От теории к практике, основные соображения и GCP сервисы
Эта статья не будет технически глубокой. Мы поговорим о Data Lake и Data Warehouse, важных принципах, которые следует учитывать, и о том, какие сервисы GCP можно использовать для создания такой системы. Мы коснёмся каждого из GCP сервисов и поймём почему они будут полезны при создании Data Lake и Warehouse.
Прежде чем перейти к своей версии Data Lake и Data Warehouse, я хотел бы привести несколько известных архитектур, с которыми вы, возможно, уже знакомы, если интересуетесь этой темой. Архитектура, которую я бы предложил, будет более общей, чем эти: Cloud Storage as a data lake и Architecture: Marketing Data Warehouse.
В своей более общей версии Data Lake и Data Warehouse я расскажу о таких сервисах GCP, как Data Transfer Service, Dataproc, Cloud Storage, Cloud Scheduler, BigQuery, и Cloud SQL.
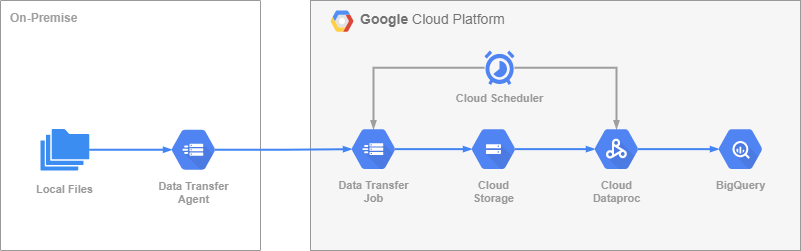
Мы соберем «пазл» и посмотрим, какую пользу и как можно использовать перечисленные сервисы.
Основные соображения
Есть много важных моментов, о которых следует подумать во время проектирования собственного Data Lake и Warehouse. Тогда, когда функции Data Warehouse почти полностью покрываются BigQuery, функции Data Lake требуют более тщательного анализа и подхода к реализации. Все эти «модные слова», такие как отказоустойчивость, надежность, масштабируемость, в равной степени применяются и к Data Lake. Очень важно, чтобы данные были хорошего качества, когда они попадают в хранилище, чтобы обработка данных была быстрой, а интеграция новых источников данных было простым процессом, и многое другое. Все эти пункты можно разделить на три основные группы вопросов, которые касаются определенных областей системы. Я хочу упомянуть о них лишь вкратце, поскольку их обсуждение не является целью данной статьи.
Передача данных. В эту группу входят вопросы о самой передаче данных и их хранении. Необработанные данные должны передаваться из вашей основной системы в Data Lake без риска потери. Они должны храниться «как есть». Data Lake не должен давать сбоев при неожиданном изменении входящих данных. В случае неожиданного увеличения объема входящих данных система все равно должна быть в состоянии быстро его обработать. Новые интеграции источников данных должны быть делом нескольких часов (даже минут), а не дней. В случае простоев и сбоев ничего не должно теряться, и система должна восстанавливаться автоматически.
Организация данных. В этой группе вопросов вам нужно ответить, как ваши данные будут храниться и запрашиваться в Data Lake, и у этого есть свои проблемы. Структура входящих данных подвержена изменениям со временем. Может отсутствовать корреляция между временем поступления данных в Data Lake и бизнес-временем, связанным с объектом данных. Одни и те же данные могут поступать от нескольких поставщиков. Вам нужно будет понять как организовать партиции необработанных данных, чтобы поледующие выорки осуществлялись быстро и экономично. Вам также может потребоваться рассмотреть права доступа к данным и безопасность для разных ролей и пользователей, хотя на этом уровне это можно пропустить.
Обработка данных. Последняя группа связана с методами обработки данных. Прежде всего, вы хотите, чтобы обработка данных была достаточно простой и независимой от инструментов, чтобы ваша организация могла использовать лучшие инструменты для достижения целей. Написание новой логики обработки должно быть таким же простым, как написание нового SQL кода, когда вы знаете структуру данных. Логика обработки должна в равной степени иметь возможность обрабатывать как малые, так и большие объемы данных. Создание новых пайплайнов обработки данных должно быть быстрым, а развертывание — простым. Должно быть одинаково просто создать обработку в реальном времени или пакетную обработку, обработку по запросу или те, которые постоянно выполняются.
Ответы на вопросы в этих группах сильно зависят от потребностей вашего бизнеса и предпосылок. Во время разработки нашего Data Lake и Warehouse с моей командой мы обсудили многие моменты. Ниже хотелось бы остановиться на нескольких конкретных моментах, на которые мы потратили большую часть времени, выбирая правильный подход.
Выбор между Cloud Storage и BigQuery для Data Lake
Один из первых вопросов касается использования BigQuery или Cloud Storage для Data Lake. Если ваши данные имеют очень стабильную структуру и их схема меняется со временем очень медленно, и вы можете считать их постоянными в течение длительного периода, то BigQuery может стать для вас хорошим выбором. У вас могут быть внешние таблицы, которые будут читать файлы из Cloud Storage, и вы можете работать с такими таблицами почти так же, как и с обычными. Вы можете автоматизировать импорт таких данных в таблицы продуктов данных в хранилище данных. Те, очень редкие случаи, когда ваши данные меняют свою структуру, вы покрываете их наполовину вытоматическими процессами и не имеете проблем с поддержкой разных схем одновременно. Вы можете построить обработку данных с помощью SQL и Scheduled Queries в BigQuery и сохранить необходимые навыки, очень удобные для DBA. Для более глубокого погружения имеет смысл почитать: What is a data lake?
В тех случаях, когда структура данных меняется чаще, усилия по поддержке такого data Lake, использующего BigQuery, могут расти в геометрической прогрессии и становиться слишком высокими и слишком сложными, чтобы оставаться рентабельными для бизнеса. В таком случае Cloud Storage и процессы вокруг него могут быть лучшим решением. И это то, что мы выбрали для себя, потому что в нашем случае схема данных меняется от записи к записи, и у нас есть несколько конвейеров данных и поставщиков.
Выбор формата сырых данных: Parquet, Avro или JSON
Выбор между форматами данных имеет ту же основу, что и выбор между BigQuery и Cloud Storage для Data Lake. Форматы файлов Parquet и Avro требуют, чтобы в файлы была встроена определенная структура для поддержки функций, которые они предлагают. Например, Parquet чрезвычайно эффективен для запросов, потому что это столбцовое хранилище данных. Он также предлагает лучшее сжатие. Но он более требователен к ресурсам для операций записи, потому что требует больше процессора и оперативной памяти для работы. Avro выглядит лучшим выбором для случаев, когда операции записи должны быть быстрыми. Вы можете добавлять построчно к файлам Avro, но не можете делать это с файлами Parquet. Это делает Avro более предпочтительным в сценариях, где вы обрабатываете данные в потоковом режиме. Я нашел очень хорошее объяснение деталей этих форматов: Big Data File Formats и Storage size and generation time in popular file formats.
Таким образом, если ваши схемы развиваются медленно и вы можете гарантировать, что все записи будут иметь одинаковую структуру в одном файле, то Avro или Parquet — очень хороший выбор. Но когда структура часто меняется и вам нужно хранить в одном файле записи с разными схемами, это становится сложной задачей.
Parquet и Avro требуют, чтобы схема была встроена в файл. Если схема ваших записей данных меняется почти для каждой записи, вам нужно будет корректировать каждую запись, чтобы подогнать их на какую-то «целевую» схему, или создать множество файлов с немного различающейся схемой. Avro заявляет, что поддерживает эволюцию схемы как для добавления, так и для удаления столбцов, но наши исследования показывают, что для этого по-прежнему требуется, чтобы все записи имели одинаковую структуру в одном и том же файле. Решить можно, но усложняет систему и добавляет дополнительные точки отказа и накладные расходы на поддержку такой системы.
Напротив, формат JSON не имеет вышеупомянутых проблем и хорошо поддерживается многими платформами обработки. Единственная проблема, о которой вы можете подумать, — это размер текстовых файлов с данными JSON. Spark позволяет читать файлы с разными схемами. Когда вы указываете какую-то ожидаемую схему, Spark правильно загружает её, даже если записи имеют существенно разные схемы. Также вы можете хранить записи с разными схемами в одних и тех же файлах. В конце концов, после нескольких экспериментов, мы остановились на JSON.
Выбор правильной организации данных для Data Lake
Основная цель организации данных — определить единую структуру в Data Lake и помочь выполнять эффективные запросы к данным. То, как вы храните данные, как вы их организуете, партиционируете, все это влияет на производительность запросов. Очень хорошее руководство об этом тут: How to Organize your Data Lake. Основная идея заключается в том, что дата приема должна быть частью организации данных на 1-м уровне вашего Data Lake.
Второй уровень Data Lake может быть более адаптирован к потребностям бизнеса. Это даст возможность перестроить 2-й уровень из 1-го, если вы решите реорганизовать подготовленные данные.
Важно, чтобы 1-й уровень Data Lake был изолирован от структуры данных и не связывал его с вашим бизнесом. Это значительно упростит интеграцию новых поставщиков и дальнейшие манипуляции с данными внутри Data Lake.
GCP сервисы для Data Lake и Warehouse
Теперь я хотел бы поговорить о строительных блоках возможного Data Lake и Warehouse. Все компоненты являются сервисами GCP и полностью покрывают потребности конкретных областей: передача данных, обработка и запросы. Мы не будем настраивать какой-либо из сервисов, но я расскажу об их основных преимуществах и о том, почему они подходят для Data Lake и Warehouse. Схему системы, о которой я говорю, вы можете найти в начале статьи.
Data Transfer Service
Для приема данных в Data Lake вам необходимо установить надежную передачу данных из исходной системы. Data Transfer Service помогает передавать данные из AWS, Azure, Cloud Storage или on-premise в другое on-premise или Cloud Storage хранилище. Служба передает файлы, проверяя передачу и может возобновить её, если она была прервана. Агенты для on-premise можно масштабировать для повышения производительности передачи данных.
В нашем случае мы переносим данные из on-premise в Cloud Storage. Для настройки необходимо создать пул агентов в Data Transfer. Все агенты общаются друг с другом через службу Pub/Sub, чтобы координировать, какие файлы были отправлены и где возобновить работу в случае сбоя инфраструктуры. Например, если агент умирает или связь прерывается, другие агенты, которые еще могут работать, продолжат передачу. В конечном итоге все агенты работают совместно, что делает передачу данных отказоустойчивой и не пропускает ни одного файла. Поробнее тут: Manage transfer agents.
Dataproc
Dataproc — это управляемая Apache Spark и Apache Hadoop кластеры. Это ядро наших ETL процессов для сырых данных. Можно настроить автоматическое масштабирование, которое по умолчанию использует вытесняемые вторичные рабочие узлы и основано на метриках YARN. Можно создать минимальный кластер из 1 главного узла и двух рабочих узлов и установить в автомасштабировании максимальное количество вторичных рабочих узлов какое-то высокое значение. Подробнее тут: Autoscaling clusters. Отличие основных и второстепенных рабочих узлов в том, что последние не могут хранить на них данные. Также возможно использовать Dataproc в бессерверном режиме, отправляя пакетные задания. Мы постоянно запускаем несколько ETL каждые три минуты. Из-за этого наш кластер Dataproc работает постоянно.
Wildcard в файловом пути
Очень интересной особенностью Spark является то, как он работает с шаблонами путей для загрузки файлов. Например, это то, что можно указать в качестве источника для spark.read.json. Предположим, у вас есть следующие структуры папок в Data Lake: gs://object/year/month/day/hour/minute/instance.json. Почти любой сервис поддерживает указание звездочки в конце строки, например: gs://object/year/month/day/hour/* — если вы хотите загрузить данные за определенный час в определенный день. Но не все поддержат это: gs://object/year/month/*/*/minute/* — если вы хотите загрузить данные только за конкретную минуту за весь месяц. И ваша организация папок может быть немного сложнее, чем эта. Особенно на 2-м уровне Data Lake, где вы будете работать с подготовленными файлами данных, где организация хранения может включать бизнес-информацию. Например, вы можете захотеть загрузить данные только для определенного клиента за весь год.
SparkSQL
SparkSQL позволяет использовать хорошо известную DSL для работы с данными. Существует множество встроенных функций, которые очень ускоряют процесс обучения, особенно для DBA. Тут подробнее: Spark SQL, Built-in Functions.
Все ваши операции могут быть выполнены внутри оператора spark.sql:
spark.sql(""" CREATE OR REPLACE TEMPORARY VIEW my_view AS SELECT CAST(field AS FLOAT) AS mapped_field FROM another_view """)
Cloud Scheduler
Служба Cloud Scheduler позволяет активировать определенный URL-адрес или отправить сообщение в топик Pub/Sub по определенному расписанию. Мы используем его для запуска Data Transfer заданий и рабочих процессов Dataproc через URL-адрес. Планировщик использует GCP REST API для сервисов для запуска операций. Задания в Data Transfer не поддерживают расписания чаще одного раза в час. А задания в Dataproc вообще не имеют расписаний. Можно использовать Cloud Composer или Cloud Functions для запуска операций с Dataproc или Transfer Service, но это усложнит систему, добавляя больше компонентов и больше мест для отказа.
Cloud SQL
Этот компонент отсутствует в схеме нашего Data Lake и Warehouse, но мы его используем. Основная его цель — отслеживание операций и обеспечение обработки всех файлов, когда они поступают в Data Lake. Существуют Cloud Functions, которые срабатывают, когда новый файл поступает в Cloud Storage, и добавляют файлы в базу данных метаданных в Cloud SQL. Для преодоления временных ошибок для функций включена повторная попытка. При включенной повторной попытке функция будет пытаться добавить файл в течение следующих 7 дней и в конечном итоге гарантирует, что каждый файл будет добавлен в базу данных, независимо от временных ошибок. Мы используем PostgreSQL.
И последнее, но не менее важное
Остальные сервисы GCP не нуждаются в специальном рассказе, т.к. хорошо известны. Мы используем Cloud Storage для нашего Data Lake и BigQuery для Data Warehouse.
При организации Data Lake в Cloud Storage стоит настроить жизненный цикл для объектов данных. В одном и том же бакете могут быть объекты разных классов. Правила жизненного цикла могут помочь изменить класс объектов в зависимости от их возраста с Standard на Nearline и так далее. Даже если стоимость хранения данных невелика, когда вы имеете дело с огромным объемом данных и операций чтения, это будет генерировать заметную цену. Управление классами объектов несколько сократит расходы.
В BigQuery вы можете захотеть иметь несколько разделов для одного и того же продукта данных. Например, одна и та же история заказов может иметь разделение по клиентам и по местоположению. Таблицы BigQuery не поддерживают несколько партиций. Мы преодолеваем это, имея несколько таблиц с одинаковыми данными, но с разными разделами. Группа таблиц, принадлежащих одному и тому же продукту данных, генерируется одним и тем же ETL, поэтому поддерживать несколько таблиц несложно.
Послесловие
Проектирование Data Lake и Data Warehouse — интересный процесс со многих точек зрения: техническая архитектура и реализация, сотрудничество с людьми из разных сфер бизнеса и изучение расширенного использования систем, которые ранее использовались как «черный ящик». В дальнейших статьях я, возможно, подробно опишу использование службы Data Transfer, запуск Dataproc джобов через REST API и другие, если найду время между этими задачами.
