Пытаемся определить язык таинственной рукописи — манускрипта Войнича — простыми методами обработки естественных языков на Python.

Манускрипт Войнича — таинственная рукопись (кодекс, манускрипт или просто книга) в добрых 240 страниц пришедшая к нам, предположительно, из XV века. Рукопись была случайно приобретена у антиквара мужем знаменитой писательницы-карбонария Этель Войнич — Уилфредом Войничем — в 1912 году и скоро стала достоянием широкой общественности.
Язык рукописи не определен до сих пор. Ряд исследователей манускрипта предполагают, что текст рукописи — шифровка. Иные уверены, что манускрипт написан на языке, не сохранившемся в известных нам сегодня текстах. Третьи и вовсе считают манускрипт Войнича бессмыслицей (см современный гимн абсурдизму Codex Seraphinianus).
В качестве примера приведу сканированный фрагмент сабжа с текстом и нимфами:

Может быть, это — поздняя подделка? По-видимому, нет. В отличие от Туринской плащаницы, ни радиоуглеродный анализ, ни прочие попытки оспорить древность пергамента пока не дали однозначного ответа. А ведь Войнич не мог предвидеть изотопный анализ в самом начале XX века…
Но если рукопись — бессмысленный набор букв пера шаловливого монаха, дворянина в измененном сознании? Нет, однозначно нет. Бездумно шлепая по клавишам, я, например, изображу всем привычный модулированный QWERTY-клавиатурой белый шум наподобие “asfds dsf”. Графологическая экспертиза показывает: автор писал твердой рукой набитые “в подкорку” символы хорошо известного ему алфавита. Плюс корреляции распределения букв и слов в тексте рукописи соответствуют “живому” тексту. К примеру, в рукописи, разделенной условно на 6 разделов, есть слова — “эндемики”, часто встречающиеся в каком-нибудь одном из разделов, но отсутствующие в прочих.
Но что если рукопись — сложный шифр, и попытки взломать его теоретически лишены смысла? Если принять на веру почтенный возраст текста, версия шифровки крайне маловероятна. Средние века могли предложить разве шифр подстановки, который так легко и элегантно ломал еще Эдгар Аллан По. И снова, корреляция букв и слов текста не характерна для подавляющего большинства шифров.
Несмотря на колоссальные успехи в переводе древних письменностей, в том числе, с применением современных вычислительных ресурсов, рукопись Войнича до сих пор не поддается ни профессиональным языковедам со стажем, ни молодым амбициозным data-scientist-ам.
… но написание отличается? Кто, например, распознает в этом тексте латынь?

А вот другой пример — транслитерация английского текста на греческий:
пайтоновской библиотекой Transliterate. NB: это уже не шифр подстановки — некоторые многобуквенные сочетания передаются одной буквой и наоборот.
Я попробую опознать (классифицировать) язык рукописи или же найти наиболее близкого родственника ему из известных языков, выделив характерные черты (features) и обучив на них модель:
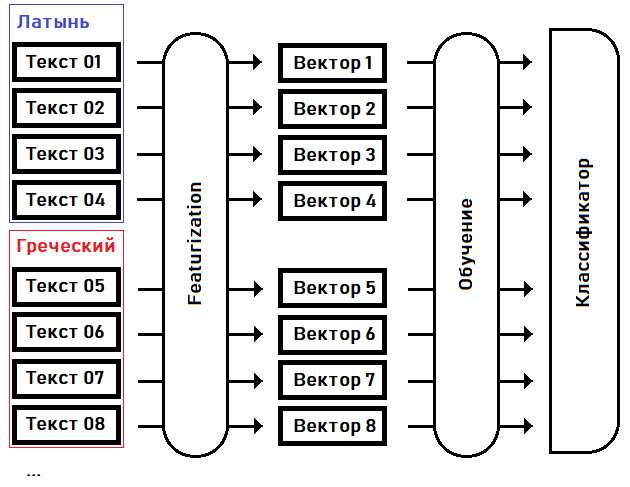
На первом этапе — featurization — мы превращаем тексты в feature-вектора: фиксированного размера массивы вещественных чисел, где каждая размерность вектора отвечает за свою особую черту (feature) исходного текста. Например, условимся в 15-м измерении вектора сохранять частоту употребления в тексте самого распространенного слова, 16-м измерением — второго по популярности слова … в N-м измерении — наибольшую длину последовательности из одного и того же повторяющегося слова и т.д.
На втором шаге — обучение — мы подбираем коэффициенты классификатора исходя из априорного знания языка каждого из текстов.
Как только классификатор натренирован, мы можем использовать эту модель для определения языка текста, не попавшего в обучающую выборку. Например, для текста рукописи Войнича.
Сложность заключается в том, как конкретно превратить текстовый файл в вектор. Отделив зерна от плевел и оставив лишь те характеристики, что свойственны языку в целом, а не каждому конкретному тексту.
Если, упрощая, превратить исходные тексты в кодировку (т.е. числа), и “скормить” эти данные как есть одной из многочисленных нейросетевых моделей, результат, вероятно, нас не порадует. Вероятней всего, натренированная на таких данных модель будет привязана к алфавиту и именно на основе символов, прежде всего, попытается определить язык неизвестного текста.
Но алфавит манускрипта “не имеет аналогов ”. Более того, мы не можем полностью положиться на закономерности в распределении букв. Теоретически возможен и вариант передачи фонетики одного языка правилами другого (язык эльфийский — а руны мордорские).
Коварный писец не использовал ни знаков препинания, ни цифр, известных нам. Весь текст можно рассматривать как поток слов, разделенных на абзацы. Нет даже уверенности в том, где кончается одно предложение и начинается другое.
Значит, поднимемся на уровень выше относительно букв и будем опираться на слова. Составим на основе текста рукописи словарь и проследим закономерности уже на уровне слов.
Разумеется, кодировать замысловатые символы манускрипта Войнича в их Unicode-эквиваленты и обратно самостоятельно вовсе не требуется — эту работу уже проделали за нас, например, здесь. С опциями по-умолчанию я получу следующий эквивалент первой строки манускрипта:
Точки и восклицательные знаки (а также ряд других символов алфавита EVA) — всего лишь разделители, которые для наших целей вполне можно заменить пробелами. Знаки вопроса и звездочки — нераспознанные слова / буквы.
Для проверки подставим текст сюда и получим фрагмент рукописи:

Вот ссылка на репозитарий кода с необходимым минимумом подсказок в README, чтобы протестировать код в работе.
Я собрал по 20+ текстов на латыни, русском, английском, польском, и греческом языках стараясь выдерживать объем каждого текста в ± 35 000 слов (объем рукописи Войнича).
Тексты старался подбирать близких датировок, в одном написании — например, в русскоязычных текстах избегал буквы Ѣ, а варианты написания греческих букв с различными диакритическими знаками приводил к единому знаменателю. Также убрал из текстов цифры, спец. символы, лишние пробелы, привел буквы к одному регистру.
Следующий шаг — построить “словарь”, содержащий такую информацию как:
“Корень” слова я забрал в кавычки — простой алгоритм (да и я сам иногда) не в состоянии определить, к примеру, какой корень у слова подставка? Подставка? Подставка?
Вообще говоря, этот словарь — наполовину подготовленные данные для построения feature-вектора. Почему я выделил этот этап — составление и кэширование словарей по отдельным текстам и по совокупности текстов для каждого из языков? Дело в том, что такой словарь строится довольно долго, порядка полуминуты на каждый текстовый файл. А текстовых файлов у меня набралось уже более 120.
Получение feature-вектора — всего лишь предварительный этап для дальнейшей магии классификатора. Как ООП-фрик я, разумеется, создал абстрактный класс BaseFeaturizer для вышестоящей логики, чтобы не нарушать принцип инверсии зависимостей. Этот класс завещает потомкам уметь превращать один или же сразу много текстовых файлов в числовые вектора.
А еще класс-наследник должен давать каждой отдельной feature (i-координате feature-вектора) имя. Это пригодится, если мы решим визуализировать машинную логику классификации. Например, 0-е измерение вектора будет помечено как CRw1 — автокорреляция частоты употребления слов, взятых из текста на соседней позиции (с лагом 1).
От класса BaseFeaturizer я унаследовал класс WordMorphFeaturizer, логика которого базируется на частоте употребления слов во всем тексте и в рамках скользящего окна из 12 слов.
Важный аспект — код конкретного наследника BaseFeaturizer помимо собственно текстов нуждается еще в подготовленных на их основе словарях (класс CorpusFeatures), которые уже скорее всего закэшированы на диске на момент старта обучения и тестирования модели.
Следующий абстрактный класс — BaseClassifier. Этот объект может обучаться, а затем классифицировать тексты по их feature-векторам.
Для реализации (класс RandomForestLangClassifier) я выбрал алгоритм Random Forest Classifier из библиотеки sklearn. Почему именно этот классификатор?
Так как, на мой взгляд, Random Forest Classifier вполне справился со своей задачей, других реализаций я уже не писал.
80% файлов — большие фрагменты из опусов Байрона, Аксакова, Апулея, Павсания и прочих авторов, чьи тексты я смог найти в формате txt — были отобраны случайным образом для тренировки классификатора. Оставшиеся 20% (28 файлов) определены для вневыборочного тестирования.
Пока я тестировал классификатор на ~30 английских и 20 русских текстах, классификатор давал большой процент ошибок: почти в половине случаев язык текста определялся неверно. Но когда я завел ~120 текстовых файлов на 5 языках (русский, английский, латынь, староэллинский и польский) классификатор перестал ошибаться и начал распознавать корректно язык 27 — 28 файлов из 28 тестовых примеров.
Затем я несколько усложнил задачу: ирландский роман XIX века “Rachel Gray” записал транслитом на греческий и подал на вход обученному классификатору. Язык текста в транслите снова был определен корректно.
Вот так выглядит одно из 100 деревьев в составе обученного Random Forest Classifier (чтобы изображение было более читаемым, я отрезал 3 узла правого поддерева):
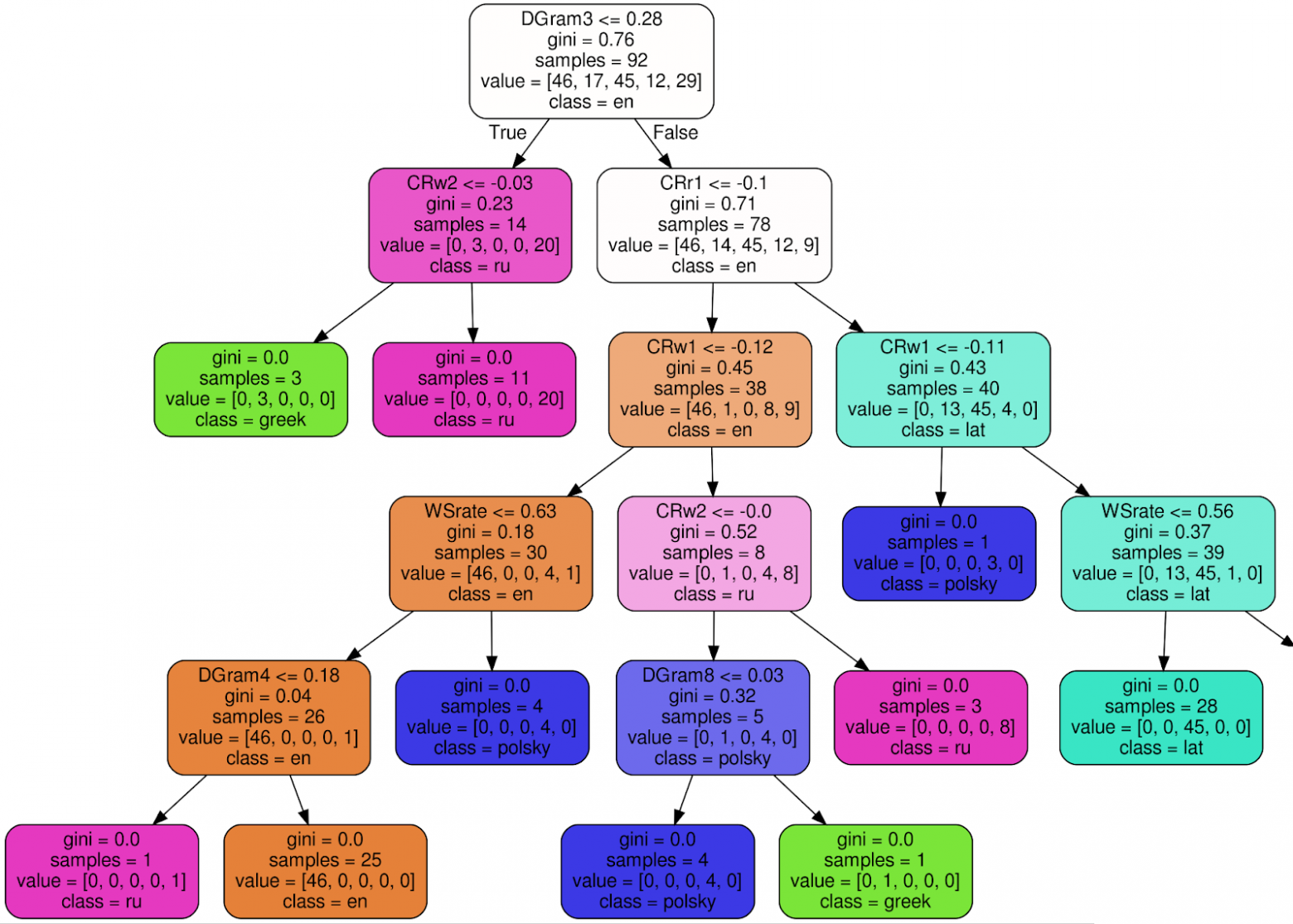
На примере корневого узла поясню значение каждой подписи:
Если критерий (DGram3 <= 0.28 для корневого узла) выполняется, переходим к левому поддереву, иначе — к правому. В каждом листе все тексты должны быть отнесены к одному классу (языку) а критерий неопределенности Джини ≡ 0.
Окончательное же решение принимает ансамбль из 100 подобных деревьев, построенных в ходе обучения классификатора.
Латынь, оценка вероятности 0.59. И, разумеется, это еще не разгадка проблемы столетия.
Соответствие один к одному словаря манускрипта и латинского языка установить непросто — если вообще возможно. Вот, к примеру, десятка самых часто употребляемых слов: рукописи Войнича, латыни,
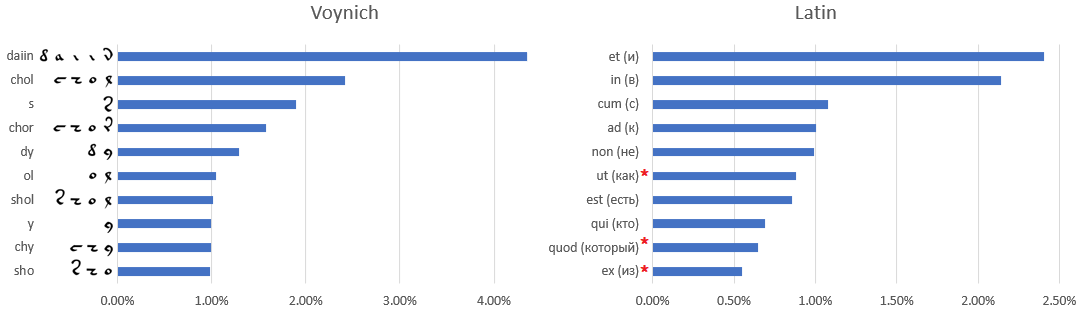
древнегреческого и русского языков:

Звездочкой отмечены слова, которым трудно подобрать русский эквивалент — например, артикли либо предлоги, меняющие значение в зависимости от контекста.
Очевидного соответствия вроде
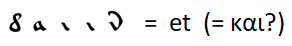
с распространением правил замены букв на остальные часто употребляемые слова мне найти не удалось. Можно лишь делать предположения — например, самое часто употребляемое слово — это союз “и” — как и во всех остальных рассмотренных языках за исключением английского, в котором союз “and” был задвинут на второе место определенным артиклем “the”.
Во-первых, стоит попытаться дополнить выборку языков текстами на современном французском, испанском, …, ближневосточных языках, по возможности — древнеанглийском, языках франции (до XV века) и прочих. Если даже ни один их этих языков не является языком рукописи, всё же повысится точность определения известных языков, а языку манускрипта, возможно, будет подобран более близкий эквивалент.
Более творческая задача — попытаться определить часть речи для каждого слова. Для ряда языков (разумеется, прежде всего — английского) с этой задачей хорошо справляются PoS (Part of Speech) токенизаторы в составе доступных для скачивания пакетов. Но как определить роли слов неизвестного языка?
Схожие задачи решал советский лингвист Б.В. Сухотин — например, он описал алгоритмы:
Для PoS-токенизации мы можем отталкиваться от частоты употребления слов, вхождения в сочетания из 2 / 3 слов, распределения слов по разделам текста: союзы и частицы должны быть распределены более равномерно, чем существительные.
Не буду оставлять здесь ссылки на книги и руководства по NLP — этого достаточно в сети. Вместо этого перечислю художественные произведения, которые стали для меня большой находкой еще в детстве, где героям пришлось потрудиться над разгадкой зашифрованных текстов:
1 Что это — манускрипт Войнича?
Манускрипт Войнича — таинственная рукопись (кодекс, манускрипт или просто книга) в добрых 240 страниц пришедшая к нам, предположительно, из XV века. Рукопись была случайно приобретена у антиквара мужем знаменитой писательницы-карбонария Этель Войнич — Уилфредом Войничем — в 1912 году и скоро стала достоянием широкой общественности.
Язык рукописи не определен до сих пор. Ряд исследователей манускрипта предполагают, что текст рукописи — шифровка. Иные уверены, что манускрипт написан на языке, не сохранившемся в известных нам сегодня текстах. Третьи и вовсе считают манускрипт Войнича бессмыслицей (см современный гимн абсурдизму Codex Seraphinianus).
В качестве примера приведу сканированный фрагмент сабжа с текстом и нимфами:
2 Чем так интересен диковинный манускрипт?
Может быть, это — поздняя подделка? По-видимому, нет. В отличие от Туринской плащаницы, ни радиоуглеродный анализ, ни прочие попытки оспорить древность пергамента пока не дали однозначного ответа. А ведь Войнич не мог предвидеть изотопный анализ в самом начале XX века…
Но если рукопись — бессмысленный набор букв пера шаловливого монаха, дворянина в измененном сознании? Нет, однозначно нет. Бездумно шлепая по клавишам, я, например, изображу всем привычный модулированный QWERTY-клавиатурой белый шум наподобие “asfds dsf”. Графологическая экспертиза показывает: автор писал твердой рукой набитые “в подкорку” символы хорошо известного ему алфавита. Плюс корреляции распределения букв и слов в тексте рукописи соответствуют “живому” тексту. К примеру, в рукописи, разделенной условно на 6 разделов, есть слова — “эндемики”, часто встречающиеся в каком-нибудь одном из разделов, но отсутствующие в прочих.
Но что если рукопись — сложный шифр, и попытки взломать его теоретически лишены смысла? Если принять на веру почтенный возраст текста, версия шифровки крайне маловероятна. Средние века могли предложить разве шифр подстановки, который так легко и элегантно ломал еще Эдгар Аллан По. И снова, корреляция букв и слов текста не характерна для подавляющего большинства шифров.
Несмотря на колоссальные успехи в переводе древних письменностей, в том числе, с применением современных вычислительных ресурсов, рукопись Войнича до сих пор не поддается ни профессиональным языковедам со стажем, ни молодым амбициозным data-scientist-ам.
3 Но что если язык манускрипта нам известен
… но написание отличается? Кто, например, распознает в этом тексте латынь?
А вот другой пример — транслитерация английского текста на греческий:
in one of the many little suburbs which cling to the outskirts of london ιν ονε οφ θε μανυ λιττλε συμπυρμπσ whιχ cλιγγ το θε ουτσκιρτσ οφ λονδον
пайтоновской библиотекой Transliterate. NB: это уже не шифр подстановки — некоторые многобуквенные сочетания передаются одной буквой и наоборот.
Я попробую опознать (классифицировать) язык рукописи или же найти наиболее близкого родственника ему из известных языков, выделив характерные черты (features) и обучив на них модель:
На первом этапе — featurization — мы превращаем тексты в feature-вектора: фиксированного размера массивы вещественных чисел, где каждая размерность вектора отвечает за свою особую черту (feature) исходного текста. Например, условимся в 15-м измерении вектора сохранять частоту употребления в тексте самого распространенного слова, 16-м измерением — второго по популярности слова … в N-м измерении — наибольшую длину последовательности из одного и того же повторяющегося слова и т.д.
На втором шаге — обучение — мы подбираем коэффициенты классификатора исходя из априорного знания языка каждого из текстов.
Как только классификатор натренирован, мы можем использовать эту модель для определения языка текста, не попавшего в обучающую выборку. Например, для текста рукописи Войнича.
4 На картинке всё так просто — в чем подвох?
Сложность заключается в том, как конкретно превратить текстовый файл в вектор. Отделив зерна от плевел и оставив лишь те характеристики, что свойственны языку в целом, а не каждому конкретному тексту.
Если, упрощая, превратить исходные тексты в кодировку (т.е. числа), и “скормить” эти данные как есть одной из многочисленных нейросетевых моделей, результат, вероятно, нас не порадует. Вероятней всего, натренированная на таких данных модель будет привязана к алфавиту и именно на основе символов, прежде всего, попытается определить язык неизвестного текста.
Но алфавит манускрипта “не имеет аналогов ”. Более того, мы не можем полностью положиться на закономерности в распределении букв. Теоретически возможен и вариант передачи фонетики одного языка правилами другого (язык эльфийский — а руны мордорские).
Коварный писец не использовал ни знаков препинания, ни цифр, известных нам. Весь текст можно рассматривать как поток слов, разделенных на абзацы. Нет даже уверенности в том, где кончается одно предложение и начинается другое.
Значит, поднимемся на уровень выше относительно букв и будем опираться на слова. Составим на основе текста рукописи словарь и проследим закономерности уже на уровне слов.
5 Исходный текст манускрипта
Разумеется, кодировать замысловатые символы манускрипта Войнича в их Unicode-эквиваленты и обратно самостоятельно вовсе не требуется — эту работу уже проделали за нас, например, здесь. С опциями по-умолчанию я получу следующий эквивалент первой строки манускрипта:
fachys.ykal.ar.ataiin.shol.shory.cth!res.y.kor.sholdy!-
Точки и восклицательные знаки (а также ряд других символов алфавита EVA) — всего лишь разделители, которые для наших целей вполне можно заменить пробелами. Знаки вопроса и звездочки — нераспознанные слова / буквы.
Для проверки подставим текст сюда и получим фрагмент рукописи:
6 Программа — классификатор текстов (Python)
Вот ссылка на репозитарий кода с необходимым минимумом подсказок в README, чтобы протестировать код в работе.
Я собрал по 20+ текстов на латыни, русском, английском, польском, и греческом языках стараясь выдерживать объем каждого текста в ± 35 000 слов (объем рукописи Войнича).
Тексты старался подбирать близких датировок, в одном написании — например, в русскоязычных текстах избегал буквы Ѣ, а варианты написания греческих букв с различными диакритическими знаками приводил к единому знаменателю. Также убрал из текстов цифры, спец. символы, лишние пробелы, привел буквы к одному регистру.
Следующий шаг — построить “словарь”, содержащий такую информацию как:
- частота употребления каждого слова в тексте (текстах),
- “корень” слова — а точнее, неизменяемая, общая часть для множества слов,
- распространенные “приставки” и “окончания” — а точнее, начала и окончания слов, вместе с “корнем” составляющие собственно слова,
- распространенные последовательности из 2-х и 3-х одинаковых слов и частота их появления.
“Корень” слова я забрал в кавычки — простой алгоритм (да и я сам иногда) не в состоянии определить, к примеру, какой корень у слова подставка? Подставка? Подставка?
Вообще говоря, этот словарь — наполовину подготовленные данные для построения feature-вектора. Почему я выделил этот этап — составление и кэширование словарей по отдельным текстам и по совокупности текстов для каждого из языков? Дело в том, что такой словарь строится довольно долго, порядка полуминуты на каждый текстовый файл. А текстовых файлов у меня набралось уже более 120.
7 Featurization
Получение feature-вектора — всего лишь предварительный этап для дальнейшей магии классификатора. Как ООП-фрик я, разумеется, создал абстрактный класс BaseFeaturizer для вышестоящей логики, чтобы не нарушать принцип инверсии зависимостей. Этот класс завещает потомкам уметь превращать один или же сразу много текстовых файлов в числовые вектора.
А еще класс-наследник должен давать каждой отдельной feature (i-координате feature-вектора) имя. Это пригодится, если мы решим визуализировать машинную логику классификации. Например, 0-е измерение вектора будет помечено как CRw1 — автокорреляция частоты употребления слов, взятых из текста на соседней позиции (с лагом 1).
От класса BaseFeaturizer я унаследовал класс WordMorphFeaturizer, логика которого базируется на частоте употребления слов во всем тексте и в рамках скользящего окна из 12 слов.
Важный аспект — код конкретного наследника BaseFeaturizer помимо собственно текстов нуждается еще в подготовленных на их основе словарях (класс CorpusFeatures), которые уже скорее всего закэшированы на диске на момент старта обучения и тестирования модели.
8 Классификация
Следующий абстрактный класс — BaseClassifier. Этот объект может обучаться, а затем классифицировать тексты по их feature-векторам.
Для реализации (класс RandomForestLangClassifier) я выбрал алгоритм Random Forest Classifier из библиотеки sklearn. Почему именно этот классификатор?
- Random Forest Classifier мне подошел со своими параметрами по-умолчанию,
- он не требует нормализации входных данных,
- предлагает простую и наглядную визуализацию алгоритма принятия решения.
Так как, на мой взгляд, Random Forest Classifier вполне справился со своей задачей, других реализаций я уже не писал.
9 Обучение и тестирование
80% файлов — большие фрагменты из опусов Байрона, Аксакова, Апулея, Павсания и прочих авторов, чьи тексты я смог найти в формате txt — были отобраны случайным образом для тренировки классификатора. Оставшиеся 20% (28 файлов) определены для вневыборочного тестирования.
Пока я тестировал классификатор на ~30 английских и 20 русских текстах, классификатор давал большой процент ошибок: почти в половине случаев язык текста определялся неверно. Но когда я завел ~120 текстовых файлов на 5 языках (русский, английский, латынь, староэллинский и польский) классификатор перестал ошибаться и начал распознавать корректно язык 27 — 28 файлов из 28 тестовых примеров.
Затем я несколько усложнил задачу: ирландский роман XIX века “Rachel Gray” записал транслитом на греческий и подал на вход обученному классификатору. Язык текста в транслите снова был определен корректно.
10 Алгоритм классификации наглядно
Вот так выглядит одно из 100 деревьев в составе обученного Random Forest Classifier (чтобы изображение было более читаемым, я отрезал 3 узла правого поддерева):
На примере корневого узла поясню значение каждой подписи:
- DGram3 <= 0.28 — критерий классификации. В данном случае DGram3 — конкретное именованное классом WordMorphFeaturizer измерение feature-вектора, а именно, частота третьего по распространенности слова в скользящем окне из 12 слов,
- gini = 0.76 — коэффициент, известный как Gini impurity, объясняется, например, в этой статье. Не вдаваясь в подробности, можно сказать, что этот коэффициент характеризует степень неопределенности относительно принадлежности входных данных какому-либо конкретному классу. Продвигаясь от корня в сторону листьев мы наблюдаем уменьшение коэффициента. Наконец, для листа gini, закономерно, равен 0 (жребий брошен),
- samples = 92 — количество текстов, на которых построено поддерево,
- value = [46, 17, 45, 12, 29] — количество текстов в поддереве, попавших в ту или иную категорию (46 английских, 17 греческих, 45 латинских и т.д.),
- class = en (английский текст) — определяется по наиболее заполненному поддереву.
Если критерий (DGram3 <= 0.28 для корневого узла) выполняется, переходим к левому поддереву, иначе — к правому. В каждом листе все тексты должны быть отнесены к одному классу (языку) а критерий неопределенности Джини ≡ 0.
Окончательное же решение принимает ансамбль из 100 подобных деревьев, построенных в ходе обучения классификатора.
11 И как же определила программа язык манускрипта?
Латынь, оценка вероятности 0.59. И, разумеется, это еще не разгадка проблемы столетия.
Соответствие один к одному словаря манускрипта и латинского языка установить непросто — если вообще возможно. Вот, к примеру, десятка самых часто употребляемых слов: рукописи Войнича, латыни,
древнегреческого и русского языков:
Звездочкой отмечены слова, которым трудно подобрать русский эквивалент — например, артикли либо предлоги, меняющие значение в зависимости от контекста.
Очевидного соответствия вроде
с распространением правил замены букв на остальные часто употребляемые слова мне найти не удалось. Можно лишь делать предположения — например, самое часто употребляемое слово — это союз “и” — как и во всех остальных рассмотренных языках за исключением английского, в котором союз “and” был задвинут на второе место определенным артиклем “the”.
Что дальше?
Во-первых, стоит попытаться дополнить выборку языков текстами на современном французском, испанском, …, ближневосточных языках, по возможности — древнеанглийском, языках франции (до XV века) и прочих. Если даже ни один их этих языков не является языком рукописи, всё же повысится точность определения известных языков, а языку манускрипта, возможно, будет подобран более близкий эквивалент.
Более творческая задача — попытаться определить часть речи для каждого слова. Для ряда языков (разумеется, прежде всего — английского) с этой задачей хорошо справляются PoS (Part of Speech) токенизаторы в составе доступных для скачивания пакетов. Но как определить роли слов неизвестного языка?
Схожие задачи решал советский лингвист Б.В. Сухотин — например, он описал алгоритмы:
- разделения символов неизвестного алфавита на гласные и согласные — к сожалению, не 100% надежного, в особенности для языков с нетривиальной передачей фонетики, вроде французского,
- выделение морфем в тексте без пробелов.
Для PoS-токенизации мы можем отталкиваться от частоты употребления слов, вхождения в сочетания из 2 / 3 слов, распределения слов по разделам текста: союзы и частицы должны быть распределены более равномерно, чем существительные.
Литература
Не буду оставлять здесь ссылки на книги и руководства по NLP — этого достаточно в сети. Вместо этого перечислю художественные произведения, которые стали для меня большой находкой еще в детстве, где героям пришлось потрудиться над разгадкой зашифрованных текстов:
- Э. А. По: “Золотой жук” — нестареющая классика,
- В. Бабенко: “Встреча” — лихо закрученная, в чем-то провидческая детективная повесть конца 80-х,
- К. Кирицэ: “Рыцари с Черешневой улицы, или Замок девушки в белом” — увлекательный подростковый роман, написанный без скидки на возраст читателя.
