когда их исковеркали и изуродовали, извините.
Строго формальные вещи (которые в том числе описыватся на языках программирования) даже математики на естественных языках не пишут. Они для этого придумали язык теоретико-множественных обозначений. Странные эти люди — ученые… Серость. Да?Таки да. Апофигея вся эта деятельность по переходу на «язык теоретико-множественных обозначений» достигла в деятельности Бурбаки.
А теперь, внимание, вопрос: много вы можете назвать ВУЗов, преподающих математику вот на основе всего этого? А почему, собственно? Ведь это же так круто и понятно?
Во всех вузах что я видел определение предела даётся таким образом:

И никак иначе
Уровень аргументации спустился ниже плинтуса, пробил дно и устремился к центру Земли, извините.
Если оппонент там уже находится, приходится идти ему настречу.
Они не «подобраны, чтобы вызывать ассоциации», извините. Они-таки являются либо словами английского языка, либо чем-то, порождённом из английского языка.
Если язык Б произошел от языка А. Это совершенно не значит что в языке Б все слова должны совпадать с языком А. У языка Б могут быть похожие слова, которые одинаково или похожим образом пишутся или читаются. И при этом они могут обозначать разные вещи (да со временем языки могут расохдиться это естественный процесс). Так что это именно слова языка Б похожие на слова из языка А. Так их просто удобнее и можно более гибко воспринимать.
Не нравится, что ключевое слово (именно полноценное слово на языке rust) mut вызывает не совсем правильную ассоциацию? Ну так проявите гибкость ума и придумайте более подходящую ассоциацию. Например: Mono UniT.
Но создателейRustкто заставлялrefвместоreferenceиспользовать? Это, извините, совместимость с чем?
Вот это как раз неудачный пример. Ключевое слово ref используется в паттернах для того, чтобы указать, что данное имя привязывается не по значению (и таким образом забирает владение), а по ссылке. До версии 1.26.0 (то есть до match ergonomics) это ключевое слово активно использовалось, потому что это был единственный способ сматчиться по значению, не перемещая его:
match &optional_value {
&Some(ref value) => println!("got value: {:?}", value),
&None => println!("got value: {:?}", value),
}Замена ref на reference раздула бы все подобные матчи, причём особенно сильно там, где матчатся по нескольким полям сразу, и не добавило бы ровным счётом ничего в читабельности.
ЗаменаКак это не добавило бы? Код стал быrefнаreferenceраздула бы все подобные матчи, причём особенно сильно там, где матчатся по нескольким полям сразу, и не добавило бы ровным счётом ничего в читабельности.
более воздушным, в нём стало бы больше строк и чатать его стало бы легче.
Да, его стало бы чуть больше, но вот реально — настолько больше, чтобы об этом было нужно переживать?
Вот это как раз в языках типа Haskell и Rust удивляет больше всего: мучитальные попытки сделать тривиальный код как можно более компактным — при этом в тех же программах будут построения на 100500 строк где хитромудрые навороты в типах устраиваются.
Зачем это всё? Вы печатаете
Rust-программу на листах A4 и платите за них? Или зачем?По-моему синтаксис раста не отличается от других си подобных языков. Что именно вырвиглазное? Единственная добавка это лайфтаймы. Действительно вначале копипасты кода на разных форумах выглядели странно, т.к. кавычки казалось бы должны закрываться. Но после того как я открыл код на расте в нормальном IDE, где лайфтаймы выделены отдельным цветом — больше никаких проблем не было. А потом и без подсветки глаз привыкает.
К красивому не нужно привыкать. А к уродству, как раз, нужно.
К C++ я уже давно привык… но красивым это его не сделало. Но там, просто, это дошло до такого маразма, что целые тьюториалы пишутся, чтобы объяснить людям как найти в чём-нибудь типа
void (*signal(int signum1, void (*handler)(int signum2)))(int signum3) аргумент функции (да, у неё два аргумента: signum1 и handler — и нет, это нифига неочевидно не только для новичка… как неочевидно даже и то, что это, собственно, фукнция (а не указатель на оную).В
Rust, насколько я знаю, всё-таки уж такого ужаса нету и, пожалуй, практически этот уровень вырвыглазности можно считать приемлемым. Но красивым? Увольте.Волосы не компенсирую.
С сохранением семантики:
use libc::{c_void, c_int};
fn signal(sign: c_int, handler: *mut fn(c_int) -> c_void) -> *mut fn(c_int) -> c_void {
// ...
}Если бы API изначально было бы на расте:
enum SignalHandler {
Default,
Ignore,
Custom(fn(Signal)),
}
fn signal(flags: SignalFlags, handler: SignalHandler) -> Result<SignalHandler, SignalError> {
// ...
}Извините, но это типичный биас. Примерно как говорили они — стерпится — слюбится
Или разберитесь и предложите альтернативы, или осознайте где вы не правы, если таких альтернатив не найдете.В этом однозначно есть здравое зерно.
Но предлагаю вынести это в отдельную тему: —
«Как сделать Раст читаемым без человеческих жертв»
Ну, напимер, если не называть уникальную ссылку mut, а использовать что-то, связанное с уникальностью — то код будет понятнее, согласитесь?
Согласен, но когда говорят про вырвиглазность обычно претензий к mut нет, а скорее "ой почему fn две буквы, почему тип после имени пеерменной, лайфтаймы не нужны" ну и прочее.
Конечно. Но та информация, что есть — описана человеческим языком. Не вот это вот тт тк прнт пст и не загадочными значками как в ML или Haskell, а обычными человеческими словми. Да, длинно — но зато читаемо.
https://habr.com/ru/news/t/479204/#comment_20981010
А то, что в Rust — это, извиняюсь, ни богу свечка, ни чёрту кочерга. Даже после C/C++ синтаксис уродским кажется, а ведь когда-то казалось, что ничего ужаснее придумать нельзя, даже если постараться… оказалось — можно! Легко!
Так что уродского? Я и говорю "давайте как в джаве", сделают как в джаве — "ой, слишком длинно, давайте половину уберём". Давайте конкретно, "вот пример говенного кода, а вот так читается намного лучше". Можно ведь с конкретикой? А то я за "ууу, худший синтаксис в истории, хуже чем даже у плюсов", когда спрашиваю в чём, начинаются непонятны аналогии и прочие, как говорят англосаксы, handweawing argumentation
Но создателей Rust кто заставлял ref вместо reference использовать? Это, извините, совместимость с чем?
То есть
match x {
&Some(ref Ok(ref Either::Left(ref value))) => {...}
}Это вырвиглазно, а
match x {
&Some(reference Ok(reference Either::Left(reference value))) => {...}
}Круто и читаемо? Вы правда думаете, что прочитав ref человек не поймет, о чем идет речь?
лайфтаймы не нужныэто стоит обсудить. ведь до сих пор явное указание лайфтаймов было не нужно, оно выводилось.
И я не поддерживаю фразу
ууу, худший синтаксис в истории, хуже чем даже у плюсовхудший был у М[umps]
Вы правда думаете, что прочитав ref человек не поймет, о чем идет речь?Я правда думаю, что если вы даёте много информации — то у вас и текста должно быть много. И то, что вы написали с reference, разумеется, ещё хуже, чем с ref, а чтобы это можно было легко читать оно должно быть отформатировано… ну хотя бы так:
match x {
Access Some(
reference Ok(
reference Either::Left(
reference value))) => {
...
}
}
Короче — далеко не всегда понятнее. И то что вы засовываете кучу сложных конструкций в одну строку — код, извините, понятнее не делает.Его становится сложнее читать, так как в этих закорючках и обрезках слов глаза путаются. Но и только.
В итоге код стал в 2 раз длиннее, без какой-либо ценности. Он не стал чище и проще читаться, в первом случае я сразу увидел что меня интересует ссылка на одно значение в трёх уровнях вложенности, а теперь мне надо парсить 4 строки кода, чтоб понять что же там такого.
Короче — далеко не всегда понятнее. И то что вы засовываете кучу сложных конструкций в одну строку — код, извините, понятнее не делает.
Это не сложные конструкции, это примитивная деконструкция. Если у меня не-нулл и результат не ошибка, то я хочу значение лежащее внутри Either'а.
Нет, вот этот Access вместо & меня очень раздражает. Я бы не хотел так писать. И читать это тоже не хотел бы.много обрезком слов и типографики.
И да, я понимаю, что сейчас время такое, писать в стиле Льва Толстого невозможно, сейчас эра твиттера и попыток впихнуть в 140 символов как можно больше всего… но мне казалось, что Хабр — последнее место, где нужно объяснять почему это плохо.
Боюсь представить какая у вас реакция на код на агде будет:
module Interleaving {a b l r} {A : Set a} {B : Set b} (L : REL A B l) (R : REL A B r) where
open import Data.List.Base
infix 3 _≣_⨝_
data _≣_⨝_ : List A → List B → List B → Set r where
[] : [] ≣ [] ⨝ []
_ˡ∷_ : ∀ {a as b l r} → L a b → as ≣ l ⨝ r → a ∷ as ≣ b ∷ l ⨝ r
_ʳ∷_ : ∀ {a as l b r} → R a b → as ≣ l ⨝ r → a ∷ as ≣ l ⨝ b ∷ r
split : xs' ⊆ xs → xs ≣ us ⨝ vs →
∃ λ us' → ∃ λ vs' → xs' ≣ us' ⨝ vs' × us' ⊆ us × vs' ⊆ vsНу, это по крайней мере напоминает математическую запись
И во-многом, как раз, из-за ужасного синтаксиса.
Rust, пожалуй, находится на грани, когда синтаксис хотя и ужасен, но недостаточно ужасен для того, чтоы всех потенциальных пользователей распугать.Мне кажется, вы придумаываете какие-то свои критерии, под которые подгоняете языки, в итоге получается что-то вроде пиратов и глобального потепления — вроде, связь есть, но если копнуть поглубже, оказывается, что нет.
Ну и ML куда проще си-подобного синтаксиса, тут даже спорить как-то неловко
И да, я знаю, что Haskell-community прилагает много разных титанические усилий для того, чтобы этим языком, не дай бог, не начали активно пользоваться, вырвиглазный синтаксис — только одна сторона вопроса, там есть много других способой «сохранения элитарности».
P.S. И да, Shell как раз на TIOBE — «ниже плинтуса», даже не 50ке: сервисы, изучающие популярность на основе исключительно числа написанных на языке файлов и использующих их проектов склонны завышать показатели Shell ибо вспомогательные скрипты часто есть в проектах просто потому, что «так жизнь устроена», а не потому что кто-то на Shell что-то сознательно пишет.
И да, я знаю, что Haskell-community прилагает много разных титанические усилий для того, чтобы этим языком, не дай бог, не начали активно пользоваться, вырвиглазный синтаксис — только одна сторона вопроса, там есть много других способой «сохранения элитарности».
Вы о чём? У Haskell лучший синтаксис из всех ЯП, которых я видел.
Проблема с <: в том, что из этого никак не выводится subtypingRelation или вообще какое-то другое имя. Это просто набор закорючек, хоть лигатурой, хоть раздельными символами. Стрелочки еще как-то можно интуитивно сопоставить с тем, что они делают — преобразование чего-то во что-то, или передачу чего-то куда-то — хотя там тоже большой простор для воображения
или там, когда я игрался с петухом,
Не рискнули по другому перевести?
Да сколько угодно таких альтернатив. Та же Ada или Oberon.
Синтаксис всех паскалеподобных языков мне кажется омезительным. И что теперь? Синтаксис всех языков программирования чудовищен, по крайней мере местами. Синтаксис Rust не хуже и даже получше прочих — ближе к ML, хотя тоже еще тот подарок.
Вы в свою очередь можете привести контр-примеры на обсуждаемую тему и «заткнуть за пояс» своих оппонентов, которых вы так неуважительно кличите «растишками»
Просто выступление было уже как бы год назад, а обсасывается растишками до сих пор. Я "слегка" удивился, что эта тысячу раз обсосанная тема снова поднимается, и снова растишками.
Жуки крестовики такие токсичные токсичные ))))
Не слышал чтобы у технических фактов был "срок годности", чай это не правонарушение.
Ну тут как бы дискуссия идёт в другой плоскости. Условно, один говорит "если в unsafe коде программист забудет такие-то проверки, то будет UB poisoning, вся программа станет unsound, поэтому safe rust — это в известной степени иллюзия". Другой ему условно отвечает "зато если не забудет, то все будет хорошо, а unsafe блоки нужны для явного выделения опасных мест". По-моему оба высказывания ничуть не противоречат друг другу.
Хороший аргумент.
Тут еще надо добавить, что областью анализа для поиска UB в C++ является вся программа целиком, а в Rust — только unsafe блоки. И я много раз писал приложения, в которых нет ни одного unsafe. Просто потому что так проще.
а в Rust — только unsafe блоки
Скорее все модули, которые могут нарушить инварианты на которые полагаются unsafe блоки, включая модуль содержащий соответствующий unsafe. Оно нелокально. Но нормальная инкапсуляция позволяет ограничить эту нелокальность границами модуля.
Возьмите какую-нибудь реализацию Vec<T> и добавьте вполне safe функцию, которая будет менять capacity и получите UB при попытке писать не в свою память.
Возьмите какую-нибудь реализациюДа-да, добавьте такую функцию не используяVec<T>и добавьте вполне safe функцию, которая будет менятьcapacityи получите UB при попытке писать не в свою память.
unsafe — а я на это посмотрю. Интересно будет увидеть как вы это устроите.P.S. Вы, конечно, правы в том смысле что если почему-то, вдруг, такое в вашем проекте, почему-то, не приводит к бану автора, написавшего это — то могут быть эксцессы. Но в этом смысле и замок у вас на входной двери не нужен (можно же положить ключ под коврик) и парль для доступа к вашему банковскому счёту ни от чего не защищает (вы же можете его на лбу вытатуировать — и всё, больше нет защиты), но, как-то, обычно всё же считается что устраивать из своей квартиры проходной двор — не стоит. И виноват в утечке денег со счёта, в таких случаях, не банк, а клиент, вытатуировавший свой пароль у себя на лбу.
Да-да, добавьте такую функцию не используя unsafe — а я на это посмотрю. Интересно будет увидеть как вы это устроите.
Вообще-то это будет обычная сейф функция.
capacity не меняя больше ничего? И давая, соответственно, доступ к чужой памяти? Это как?Ну, к примеру, возможна такая ситуация:
// нормальные данные
buf = 0x... // allocated
capacity = 8
len = 7А потом делаем capacity + N без переаллокации буфера:
// плохие данные
buf = 0x... // old allocated
capacity = 8+N
len = 7Тогда при последующем vec.push всё будет хорошо(len=8), но еще один vec.push всё сломает, т.к. мы выйдем за границы аллоцированного куска памяти.
Так что ничего удивительного нет. Код снаружи unsafe может инвалидировать код внутри unsafe. Радует, что можно инкапсулировать этот unsafe и уменьшить поле для анализа.
Ну а в стандартном векторе нет возможности изменить capacity иначе, чем через resize/push(который может сделать переаллокацию и увеличение capacity). А метод Vec::set_len помечен как unsafe.
Ну а в стандартном векторе нет возможности изменить capacity иначе, чем через resize/push(который может сделать переаллокацию и увеличение capacity). А метод Vec::set_len помечен как unsafe.Ну так об этом и речь. Внутри функции, которая будет менять
capacity вам придётся использовать какой-то небезопасный механизм. Не обязательно даже unsafe-блок. Можно, в конце-концов, внешнюю программу запустить, которая через ptrace к вам обратно в память залезет и всё испортит.Так же, и в реальном мире: не обязательно владеть копией ключа, можно и через окно залезть, если сильно стащить что-нибудь хочется. Но в любом случае — весь насанкционированный доступ сводится к конечному, относительно небольшому, списку «точек уязвимости». И если вы всем сотрудникам даёте ключи от склада с одинаковыми правами — то это не вина того, кто проектировал для этого склада замки.
То же самое и с Rust: совершенно очевидно, что тот, кто имеет право «привилегированного доступа» (
unsafe-блок) может передать ключи своему помощнику… но виноват-то будет в любом случае тот, у кого был привелигированный доступ изначально.Вы же говорите «для доступа на охраняемую территорию нужно быть в списке зарегистрированных» (и получить соотвествующий бейдж), а не «для доступа на охраняемую территорию нужно забрать бейдж у кого-то, кому он положен — а быть внесённым в список — не нужно». Хотя технически — верно второе, а не первое.
Вот и в случае с
unsafe-блоками Rust — всё то же самое: технически ошибка может проявиться где угодно в «безопасном» коде… но организационно — это обозначает что кто-то за своим бейджиком не следит. Из тех, кому он положен.Посмотрите пример, который линканули выше. Тлдр:
- вектор когда смотрит ресайзить или нет смотрит на поле cap
- изменение поля cap на неправильное значение можно сделать в полностью safe коде. Небольшой пример: https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=ec51a529108ac76a0bf8b2b695b015ad
Функция evil_nut_safe совершенно безопасная, но ломает ансейф в совершенно другой части приложения. То есть да, падает в ансейф блоке, но причина падения — не в нём.
Да нет, все же в нем. Нельзя просто так разыменовывать указатель, не проверив его на null. То, что возникла утечка памяти в evil_but_safe — это проблема, но про нее Rust как раз и не дает гарантий, что он будет защищать от них.
нулл тут не при чём. Если я туда вместо нулла запишу 0x123456 то это будет не нулл, но лучше не станет. Это же просто пример, с вектором он запутаннее немного, но зато куда жизненнее.
unsafe — то вы должны:- Убедиться в том, что вы понимаете в каком состоянии данные, с которыми вы собрались работать.
- Убедиться в том, что после окончания работы все инварианты, которые требуют соблюдать Rust-система — соблюдены.
self.0 тоже. В противном случае сама по себе пометка unsafe мало о чём говорит.Не сильно жизненнее. Когда вы пишите слово unsafe — то вы должны
Нет, когда я пишу unsafe то я должен убедиться, что не делаю вещи, которые описаны в перечне "чего не надо делать". Даже не так, я должен писать unsafe только если компилятор его требует, у меня только выбор написать его на топ-левеле в декларации (и экспортировать ансейф вызывающему коду), или я считаю что это безопасный враппер, поэтому ансейф можно написать на уровне тела. Поэтому
Если в Rust принято размечать блоки так, как вы из разметили, то это очень грустно.
Именно так блоки и размечаются, потому что если компилятор не требует unsafe блока, то его писать не надо, это будет считаться ошибкой (насколько мне известно).
Как раз потому, что инварианты типов слабо соотносятся с тем, что "раст считает unsafe".
unsafe-блоков глядя не на валидность чего-то, ограниченного языком, а на валидность чего-то, ограниченного внеязыковыми соглашениями… в общем вы тут меня огорчили. Сильно огорчили.Больше, чем всё остальное, что было тут сказано в комментариях…
Значит просто вместо self.0.is_null() должна быть проверка self.0 == 0x123456. Повторюсь — проблема в том, что вы разыменовываете что-то, про что вам сказали, что вы не можете разыменовывать, пока не проверите (неважно как, да хоть с помощью хрустального шара).
И как это должно работать, если по стечению обстоятельств self.0 действительно оказался 0x123456?
Вы пытаетесь починить частности, он это то что называется MRE. Оно и ставит своей целью проиллюстрировать проблему. Говорить что в МРЕ вопиющая неправильность и надо ПРОСТО сделать Х — это проявление непонимания, ззачем вообще мре нужны.
Функция evil_nut_safe совершенно безопасная, но ломает ансейф в совершенно другой части приложения.Извините, но она не «ломает ансейф». Они просто меняет данные.
То есть да, падает в ансейф блоке, но причина падения — не в нём.Причина — как раз в нём. Товарищ, которому доверяли, взял инструкцию у «Дяди Васи» и воволок со склада 100 банок пива. Виноват «Дядя Вася»? Нет, конечно. Дядя Вася разве что заказчиком преступления по суду пройдёт.
Виноват всегда тот, кто «не оправдал доверия».
Но в моем понимании, абсолютно любое значение raw_pointer валидно само по себеК сожалению такое понимание не даёт возможности писать надёжные программы. Так как в
Rust отсутствует технология, позволяющая отличить «хорошие» ссылки (которые можно безопасно разименовывать и туда писать) от «плохих»Вообще терминология
safe и unsafe в Rust — изначально неправильная. Так же как как mut концентрируется «не на том» (изменяемость, а не уникальность), так же и unsafe.По хорошему нужно было бы не выпендриваться и называть этот код так же, как во всяких OS и прочих подобных системах его называют: trusted. А подавляющая часть кода, соответственно,
untrusted. Это вызывает нужные ассоциации: человек «с доступом к гостайне», разумеется, не должен верить кому попадя и всё должен проверять. Ну а за untrusted кодом — следит компилятор.Но сейчас, понятно, уже поздно менять…
trusted и untrusted, к сожалению, вызывает неправильные ассоциации. Тоже.
Я не представляю последствий этого, хотя возможно будут и околонулевые.
Ваш unsafe-метод может быть связан с состоянием объекта, со значением в некотором поле. Так как это значение в случае приватного поля разрешено модифицировать во всем модуле, то и граница безопасности проходит по модулю, а не по отдельному методу, который использует unsafe.
unsafe код, который не делает ничего «незаконного» с точки зрения языка, но который, затем, может использоваться unsafe-кодом без проверок — то вы правы.Просто, как я уже заметил, я пока с Rust серьёзно не работал и ожидал, скорее, подхода как в любой другой системе с «уровнями привилегий» (ядро, всякие модули безопасности и прочее) — где принято помечать весь код, который делает небезопасные операции, в том числе — тот, который, формально, делает операции, которые «недоверенный» код также мог бы, теоретически, сделать.
Впрочем это, связано, отчасти, с тем, что граница между «привелегированным кодом» и «непривелегированным» в большинстве таких систем достаточно «толстая» и пересекать её нелегко.
Сразу возникает следующий вопрос: а вот эти данные, которые безопасный код может трогать, но которые потом
unsafe могут спровоцировать на «неправомерные действия» — их как-то хотя бы помечать принято?ИМХО если функция evil помечена как pub то она должна быть unsafe. А если это какой то private implementation details то нет. Проэтом грепать по unsafe это такой полу-миф, потому что как только вы нашли unsafe внутри какого-то mod надо проверять весь модуль. Cмысл unsafe в том что необходимые инварианты приходят из другого кода, т.е. чтобы узнать что они выполнены надо доказать гарантии которые дает другой код (тот который скорее всего safe).
Добавлю: в том примере про actix чел пометил функцию evil (называлась get_mut) как pub(crate) т.е. другими словами приватную для всей библиотеки, а не для модуля (в данном случае модуль это файл cell.rs). Ну и ему сказали за это "не пиши больше на расте бро".
Проэтом грепать по unsafe это такой полу-миф, потому что как только вы нашли unsafe внутри какого-то mod надо проверять весь модуль.Вот это-то и плохо. Это значит, что «привилегированный код» «доверяет» непривелегированному.
Это почти всего кончается плохо. Должно быть чёткое разделение привилегий. В противном случае совершенно непонятно какой код нужно читать «с повышенным вниманием», а какой — «без напряга».
А тот так можно дойти до того, что завести пару «безопасных» функций
peek и poke, которые по адресу в памяти будут обращаться.Cмысл unsafe в том что необходимые инварианты приходят из другого кода, т.е. чтобы узнать что они выполнены надо доказать гарантии которые дает другой код (тот который скорее всего safe).Тогда должны быть какие-то пометки, чтобы понимать какой код «привилегированный», а какой — нет.
Добавлю: в том примере про actix чел пометил функцию evil (называлась get_mut) как pub(crate) т.е. другими словами приватную для всей библиотеки, а не для модуля (в данном случае модуль это файл cell.rs).А какая, собственно, разница? Почему на уровне модуля — можно, а на уровне библиотеки — нельзя?
Если считается, что всем коду, который внутри модуля
unsafe блоки «доверяют» — то тогда модуль и должен метиться как unsafe. А не кусок кода, который, при таком подходе, ничем особо-то и не выделяется.Есть предложение по использованию unsafe для полей, что решит данную проблему:
https://github.com/reem/rfcs/blob/unsafe-fields/active/0000-unsafe-fields.md
https://github.com/rust-lang/rfcs/issues/381
Но пока это не внедрено — да, потенциально придется анализировать весь модуль при модификации чего-то с unsafe.
А какая, собственно, разница? Почему на уровне модуля — можно, а на уровне библиотеки — нельзя?
Потому что в библиотеке могут быть десятки и сотни модулей, а протекание unsafe за пределы своего модуля на уровень библиотеки делает их также потенциально небезопасными.
К тому же со временем ваш pub(crate) вполне может превратиться в pub или появится публичная функция в другом модуле, которая будет оборачивать небезопасную функцию, а так как она не помечена unsafe и определена далеко в другом модуле, то такое отследить будет гораздо сложнее.
Если считается, что всем коду, который внутри модуля unsafe блоки «доверяют» — то тогда модуль и должен метиться как unsafe.Тут есть маааленькая проблема.
1. На расте принципиально нельзя написать все сейф из-за ограничений языка, начиная со стандартной библиотеки.
2. Наследование ансейфа приведет к тому, что все программы станут ансейф.
Так что принят подход «трусов и крестика»
Забавно. А в некоторых других языках принят подход "Ходим без трусов, но с двумя крестиками".
Понимаете — Rust тут нифига не исключение со своим подходом «вся система будет работать хорошо, если те, кто пишут её небольшую часть — напишут её правильно».
Все современные популярне операционки, всякие виртуальные машины (JVM, CLR), браузеры и прочая-прочая-прочая имеют такое деление.
И везде код делится не на «опасный» и «безопасный», а на «доверенный» (trusted) и «недоверенный» (untrusted).
Чтобы там и как ни творила JVM — но пока она не загружает «доверенный» модуль на C — безопасность гарантирована.
А вот когда загружает… модуль на C может «делегировать» заботу о безопасности Java (любой указатель ведь легко влазит в int64).
Но так делать не принято — именно чтобы у нас
trusted не зависел от untrusted.А вот в Rust, с его разделением
safe/unsafe и подходом "unsafe-код иногда может доверять safe коду"… говорить о безопасности trusted кода становится сложнее.То есть понятно, что весь код, помеченный
unsafe вполне себе trusted (просто по определению)… а что ещё?потому что как только вы нашли unsafe внутри какого-то mod надо проверять весь модуль
На практике часто бывает, что инвариант нужный unsafe коду обеспечивается на предыдущей строчке. Например: raw_vec.rs#154 инвариант обеспечивается в строчке 152.
Так что "как только нашли unsafe, так проверять весь модуль" — это преувеличение.
Так что «как только нашли unsafe, так проверять весь модуль» — это преувеличение.Это было бы преувеличением если бы так было не «часто», а «почти всегда». Достаточно редко для того, чтобы каждый случай, когда безопасность
unsafe-кода обеспечивается инвариантами, которые может разрушить safe-код был отдельно откомментирован.Если же это не так и ситуация, когда безопасность
unsafe-кода зависит от safe-кода в том же модуле, не считается достаточно необычной для того, чтобы заслуживать отдельного комментария каждый раз… придётся считать, кто «как только нашли unsafe, так проверять весь модуль»…Ну, или, на практике, скорее возможен «двухпроходный» алгоритм: проверили безопасность
unsafe-блока, если понять почему он «не экспортирует небезопасность» не удалось — смотрим на весь модуль.Но тут непонятно, сколько умственных усилий стоит выделять на первый проход, перед тем, как переходить ко второму. Я бы «заморачивался по минимуму»: ну вот если прям сходу очевидно, что
unsafe-код ничего ужасного не делает, то принимаем так, если нет — начинаем разбираться с исходниками всего модуля…каждый случай, когда безопасность unsafe-кода обеспечивается инвариантами, которые может разрушить safe-код был отдельно откомментирован.
В примере выше (из raw_vec.rs) unsafe можно без проблем сломать из safe кода, создав MemoryBlock с висячим указателем, вместо того, чтобы брать результат alloc. Но очевидно, что этого в данном случае не происходит.
Тут скорее "каждый случай, когда безопасность unsafe-кода обеспечивается нелокально". А это уже принято комментировать.
Тут скорее «каждый случай, когда безопасность unsafe-кода обеспечивается нелокально».Понятие «локально» где-нибудь документировано?
У меня ровно к этому претензия.
Я считал, что метки
unsafe принято для этого использовать… но оказалось, что это не так. А что принято для этого использовать?Боюсь что только комментарии. Но я ниразу не авторитет по таким вопросам.
Понятие «локально» где-нибудь документировано?
Требуемый инвариант поддерживается кодом в той-же функции. Пойдёт?
А что принято для этого использовать?
В RustBelt используют доказательства корректности.
Но в основном принято изучение Rustonomicon и использование полученных знаний для построения интерфейсов безопасно изолирующих unsafe код, с неформальным доказательством соблюдения нетривиальных инвариантов в комментариях к unsafe блокам.
Таким вот образом. И я очень сильно сомневаюсь, что возможно создать системный язык, в котором блок unsafe будет ограждать окружающий код от всего, что может произойти внутри. Разве что в паре с соответствующим процессором, способным организовать аппаратные анклавы.
Требуемый инвариант поддерживается кодом в той-же функции. Пойдёт?Подошло бы — если был это бы типичный случай.
И, главное, если бы это было бы где-нибудь документировано. Чтобы тем, кто делает иначе можно было говорить не «ты не пропитался духом
Rust — изыди, а ты нарушил такой-то пункт рекомендаций — исправь».И я очень сильно сомневаюсь, что возможно создать системный язык, в котором блок unsafe будет ограждать окружающий код от всего, что может произойти внутри.Так импликация в обратную сторону: если
unsafe-блоки нарушают инварианты языка только временно, внутри себя так, чтобы снаружи они сохранялись — тогда вся программа будет свободна от ошибок определённого класса.Поскольку компилятор нам тут не помощник — должна быть достаточно строгая дисциплина с подробным описанием того, что можно делать, а чего нельзя…
если unsafe-блоки нарушают инварианты языка только временно, внутри себя так, чтобы снаружи они сохранялись — тогда вся программа будет свободна от ошибок определённого класса.
Unsafe блоки не должны нарушать инварианты safe Раста ни в каком случае. Даже временно. Нельзя использовать две &mut ссылки на один объект. Нельзя интерпретировать неинициализированную память как значение переменной, даже если она будет уничтожена до выхода из unsafe блока. Нельзя создавать слайс, если память под него не была аллоцирована каким-то образом. Нельзя создавать ссылку из null_ptr(). И т.д. и т.п.
Unsafe блоки и интерфейс вокруг них предназначены для выражения инвариантов, которые не могут быть выражены в safe Rust или могут быть выражены только с большим оверхэдом (двусвязный список на указателях и двусвязный список на Rc и Weak, например). Временное нарушение таких инвариантов позволительно. А если это не вызывает UB, то и не временное нарушение позволительно — это будет просто логической ошибкой (например, хранение неверной длины двусвязного списка, если она используется только safe кодом).
"Протекание unsafe" — это некорректный unsafe код и/или интерфейс к нему, который приводит к UB при вызовах из safe кода за пределами "границы изоляции unsafe".
Где проходит эта "граница изоляции" и есть ли она вообще, определить формальными методами в общем случае (то есть для произвольного unsafe кода) невозможно (см. теорема Райса). В конкретных случаях строят доказательства (RustBelt) или внимательно проверяют, что вызовы внешнего интерфейса (как мы его сами определили) не приводят к UB.
Так что отметка этой "границы изоляции" синтаксическими маркерами будет играть только декоративную роль и комментарии в этом плане ничем не хуже.
Поскольку компилятор нам тут не помощник — должна быть достаточно строгая дисциплина с подробным описанием того, что можно делать, а чего нельзя…
Да. Я про это писал. Rustonomicon описывает правила написания unsafe кода. В группе RustBelt занимаются созданием формального описания этих правил.
Где проходит эта «граница изоляции» и есть ли она вообще, определить формальными методами в общем случае (то есть для произвольного unsafe кода) невозможно (см. теорема Райса).Именно поэтому эта граница должна быть описана автором кода. В противном случае ревьюер упрётся во всё ту же теорему Райса.
Так что отметка этой «границы изоляции» синтаксическими маркерами будет играть только декоративную роль и комментарии в этом плане ничем не хуже.Хуже. Вот возьмите вот этот пример, о котором уже говорили. Видите там эти комментарии? Вот и я не вижу.
Синтаксические маркеры лучше в том смысле, что компилятор может требовать их наличия — и дальше уже можно жаловаться на то, что их «не там поставили». А комментарии, как бы, писать не требуется — их, как видим, и не пишут.
Да. Я про это писал. Rustonomicon описывает правила написания unsafe кода. В группе RustBelt занимаются созданием формального описания этих правил.После чего в стандартной библиотеке (а уж она-то должна не последними людьми в Rust-сообществе редактироваться) не остаётся в коде ни-че-го.
Хуже. Вот возьмите вот этот пример, о котором уже говорили. Видите там эти комментарии? Вот и я не вижу.
assert!(ptr != null_ptr());
unsafe {
requires_non_null_ptr(ptr);
}Тоже комментарии писать? А это практически эквивалентный код. Теорема Райса она для произвольного кода. Частные случаи могут быть тривиальными.
не остаётся в коде ни-че-го.
Останется. Часть уже верифицировали. Арифметикой, кстати, пользовались задолго до аксиом Пеано и продолжают пользоваться после теоремы Гёделя о неполноте.
Тоже комментарии писать?Ну… есть способ получше:
unsafe {
assert!(ptr != null_ptr());
requires_non_null_ptr(ptr);
}А это практически эквивалентный код.И этот практически эквивалентный код «учит плохому». Посмотрев на это осознать, что правило не «если компилятор тебе мешает, то заткни его, поставив
unsafe», а что-то более сложное — невозможно.Частные случаи могут быть тривиальными.И для тривиальных случаев есть тривиальное же решение.
И в итоге, есть ли какое то правило насколько максимум позволено быть границе изоляции unsafe? один mod или один crate? Как фомально понять осудить автора актикс или оправдать?
trusted-код никак не отделяют, понять что ты что-то сделал неправильно можно уже только когда «буря в стакане воды» начнётся.Грустно это. Уж такую «детскую» ошибку можно было бы и не совершать… но с другой стороны — чего вы хотите от людей, которые уникальную ссылку отмечают словом
mut.Такое ощущение, что CS-наука и IT-индустрия существуют в параллельных мирах: практики с трудом и страданиями в очередной раз доходят до того, что теоретики открыли полвека назад… а теоретики — измеряют то, что практики уже давно посчитали и что им уже даже не очень интересно… интересно — в других отраслях ситуация такая же?
А никак, похоже. Формальных правил нету, библиотеки (в том числе даже стандартная) trusted-код никак не отделяют, понять что ты что-то сделал неправильно можно уже только когда «буря в стакане воды» начнётся.
А вы уверены что такие формальные правила вообще хотя бы теоретически можно сделать, ну, чтобы они во всех случаях работали?
- Традицонный вариант родом из 60х годов прошлого века: никакой
unsafe-код не зависит от инвариантовsafe-кода.
Будет работать? Конечно: во всех операционках он и используется. В крайнем случае весь код окажется помеченunsafe, но очевидно, что любая программа может быть реализована. - Менее традиционный вариант: если инвариант обеспечивается
safe-кодом в той же фукции — про это можно не писать.
Будет работать? Разумеется: по той же причине. - Типичный подход расширений JVM: код в модуле не должен зависеть от инвариантов вне модуля.
Будет работать? Разумеется: в чём вопрос?
Собственно единственный вариант, который мне кажется недопустимым — это то, что сейчас реализовано: код в
unsafe-блоках может зависеть бог-знает-от-чего, это нигде не документировано и нигде не описано и единственный способ узнать о том, что ты что-то сделал «не так» — получить кучу ругани от «настоящих гуру» в issues к твоему проекту.Чем локальнее, тем лучше. Не представляю себе ситуацию, когда требуется протекание unsafe за пределы модуля, причем в безопасном (!) интерфейсе.
Чем локальнее, тем лучше.Вы когда-нибудь детей чему-нибудь учили? Я вас уверяю: если у вас нет жёстких и легко проверяемых критериев, то ребёнок, с лёгкостью неимоверной, «растянет» ваши невнятные принципы — до бесконечности.
А взрослые разработчики, как показывает практика — ничуть не менее (а часто и более) изобретательны.
Не представляю себе ситуацию, когда требуется протекание unsafe за пределы модуля, причем в безопасном (!) интерфейсе.А вот автор Actix — представил. И что теперь делать? Мясник так видит!
И что теперь делать?
Переходить на Arend. Если вы не смогли это доказать, то вы не можете это использовать. Куча народу отсеется.
Т.е. закапывать раст не откопав? :)
Раст надо использовать там, где он опдходит, а именно если вам нужен производительный но-гц язык.
Все языки с мощными системами типов вроде идрисов, арендов и прочих гц-онли. И компилятся годами. Ну и в отличие от хаскелля, они не заморачиваются такими вещами как "быть производительными в рантайме".
Если же вам гц вполне ок, то раст можно закапывать, да. И не откапывать пока вам не понадобятся его трейдофы)
Все языки с мощными системами типов… гц-онлиНет. Ada, D, Swift
Ни один из них не является ЯПом с мощной системой типов.
Раст надо использовать там, где он подходит, а именно если вам нужен производительный но-гц язык.А какая разница — гц или не-гц, если важна просто производительность? Недавно где-то на Хабре прочитал сравнение Джавы и Раста — разница совсем небольшая.
Сейчас не вспомню сразу, где найти сравнение Джавы и Хаскеля…
https://benchmarksgame-team.pages.debian.net/benchmarksgame/fastest/rust-java.html
Почти каждый бенчмарк раст выигрывает в Н раз
Разница гигантская, если говорить не про бенчи на 100 строк, а реальные приложения. Я общался с Николаем Кимом — который автор актикса, типа зачем он его вообще делал и так далее. Так вот, оказалось, что он его делал не потому что захотелось, а потому что сишарп на Azure IoT хоть и работал, но не очень успешно. Так вот, когда они перенесли на раст, они получили прирост в 15 раз. На IO bound задаче.
И это майкрософт, который обладает наибольшей экспертизой по сишарпу в мире (или одни из).
Джава немного пошустрее дотнета, но не в 15 раз даже близко.
Это понятно. Просто в обсуждении актикс было много вопросов мол как, кого, когда, и куда, вежливо посылать. Но формальной стороне вопроса (точнее формализуемой), а именно каковы на самом деле гайдлайны комьюнити по написанию ансейф кода, не озвучивали. Вот в этом и вопрос, а red75prim попытался съехать с этой темы в дебри идрисов и прочей экзотики :)
Гайдлайны автору долго объясняли, но он сопротивлялся.
Если из модуля торчит функция не помеченная как unsafe, но использование которой может привести к UB — то это неправильно.
может где то осталась переписка или блог чей-то? Я понимаю что если взять какую то либу то обычно в одном mod живет одна структура (или максимум еще парочку вспомогательных) и публичный интерфейс к ней. А весь ансейф если он есть то инкапсулирован внутри модуля.
Базовый guideline — здравый смысл, как всегда. И глава 19 раздел 1 Rust Book, которая говорит:
People are fallible, and mistakes will happen, but by requiring these five unsafe operations to be inside blocks annotated with unsafe you’ll know that any errors related to memory safety must be within an unsafe block. Keep unsafe blocks small; you’ll be thankful later when you investigate memory bugs.
To isolate unsafe code as much as possible, it’s best to enclose unsafe code within a safe abstraction and provide a safe API, which we’ll discuss later in the chapter when we examine unsafe functions and methods. Parts of the standard library are implemented as safe abstractions over unsafe code that has been audited. Wrapping unsafe code in a safe abstraction prevents uses of unsafe from leaking out into all the places that you or your users might want to use the functionality implemented with unsafe code, because using a safe abstraction is safe.
Плюс, если человек начинает писать unsafe код менее тривиальный чем использование get_unchecked с предварительной проверкой допустимости индекса ожидается что он почитал Rustonomicon, который как раз про то как работать с unsafe.
А это "обсасывание" правда было? Я вот впервые увидел, как и оригинальное выступление.
В Rust такая ситуация с неопределенным поведением в арифметике невозможна в принципе.но функция одинаково транслируется в ассемблер, не?
И C++, и Rust сгенерировали одинаковый выхлоп ассемблера, оба добавили push rbx для выравнивания стека. Q.E.D.не одинаковый, rust-версия идет на стек
При меньших трудозатратах Rust генерирует меньше ассемблера*в конкретном случае.
Ну а само использование сишной библиотеки занимает буквально одну строчку в вашем конфиге:*при условии что библиотеку добавили в репозиторий, ну и что обертка без багов…
По статистике Microsoft, 70% уязвимостей связаны с нарушениями безопасности доступа к памяти и с другими классами ошибок, от которых Rust предотвращает ещё на этапе компиляциивы если оспариваете утверждение про то, что ошибки в основном в сишном коде а не в плюсовом, не надо приводить общую статистику microsoft как доказательство что ошибок в rust нет. Как минимум потому, что утверждение про другое, а MS вряд ли успели набрать статистически значимую экспертизу в rust
А они используют сишные функции… корректность которых не доказана.
Здесь и сейчас — да. А завтра — кто его знает. C++ не гарантирует, что на другом компиляторе или другой версией того же компилятора код будет такой же или хотя бы вести себя так же. В этом и суть претензий, а вы даже не пытаетесь их понять, судя по аргументам.
но функция одинаково транслируется в ассемблер, не?
Это до момента пока она не заинлайнится и С++ компилятор не увидит, что у вас там UB из за переполнения. В таком случае он вправе весь ваш код соптимизировать в ноль.
То есть вы считаете нормой, что перемножив 46341 в Rust в релизе вы получите -2147479015 а не аналог исключения. Это ничуть не безопаснее.
> Миф №2. Плюсы Rust только в анализе времени жизни объектов.
> Это заявление ложно, так как безопасное подмножество Rust защищает от ошибок, связанных с многопоточностью
В Rust без вских unsafe можно получить deadlock doc.rust-lang.org/std/sync/struct.Mutex.html
Основная причина — невозможность выразить необходимое в системе типов Rust. Поэтому да — только lifetime (что включает в себя немного гонок, и выстрелов по памяти)
> Миф №3. Вызовы функций в Rust бездумно трогают память.
Выше сравнение по ссылке godbolt.org/z/C5ADqM — неверное. Если вы сравниваетесь с отключенными проверками в Rust, отключайте их и для C++ godbolt.org/z/fh8_U2
> Миф №4. Rust медленнее C++.
> Складывается впечатление, что весь этот анализ ассемблерного выхлопа был нужен лишь для того, чтобы сказать, что больше асма → медленнее язык.
Прочитайте пожалуйста внимательнее ассемблер. Это код без условных переходов, а инструкции наподобие `mov dword ptr [rdi], ecx` трогают оперативную память. Пожалуйста не приписывайте мне ваши неверные выводы.
> Миф №5. C → С++ — noop, C → Rust — PAIN!!!
Да, штатный пакетный менеджер помогает замять множество проблем. Первоначальная проблема от этого остаётся.
> Миф №6. unsafe отключает все проверки Rust.
Забавно, что в другом разделе документации имеется неполный список UB doc.rust-lang.org/reference/behavior-considered-undefined.html, который практически полностью совпадает с C++ списком. Обратите внимание на термин «unsound», подразумевающий что код после unsafe может взорваться в любом месте. Так что да, unsafe все проверки убивает.
> Миф №7. Rust не поможет с сишными библиотеками.
Только вот мало какая С библиотека нынче поставляется с LTO. Так что накладные расходы пока есть. Ну и про unsafe см выше, вы не можете использовать C без unsafe.
> Миф №8. Безопасность Rust не доказана.
В выступлении эта часть была про Хаскель :) Но процитируйте пожалуйста полностью эту часть выступления, вы парировали только треть (да и то не до конца честно, см UB в Mutex).
> Заключение
> Однако от признаных экспертов я ожидаю взвешенного освещения ситуации, которое, как минимум, не содержит грубых фактических ошибок.
К несчастью в вашем ответе грубых ошибок по паре в каждом пункте, нет убедительных опровержений, а работало над ответом аж 3 человека. Попробуйте подойти более ответственно и честно к сравнению.
На каждой ошибке я не останавливался, попробуйте найти их сами.
P.S.: Ваш заголовок вводит в заблуждение. Никаких замеров в статье нет, нигде в выступлении такое не говорилось, Яндекс (насколько мне известно) вы не представляете. Получается очень некрасиво с вашей стороны
То есть вы считаете нормой, что перемножив 46341 в Rust в релизе вы получите -2147479015 а не аналог исключения. Это ничуть не безопаснее.
Считаю это безопаснее, так как отсутствует UB. Мне в личку уже скинули пример с observable UB с использованием square.
В Rust без вских unsafe можно получить deadlock
Который не является неопределенным поведением.
Если вы сравниваетесь с отключенными проверками в Rust, отключайте их и для C++ godbolt.org/z/fh8_U2
Ну вот вы опять рождаете UB на трёх строчках кода. В Rust UB не будет даже без отключенных проверок.
Пожалуйста не приписывайте мне ваши неверные выводы.
На протяжении всего доклада вы говорите, что из-за этого Раст медленнее. Бенчмарки в студию.
Обратите внимание на термин «unsound», подразумевающий что код после unsafe может взорваться в любом месте. Так что да, unsafe все проверки убивает.
Обратите внимание на "If". Ничего не отключается. Что и подтверждается в пейпере, который я вам несколько раз пересылал.
Только вот мало какая С библиотека нынче поставляется с LTO. Так что накладные расходы пока есть.
Накладные расходы, одинаковые и для C++.
В выступлении эта часть была про Хаскель :)
Под заголовком слайда "Программа написанная на языке Rust X не содержит ошибок" в топике про Rust и перед тем как вы перешли на C++ vs Go? Ок..
Ваш заголовок вводит в заблуждение. Никаких замеров в статье нет,
Ну так сделайте замеры. Будьте объективны.
* не меняйте тему обсуждения. Вы подменили «Плюсы Rust только в анализе времени жизни объектов» на «deadlock — это не неопределённое поведение, всё хорошо». Или вы так ненавязчиво согласились, что Rust безопасен только для lifetime?
* Не возлагайте бремя доказательства на другого. Я в выступлении показал неэффективность. Если хотите доказать, что обращения к памяти бесплатны — доказывайте.
* не делайте необоснованных утверждений, наподобие «Накладные расходы, одинаковые и для C++.». Calling convention в C++ и Rust разный, Rust вынужден перекладывать больше параметров на стеке (да, опять трогать память). Посмотрите примеры, я их где-то в соседних выступлениях приводил.
> Под заголовком слайда «Программа написанная на языке
И правда… Хм, когда-то я задумывал этот слайд в ответ Хаскелистам, про то что написал там Rust уж и забыл :)
Ваши тексты вообще пестрят той самой софистикой, отказаться от которой вы предлагаете Роману, как-то не хорошо. Вообще, это сквозит во всех сообщениях, но обращу внимание например на вот эту цитату
- не меняйте тему обсуждения. Вы подменили «Плюсы Rust только в анализе времени жизни объектов» на «deadlock — это не неопределённое поведение, всё хорошо». Или вы так ненавязчиво согласились, что Rust безопасен только для lifetime?
Это так называемое "а вы перестали пить конъяк по утрам?". То есть по-вашему, если раст не детектирует дедлок, то он проверяет только лайфтаймы. Надо ли говорить, что из посылки совершенно не следует вывод?
Давайте распишу по шагам, коль вы тут увидели уловку:
>> Миф №2. Плюсы Rust только в анализе времени жизни объектов.
> Это заявление ложно, так как безопасное подмножество Rust защищает от ошибок, связанных с многопоточностью, гонками данных и выстрелами по памяти.
Итак, с многопоточностью безопасное подмножество Rust ошибку не нашло, значит Rust не защищает от ошибок с многопоточностью.
Бесконечная рекурсия на простом примере тоже не очень отработала. Спишем на багу в LLVM. Однако, на более сложных примерах LLVM не справится с детектированием бесконечных рекурсий (см. проблема остановки) и во время работы приложения будет выеден весь стек и будет выстрел по памяти в безопасном подмножестве Rust. То есть и с памятью Rust не помог.
Что остаётся у Rust из преимуществ, по сравнению с C++?
Возможно автор имел в виду «Это заявление ложно, так как безопасное подмножество Rust частично защищает от ошибок, связанных с многопоточностью, гонками данных и выстрелами по памяти.». Но в статье то написано не это, люди воспринимают Rust как 100% защиту от багов. И, к несчастью, подобное введение в заблуждение в подавляющем большинстве статей про Rust.
Но в статье то написано не это, люди воспринимают Rust как 100% защиту от багов.
я согласен, что Rust не является 100% защитой от 100% багов, но давайте примем, что от определенного типа багов Rust спасает :-) И это лучше, чем полное отсутствие… правил и ограничений, как в С++ — где даже линтеры и статические анализаторы не всегда помогают.
А где вы эти толпы видели? Или было какое-то исследование?
От сегфолтов он, внезапно, вполне себе защищает в 99% случаях, это уже весьма неплохо. А придираться к целочисленным переполнениям и считать их чем-то ну прямо самым важным, игнорируя гигантский ворох проблем — это ну чистейшей воды манипуляция.
Кстати, никто тут в холиворе не упомянул такое важное и фундаментальное преимущество Раста, как алгебраические типы данных, которые часто очень заметно и ощутимо меняют подходы к архитектуре приложений и во многих случаях дают прямо существенный профит как к удобству, так и к безопасности.
Отстрелить себе ноги, как в случае с std::optional или std::variant не позволит система типов. Сама по себе концепция null safety позволяет жить вот прямо заметно спокойнее и не переживать из за проверок указателей на null.
Да и отстрел ног при помощи move семантики тоже ведь весьма распространенное развлечение в плюсовом коде.
Я уже молчу, что и в случае ADT и в случае move семантики у Раста больше гарантий и поэтому фронтенд спокойно может проводить более агрессивные оптимизации.
От сегфолтов он, внезапно, вполне себе защищает в 99% случаях, это уже весьма неплохоНеа. Вот в показательной статье мало того, что работающую программу сортировки на Расте не осилили — так при отладке я посмотрел как прекрасно падает по переполнению стека или по выходе за границу массива (тут конечно не сегфолт, а управляемая паника)
От переполнения стека увы никакой язык не поможет, это фундаментальная проблема, но опять же stack overflow хотя бы можно детектить на уровне операционки. А во втором случае ведь произошла паника, а не сегфолт, разница прямо скажем принципиальная.
Натолкнуло на мысль, точнее такой вопрос просто для общего развития: Есть ли какое то ограничение у того же idris или coq или еще чего-то (нужное подчеркнуть) на какой то "класс" математических доказательств, которые можно с помощью них доказать? Т.е. если я вот сел с листиком у ручкой и что-то доказал, гарантировано ли я смогу перенести это в формализм языков "программирования"?
Я так понимаю вопрос в аксиоматике, если вы доказали утверждение в рамках обычной формальной логики, то изоморфизм Карри-Говарда отвечает на жтот вопрос положительно.
На самом деле всё очень просто. Попробуйте подоказывать простейшие теоремы из разряда (a => b => c) => (a => b) => (a => c) или a = !!a на том же аренде, там вы за полчаса поймете 90% того что нужно понимать.
Safety в контексте Rust — это отсутствие весьма специфического набора поведений, в которое дедлок не входит. Более того, по этой же ссылке он приведён как пример того, что программа на safe Rust может делать.
Но в статье то написано не это, люди воспринимают Rust как 100% защиту от багов. И, к несчастью, подобное введение в заблуждение в подавляющем большинстве статей про Rust.
В статье написано про 100% защиту от определенного класса проблем. Например, раст не защищает от утечек памяти (пресловутая мантра "leaks are safe"). В частности, как пишет одно из основных обсуждений на тему:
Rust provides safety from out-of-bounds reads/writes, use-after-free, null pointer dereference and data races.
Или, как говорит сама документация:
Rust is otherwise quite permissive with respect to other dubious operations. Rust considers it "safe" to:
- Deadlock
- Have a race condition
- Leak memory
- Fail to call destructors
- Overflow integers
- Abort the program
- Delete the production database
Ну так, это первая часть определения, но вот некоторые почему-то думают, что Rust защищает и от второй части, а опровергая это утверждение заодно утверждают, что Rust не бережет и от первой части.
Такая вот казуистика.
Например, гонка данных это ведь не тоже самое, что гонка условий, второй вид гонки невозможно задетектить ибо проблема останова, по сути condition race это вид логической ошибки.
Rust provides safety from… and data races.
Rust considers it «safe» to: Deadlock, Have a race conditionээм
Считаю это безопаснее, так как отсутствует UB. Мне в личку уже скинули пример с observable UB с использованием square.
В безопасности есть такое понятие, как безопасное состояние. Оно означает, система должна обнаружить ошибку и перевести её в безопасное состояние. Т. Е. основной посыл, что само наличие ошибки не является фейлом, главное чтобы ошибка была бнаружена. Поэтому с точки зрения безопасности тут лажа в обоих случаях.
А разве в cpp не так же?
В C++ вы наблюдаете неопределённое поведение, которое случайно похоже на поведение в Rust.
Скомпилируйте и запустите с UBSAN :)
Именно так я и делал. В статье есть пример:
runtime error: signed integer overflow: 46341 * 46341 cannot be represented in type 'int'
runtime error: signed integer overflow: -46341 * -46341 cannot be represented in type 'int'Разница в том, что в случае UB проблема молча есть или нет, а в случае паники у тебя сразу есть сигнал о том, что проблема есть.
Разница есть, поскольку это поведение может поменяться в любой момент, даже без обновления компилятора в самый неожиданный момент (например при правке кода совершенно в другом месте). Вот наглядный пример того, что может пойти не так с UB.
Ведь если ответ не правльный, какая мне разница UB это или не UB.
Потому что UB по сути даёт карт-бланш компилятору изменять ваш код как ему заблагорассудится. И эти трансформации могут быть чрезвычайно неинтуитивными. Если вам повезёт, то вы всего-лишь получите "неправильный" ответ, если нет, то гейзенбаг, который вам придётся отлавливать в 4 часа утра в обнимку с дебагером.
Заслуживающий своего имени гейзенбаг под дебагером не ловится. Вот, говорят, теорема Ферма верна тогда и только тогда, когда есть отладочная печать.
Я хоть и не автор статьи но у меня тоже есть что сказать по этому поводу…
>> Миф №1. Арифметика в Rust ничуть не безопасней C++
> То есть вы считаете нормой, что перемножив 46341 в Rust в релизе вы получите -2147479015 а не аналог исключения. Это ничуть не безопаснее.
Rust отключает некоторые проверки в release-е, но в debug-е он вызывает завершение программы через вызов макроса panic! при этом он говорит где была задетектирована ошибка, со строкой в файле и даже backtrace-ом
В release-е компилятор конечно же некоторые проверки убирает, но паника все равно остается для того кода на производительность которого это не сильно влияет или это не преведет к SIGSEGV (Segmentation Fault)
>> Миф №2. Плюсы Rust только в анализе времени жизни объектов.
>> Это заявление ложно, так как безопасное подмножество Rust защищает от ошибок, связанных с многопоточностью
> В Rust без вских unsafe можно получить deadlock doc.rust-lang.org/std/sync/struct.Mutex.html
> Основная причина — невозможность выразить необходимое в системе типов Rust. Поэтому да — только lifetime (что включает в себя немного гонок, и выстрелов по памяти)
Deadlock является проблемой программиста, так как компилятор не может проверить семантику программы, но все что компилятор может проверить статическими методами он делает
>> Миф №4. Rust медленнее C++.
>> Складывается впечатление, что весь этот анализ ассемблерного выхлопа был нужен лишь для того, чтобы сказать, что больше асма → медленнее язык.
>> Миф №5. C → С++ — noop, C → Rust — PAIN!!!
> Да, штатный пакетный менеджер помогает замять множество проблем. Первоначальная проблема от этого остаётся.
По моему все работает также само как и в C++… Также есть ключевое слово extern… ?!
doc.rust-lang.org/std/keyword.extern.html
doc.rust-lang.org/nomicon/ffi.html
Единственное что для C/C++ int, long long нужно использовать типы из ffi
>> Миф №6. unsafe отключает все проверки Rust.
> Забавно, что в другом разделе документации имеется неполный список UB doc.rust-lang.org/reference/behavior-considered-undefined.html, который практически полностью совпадает с C++ списком. Обратите внимание на термин «unsound», подразумевающий что код после unsafe может взорваться в любом месте. Так что да, unsafe все проверки убивает.
Проверки не убираются…
В статье описано что разрешено делать в unsafe секции
>> Миф №7. Rust не поможет с сишными библиотеками.
> Только вот мало какая С библиотека нынче поставляется с LTO. Так что накладные расходы пока есть. Ну и про unsafe см выше, вы не можете использовать C без unsafe.
Интересно как?
>> Миф №8. Безопасность Rust не доказана.
> В выступлении эта часть была про Хаскель :) Но процитируйте пожалуйста полностью эту часть выступления, вы парировали только треть (да и то не до конца честно, см UB в Mutex).
Да она не доказана, но это все равно лучше чем дает С++ :)
Я бы почитал, какие оптимизации не умеет Rust, особенно с учётом того, что в основе Rust лежит LLVM — тот же самый бэкенд, что и у Clang. Rust «бесплатно» получил и разделяет с C++ большую часть независящих от языка трансформаций кода и оптимизаций
Сильное утверждение. Что там насчёт оптимизаций, которые есть только в GCC/ICC/AOCC. Вы же не будете говорить, что в них смысла уже нет, правда? Бенчмарки между ними и LLVM-based (хоть AOCC и тоже LLVM-based)смотрите где вашей душе угодно.
Пример с flate2 примечателен тем, что в начале своего существования этот крейт использовал сишную библиотеку miniz, написанную на C, но со временем сообщество переписало сишный код на Rust. И flate2 стал работать быстрее.
Всегда любил такие примеры, которые растоманы регулярно приводят. Они берут программу, переписывают её с нуля на Rust и потом говорят, что она работает быстрее. Никто правда не говорит, что если её переписать с нуля на том же С или C++, то она тоже будет работать быстрее, но это мелочи, конечно же.
Про упоминание наличия пакетного менеджера — да, хорошо. Только вот и в С++ пакетными менеджерами пользуются :)
Про статистику от Microsoft уже выше откомментировали.
Сначала маленькая заметка
Так откуда взялись эти "лишние" инструкции, которые трогают память? Соглашение о вызове функции x86-64 требует, чтобы стек был выравнен до 16 байт, инструкция call кладёт 8-байтовый адрес возврата на стек, что ломает выравнивание.
x64 API не требует выравнивания стека на 16, это 64-битная платформа, стек 64-битный. Здесь мы видим пару push/pop не для выравнивания стека (для этого была бы арифметика с rsp), а для сохранения регистра rbx, который вызываемая функция может менять.
Del
Именно что требует, не вводите в оману.
Документ «System V Application Binary Interface AMD64 Architecture Processor Supplement» — стандарт соглашения по вызову для Unix, раздел 3.2.2:
The end of the input argument area shall be aligned on a 16 (32, if __m256 is passed on stack) byte boundary. In other words, the value (%rsp + 8) is always a multiple of 16 (32) when control is transferred to the function entry point. The stack pointer, %rsp, always points to the end of the latest allocated stack frame.
Компиляция, судя по регистрам, была именно юниксовая.
Зачем такое требование — по известным мне данным, для правильного выравнивания XMM-данных.
И раз уж тут собрался цвет Си++/Раст сообщества давайте разберем тот давнишний пример из рассказа Антона на Си++Раша — https://godbolt.org/z/keDEZG
Я бы ожидал видеть идентичный код, сгенерированным одинаковым LLVM бекэндом, и код почти идентичен, но не совсем. В Расте зачем-то RAX спилят в стек и в конце вытаскивают в RCX. Причем этого не делается, если убрать цикл. Кажется, что тут какой-то Rust-специфик баг в годогенераторе LLVM, но не понимаю, чего вообще тут хотят добиться этим спиллингом регистра? (Так как ABI Си-шных функций одно, на одной платформе, и делать чего-то дополнительного, относительно Си++ не надо)
Что я упускаю?
А почему у раста символ с external linkage, да и еще и с сишным интерфейсом (pub extern"C"), а у примера с плюсами нет?
Хм, а в C++ варианте шесть обращений к памяти в виде mov регистр, память или mov память, регистр, в то время как в Rust только пять плюс push/pop. Не знаю будет ли от этого быстрее C++ или Rust.
Вы серьезно этим собираетесь подвинуть плюсы, а тем более Си?Вам не кажется что в вашей же фразе содержится ответ? C++ — гораздо менее лаконичен, чем C. Несмотря на то, что
S s= new S(); короче, чем "struct S s= malloc(sizeof s); в реальных программах C++ более многословен… и даже сам ваш вопрос это подтверждает.Так что… не просто собираются, но и подвинут. Карма такая.
Я вот до сих пор, когда смотрю на программы на Pascal или Ada… душа радуется. Красиво так и читаемо. А вот уже C, C++… ужас… но они вытеснили Pascal — и тут то же самое будет. А жаль. Мне очень нравится идеология Rust, но вот его вырвиглазный синтаксис… это качмар.
Но после истерики Полухина и, особоенно, ZaMaZaN4iK стало ясно: да, пора, увы, пора. Как раз выходные, можно поставить Rust и начать играться…
Ко всему возможно привыкнуть. Синтаксис это настолько ничтожная часть языка, что на неё нет смысла обращать внимание.
Тем не менее, из-за того, что в C/C++ нет ключевого слова function, язык из-за этого поимел кучу проблем, например, когда имеется неоднозначность между объявлением функции и вызовом конструктора. Ну или "красивые" указатели на функции.
void (*signal(int signum, void (*)(int signum)))(int signum); в C++11 теперь можно auto signal(int signum, auto (*)(int signum)->void)->auto(*)(int signum)->void; написать.Да, многословно, но хотя бы нет ребуса в духе «поди разберись где тут что».
Я как-то в том году заглядывал на форум оберонщиков (примерно тот же уровень популярности) — последнее сообщение было черт знает когда, то ли в Обероне нет проблем вообще, то ли…
Вашу статью про адское программирование для МК я читал, и конечно встроенные контракты меня тоже впечатляют (жаль в плюсы они пока не заехали), но, как ни печально, любое умение надо уметь продавать, а куда это продавать — большой вопрос. Только в качестве упражнения для ума.
Ada — я ещё понял бы, но Паскаль с его кривыми begin-end? Дело вкуса, конечно… и связывать это с лаконичностью как-то странно. Наоборот, введение всех этих var, хотя и улучшает грамматику, требует лишних нажатий (я четырьмя руками «за» за них, но факт не отменить).
???
Тут такое дело. Ада — паскалеподобный язык, в нем такие же "кривые" begin-end блоки
Тут такое дело… вы просто не в курсе.
Modula, Ada и как минимум примкнувший к ним Ruby:
if условие then <-- не нужно лишнего begin
тело1.1
;
тело1.2
...
end <-- обязательно
А теперь в Паскале:
if условие then
тело1.1
но обязательно:
if условие then
begin
тело1.1
;
тело1.2
end
(я выделил ';' потому что он разделитель, а не завершитель)
Скобки begin-end в Паскале/Delphi/etc. — необязательны, но надо не забыть поставить их, как только тело переходит из одного утверждения в несколько. А когда их ставишь — появляется лишнее begin.
Когда я учил Паскалю подопечных школьников, этой кривофиче было очень тяжело обучать — постоянные грабли, пока не наработалась привычка, а нарабатывалась она тяжелее почти всего остального.
Вирт в потомках (как Modula) это исправил, и в Ada пошло исправленное, но как обычно в IT — выживает не лучшее, а первое минимально пригодное.
В C с потомками та же кривизна — и только новое поколение (Go, Swift...) начало это фиксить.
Когда я учил Паскалю подопечных школьников, этой кривофиче было очень тяжело обучать — постоянные граблиВот у нас в школе никто никаких граблей никогда не видел. Просто потому что никому не говорили о том, что в
if или while можно опускать begin/end. А «особо продвинутым» объясняли примерно «да, в языке есть много фич, которые не нужно использовать — вы нашли одну из них».И всё. И нет никаких проблем. Объяснение понималось всем классом «с первого раза» и даже «продвинутые» легко принимали «правила игры».
Уж не знаю почему вы ваших школьников не любили, честно.
Это не я «не любил», это стандартные учебники, с последствиями которых приходилось бороться. И прошу не выдвигать подобных домыслов с потолка.
Но сама необходимость тратить лишние силы на неиспользуемые фичи показывает качество языка. Только Вирт осилил признать ошибки и исправить в новых языках, а те, кто зачем-то именно Паскаль отправил в продуктив и в обучение — не смогли.
Это не я «не любил», это стандартные учебники.К сожалению почти все современные учебники написаны людьми, которые явно либо недолюбливают, либо прямо ненавидят детей. Учебники по программированию — не исключение. Это, кстати, не только в России так. Помните «Отбор учебников по обложкам» у Фейнмана?
Так что все учителя, которые любят предмет (а у нас их в школе было немало) писали свои листочки и раздавали их.
А использовать стандартные учебники — это как раз и значит не любить детей, увы.
А указатели? Казалось бы — какая разница, писать
p^ или *p? А вот… есть разница. Потому что когда у вас есть *p, но a[b] и a.b, то синтаксис превращается «в адъ» (и появляется пресловутая ->).А так… ну да, Pascal не идеален, Ada не идеальна, C++ уж совсем далёк от идеала… но почему-то в области синтаксиса популярные изыки движутся от простых и понятных к «наворочанным» и запутанным… Rust не исключение.
Наоборот, введение всех этих var, хотя и улучшает грамматику, требует лишних нажатий (я четырьмя руками «за» за них, но факт не отменить).Begin-end у меня ставится по месту или на блок одним хоткеем: Ctrl+Shift+B уже лет 7 или больше. Никто уже очень давно руками begin/end не пишет. Вообще автоматизаций именно набора кода в Дефли и экспертах — десятки, если не сотни:
www.tdelphiblog.com/p/experts.html
А при чём тут необходимость писать руками?
Что заставит вас, имея код с одним предложением в теле цикла и без begin-end, гарантированно вспомнить, что надо поставить скобки прежде чем добавлять туда же второе предложение? Опыт показывает, что промахнуться и забыть их поставить — типовая проблема.
А если вы ставите эти скобки на любой блок, даже если в нём заведомо одно предложение, то, значит, все begin — лишние и без них можно было спокойно обойтись.
Опыт показывает, что промахнуться и забыть их поставить — типовая проблема.Я тут поспрашивал у нас и в соседних командах — никто не смог вспомнить ни одного случая.
Что заставит вас, имея код с одним предложением в теле цикла и без begin-end, гарантированно вспомнить, что надо поставить скобки прежде чем добавлять туда же второе предложение?Тот факт, что до того, как вы это сделаете кто-нибудь уже добавит
begin/end?Да, в языках типа Pascal или C++, где закрывающая скобка опциональна не нужно пользоваться этой ошибкой синтаксиса. И всё. И нет проблем. Просто ставьте
begin/end всегда — и будет вам счастье.Благо код сейчас редко кто печатает, а стоимостью флешки, на которой будет лишние несколько килобайт (или мегабайт) кода — можно пренебречь.
А если вы ставите эти скобки на любой блок, даже если в нём заведомо одно предложение, то, значит, все begin — лишние и без них можно было спокойно обойтись.Конечно можно было бы. Но пока Algol, Pascal и 40 Oberon'ов дробили базу кода — C и C++ её наращивали. И кончилось тем, что C/C++ стали мейнстримом, а Pascal этот статус потерял.
В некоторых случаях несовместимые измнения в языке — полезны, но когда это делается из-за малочей типа
begin/end…А у нас бывало неоднократно, по таким же отзывам. Может, потому, что программисты не звёздные, а обычные. Может, потому, что в вашем опросе никто не захотел признаться в таком позоре. Но случаи бывали и у меня на глазах. Так что я буду верить своим данным.
> Конечно можно было бы. Но пока Algol, Pascal и 40 Oberon'ов дробили базу кода — C и C++ её наращивали. И кончилось тем, что C/C++ стали мейнстримом, а Pascal этот статус потерял.
Потеря Паскалем первенства не связана с Обероном или чем-то подобным.
Может, потому, что программисты не звёздные, а обычные.А может быть потому, что у вас не принято просто ставить «забытые скобочки»?
Всё с этого ничинается: если у вас нет ни цилов ни, ни условий с однострочниками без фигурных скобочек — то вы не будете делать таких ошибок. А не будет их только тогда, когда с ними борются «всем миром».
Потеря Паскалем первенства не связана с Обероном или чем-то подобным.Связана-связана. В 80е, когда C только-только набирал библиотеки — на Pascal была уже куча всего. Вспомните: macOS была изначально на Pascal написана, ARX, даже Windows в 1983м (но к 1985му они уже на C перебрались).
Но регулярные (то есть неоднократные) переходы с потерей всей базы накопленного кода (Modula-2, Modula-3, Oberon и так далее)… добром не кончились.
На C++ можно было использовать старые, проверенные, библиотеки… и новые возможности. ALGOL-векта, увы, такой возможности не давала: либо новые языки и новые фичи… либо старые библиотеки.
В разных местах была разная полиси. Где не было жёсткой полиси их ставить всегда, от слова «совсем» — там нарывались. Где была — не нарывались. Логично же :)
На текущей работе мы этому обучили uncrustify (то ещё чудо без перьев, но сменить на что-то другое отдел пока не осилил) — по крайней мере прогон перед коммитом ставит скобки и выравнивает, так что визуально в коде можно найти проблемы (никто не нарвётся на висячий else).
> Но регулярные (то есть неоднократные) переходы с потерей всей базы накопленного кода (Modula-2, Modula-3, Oberon и так далее)… добром не кончились.
Не было этого перехода у тех, кто что-то значил в индустрии. Вирт себе витал в башне из слоновой кости, а индустрия пошла своим путём, заоссифицировав его ранние ошибки.
Паскаль тут начал дохнуть по внутренним причинам — он не был языком, допускавшим свободное хакерство, где хотелось тогдашним программистам, в отличие от C. Это сейчас требуют противоположного от языка… а тогда или пиши на своём диалекте (как у Борланда), или теряй переносимость. Модула для этого не требовалась, Паскаля хватило.
заоссифицировав?
Я знаю только слово fossile — окаменелость
Слово, например, любимо адептами QUIC в доказательстве, что TCP уже не исправить.
Не было этого перехода у тех, кто что-то значил в индустрии. Вирт себе витал в башне из слоновой кости, а индустрия пошла своим путём, заоссифицировав его ранние ошибки.Мне кажется, что мы говорим плюс-минус об одном и том же. Фишка в том, что ни ISO 7185:1983, ни ISO/IEC 10206:1990 толком не поддерживаются ни одним популярным компилятором языка Pascal, а более новые фичи — уже и совсем не стандартизованы. В то же время в мире C ISO/IEC 9899:1990 явился вехой, которую, так или иначе стремились поддержать все разработчики. И ISO/IEC 14882:1998 — тоже (хотя некоторым потребовалось несколько лет).
Паскаль тут начал дохнуть по внутренним причинам — он не был языком, допускавшим свободное хакерство, где хотелось тогдашним программистам, в отличие от C. Это сейчас требуют противоположного от языка… а тогда или пиши на своём диалекте (как у Борланда), или теряй переносимость. Модула для этого не требовалась, Паскаля хватило.
То есть в мире «Algol/Pascal/Modula-2/далее везде» царили центробежные силы, а в мире C/C++ — их успешно подавляли.
Почему так случилось — можно спорить, но мне кажется что причины появления бесчисленных несовместимых диалектов Pascal и 40 Oberon'ов — одна и те же: всем наплевать на стандарт и совместную разработку. А вопрос «могли ли эти тенденции уничтожить Pascal если бы все создаваемые языки назывались бы <что-нибудь> Pascal, а не Modula-2 и Oberon» — вопрос философский. Я его даже обсуждать не хочу, это вообще дело десятое.
Но регулярные (то есть неоднократные) переходы с потерей всей базы накопленного кода (Modula-2, Modula-3, Oberon и так далее)… добром не кончились.
На C++ можно было использовать старые, проверенные, библиотеки… и новые возможности. ALGOL-векта, увы, такой возможности не давала: либо новые языки и новые фичи… либо старые библиотеки.
Перечисление «через запятую» создаёт некий мираж, поэтому привожу генеалогическое дерево:
Паскаль --} Модула-2 --} Оберон --} Оберон-2 --} Component Pascal
|
+--} Модула-3
Давайте ограничимся «вектором развития» Pascal to Modula-2 to Modula-3.
Впрочем, есть и конвертер Pascal to CP. А так же, p2ada.
В комплекте DECWRL Modula-2 шёл конвертер с Berkeley Pascal.
Существует и m2tom3.
(
Про Modula-3 и проверенные библиотеки: 1) SWIG 2) m3sleep, как образец
)
Можно ещё вспомнить про семейство компиляторов TopSpeed.
Т.е. множество фактов противоречат теории.
Давайте ограничимся «вектором развития» Pascal to Modula-2 to Modula-3.А ещё есть 2to3.
Впрочем, есть и конвертер Pascal to CP. А так же, p2ada.
Да, это язык «из совсем другой оперы» — но он как раз показывает как «усмешно» происходит «переход через конвертор»: полный отказ от развития «старого» языка, 10 лет пропаганды и непрерывных усилий… и только сейчас люди начали задумывается об уходе с Python2 (у нас в проекте куча скриптов на Python2 и особо как-то их никто конвертировать не стремится).
Или посмотрите на переход с C на C++. Там даже и конвертор-то не нужен, только код немного «подрихтовать» на промежуточный период, чтобы он был как валидным C кодом, так и валидным C++ кодом, но… разговоры про перевод GCC на C++ начались в 2008м году. Это на язык, появившийся в 1985м и стандартизованном в 1998м! Тоже, фактически, 10 лет.
Можно ещё вспомнить про семейство компиляторов TopSpeed.Да, красивая была концепция. Кстати, у кого-нибудь бинарники есть? А то я про них только в книжках читал. Кроме шуток — мне итересно.
Но, в любом случае для того, чтобы люди с этого всего дурдома не сбежали нужен не разовый конвертор, а вот именно, такой вот подход, да. Когда на протяжении десятилетий вы можете писать на двух языках одновременно.
Потому что в реальном (а не академическом) мире есть такая штука, как техподдержка. 18 лет продаж Windows 3.11 — это, конечно, исключение, но 5-10 лет поддержки старых ваерсий — во времена вот этой вот всей вакханалии было нормой.
И, как вы понимаете, никто не будет переписывать (или даже 'автоматически конвертировать") старый код без крайней необходимости, пока какая-то его версия ещё поддерживается.
Вот писать новый (на другом языке или новой версии того же языка) — легко… если можно этот код смешивать в одном проекте со старым.
Так что, увы… единственная попытка, которую можно защитать — это да, TopSpeed. Очень инетересная, теоретически, попытка, но судя по тому как мало от неё сохранилось… она не была особенно популярной.
Интересно, кстати, что сегодня ситуация немного поменялась. Windows 7, выпущенная всего-то 10 лет назад — уже уходит в историю и до 18 лет явно не дотянет. А Windows 10 — так и вообще каждые два года одновляется (и то же самое с Android). Так что время, в течении которого вам нужно поддерживать код на двух языках (или двух версиях одного языка) — стало поменьше. Но всё равно, подход flag day, разовая конвертация, извините — не канает. Разработчики языков, которые реально претендуют на какую-то популярность — это прекрасно понимают. Вот — хороший пост от разработчиков Rust.
P.S. Я, кстати, не могу со 100% уверенностью сказать, что моя теория верна. В «социальных науках» эксперименты ставить сложно. Но факты (весьма и весьма и весьма немаленькую популярность потомков ALGOL в 1980е и резкое падение оной в 1990е) — моя теория объясняет. Так что если у вас есть другая, альтернативная, она их должна объяснять тоже. Только, пожалуйста, не «языки семейства ALGOL ушли со сцены и люди массово перебрались на языки с C-подобным синтаксисом, потому что закрывающая фигурная скобка выглядит красивее, чем слово
end»… Хотя PHP, конечно позволяет использовать if/else/endif, но есть подозрение, что он всё-таки выехал на чём-то ином, чем на привлечении одновременно сторонников ALGOL и C++. В конце-концов людей стонущих об ужасном синтаксисе Rust много (я, в том числе), но и обдумыващих переход на него — не меньше (я, в том числе).Windows 10 — так и вообще каждые два года обновляетсяКаждые полгода…
Заодно уж, «языки семейства ALGOL» включают в себя и Си. ( Да, да: из песни слова не выкинешь).
Т.к. Си точно не разновидность Fortran, COBOL или Lisp, то остаётся только один вариант ( и не только поэтому).
Естественно, от такого родственника все отрекаются. Даже создатели BCPL; из него забыли взять ELSIF, кстати.
)
закрывающая фигурная скобка выглядит красивее, чем слово endУгадайте ( ради интереса), что было ( опционально) в Паскале для БЭСМ вместо begin end.
Когда на протяжении десятилетий вы можете писать на двух языках одновременно.
Двуязычные системы не редкость, например:
XDS Modula-2/Oberon-2
Modula-3, фактически, тоже: там Си и собственно M3.
И раз уж у нас вечер загадок, то каково соотношения кода на этих двух языках в утилите ( уже намекал на этот занятный факт) m3sleep?
Кстати, подсказка: задача интересная и в чисто математическом плане.
P.S. Я, кстати, не могу со 100% уверенностью сказать, что моя теория верна. В «социальных науках» эксперименты ставить сложно.
Но факты (весьма и весьма и весьма немаленькую популярность потомков ALGOL ( В.В.М.: скорее, Pascal) в 1980е и резкое падение оной в 1990е) — моя теория объясняет.
Так что если у вас есть другая, альтернативная, она их должна объяснять тоже.
Причина невероятно простая: как говорил школьникам герой книги ( и фильма) про эсперанто — поменялась международная обстановка.
Поэтому же французы и итальянцы в 1954 — 1991 ( и чуть позже) «жили лучше» чем при развитом социализме.
Показательно, что на Эльбрус-2 были чуть ли не все языки программирования. Кроме, Си. Подозреваю, его наличие заказчик ( и исполнители) просто не считал необходимым…
P.P.S. TopSpeed я недавно где-то видел «на просторах всемирной паутины».
Нет. Каждые полгода выходит новая версия, но она не устанавливается автоматически, только руками. А вот по прошествии двух лет уже — обновление случается автоматически.Windows 10 — так и вообще каждые два года обновляетсяКаждые полгода…
Заодно уж, «языки семейства ALGOL» включают в себя и Си.Не. Не пойдёть. Там чёткая генеология достаточно чётко прослеживается: CPL, BCPL (где впервые появились фигурные скобочки), B, C.
Да, он испытал влияние ALGOL тоже и кое-какие идеи оттуда взял, но синтаксис был, в результате эволюции, перекручен капитально (и не в лучшую сторону, надо сказать).
Modula-3, фактически, тоже: там Си и собственно M3.Ну это уже был «гиблый номер»: у C к тому моменту моменту уже появился «оффициальный наследник», другим языкам было уже «нечего ловить». Objective C смог сохранится в одной-единственной нише, но даже [относительная] популярность Маков не помогла ему выбраться на другие рынки.
Причина невероятно простая: как говорил школьникам герой книги ( и фильма) про эсперанто — поменялась международная обстановка.Какой-то смысл за этой фразой есть? Что именно поменялось?
Показательно, что на Эльбрус-2 были чуть ли не все языки программирования. Кроме, Си. Подозреваю, его наличие заказчик ( и исполнители) просто не считал необходимым…Именно так. В 80е — он был «одним из многих» языков, далеко не самым популярным и не самым перспективным… а в 1990е, появился C++ (строго говоря он раньше появился, но популярные компиляторы: Turbo C++, Microsoft C++, Watcom C++, разного рода SunPro и так далее — это уже 1990е) и эта «сладкая парочка» просто как катком проехалась по всем проектам, где до того использовались Pascal и его потомки.
Должна же быть у этого всего какая-то причина?
Должна же быть у этого всего какая-то причина?Я бы сказал, что причина — эволюция.
В Ваткоме был оптимизирующий 32-битный компилятор с Dos4GW — см DOOM итп. А в Борланд Паскале 16-бит DPMI на костылях.
Никто не хотел отставать в гонке _вдвое_.
Потому почти все игры на буме развития отрасли писались на С ==> Ты пишешь на Паскале == неудачник.
Хотя был бы нормальный компилятор тогда, хз как бы повернулось, а ведь и до сих пор нет для Паскаля сравнимых с С++ по оптимизации. И со временем отстали и по удобству, синтаксису итп
В Ваткоме был оптимизирующий 32-битный компилятор с Dos4GW — см DOOM итп. А в Борланд Паскале 16-бит DPMI на костылях.Ага, понял. Из-за того, что у Watcom был самый классный, на то время компилятор, Apple перевела MPW на C++.
И IBM добавила к COBOL и RP для AS/400 C++ — по той же причине?
Вы это так себе представляете?
Знаете, это даже не смешно.
Хотя был бы нормальный компилятор тогда, хз как бы повернулось,Никак бы не повернулось.
Понимаете — вы сейчас посмотрели на одну мааааленькую площадочку IT-индустрии — и придумали объяснение. Хотя могу поверить, что из «бывшего СССР» она такой не казалась, так как IBM PC клоны были доступны в количестве, а вот все эти Маки, мейнфреймы и прочая «экзотика» типа AS/400 была мало кому доступна, но… в реальности кроме Dos4GW и Borland Pascal в IT-индустрии была масса игроков. И вот как раз где-то в конце 1980х-1990х — они, вдруг, по какой-то причине, все обратили внимание на C/C++. В 90е были доступны несколько десятков компиляторов C и C++ (только для DOS их было порядка десяти штук).
Да, несоменно, стандартизация (стандарт C89 он же C90 как раз только вышел) и прочее… но сколько тех стандартов выходило? Даже у Pascal их было два: IEC/ISO 7185 (1983го года и, как раз, тоже 1990го) и 10206:1990. И компиляторов Modula-2, Modula-2+, Modula-3 и других тоже было… немало.
И вот глядя на это — нет у меня ощущения, что вот какой-то один компилятор вышел — и развенул всю индустрию. Ну вот нету. По датам «не бьётся». DOS/4G — это 1996й год… а CodeWarrior — это 1993/1994й, а Think C и Macintosh Programmer's Workshop 2.0 (версии которые начали переход с Pascal на C на Маках) — 1987й/1988й.
Да даже и «крутой и независимый» Джобс в своей уже новой компании (где ему никто не мог мешать делать что угодно) — выбрал всё равно надстройку над C.
То есть нет, Watcom — это круто, DOS4/GW — это ещё круче… но не выглядят они как что-то, что могло спровоцировать разворот всей индустрии с Pascal и его потомков на C и C++. Наоброт — если глянуть на даты, то становится очевидно, что и Watcom C 7.0/386 и DOS4/GW и вот всё это — это уже следствия того, что индустрия повернулась в сторону C и C++.
а ведь и до сих пор нет для Паскаля сравнимых с С++ по оптимизации.Ну дык это логично. Если оптимизацией компиляторов C++ занимаются десятки компаний, а компиляторов Pascal — горстка энтузазистов и одна компания, которыя занимается привлечением «ынтыррайза»… то и не будет у вас «компиляторов сравнимых с С++ по оптимизации»… но это уже следствие, не причина. «Приличные» C++ компиляторы появились через многие годы после «большого разворота», а «крутые» — через два десятка лет.
Всё это явно следствия. «Крутые» компиляторы не появляются так, что «суперВася» чешет репу месяц, а потом садится — и ешё за месяц делает классный компилятор. Нифига. Крутой компилятор — это просто компилятор, в который вбухано несколько тысяч человеко-лет. С них «крутые развороты в индустрии» не начинаются…
Это можно на LLVM посмотреть: разработка началась в 2000м году, а плюс-минус паритет с GCC — это где-то год c 2013-2015й.
Но смотрим таки на даты
DOS4GW вышел с Watcom уже в 1991г, DOOM — 1993.
С-программы выигрывали по скорости у паскаля вдвое тогда. Для медленного железа это решало.
Не возражаю, что разворот для других систем произошел ранее, да и
The Lattice C Compiler was released in June 1982 by Lifeboat Associates and was the first C compiler for the IBM Personal Computer
Что заставит вас, имея код с одним предложением в теле цикла и без begin-end, гарантированно вспомнить, что надо поставить скобки прежде чем добавлять туда же второе предложение?
Хм, неужели понимание что я вообще тут делаю?
Опыт показывает, что промахнуться и забыть их поставить — типовая проблема.Опыт показывает, что это редчайшая проблема. Если это действительно проблема — то достаточно ставить begin/end всегда не задумываясь.
Как уже сказал, при отсутствии какого-то широкого методически правильно обеспеченного опроса ширнармасс программистов я буду верить своему опыту, а не чужому :)
> Если это действительно проблема — то достаточно ставить begin/end всегда не задумываясь.
Ну вот мы в автоформаттере для C/C++ кода ставим эти {} принудительно. Если бы каким-то дьяволом занесло на Паскаль — поискали бы и для него такую же тулзу.
Как уже сказал, при отсутствии какого-то широкого методически правильно обеспеченного опроса ширнармасс программистов я буду верить своему опыту, а не чужому :)По опыту чтения и весьма активного участия примерно в течение 20 ти лет на форумах и (сейчас) телеграмм чатов Delphi. Видел несколько раз жаловались за всё время, не более того. Проблема просто надумана.
А вот обратную проблему: кривую копипасту кода Питона, в котором обошлись без программных скобок испытываю постоянно. Пописываю некоторые куски на Питоне, бывает.
поискали бы и для него такую же тулзуВстроенный форматтер так умеет делать насколько помню.
Вам не кажется что в вашей же фразе содержится ответ? C++ — гораздо менее лаконичен, чем C. Несмотря на то, что S s= new S(); короче, чем «struct S s= malloc(sizeof s); в реальных программах C++ более многословен… и даже сам ваш вопрос это подтверждает.
Во-первых для Си вы еще забыли приведение типа, тогда еще хуже станет (однако и с приведение будет не плохо, а вполне понятно и разумно!). А во-вторых — ну нет, конечно равноценные программы на плюсах никак не вербознее. А более сложные — ну штош.
Касаемо Паскаля, мы уже как-то обсуждали с вами — он более вербозный, он менее понятный „с листа“ (дада, именно из-за бегин-енда вместо скобочек), но тем не менее он понятный, то есть условный ньюкаммер достаточно быстро примерно поймет суть дела. А тут?
Во-первых для Си вы еще забыли приведение типа
А оно тут и не нужно, malloc возвращает значение типа void*, которое в C неявно приводится к любому другому типу указателя.
Приходите в golang
А что вы имеете в виду под нормальным синтаксисом? Я каждый раз задаю этот вопрос, и каждый раз не получаю конкретного ответа. Ну то есть вам fn не нравится? Как вместо этого, лучше function? или auto?
Часто ответом предлагается "да уберите эти чертовы лайфтаймы", но если человек так говорит, то он просто не понял, зачем эти закорючки с апострофами нужны и какую они роль выполняют.
(Раз пошла такая пьянка, то)
Вот старые Microsoft SAL аннотации для описания ограничений у параметров библиотеки были вполне читабельными, без введения нового языка ("закорючек") https://docs.microsoft.com/en-us/cpp/code-quality/understanding-sal
Но как-то дальше prefast чекера у драйверов эксперимент не пошел. А зря. IMVHO.
Знаете, вот эти "Закорючки" куда лучше чем то что по ссылке. Это всё равно что использовать какой-нибудь Reference/Pointer и так далее вместо & и *.
Это всё равно что использовать какой-нибудь Reference/Pointer и так далее вместо & и *.Это как раз то, что делает Ada — и да, мне это нравится. Увы, я, похоже, один такой. После Борна, собственно. Который вот такое вот вытворял.
Ну что ж, раз людям нравятся закорючки… будем использовать закорючки. Борн боле известен, чем я — но и он смирился, в конечном итоге…
В принципе, в Rust не с потолка все языковые фичи, в том числе и эти "закорючки" берутся — всё это проходит свою эволюцию через обсуждение с комьюнити. Часть "закорючек", к слову в процессе развития языка таки убрали.
Но есть такой конфликт: когда новая фича только появляется, или когда кто-то изучает новую для себя фичу — преобладает желание, чтобы она была более вербозной. Однако, когда опыта и кода становится больше, — возникает желание выражать всё более компактно.
Так что всё зависит от того, кто смотрит на код, и даже восприятие одного человека — не постоянно, и со временем меняется.
Думаю дело про ощущение ситаксиса в целом. В частности, те самые закорючки вместо ключевых слов. И сравнение тут не с C++, а скорее с другими языками. И, судя по частоте притензий на эту тему, уже сложилась прослойка программистов, для которых первым языком был не C/C++, а Python, Java или что-то подобное. Имхо, синтаксис Rust никогда не проектировался, как например Python или Kotlin, он развивался дарвинистски и пришел за несколько лет туда же, куда и C++ за десятилетия.
Как раз-таки по-моему синтаксис раста очень неплохо продуман. Попробуйте заменить любой элемент, и скорее всего это окажется неудобным. Кроме вопроса "насколько потятен С/С++ разработчикам" стоит вопрос писать такой код 8 часов в день. И если вместо пары закорючек нужно писать длиннющие слова то обычно это заканчивается не очень. Не даром begin/end — первое, что вспоминают при слове "паскаль", и обычно еще предворяют словом "ужасные". Прям 1 в 1: ужасные закорючки {} или нормальные кейворды.
Как мне кажется, что наиболее часто встречающиеся в коде символы — это первый кандидат в закорючки, это реально упрощает его визуальное восприятие, но не сразу, а как только более менее привык к ним, тогда они наоборот помогают воспринимать инфу.
&& делают в такой вот записи: template<3>
auto&& get() && {
return x;
}
И что же? Впервые вижу их на таком месте
&& — это закорючки C++11, не C++17.Вы верно смеетесь, батюшка :(. Что тут очевидного и каким боком оно вообще к structured binding — по этой ссылке ничего подобного нет. Где там описание наличия & или && между именем функции и ее телом?
X& и X&&. Ну и чем foo(); от foo(...) const; отличается. Без последнего же ведь даже в C++98 не прожить. Вот get() &; vs get() &&; — это то же самое, что и этот const, только про разницу между value и xvalue.А structured binding — там всё вообще просто. Разница между:
Foo foo;
auto&& [x, y] = foo;
auto&& [x, y] = Foo();
Погоди-погодите… Это что, новый оператор появился?
auto get<>() && { /*что возвращать при структурном биндинге*/ }Или это какая-то шаблонная магия для tuple? Все рано непонятно, что значат эти &/&& между именем функции и телом. В чем различие по аналогии с const/не-const понятно, но как вот они взаимодействуют с const, noexcept, throws, override и указанием возвращаемого типа через -> — непонятно. И где они вообще описаны, кроме стандарта? Ни в одном обсуждении новых фич C++ я такой штуки не видел (хотя я не слежу пристально, но уж на хабре бы должны были такое заметить).
Ну как что? Это же обычный модификатор для скрытого параметра *this. Если написать там const — то this будет указателем на const, если написать там & — то this будет указателем на ссылку, если написать там && — то this будет указателем на rvalue-ссылку. Указатель на ссылку, правда, в языке C++ запрещен — но, видимо, для this есть исключение.
Я, конечно, тоже первый раз вижу такой синтаксис — но пониманию что он означает это не мешает же.
Ну это не совсем так — *this даже в случае rvalue-ref квалифицированного метода все равно остаётся lvalue, но вот так называемый скрытый параметр, который неявно передаётся при вызове любого нестатического метода, в этом случае будет квалифицирован как rvalue reference.
Указатель на ссылку, правда, в языке C++ запрещен — но, видимо, для this есть исключение.Там нет исключения. Там где вы вызываете — там вы работаетe с объектами:
foo.get(); или Foo().get();.А внутри функции — да, там у вас
this уже указатель… обычный указатель, без выкрутасов. Они там уже и не нужны: выбор нужной функции произошёл, дальше разницы между двумя функцияими для вас нету. Просто вы знаете, что один объект, после вызова вашей функции (функций, если речь о structured binding) исчезнет, а в другом — не исчезнет.Синтаксис не новый, как я сказал, он в C++11 появился.
И если вместо пары закорючек нужно писать длиннющие слова то обычно это заканчивается не очень.
Есть обратный пример Java. Один из самых популярных языков. Он весьма многословен. Да, Pascal слегка доставал этими begin/end, но он был в до IDE'шную эпоху. Уже в Delphi это так не напрягало, а с современными IDE и языками вопрос написания отходит на второй план. Важнее вопрос восприятия и читабельности.
К тому же здесь важен баланс. {} это безусловно удобное сокращение. * для указателей в C, тоже разумный ход, но грань где-то должна быть. И судя по частоте притензий к Rust, он эту грань перешел.
Про эти претензии обычно говорят люди, которые на расте ничего писать не пробовали. Ну то есть представим гипотетический сценарий, что ланг типа вняла всем этим советам и всё переделалала, в новом Rust 2022 edition. Знаете что произойдет? Разрабочтики на расте просто взвоют, реддит заполонят "Cannot write any code in this Rust 2022"/"Rust 2022: is it a joke?", и из языка свалит наверное половина народу, если не больше.
Такие же претензии у людей к ML синтаксису хаскелля. "Блин, функции без скобок, неудобно". Окей, сделали скалу, который во многом тот же хаскель, но в сишном синтаксисе. Стали люди довольны? Еще пуще прежнего начали: "Ой, да тут столько скобочек, невозможно читать, даже хаскель лучше".
Ну кмон, в итоге это типичная басня про общественное мнение. И про людей, которым не нужен автомобиль, а нужна более быстрая лошадь (С+++, а не раст).
style guide, что я видел, написано «используйте, если по другому написать в принципе невозможно, в противном случае — пишите как в прошлом веке».Привычка — вторая натура…
А вот я кстати хоть убей не понима зачем надо писать
impl<T> Foo for Bar<T> вместо impl Foo for Bar<T>. Уж вывести что там в правой части не указано явно и автоматом понять что это внешний параметр проблем вообще не должно быть. А если вместо T там 'a, а эти 'a иногда при рефакторинге добавляются гораздо чаще чем T, то вообще застрелится можно каждый раз менять всюду.
Апд: хабр съел код
Полагаю, для однозначности. Иначе пришлось бы довольно сильно переделывать парсер, и добавлять контекстной-зависимости, которую в расте очень не любят. Например
impl Foo for Bar<T>это совсем не то же что
impl Foo<T> for Bar<T>То есть нужно трекать, какие Т были введены в контекст, какие нет, и вот это всё. Ну и явность страдает, не сразу видно, сколько генерик параметров объявляется, а иногда это важно. Картинка-пугалка в тему:
О даа километровые where блоки это классика жанра. Я и сам за принцип что явное это хорошо, и в крайнем случае иде пусть за меня пишет код. Но вот когда в одной строчке два раза подряд то же самое идёт, то руки начинают играть в злую игру и пытаются заставить мозг придумать как упростить себе жизнь)))
Госпади, так пишет кажется лишь один Томака)))
Ну, я ещё добавлю.
impl<T> — это объявление переменной типа. В этом контексте для Bar<T> — используется переменная, созданная в этом объявлении.
Но точно так же мы можем написать impl Foo for Bar<T> — это такая же легальная реализация, только для конкретного типа T.
Если мы заставим компилятор догадываться "здесь подразумевалась переменная, которую решили не указывать, или конкретный тип, который забыли импортировать" — это в итоге создаст сильно больше проблем, чем решит их. Хотя подобные предложения были и рассматривались в рамках обсуждения по улучшению эргономики языка.
Ну, можно было бы пойти по пути хаскелля — все типовые переменные с маленькой буквы считаются вводимыми генерик аргументами. Это работает, но это идёт как раз вопреки тенденции раста быть максимально "немагическим" и явным. Например, в расте часто надо вызывать генерики частично применённые явно, тпа Foo::bar<i32, _>, как в таком случае оно делается? Мне вот каждый раз надо вспоминать какой порядок аргументов в каком-нибудь хаскелле у foo :: m a -> d -> c b -> b, должно ли тут быть foo @List _ @Int или foo @List _ _ @Int или @List _ _ _ @Int?
Есть обратный пример Java. Один из самых популярных языков. Он весьма многословен.
Только вот вопрос, а что, собственно, популярно — Java или JVM? И не может ли получиться так, что Java сейчас живёт только за счёт уже наработанного массива кода, а в новых проектах её уже вполне может потеснить хотя бы и тот же Kotlin?
Часто ответом предлагается «да уберите эти чертовы лайфтаймы»
Ни в коем случае, без этого Раст вообще непонятно зачем нужен.
Ответ на ваш вопрос не существует. Я уже пытался в прошлом холиваре что-то описать, слил карму и наполучал минусов (в этот раз растоманы тоже уже по мне прошлись, кек), но сути дела так выяснить и не удалось, поскольку на любой вопрос «Боже, зачем так?» говорилось «а мне вот все понятно». Дискуссию в таком тоне я продолжать не вижу смысла. Ну вот покажут вам девушку (пардон присутствующим дамам за сексистский пример), вы подумаете «какая-то она не очень», а что в ней именно не очень? Ну нос как нос, глаза как глаза, ну волосы жидковаты, ноги кривоваты — а что, зачем прямые ноги? Вот правда, зачем человеку прямые ноги? Вот и я видимо не умею объяснить, почему я смотрю на синтаксис Раста — и просто коробит. Реально, ровно одну статью смог прочитать, больше не осилил!
Я не так много вращался в Джаве и довольно много (но колхозно) вращаюсь в Шарпе, но мне, черт побери, нравится многословность и CamelCase. Это сделано для людей, а все остальное решает IntelliSense и нормально спроектированные библиотеки. Знаете как я начал писать на Шарпе? Какую книгу я прочитал первой, попробуйте угадать?
Ну вот или как например объяснить, чем мне не нравится бегин-енд (хотя это же многословно, ура!), и почему я считаю странными знаменитые питоновские отступы? Ну вот потому что, не люблю кривые ноги, не знаю почему. К волосам у меня претензий нет, а вот ноги чот раздражают (еще раз прошу пардону за сексизм).
Если вам не нравятся "закорючки" раста, но при этом одновременно "не нравятся" begin/end паскаля, а в сишарпе на ваш взгляд всё органично сочетается, то могу только предположить что это пресловутый "синдром утёнка" (без какой-либо негативной коннотации, просто факт).
Что до PascalCase или нет — мне вот вообще кажется, что если к синтаксису ещё можно как-то докапываться, то как писать переменные… Да какая разница? Вот я один человек, но в сишарпе я пишу ПаскальКейс, в тайпскрипте/хаскелле — камелКейс, в расте/питоне — снейк_кейс, и везде это выглядит органично и понятно.
могу только предположить что это пресловутый «синдром утёнка»
Именно так, ведь я начинал свой путь в программировании с Паскаля, потом Дельфи, и все это было весьма долго… Ой нет, кажется «синдром утенка» — это про что-то другое? Подсказку, кстати, я вам выше давал — Шарп был не первым моим языком, а крайним.
Как писать переменные — весьма большая разница (и вы верно напомнили — конечно ПаскальКейс, не кэмелКейс). Привязанность целых отдельных видов разработки и, что еще более ужасно, целых языков, к тому или иному способу написания — это ужас какой-то.
Именно так, ведь я начинал свой путь в программировании с Паскаля, потом Дельфи, и все это было весьма долго… Ой нет, кажется «синдром утенка» — это про что-то другое? Подсказку, кстати, я вам выше давал — Шарп был не первым моим языком, а крайним.
Да я собственно не сомневался, намёк был, скажем так, очень даже не тонкий. Но я прошел тот же самый путь, паскаль, дельфи, сишарп,… Собственно, вы же знаете что Хелсберг разрабатывал и делфи, и сишарп? Поэтому они так похожи, включая PascalCase и некоторые другие особенности. Поэтому ничего удивительного, что именно шарп стал вашим последним языком.
Как писать переменные — весьма большая разница
Только если вы сами решите так относиться. У меня на работе коллега пишет на сишарпе, расте и хаскелле, я сам тоже пишу в основном на шарпе, но иногда переключаюсь на ноду и тот же раст. 3 разных стиля написания — никаких проблем нет. Не надо зацикливаться просто самому. Куда важнее какая в языке система типов, какие гарантии от самого языка, что с библиотеками и тулингом. А как там переменные и функции называть — да по барабану, дайте гайдлайн, буду именовать как рекомендуют.
Поэтому ничего удивительного, что именно шарп стал вашим последним языком
Во-первых я все же надеюсь, что не последним, а крайним, а во-вторых — вы все-таки не поняли, о чем я говорю. Мой путь не «начался в Паскале, кончился в Шарпе», я кратно большее количество кода написал на С/С++, где все по-другому (и нет богомерзкого бегин-енда). То есть если вы вдруг где-то там предположили «ну он паскалевод, все ясно», то непонятно почему вдруг.
Отсылка к Хелсбергу совершенно правильная, когда человек умеет делать свое дело — его труд всегда становится востребован. Самые светлые мои воспоминания — годы работы в Borland С++ Builder, угадайте почему.
А как там переменные и функции называть — да по барабану, дайте гайдлайн, буду именовать как рекомендуют
Мы немного углубились куда не следовало. Я не пытался доказать (хотя я так считаю, да), что во всех языках надо писать одинаково. Я лишь привел примеры того, как люди умеют писать понятно.
Во-первых я все же надеюсь, что не последним, а крайним, а во-вторых — вы все-таки не поняли, о чем я говорю
Говорить "крайний" в смысле "последний" — довольно грубая грамматическая ошибка. Не надо так.
Мы немного углубились куда не следовало. Я не пытался доказать (хотя я так считаю, да), что во всех языках надо писать одинаково. Я лишь привел примеры того, как люди умеют писать понятно.
Понятность никак не зависит от того, используется паскалькейс или другой.
Говорить "крайний" в смысле "последний" — довольно грубая грамматическая ошибка
это не ошибка, а некая дурацкая традиция. Я ей, кстати, не подвержен https://mel.fm/pravopisaniye/1508769-posledniy
Я уж не говорю, что у той же очереди есть два края — передний и задний, блин. Чертовы проф. суеверия и деформации.
Говорить «крайний» в смысле «последний» — довольно грубая грамматическая ошибка. Не надо так.
Я в курсе. Но я не мог это не сказать, понятно же ))
Понятность никак не зависит от того, используется паскалькейс или другой.
Вы утрируете. Решает качество платформы, а выбранный способ представления имен — как ни странно ее часть.
Я не так много вращался в Джаве и довольно много (но колхозно) вращаюсь в Шарпе, но мне, черт побери, нравится многословность и CamelCase. Это сделано для людей, а все остальное решает IntelliSense и нормально спроектированные библиотеки.
Лично мне кажется, что одним из критериев полноценного языка программирования является возможность сравнительно эффективно читать и писать код на этом языке без средств поддержки, конкретно под этот язык заточенных.
Без фанатизма – всё-таки подсветка синтаксиса сильно облегчает жизнь, не говоря уже про нормальную работу с отступами – но это вещи, которые умеет любой приличный редактор кода. А вот автодополнение и всплывающие подсказки типов уже должны бы быть опциональны для эффективной работы.
Не говоря уже про языки, обязывающие использовать единственную фирменную IDE, наподобие какого-нибудь там LabVIEW.
Я вот новичок в расте, но немного освоившийся. На данный момент ощущения от синтаксиса у меня такие
- Привычные:
<T>— дженерики везде одинаковы;{}— ура, скобочки (надоел Python);.— доступ к полям объекта тоже как и везде;&,*— хоть я плюсы только в учебнике видел, но операторы запомнил - Знакомые:
->— return тип в таком виде встречается;=>— ну паттерн матчинг понятие новое, но такие стрелочки в жизни я встречал в каких-то похожих контекстах; - Изящные:
?— отличное решение проброса ошибки вместо эксепшнов;print!— сначала ощущение, что на тебя кричат, но вообще удобно отличать макрос от функции - Напрягающие:
?Sized— выглядит как костыль (почему не UnSized какой-нибудь?);dyn Trait— вся концепция какая-то мутная, неизящная, ещё и постоянно юзается какBox<dyn Trait>как бы подчёркивая кривизну;@— тут явно чё-то перемудрили с выбором синтаксиса для, имхо, редкоюзаемой фичи - Мозговзрывающие:
a..=b— автоматически читается какa= a..bс фатал эррором в голове при поиске оператора..(для тех кто не знает раст — это, упрощённо, range a..b только включая b);||{}— лямбды хоть и знакомы из руби, всё равно ощущаются инородно, расту больше бы какая-то стрелочка здесь подошла (надо было у паттерн-матчинга отнять). Вовочка:'a— конечно же лайфтаймы, глаза автоматически пытаются искать закрывающую кавычку. Считаю это самым худшим решением в синтаксисе раста, учитывая что лайфтаймы не так и редко нужны и — что ещё хуже — используются подряд в большом количестве, делая максимально нечитаемыми определения функций. Лучше б уж сюда@присобачили.
Я понимаю, что ещё наверное пара месяцев игр с растом, и я ко всему привыкну, но тут обсуждалось чем синтаксис может оттолкнуть новичков, так что думаю я встрял вовремя)
P.S. Насчёт ключевых слов (fn, trait, impl, struct). Считаю, что у раста с этим всё очень хорошо. С одной стороны они довольно знакомы и очевидны, с другой — дают понять, что struct это вам не class, а trait — не совсем interface.
Отвечу только на то что вызвало вопросы:
Напрягающие: ?Sized — выглядит как костыль (почему не UnSized какой-нибудь?);
ИМХО оно и есть костыль. UnSized не подошел потому что тогда нужно делать в компилятор хитрую связь между Sized/UnSized, ну и всякие другие нюансы. В общем там всё непросто.
Мозговзрывающие: a..=b
Ну тут всё просто, если посмотреть на историю: изначально ренжи выглядели как и везде let foo = a..b. Через какое-то время стало понятно, что они не всегда работают как надо, например вы не можетесь пройти по всем значениям байта от 0 до 255, потому что верхняя граница не включается. Тогда придумали писать a..=b, то достаточно легко прочитать как "ренж от а до б, включая б", как следствие записи a..b "ренж от а до б".
@ — тут явно чё-то перемудрили с выбором синтаксиса для, имхо, редкоюзаемой фичи
Эта фича в таком виде используется во многих других языках, включая хаскель. Поэтому так же по аналогиию. Плюс, @ читается как "at", что придает оператору хорошую мнемонику.
dyn Trait — вся концепция какая-то мутная, неизящная, ещё и постоянно юзается как Box<dyn Trait>А вот тут всё интересно — вы наверняка знакомы с понятием синтаксического сахара. Так вот, dyn Trait — это синтаксическая соль. Они абсолютно сознательно сделали так, чтобы вы старались их избегать и не использовали без лишней необходимости. С той же целью кстати и сделанно длиннющее слово unsafe {}, которое обычно делает код просто в 2 раза длиннее
(сравните let a = arr[i] и let a = unsafe { arr.get_unchecked(i) };). Могу сказать — что работает отлично, часто код структурируется на генериках без виртуальных вызовов, потому что так он выглядит изящнее. Что сказать — как по мне, решение хорошее.
Вовочка: 'a — конечно же лайфтаймы, глаза автоматически пытаются искать закрывающую кавычку. Считаю это самым худшим решением в синтаксисе раста, учитывая что лайфтаймы не так и редко нужны и — что ещё хуже — используются подряд в большом количестве, делая максимально нечитаемыми определения функций. Лучше б уж сюда @ присобачили.
Мне кажется, что с лайтаймами в этом плане всё в порядке. Чутка чужеродно, но как раз какой-то большой символ присобачивать не очень — он место сожрет, а из небольших апостроф один из самых заметных. Если еще и IDE взять подходящую, которая лайфтаймы красиво расскрашивает зелёным курсивом, то тогда код читать одно удовольствие. Ну и да, лайфтаймы довольно редкий зверь. Не знаю, сколько у нас их в нашем проекте в точности, но не очень-то и много.
Вы путаете непривычность синтаксиса с неудобством. Для тех, кто программирует на Rust — синтаксис вполне хороший, это только для новичков он выглядит страшно, потому что непривычен. Да, с синтаксисом есть и проблемы, которые в новых версиях языка пытаются решать, но они совсем не в тех местах, которые вы указали.
И конечно я понимаю, что когда ты привык, то ты этого уже не видишь. Примерно как на Паскале писали бегин-енды, и не ныли, а теперь уже таким бредом кажется.
Примерно как на Паскале писали бегин-енды, и не ныли, а теперь уже таким бредом кажется.Мне они до сих пор нравятся. То, что их можно опустить — да, это плохо. А сами по себе они как раз хороши. Наоборот мне не нравится, что в
record имеем end без beginа.Все-таки программа — это не просто поток текста, это структурированный текст. Поэтому грамотное использование спецсимволов может сильно улучшить восприятие программы в целом, соотношение ее составных частей.
Нечитаемое месиво получается только тогда, когда собственные идентификаторы программист начинает делать однобуквенными, тогда их просто труднее отделить от операций и кусков синтаксиса самого языка и все сливается в одном потоке коротких символов. Другая крайность: писать ключевые слова и операции длинными словами, как и пользовательские имена — опять же получится трудночитаемое месиво.
fn get_elem_by_index(elems: &[u8], index: usize) -> u8 {
return unsafe { unchecked_get_elem_by_index(elems, index) };
}Ну так и не должен. Безопасная функция с unsafe должна гарантировать, что не падает с UB. Хоть это и на уровне соглашения, но любой код можно написать плохо :)
Сегодняшнаяя статьи и, особенно, рекация на неё показали: адепты C++ боятся, а значит мы уже на второй стадии… так что процесс идёт.
Боятся скорее адепты раст, причём настолько боятся, что уже год занимаются написанием возражений на оригинальное видео Антона… различной степени адекватности, скажем так, а также изобретениями теорий заговора про то, как вредители мешают повсеместному распространению раста. Вся эта агрессия, причём зачастую слабо подкрепленная с технической точки зрения, мне совершенно непонятна. Почему-то те же гошники или свифтовики так себя не ведут.
Гошникам некогда, они на nil проверяют.
уже год занимаются написанием возражений на оригинальное видео Антона…
Антон три раза выступал с этим докладом. Раз. Два. Три.
А в комментах на хабре до сих пор пользуются этим докладом в качестве аргументов. https://habr.com/ru/post/497158/#comment_21498428
Последней каплей стало заявление моего коллеги. Я могу игнорировать доклады Антона, если они проходят мимо меня, но если они касаются лично меня и моей работы, я считаю, что у меня есть право ответить.
"Лично вас"? Любую критику раста вы воспринимаете уже на личном уровне? Ну это уже крузайдерство чистой воды, как по мне. Ну ОК. Антон вам уже тоже ответил, хотя и, как я понимаю, ему все это тоже уже давно небось надоело.
Перечитайте начало статьи:
Недавно я пытался заманить коллегу, сишника из соседнего отдела, на Тёмную сторону Rust. Но мой разговор с коллегой не задался.
Для меня найм людей в мою команду — работа. Почему я не могу взять человека из соседнего отдела? Он адекватен, у него есть опыт, он понюхал пороху с С++. Не могу, потому что он посмотрел доклад. Вот кину ему статью, посмотрим, изменит он своё отношение или нет.
А наезды на язык — дело такое. Пускай наезжают, у каждого есть право на личное мнение.
Любопытно. Я гошник, послушал доклад, попробовал код. Было любопытно, мне понравилось. Призадумался о маркетинге и ЯП. Вспомнил, что в началах распространения go тоже были радикальные адепты и тут на хабре тоже. Сейчас они как-то замолчали и от этого все выиграли. Сместились акценты с маркетинга обратно на разработку.
А что до доклада, то мне он показался честным. Те же проблемы го, действительно есть и давно обозначены. Чего на указание на них орать или писать гневные статьи.
Тому видео вообще-то год уже, которое тут разбирается. Впрочем, подобные холиворы вокруг Раста и плюсов возникают регулярно и они намного более яростные, чем ну холиворы между С++ и D к примеру.
То есть на всем известной шкале это было явно стадия «отрицание». А туда попадаются как «неизбежные» явления, так и «неважные». Фигня всякая, из которой никогда ничего не выйдет.
А вот тут мы уже очень хорошо видим, что стадия «отрицания» пройдена и наблюдается стадия «грев» — в полной мере.
И это — очень важный момент. Потому что это первая «настоящая» стадия — все дальнейшие следуют автоматически.
Единственное что может остановить «принятие неизбежного» — это более сильное событие, которое этот переход «перебьёт». Условно: может перейти не переход на Rust, а переод на какой-нибудь неведомый нам пока CoreC++, если тот окажется для этого достаточно хорош.
Это ты не видел любую тему про релиз раста или любой программы или библиотеки на расте на лоре и опеннете.
Там всегда тонны набежавших царей пасутся.
И, чтобы два раза не вставать, давайте я проговорю мою точку зрения, за которую я топил в Си++-сообществе?
Раст-сообщество не конкуренты, а дополнение Си/Си++ сообщества. Они не изобретают тулинг на пустом месте (как делают гошники), binutils те же, отладочная информация та же, линкер и LTO тот же самый, отладчики те же. Нет ни одной причины (ну разве кроме агрессивности RESF) относится к ним как к чему-то чужеродному.
Раст надо считать третьим компонентом в "C/C++-community". Со временем, если он научится жить в мире (и переключит внимание RESF на что-то более полезное) мы будем писать "C/C++/Rust — community".
P.S.
И раз у нас есть уже LTO межязыковое, давайте уже к Cargo чисто C++ модули приделайте?
И раз у нас есть уже LTO межязыковое, давайте уже к Cargo чисто C++ модули приделайте?
Уже 3 года как можно. И даже в cmake.
интересно, а много таких Си++ библиотек уже в крейты сконвертировано? А Boost можно? ;)
чтобы
cargo install boost-cxxТам темплейты не пролезут через ffi.
Если нет аналогов (по функциональности и производительности) на чистом Расте и библиотека представляет C API, то народ вполне использует плюсовые библиотеки обёрнутые в крейты. Не говоря уже о куче обёрток вокруг C библиотек. Из плюсовых обёрток лично я использовал shaderc и самописный биндинг к декодеру FLIF. От последнего отказался когда декодер на чистом Расте стал достаточно производителен и получил нужную мне функциональность. Если же библиотека не имеет нормального C API, то к чёрту такое оборачивать… Например, после бесплодных попыток обернуть libpcl (плотно сидящий на темплейтах) я плюнул и написал нужные мне алгоритмы с нуля. Примерно так же народ плюнул на оборачивание OpenCV, большинство обёрток, насколько я знаю, далеки от желаемого.
А Boost можно?
А что конкретно вам из него нужно чего нет в существующих крейтах на чистом Расте?
А что конкретно вам из него нужно чего нет в существующих крейтах на чистом Расте?
Тут есть маленькая проблема — Раст. Мне не нужен чистый Раст, я не религиозен, если есть решение на Си, Си++ или даже Фортране, я их принесу в билд систему и слинкуюсь.
И, вообще, я Си/Си++ программист (ну или ментально остаюсь таковым, несмотря на обстоятельства). Мне Раст никак пока не релевантен. Хотя вот Cranelift, конечно, очень интересный проект и хотелось бы поиграться, ну или вон ripgrep можно было бы прилинковать. Хотелось бы, если бы принесение Раст кода в Си++ проект не было бы такой болью (я так и не понял всего объема отжимания в Firefox).
С другой стороны, в Расте есть одно важное преимущество — Cargo. И было бы замечательно, если бы при помощи Cargo можно было бы легко замешивать C/C++ и Раст код. Чтобы он хидера в обе стороны генерировал, чтобы слинковать в один проект без боли можно было бы (путь и для простого проекта). Это стало бы реально инструментом, объединившем оба (3) сообщества.
При прочих равных всегда удобнее работать с моноязыковым проектом, поэтому если вы пишете на Расте, то при возможности имеет смысл использовать идиоматичный код, а не тащить привычные инструменты из другого языка. Если у вас есть плюсовая библиотека использующая буст, то делайте к ней C API, относительно тривиально оборачивайте в крейт и используйте в Расте без каких-либо проблем. Либо наоборот, используйте Растовый крейт обёрнутый в C API в вашем плюсовом коде.
ну или вон ripgrep можно было бы прилинковать
Существенную часть heavy lifting, насколько я понимаю, тут делает regex крейт, для которого уже существует C API, так что, насколько я могу судить, это можно сделать относительно просто уже сейчас.
было бы замечательно, если бы при помощи Cargo можно было бы легко замешивать C/C++ и Раст код
Cargo это в первую очередь билд система для Раста, распыление и без того ограниченных ресурсов и feature creep имхо скорее повредит проекту. Благо специализированные крейты (cc, сmake, cxx) и билд скрипты уже сейчас делают создание обёрток из C/C++ в Раст относительно безболезненным.
Вообще, я не думаю, что "лёгкое замешивание" возможно достичь малой кровью. С++ (справедливости ради, как и Раст) чрезвычайно сложно автоматически замешивать с другими языками не выделяя вручную C API. Не говоря уже о том, что даже при наличии C API нужно код оборачивать в безопасный Раст, что в зависимости от архитектуры сишного или плюсового кода не всегда возможно сделать нормально (например, см. провалившуюся попытку обернуть wlroots). Насколько я слышал, даже D, ставя одной из своих основных задач совместимость с C++ всё ещё имеет ворох проблем, что уж говорить о Расте для которого таких задач не ставилось.
Хотелось бы, если бы принесение Раст кода в Си++ проект не было бы такой болью (я так и не понял всего объема отжимания в Firefox).
А можно подробнее про "боль"? Я в паре своих проектов без проблем интегрировал C++ и Rust. В конце концов нужно то две команды: cargo build и cbindgen, чтобы собрать библиотеку на Rust и сгенерировать заголовочный файл для нее, в общем-то не сложнее использования Qt/moc.
Пишу cpp!(/* код внутри Rust модулей, и вызываю из них rust!( код вложенными макросами ) */). Скажите, доктор, в каком аду мне гореть?
Спойлер: C++ не быстрее и не медленнее и вообще смысл не в этом.
Убийца — дворецкий.
C++ быстрее и безопаснее Rust
Еще бы сдесь не было столько комментов )
Сишники, чуваки, старички… эй алё. Я раст не знаю, но знаю что сишка немного устарела. Срать на раст, го же )
Чтобы избегать facepalm в подобных сравнениях нужно чуть больше/тщательнее знать оба языка и особенности обоих компиляторов (LLVM, GCC). Иначе, по-сути, повторяются те же ошибки, что сделал предыдущий критикуемый автор/докладчик.
Это же относится к битовым операциям над знаковыми типами: при всех порождаемых проблемах они есть и отказаться от них в низкоуровневых языках, увы, невозможно.
Кстати, а чем это мотивировано?
Аргументы за / против ?
Кстати, дурацкий вопрос, почему так не любят беззнаковые типы? Какие с ними проблемы, которых со знаковыми нет?
Имеем цикл:
for (unsigned i = 0; i < len; ++i) {
foo(a[i]);
}
Потребовалось изменить порядок и идти с конца. Наивно переворачиваем:
for (unsigned i = len - 1; i >= 0; --i) {
foo(a[i]);
}
и почему-то никогда не выходим из цикла…
Да, есть шанс, что компилятор отловит (предупреждение про бессмысленную проверку), что юнит-тест упадёт, потому что зависнет… но всё не окончательно гарантировано.
А дальше возникает интересный вопрос: а как на самом деле надо было-то? Переделать в цикл с постпроверкой (типа do-while)? Так это надо иметь уже опыт подобных граблей…
В случае знакового обычно не натыкаемся на опасные граничные значения вроде INT_MAX — большинство применений до них не доходят. А при беззнаковом граница на переходе 0 -> -1 опасно близко.
Ну, например, такое.
Имеем цикл:
for (unsigned i = 0; i < len; ++i) { foo(a[i]); }
Ну ок:
for i in 0..len {
foo(a[i]);
}Потребовалось изменить порядок и идти с конца. Наивно переворачиваем:
for (unsigned i = len - 1; i >= 0; --i) { foo(a[i]); }
Окей, наивно переворачиваем:
for i in (0..len).rev() {
foo(a[i]);
}Так в чём проблема-то?
Это какой язык? Мы вообще-то в контексте C++ говорили :)
Это какой язык?
Rust
Мы вообще-то в контексте C++ говорили
Специально перечитал все комментарии в ветке, С++ упоминается лишь косвенно как источник для первого примера.
Тогда:
1. Тип i где задан? Если какой-то из unsigned, то интересно, каким образом он справляется с этим (на уровне того, какой код подан на вход LLVM; ассемблерник уже не интересен, поскольку будет очень серьёзно преобразован). Я подозреваю, что будет та же самая проверка в конце цикла.
2. Вы вцепились в один пример, он предельно простой. Я на нём хотел показать именно то, что граница допустимых значений проходит очень близко к законному и допустимому 0, и переход через неё даёт плохие эффекты; а конкретная реализация этих эффектов может быть весьма разной.
Например, a+b-c из-за подозрения на переполнение заменяют на a-c+b, или a+(b-c); если беззнаковые значения и переполнение… ну тут C гарантирует политику усечения (truncating, она же wrapping для дополнительного кода), но другие могут и иначе подходить.
Или: у меня коллега как-то нарвался:
#include <stdio.h>
#include <fcntl.h>
int main()
{
printf("%llx\n", (off_t)(-sizeof(int)));
return 0;
}
В 32-битном режиме у него дало 0xfffffffc. Тут sizeof, да, заметно — хотя таких граблей он всё равно не ожидал. А если бы размер был сохранён в промежуточной переменной неизвестно какого типа?
С sizeof толком альтернатив нет (хотя его можно сразу переводить в ssize_t и после этого уже только использовать; можно хоть макру написать), но в собственном коде уйти от беззнаковых — значит уйти от целой пачки подобных эффектов.
1. Тип i где задан?
Он будет выведен равным типу len.
Если какой-то из unsigned, то интересно, каким образом он справляется с этим
Тут придётся немного углубиться в то, как в Rust работает цикл for. Если вы хотите сразу перейти к реализации — можете пропустить следующие три абзаца.
В качестве источника значений (то, что стоит после in) в цикле for можно использовать любой тип, реализующий трейт IntoIterator. Этот трейт определяет единственный метод: into_iter. Этот метод возвращает значение, реализующее трейт Iterator. В этом трейте определяются: тип Item (тип элементов, возвращаемых итератором) и метод next с сигнатурой такого вида: fn next(&mut self) -> Option<Self::Item> (а также ещё пачку других методов, но они все имеют реализацию по умолчанию). Цикл for x in iterable { ... } рассахаривается в примерно следующий код:
let mut iter = IntoIter::into_iter(iterable);
loop {
match iter.next() {
None => break,
Some(x) => { ... }
}
}Некоторые типы могут выдавать элементы, условно говоря, не в прямом порядке, а в обратном, и потому могут реализовывать трейт DoubleEndedIterator, в котором определён метод next_back с сигнатурой fn next_back(&mut self) -> Option<Self::Item>. Для подобных типов реализован метод Iterator::rev. Он возвращает адаптер Rev, который реализует Iterator и который в методе next вызывает next_back у нижележащего итератора.
Далее, синтаксис a..b является синтаксическим сахаром для создания полуоткрытого диапазона, т. е. структуры Range — с тем же успехом можно было бы написать Range { start: a, end: b }. Этот синтаксис никак не связан с синтаксисом цикла for и может быть использован отдельно от него. Range, параметризованный примитивным числовым типом, реализует как Iterator, так и DoubleEndedIterator, поэтому в моём примере в цикле вызывается next у Rev<Range<SomeNumericType>>, соответствующий методу next_back у Range<SomeNumericType>.
Таким образом, для того, чтобы определить, какой код вызывается на каждой итерации цикла, нужно смотреть реализацию метода Range::next_back:
impl<A: Step> DoubleEndedIterator for ops::Range<A> {
fn next_back(&mut self) -> Option<A> {
if self.start < self.end {
self.end = self.end.sub_one();
Some(self.end.clone())
} else {
None
}
}
// ...
}Как видно из кода, в структуре хранятся начало и конец диапазона, а так как диапазон не включает верхнюю границу, то верхняя граница уменьшается на единицу перед тем, как она возвращается, а критерием остановки является условие равенства (в общем случае — превосходства) нижней и верхней границы.
Например, a+b-c из-за подозрения на переполнение заменяют на a-c+b, или a+(b-c); если беззнаковые значения и переполнение… ну тут C гарантирует политику усечения (truncating, она же wrapping для дополнительного кода), но другие могут и иначе подходить.
Как уже неоднократно замечали здесь в комментариях, если вам требуется определённое поведение, отличное от оборачивания, то к вашим услугам методы {wrapping, checked, overflowing, saturating}_{add, sub, mul, div}, определённые на всех примитивных целочисленных типах (ну, кроме saturating_div, который непонятно, что должен делать). Если же вам везде нужна семантика оборачивания, то есть newtype Wrapping, который реализует wrapping-методы как арифметические операции. Ничто не мешает написать обёртку, предоставляющую подобные возможности для, скажем, saturating-операций.
Или: у меня коллега как-то нарвался:
Тут проблема в том, что обращение знака почему-то работает на значении беззнакового типа. Аналогоми size_t и off_t в Rust являются usize и isize. size_of и size_of_val возвращают usize, для которого унарный минус попросту не определён, поэтому аналогичный код попросту не скомпилируется.
А если бы размер был сохранён в промежуточной переменной неизвестно какого типа?
То в Rust пришлось бы явно кастить, потому что в нём вообще нет неявных преобразований между численными типами, как и usual ariphmetic conversion из C.
Короче, если у вас проблемы с беззнаковыми числами, то проблема может быть не в самих числах, а в языке.
Какой развёрнутый ответ!
По пунктам ближе к обсуждению:
> то верхняя граница уменьшается на единицу перед тем, как она возвращается
Ага, вот тут и главное. Напрямую на логику цикла в стиле C такое не ложится, а здесь достаточно неплохо интегрировано. Тогда да, проблемы нет.
> Если же вам везде нужна семантика оборачивания, то есть newtype Wrapping
Вот тут постоянный спор в том, каким образом этот режим операций должен быть определён: контекстом, участвующими типами или явным указанием при операции. В реальности можно видеть все три (можно долго перечислять, где что реализовано), но я считаю, что при стандартных целых типах, синтаксический контекст — самый правильный подход именно потому, что наиболее естественно привязывает характер операции к тому, где и как она применяется. Типы в данном случае это, в значительной мере, неизбежный костыль.
С другой стороны, если типы уже подразумевают возможность ограничения допустимых значений (как в Ada, где можно писать в духе type humidity = new integer range 0..100), то типы, да, прямее показывают ограничения. Но тут немножко ещё не тот случай…
> usize, для которого унарный минус попросту не определён, поэтому аналогичный код попросту не скомпилируется.
Вот это правильно, поддерживаю.
> Короче, если у вас проблемы с беззнаковыми числами, то проблема может быть не в самих числах, а в языке.
Ну так по сути это и есть главный вывод — что в C работа с беззнаковыми сделана, мягко говоря, «на отцепись», и в C++ это принято как наследство. И те, кто прошёлся по граблям, могут захотеть запретить это полностью.
Для других языков и политика будет другой.
Нет, речь шла про то в С++ проекте запрещены unsigned int'ы, по вот такой причине. В расте такой проблемы нет, окей, но речь не про него шла.
Проблема при смешении знаковых и беззнаковых операндов при выполнении арифметических операций и операций сравнения.
В C++ беззнаковые операции активно используются из-за того, что их поведение при переполнении стандартизировано, в отличие от знаковых, для которых переполнение — UB.
Не нужно его делать положительным, как зачем-то сделал автор.
К тому же человек, который это написал, видимо не знаком с представлением чисел в дополнительном коде.
if (h < 0) h += MAX_INT;
INT_MIN -2147483648 Defines the minimum value for an int.
INT_MAX +2147483647 Defines the maximum value for an int.
В сумме дадут -1
По пункту 1: В расте взяли -fwrapv из llvm и сказали что это фича раста.
Минусаторы не хотят объяснить отличия если это не так?
Я так и написал: "сделали то-то и то-то (дело техники) и сказали что фича раста". Я не обсуждал является оно фичей или нет. Формально является, но не с точки зрения технологий, а с точки зрения менеджмента. Последнее тоже важно, но лично мне не так интересно. Более того, раз мы говорим про сравнение с С++ в этой теме, то эта же фича достигается выставлением соответсвующего флага компилятору. Т.е. по сути она не уникальна, как можно было подумать прочитав статью (что я и подчеркнул в комментарии). Ну окей, мы упростили задачу менеджемнта и теперь никто не забудет выставить нужный флажок.
Теперь напрашивается вопрос, раз это такой полезный флажок который надо было просто насильно добавить компилятору как это сделали в расте, то почему так не сделали в clang? На этот вопрос дает ответ Антон:
При этом за счет того, что они документируют это поведение, Rust теряет возможность делать многие оптимизации.
Речь тут вот о чём. Если у вас есть
if (x + 100 > x) { /* do something */ }То в нормальной математике условие всегда верно и компилятор его выкидывает. Это оптимизация? — мой ответ да (можно попробовать придумать менее тривиальные примеры). За цитатой Антона следует фраза автора данного поста:
Я бы почитал, какие оптимизации не умеет Rust, особенно с учётом того, что в основе Rust лежит LLVM — тот же самый бэкенд, что и у Clang.
Да вот такую оптимизацию выше он и не умеет! Ещё раз, что делает раст: он говорит компилятору LLVM (через ту самую опцию -fwrapv) не делать такую оптимизацию, потому что она опасна. Ведь на компьютере математика циклична и при добавление к MAX_INT мы получаем отрицательное число (на большинстве цпу). Поэтому условие не обязательно всегда верно. Итого clang оставляет программисту больше пространства для манёвра (что бывает вредно — хтож спорит), и тем самым даёт возможность применить больше оптимизаций. Но по-хорошему некому Антону надо сидеть с ручкой и листиком и доказывать что нету переполнений.
Хотя выше вспоминали другое решение данной проблемы, которое переносит все проверки в компайл-тайм. Наример safe_numerics из boost. Кстати в раст такого пока сделать нельзя (или же будет супер громоздко).
По сути идея та же, упроситить людям жизнь в случае переполнений численного типа, но детали разные. И флаг -fwrapv уже можно смело выкидывать, но не в раст т.к. там его видимо прибили гвоздями. Дело в том что в низкоуровневых языках "дело техники" имеет значение. Потомучто иначе, можно пойти и путём питона, где в случае переполнения int автоматически идёт переключение на длинную арифметику. И это уже абсолютно другой результат с точки зрения оптимизаций, удобства и всего этого.
Апд: Ха-ха про safe_numerics вы сами и вспомнили, кароче не мне вам рассказывать :)
Речь тут вот о чём. Если у вас есть
if (x + 100 > x) { /* do something */ }
То в нормальной математике условие всегда верно и компилятор его выкидывает.
Так это в математике у вас ℤ, а на компьютере что-то вроде ℤ/2n
Более того, раз мы говорим про сравнение с С++ в этой теме, то эта же фича достигается выставлением соответсвующего флага компилятору.
Который не всегда работает.
То в нормальной математике условие всегда верно и компилятор его выкидывает.
В модульной арифметике-то?
В модульной арифметике-то?
У вас тоже терпение кончилось дочитать до конца. Вот пишешь кратко — не нравится, занудствуешь — не читают. Как найти золотую середину...
Окей.
Да вот такую оптимизацию выше он и не умеет! Ещё раз, что делает раст: он говорит компилятору LLVM (через ту самую опцию -fwrapv) не делать такую оптимизацию, потому что она опасна. Ведь на компьютере математика циклична и при добавление к MAX_INT мы получаем отрицательное число (на большинстве цпу). Поэтому условие не обязательно всегда верно. Итого clang оставляет программисту больше пространства для манёвра (что бывает вредно — хтож спорит), и тем самым даёт возможность применить больше оптимизаций.
Умеет. https://doc.rust-lang.org/nightly/std/intrinsics/fn.unchecked_mul.html + https://doc.rust-lang.org/nightly/std/hint/fn.unreachable_unchecked.html.
С++ идет путём доверия программисту: если он что-то пишет, значит он решил, что это правильно.
Раст идёт иным путём: давайте всё сделаем безопасно, но если человек так уж хочет отстрелить себе ноги в оптимизациях, давайте дадим ему эту возможность, но делать ему это будет явно неудобнее, нежели если бы он писал обычный сейф код.
А зачем для такого выключать проверки в release-сборке и переводить арифметику на модульную?
Или release уже целиком считается «тут можно отстреливать ноги»?
А зачем для такого выключать проверки в release-сборке
Затем, что иначе набежали бы Антоны и говорили, что каждая арифметическая операция создает дополнительный бранч, что создает накладные расходы.
Эту опцию и так скрыли под -C overflow-checks=on, но Антон всё равно её раскопал и начал всем твердить, что арифметика в расте тормозит.
Вы отвечаете на какой-то совсем другой вопрос, а не мой. Почему режим операций зависит от общего режима сборки?
Для, грубо говоря, >90% кода проверки важнее скорости и в дебаге, и в релизе — он не является critical path. Для кода, критичного по скорости, расслабленный режим нужен и в дебаге (чтобы оно хоть как-то успевало). Почему я должен полагаться на режим сборки, а не явно выставленные мной политики для конкретного модуля, функции или другой единицы трансляции? Где управление этими политиками с нужной программисту грануляцией?
Да, для какой-то очень малой части кода я действительно захочу политику типа «panic — в debug, другое — в release (причём не обязательно truncating, это может быть и relaxed), но кто лучше, чем сам автор кода, знает, где можно делать послабления?
Где управление этими политиками с нужной программисту грануляцией?
Семейство функций wrapping*, saturating*, overflowing* и checked*
А по-умолчанию я хочу максимально безопасный код в дебаге, и возможно не такой безопасный, но более быстрый код в релизе. Это разумное допущение, как мне кажется. Если вы с этим не согласны, пишите арифметику в том виде в котором считаете нужным.
возможно не такой безопасный
Всё же он будет без UB.
[Forwarded from Αλεχ Zhukovsky]
в расте разница такая же как между паникой и уб
[Forwarded from Constantine Drozdov]
Ну вот как ошибочная программа сигнализирует, что она ошибочная, уж точно оффтоп, помилуйте. Здесь, кажется, как раз «как сделать программы без ошибок» основная тема
[Forwarded from Αλεχ Zhukovsky]
разница очень существенная
[Forwarded from Αλεχ Zhukovsky]
от паники ханойские башни не запускаются и rm -rf не выполняется
[Forwarded from Constantine Drozdov]
а от уб абандон мьютексы не получаются
> Это разумное допущение, как мне кажется.
Именно что нет. Разумное допущение для большей части кода (всё кроме критических путей) — всегда проверять, даже в релизе, а опасные места огораживать явными флажками. А вариант с тотальным наплевательством в релизе это «Вы, когда в СССР въезжали, красный флаг на границе видели?»
Но, чтобы это было эффективно в плане расходования усилий программиста, надо, чтобы нужный вариант автоматически подключался на операции в обычной записи.
Это должно делаться сторонними инструмент, а не самим компилятором. Иначе в стд раста такими темпами Гамма-функцию протащат.
И такой инструмент есть https://crates.io/crates/overflower.
Умеет. https://doc.rust-lang.org/nightly/std/intrinsics/fn.unchecked_mul.html + https://doc.rust-lang.org/nightly/std/hint/fn.unreachable_unchecked.html.
Ага я думал это глобальный флаг. Оказалось прикольно что llvm позволяет выставить это свойство для каждой операции add, но соответсвующих интринзиков для clang я сходу не нашёл, а в расте есть.
Который не всегда работает.
А про это можно было бы и подробнее. Хотя я могу прикинутся шлангом и сказать что это не С++ а детали реализации, не более. Не, а если серьёзно то расскажите, узнаю что-то новое для себя.
В статье была ссылка: https://gcc.gnu.org/bugzilla/show_bug.cgi?id=35412
Это -ftrapv и gcc, это другое. В clang должно работать, иначе в расте бы тоже не работало, по логике.
https://bugs.llvm.org/show_bug.cgi?id=45784
В Расте это работает немного иначе. Поэтому и работает корректно: https://godbolt.org/z/SVgkEV
Три момента:
- В России раст пока получил куда меньшее распространение, чем в Европе. Возможно даже, из-за обсуждаемого тут доклада)
- Вопрос в качестве этих вакансий. Если нет желания копаться в легаси и древних технологиях, то эту цифру нужно делить на какой-то коэффициент.
- Может мне не повезло, но почему-то на первой странице я вообще не нашел С++ — только шарп, джава и PHP.
Это выглядело бы как попытка доказать что C — лучше, быстрее и популярнее, чем C++ сегодня: смешно и грустно.
Там где данным можно более-менее доверять (GitHub) разница вдвое в пользу C++ и растёт.
Роман, спасибо за статью.
Конечно же многие из с++ сообщества будут сопротивляться… представьте что вы потратили на инструмент сколько-то лет (может — много) а его потом хотят отбросить в прошлое. Кому же это понравится? Так что эту защиту территории можно понять…
Я отклыдывал знакомство с Растом и относился к нему скептично (я мигрировал на java несколько лет назад, устав бороться с с++ как инструментом). Бегло посмотрел — по-моему весьма неплохо. Если компилятор помогает в контроле памяти — это же круто. Синтаксис макросов показался сложноватым, и вот непонятно — как-то можно развернуть макрос чтобы увидеть во что он превращается? — это было бы очень полезно.
То что Раст не защищает от всех ошибок, не должно нивелировать то от чего он всё-таки защищает, т.к. с++ не делает и этого.
как-то можно развернуть макрос чтобы увидеть во что он превращается?
-Z unstable-options --pretty expanded
Синтаксис макросов показался сложноватым
Для написания своих макросов во многих случаях можно использовать чужие макросы (https://dev.to/jeikabu/rust-derive-macros-o38). Писать derive макросы таким образом очень удобно.
как-то можно развернуть макрос чтобы увидеть во что он превращается?
Есть еще сахар для команды выше в виде github.com/dtolnay/cargo-expand
Я отклыдывал знакомство с Растом и относился к нему скептично
Очень зря. Рекомендую попробовать. Использовать одно удовольствие :)
Недавно я пытался заманить коллегу, сишника из соседнего отдела, на Тёмную сторону Rust
Замечаю неприятную тенденцию превращения программистов из инженеров в маркетологов.
Всегда было так. Иначе бы у нас не было горы примеров, как не особо хорошая, но распиаренная технология взяла верх над более разумной альтернативой.
Прямо представил — выходишь такой пообедать на кухную, а к тебе пристает коллега:
«Привет! Не хочешь поговорить о новом замечательном языке Rust? По данным опроса Stack Overflow это самый любимый программистами язык!».
А что плохого? Если я буду не в настроении общаться с кем-то, или тема будет явно не интересна, то я просто скажу "отстань". Но в целом я не против посраться подискутировать на техническую тему, будь то Rust/Go/очередной web фреймворк для питона или хз еще что. Нельзя же только обсуждать, у кого как тугосеря покак сделал. Ну и не понимаю, почему нельзя одновременно быть маркетологом и инженером?
Прямо представил — выходишь такой пообедать на кухную, а к тебе пристает коллега:
«Привет! Не хочешь поговорить о новом замечательном языке Rust? По данным опроса Stack Overflow это самый любимый программистами язык!».
Я так и делал. И про Раст, и про хаскель, и про идрис. Сейчас я примерно так с нашими саппортами общаюсь, которые на питоне пишут и страдают. Дать человеку выбор, рассказать, что вот есть инструмент который решает такую вот боль — чем плохо? Пусть сам проверяет, не понравится — не будет пользоваться.
Реклама это не плохо, если она объективная. Ну то есть когда вам не льют враньё в уши, а просто рассказывают про достоинства, и возможно недостатки. Я вот никогда не узнал бы что экспрешн проблем на самом деле имеет решение если бы мне не продали поездку на ФП конференцию где про это рассказали. Я бы никогда не узнал что можно писать без изменяемых данных вообще, но программа будет делать что-то полезное. Я бы никогда не узнал, что когда у меня есть асинхронный интерфейс в двумя реализациями, одна из которых полностью синхронная и вызывает Task.FromResult на каждом методе — что это костыль и можно лучше.
Спасибо тем, кто мне рекламировал ФП и всё это, даже не меняя языка и оставаясь в рамках сишарпа я начал писать куда более красивый и понятный код. Реклама — способ донести информацию, которую иначе люди никогда не услышат, потому что обычно они сидят в своём инфорационном пузыре и изучают тысячный способ сделать то что они давно умеют делать. Людей, которые по своей воле начинают вылезать из скорлупы и что-то пробуют — единицы.
Просто надо быть честными и не рекламировать того, чего нет. Тогда всё будет хорошо.
Я так и делал. И про Раст, и про хаскель, и про идрис.
Вам наверное тогда и свидетели Иеговы нравятся? Они всем очень убедительно рассказывают, как можно стать счастливым.
Реклама это не плохо, если она объективная
Очевидно у нас разные понятия рекламы. Я люблю послушать чем занимаются коллеги и рассказать, чем занимаюсь я и какие проблемы я смог решить. Кого я не люблю, это евангелистов. То есть людей, которые просто втюхивают тебе технологию как товар на базаре.
Просто надо быть честными и не рекламировать того, чего нет.
В этом моя претензия. Особенно на конференциях, беспристрастная подача информации почти не встречается. Ну то есть не просто засрать Rust потому что ты член комитета ISO по С++, а рассказать как ты пытался написать что-нибудь на нем и какие проблемы возникли.
Вам наверное тогда и свидетели Иеговы нравятся? Они всем очень убедительно рассказывают, как можно стать счастливым.
Нет, потому что они лгут. А вот против общеобразовательных передач в стиле "В мире животных" или "один день из жизни врача" не имею никаких проблем.
Очевидно у нас разные понятия рекламы.
Очевидно
Реклама это не плохо, если она объективная*при этом объективная она или нет на усмотрение рекламирующего субъекта.
Например, когда растовитяне рекламируют язык сравнивая его с плюсами, часто можно увидеть аргументы вида «он безопаснее». Бесспорно. Однако когда начинаешь разбираться в том, насколько он безопаснее, постоянно проскакивают сравнения кода на расте 2015-ого года с кодом на плюсах 1998-ого, а иногда и на чистом си. Емнип я именно вас на этом и ловил. Ну то есть мы рассказываем какой раст классный совершенно упуская что за последние 20 лет плюсы тоже развивались, и что пропорция логических ошибок к ошибкам памяти в них очень сильно выросла. Да, мы можем в 100500-й раз привести в пример статистику майкрософта и проигнорировать, что она собрана с кодобаз старше многих хабражителей.
От евангелиста раста никогда не услышишь что некоторые вещи может быть довольно сложно выразить в расте, что его библиотеки зачастую сырые, что иногда приходится писать много бойлерплейта. Но это услышишь от людей которые на расте пишут в прод. А таковых, к сожалению, пока что меньше чем уставших от других языков и написавших пару мелких петов на расте.
В общем, либо не претендуйте на объективность, либо не забывайте про вторую сторону медали.
Например, когда растовитяне рекламируют язык сравнивая его с плюсами, часто можно увидеть аргументы вида «он безопаснее». Бесспорно. Однако когда начинаешь разбираться в том, насколько он безопаснее, постоянно проскакивают сравнения кода на расте 2015-ого года с кодом на плюсах 1998-ого, а иногда и на чистом си.
Спросите у humbug или еще кого-нибудь из плюсисто-растистов с богатым опытом об их опыте. Мне трудно оценивать, в том числе именно потому, что я шарпист, и С/С++ никогда не изучал, мой путь был из паскаля в дельфи, а оттуда сразу в сишарп.
Ну и вопрос не только в безопасности же. Тут и вопрос удобства, и тулинга, и всего остального.
Емнип я именно вас на этом и ловил. Ну то есть мы рассказываем какой раст классный совершенно упуская что за последние 20 лет плюсы тоже развивались, и что пропорция логических ошибок к ошибкам памяти в них очень сильно выросла. Да, мы можем в 100500-й раз привести в пример статистику майкрософта и проигнорировать, что она собрана с кодобаз старше многих хабражителей.
Поэтому возможно вы меня и ловили, потому что я пишу так, как показывает стаковерфлоу и гугл. На расте у меня так его выучить и написать что-то полезное получилось, на плюсах — нет. Доказывает ли это что плюсы плохи или раст хорош или что я не умею в языки программирования? Вопрос спорный.
Но у меня сложилось впечатление, что "готовить" плюсы правильно — сложно или невозможно.
От евангелиста раста никогда не услышишь что некоторые вещи может быть довольно сложно выразить в расте, что его библиотеки зачастую сырые, что иногда приходится писать много бойлерплейта. Но это услышишь от людей которые на расте пишут в прод. А таковых, к сожалению, пока что меньше чем уставших от других языков и написавших пару мелких петов на расте.
Ну я не евангелист раста — хаскель или идрис мне нравятся куда больше, но да, всё так — многие библиотеки сыроваты (я вот искал сваггер для actix, единственное решение что есть мне не очень понравилось), куча вещей выражается хреново (любые юайные вещи, наследования ведь нет, всякие графы-матрицы-етц, пины — ужасный костыль). Вот бойлерплейта не видел — гигиенические макросы и атрибутные макросы решают этот вопрос достаточно надёжно. В остальном — да, есть минусы. Если их скрывают — вполне вероятно это просто воинствующие фанаты, а не евангелисты, продать информацию которая потом окажется неправдой — работает в минус языку, поэтому адекватные люди так не делают.
В общем, либо не претендуйте на объективность, либо не забывайте про вторую сторону медали.
Да я в общем-то не против, в статье про то что го обошел раст например я обозначил, почему так произошло, и как этот гап можно ликвидировать, но я не писал разгромных статей "автор, ты ничего не понял, кто ж так пишет". Наверное, так и стоит делать разумным людям.
Но у меня сложилось впечатление, что «готовить» плюсы правильно — сложно или невозможно.Не то, чтобы невозможно. Просто каждую строку нужно писать так, как если бы компилятор везде и всюду хочет тебя «подставить». Вот, кстати, прекрасный пример. Вот именно на тему управлением жизни объектами. Как известно Core Guidelines советуют передавать unique_ptr в конструктор объекта, который, потом, этим объектом будет заведовать. Вот только если глянуть на сгренерённый код — то легко видеть, что семантика-то у этого деяния совсем-совсем другая! Когда вы передаёте
unique_ptr (в полном соотвествии «с рекомендациями лучших собаководов») — вы, на самом деле, говорите компилятору «дай этой функции за этот объект „подержаться“… если она его „заберёт“ — то ничего не делай, а если не захочет — ну тогда удали его». А конструктор, со своей стороны, забирает себе объект, и «отчитывается» — «да-да, точно-точно, забрал я объект, можешь успокоиться».Понятно, что если обе функции у вас в одном файле и заинлайнятся, то лишний код выкинется… но нельзя же, в самом деле, верить в то, что всё вседа во всё инлайнится?
Вот и сравните вот это вот (а это, напоминаю, как раз «самый людчий», «самый новейший», «самый рекомендрованный» подход) — с тем, что, в таких случаях делает Rust.
Почти на 100% уверен, что это вызовет очередную истерику и объяснение, что тот факт, что так рекомендуют делать все «светила» в области C++ — неважен, потому что подход C++98 — более эффективен…
Не то, чтобы невозможно. Просто каждую строку нужно писать так, как если бы компилятор везде и всюду хочет тебя «подставить».
По-вашему это возможно для сколько-нибудь крупного проекта? Для меня "Просто пишите без ошибок" кажется немного издевательским тезисом.
unsafe Rust + safe Rust должны бы сработать не хуже.Спросите у humbugну вот вы сослались на парочку самых ярых «воинствующих фанатов» на хабре. Вы, судя по многочисленным комментариям, вполне себе сходите за третьего. Сколь-либо статистически значимый опыт написания коммерческого кода на расте из вас троих емнип есть только у humbug'а. Один из трех, 33%. Понимаете, о чем я?
«готовить» плюсы правильно — сложно или невозможно.
Если я сколько-нибудь прав, то у них тоже «туннельное зрение», а в спорах позиция по типу «чего в с++ нет — то не нужно, а что есть в с++ а нет у других — то важно».
Мне ребята написавшие статью показались убедительными. Какое-то адвокатирование я бы оставил за скобками — сам факт защиты или рекламы не обнуляет их аргументы. В конце концов сам Антон из Яндекс бросил перчатку (делая такой доклад — чего он ожидал?).
Сам я тоже не эксперт в этих областях, но мне кажется что некоторые изъяны с++ носят глубокий характер (например работа с сырыми указателями) и без радикального изменения языка с утратой совместимости этот язык не потюнать ни 2020 стандартом, ни 2050. Последний раз я пользовался языком в 2015 году, потом новых фич ещё прибыло, но увеличилась когнитивная нагрузка (и без того большая). Сейчас мне развитие с++ напоминает попытки исправить яму углубляя и роя её ещё дальше.
Я часто слышал что «вы просто не умеет готовить». Это верно только отчасти, т.к. готовить из хороших продуктов всё-таки легче.
На хабре куда больше трех человек которые шарят в обоих языках, просто они не так часто комментируют.
Хотя я и не пишу на плюсах, у меня есть достаточно богатый опыт общения с людьми, которые это делают. И у меня сложилось вполне определенное впечатление. Бонусом узнал много интересного про CryEngine.
Вы, судя по многочисленным комментариям, вполне себе сходите за третьего.
Ну спасибо.
Сколь-либо статистически значимый опыт написания коммерческого кода на расте из вас троих емнип есть только у humbug'а
Вот мне было бы интересно почитать про такой опыт. К сожалению, таких статей как-то не находил (на хабре). Зато кидание фекалиями с кривыми написанными на коленке бенчмарками всем заходит на ура.
Ну вот я пишу в прод на Rust, и, на самом деле, никаких дополнительных преимуществ Rust или его недостатков прод не вскрыл в сравнении с тем, что было уже понятно на фазе изучения языка и разработки хобби-проектов.
То есть писать-то особо и не о чем, кроме как повторять то, что уже было сказано десятки раз.
сложно или невозможно.
0xd34df00d? Ваше мнение ?
С количеством строк кода сложность превращается в невозможность.
Сразу уточню: я имею в виду любые ошибки, в т.ч. логические
Вы ожидаете ответ "такого языка нет", на чыто ответите "НУ ВОТ ВИДИТЕ!!". Такое себе.
А вот языки, где можно совершить практически только логическую ошибку (то есть неправильно понять спеку) — есть.
Кстати, отсюда же вопрос: если Вася складывает метры с дюймами и у него ракеты падают и самолёты переворачиваются при пересечении линии перемены дат, а Петя использует ньютайпы чтобы метры и дюймы в разных структурах хранить — ошибка сложения не того и не с тем — логическая или нет?
А вот языки, где можно совершить практически только логическую ошибку (то есть неправильно понять спеку) — есть.раст не относится к языкам где можно совершить только логические ошибки ибо unsafe.
ошибка сложения не того и не с тем — логическая или нет?если Петя позаботился о переносе единиц измерения в пространство типов, т.е. во время компиляции, он молодец. Такое можно (и нужно) делать во многих языках, включая и раст с плюсами. Но если например обратиться к блогу PVS Studio, они в основном лечат не UB а ошибки вида «не там скобки», «не тот логический оператор», «не та переменная» и пр.
Мой поинт в том, что если Вася писал на с++ и сделал 12 ошибок, а Петя писал на расте и сделал 10, не надо продавать раст как инструмент, гарантирующий спасение от ошибок.
Ну и при прочих равным можно проворачивать более сложные рефакторинги или проворачивать той же сложности быстрее.
В конечном счёте это всегда вопрос стоимости разработки, ошибок и поддержки кода.
В конечном счёте это всегда вопрос стоимости разработки, ошибок и поддержки кода.программистов на с++ в десятки раз больше, их средний опыт выше в несколько раз, а ожидания зп в среднем ниже.
Средний опыт использования языка — меньше, но опят в целом — ой не факт.
Про зп тоже спорно. Точно есть люди, вполне готовые поступиться частью зп, но писать при это на более удобном им Rust.
Более объективно: в областях, где пока нет своих библиотек и хороших обёрток — там очевидно Rust проигрывается (тупо надо писать больше кода). В остальных — очевидного перевеса нет.
С количеством готов согласиться. Остальное бездоказательно.за статистикой далеко ходить не надо. Причем учтите, что горизонтальная шкала — «years of professional programming experience», т.е. общий опыт разработки, а не на конкретном языке. Опыт программирования на расте в 5+ лет имеют преимущественно те, кто его разрабатывал.
Средний опыт использования языка — меньше, но опят в целом — ой не факт.
Про зп тоже спорно. Точно есть люди, вполне готовые поступиться частью зп, но писать при это на более удобном им Rust.
Так? ))))
раст не относится к языкам где можно совершить только логические ошибки ибо unsafe.
Пишите без unsafe, никто не запрещает. Да и unsafe вполне себе можно валидировать.
Мой поинт в том, что если Вася писал на с++ и сделал 12 ошибок, а Петя писал на расте и сделал 10, не надо продавать раст как инструмент, гарантирующий спасение от ошибок.
Инструмент, гарантирующий от 2 ошибок из 12. Правда, учитывая статистику от всяких макйрософтогуглов там помощь чутка побольше, чем одна ошибка из шести.
Правда, учитывая статистику от всяких макйрософтогуглов там помощь чутка побольше, чем одна ошибка из шести.
Да, мы можем в 100500-й раз привести в пример статистику майкрософта и проигнорировать, что она собрана с кодобаз старше многих хабражителей.(с) я.
Ну приведите другую. Пока более точной нет, приходится руководствоваться той, что есть. Ну и сарафанным радио, конечно.
Буду только рад услышать более точную информацию.
Пока более точной нет, приходится руководствоваться той, что естьблин, вы пытаетесь натянуть статистику, собранную по си/си с классами, на современный с++. Отсутствие альтернатив не делает её более корректной. Это как если бы я сказал что «вон та планета вон там-где-вы-не-видите обитаемая» и вы за отсутствием опровержения или более достоверной информации приняли бы это утверждение за истину.
уменьшению ошибок в более новых плюсах заметна
Там отслеживается количество ошибок в ответах на stack overflow. Количество ошибок начало снижаться после 2011 года (пика популярности C++ на github), так что этот результат может быть частично объяснен снижением количества ответов от новичков.
Количество ошибок начало снижаться после 2011 года (пика популярности C++ на github)статистика популярности языков от github. Был локальный максимум в 2014-м, сейчас популярность с++ растет. Я бы сказал что корреляции нет
Да, ошибся с датой и интерпретацией. В статье приводится 2013-й год: "If one hypothesizes that StackOverflow usage reflects the popularity of the programming language, C++ has been the most popular programming language in 2013, and its usage declined after that."
2011 — это год, когда в ответах на StackOverflow появлялось максимальное количество кода с уязвимостями и максимальное количество уязвимостей переносилось в проекты на GitHub.
Я бы сказал что корреляции нет
В этом исследовании нет данных, чтобы проверить корреляцию количества ответов новичков и количества уязвимостей. Нужны дополнительные исследования, а пока "Новые версии C++ приводят к уменьшению числа уязвимостей" — это гипотеза, которая не лучше и не хуже "Снижается количество новичков, отвечающих на вопросы по С++ на StackOverflow"
Нужны дополнительные исследованияох уж эта демагогия. Значит как мы приводим совершенно нерелевантное исследование от MS, то «пока более точной нет, приходится руководствоваться той, что есть», а как я привожу исследование которое хотя бы релевантно, так «нужны дополнительные исследования».
«Новые версии C++ приводят к уменьшению числа уязвимостей» — это гипотезаэту гипотезу подтвердит опыт практически любого с++ программиста.
«Новые версии C++ приводят к значительному уменьшению числа уязвимостей, сравнимому с использованмем Rust, при сравнимом количестве ресурсов»
Будет правильнее. А то, что новые версии плюсов делают не хуже, а в чем-то лучше, вроде, очевидно.
Согласен. Очевидно, что новые версии плюсов дают инструменты для уменьшения количества ошибок и уязвимостей.
Для перехода к "и это вызывает значительное уменьшение числа уязвимостей" нужно ещё "большая часть новых проектов и нового кода в старых проектах пишется с использованием возможностей предоставляемых новыми версиями C++ и их совместное использование со старой кодовой базой не вызывает значительного роста числа ошибок".
… и их совместное использование со старой кодовой базой не вызывает значительного роста числа ошибокуж точно не вызывает большего роста ошибок, чем переход на раст с написанием 100500 unsafe оберток над сишным/плюсовым легаси кодом.
Ну то есть если мы пишем с нуля проект, основанный только на полнофункциональных и качественных библиотеках, то возможно
Сразу уточню: я имею в виду любые ошибки, в т.ч. логические
отсюда вывод, что надо писать на максимально лаконичных языках? Ну, типа — меньше строк — меньше проблем ?
Он же его недавно высказывал: Пора на свалку.
Особенно заметно по докладу "Незаменимый C++"? =)
Ваше предложение? Давайте свое опровержение "Мифа 4".
Также нахожу странным, что в пункте «Миф №4. Rust медленнее C++.» пытаются сказать, что «больше асма → медленнее язык» — не применимо к Rust в рассмотренных примерах
В рассмотренных примерах Антона асма в расте больше. А я привёл другой пример, когда раст генерирует меньше асма. Это значит, что где-то раст будет генерить больше асма, где-то меньше. Поэтому для утверждения, что раст медленнее, надо писать бенчмарки.
Аргументация Антона очень похожа на когнитивное искажение под названием предвзятость подтверждения.
По простому весь параграф к Мифу №4 можно свести к "пиши негативные тесты".
Я бы почитал, какие оптимизации не умеет Rust
например такую:
pub fn square(num: i32) -> i32 {
num * 2 / 2
}как выразился бы автор доклада, "опять лишний раз трогает память"
Да, различие в семантике знаковых целых. В расте придётся писать pub fn foo(x: i32) -> i32 { x }. Впрочем, в С++ с беззнаковыми целыми тоже придётся оптимизировать *2/2 вручную.
естественно, если компилятор не выполняет определенную оптимизацию, то её придется делать вручную. Вы там с чем-то не согласны, или что?
Уточнил почему Rust не выполняет эту оптимизацию: потому что она некорректна.
бгг. Ну тогда советую создать тикет в багтрекере LLVM: "ребята, у вас тут некорректная оптимизация" :)))
LLVM поддерживает как раз оба варианта, и из плюсов и из раста можно их оба использовать. Отличие только в варианте по умолчанию, выше в комментах уже выяснили.
Дак я и не против. Это red75prim заявляет, что она некорректна, все претензии к нему :)
LLVM тут не при чём. С++ тоже не оптимизирует unsigned_int*2/2, не потому что в LLVM баг, а потому что беззнаковое переполнение не является undefined behavior согласно спецификации C++. А в Rust'е и знаковое переполнение — не undefined behaviour, в отличие от C++.
Так же как и Котлин стал 'подпирать' Жаву, что бы не расслаблялась.
Мобильная разработка — Java/Kotlin ну и так далее.С этого момента — поподробнее. Напомню, что если вы типичный мобильный разработчик, то вы где-то ⅔ денег получаете от фанатов «яблока» и ⅓ — от Android… ну или ближе к половинке-на-половинку, если вы активны на рынке Китая. Как сюда вписывается Java/Kotlin?
Плюсы давно уже не самый популярный язык, и ниша уменьшается с каждым годом.Плюсы уж «самыми популярными» никогда не были, но в пятёрку они входили всегда. И сейчас входят. Есть, правда, беда: HR часто рассматривают C и C++ как один язык, но, в общем… «слухи о смерти C++ таки очень сильно преувеличены».
Напомню, что если вы типичный мобильный разработчик, то вы где-то ⅔ денег получаете от фанатов «яблока» и ⅓ — от Android… ну или ближе к половинке-на-половинку, если вы активны на рынке Китая. Как сюда вписывается Java/Kotlin?
Ok, забыл Swift/Objective C — как это меняет картину?
«слухи о смерти C++ таки очень сильно преувеличены».
Есть мнение, что tiobe не самый лучший индикатор популярности. Как пишут они сами
Popular search engines such as Google, Bing, Yahoo!, Wikipedia, Amazon, YouTube and Baidu are used to calculate the ratings. It is important to note that the TIOBE index is not about the best programming language or the language in which most lines of code have been written.
То есть это тупо тренды в поисковиках/ютубе. К количеству вакансий отношение косвенное.
Ok, забыл Swift/Objective C — как это меняет картину?Это меняет картину принципиально, как ни странно. Потому что у вас есть возможность написать две реализации — одна на Swift/Objective C, другая на Java/Kotlin… или одну — на C++.
В результате C++ в мобильных приложениях отнюдь не редкость. Вот ни разу не редкость.
То есть это тупо тренды в поисковиках/ютубе. К количеству вакансий отношение косвенное.Ну возьмие вакансии, если хотите. Java — 8440, C++ — 7524… Но да, это C и C++ вместе. Можете Kotlon ваш любимый добавить — ещё 364 вакансии.
Возможно сегодняшние выпускники, к их выходу на пенсию, таки увидят закат C++… но и то не факт.
В результате C++ в мобильных приложениях отнюдь не редкость. Вот ни разу не редкость.
Громкие слова. Приведете пример?
Ни разу не слышал о С++ как о граале кроссплатформенной разработки.
На расте, если что, чтобы скомпилить под ARM мне понадобилось буквально 2 команды (одна из них для установки тулчейна). Сколько времени понадобится для этого на С++?
Kotlon ваш любимый
Это Kotlin, если что. На котором пишут под мобильные исключительно (он продвигается фанатами вроде вас, которые пытаются продать его всюду — пока выходит не очень).
Возможно сегодняшние выпускники, к их выходу на пенсию, таки увидят закат C++
Какой закат? На коболе, перле, visual basic сейчас вполне пишут и будут продолжать писать пока все легаси не сдохнет. Просто их ниша уменьшается ежегодно, как и у С++.
Тогда какую, по вашей оценке, долю рынка, на котором присутстует Кобол, он занимает в процентном выражении от общего числа разработчиков на этом рынке?
И что по-вашему закат ЯП?
И что по-вашему закат ЯП?Я бы сказал «закат» — это отсуствие востребованности на рынке… и уменьшение интереса со временем.
Вот сравните, к примеру, Cobol и Rust. Уже сейчас количество предложений для Rust — вдвое выше, чем для Cobol… и разница таки действительно, растёт.
А вот с C++ — это ни разу не так. Доля рынка, возможно, и падает — но и сейчас она сравнима с лидерами (Java, Python) и заметно выше, чам, скажем, у C#… а вроде как C# — не самый экзотический язык, согласитесь?
Вообще
Rust — один из немногих язков, который, хотя бы чисто теоретически, может «похоронить C++»: потому что он, по крайней мере в теории, без C++ может обойтись. Все же остальные «хайповые» языки в принципе не претендуют, скажем, на возможность написания на них операционки (забавно, что как раз C# на эту роль, как известно, серьёзно готовили… в результате Microsoft успешно профукал все рынки, кроме десктопа, что, может быть, и хорошо… но операционки остались написанными на C/C++ — с добавлением и других, разных для разных операционок, конечно, языков).Громкие слова. Приведете пример?Пример чего извините? Ипотенции вашего любимного Kolton'а? Вот, пожалуйста. Самое хайповое направление на сегодня: нейронные сети. Если хотите использовать в Android — вам придётся забыть про Java. И то же самое — если захотите использовать Vulkan.
На котором пишут под мобильные исключительно (он продвигается фанатами вроде вас, которые пытаются продать его всюду — пока выходит не очень).«Выходит не очень», во многом, именно потому что несмотря на хайп и миллиарды вбуханных денег C#/Java не смогли заменить C++.
Одно время вокруг «полного перехода на managed языки» была куча хайпа. И были даже люди, которые в это верили. Практический результат — крушение Sun и потеря Microsoft титула «лидер индустрии». А C++ как раз выжил и, в послденее время, всё больше API разрабатываются так, что из
managed мира они недоступны. Примеры я выше приводил.Сколько времени понадобится для этого на С++?Те же самые две команды. Одна из них будет
apt-get install. Ну или если вы фанат Visual Studio, то можете запустить её инсталлятор и крыжик там поставить.Ипотенции вашего любимного Kolton'а
Вас в школе правописанию учили, юноша? Или вы еще не окончили?
Пишется K-o-t-l-i-n. Это латиница, если что — может в вашей деревне такое не изучают.
Если хотите использовать в Android — вам придётся забыть про Java.
Если хотите использовать какой-то API от гугла. Встроенные нейросети есть на любом языке.
Собственно, примеров нет, как я и говорил. Тот же tensorflow используется только через Python или JS обертку, лол. Несмотря на то что ядро пока на С++.
C#/Java не смогли заменить C++
всё больше API разрабатываются так, что из managed мира они недоступны
Подобную чушь я даже комментировать не буду. Sapienti sat.
Самое хайповое направление на сегодня: нейронные сети. Если хотите использовать в Android — вам придётся забыть про Java. И то же самое — если захотите использовать Vulkan.
Это низкоуровневые системные API, не имеющие к C++ никакого отношения, кроме описания API на языке C и схожести синтаксисов C и C++.
всё больше API разрабатываются так, что из managed мира они недоступны.
В чём именно это проявляется?
Это низкоуровневые системные API, не имеющие к C++ никакого отношения, кроме описания API на языке C и схожести синтаксисов C и C++.Конечно-конечно. API библиотеки, написанной на C++ и используемой из C++, разумеется, никакого отношения к C++ не имеют.
Да, не имеет абсолютно никакого отношения. API там — чистый C, функции-врапперы для C++ кода.
API библиотеки, написанной на C, не имеет никакого отношения к C++. Именно поэтому есть отдельный проект — враппер в C++: https://github.com/KhronosGroup/Vulkan-Hpp
API библиотеки, написанной на C, не имеет никакого отношения к C++.
Так всё ещё веселее: библиотека написана на C++, публичный API — на C, а враппер — снова на C++. Нет прямых вызовов C++ кода.
Собственно, ничто не мешает точно такой же враппер на абсолютно любом языке, поэтому исключительность C++ мне здесь непонятна.
Собственно, ничто не мешает точно такой же враппер на абсолютно любом языке, поэтому исключительность C++ мне здесь непонятна.Серьёзно? Вы не понимаете почему C API проще использовать из C++, чем, скажем, из JavaScript?
«Уши» языка, на котором написана библиотека — всё равно торчат. Библиотека, написанна на
Rust будет иметь другой API, чем библиотека, написанная на C++. Да если, формально, интерфейс у обоих будет extern C.На самом же C любой низкоуровневый API использовать одинаково неудобно, потому даже документация, говоря о «C API» использует в примерах
nullptr и прочее.Серьёзно? Вы не понимаете почему C API проще использовать из C++, чем, скажем, из JavaScript?
Несомненно, вызывать C-шные функции из C++ — это удобно.
Но когда речь доходит до врапперов, язык уже не имеет значения.
И не знаю, как в случае Vulkan, а в случае нейросетей голый API не используют, а работают через фреймворки.
Так всё ещё веселее: библиотека написана на C++, публичный API — на C
Правда? Дайте ссылку, пожалуйста. Стало интересно)
(У меня комментарии открывались 3 секунды)
Антон Полухин @antoshkkaи остальные,
Ассемблер это уже достаточно высокий ЯП. Правильно @ElleSolominaи @0xd34df00d вспоминали про микрокод(ы).
Без сравнения на равных микроархитектурах и кэшах от лукавого это всё.
Это сравнение "цитрусов", а не "апельсин с апельсином". Если не повезёт, то будете сравнивать цитрусы с яблоками.
Проверяем миф №1 и что видим? Автор этой статьи не понимает о чём говорит Полухин. А Антон всё верно говорит: в Расте тоже есть переполнения, только адепты святого и безопасного Раста будут думать что у них всё ОК.
Проблема-то не в самом переполнении, а в том что в плюсах это UB
Вот выше пример переполнения на С++ и на Rust. Что C++ переполнение не вылавливает без специальных флагов компилятора, что Rust. Только в C++ нет веры в чудесное отсутствие переполнения а в Rust:
в случае Rust область определения [-2147483648, 2147483647], а в случае C++ это [-46340, 46340]. Как такое может быть? Магия?
В Rust такая ситуация с неопределенным поведением в арифметике невозможна в принципе.
Как видим, вполне возможна и даже в safe коде.
P.S. Указал на фактическую ошибку в статье, а мне за это минусов накидали. Обидно, досадно, ну и ладно.
Читайте внимательнее:
В Rust такая ситуация с неопределенным поведением в арифметике невозможна в принципе.
Поведение при знаковом переполнении в Rust определено. Это не значит что переполнений не бывает, это значит что компилятор не сотворит ничего неожиданного если на него наткнётся.
UB не проблема если ты о нём знаешь и избегаешь или осознанно используешь. Проблемы начинаются когда программист на любом языке про UB не знает, а оно в его коде есть.
C++ быстрее и безопаснее Rust, Yandex сделала замеры