В некоторых проектах сборке отводится роль Золушки. Основные усилия команда сосредоточивает на разработке кода. А самой сборкой могут заниматься люди, далёкие от разработки (например, отвечающие за эксплуатацию, либо за развёртывание). Если сборка хоть как-то работает, то её предпочитают не трогать, и речь об оптимизации не заходит. Вместе с тем в больших гетерогенных проектах сборка оказывается достаточно сложной и к ней вполне можно подходить как к самостоятельному проекту. Если же относиться к сборке как к второстепенному проекту, то в результате будет получен неудобоваримый императивный скрипт, поддержка которого будет в значительной степени затруднена.
В предыдущей заметке мы рассмотрели, по каким критериям мы выбирали инструментарий, и почему остановились на gradle/kotlin, а в этой заметке рассмотрим, каким образом используем gradle/kotlin для автоматизации сборки не-JVM проектов. (Есть также перевод на английский.)

Введение
Gradle для JVM-проектов является общепризнанным инструментом и не нуждается в дополнительных рекомендациях. Для проектов за пределами JVM он также используется. Например, в официальной документации описаны сценарии использования для C++ и Swift проектов. Мы используем gradle для автоматизации сборки, тестирования и развёртывания гетерогенного проекта, включающего модули на node.js, go, terraform.
Использование git submodule для организации интеграционной сборки
Каждый модуль большого проекта разрабатывается отдельной командой в своём репозитории. В то же время, хотелось бы работать с большим проектом как с одной целостной системой:
- предоставлять единые настройки для проектов,
- осуществлять интеграционное тестирование,
- выполнять развёртывание в различных конфигурациях,
- выпускать согласованные релизы,
- и т.д.
Достаточно удобно подключить репозитории проектов в один репозиторий с помощью git submodule. При этом мы имеем возможность работать с одной сквозной версией всех подпроектов. Каждый из подпроектов будет зафиксирован на одном коммите. В случае реализации функциональности, затрагивающей несколько подпроектов, мы можем создать ветку в проекте верхнего уровня и для каждого подпроекта указать подветку, которую следует использовать. Тем самым появляется возможность согласованной разработки и тестирования именно этой новой функциональности без интерференции со стороны других функциональных возможностей.
При развёртывании используется имя ветки проекта верхнего уровня для идентификации ресурсов, относящихся к этой ветке. Такая схема идентификации позволяет непосредственно перед удалением ветки автоматически удалить все связанные ресурсы.
Краткий обзор, как работает gradle
Фаза инициализации. Gradle вначале ищет settings.gradle.kts, компилирует и исполняет его, чтобы выяснить, какие подпроекты и где расположены. Компиляция здесь и в других точках — только по мере необходимости, если файл и зависимости не менялись, то будет использована последняя скомпилированная версия.
Фаза конфигурации. Затем для всех проектов находятся скрипты сборки и тоже компилируются (по мере необходимости) и исполняются (только те проекты, которые нужны для целевой задачи).
Основной моделью представления системы сборки является направленный граф без циклов (DAG). Узлами графа служат задачи, между которыми устанавливаются зависимости. Частично зависимости выводятся gradle-ом с использованием свойств задач (подробнее — ниже). Граф задач в целом очень похож на структуру, используемую в make.
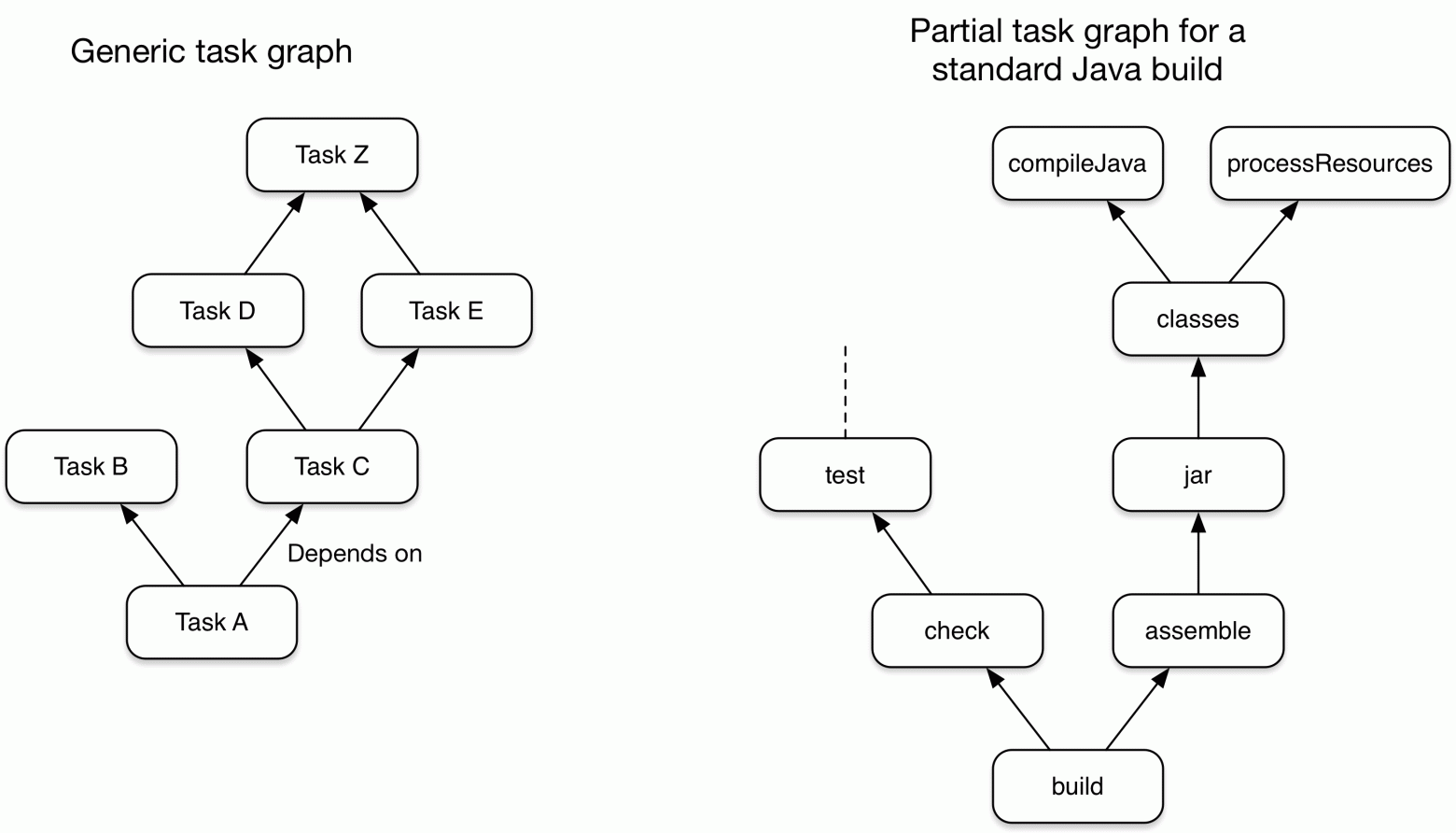
Фаза исполнения. По построенному частичному графу зависимостей между задачами определяется подграф, который необходим для достижения целей текущей целевой задачи. Для задач проверяется выполнение условия up-to-date, то есть, надо ли выполнять задачу или нет. И потом выполняются только те задачи, которые нужны.
Код сборки на основе только лишь графа задач представляет собой трудно поддерживаемый императивный скрипт. Для того, чтобы упорядочить аналогичные наборы задач, относящиеся к разным модулям, в gradle имеются понятия проектов и плагинов. Проектом называется модуль, представляющий часть исходного кода большого проекта, а плагином — повторно используемый набор взаимосвязанных задач, которые инстанцируются для конкретного проекта. Похожие понятия используются и в maven.
DSL (domain-specific language)
Gradle использует гибкий подход к организации скрипта сборки на основе идеи встроенного специализированного языка. В основной язык (groovy или kotlin) добавляются функции, объекты и классы, спроектированные специальным образом, чтобы при их использовании получались легко воспринимаемые скрипты, похожие на декларативное описание проекта. То есть, несмотря на то, что скрипт сборки представляет собой императивную программу, он может выглядеть как декларативное описание конфигурации плагинов и структуры проекта.
В этом подходе кроется как сила/удобство gradle, так и уязвимость к чрезмерному использованию императивных возможностей. На данный момент выглядит так, что единственное средство — самодисциплина.
Общие соображения, как лучше использовать gradle/kotlin
Встроенный проект buildSrc
Настройка сборки проекта в основном делается в скриптах build.gradle.kts. Среди прочего эти скрипты позволяют создавать ad-hoc задачи и выполнять произвольный код. Если не соблюдать самодисциплину и не следовать рекомендациям, то скрипт сборки быстро превращается в макаронный код. Поэтому создание тасков и использование исполняемого кода внутри скрипта сборки следует считать исключением и временной мерой, и помнить, что поддержка проекта сборки с императивной логикой в скриптах сборки крайне затруднительна.
Основным местом для императивной логики и пользовательских задач следует считать вспомогательный проект buildSrc. Этот проект компилируется автоматически и добавляется в зависимости скрипта сборки. Так что всё, что в нём объявлено, будет доступно для использования в скриптах.
В самом скрипте сборки остаются объявления плагинов, их конфигурации и настройки проекта.
Проект buildSrc является совершенно обыкновенным JVM-проектом. В нём располагается обычный код, можно добавлять ресурсы, писать тесты, реализовывать сложные сценарии сборки. (При этом получается что-то вроде "рекурсивной сборки".) Основным результатом сборки этого вспомогательного проекта являются классы, которые будут автоматически добавлены в classpath всех проектов. То есть если объявить плагин в buildSrc, то без всяких дополнительных настроек этот плагин можно будет использовать во всех проектах и подпроектах.
Следует также отметить, что buildSrc не содержит скриптов, которые будут выполняться в фазе конфигурации. То есть, если нужно создать какие-то задачи, необходимо вызвать код. Либо прямым вызовом какой-либо функции, либо применением плагина (будет вызван метод apply(Project)).
Плагины
Для разных типов проектов (go, node.js, terraform) имеет смысл создавать плагины. Имеющиеся плагины (например, kosogor для terraform'а) можно использовать, но некоторых возможностей может не хватить.
Плагин можно делать в buildSrc, либо в качестве отдельных проектов для повторного использования. Если используются отдельные проекты, то либо надо подключать эти проекты в качестве included build, либо публиковать артефакты в развёрнутом репозитории (Artifactory, Nexus).
Плагин можно рассмотреть как совокупность следующих элементов:
- декларативная конфигурация;
- скрипт/процедура создания задач на основе конфигурации;
- возможность однократного подключения к отдельному проекту и
настройки подключенного экземпляра;
Простой плагин может выглядеть так:
open class MyPluginExtension(objects: ObjectFactory) { val name: Property<String> = objects.property(String::class.java) val message: Property<String> = objects.property(String::class.java) init { name.convention("World") message.convention(name.map{"Hello " + it}) } } class MyPlugin: Plugin<Project> { override fun apply(target: Project) { val ext = target.extensions.create("helloExt", MyPluginExtension::class.java) target.tasks.register("hello-name"){ it.doLast{ println(ext.message.get()) } } } }
Некоторым неудобством плагинов является необходимость создания задач и расширения (объекта конфигурации) в момент применения плагина. Только после этого появляется возможность конфигурирования плагина. Такой порядок работы не очень удобен, т.к. в момент создания задач конфигурация ещё отсутствует. Поэтому приходится использовать более сложный механизм свойств и провайдеров. Они позволяют оперировать с будущими значениями, которые окажутся доступны только в фазе исполнения. (См. ниже подробнее про свойства.) При этом важно не пытаться использовать значения свойств на этапе конфигурирования, т.к. они будут иметь значения по умолчанию (convention).
Пользовательский DSL
Кроме собственно плагинов, похожего результата можно достичь просто вызывая заранее написанные функции, создающие задачи.
В качестве примера можно посмотреть, как в библиотеке kosogor сделано добавление задач с помощью DSL.
terraform { config { tfVersion = "0.11.11" } root("example", File(projectDir, "terraform")) }
Внешняя функция terraform выглядит как extension для типа Project:
@TerraformDSLTag fun Project.terraform(configure: TerraformDsl.() -> Unit) { terraformDsl.project = this terraformDsl.configure() }
То есть код, который напишет пользователь внутри {} будет выполнен на объекте типа TerraformDsl. Например, метод root создаёт задачи с использованием конфигурации и переданного в метод имени:
@TerraformDSLTag fun root(name: String, dir: File, enableDestroy: Boolean = false, targets: LinkedHashSet<String> = LinkedHashSet(), workspace: String? = null) { val lint = project!!.tasks.create("$name.lint", LintRootTask::class.java) { task -> task.group = "terraform.$name" task.description = "Lint root $name" task.root = dir } // ... }
Использование в Kotlin методов, принимающих последним параметром функции вида Type.()->Unit, позволяет сделать DSL, который выглядит достаточно элегантно и удобно. В чём-то это предоставляет больше гибкости и удобства, чем плагины. Например, в момент работы метода root предшествующий метод config уже завершён и все конфигурационные параметры доступны напрямую. Правда, при этом теряются возможности, предоставляемые свойствами (см. ниже).
Tips&tricks
Почему важно добиваться инкрементности билда
Сборка проекта может запускаться сотни раз в день. Если при этом билд-скрипт делает лишнюю работу, то это может выливаться в заметные потери времени. В запущенных случаях, если, например, сборка занимает 10-30 минут, работа существенно затрудняется и может вызывать раздражение. Если сборка выполняется в облаке и производит развёртывание в нескольких конфигурациях, то длительная работа скрипта может приводить и к повышению расходов.
Свойство "инкрементности" не появляется само по себе. Инкрементным билд становится в том случае, если все задачи поддерживают это свойство. В идеальном случае повторный запуск последней команды gradle должен происходить за доли секунды, т.к. все задачи будут пропущены.
Автоматические зависимости на основе свойств и файлов
Если задача Б зависит от результата задачи А, то можно так сконфигурировать эти задачи, что gradle догадается, что надо выполнить задачу А, даже без явного указания зависимости.
Для этого в gradle предусмотрен целый механизм properties и providers (в других языках/системах похожим образом можно использовать монады). (Механизм, в целом похож на "настройки" в sbt.) На этапе конфигурирования некоторые значения должны быть спрятаны внутрь провайдеров. Если одно значение вычисляется (или в частном случае равно) на основе другого значения, то у провайдера источника вызывается .map или .flatMap и внутри лямбды можно оперировать будущим значением. При этом будет создан "провайдер", который вычислит значение выражения по требованию в фазе исполнения.
Пример
class TaskA: DefaultTask() { @OutputFile val result = project.objects.fileProperty() init { result.convention(project.buildDir.file("result.txt")) } } class TaskB: DefaultTask() { @InputFile val input = project.objects.fileProperty() @Action fun taskB() { println(input.get().asFile.absolutePath) } }
В скрипте зависимость между этими задачами можно не объявлять явно, при условии, что связаны свойства:
val taskA = tasks.register<TaskB>("taskA") { output.set(file("other.txt")) } tasks.register<TaskB>("taskB") { input.set(taskA.result) }
Теперь, при вызове taskB будет проверяться актуальность задачи А и, в случае необходимости, выполняться.
Использование файлов в качестве сигналов, которые переживают вызовы
При выполнении операций, которые только производят побочные эффекты (например, развёртывание в облако), и не отражаются естественным образом в файловой системе, gradle не может проверить, надо ли выполнять задачу или не надо. В результате соответствующая задача будет выполняться всякий раз.
Чтобы помочь gradle-у, можно по окончании выполнения задачи создавать файл taskB.done, и указать, что этот файл является выходным для задачи. В этом файле желательно отразить в сжатом виде описание того, в каком состоянии находится облачная конфигурация. Можно, например, указать sha развёрнутой конфигурации или просто текстом — развёрнутые компоненты и их версии.
Если несколько задач меняют общее облачное состояние, то в этом случае полезно это состояние представлять в виде одного или нескольких файлов, общих для этих задач (cloud.state). Каждая задача, меняющая состояние в облаке, также приведёт к изменению локальных файлов. Тем самым gradle будет понимать, какие задачи могут потребовать перезапуска.
Перезапуск локального сервиса, только если изменился исполняемый файл
Пусть у нас есть задача сборки, которая производит исполняемый файл
class BuildNative(objects: ObjectFactory): DefaultTask() { @OutputFile val nativeBinary: FileProperty = objects.fileProperty() init { nativeBinary.convention("binary") } @TaskAction fun build() { // ... } }
Запуск сервиса производится созданием процесса с именем этого исполняемого файла.
open class StartService(objects: ObjectFactory): DefaultTask() { @InputFile val nativeBinary: FileProperty = objects.fileProperty() @OutputFile val pidFile: FileProperty = objects.fileProperty() init { nativeBinary.convention("binary") pidFile.convention("binary.pid") } @TaskAction fun start() { pidFile.get().asFile.writeText( Process(nativeBinary.get().asFile.absolutePath).start() )// несколько упрощённо } }
Теперь мы можем объявить задачу перезапуска, которая не будет выполняться, если исполняемый файл не изменился
class ServiceStarted(objects: ObjectFactory): StartService(objects) { @TaskAction fun restartIfNeeded() { if(pidFile.get().asFile.exists()) { kill(pidFile.get().asFile.readText()) } start() } }
Такая цепочка задач удобна для локальной отладки сервисов. При изменении любой строчки в любом из сервисов, только он будет пересобран и перезапущен.
Централизованное задание номеров портов
Для тестирования может потребоваться запуск конфигураций с различным составом сервисов. Сервисы зависят друг от друга. В паре сервисов порт взаимодействия необходимо указать дважды — в самом сервисе и в клиенте этого сервиса. Ясно, что согласно принципу единственной версии правды (SVOT/SSOT), порт должен быть указан в одной точке, а в остальных местах следует ссылаться на этот доверенный источник. Единая конфигурация сервиса должна быть доступна и для самого сервиса и для клиента.
Рассмотрим пример, как это можно сделать в gradle.
data class ServiceAConfig(val port: Int, val path: String) { fun localUrl(): URL = URL("http://localhost:$port/$path") }
В главном скрипте build.gradle.kts мы создаём конфигурацию и помещаем её в extra:
val serviceAConfig: ServiceAConfig by extra(ServiceAConfig(8080, "serviceA/test"))
А в других скриптах мы можем получить доступ к этой конфигурации, объявленной в rootProject'е:
val serviceAConfig: ServiceAConfig by rootProject.extra
Таким образом обеспечивается возможность связывания сервисов и централизации конфигурации.
Непрошенные советы
- Прочитайте документацию. Документация gradle может служить образцом для подражания в других проектах.
- Поймите модель gradle. Множество вопросов отпадёт само по себе, если разобраться с базовой моделью gradle.
- Используйте buildSrc. При сборке проектов зачастую требуется добавить отдельные вспомогательные задачи. Помещайте такие задачи в
buildSrc. Также можно создавать самостоятельные проекты с плагинами, что позволит использовать их в других проектах. - Добивайтесь инкрементности каждой задачи. В этом случае изменение любой строчки кода
приведёт к выполнению только строго необходимых задач. Сборка будет происходить
максимально быстро. - Делитесь знаниями. Многие вещи в gradle и в kotlin могут оказаться непривычными для людей, не имевших опыта работы с ними, то есть существует определённый порог входа. Внесение изменений вслепую, без понимания принципов работы системы сборки, весьма затруднительно, и вряд ли приведёт к хорошему результату.
Заключение
В этом посте мы рассмотрели некоторые особенности инструментария сборки проекта и CI/CD на основе gradle/kotlin. Gradle оказывается достаточно удобен и для сборки не-JVM-проектов. При этом сохраняются почти все преимущества — модульность, скорость работы, защита от ошибок. Если соблюдать самодисциплину и разрабатывать проект сборки с учётом общих принципов инженерии, то gradle позволяет получить гибкую систему, которую достаточно легко поддерживать.
Благодарности
Хотелось бы поблагодарить nolequen, Starcounter, tovarischzhukov за конструктивную критику черновика статьи.
