Именно такие претензии я услышал от наших девелоперов. Самое интересное, что это оказалось правдой, дав начало длительному расследованию. Речь пойдет про SQL servers, которые крутятся у нас на VMware.

Собственно, добиться того, чтобы production server безнадежно отстал от лаптопа легко. Выполните (не на tempdb и не на базе с включенной Delayed Durability) код:
На моем десктопе он выполняется 5 секунд, а на production server — 28 секунд. Потому что SQL должен ожидать физического окончания записи в transaction log, а мы тут делаем очень короткие транзакции. Грубо говоря, мы загнали большой мощный грузовик в городской траффик, и наблюдаем, как его лихо обгоняют доставщики пиццы на скутерах — тут не важен throughput, важна лишь latency. А ни один network storage, сколько бы нулей ни было в его цене, не сможет выиграть по latency у локального SSD.
Однако в данном случае мы имеем дело стривиальными нулями зэта функции Римана с тривиальным примером. В том примере, который мне принесли девелоперы, было другое. Я убедился, что они правы, и стал вычищать из примера всю их специфику, связанную с бизнес логикой. В какой-то момент я понял, что могу полностью выбросить их код, и написать свой — который демонстрирует ту же проблему — на production он выполняется в 3-4 раза медленнее:
Если у вас все хорошо, то проверка простоты числа будет выполняться 6-7-8 секунд. Так и было на ряде серверов. Но вот на некоторых проверка занимала 25-40 секунд. Что интересно, не было серверов, где выполнение занимало бы, скажем, 14 секунд — код работал либо очень быстро, либо совсем медленно, то есть проблема была, скажем так, черно белой.
Что я сделал? Полез в метрики VMware. Там было все хорошо — реcурсов было в избытке, Ready time = 0, всего хватает, во время теста и на быстрых, и на медленных серверах CPU=100 на одном vCPU. Я взял тест по расчету числа Pi — тест показывал одинаковые результаты на любых серверах. Все сильнее пахло черной магией.
Выбравшись на DEV ферму, я стал играться серверами. Выяснилось, что vMotion с хоста на хост может «вылечить» сервер, но может и наоборот, «быстрый» сервер превратить в «медленный». Кажется вот оно — какие то хосты имеют проблему… но… нет. Какая-то виртуалка тормозила на хосте, допустим, A но работала быстро на хосте B. А другая виртуалка наоборот, работала быстро на A и тормозила на B! На хосте часто крутились и «быстрые» и «медленные» машинки!
С этого момента в воздухе отчетливо запахло серой. Ведь проблема не могла быть приписана ни виртуалке (windows patches, например) — ведь она превращалась в «быструю» при vMotion. Но проблема также не могла быть приписана хосту — ведь на нем могли быть как «быстрые», так и «медленные» машинки. Также это не было связано с нагрузкой — мне удалось получить «медленную» машинку на хосте, где кроме нее вообще не было ничего.
От отчаяния я запустил Process Explorer от Sysinternals и посмотрел стек SQL. На медленных машинках мне сразу бросилась в глаза строка:
ntoskrnl.exe!KeSynchronizeExecution+0x5bf6
ntoskrnl.exe!KeWaitForMultipleObjects+0x109d
ntoskrnl.exe!KeWaitForMultipleObjects+0xb3f
ntoskrnl.exe!KeWaitForSingleObject+0x377
ntoskrnl.exe!KeQuerySystemTimePrecise+0x881 < — !!!
ntoskrnl.exe!ObDereferenceObjectDeferDelete+0x28a
ntoskrnl.exe!KeSynchronizeExecution+0x2de2
sqllang.dll!CDiagThreadSafe::PxlvlReplace+0x1a20
… skipped
sqldk.dll!SystemThread::MakeMiniSOSThread+0xa54
KERNEL32.DLL!BaseThreadInitThunk+0x14
ntdll.dll!RtlUserThreadStart+0x21
Это было уже что-то. Была написана программа:
Эта программа демонстрировала еще более яркое замедление — на «быстрых» машинах она показывает 16-18 миллионов циклов в секунду, тогда как на медленных — полтора миллиона, а то и 700 тысяч. То есть разница составляет 10-20 раз (!!!). Это было уже маленькой победой: во всяком случае, не было угрозы застрять между Microsoft и VMware support так, чтобы они переводили стрелки друг на друга.
Далее прогресс остановился — отпуск, важные дела, вирусная истерия и резкое возрастание нагрузки. Я часто упоминал магическую проблему коллегам, но временами казалось, что они даже не всегда мне верят — слишком уж чудовищным было заявление от том, что VMware замедляет код в 10-20 раз.
Я пытался сам раскопать, что же тормозит. Временами мне казалось, что я нашел решение — включение и выключение Hot plugs, изменение объема памяти или числа процессоров часто превращало машинку в «быструю». Но не навсегда. А вот что оказалось правдой — так это то, что достаточно выйти и постучать по колесу — то есть изменить любой параметр виртуалки
Наконец, мои американские коллеги вдруг нашли root cause.
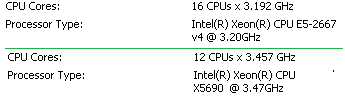
Хосты отличались частотой!
Но есть случаи, когда эти грабли больно бьют. И таки да, постучав по колесу (поменяв что-то в настройках VM) я заставлял VMware 'пересчитать' конфигурацию, и частота текущего хоста становилась 'родной' частотой машинки.
www.vmware.com/files/pdf/techpaper/Timekeeping-In-VirtualMachines.pdf
Короче говоря, надо добавить параметр
monitor_control.virtual_rdtsc = FALSE
У вас наверняка возник вопрос: а нафига SQL вызывать GetTimePrecise так часто?
У меня нет исходников SQL server, но логика говорит вот что. SQL это почти операционка с cooperative concurrency, где каждый thread должен время от времени «уступать». А где это лучше сделать? Там, где есть естественное ожидание — lock или IO. Хорошо, а что, если мы крутим вычислительные циклы? Тогда очевидное и почти единственное место — в интерпертаторе (это не совсем интерпретатор), после выполнения очередного оператора.
Как правило, SQL server не используется длязабивания гвоздей чистых вычислений и это не является проблемой. Но циклы с работой со всякими временными табличками (которые тут же кешируются) превращают код в последовательность очень быстро выполняемых операторов.
Кстати, если функцию обернуть в NATIVELY COMPILED, то она перестает запрашивать время, и ее скорость увеличивается раз в 10. А как же cooperative multitasking? А вот для natively compiled code и пришлось в SQL сделать PREEMPTIVE MULTITASKING.
Собственно, добиться того, чтобы production server безнадежно отстал от лаптопа легко. Выполните (не на tempdb и не на базе с включенной Delayed Durability) код:
set nocount on create table _t (v varchar(100)) declare @n int=300000 while @n>0 begin insert into _t select 'What a slowpoke!' delete from _t set @n=@n-1 end GO drop table _t
На моем десктопе он выполняется 5 секунд, а на production server — 28 секунд. Потому что SQL должен ожидать физического окончания записи в transaction log, а мы тут делаем очень короткие транзакции. Грубо говоря, мы загнали большой мощный грузовик в городской траффик, и наблюдаем, как его лихо обгоняют доставщики пиццы на скутерах — тут не важен throughput, важна лишь latency. А ни один network storage, сколько бы нулей ни было в его цене, не сможет выиграть по latency у локального SSD.
(в комментах выяснилось что я соврал — у меня в обоих местах затесался delayed durability. Без delayed durability получается:
Desktop — 39 секунд, 15K tr/sec, 0.065ms /io roundtrip
PROD — 360 секунд, 1600 tr/sec, 0.6ms
Я должен был обратить внимание, что уж слишком быстро)
Однако в данном случае мы имеем дело с
create function dbo.isPrime (@n bigint) returns int as begin if @n = 1 return 0 if @n = 2 return 1 if @n = 3 return 1 if @n % 2 = 0 return 0 declare @sq int set @sq = sqrt(@n)+1 -- check odds up to sqrt declare @dv int = 1 while @dv < @sq begin set @dv=@dv+2 if @n % @dv = 0 return 0 end return 1 end GO declare @dt datetime set @dt=getdate() select dbo.isPrime(1000000000000037) select datediff(ms,@dt,getdate()) as ms GO
Если у вас все хорошо, то проверка простоты числа будет выполняться 6-7-8 секунд. Так и было на ряде серверов. Но вот на некоторых проверка занимала 25-40 секунд. Что интересно, не было серверов, где выполнение занимало бы, скажем, 14 секунд — код работал либо очень быстро, либо совсем медленно, то есть проблема была, скажем так, черно белой.
Что я сделал? Полез в метрики VMware. Там было все хорошо — реcурсов было в избытке, Ready time = 0, всего хватает, во время теста и на быстрых, и на медленных серверах CPU=100 на одном vCPU. Я взял тест по расчету числа Pi — тест показывал одинаковые результаты на любых серверах. Все сильнее пахло черной магией.
Выбравшись на DEV ферму, я стал играться серверами. Выяснилось, что vMotion с хоста на хост может «вылечить» сервер, но может и наоборот, «быстрый» сервер превратить в «медленный». Кажется вот оно — какие то хосты имеют проблему… но… нет. Какая-то виртуалка тормозила на хосте, допустим, A но работала быстро на хосте B. А другая виртуалка наоборот, работала быстро на A и тормозила на B! На хосте часто крутились и «быстрые» и «медленные» машинки!
С этого момента в воздухе отчетливо запахло серой. Ведь проблема не могла быть приписана ни виртуалке (windows patches, например) — ведь она превращалась в «быструю» при vMotion. Но проблема также не могла быть приписана хосту — ведь на нем могли быть как «быстрые», так и «медленные» машинки. Также это не было связано с нагрузкой — мне удалось получить «медленную» машинку на хосте, где кроме нее вообще не было ничего.
От отчаяния я запустил Process Explorer от Sysinternals и посмотрел стек SQL. На медленных машинках мне сразу бросилась в глаза строка:
ntoskrnl.exe!KeSynchronizeExecution+0x5bf6
ntoskrnl.exe!KeWaitForMultipleObjects+0x109d
ntoskrnl.exe!KeWaitForMultipleObjects+0xb3f
ntoskrnl.exe!KeWaitForSingleObject+0x377
ntoskrnl.exe!KeQuerySystemTimePrecise+0x881 < — !!!
ntoskrnl.exe!ObDereferenceObjectDeferDelete+0x28a
ntoskrnl.exe!KeSynchronizeExecution+0x2de2
sqllang.dll!CDiagThreadSafe::PxlvlReplace+0x1a20
… skipped
sqldk.dll!SystemThread::MakeMiniSOSThread+0xa54
KERNEL32.DLL!BaseThreadInitThunk+0x14
ntdll.dll!RtlUserThreadStart+0x21
Это было уже что-то. Была написана программа:
class Program { [DllImport("kernel32.dll")] static extern void GetSystemTimePreciseAsFileTime(out FILE_TIME lpSystemTimeAsFileTime); [StructLayout(LayoutKind.Sequential)] struct FILE_TIME { public int ftTimeLow; public int ftTimeHigh; } static void Main(string[] args) { for (int i = 0; i < 16; i++) { int counter = 0; var stopwatch = Stopwatch.StartNew(); while (stopwatch.ElapsedMilliseconds < 1000) { GetSystemTimePreciseAsFileTime(out var fileTime); counter++; } if (i > 0) { Console.WriteLine("{0}", counter); } } } }
Эта программа демонстрировала еще более яркое замедление — на «быстрых» машинах она показывает 16-18 миллионов циклов в секунду, тогда как на медленных — полтора миллиона, а то и 700 тысяч. То есть разница составляет 10-20 раз (!!!). Это было уже маленькой победой: во всяком случае, не было угрозы застрять между Microsoft и VMware support так, чтобы они переводили стрелки друг на друга.
Далее прогресс остановился — отпуск, важные дела, вирусная истерия и резкое возрастание нагрузки. Я часто упоминал магическую проблему коллегам, но временами казалось, что они даже не всегда мне верят — слишком уж чудовищным было заявление от том, что VMware замедляет код в 10-20 раз.
Я пытался сам раскопать, что же тормозит. Временами мне казалось, что я нашел решение — включение и выключение Hot plugs, изменение объема памяти или числа процессоров часто превращало машинку в «быструю». Но не навсегда. А вот что оказалось правдой — так это то, что достаточно выйти и постучать по колесу — то есть изменить любой параметр виртуалки
Наконец, мои американские коллеги вдруг нашли root cause.
Хосты отличались частотой!
- Как правило, это не страшно. Но: при переезде с 'родного' хоста на хост с 'другой' частотой VMware должна корректировать результат GetTimePrecise.
- Как правило это не страшно, если только не оказывается аппликации, которая запрашивает точное время миллионы раз в секунду, как SQL server.
- Но и это не страшно, так как SQL server делает это далеко не всегда (см. Заключение)
Но есть случаи, когда эти грабли больно бьют. И таки да, постучав по колесу (поменяв что-то в настройках VM) я заставлял VMware 'пересчитать' конфигурацию, и частота текущего хоста становилась 'родной' частотой машинки.
Решение
www.vmware.com/files/pdf/techpaper/Timekeeping-In-VirtualMachines.pdf
When you disable virtualization of the TSC, reading the TSC from within the virtual machine returns the physical machine’s TSC value, and writing the TSC from within the virtual machine has no effect. Migrating the virtual machine to another host, resuming it from suspended state, or reverting to a snapshot causes the TSC to jump discontinuously. Some guest operating systems fail to boot, or exhibit other timekeeping problems, when TSC virtualization is disabled. In the past, this feature has sometimes been recommended to improve performance of applications that read the TSC frequently, but performance of the virtual TSC has been improved substantially in current products. The feature has also been recommended for use when performing measurements that require a precise source of real time in the virtual machine.
Короче говоря, надо добавить параметр
monitor_control.virtual_rdtsc = FALSE
Заключение
У вас наверняка возник вопрос: а нафига SQL вызывать GetTimePrecise так часто?
У меня нет исходников SQL server, но логика говорит вот что. SQL это почти операционка с cooperative concurrency, где каждый thread должен время от времени «уступать». А где это лучше сделать? Там, где есть естественное ожидание — lock или IO. Хорошо, а что, если мы крутим вычислительные циклы? Тогда очевидное и почти единственное место — в интерпертаторе (это не совсем интерпретатор), после выполнения очередного оператора.
Как правило, SQL server не используется для
Кстати, если функцию обернуть в NATIVELY COMPILED, то она перестает запрашивать время, и ее скорость увеличивается раз в 10. А как же cooperative multitasking? А вот для natively compiled code и пришлось в SQL сделать PREEMPTIVE MULTITASKING.
