Этот заключительный пост посвящен анализу дисперсии. Предыдущий пост см. здесь.
Анализ дисперсии
Анализ дисперсии (варианса), который в специальной литературе также обозначается как ANOVA от англ. ANalysis Of VAriance, — это ряд статистических методов, используемых для измерения статистической значимости расхождений между группами. Он был разработан чрезвычайно одаренным статистиком Рональдом Фишером, который также популяризировал процедуру проверки статистической значимости в своих исследовательских работах по биологическому тестированию.
Примечание. В предыдущей и этой серии постов для термина «variance» использовался принятый у нас термин «дисперсия» и в скобках местами указывался термин «варианс». Это не случайно. За рубежом существуют парные термины «variance» и «covariance», и они по идее должны переводиться с одним корнем, например, как «варианс» и «коварианс», однако на деле у нас парная связь разорвана, и они переводятся как совершенно разные «дисперсия» и «ковариация». Но это еще не все. «Dispersion» (статистическая дисперсия) за рубежом является отдельным родовым понятием разбросанности, т.е. степени, с которой распределение растягивается или сжимается, а мерами статистической дисперсии являются варианс, стандартное отклонение и межквартильный размах. Dispersion, как родовое понятие разбросанности, и variance, как одна из ее мер, измеряющая расстояние от среднего значения - это два разных понятия. Далее в тексте для variance везде будет использоваться общепринятый термин «дисперсия». Однако данное расхождение в терминологии следует учитывать.
Наши тесты на основе z-статистики и t-статистики были сосредоточены на выборочных средних значениях как первостепенном механизме проведения разграничения между двумя выборками. В каждом случае мы искали расхождение в средних значениях, деленных на уровень расхождения, который мы могли обоснованно ожидать, и количественно выражали стандартной ошибкой.
Среднее значение не является единственным выборочным индикатором, который может указывать на расхождение между выборками. На самом деле, в качестве индикатора статистического расхождения можно также использовать выборочную дисперсию.
, постранично и совмещенно")
В целях иллюстрации того, как это могло бы работать, рассмотрим приведенную выше диаграмму. Каждая из трех групп слева может представлять выборки времени пребывания на конкретном веб-сайте с его собственным средним значением и стандартным отклонением. Если время пребывания для всех трех групп объединить в одну, то дисперсия будет больше средней дисперсии для групп, взятых отдельно.
Статистическая значимость на основе анализа дисперсии вытекает из соотношения двух дисперсий — дисперсии между исследуемыми группами и дисперсии внутри исследуемых групп. Если существует значимое межгрупповое расхождение, которое не отражено внутри групп, то эти группы помогают объяснить часть дисперсии между группами. И напротив, если внутригрупповая дисперсия идентична межгрупповой дисперсии, то группы статистически от друг друга неразличимы.
F-распределение
F-распределение параметризуется двумя степенями свободы — степенями свободы размера выборки и числа групп.
Первая степень свободы — это количество групп минус 1, и вторая степень свободы — размер выборки минус число групп. Если k представляет число групп, и n — объем выборки, то получаем:


Мы можем визуализировать разные F-распределения на графике при помощи функции библиотеки pandas plot:
def ex_2_Fisher(): '''Визуализация разных F-распределений на графике''' mu = 0 d1_values, d2_values = [4, 9, 49], [95, 90, 50] linestyles = ['-', '--', ':', '-.'] x = sp.linspace(0, 5, 101)[1:] ax = None for (d1, d2, ls) in zip(d1_values, d2_values, linestyles): dist = stats.f(d1, d2, mu) df = pd.DataFrame( {0:x, 1:dist.pdf(x)} ) ax = df.plot(0, 1, ls=ls, label=r'$d_1=%i,\ d_2=%i$' % (d1,d2), ax=ax) plt.xlabel('$x$\nF-статистика') plt.ylabel('Плотность вероятности \n$p(x|d_1, d_2)$') plt.show()

Кривые приведенного выше графика показывают разные F-распределения для выборки, состоящей из 100 точек, разбитых на 5, 10 и 50 групп.
F-статистика
Тестовая выборочная величина, которая представляет соотношение дисперсии внутри и между группами, называется F-статистикой. Чем ближе значение F-статистики к единице, тем более похожи обе дисперсии. F-статистика вычисляется очень просто следующим образом:

где S2b — это межгрупповая дисперсия, и S2w — внутригрупповая дисперсия.
По мере увеличения соотношения F межгрупповая дисперсия увеличивается по сравнению с внутригрупповой. Это означает, что это разбиение на группы хорошо справляется с задачей объяснения дисперсии, наблюдавшейся по всей выборке в целом. Там, где это соотношение превышает критический порог, мы можем сказать, что расхождение является статистически значимым.
F-тест всегда является односторонним, потому что любая дисперсия среди групп демонстрирует тенденцию увеличивать F. При этом F не может уменьшаться ниже нуля.
Внутригрупповая дисперсия для F-теста вычисляется как среднеквадратичное отклонение от среднего значения. Мы вычисляем ее как сумму квадратов отклонений от среднего значения, деленную на первую степень свободы. Например, если имеется k групп, каждая со средним значением x̅k, то мы можем вычислить внутригрупповую дисперсию следующим образом:

где SSW — это внутригрупповая сумма квадратов, и xjk — это значение j-ого элемента в группе .
Приведенная выше формула для вычисления SSW имеет грозный вид, но на деле довольно легко имплементируется на Python, как сумма квадратичных отклонений от среднего значения ssdev, делающая вычисление внутригрупповой суммы квадратов тривиальным:
def ssdev( xs ): '''Сумма квадратов отклонений между каждым элементом и средним по выборке''' mu = xs.mean() square_deviation = lambda x : (x - mu) ** 2 return sum( map(square_deviation, xs) )
Межгрупповая дисперсия для F-теста имеет похожую формулу:

где SST — это полная сумма квадратов отклонений, и SSW — значение, которое мы только что вычислили. Полная сумма квадратов является суммой квадратичных расхождений от «итогового» среднего значения, которую можно вычислить следующим образом:

Отсюда, SST — это попросту полная сумма квадратов без какого-либо разбиения на группы. На языке Python значения SST и SSW вычисляются элементарно, как будет показано ниже.
ssw = sum( groups.apply( lambda g: ssdev(g) ) ) # внутригрупповая сумма # квадратов отклонений sst = ssdev( df['dwell-time'] ) # полная сумма квадратов по всему набору ssb = sst – ssw # межгрупповая сумма квадратов отклонений
F-статистика вычисляется как отношение межгрупповой дисперсии к внутригрупповой. Объединив определенные ранее функции ssb и ssw и две степени свободы, мы можем вычислить F-статистика.
На языке Python F-статистика из групп и двух степеней свободы вычисляется следующим образом:
msb = ssb / df1 # усредненная межгрупповая msw = ssw / df2 # усредненная внутригрупповая f_stat = msb / msw
Имея возможность вычислить F-статистику из групп, мы теперь готовы использовать его в соответствующем F-тесте.
F-тест
Как и в случае со всеми проверками статистических гипотез, которые мы рассмотрели в этой серии постов, как только имеется выборочная величина (статистика) и распределение, нам попросту нужно подобрать значение уровня значимости и посмотреть, не превысили ли наши данные критическое для теста значение.
Библиотека scipy предлагает функцию stats.f.sf, но она измеряет дисперсию между и внутри всего двух групп. В целях выполнения F-теста на наших 20 разных группах, нам придется имплементировать для нее нашу собственную функцию. К счастью, мы уже проделали всю тяжелую работу в предыдущих разделах, вычислив надлежащую F-статистику. Мы можем выполнить F-тест, отыскав F-статистику в F-распределении, параметризованном правильными степенями свободы. В следующем ниже примере мы напишем функцию f_test, которая все это использует для выполнения теста на произвольном числе групп:
def f_test(groups): m, n = len(groups), sum(groups.count()) df1, df2 = m - 1, n - m ssw = sum( groups.apply(lambda g: ssdev(g)) ) sst = ssdev( df['dwell-time'] ) ssb = sst - ssw msb = ssb / df1 msw = ssw / df2 f_stat = msb / msw return stats.f.sf(f_stat, df1, df2) def ex_2_24(): '''Проверка вариантов дизайна веб-сайта на основе F-теста''' df = load_data('multiple-sites.tsv') groups = df.groupby('site')['dwell-time'] return f_test(groups)
0.014031745203658217
В последней строке приведенной выше функции мы преобразуем значение F-статистики в p-значение, пользуясь функцией scipy stats.f.sf, параметризованной правильными степенями свободы. P-значение является мерой всей модели, т.е. насколько хорошо разные веб-сайты объясняют дисперсию времени пребывания в целом. Нам остается только выбрать уровень значимости и выполнить проверку. Будем придерживаться 5%-ого уровня значимости.
Проверка возвращает p-значение, равное 0.014, т.е. значимый результат. Разные варианты веб-сайта действительно имеют разные дисперсии, которые нельзя просто объяснить одной лишь случайной ошибкой в выборке.

Для визуализации распределений всех вариантов дизайна веб-сайта на одном графике мы можем воспользоваться коробчатой диаграммой, разместив распределения для сопоставления рядом друг с другом:
def ex_2_25(): '''Визуализация распределений всех вариантов дизайна веб-сайта на одной коробчатой диаграмме''' df = load_data('multiple-sites.tsv') df.boxplot(by='site', showmeans=True) plt.xlabel('Номер дизайна веб-сайта') plt.ylabel('Время пребывания, сек.') plt.title('') plt.suptitle('') plt.show()
В приведенном выше примере показана работа функции boxplot, которая вычисляет свертку на группах и сортирует группы по номеру варианта дизайна веб-сайта. Соответственно наш изначальный веб-сайт с номером 0, на графике расположен крайним слева.
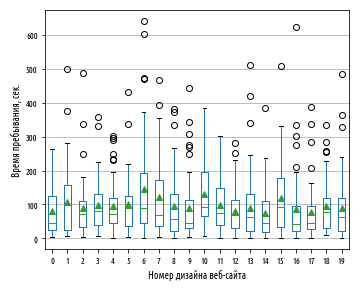
Может создастся впечатление, что вариант дизайна веб-сайта с номером 10 имеет самое длительное время пребывания, поскольку его межквартильный размах простирается вверх выше других. Однако, если вы присмотритесь повнимательнее, то увидите, что его среднее значение меньше, чем у варианта дизайна с номером 6, имеющего среднее время пребывания более 144 сек.:
def ex_2_26(): '''T-проверка вариантов 0 и 10 дизайна веб-сайта''' df = load_data('multiple-sites.tsv') groups = df.groupby('site')['dwell-time'] site_0 = groups.get_group(0) site_10 = groups.get_group(10) _, p_val = stats.ttest_ind(site_0, site_10, equal_var=False) return p_val
0.0068811940138903786
Подтвердив статистически значимый эффект при помощи F-теста, теперь мы вправе утверждать, что вариант дизайна веб-сайта с номером 6 статистически отличается от изначального значения:
def ex_2_27(): '''t-тест вариантов 0 и 6 дизайна веб-сайта''' df = load_data('multiple-sites.tsv') groups = df.groupby('site')['dwell-time'] site_0 = groups.get_group(0) site_6 = groups.get_group(6) _, p_val = stats.ttest_ind(site_0, site_6, equal_var=False) return p_val
0.005534181712508717
Наконец, у нас есть подтверждающие данные, из которых вытекает, что веб-сайт с номером 6 является подлинным улучшением существующего веб-сайта. В результате нашего анализа исполнительный директор AcmeContent санкционирует запуск обновленного дизайна веб-сайта. Веб-команда - в восторге!
Размер эффекта
В этой серии постов мы сосредоточили наше внимание на широко используемых в статистической науке методах проверки статистической значимости, которые обеспечивают обнаружение статистического расхождения, которое не может быть легко объяснено случайной изменчивостью. Мы должны всегда помнить, что выявление значимого эффекта — это не одно и то же, что и выявление большого эффекта. В случае очень больших выборок значимым будет считаться даже крошечное расхождение в выборочных средних. В целях более глубокого понимания того, является ли наше открытие значимым и важным, мы так же должны констатировать величину эффекта.
Интервальный индекс d Коэна
Индекс d Коэна — это поправка, которую применяется для того, чтобы увидеть, не является ли наблюдавшееся расхождение не просто статистически значимым, но и действительно большим. Как и поправка Бонферрони, она проста:
Здесь Sab — это объединенное стандартное отклонение (не объединенная стандартная ошибка) выборок. Она вычисляется аналогично вычислению объединенной стандартной ошибки:
def pooled_standard_deviation(a, b): '''Объединенное стандартное отклонение (не объединенная стандартная ошибка)''' return sp.sqrt( standard_deviation(a) ** 2 + standard_deviation(b) ** 2)
Так, для варианта под номером 6 дизайна нашего веб-сайта мы можем вычислить индекс d Коэна следующим образом:
def ex_2_28(): '''Вычисление интервального индекса d Коэна для варианта дизайна веб-сайта под номером 6''' df = load_data('multiple-sites.tsv') groups = df.groupby('site')['dwell-time'] a = groups.get_group(0) b = groups.get_group(6) return (b.mean() - a.mean()) / pooled_standard_deviation(a, b)
0.38913648705499848
В отличие от p-значений, абсолютный порог для индекса d Коэна отсутствует. Считать ли эффект большим или нет частично зависит от контекста, однако этот индекс действительно предоставляет полезную, нормализованную меру величины эффекта. Значения выше 0.5, как правило, считаются большими, поэтому значение 0.38 — это умеренный эффект. Он определенно говорит о значительном увеличении времени пребывания на нашем веб-сайте и что усилия, потраченные на обновление веб-сайта, определенно не были бесполезными.
Примеры исходного кода для этого поста находятся в моем репо на Github. Все исходные данные взяты в репозитории автора книги.
Резюме
В этой серии постов мы узнали о разнице между описательной и инференциальной статистикой, занимающейся методами статистического вывода. Мы еще раз убедились в важности нормального распределения и центральной предельной теоремы, и научились квантифицировать расхождение с популяциями, используя проверку статистических гипотез на основе z-теста, t-теста и F-теста.
Мы узнали о том, каким именно образом методология инференциальной статистики анализирует непосредственно сами выборки, чтобы выдвигать утверждения о всей популяции в целом, из которой они были отобраны. Мы познакомились с целым рядом методов —интервалами уверенности, размножением выборок путем бутстрапирования и проверкой статистической значимости — которые помогают разглядеть глубинные параметры популяции. Симулируя многократные испытания, мы также получили представление о трудности проверки статистической значимости в условиях многократных сравнений и увидели, как F-тест помогает решать эту задачу и устанавливать равновесие между ошибками 1-го и 2-го рода.
Мы также коснулись терминологических болевых точек и выяснили некоторые нюансы смыслового дрейфа в отечественной статистике.
В следующей серии постов, если читатели пожелают, мы применим полученные знания о дисперсии и F-тесте к одиночным выборкам. Мы представим метод регрессионного анализа и воспользуемся им для обнаружения корреляции между переменными в выборке из спортсменов-олимпийцев.
