Недавно нужно было написать API автотесты - запросы Post с большим количеством параметров в теле, в том числе вложенные JSON объекты, массивы , массивы JSON объектов. Многие параметры не обязательные, а значит - большое количество наборов тестовых данных.
Дано: Датапровайдер - для многократного запуска тестов, тестовые данные в таблице Excel.
Что бы сформировать тело первого запроса пришлось создать несколько классов, через сеттеры присваивать значения переменным в классе и из базового класса формировать JSON, который и использовался как тело запроса. И вдруг оказалось, что все написанное никак не получится переиспользовать для других эндпоинтов. Тогда и решил написать метод, который будет превращать таблицу Excel в JSON объект без всяких там классов и правок в коде. Нужно только придерживаться некоторых правил при составлении таблицы.
Итак! Для получения данных из таблицы использовал, как обычно, Fillo. Название столбца будет ключом, значения в столбце, собственно, значениями ключа в запросе. Строка таблицы - один набор тестовых данных.
Должно быть как-то так на входе:
shop_name | сity |
shop#1 | Charkiv |
shop#2 | Kyiv |
shop#3 | Dnipro |
На выходе:
[{"shop_name": "shop#1", "сity": "Charkiv"}, {"shop_name": "shop#2", "сity": "Kyiv"}, {"shop_name": "shop#3", "сity": "Dnipro"}]
Для начала, метод для получения ВСЕХ данных из Excel листа в виде массива мапов. Раньше использовал для похожих задач для вебтестов. Метод принимает две строки: путь к Excel файлу и название листа. Это единственные константы, которые вам придется захардкодить, все остальное управление формированием тела запроса выполняется из Excel файла. Я создаю для этого класс констант и там, если необходимо, меняю значение, которое потом используется во всех тестах.
Hidden text
public List fromExcelToListOfMaps (String docPath, String sheet) { PATH_TO_EXCEL_DOC = docPath; Fillo fillo = new Fillo(); Connection connection; List<Map<String, String>> listOfMaps = new ArrayList<>(); try { /* getting all the data from excel file */ connection = fillo.getConnection(PATH_TO_EXCEL_DOC); Recordset recordset = connection.executeQuery("Select * From " +sheet+" "); /* getting column names*/ ArrayList<String> keys = recordset.getFieldNames(); int size = keys.size(); /* creating array of maps*/ while (recordset.next()) { Map<String, String> values = new LinkedMap<>(); for (int i = 0; i <size; i++) { String key = keys.get(i); String value = recordset.getField(key); values.put(key, value); } listOfMaps.add(values); } recordset.close(); connection.close(); } catch (FilloException e) { e.printStackTrace(); } return listOfMaps; }
результат:
[{shop_name=shop#1, сity=Charkiv}, {shop_name=shop#2, сity=Kyiv}, {shop_name=shop#3, сity=Dnipro}]
Превратить мапу в JSON с помощью GSON можно за одно действие, но тут оказалось, что сервер не принимает пустые ключи, поэтому их нужно выпилить в процессе. Следующий метод принимает на вход массив из метода fromExcelToListOfMaps , удаляет ключи без значений и возвращает массив JSON строк.
public List<String> dataToListOfJson(List<Map<String, String>> listOfMaps){ Gson gson = new Gson(); List<String> listOfJson = new ArrayList<>(); for (int i=0; i<listOfMaps.size(); i++) { /* * getting each map collection * */ Map<String,String> row = listOfMaps.get(i); /* * deleting empty values */ row.entrySet().removeIf(y -> (y.getValue().equals(""))); /* * Turn map without empty fields to json */ String requestBody = gson.toJson(row); listOfJson.add(requestBody); } return listOfJson; }
На входе:
shop_name | сity |
shop#1 | Charkiv |
Kyiv | |
shop#3 |
После первого метода:
[{shop_name=shop#1, сity=Charkiv},
{shop_name=, сity=Kyiv},
{shop_name=shop#3, сity=}]
На выходе:
[{"shop_name":"shop#1","сity":"Charkiv"},
{"сity":"Kyiv"},
{"shop_name":"shop#3"}]
В таком виде уже можно отправлять результат в датапровайдер, но у меня значения не только типа String. А как объяснить методу, что вот это вот boolean, а вот это Integer и кавычки тут не нужны, а там вообще массив JSON объектов. И в коде указывать нельзя, получится не универсально. Решил в название столбцов добавить ключевые слова:
string - нет ключевого слова
boolean - bool
float - flo
int - int
Ключевое слово отделяется от имени ключа двумя звездочками (**). Теперь, после проверки на пустые значения, выполняется проверка на наличия ключевого слова в названии столбца, и, если это слово есть и соответствует одному из приведенных выше, создается новый ключ (отбрасывается ключевое слово и звездочки) и ему присваивается значение с приведением к нужному типу данных. Выглядит примерно так:
public static final String FLOAT_VAL = "flo"; public static final String BOOLEAN_VAL = "bool"; /*work with Float*/ else if (keyWord.equals(FLOAT_VAL)){ value = value.replace(",", "."); JsonElement a = gson.toJsonTree(Float.parseFloat(value)); jsElemMap.add(key.substring(x+2), a); } /*work with Boolean*/ else if (keyWord.equals(BOOLEAN_VAL)){ JsonElement a = gson.toJsonTree(Boolean.parseBoolean(value)); jsElemMap.add(key.substring(x+2), a);
после чего из мапы выпиливаются все пары в ключе которых присутствуют ** . Т.е. если написать в таблице ключевое слово с ошибкой, то эта колонка в запрос не попадет.
В результате
На входе:
shop_name | сity | Int**employee_qty | Bool**Sunday_off |
shop#1 | Charkiv | 3 | true |
shop#2 | Kyiv | 3 | true |
shop#3 | Dnipro | 2 | false |
на выходе:
[{"shop_name":"shop#1","сity":"Charkiv","employee_qty":3,"Sunday_off":true}, {"shop_name":"shop#2","сity":"Kyiv","employee_qty":3,"Sunday_off":true}, {"shop_name":"shop#3","сity":"Dnipro","employee_qty":2,"Sunday_off":false}]
Конечно работать с разными типами данных в Map<String, String> не получится, поэтому все результаты пересобираются в переменную типа JsonObject.
Дальше нужно было добавить ключи со значениями класса JsonObject. Конечно можно просто в Excel ячейку записать что-то типа {"salary": 25.0,"bonus": 4.75}, но ведь у меня уже есть метод, который который соберет JSON из листа Excel. Нужно только указать лист и строку которая будет использоваться. Получилось чуть-чуть рекурсии. Ключевое слово:
JsonObject - Если в качестве значения ключа нужен JsonObject, то ключевое слово должно совпадать с названием Excel листа, из которого берутся данные (добавил метод получающий все имена листов Excel файла в массив). Значение в ячейке (тип int) - номер строки в этом листе (нумерация с нуля).
/*work with JsonObjects */ /*If Excel file contains sheet which name equals keyWord */ else if (excelSheetNames(PATH_TO_EXCEL_DOC).contains(keyWord)){ /*get this sheet as list of json*/ List aa = dataToListOfJson2(fromExcelToListOfMaps(PATH_TO_EXCEL_DOC,keyWord)); /*and add one of json as value of current key*/ jsElemMap.add(key.substring(x+2), gson.toJsonTree(aa.get(Integer.parseInt(value)))); }
В результате на входе:

На выходе:
[{"Id":0,"First_Name":"Wasja","Last_Name":"Smith","Age":19,"Gender":"m","paycheck":{"salary":20.0}}, {"Id":1,"First_Name":"Tanja","Last_Name":"Johnson","Age":25,"Gender":"f","paycheck":{"salary":20.0}}, {"Id":250,"First_Name":"Ighor","Last_Name":"Williams","Age":42,"Gender":"m","paycheck":{"salary":25.0,"bonus":4.75}}, {"Id":13,"First_Name":"Masha","Last_Name":"Brown","Age":19,"Gender":"f","paycheck":{"salary":25.0,"bonus":4.75}}, {"Id":4,"First_Name":"Olja","Last_Name":"Davis","Age":18,"Gender":"f","paycheck":{"salary":33.3,"bonus":5.8}}, {"Id":40,"First_Name":"Oleg","Last_Name":"Miller","Age":25,"Gender":"m","paycheck":{"bonus":100.0}}, {"Id":6,"First_Name":"Kolja","Last_Name":"Wilson","Age":21,"Gender":"m","paycheck":{"salary":33.3,"bonus":5.8}}, {"Id":7,"First_Name":"Andrew","Last_Name":"Moore","Age":20,"Gender":"m","paycheck":{"salary":25.0,"bonus":4.75}}]
Остались массивы. Наверное, стоило написать логику с нуля, но я поленился и решил из JsonObject и выбранной строки просто все значения перенести в List<Object> . Написал отдельный метод. На вход принимает путь к Excel файлу, имя листа и номер строки (нумерация с нуля)
public List arrayVal(String pathToExcel, String sheetName, int rowNumber){ List<JsonObject> x = dataToListOfJson2(fromExcelToListOfMaps(pathToExcel, sheetName)); JsonObject dataForArray = x.get(rowNumber); List<Object> arr= new LinkedList<>(); for(String key : dataForArray.keySet()){ arr.add(dataForArray.get(key)); } return arr; }
Ключевое слово:
List<Object> - arr. Имя столбца должно совпадать с именем Excel листа, из которого будут браться значения для массива. Значение в ячейке (тип int) - номер строки. Имя столбцов в Excel листе из которого будут набираться данные в массив значения не имеют, но они не должны повторяться (Fillo не обработает) и для всех столбцов должно быть одинаковое ключевое слово. (для данных типа String ключевое слово не нужно).
В результате как-то так на входе:

На выходе:
[{"shop_name":"shop#1","сity":"Charkiv","income_per_month":[78500,22222,2222,159]}, {"shop_name":"shop#2","сity":"Kyiv","income_per_month":[56900,11111,987456,6423,98741]}, {"shop_name":"shop#3","сity":"Dnipro","income_per_month":[12694,33333,111111]}]
Вот основной класс с методами:
Hidden text
package api; import com.codoid.products.exception.FilloException; import com.codoid.products.fillo.Connection; import com.codoid.products.fillo.Fillo; import com.codoid.products.fillo.Recordset; import com.google.gson.Gson; import com.google.gson.JsonElement; import com.google.gson.JsonObject; import org.apache.commons.collections4.map.LinkedMap; import java.util.*; import static api.ApiConstants.ApiBodyConstants.*; import static jdk.nashorn.internal.objects.NativeString.toLowerCase; public class ApiBase { public static String PATH_TO_EXCEL_DOC = ""; public List fromExcelToListOfMaps (String docPath, String sheet) { PATH_TO_EXCEL_DOC = docPath; Fillo fillo = new Fillo(); Connection connection; List<Map<String, String>> listOfMaps = new ArrayList<>(); try { /* getting all the data from excel file */ connection = fillo.getConnection(docPath); Recordset recordset = connection.executeQuery("Select * From " +sheet+" "); /* getting column names*/ ArrayList<String> keys = recordset.getFieldNames(); int size = keys.size(); /* creating array of maps*/ while (recordset.next()) { Map<String, String> values = new LinkedMap<>(); for (int i = 0; i <size; i++) { String key = keys.get(i); String value = recordset.getField(key); values.put(key, value); } listOfMaps.add(values); } recordset.close(); connection.close(); } catch (FilloException e) { e.printStackTrace(); } return listOfMaps; } public List<String> dataToListOfJson(List<Map<String, String>> listOfMaps){ Gson gson = new Gson(); List<String> listOfJson = new ArrayList<>(); for (int i=0; i<listOfMaps.size(); i++) { /* * getting each map collection * */ Map<String,String> row = listOfMaps.get(i); /* * deleting empty values */ row.entrySet().removeIf(y -> (y.getValue().equals(""))); /*deleting empty values in a longer way*/ // for (Map.Entry<String, String> entry: row.entrySet()) { // String key = entry.getKey(); // String value = entry.getValue(); // if(value.equals("")){ // row.remove(key); // } // } /* * Turn map without empty fields to json */ String requestBody = gson.toJson(row); listOfJson.add(requestBody); } return listOfJson; } public List<JsonObject> dataToListOfJson2(List<Map<String, String>> listOfMaps){ Gson gson = new Gson(); List<JsonObject> listOfJson = new ArrayList<>(); for (int i=0; i<listOfMaps.size(); i++) { /* * getting each map collection * */ Map<String,String> row = listOfMaps.get(i); JsonObject jsElemMap = new JsonObject(); /* * deleting keys that have empty values */ row.entrySet().removeIf(y -> (y.getValue().equals(""))); /*iteration map to change value classes and add them to json object */ for (Map.Entry<String, String> entry: row.entrySet()) { String key = entry.getKey(); String value = entry.getValue(); if (key.indexOf("**")>0) { int x = key.indexOf("**"); String keyWord = toLowerCase(key.substring(0, x)); /*work with Integer*/ if (keyWord.equals(INT_VAL)){ JsonElement a = gson.toJsonTree(Integer.parseInt(value)); jsElemMap.add(key.substring(x+2), a); } /*work with Float*/ else if (keyWord.equals(FLOAT_VAL)){ value = value.replace(",", "."); JsonElement a = gson.toJsonTree(Float.parseFloat(value)); jsElemMap.add(key.substring(x+2), a); } /*work with Boolean*/ else if (keyWord.equals(BOOLEAN_VAL)){ JsonElement a = gson.toJsonTree(Boolean.parseBoolean(value)); jsElemMap.add(key.substring(x+2), a); } /*work with array*/ else if (keyWord.equals(ARRAY_VAL)&& excelSheetNames(PATH_TO_EXCEL_DOC).contains(key.substring(x+2))){ List arr = arrayVal(PATH_TO_EXCEL_DOC, key.substring(x+2), Integer.parseInt(value)); JsonElement a = gson.toJsonTree(arr); jsElemMap.add(key.substring(x+2), a); } /*work with JsonObjects */ /*If Excel file contains sheet which name equals keyWord */ else if (excelSheetNames(PATH_TO_EXCEL_DOC).contains(keyWord)){ /*get this sheet as list of json*/ List aa = dataToListOfJson2(fromExcelToListOfMaps(PATH_TO_EXCEL_DOC,keyWord)); /*and add one of json as value of current key*/ jsElemMap.add(key.substring(x+2), gson.toJsonTree(aa.get(Integer.parseInt(value)))); } }else{ /*If there is no keyWord*/ jsElemMap.add(key, gson.toJsonTree(value) ); } } /* remove all keys with keyword */ row.entrySet().removeIf(y -> (y.getKey().contains("**"))); /* * Turn map without empty fields to json */ listOfJson.add(jsElemMap); } return listOfJson; } public List arrayVal(String pathToExcel, String sheetName, int rowNumber){ List<JsonObject> x = dataToListOfJson2(fromExcelToListOfMaps(pathToExcel, sheetName)); JsonObject dataForArray = x.get(rowNumber); List<Object> arr= new LinkedList<>(); for(String key : dataForArray.keySet()){ arr.add(dataForArray.get(key)); } return arr; } /*getting names of sheets to list*/ public List<String> excelSheetNames(String filePath){ Fillo fillo = new Fillo(); Connection connection =null; List<String> names = new ArrayList<>(); try { connection = fillo.getConnection(filePath); names = connection.getMetaData().getTableNames(); connection.close(); } catch (FilloException filloException) { connection.close(); filloException.printStackTrace(); } return names; } }
В общем по функционалу на этом все, осталось заполнить таблицу. Оказалось, что указывать номера строк, находящихся на другом листе, не очень-то и удобно, постоянно какая-то путаница. Тут мне на помощь пришли неправильные ключевые слова. Если в имени столбца присутствует две звездочки (**), но текст перед ** не соответствует одному из ключей, то этот столбец в запросе игнорируется, и в него можно писать комментарии, добавлять нумерацию, или выводить результаты теста. Я ставил четыре звездочки, чтобы сходу видеть, что в запрос не попадет. Таблицы стали выглядеть как-то так:
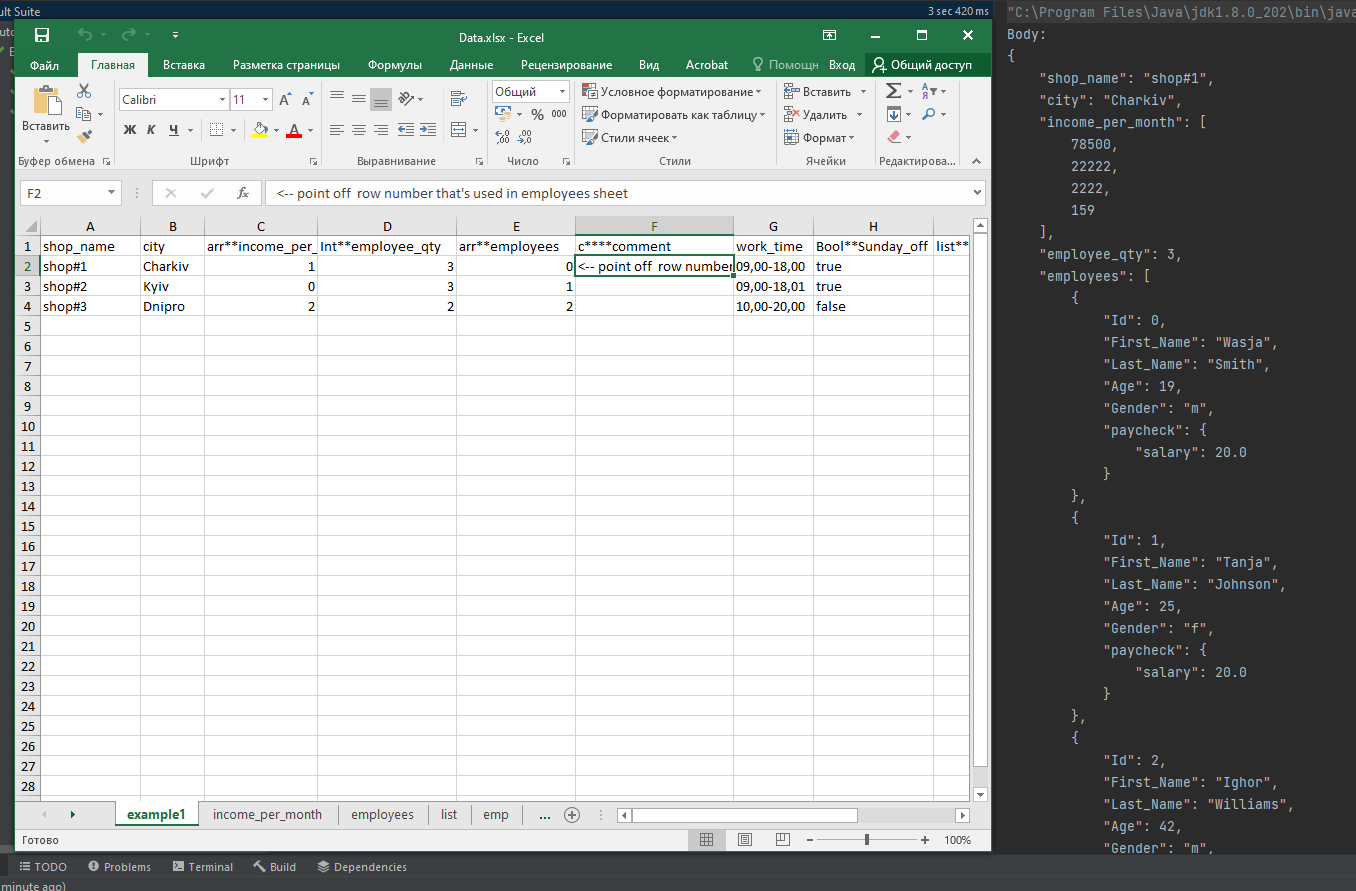
int**Id | First_Name | Last_Name | int**Age | Gender | pay**paycheck | com****coment |
0 | Wasja | Smith | 19 | m | 0 | <-- Point off row****number from the sheet pay |
1 | Tanja | Johnson | 25 | f | 0 | |
2 | Ighor | Williams | 42 | m | 1 | |
3 | Masha | Brown | 19 | f | 1 | |
4 | Olja | Davis | 18 | f | 3 | |
5 | Oleg | Miller | 25 | m | 4 | |
6 | Kolja | Wilson | 21 | m | 3 | |
7 | Andrew | Moore | 20 | m | 1 |
row****numb | flo**salary | flo**bonus |
0 | 20 | |
1 | 25 | 4,75 |
2 | 22 | 4 |
3 | 33,3 | 5,8 |
4 | 100 |
Осталось передать все это в датапровайдер и превратить в классический двухмерный массив строк.
@DataProvider(name = "Request2") public Object[][] request2() { List<JsonObject> listOfJson = base.dataToListOfJson2(base .fromExcelToListOfMaps(PATH_TO_EXCEL_DOC,SHEET_NAME)); String[][] arrayOfJson = new String[listOfJson.size()][1]; for(int i = 0; i< listOfJson.size(); i++){ arrayOfJson[i][0] = listOfJson.get(i).toString(); } return arrayOfJson; }
И дальше в тест:
@Test(dataProvider = "Request2") public void exampleTest1_3 (String request){ given() .spec(requestPostEvents(request)) .when() .log().body() .post(); }
Тело первого теста:
Hidden text
Body:
{
"shop_name": "shop#1",
"сity": "Charkiv",
"income_per_month": [
78500,
22222,
2222,
159
],
"employee_qty": 3,
"employees": [
{
"Id": 0,
"First_Name": "Wasja",
"Last_Name": "Smith",
"Age": 19,
"Gender": "m",
"paycheck": {
"salary": 20.0
}
},
{
"Id": 1,
"First_Name": "Tanja",
"Last_Name": "Johnson",
"Age": 25,
"Gender": "f",
"paycheck": {
"salary": 20.0
}
},
{
"Id": 2,
"First_Name": "Ighor",
"Last_Name": "Williams",
"Age": 42,
"Gender": "m",
"paycheck": {
"salary": 25.0,
"bonus": 4.75
}
}
],
"work_time": "09,00-18,00",
"Sunday_off": true,
"goods": {
"tobacco": true,
"alcohol": true,
"groshery": true,
"weapons": false,
"drugs": false
}
}
Теперь, в случае если будут добавлены, удалены или изменены параметры, или тестовые данные, мне даже не нужно будет заглядывать в код, только подправить табличку. Как и все универсальное, в обращении не очень удобно, но привыкнуть можно.
Все это писалось в отдельном проекте, клонировать можно здесь.
Можно подправить файл Data.xlsx под ваши нужды и позапускать тесты из класса ExampleTests , что бы посмотреть, получите ли вы то, что вам нужно. Если вы начинаете новый проект с API (+WEB) тестами, это можно использовать как шаблон.
Если нужно применить в существующем проекте, но совсем не хочется разбираться как это устроено, то скопируйте пакеты api и файл Data.xlsx в соответствующие разделы вашего проекта на Maven + TestNG, при необходимости добавьте нужные зависимости и пишите тесты в классе ExampleTests.

Собираюсь потихоньку перетянуть сюда все универсальные методы, которые использовал - пусть все лежит в одном месте! Надеюсь, что информация поможет другим начинающим автоматизаторам).
