
Обработка естественного языка сейчас используется повсеместно: стремительно развиваются голосовые интерфейсы и чат-боты, разрабатываются модели для обработки больших текстовых данных, продолжает развиваться машинный перевод.
В этой статье мы рассмотрим относительно новую библиотеку SpaCy, которая на данный момент является одним из самых популярных и удобных решений при обработке текста в Python. Её функционал позволяет решать очень широкий спектр задач: от определения частей речи и выделения именованных сущностей до создания собственных моделей для анализа.
Для начала давайте наглядно рассмотрим, как происходит обработка данных в SpaCy. Загруженный для обработки текст последовательно проходит через различные компоненты обработки и сохраняется как экземпляр объекта Doc:

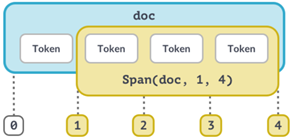
Doc является центральной структурой данных в SpaCy, именно в нём хранятся последовательности слов или, как их ещё называют, токенов. Внутри объекта Doc можно выделить два других типа объекта: Token и Span. Token представляет собой ссылку на отдельные слова документа, а Span – ссылку на последовательность из нескольких слов (их можно создавать самостоятельно):
Ещё одной важной структурой данных является объект Vocab, который хранит набор справочных таблиц, общий для всех документов. Это позволяет экономить память и обеспечивать единый источник информации для всех обрабатываемых документов.
Токены документов связаны с объектом Vocab через хеш, используя который можно получить начальные формы слов или другие лексические атрибуты токенов:

Теперь мы знаем, как устроено хранение и обработка данных в библиотеке SpaCy. А как воспользоваться возможностями, которые она предоставляет? Давайте последовательно рассмотрим операции, с помощью которых можно обработать текст.
1. Базовые операции
Прежде чем начинать работу с текстом, следует импортировать языковую модель. Для русского языка сущ��ствует официальная модель от SpaCy, поддерживающая токенизацию (разбиение текста на отдельные токены) и ряд других базовых операций:
from spacy.lang.ru import RussianПосле импорта и создания экземпляра языковой модели можно начинать обработку текста. Для этого нужно всего лишь передать текст созданному экземпляру:
nlp = Russian()
doc = nlp("Съешь ещё этих мягких французских булок, да выпей чаю.")Работа с получившимся объектом Doc очень схожа с работой со списками: можно обращаться к нужному токену по индексу или делать срезы из нескольких токенов. А чтобы получить текст токена или среза, можно использовать атрибут text:
token = doc[0]
print(token.text)
span = doc[3:6]
print(span.text)
Съешь
мягких французских булокДля получения дополнительной информации о том, какой тип информации содержится в токене, можно использовать следующие атрибуты:
- is_alpha – проверка на то, содержит ли токен только буквенные символы
- is_punct – проверка на то, является ли токен знаком пунктуации
- like_num – проверка на то, является ли токен числом
print("is_alpha: ", [token.is_alpha for token in doc])
print("is_punct: ", [token.is_punct for token in doc])
print("like_num: ", [token.like_num for token in doc])
Рассмотрим ещё пример, где на экран выводятся все токены, предшествующие точке. Чтобы получить такой результат, при переборе токенов следует делать проверку следующего токена, используя атрибут token.i:
for token in doc:
if token.i+1 < len(doc):
next_token = doc[token.i+1]
if next_token.text == ".":
print(token.text)
чаю2. Операции с синтаксисом
Для более сложных операций по обработке текста используются другие модели. Они специально натренированы для задач, связанных с синтаксисом, выделением именованных сущностей и работы со значениями слов. Например, для английского языка существует 3 официальных модели, различающихся размером. Для русского языка на настоящий момент официальная модель ещё не обучена, однако уже есть модель ru2 из сторонних источников, которая умеет работать с синтаксисом.
В конце этой статьи мы разберём, как создавать свои собственные модели или дополнительно обучать существующие, чтобы они лучше работали для конкретных задач.
Чтобы полностью проиллюстрировать возможности SpaCy, в этой статье мы будем использовать модели для английского языка. Давайте установим маленькую модель en_core_web_sm, которая отлично подойдёт для демонстрации возможностей. Для её установки в командной строке необходимо набрать:
python -m spacy download en_core_web_smС использованием этой модели мы можем для каждого из токенов получить часть речи, роль в предложении и токен, от которого он зависит:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("New Apple MacBook set launch tomorrow")
for token in doc:
token_text = token.text
token_pos = token.pos_
token_dep = token.dep_
token_head = token.head.text
print(f"{token_text:<12}{token_pos:<10}" \
f"{token_dep:<10}{token_head:<12}")New PROPN compound MacBook
Apple PROPN compound MacBook
MacBook PROPN nsubj set
set VERB ROOT set
to PART aux launch
launch VERB xcomp set
tomorrow NOUN npadvmod launch Несомненно, лучший способ увидеть зависимости – не вчитываться в текстовые данные, а построить синтаксическое дерево. В этом может помочь функция displacy, которой нужно просто передать документ:
from spacy import displacy
displacy.render(doc, style='dep', jupyter=True)В результате выполнения кода мы получаем дерево, на котором расположена вся синтаксическая информация о предложении:

Для расшифровки названий тегов можно воспользоваться функций explain:
print(spacy.explain("aux"))
print(spacy.explain("PROPN"))
auxiliary
proper nounЗдесь на экран выводятся расшифровки аббревиатур, из которых мы можем узнать, что aux обозначает вспомогательную частицу (auxiliary), а PROPN – имя собственное (proper noun).
В SpaCy также реализована возможность узнать начальную форму слова для любого из токенов (для местоимений используется -PRON-):
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("I saw a movie yesterday")
print(' '.join([token.lemma_ for token in doc]))
'-PRON- see a movie yesterday'3. Выделение именованных сущностей
Часто для работы с текстом требуется выделить сущности, упомянутые в тексте. Чтобы получить список именованных сущностей в документе, используется атрибут doc.ents, а для получения метки для этой сущности – атрибут ent.label_:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for 1$ billion")
for ent in doc.ents:
print(ent.text, ent.label_)
Apple ORG
U.K. GPE
1$ billion MONEYЗдесь также можно использовать атрибут explain, чтобы узнать расшифровки меток именованных сущностей:
print(spacy.explain("GPE"))
Countries, cities, states
А функция displacy поможет наглядно обозначить списки сущностей прямо в тексте:
from spacy import displacy
displacy.render(doc, style='ent', jupyter=True)

4. Создание собственных шаблонов для поиска текста
Модуль spaCy содержит очень полезный инструмент, который позволяет строить свои собственные шаблоны для поиска текста. В частности, можно искать слова определённой части речи, все формы слова по его начальной форме, делать проверку на тип содержимого в токене. Вот список основных параметров:

Давайте попробуем создать собственный шаблон для распознавания последовательности токенов. Допустим, мы хотим извлечь из текста строки про кубки мира FIFA или ICC Cricket с упоминанием года:
import spacy
from spacy.matcher import Matcher
nlp = spacy.load("en_core_web_sm")
matcher = Matcher(nlp.vocab)
pattern = [
{"IS_DIGIT": True},
{"LOWER": {"REGEX": "(fifa|icc)"}},
{"LOWER": "cricket", "OP": "?"},
{"LOWER": "world"},
{"LOWER": "cup"}
]
matcher.add("fifa_pattern", None, pattern)
doc = nlp("2018 ICC Cricket World Cup: Afghanistan won!")
matches = matcher(doc)
for match_id, start, end in matches:
matched_span = doc[start:end]
print(matched_span)2018 ICC Cricket World CupИтак, в этом блоке кода мы импортировали специальный объект Matcher, позволяющий хранить набор пользовательских шаблонов. После его инициализации мы создали шаблон, где указали последовательность токенов. Обратите внимание, что для выбора между ICC и FIFA мы использовали регулярные выражения, а для токена Cricket – ключ, указывающий на необязательность наличия этого токена.
После создания шаблона требуется добавить его к набору с помощью функции add, указав в параметрах уникальный ID шаблона. Результаты поиска представлены в форме списка кортежей. Каждый из кортежей состоит из ID совпадения, а также начального и конечного индексов найденного в документе среза.
5. Определение семантической близости
Два слова могут быть очень схожи по смыслу, но как измерить их близость? В подобных задачах на помощь могут прийти семантические вектора. Если два слова или многословных выражения похожи, то их вектора будут лежать близко друг к другу.
Посчитать семантическую близость векторов в SpaCy несложно, если языковая модель была обучена для решения таких задач. Результат сильно зависит от размера модели, поэтому для этой задачи возьмём модель побольше:
import spacynlp = spacy.load("en_core_web_md")
doc1 = nlp("I like burgers")
doc2 = nlp("I like pizza")
print(doc1.similarity(doc2))0.9244169833828932Значение может колебаться от нуля до единицы: чем ближе к единице, тем больше схожесть. В примере выше мы сравнивали два документа, однако точно так же можно сравнивать отдельные токены и срезы.
Оценка семантической близости может быть полезна при решении множества задач. Например, с её помощью можно настроить рекомендательную систему, чтобы она предлагала пользователю похожие тексты на основе уже прочитанных.
Важно помнить, что семантическая близость очень субъективна и всегда зависит от контекста задачи. Например, фразы «я люблю собак» и «я ненавижу собак» похожи, поскольку обе выражают мнение о собаках, но в то же время сильно различаются по настроению. В некоторых случаях придётся дополнительное обучить языковые модели, чтобы результаты коррелировали с контекстом вашей задачи.
6. Создание своих собственных компонентов обработки
Модуль SpaCy поддерживает ряд встроенных компонентов (токенизатор, выделение именованных сущностей), но также позволяет определять свои собственные компоненты. По сути, компоненты – это последовательно вызывающиеся функции, которые принимают на вход документ, изменяют его и отдают обратно. Новые компоненты можно добавлять с помощью атрибута add_pipe:
import spacy
def length_component(doc):
doc_length = len(doc)
print(f"This document is {doc_length} tokens long.")
return doc
nlp = spacy.load("en_core_web_sm")
nlp.add_pipe(length_component, first=True)
print(nlp.pipe_names)
doc = nlp("This is a sentence.")['length_component', 'tagger', 'parser', 'ner']
This document is 5 tokens long.В примере выше мы создали и добавили собственную функцию, которая выводит на экран количество токенов в обрабатываемом документе. С помощью атрибута nlp.pipe_names мы получили порядок выполнения компонентов: как мы видим, созданный компонент первый в списке. Чтобы указать, куда добавить новый компонент, можно использовать следующие параметры:

Возможность добавления пользовательских компонентов – очень мощный инструмент, позволяющий оптимизировать обработку под свои задачи.
7. Обучение и обновление моделей
Статистические модели делают прогнозы на основе тех примеров, на которых они обучались. Как правило, точность таких моделей можно улучшить, дополнительно обучив их на примерах, характерных для вашей задачи. Дополнительное обучение существующих моделей может быть очень полезно (например, для распознавания именованных сущностей или синтаксического анализа).
Дополнительные примеры для обучения можно добавлять прямо в интерфейсе SpaCy. Сами примеры должны состоять из текстовых данных и списка меток для этого примера, на которых модель будет обучаться.
В качестве иллюстрации рассмотрим обновление модели для извлечения именованных сущностей. Чтобы обновить такую модель, нужно передать ей множество примеров, которые содержат текст, указание на сущности и их класс. В примерах необходимо использовать целые предложения, поскольку при извлечении сущностей модель во многом ориентируется на контекст предложения. Очень важно всесторонне обучить модель, чтобы она умела распознавать токены, не являющиеся сущностями.
Например:
("What to expect at Apple's 10 November event", {"entities": [(18,23,"COMPANY")]})
("Is that apple pie I smell?", {"entities": []})В первом примере упоминается компания: для обучения мы выделяем позиции, где начинается и заканчивается её наименование, а затем проставляем нашу метку о том, что эта сущность является компанией. Во втором примере речь идёт о фрукте, поэтому сущности отсутствуют.
Данные для обучения модели обычно размечаются людьми, однако эту работу можно немного автоматизировать, использ��я собственные поисковые шаблоны в SpaCy или специализированные программы для разметки (например, Prodigy).
После того, как примеры будут подготовлены, можно приступать непосредственно к обучению модели. Чтобы модель эффективно обучилась, нужно провести серию из нескольких обучений. С каждым обучением модель будет оптимизировать веса тех или иных параметров. Модели в SpaCy используют методику стохастического градиентного спуска, поэтому неплохим решением будет перемешивать примеры при каждом обучении, а также передавать их небольшими порциями (пакетами). Это увеличит надежность оценок градиента.

import spacy
import random
from spacy.lang.en import English
TRAINING_DATA = [
("What to expect at Apple's 10 November event",
{"entities": [(18,23,"COMPANY")]})
# Другие примеры...
]
nlp = English()
for i in range(10):
random.shuffle(TRAINING_DATA)
for batch in spacy.util.minibatch(TRAINING_DATA):
texts = [text for text, annotation in batch]
annotations = [annotation for text, annotation in batch]
nlp.update(texts, annotations)
nlp.to_disk("model")В примере выше цикл состоял из 10 обучений. После завершения обучения модель была сохранена на диск, в папку model.
Для случаев, когда нужно не просто обновить, а создать новую модель, перед началом обучения требуется совершить ряд операций.
Рассмотрим процесс создания новой модели для выделения именованных сущностей:
nlp = spacy.blank("en")
ner = nlp.create_pipe("ner")
nlp.add_pipe(ner)
ner.add_label("COMPANY")
nlp.begin_training()Сначала мы создаём пустую модель при помощи функции spacy.blank(«en»). Модель содержит только языковые данные и правила токенизации. Затем добавляем компонент ner, отвечающий за выделение именованных сущностей, и с помощью атрибута add_label добавляем метки для сущностей. После чего применяем функцию nlp.begin_training(), чтобы инициализировать модель для обучения со случайным распределением весов. Ну а дальше достаточно будет обучить модель, как было показано в предыдущем примере.
