В разработке часто возникает необходимость работы с динамическими атрибутами для тех или иных сущностей, более того — сами сущности могут быть полностью динамическими. Думаю, что самым известным таким примером является JIRA, где администраторы могут добавлять или удалять атрибуты тикетов, после чего каждый пользователь потенциально сможет с ними работать (просматривать или изменять их значения). В то же самое время JIRA предоставляет широкие возможности для фильтрации и сортировки тикетов по динамическим атрибутам, что говорит о том, что работа с динамическими атрибутами глубоко интегрирована в хранилище данных JIRA, иначе добиться хорошей производительности при работе с большим количеством данных вряд ли бы получилось. Так, например, если есть тысячи или даже миллионы хранимых объектов (тех же тикетов в JIRA) и если бы фильтрация не была реализована в самом хранилище данных, то необходимо было бы прочитать каждый объект в память приложения, чтобы проверить, не соответствует ли он заданным условиям фильтрации. Очевидно, что такой подход не выглядит особо эффективным.
Работая над различными проектами, я несколько раз сталкивался с подобными задачами, и теперь хочу предложить достаточно эффективное, на мой взгляд, решение.
Примечание. Далее мы сосредоточимся только на базах данных SQL. Скорее всего, многие согласятся с утверждением, что базы данных SQL на сегодняшний день по-прежнему остаются самым популярным способом хранения данных приложений.
Прежде чем фильтровать данные, надо сначала определиться с тем, как правильно организовать данные в таблицах SQL. В простейшем сценарии структура таблиц для динамических атрибутов может выглядеть следующим образом:
- Product — Список объектов, которые будут расширены динамическими атрибутами;
- Attribute — Cписок динамических атрибутов (имя атрибута и его тип);
- ProductAttribute — значения динамических атрибутов для объектов.
Давайте рассмотрим пример, когда у нас есть список моделей мобильных телефонов, и мы хотим динамически добавлять какие-нибудь дополнительные атрибуты, такие как «производитель», «внутренняя память (Гб)», «протоколы сотовой связи», «дата выпуска» и т. д.
В этом случае данные могут выглядеть следующим образом:

В этой простой структуре есть один момент, который может вызвать определенные проблемы — обратите внимание, что тип столбца Value — это строка. На первый взгляд это кажется логичным, так как тип атрибута может быть разным, но при этом любой из типов всегда можно представить в виде строки. Однако с точки зрения фильтрации и сортировки — это не лучший выбор, потому что в общем случае сравнение строк не соответствует сравнению закодированных значений. Так, например, при сравнении строк '2,11' и '11,2' и сравнении чисел 2.11 и 11.2 будет получен прямо противоположный результат — строка '2,11' «больше», чем строка '11,2', но число 2,11 меньше, чем число 11,2.
Другая проблема с использованием строк заключается в том, что одни и те же данные могут быть закодированы по-разному. Думаю, многие разработчики сталкивались с проблемами, вызванными разными форматами даты: 05/29/2022, 2022–05–22, 29.05.2022 — одна и та же дата, но разные строки.
Помимо этого, значения атрибутов могут быть и более сложными структурами, такими, как например списки, и если они закодированы в виде одной строки, то такие значения становятся практически неуправляемыми на уровне базы данных.
Учитывая всё вышесказанное, рассмотрим новую структуру таблиц:

Теперь таблица значений ProductAttribute имеет по одному столбцу для каждого типа атрибута (ссылка, номер, дата), а значения-списки перемещены в отдельную таблицу ProductAttributeItem.
Используя эту структуру таблиц, мы можем попытаться выбрать некоторые объекты, соответствующие неким заданным критериям.
Фильтрация в SQL
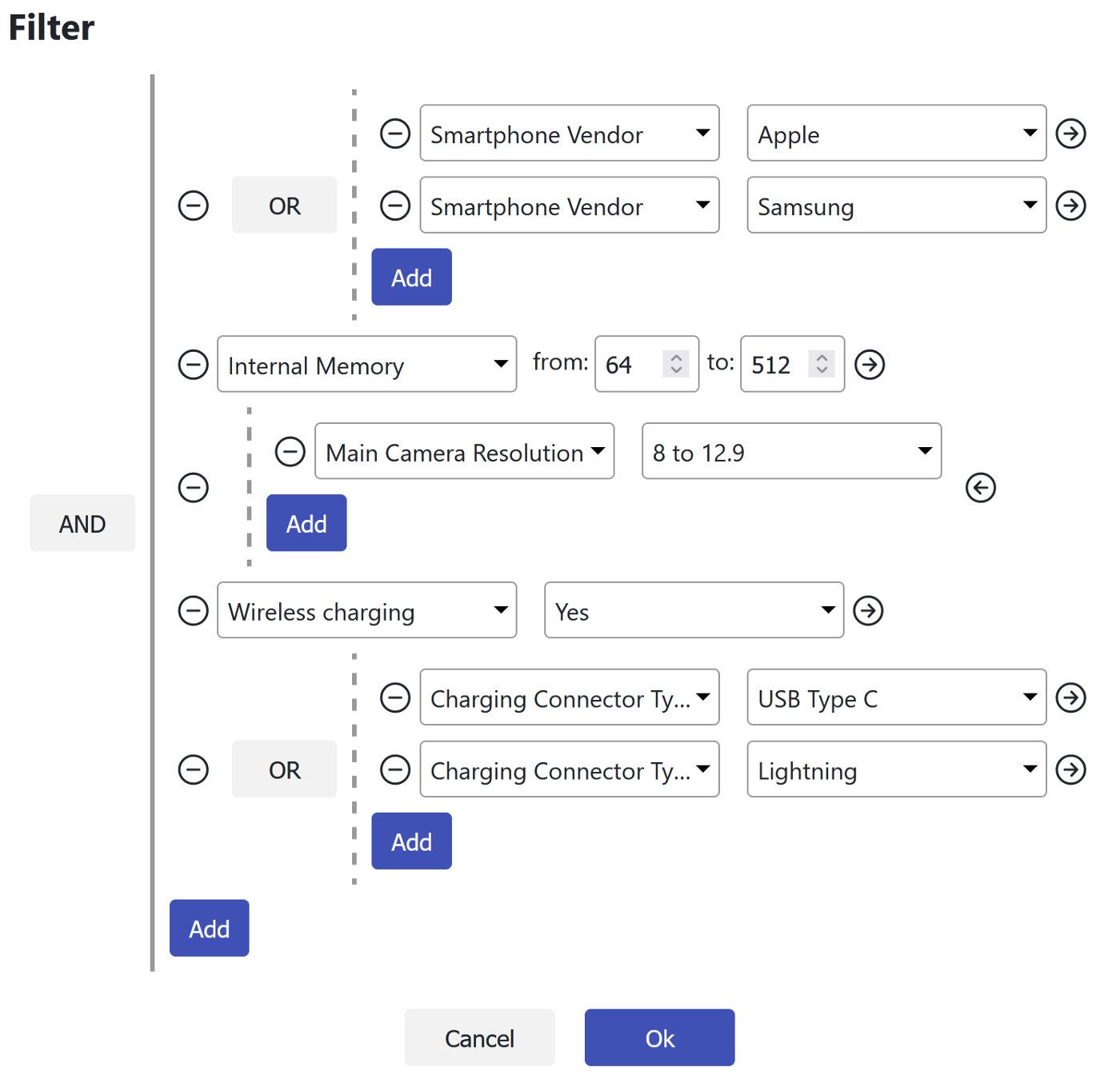
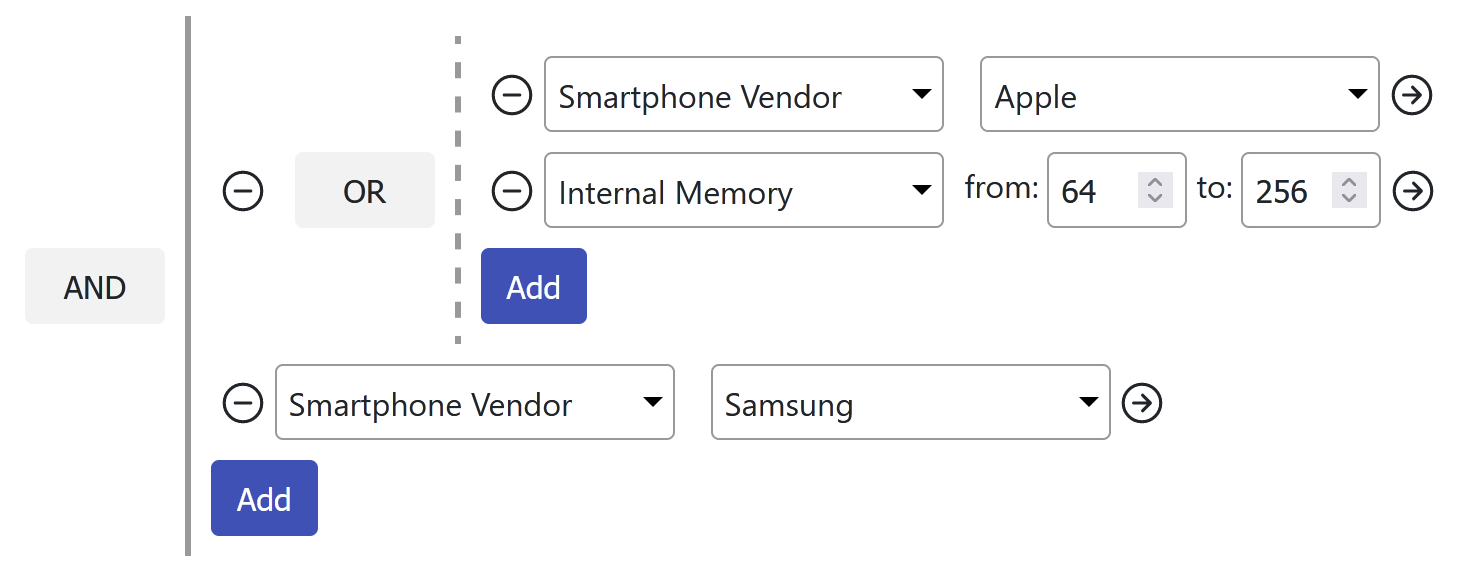
Рассмотрим пример «сложного фильтра»:
В виде SQL он может быть выражен как:
( [1]/*Vendor*/ = 1/*Apple*/ AND [2]/*Internal Memory*/ >= 64 AND [2]/*Internal Memory*/ <= 256 ) OR ([1]/*Vendor*/ = 2/*Samsung*/)
Идея состоит в том, чтобы внедрить это выражение в некий SQL-запрос таким образом, чтобы сервер баз данных выполнил фильтрацию самостоятельно. Для этого нужно сделать следующее:
-Проанализировать то какие атрибуты используются в фильтре
-Присоединить таблицу значений ProductAttribute столько раз, сколько уникальных атрибутов присутствует в фильтре.
Фильтр из примера содержит два атрибута:
-[1] Vendor — ссылка на перечисление;
-[2] Internal Memory — число.
Таким образом, окончательный запрос должен содержать под-запрос, в котором ProductAttribute соединяется два раза с правильным псевдонимами столбцов:
SELECT [ATTRIBUTES].ProductId FROM ( SELECT [P].ProductId, [AT_1].ValueItem [1], [AT_2].ValueInt [2] FROM Product [P] LEFT JOIN ProductAttribute [AT_1] ON [AT_1].AttributeId = 1/*Vendor*/ AND [AT_1].ProductId = [P].ProductId LEFT JOIN ProductAttribute [AT_2] ON [AT_2].AttributeId = 2/*Internal Memory*/ AND [AT_2].ProductId = [P].ProductId ) [ATTRIBUTES] WHERE ( [1]/*Vendor*/ = 1/*Apple*/ AND [2]/*Internal Memory*/ >= 64 AND [2]/*Internal Memory*/ <= 256 ) OR ([1]/*Vendor*/ = 2/*Samsung*/)
Как мы видим, исходное выражение фильтра (как и любое другое с такими же атрибутами) можно внедрить в созданный запрос, и фильтрация будет выполнена непосредственно в базе данных. Помимо того, что эта фильтрация будет достаточно эффективной (там же будут индексы, да?), мы также получаем возможность выделения диапазона в отсортированном наборе данных (пагинация с FETCH OFFSET), что потребовало бы наличия всех данных в памяти приложения в том случае, если бы фильтрация не производилась бы на уровне базы данных.
Построение динамического SQL
В теории это выглядит нормально, но не совсем понятно, как использовать этот подход в реальном приложении, так как сначала нужно каким-то образом решить следующие задачи:
-Преобразовать критерии фильтрации в булевское SQL выражение;
-Подготовить правильный подзапрос со всеми необходимыми соединениями таблиц.
Вряд ли используемая вами ORM достаточно гибкая, чтобы выполнить все эти манипуляции, и первая идея, которая приходит в голову, — это создавать динамические SQL-запросы в виде текста, что, конечно, возможно, но я бы рекомендовал использовать какие-нибудь SQL компоновщики, которые позволяют работать с синтаксическими деревьями— это было бы гораздо более безопасным и гибким решением.
Далее в качестве примера я буду использовать библиотеку SqExpress для платформы .Net.
Конечно, вы можете использовать и другие подобные библиотеки — принципы останутся прежними.
Итак, начнем с построения логического выражения:
Примечание: здесь фильтр "захардкожен", но ничто не мешает создать его динамически из какой-либо модели (фильтра).
var vendor = SqQueryBuilder.Column("1"); var internalMemory = SqQueryBuilder.Column("2"); ExprBoolean filter = vendor == 1; filter = filter & internalMemory >= 64 & internalMemory <= 256; filter = filter | vendor == 2;
Небольшая проверка, что это то, что мы хотим:
Console.WriteLine(TSqlExporter.Default.ToSql(filter)); //[1]=1 AND [2]>=64 AND [2]<=256 OR [1]=2
Используя обход синтаксического дерева, мы можем найти все уникальные идентификаторы атрибутов в этом выражении:
List<int> filterAttributes = filter .SyntaxTree() .DescendantsAndSelf() .OfType<ExprColumn>() .Select(c => int.Parse(c.ColumnName.Name)) .Distinct() .ToList(); foreach(var filterAttribute in filterAttributes) { Console.WriteLine(filterAttribute); } //1 //2
Теперь когда мы знаем все идентификаторы динамических атрибутов в фильтре, мы можем получить их типы:
var tblAttribute = AllTables.GetAttribute(); Dictionary<int, AttributeType> typesDict = await SqQueryBuilder .Select(tblAttribute.AttributeId, tblAttribute.AttributeType) .From(tblAttribute) .Where(tblAttribute.AttributeId.In(filterAttributes)) .QueryDictionary( database, r => tblAttribute.AttributeId.Read(r), r => (AttributeType)tblAttribute.AttributeType.Read(r));
Используя информацию об атрибутах, мы можем построить подзапрос, в котором таблица ProductAttribute будет присоединена один раз для каждого уникального атрибута:
var tblProduct = AllTables.GetProduct(); var subQueryColumns = new List<IExprSelecting> { tblProduct.ProductId }; var subQuerySelect = SqQueryBuilder .Select(subQueryColumns) .From(tblProduct); foreach (var filterAttributeId in filterAttributes) { var tblProductAttribute = AllTables.GetProductAttribute(); subQuerySelect = subQuerySelect.LeftJoin( tblProductAttribute, on: tblProductAttribute.ProductId == tblProduct.ProductId & tblProductAttribute.AttributeId == filterAttributeId); switch (typesDict[filterAttributeId]) { case AttributeType.Integer: subQueryColumns.Add(tblProductAttribute.ValueInt.As(filterAttributeId.ToString())); break; case AttributeType.Set: subQueryColumns.Add(tblProductAttribute.ValueItem.As(filterAttributeId.ToString())); break; case AttributeType.Date: subQueryColumns.Add(tblProductAttribute.ValueDate.As(filterAttributeId.ToString())); break; } }
Собирая всё вместе:
var subQuery = subQuerySelect.As(SqQueryBuilder.TableAlias("ATTRIBUTES")); var query = SqQueryBuilder .Select(tblProduct.ProductName) .From(tblProduct) .InnerJoin( subQuery, on: tblProduct.ProductId == tblProduct.ProductId.WithSource(subQuery.Alias)) .Where(filter) .Done(); await query.Query(database, r => Console.WriteLine(tblProduct.ProductName.Read(r))); //iPhone 11 128 //Galaxy Note 20 Ultra
Это всё прекрасно работает с простыми атрибутами, но если тип атрибута это «Set» (значение представляет собой набор элементов), то потребуется чуть больше усилий. Например, мы хотим фильтровать по сотовым протоколам:
var cProtocols = SqQueryBuilder.Column("3"); filter = cProtocols.In(3, 5); Console.WriteLine(TSqlExporter.Default.ToSql(filter)); //[3] IN(3,5)
Для выполнения этой фильтрации в базе данных, этот фильтра должен быть изменен следующим образом: оператор IN должен быть заменен подзапросом EXISTS для того, чтобы использовалась таблица ProductAttributeItem. Это можно сделать, изменив синтаксическое дерево исходного фильтра:
filter = (ExprBoolean)filter.SyntaxTree().Modify<ExprInValues>(exprInValues => { var column = (ExprColumn)exprInValues.TestExpression; var columId = int.Parse(column.ColumnName.Name); var t = AllTables.GetProductAttributeItem(); return SqQueryBuilder.Exists( SqQueryBuilder .SelectOne() .From(t) .Where( t.AttributeId == columId & t.ProductId == tblProduct.ProductId & t.AttributeItemId.In(exprInValues.Items))); })!; Console.WriteLine(TSqlExporter.Default.ToSql(filter));
EXISTS ( SELECT 1 FROM [dbo].[ProductAttributeItem] [A0] WHERE [A0].[AttributeId]=3 AND [A0].[ProductId]=[A1].[ProductId] AND [A0].[AttributeItemId] IN(3,5) )
После модификации фильтр можно использовать в запросе:
await SqQueryBuilder .Select(tblProduct.ProductName) .From(tblProduct) .Where(filter) .Query(database, r => Console.WriteLine(tblProduct.ProductName.Read(r)));
...
Итого, используя описанные выше подходы, можно не только создавать приложения с динамически расширяющимися сущностями, но и предоставлять богатый функционал для фильтрации этих сущностей по различным критериям.
Ссылки:
- SqGoods — это демо веб-приложение, демонстрирующее динамическую фильтрацию динамических сущностей;
- Исходный код для этой статьи
- SqExpress — библиотека для создания динамического SQL, которая была использована в примерах в этой статье.
