
Небольшой дисклаймер - статья и проект мои. Изначально опубликовал на английском языке, поэтому повесил плашку "перевод" ибо это и есть перевод.
Введение
Как-то мне пришла в голову мысль о том, насколько же быстрее современные процессоры по сравнению с ранними экземплярами. Да, можно размышлять об этом эмпирически - зная тактовую частоту и особенности микроархитектуры (как устроен конвейер, сколько есть ALU, и т.д.), можно прикинуть производительность Intel 4004. Пусть и не в FLOPS'ах, ибо нативная поддержка чисел с плавающей запятой появилась позже. Но это будет весьма грубая прикидка, так как у этого процессора есть несколько интересных черт: разрядность только 4 бита (а не 64, как у большинства современных машин), очень скудный набор инструкций (нет даже AND'a и XOR'a!) и ограничения периферии (в частности памяти не так уж и много).
Поэтому я решил исследовать вопрос на практике. В качестве бенчмарка выбор пал на вычисления числа π. В конце-то концов, даже ENIAC в дремучем 1949 году справился с этой задачей! [2]
Ограничения железа
Обычно у нас есть задача и, исходя из неё, мы выбираем платформу. Но в моём случае ситуация обратная - нужно подобрать алгоритм, который может быть исполнен с учётом ограничений целевого процессора. Ок, какие же это ограничения?
Сам процессор очень прост, и в наборе инструкций присутствуют только несколько базовых операций ALU (сложение/вычитание 4-битных слов), оператор отрицания, циклический сдвиг влево/вправо. И на этом всё... Нет ни умножения, ни деления, ни даже других логических инструкций.
Счетчик команд 12-битный, то есть может адресовать 2^12 байт (4 килобайта). Хотя большинство инструкций и занимают всего 1 байт, некоторые отгрызут целых 2 байта из ROM. Всё это говорит нам о том, что программа не должна быть слишком объемной. Это весьма печально, потому что нам нужно заложить фундамент, реализовав недостающие математические операции самостоятельно (увы не существует алгоритма вычисления π только на сложениях и вычитаниях).
Если говорить про ОЗУ, то каждый RAM чип из семейства MCS-4 (с ними 4004 работает из коробки) состоит из 4х регистров по 20 слов (4-битных, конечно же). Процессор может работать с 8 банками памяти (используя простой 3-к-8 демультиплексор, без него - 4 банка). К счастью, при выборе регистра процессор выдаёт на шину все 4 бита (а не те два, которых было бы достаточно для выбора одного из 4х регистров). И Intel предусмотрительно сделала 4 варианта микросхемы 4002, каждый из которых активен только если при выборе регистра на шине был выставлен соответстующий номер варианта чипа (это сделано через дополнительный пин, а-ля chip enable, подтянутый к старшему разряду и двумя физическими вариантами чипа - 4002-1 и 4002-2, которые отличаются слоем металлизации) [7]. Таким образом, максимальный размер памяти будет 8 банков * 4 чипа * 4 регистра * 20 слов * 4 бита = 10240 бит. Не очень много...
Алгоритм
Существует множество формул вычисления π, но, после изучения того, что у нас есть в распоряжении (особенно количество оперативки), я остановил свой выбор на краниковом (spigot) алгоритме за авторством Stan Wagon и Stanley Rabinowitz [1]. Он достаточно прост для реализации: целочисленное деление и нам не нужна длинная арифметика (в отличии от формул Мэчина). Расскажу немного о том, как же работает этот алгоритм (лучше же конечно почитать первоисточник, но вдруг вам недосуг?).
Используем схему Горнера (4) для вычисления ряда Лейбница для π (1), подвергнутого преобразованию Эйлера (2) и еще одной простой трансформации последовательности (3):




И что же нам даёт схема Горнера? Рассмотрим её применение к десятичным числам (1.234, к примеру):

Присмотревшись, можно заметить сходство с представлением π. Можно сказать, что мы знаем чему равно π - 2.22..2(2)! Но есть нюанс, мы знаем его значение не в десятичной системе счисления, а в смешанной системе счисления с основанием c:

Осталось только сконвертировать его в десятичную форму. Мы будем извлекать цифры по порядку, что весьма несложно для вещественных чисел - выдаём целую часть числа, умножаем дробную часть на 10, выводим целую часть результата, отбрасываем её и повторяем умножение. Следуем этим шагам пока не получим нужную точность. Это универсальный алгоритм, так что он применим и к числам в смешанной системе счисления:

Каждая цифра в системе счисления c (ai) принадлежит алфавиту { 0, 1, ..., (2i + 1) - 1 } = { 0, 1, ..., 2i }. Не совсем очевидно на первый взгляд, но набор символов (алфавит) для цифр в системе счисления p/q и q/p совпадает и равен { 0, 1, ..., max(p-1, q-1) }. [4] Поэтому после умножения на 10, нам нужно вернуть число в корректную форму (каждая цифра должна быть представлена в вышеупомянутом алфавите). Авторы алгоритма называют это форму регулярной.
Мы будем работать с числами в формате (0; a1, a2, a3,... ), где 0 отвечает за целую часть числа. В привычной нам десятичной форме данное число будет в диапазоне [0, 1). Но для конкретно этой смешанной системы счисления диапазон увеличивается до [0, 2). В оригинальной работе есть доказательство, что максимальное число с нулевой целой частью это (0; 2, 4, 6, ...) и оно равно 2 в десятичной форме.
К чему эта информация? А к тому, что получив число (a0; a1, a2, a3,...), мы не можем просто напечатать a0 в качестве очередной цифры π, потому что оставшаяся дробная часть может быть больше единицы и в таком случае добавит дополнительную 1 к десятичной цифре. К примеру, очередная цифра в десятичной форме dk = 5, а на следующем шаге мы можем получить dk+1 = 12, и поэтому нам нужно вернуться в прошлое и вывести на экран 6, а не 5!
Значит нам нужна буферизация вывода, пока мы не будем знать произойдет ли переполнение. Причём недостаточно буферезировать только одну цифру, потому что нам может встретиться каскадное переполнение и нам нужно будет вместо ...2999x... вывести ...3000y...
Реализация на языке высокого уровня
В изначальной статье авторы используют Pascal, но для меня он не так привычен, поэтому я переписал алгоритм на JavaScript, дабы иметь какой-то референс перед написанием ассемблерного кода.
Если написать в лоб, то получим что-то такое:
const N = 1000; const LEN = Math.floor((10 * N) / 3) + 1; const a = Array(LEN); let previousDigit = 2; let nineCount = 0; for (let i = 0; i < LEN; i++) { a[i] = 2; } let printed = 0; while (printed < N) { // multiply each digit by 10 for (let i = 1; i < LEN; i++) { a[i] = a[i] * 10; } // normalize representation // each digit should be in range 0..2i, so carry extra rank to higher digit let carry = 0; for (let i = LEN - 1; i > 0; i--) { const denominator = i, numerator = 2 * i + 1; const x = a[i] + carry; a[i] = x % numerator carry = Math.floor(x / numerator) * denominator; } // latest carry would be integer part of current number // and sequental digit of Pi const digitFromCarry = Math.floor(carry / 10); const nextDigit = carry % 10; // if current digit is 9, then we can't decide if we would have cascade carry if (nextDigit === 9) { nineCount++; continue; } // print previous digit, because now we knows if current digit is more than 10 const currentDigit = previousDigit + digitFromCarry; process.stdout.write(currentDigit.toString()); printed++; // if previous digit is followed by 9s, then print them // or 0s, if we have cascade carry for (let i = 0; i < nineCount; i++) { process.stdout.write((digitFromCarry === 0 ? 9 : 0).toString()); printed++; } nineCount = 0; previousDigit = nextDigit; }
Уже на этом этапе мы можем внести улучшения. Оптимизировать вывод цифр необязательно (занимает меньшую часть времени), а вот подумать над производительностью цикла нормализации можно (циклы обычно очевидная цель для оптимизаций):
Можно объединить умножение и нормализацию в одном цикле, а не делать это в два шага.
Вместо вычисления числителя на каждой итерации мы можем загнать его в качестве счетчика цикла.
В JavaScript'e нет оператора целочисленного деления, который одновременно выдаёт частное и остаток от деления, но мы можем создать такой оператор в реализации кода под Intel 4004.
Применив эти оптимизации, получим примерно такой цикл:
for (let i = LEN - 1, numerator = (2 * LEN - 1); i > 0; i--, numerator -= 2) { const x = a[i] * 10 + carry; a[i] = x % numerator carry = Math.floor(x / numerator) * i; }
Сколько же цифр мы сможем вычислить в теории?
Возможно вы заметили, что нам нужно всегда хранить число в памяти. Но памяти не так много. Доказано, что если мы хотим получить N десятичных цифр π, то нам нужно число в смешанной системе c, которое имеет как минимум (10 * N / 3) + 1 разрядов. Зная сколько у нас памяти (10240 бит), мы можем вычислить на сколько цифр её хватит:

Решив это неравенство, получаем N = 279, и разрядность в 11 бит на элемент массива.
Но я очень не хотел вводить битовую арифметику и хранить цифры не по границам 4-битных слов. Да, мы можем иметь, скажем, 14-битные цифры, но это будет больно и потребует много кода, так как в Intel 4004 нет поддержки многих битовых операций. Есть еще вариант с плавающей разрядностью - первые цифры числа в системе счисления c используют куда меньший набор символов из общего алфавита. Но это тоже звучит весьма сложно для кодинга.
Поэтому выбираем между 8-битными цифрами (сможем вычислить только 38 цифр) и 12-битными (что даст нам первые 255 цифр π). Думаю, понятно какой вариант предпочтительнее. Кроме того, мы получим свободные 40 бит под переменные.
Реализация алгоритма на ассемблере для Intel 4004
Я предполагал, что отладка кода на реальном железе будет весьма непростым занятием, поэтому для начала я написал свой эмулятор. Да, есть несколько достойных проектов. Но я привык к удобным IDE с подсветкой кода, брейкпойнтами и горячими клавишами. Кроме того, я планировать написать не такую уж и короткую программу. Разработал ассемблер (не язык, а непосредственно программа, которая преобразовывает код в байты), а затем и эмулятор, запускаемый в браузере.
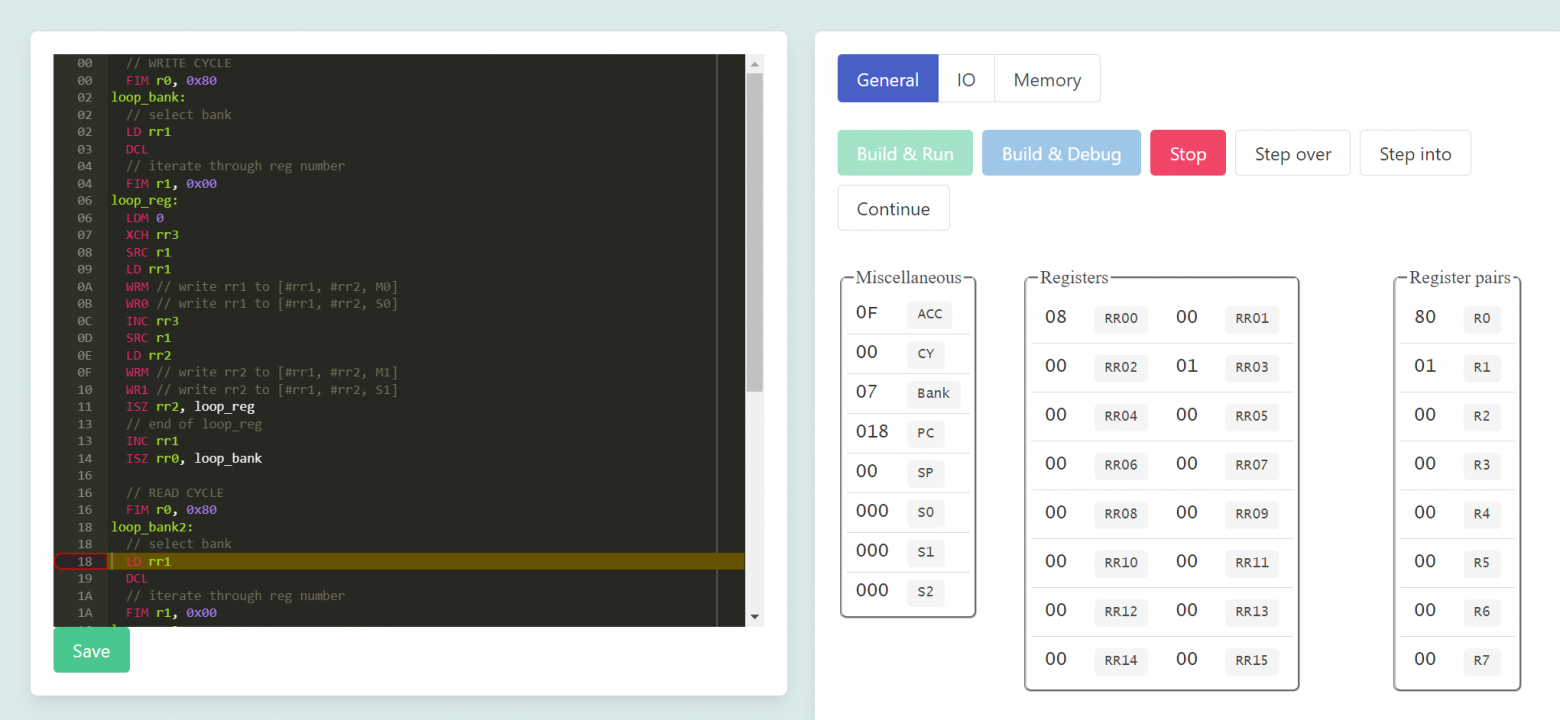
Я уже касался набора команд для intel 4004, но поговорим о нём немного подробнее. Всего существует 45 инструкций, треть из которых относится к ОЗУ и вводу/выводу. Не планирую описывать все нюансы программирования систем на основе MCS-4, ибо есть хороший мануал на этот счет (даже с релевантными примерами кода!) [8], но упомяну несколько интересных моментов, которые сказывались на процессе написания кода:
Процессор предоставляет доступ к 16 регистрам общего назначения (4-битным). Обращаться из кода можно к ним поодиночке, а можно и попарно как к квази-восьмибитному регистру (но только для ряда инструкций, вся арифметика по-прежнему 4-битная). В набор регистров также включен специальный регистр-аккумулятор, только с которым работают очень многие команды. Значение одного регистра не превышает 15, а почти все наши переменные будут больше. Поэтому нужно заранее спроектировать распределение переменных по регистрам. Даже дополнительные 40 бит в памяти не позволяют разгуляться.
Если говорим о регистрах, то нет инструкции загрузки заданного значения в отдельный регистр. Однако можно загрузить значение в регистровую пару (подпортив соседний регистр), либо обменяться содержимым с аккумулятором (для которого уже есть инструкция загрузки заданного числа).
Есть поддержка подпроцедур, но стек вызова ограничен только тремя уровнями. Это не так критично, так как у нас не такие большие программы, но пару раз я вынужден был реорганизовать код.
Среди флагов у нас присутствует флаг переноса, который устанавливается в 1 после операции сложения если результат превышает 15. Но вот что очень неинтуитивно, так это то, что флаг будет установлен в 0 при отрицательном переносе (когда вычитаем из меньшего числа большее). Приходилось постоянно корректировать его после операций вычитания. Этот флаг устанавливается только при операциях с регистром-аккумулятором. Если произойдет переполнение при инкременте обычного регистра, то флаг не поменяет своего значения.
Некоторые прыжковые инструкции работают только в 8-битном диапазоне и это не позволяет делать прыжки между страницами ПЗУ (старшие 4 бита адреса для прыжка должны быть неизменными). Так что нужно следить еще и за этим - не получится сделать условный прыжок с адреса 0x123 на адрес 0x245.
Но это еще не всё! Из-за особенностей процессора, если ты делаешь короткий прыжок с последних байт страницы ПЗУ (адреса вида
0x*FE / 0x*FF), то счетчик команд успеет инкрементироваться до того, как прыжок будет сделан и в итоге мы прыгнем на следующую страницу. К примеру если с 0x1FF хотим прыгнуть на 0x123 (что в теории норм), то в итоге попадём на 0x223. И такое мне встречалось в реальном коде, увы...Доступ к ОЗУ состоит из трех этапов - выбор банка ОЗУ, выбор чипа/регистра/слова и только затем выполнение необходимого действия: чтение, запись, доступ к порту ввода-вывода.
Уже упоминал, но хочу еще раз сакцентировать - из логических операций у нас только отрицание и циклический сдвиг.
Пример простой программы, которая пробегается по ОЗУ и записывает в неё какие-то данные:
FIM r0, 0x80 loop_bank: // select bank LD rr1 DCL // iterate through reg number FIM r1, 0x00 loop_reg: LDM 0 XCH rr3 SRC r1 LD rr1 WRM // write rr1 to [#rr1, #rr2, M0] WR0 // write rr1 to [#rr1, #rr2, S0] INC rr3 SRC r1 LD rr2 WRM // write rr2 to [#rr1, #rr2, M1] WR1 // write rr2 to [#rr1, #rr2, S1] ISZ rr2, loop_reg // end of loop_reg INC rr1 ISZ rr0, loop_bank
Конечно же, я не буду сюда постить весь ассемблерный листинг на 1500 строк кода. Если вам интересно, то можете взглянуть на него здесь. Разве что дам небольшие пояснения по блокам кода.
Для начала я реализовал необходимую арифметику над 4-битными словами - умножение, деление, сдвиговые операции. Затем мне нужно была многоразрядное деление (до 5 разрядов по 4 бита каждый). Кстати, этот функционал занимает весьма приличную часть всего кода. Реализация основана на широкоизвестных алгоритмах [5][6], поэтому не буду углубляться в детали.
Изначально я соптимизировал код, храня числитель и знаменатель в отдельных переменных цикла, но увы после подсчетов, я выяснил, что регистров/памяти не хватает, поэтому пришлось пересчитывать знаменатель на каждой итерации.
Как ни странно, еще один большой кусок кода отвечает за операции с памятью. В частности, нам нужно конвертировать индекс элемента в массиве (разряд) в линейный адрес (делается весьма просто - address = (denominator - 1) * 3), а затем уже в физический:
bank index = address / 320 register index = (address % 320) / 20 character index = ((address % 320) % 20)
Достоен внимания еще тот момент, что у нас 2 набора инструкций для работы с ОЗУ. Первый набор взаимодействует с 16 словами ОЗУ регистра (RDM/WRM), но нужно предварительно совершать процедуру выбора этого слова, что занимает лишние байты и такты. Второй набор даёт доступ к отдельным 4 словам (RDx / WRx, где x от 0 до 3) - это позволяет единожды выбрать регистр, и работать с отдельными четырьмя "ячейками", без необходимости выбирать их отдельно.
В принципе, код достаточно линеен и понятен (если вы знакомы с ассемблером Intel 4004, конечно же).
Запускаем программу на реальном железе
Окей, у нас есть эмуляция, но я всё же хотел посмотреть реальную производительность процессора. Значит мне нужна настоящая система на процессоре Intel 4004. У меня не было цели собирать аутентичную MCS-4 систему, нужен был только процессор. Поэтому я реализовал симулятор ПЗУ (intel 4001) и ОЗУ (intel 4002) на микроконтроллере семейства stm32. Даже не самые производительные варианты укладывались в необходимые тайминги. Спасибо Frank Buß за его дизайн схемотехники. Разве что он брал PIC16 микроконтроллер. Но я использовал его схему почти без изменений:

Прошивка не представляет из себя ничего интересного - генерируется 2-фазный тактовый сигнал (использовал два встроенных таймера в режиме master-slave для генерации ШИМ сигналов), затем слушаем UART и по команде грузим образ ПЗУ в нашу память и стартуем 4004 процессор. Единственный узкий момент был в том, чтобы уместить всю логику в 1000ns окно.
Потратив некоторые время на отладку, я всё-таки добился стабильности:

Итоги
Программа успешно запустилась и выдала корректные цифры π. Я считаю, что это успех. Сколько же ушло на это процессорного времени?
3 часа, 31 минута и 13 секунд. Дополнительно stm32 считал такты и результат совпал с замерами на ПК (0x3AFAB080 = 989507712 cycles * 8 * 1600ns = 12665s)
Просто для сравнения, на моём старом Xeon'e вычисление 25 миллионов цифр числа π заняло куда меньше секунды. Я даже не буду пытаться сравнивать эти значения. В любом случае было интересно поработать с самым первым процессором от Intel (которому исполнилось уже 50 лет!).
References
[1]: Stanley Rabinowitz and Stan Wagon, "A Spigot Algorithm for the Digits of π"
[2]: Brian J. Shelburne, "The ENIAC's 1949 Determination of π"
[3]: Intel, "Intel Data Catalog 1975"
[4]: Shigeki Akiyama, Christiane Frougny, Jacques Sakarovitch, "On the Representation of Numbers in a Rational Base"
[5]: Donald E. Knuth, "Art of Computer Programming, Volume 2: Seminumerical Algorithms", 4.3. Multiple Precision Arithmetic
[6]: Henry S. Warren, "Hacker's Delight"
[7]: Intel MCS-4 Data Sheet
[8]: Intel MCS-4 Users Manual
