В этой статье я покажу как решить одну из проблем, возникающих при использовании распределенных очередей задач — регулирование пропускной способности очереди, или же, более простым языком, настройка ее rate limit'a. В качестве примера я возьму python и свою любимую связку Celery+RabbitMQ, хотя алгоритм, который я использую, никак не зависит от этих инструментов и может быть реализован на любом другом стэке.

So what's the problem?
Для начала пара слов о том, какую проблему я вообще пытаюсь решить. Дело в том, что 99.9% сервисов в интернете запрещают бесконтрольно закидывать их сотнями/тысячами запросов в секунду, угрожая дать в ответ какой-нибудь 403 или 500. Нет, ну правда, жалко им чтоле? Иногда таким сервисом может выступать даже своя собственная БД… Вобщем, доверять нынче нельзя никому, поэтому приходится себя как-то сдерживать.
Конечно, если вся работа ведется внутри 1го процесса, то никакой проблемы нет, но т.к мы работаем с Celery, то у нас может быть не только N процессов (далее воркеров), но и M машин, и задача все это дело синхронизировать уже не кажется столь тривиальной.
What's in the box
Первое, на что натыкаешься, когда ищешь, как же настроить throttling в celery, это встроенный параметр rate_limit класса Task. Звучит как то, что надо, но, копнув чуть глубже, замечаем, что:
Нельзя задать rate limit на группу задач.
Это неудобно, т.к зачастую доступ к какому-то лимитированому ресурсу размазан между разными тасками.
# представим что у нас лимит на вызовы API гитхаба 60 req/min # придется поделить вызовы поровну @app.task(rate_limit='30/m') def get_github_api1(): ... @app.task(rate_limit='30/m') def get_github_api2(): ...
Этот лимит работает только внутри воркера, то есть он локальный и у каждого воркера свой.
Конечно, можно еще раз поделить лимит, теперь взяв в расчет еще и количество воркеров. Но все это начнет работать дико неэффективно, если таски будут прилетать неравномерно, например в какую-то минуту мы получим 60 вызовов get_github_api1() и 0 вызовов get_github_api2() — будут выполнены только 30 вызовов первого типа, хотя могли бы быть все 60. К тому же каждый раз, как появится новая таска, которой нужен доступ к этому ресурсу, придется снова везде пересчитывать все лимиты. Вобщем фича конечно полезная, но только для самых простых вариантов.
Bringing decision
Token Bucket
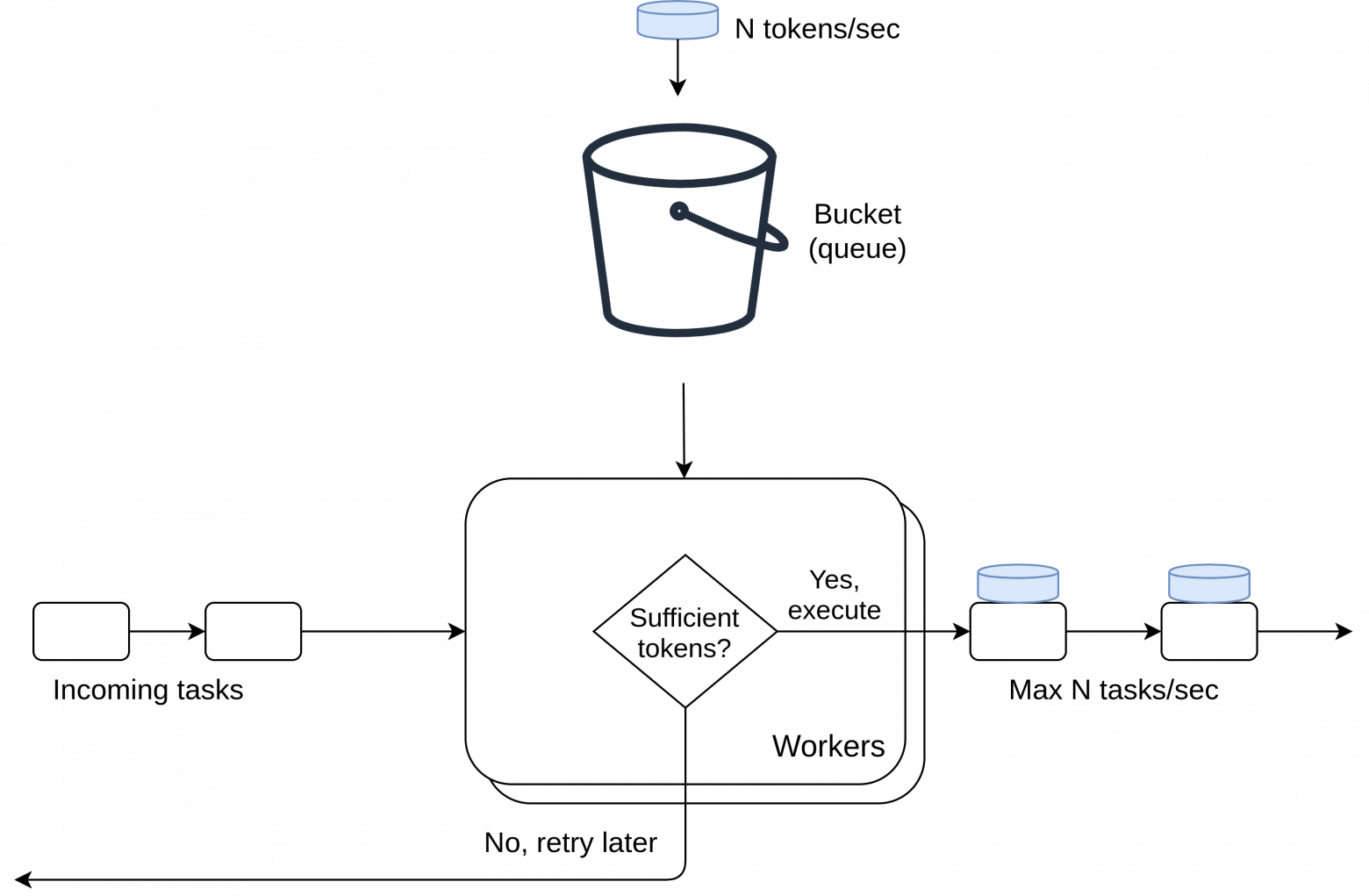
Решением проблемы для меня стал Token Bucket — алгоритм, использующийся для контроля полосы пропускания канала в компьютерных и телекомуникационных сетях. Опишу его в 2ух словах: пакет данных, чтобы пройти проверку канала на лимит, должен иметь при себе токен, который он взял из хранилища; в то же время в хранилище токены поступают с некоторой частотой. То есть пропускная способоность канала ограничивается скоростью выпуска токенов, которую нам и надо регулировать.
В нашем же случае вместо пакета данных мы имеем таску, а хранилищем токенов будут выступать очереди RabbitMQ.
Wrting some code
Чтож, приступим к написанию кода. Создадим файл main.py и зададим базовые настройки:
from celery import Celery from kombu import Queue app = Celery('Test app', broker='amqp://guest@localhost//') # 1 очередь под сами таски и 1 очередь под токены для них app.conf.task_queues = [ Queue('github'), # я ограничил длину очереди до 2ух, чтобы токены не скапливались # иначе это может привести к пробою нашего rate limit'a Queue('github_tokens', max_length=2) ] # это таска будет играть роль нашего токена # она никогда не будет запущена, мы просто будем забирать ее как сообщение из очереди @app.task def token(): return 1 # настраиваем постоянный выпуск нашего токена @app.on_after_configure.connect def setup_periodic_tasks(sender, **kwargs): # мы будем выпускать по 1му токену в секунду # это значит что rate limit для очереди github - 60 задач в минуту sender.add_periodic_task(1.0, token.signature(queue='github_tokens'))
Не забудьте развернуть Rabbit, я предпочитаю делать это 1ой строчкой докера:
docker run -d --rm --name rabbit -p 15672:15672 -p 5672:5672 rabbitmq:3-management
Теперь запустим celery beat — это специальный воркер celery, запускаемый всегда в единственном экземпляре и отвечающий за запуск периодических задач.
celery -A main beat --loglevel=info
После этого в консоли раз в секунду начнут появляться сообщения:
[2020-03-22 22:49:00,992: INFO/MainProcess] Scheduler: Sending due task main.token() (main.token)
Отлично, мы наладили выпуск токенов для нашего 'ведра'. Осталось только научить наших воркеров из него брать. Попробуем оптимизировать код, который мы написали ранее для запросов в github. Добавим эти строчки к main.py:
# Напишем функцию для взятия токена из очереди def rate_limit(task, task_group): # берем соединение с брокером из пула with task.app.connection_for_read() as conn: # забираем токен msg = conn.default_channel.basic_get(task_group+'_tokens', no_ack=True) # получили None - очередь пуста, токенов нет if msg is None: # повторить таску через 1 сек task.retry(countdown=1) # Добавим print в таски для логирования # Здесь я поставил max_retries=None, так что таски будут # повторяться, пока не будут выполнены @app.task(bind=True) def get_github_api1(self, max_retries=None): rate_limit(self, 'github') print ('Called Api 1') @app.task(bind=True) def get_github_api2(self, max_retries=None): rate_limit(self, 'github') print ('Called Api 2')
А теперь проверим, как это все работает. В дополнение к уже запущенному beat добавим 8 воркеров:
celery -A main worker -с 8 -Q github
И создадим отдельный маленький скрипт для запуска этих задач, назовем его producer.py:
from main import get_github_api1, get_github_api2 tasks = [get_github_api1, get_github_api2] for i in range(100): # запускаю таски в перемешку tasks[i % 2].apply_async(queue='github')
Запускаем — python producer.py, и смотрим в логи воркеров:
[2020-03-23 13:04:15,017: WARNING/ForkPoolWorker-3] Called Api 2 [2020-03-23 13:04:16,053: WARNING/ForkPoolWorker-8] Called Api 2 [2020-03-23 13:04:17,112: WARNING/ForkPoolWorker-1] Called Api 2 [2020-03-23 13:04:18,187: WARNING/ForkPoolWorker-1] Called Api 1 ... (96 more lines)
Несмотря на то, что у нас целых 8 рабочих процессов, таски выполняются примерно раз в секунду, отправляясь в конец очереди, если на момент их выполнения не оказалось токена. Также, я думаю, вы уже заметили, что на самом деле мы накладываем rate limit не совсем на очередь, а скорее на какую-то логически связанную группу задач, которые на самом деле могут находится как в разных очередях, так и в одной. Таким образом наш контроль становится даже более детальным и гранулированным.
Putting it all together
Конечно, количество таких групп задач не ограничено (разве что возможностями брокера). Соберем весь код в кучку, расширим и причешим его:
from celery import Celery from kombu import Queue from queue import Empty from functools import wraps app = Celery('hello', broker='amqp://guest@localhost//') task_queues = [ Queue('github'), Queue('google') ] # количество запусков в минуту rate_limits = { 'github': 60, 'google': 100 } # автоматически сгенерируем очереди с токенами под все группы, на которые нужен лимит task_queues += [Queue(name+'_tokens', max_length=2) for name, limit in rate_limits.items()] app.conf.task_queues = task_queues @app.task def token(): return 1 @app.on_after_configure.connect def setup_periodic_tasks(sender, **kwargs): # автоматически настроим выпуск токенов с нужной скоростью for name, limit in rate_limits.items(): sender.add_periodic_task(60 / limit, token.signature(queue=name+'_tokens')) # Как можно не любить декораторы? def rate_limit(task_group): def decorator_func(func): @wraps(func) def function(self, *args, **kwargs): with self.app.connection_for_read() as conn: # тут я для примера использовал другой более высокоуровневый подход: # в замен на получение полноценного интерфейса очереди # мы немного теряем в перфомансе, т.к под капотом происходит обмен # несколькими сообщениями с брокером with conn.SimpleQueue(task_group+'_tokens', no_ack=True, queue_opts={'max_length':2}) as queue: try: # из плюсов также - наличие вот такого блокирующего вызова # это может быть удобнее, чем постоянная ротация с retry() # впрочем, это нужно подбирать под кейс queue.get(block=True, timeout=5) return func(self, *args, **kwargs) except Empty: self.retry(countdown=1) return function return decorator_func # с декораторами все-таки намного красивее и читабельнее, согласитесь? ;) @app.task(bind=True, max_retries=None) @rate_limit('github') def get_github_api1(self): print ('Called github Api 1') @app.task(bind=True, max_retries=None) @rate_limit('github') def get_github_api2(self): print ('Called github Api 2') @app.task(bind=True, max_retries=None) @rate_limit('google') def query_google_api1(self): print ('Called Google Api 1') @app.task(bind=True, max_retries=None) @rate_limit('google') def query_google_api1(self): print ('Called Google Api 2')
Таким образом суммарные вызовы задач группы google не превысят 100/мин, а группы github — 60/мин. Заметьте, что для того, чтобы настроить такой throttling, понадобилось меньше 50 строк. Как по мне, достаточно просто.
Moving further
Ну, вот все и работает как надо, причем без каких-либо сторонних примочек, средствами только самого брокера. Но зачем останавливаться на достигнутом ;)? Грамотно используя данный алгоритм, можно пойти дальше и создать намного более сложные и гибкие стратегии. Например, некоторые таски могут брать не 1, а несколько токенов (возможно даже из разных очередей, если обращение идет к нескольким сервисам), таким образом у нас появится понятие 'веса' задачи, или же расширить размер нашего 'ведра' токенов, позволив им накапливаться, тем самым компенсируя периоды простоя. Вобщем, пространство для маневра просто огромное и ограничено только вашим воображением и инженерными навыками) Всем спасибо, всем удачи!
P.s. Поделитесь кто как решал подобную проблему, будет интересно услышать ;)
