Comments 66
+1
Intel не позволит кануть x86. Вспомните про Larrabee, который поддерживает и базируется на x86 инструкциях.
эти 153 GFLOP достаточно непрактично использовать, потому и не
пробовал (с точки зрения выпуска программы не для внутреннего потребления).
Что имеется в виду?
Доступ к ним тяжеловато получить.
O RLY?
Не понимаю. Если это готовый сервер или акселератор с интерфейсом PCI-E, то вот они, ресурсы. Если это PS3, то ставим Yellow Dog (или какой-нибудь другой дистрибутив GNU/Linux) и делаем свои расчеты на всех доступных SPE.
Во всех случаях для программирования используются одни и те же библиотеки/фреймворки, так что разработка отличается не очень кардинально.
Не понимаю. Если это готовый сервер или акселератор с интерфейсом PCI-E, то вот они, ресурсы. Если это PS3, то ставим Yellow Dog (или какой-нибудь другой дистрибутив GNU/Linux) и делаем свои расчеты на всех доступных SPE.
Во всех случаях для программирования используются одни и те же библиотеки/фреймворки, так что разработка отличается не очень кардинально.
Для конечного пользователя релизнуть трудно.
Объяснять простому юзеру как ему надо на приставку линух ставить — достаточно трудновато.
Ну а о цене акселей с интерфейсом PCI-E лучше помолчим, чтобы не расстраиваться зря :-)
Объяснять простому юзеру как ему надо на приставку линух ставить — достаточно трудновато.
Ну а о цене акселей с интерфейсом PCI-E лучше помолчим, чтобы не расстраиваться зря :-)
Когда речь идёт о пиковой производительности то получить её на х86 не намного легче чем на CELL.
Умножение больших матриц даёт на полноценном CELL ожидаемые 200GFlops.
Умножение больших матриц даёт на полноценном CELL ожидаемые 200GFlops.
Строка «Реальная скорость, GFLOP» не несёт практической смысловой нагрузки, т.к. не указано каких операций. Тем более у разных операций различное время выполенения.
FLOPS — FLoating point Operations Per Second (операций с плавающей точкой(одинарной точности наверно))
так что все очень даже понятно: например надо перемножить 2 матрицы NxN, считаешь, сколько надо операций, и считаешь приблизительное время
так что все очень даже понятно: например надо перемножить 2 матрицы NxN, считаешь, сколько надо операций, и считаешь приблизительное время
Побольше таких статей, если можно :)
В синтетических — да, из одночиповых — на практике — 295ая нвидиа
А по себе скажу, что 4870 страдает от нехватки нормальных дров. Очень.
Это спорно, к тому же заточка многих игр под nVidia нивелирует незначительный прирост в производительности. Ну а вычисления на GPU пока массово идут под брендом CUDA.
Нет заточки под nVidia. Mean to be played — всего лишь шильдик, который значит, что если видяха в списке поддерживаемых есть, и компьютер соответствует минимальным требованиям — оно запустится.
Эта программа и есть для того, чтобы разработчики затачивали игры под GeForce, вообще-то.
en.wikipedia.org/wiki/The_way_it's_meant_to_be_played
en.wikipedia.org/wiki/The_way_it's_meant_to_be_played
Кстати, а куда делать платформа OpenCL, которую помойму AMD и продвигает, как основного соперника CUDA?
AMD has decided to support OpenCL (and DirectX 11) instead of the now deprecated Close to Metal in its Stream framework.
АМД решила продвигать OpenCL, вместо CTM. Я об этом и говорю. Или от её слов до дела ещё не дошло?
На деле пока все крайне странно себя ведет, это раз, два — CTM — это как раз реализация низкоуровневых команд. (Даже название об этом говорит)
Вы, видимо не верно поняли мой вопрос.
Я говорю про то, что вы использовали Brook+ и даже похвалили, что в нём реализованны CTM.
Хотелось увидеть в статье (возможно продолжение этой) OpenCL, как альтернативу CUDA и Broom+. Если можно, конечно.
Собираюсь просто этим заниматься скоро — OpenCL сейчас вижу, как достаточно продуманную кроссплатформенную (Radeon+Geforce) альтернативу.
Я говорю про то, что вы использовали Brook+ и даже похвалили, что в нём реализованны CTM.
Хотелось увидеть в статье (возможно продолжение этой) OpenCL, как альтернативу CUDA и Broom+. Если можно, конечно.
Собираюсь просто этим заниматься скоро — OpenCL сейчас вижу, как достаточно продуманную кроссплатформенную (Radeon+Geforce) альтернативу.
Хороший обзор. Скажите, а чем предполагается компилировать код для Phenom?
Программы, работающие по 5 секунд — это ещё очень далеко от HPC. Может они и высокопроизводительные, но много насчитать не очень-то получится… Раз уж у вас есть под рукой необходимое оборудование, стоило бы проверить производительность на более приближенных к жизни операциях, например двумерном Фурье-преобразовании матрицы размером 8192x8192 :)
5 секунд — это всего лишь время через которое ОС посчитает что вычисления захватили ресурсы видеокарты и снимет процесс.
Если покупается GPU для специальных рассчетов, то монитор к ней подключать не следует, и в таком случае Windows watchdog не срабатывает, можно считать сколько нужно.
Если покупается GPU для специальных рассчетов, то монитор к ней подключать не следует, и в таком случае Windows watchdog не срабатывает, можно считать сколько нужно.
Обойти можно всё, это понятно :) Но это лишний камень в огород CUDA, пресс-релизы которой пестрят заявлениями о том, как же с ней удобно работать даже на офисных PC. Особенно, если не покупать новые топовые карты, а пробовать работать с той, которая стоит на рабочем компьютере.
5 секунд — это лимит на исполнение одного kernel'я, а в консьюмерских задачах кернели отрабатывают зачастую за миллисекунды.
И никаких камней нет, потому что ATI имеет те же проблемы.
И никаких камней нет, потому что ATI имеет те же проблемы.
Я имел в виду сравнение не с ATI, а с вычислительными системами на основе CPU :) Не спорю, что есть много задач, где вычисления занимают мало времени, просто я их, видимо, не отношу сильно к области HPC, которая была заявлена в заголовке статьи. Либо я не до конца понимаю терминологии, чтож, буду читать…
Классическое умножение матриц 6000x6000: www.gpgpu.ru/articles/sgemm-7.html
Спасибо за ссылку. Намного более адекватный результат, превосходство GTX280 над Core2Quad 9300 всего полтора раза. И это для перемножения матриц, которое для GPU идеально подходит.
Так написано же, что на double производительность в 10 раз падает. Смотрите float:
Blas — 87, Cuda — 372. В 4.3 раза быстрее чем Quad, в 17 раз быстрее одного ядра.
Думаю, быстрое преобразование фурье может дать больший разрыв во floate за счёт хорошего синуса в Nvidia.
Blas — 87, Cuda — 372. В 4.3 раза быстрее чем Quad, в 17 раз быстрее одного ядра.
Думаю, быстрое преобразование фурье может дать больший разрыв во floate за счёт хорошего синуса в Nvidia.
Мне кажется сравнивать с одним ядром уже давно пора перестать :)
В том-то и дело, что в реальных считательных задачах не всегда достаточно float. Если кратко, то этого достаточно для видео, графики, игр, что и неудивительно, но не стоит экономить на точности при расчёте ядерных реакторов. Фурье само по себе имеет тенденцию терять точность даже при преобразовании туда-обратно, то делать это во float не очень хорошо.
В том-то и дело, что в реальных считательных задачах не всегда достаточно float. Если кратко, то этого достаточно для видео, графики, игр, что и неудивительно, но не стоит экономить на точности при расчёте ядерных реакторов. Фурье само по себе имеет тенденцию терять точность даже при преобразовании туда-обратно, то делать это во float не очень хорошо.
Что то FLOPS в вашей табличке для чипов сильно расходятся с тем что приведено в en.wikipedia.org/wiki/FLOPS
Это потому что у вас «реальные»? :-)
Это потому что у вас «реальные»? :-)
На самом деле пиковая производительность x86 i7 @ 3GHz(Nehalem):
a) Single precision: 8*3Ghz = 24GFlops per core, 24*4 = 96GFlops per CPU;
b) Double precision: 4*3GHz = 12GFlops per core, 12*4 = 48GFlops per CPU.
Смотрите например тут:
icl.cs.utk.edu/hpcc/hpcc_results.cgi
Подтест DGEMM — как раз этот случай. Высокая локальность, чисто Flops-ы :)
S-DGEMM — замер на одном процессе, EP-DGEMM — замер на всех ядрах, усредненный.
Вот, а «Реальная скорость в 153 GFLOPS» — это от лукавого…
a) Single precision: 8*3Ghz = 24GFlops per core, 24*4 = 96GFlops per CPU;
b) Double precision: 4*3GHz = 12GFlops per core, 12*4 = 48GFlops per CPU.
Смотрите например тут:
icl.cs.utk.edu/hpcc/hpcc_results.cgi
Подтест DGEMM — как раз этот случай. Высокая локальность, чисто Flops-ы :)
S-DGEMM — замер на одном процессе, EP-DGEMM — замер на всех ядрах, усредненный.
Вот, а «Реальная скорость в 153 GFLOPS» — это от лукавого…
В этой статьи не рассматриваются вопросы связанные с падением производительности из-за памяти/кеша. К указанной в таблице цифре я приближался на всех платформах кросе Cell. На x86 все помещалось в регистры и немного L1 кеша, потому и скорость 150 а не 96.
Уважаемый — я вам даю теоретический пик. С которым вообщем-то согласны в индустрии. А вы мне черт знает что — я не могу понять в чем вы измеряете свои флопсы, откуда взялась эта цифра 150??
Этот теоретический пик — на матричных операциях, и я согласен что он тоже важен. В данной статье я привожу максимальную реально достижимую скорость, не учитывая ограничения памяти (например когда все в регистрах или в L1 кеше). Производительность работы с памятью (bandwidth & latency на разных уровнях) можно рассмотреть в отдельной статье, там тоже много интересного :-)
Теоретический пик как раз и не учитывает кэши и память.
Ну вы приведите код в конце концов, и все ведь станет ясно. Тот кусок кода что в оригинальной статье меряет не Flops-ы а Mips-ы, т.е целочисленные инструкции. Возможно отсюда у автора и такие цифры.
Про bandwidth и latency — пожалуйста. Только сразу указывайте для какой операции.
Ну вы приведите код в конце концов, и все ведь станет ясно. Тот кусок кода что в оригинальной статье меряет не Flops-ы а Mips-ы, т.е целочисленные инструкции. Возможно отсюда у автора и такие цифры.
Про bandwidth и latency — пожалуйста. Только сразу указывайте для какой операции.
Производительность и на 32 битных целых, и синглах(по крайней мере пока мы говорим о простых операциях) у всех одинаковая — все занимает по одному такту.
Код в статье — лишь для примера.
Код в статье — лишь для примера.
Не может быть!!! Вас кто-то обманул :)
4 сингловые операции за такт или 3 целочисленные, а с применением адресной арифметики может быть и 5.
И вообще х86 сейчас может выполнять до 6-ти или 11-ти (точно не помню) инструкций за такт с помощию буфера циклов.
4 сингловые операции за такт или 3 целочисленные, а с применением адресной арифметики может быть и 5.
И вообще х86 сейчас может выполнять до 6-ти или 11-ти (точно не помню) инструкций за такт с помощию буфера циклов.
Я говорю об SSE операциях, так и получается 12 операций за такт на ядро — 3 операции по 4 числа.
Ставить вместо SSE операций обычные пожалуй не стоит :-)
Ставить вместо SSE операций обычные пожалуй не стоит :-)
Еще раз. В процессоре 1 блок SSE шириной 128бит. Он за 1 такт выполняет 1 SSE инструкцию над 128 битами.
«3 операции по 4 числа.» — нихт. Никак. Невозможно.
«3 операции по 4 числа.» — нихт. Никак. Невозможно.
В Core2Duo и выше 3 SSE блока — это и дает очень большую скорость.
В Phenom — тоже 3, но 2 из них специализированные.
На реальных приложениях (например моя программа BarsWF) выжимает ~35 млрд операций в секунду на ядро, как это возможно если можно делать только 4 операции за такт?
В Phenom — тоже 3, но 2 из них специализированные.
На реальных приложениях (например моя программа BarsWF) выжимает ~35 млрд операций в секунду на ядро, как это возможно если можно делать только 4 операции за такт?
Небольшой апдейт:
1 блок FP умножения и 1 блок FP сложения — отдельно.
Итого 2+2=4 double precision FP операции за такт.
Делилка и вычиталка — те же самые блоки.
Другие операции — сильно медленнее.
Конверсия чисел, load и store за операции не считаются.
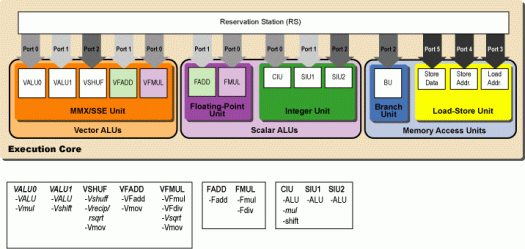
Вобщем чтобы прекратить спор предлагаю вам написать программу, делающую больше 4 FP операций за такт. Хотспот вашей BarsWF подойдет.
1 блок FP умножения и 1 блок FP сложения — отдельно.
Итого 2+2=4 double precision FP операции за такт.
Делилка и вычиталка — те же самые блоки.
Другие операции — сильно медленнее.
Конверсия чисел, load и store за операции не считаются.
Вобщем чтобы прекратить спор предлагаю вам написать программу, делающую больше 4 FP операций за такт. Хотспот вашей BarsWF подойдет.
Вы правы, а я не прав :-)
peak FP throughput for vectorized code of 2 64-bit MUL and 2 64-bit ADD per cycle (8 SP or 4 DP FLOPS)
Отлично :)
Теперь можете прикинуть как это выглядит на больших машинах, на отлично вылизанном DGEMM (или распределенном Linpack) — сколько реально достигается процентов от пика. Ссылку я давал выше.
Данные будут примерно такого порядка: 75% на п4, 82% на Core2Duo и примерно 85-89% на Нехалеме. В этом и сила этого процессора.
Теперь можете прикинуть как это выглядит на больших машинах, на отлично вылизанном DGEMM (или распределенном Linpack) — сколько реально достигается процентов от пика. Ссылку я давал выше.
Данные будут примерно такого порядка: 75% на п4, 82% на Core2Duo и примерно 85-89% на Нехалеме. В этом и сила этого процессора.
фанАТИчно пахнущая статья…
Спасибо!!! Ещё бы вводные курсы по nVidia CUDA и AMD Brook почитать.
Кроме того, материнская плата под 4 видеокарты стоит намного дешевле платы под 4 процессора.А можно пример такой материнки? Я максимум слышал про 3 карточки, и из них одна по шине еще зажата будет…
www.newegg.com/Product/Product.aspx?Item=N82E16813130140
279$
Зажаты — может быть, не для всех задач нужна полная полоса пропускания.
Работающию систему 4x9800GX2 видел и на скриншоте и внешний вид )
279$
Зажаты — может быть, не для всех задач нужна полная полоса пропускания.
Работающию систему 4x9800GX2 видел и на скриншоте и внешний вид )
Sign up to leave a comment.
HPC: nVidia, AMD, Sony Cell, x86