 Регулярные выражения — это арифметика для алгоритмов. Они доступны во многих языках программирования, редакторах и настройках приложений. Как и сложение с умножением они просты в использовании.
Регулярные выражения — это арифметика для алгоритмов. Они доступны во многих языках программирования, редакторах и настройках приложений. Как и сложение с умножением они просты в использовании. Но для правильного и эффективного использования regexp-ов нужно понимание того, как они работают. Я постараюсь описать принцип работы регулярных выражений, покажу в каких случаях бывают проблемы и как их решать.
В продолжение общих советов.
Не хочу писать банальное описание метасимволов или какой-то справочник. Я хочу показать те грабли, которые мне памятны. Наметить путь по ним к самовыражению через регулярные структуры. И попробовать передать некий способ мышления, естественным образом порождающий эффективные регэкспы.
Я повторюсь, но научиться можно только на собственном опыте. Поэтому, если Вы не написали хотя бы десяток, лучше сотню регэкспов, думаю что стоит пока просто почитать документацию или книжки и экспериментировать.
Для отличия и удобства я несколько раскрасил регулярные выражения, встречающиеся в тексте. Синим — символы, зеленым — квантификаторы, серым — скобки и прочие служебные символы, каштановым — метасимволы, красным — точку ( что-бы не потерялась ) и ограничивающие регулярное выражение слэши.
Немного теории
Не буду формалистом и попробую описать теоретическую основу простыми словами. Желающие могут найти точные формулировки в wiki.
Регулярные выражения, помимо алфавита, имеют три свойства:
сцепление, когда два выражения a и b могут, сцепившись, образовать выражение ab
Другими словами, сначала выполняется выражение а, потом, на оставшейся строке, выражение b. Можно сказать что между ними как условиями, логическое И.
В применении это дает нам очень простой и основной метод: делим строку для поиска на последовательные части и для каждой строим свое выражение, а потом «сцепляем» — просто пишем их подряд.
чередование, когда два выражения a и b могут, с помощью оператора | образовывать выражение a|b
Разница со сцеплением в том что между условиями a и b стоит логические ИЛИ и для проверки используется одна и та-же строка.
В применении это позволяет нам легко добавлять простые ветвления в готовое выражение.
замыкание, когда для выражения a* проверяются все варианты (пусто),a,aa,aaa,… и так далее
Другими словами, мы рекурсивно пытаемся применить выражение а, пока оно применяется. В реальности парсер так и делает и это порождает проблемы с производительностью, но об этом ниже, когда, собственно, будем рассматривать работу квантификаторов.
Отлично! Но легко сделать выражение, которое совпадет, с нужным нам шаблоном. Труднее его модифицировать так, что бы он не совпал с тем что нам не нужно.
В этом месте менторское описание должно закончиться словами: Эффективность к тебе со временем придет, юный падаван ...
Ничего подобного !
Говорят что регулярные выражения появились как воплощение работы нервной системы. Не знаю насколько это правда, но достаточно легко научиться думать регулярными выражениями. Ключ к этому — иерархия. Представьте себе не просто варианты строк, которые надо найти, а структуру, состоящую из более мелких элементов. И тогда регулярка — просто описание этой структуры.
Сначала надо поговорить о символах. Символ — это некая минимальная составляющая нашей структуры, но надо различать голый текст, состоящий из литеральных символов и, например, строку в каком-нибудь языке программирования: пусть строка ограничивается кавычками и для указания кавычек внутри строки используется экранирование ( escape ) с помощью специального символа или повторением. Также, обычно, есть возможность указывать непечатаемые символы — перевод строки или табуляция. Все это расширяет литеральные символы до символа строки. И если надо разобрать строку, в первую очередь надо подняться на эту ступеньку — надо описать символы нашего алфавита.
Пусть у нас экранирующий символ — "\". Тогда символы строки это чередование обычных символов "." и экранированных "\.". Тут надо сказать что в чередовании выражения не равноправны, а имеют приоритет в порядке следования. То есть, если мы напишем .|\., то точка, как любой символ будет находится всегда, поэтому поставим ее последней: \.|.. Замкнув все это с помощью квантификатора * и сцепив с кавычкой в начале и в конце мы получим выражение для описания строки. Но тут есть еще один подводный камень — точка в подвыражении символа. Хотя, учитывая приоритеты, точка стоит последней, парсер каждый раз, видя варианты, ставить так называемые точки возврата. К которым может вернуться, если последующее выражение не выполнится. В каком-то тексте кавычки могут быть непарными и, не найдя последнюю, парсер будет откручивать по точкам возврата выражение назад. Если же у нас встретится экранированная кавычка, то парсер ее разложит на два символа и довольный этим неправильным результатом продолжит работу. Из этого можно сделать простой вывод, верный для всех регулярок, — неопределенность надо устранять. В нашем случае это просто — вместо точки поставим символьный класс [^\"], убрав все неоднозначности.
Не забудьте что в строке которую вы отдаете компилятору или интерпретатору, некоторые символы также надо экранировать, поэтому в тексте программы это будет выглядеть так
/"(\\.|[^\\"])*"/Составляем выражение
Поняв и описав символы, можно подниматься по иерархии выше, используя сцепление или замыкание и, если надо варианты, чередование.
Например, для описания URL, мы должны сначала разбить его на части: протокол, иногда пользователь и пароль, имя сервера, путь к файлу и так далее. После чего нужно разделить части на элементарные куски, например имя сервера — это слова, разделенные точкой, при этом эти слова имеют свои разрешенные символы и самым правым должен быть tld. Для каждой элементарной части нужно аккуратно прописать свой алфавит символов и сцеплять их в выражение для структуры следующего уровня.
Например имя состоит из [-a-z0-9]+, разделенных точкой [-a-z0-9]+\.[a-z]{2,4} ( в более строгом случае можно в правой части описать разрешенные tld: com|net|org|ru|info ), при этом в левой части могут быть несколько уровней имен через точку ([-a-z0-9]+\.)+[a-z]{2,4}
Протокол может быть https?:// или ftp://, после которого могут идти имя \w+ и пароль .+?
вместе
/(https?:\/\/|ftp:\/\/(\w+(:.+?)?@)?)([-a-z0-9]+\.)+[a-z]{2,4}/в общем легко описывать формальные структуры, поскольку всю работу уже сделали до нас, четко указав поля, разделители и предусмотрев вариативность. Главное не ошибиться нужным символом :)
Хочу повторить заезжую истину — преждевременная оптимизация вредна. Не ленитесь и повторите блок чередованием, если нужен несколько другой вариант. Опциональные или повторяющиеся части должны иметь «якоря» — литеральные символы в начале или в конце. Если что-то добавляете — не ленитесь — разберите структуру снова, добавьте нужное и соберите обратно. Непонятная мешанина внутри выражения — верный путь к ошибке. Проверьте как на покрытие нужных так и на игнорирование ненужных вариантов. И только потом оптимизируйте. А лучше не надо — хорошо структурирование выражение и работает быстро, хотя иногда выглядит страшно и на первый взгляд запутанно.
Жадные (greedy) квантификаторы
В современных регулярных выражениях есть несколько разновидностей замыканий. Stephen Cole Kleene, который ввел это понятие, описал два таких: * и +. Как было описано выше, поведение их «жадное» — они пытаются покрыть все что можно — до конца строки. Но дальше в нашем выражении идет следующий оператор или символ, а мы уже в конце строки. Тут парсер откручивает наш квантификатор обратно по точкам возврата, пока не выполнится условие последующего подвыражения.
Очевидно что подобное поведение легко порождает проблемы с производительностью. Вот время выполнения для нескольких вариантов:
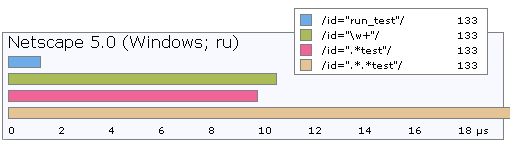
Последний случай с двумя звёздочками на самом деле отрабатывает на порядок медленнее. Это связано с особенностью работы парсера. Как было сказано, выражение «любой символ много раз» выполняется дословно и фактически парсер сначала покрывает этим выражением всю строку, сохраняя на каждом символе точку возврата. Увидев что наше выражение не закончено, парсер возвращается обратно, пока не найдет совпадение. Наличие двух звездочек увеличивает количество точек возврата на порядок, трех — еще на порядок. Легко увидеть что такой путь может «простое выражение» сделать ощутимо медленным.
но есть несколько способов улучшить эффективность:
-
интервал со стоп-символом
Например, если мы ищем теги от '<' до '>', то можно указать интервал вместо произвольного символа:
Парсер остановится, увидев символ вне диапазона и сразу же сработает последующий литеральный символ '>'./<[^>]+>/
использовать интервал повторений {min,max}
Хорошо работает, если нам известно сколько должно быть символов, например при первичной проверке uid или md5 сигнатур.
Нежадные (non-greedy) или ленивые (lazy) квантификаторы
В свое время Perl ввёл это понятие. Такой квантификатор действует наоборот — покрывает минимальный набор символов и расширяет его, если последующие сцепленные выражения не выполняются.
С точки зрения производительности очень хорошо работает для вложенных необязательных выражений, но также как и жадный квантификатор может вызвать существенное замедление, поскольку если в хорошем случае ( когда наше выражение выполняется ) все более-менее быстро, то в плохом случае парсер пытается увеличить покрытие для нежадного квантификатора, пока не дойдет до очевидного конца. Что-бы избежать этого, желательно максимально сузить покрываемые символы интервалом и сразу после него поставить простое выражение — фиксированные символы, например.
Как я уже сказал, выражения с ленивыми квантификаторами покрывают минимально возможную подстроку. Это позволяет просто избежать проблем с излишним покрытием, например
/\(.+\)//\(.+?\)/Почему не стоп-символ? Потому что не всегда его можно применить. Следующий символ может сложным или быть частью подвыражения с перечислением или вообще нельзя четко описать границу. Также ленивый квантификатор эффективен, если мы знаем что будет немного символов. Очень рекомендую ставить ленивые + и * после точки, которая соответствует произвольному символу, иначе парсер прогуляется до конца строки. Но помните что парсеру надо указать где остановиться.
Сравним скорость:
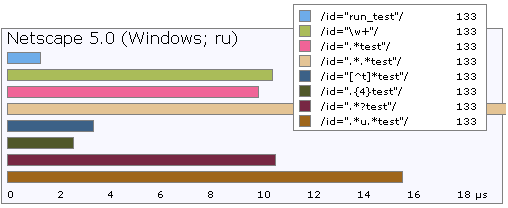
У ленивых «звездочек» и «плюсов» есть еще один недостаток — они могут и очень часто покрывают слишком мало символов, если границу не обозначить последующим подвыражением. Например, если вы разбираете слова так:
\w+? то можете обнаружить что без последующего литерального символа ( в конце большого выражения ), это комбинация покроет только одну букву и в данном случае эффективнее «жадный» вариант. Также жадные эффективнее если четко известно что следующим будет другой символ \w+ так можно описать слово или параметр, ленивый тут просто менее эффективный. Кроме ленивых и жадных есть еще
супер жадные или ревнивые квантификаторы
Их существенное отличие в том что они не откатываются обратно. Это свойство можно использовать, если есть неоднозначность. Правда, повторюсь, неоднозначность — враг эффективного регулярного выражения. Я лично не использовал их, хотя имею мнение что в хорошее выражение вместо жадного можно спокойно поставить ревнивый. Хороший, хоть и не очень жизненный пример применения ревнивого квантификатора подробно описан тут.
В заключение
покажу несколько плохих случаев из кода:
(\w*)* — внешняя жадная звездочка работать просто не будет.
Самое замечательное что некоторые парсеры просто проигнорируют такое выражение — сработает защита на зацикливание.
([^>]+)* — почти тоже самое.
По смыслу это внутренности тега после его имени и они не обязательные. Так что + меняем на * и внешнюю просто убираем
.*;?.*?\r? — после жадной * стоит целый ряд необязательных символов.
Они никогда не будут иметь значения, поскольку необязательные выражения для парсера не повод вернуться и уменьшить покрытие жадного квантификатора. Скорее всего жертва изменений. После первой звезды остальное можно просто убрать.
\.([a-z\.]{2,6}) — разделитель внутри структуры.
Просто скажу что это покроет например несколько точек вместо tld, как задумывалось.
В продолжении
- метасимволы \s \d \w \b и unicode
- тонкости multiline
- позиционирование и предпросмотр
- … и прочая
