У разных электронных компаний вопросы на интервью немного отличаются. В одной интервьюер на скрининге (первом интервью) спросит кандидата на RTL позицию про конечный автомат, в другой про арбитр, кэш или конвейер, в третьей про упорядочение неупорядоченных транзакций. Но на большом интервью вопрос про очередь FIFO появится практически всегда - не первым/вторым, но третьим.
Это может быть элементарный вопрос "напишите на доске (физической, ха-ха, без доступа к интернету и ChatGPT) код для FIFO на D-триггерах". Или это может быть обсуждение микроархитектуры какого-нибудь извращенного FIFO, например FIFO с отменой вталкиваний, или с возможностью втолкнуть и вытолкнуть переменное количество кусков данных за такт, или с конвейером и кредитным счетчиком, или работающее на памяти с высокой латентностью, или асинхронное FIFO из статьи Клиффа Каммингса про пересечение тактового домена.
Эта заметка является сиквелом заметки "FIFO для самых маленьких", а также приквелом занятия в Школе синтеза цифровых схем в ближайшую субботу. Главное нововведение - все примеры и упражнения теперь делаются не только в симуляторе, но и на плате ПЛИС.
Новости Школы Синтеза и об авторах занятия
К Школе Синтеза присоединился двенадцатый участник - Томский Государственный Университет. На карте 11 кружочков, но в Москве две площадки - ВШЭ МИЭМ и МИРЭА:

В субботу сначала преподаватели зеленоградского МИЭТ Александр Силантьев и Евгений Примаков расскажут про внутреннюю структур ячеек ПЛИС, с ручным синтезом дизайна из них, а потом пройдет часть про FIFO. Занятие будет как всегда транслироваться на ютюбе с обсуждением в телеграме.
Занятие по FIFO проведет Владимир Ефимов, новый преподаватель Школы. Материалы готовили Рафаэль Ильясов и Андрей Зыков из казанского Иннополиса (анимации работы FIFO), преподаватель Самарского Университета Илья Кудрявцев (обзорная лекция по FIFO в прошлом году) и ваш покорный слуга (примеры кода). Мы также посматривали на слайды декана Черниговского Политехнического Университета Сергея Иванца, который делал презентацию про FIFO год назад.

Подготовка: Git и клонирование
Раньше примеры для школы скачивались в виде zip-файлов, но теперь мы решили приучать будущих разработчиков к системе управления версиями git. На Линуксе она либо стоит изначально, либо устанавливается с помощью менеджера пакетов.
Под Linux основанном на Debian (Ubuntu, Lubuntu, Astra Linux, Green Linux), а также под Linux ALT и Simply Linux, установка git делается с помощью:
sudo apt-get install gitПод РедОС и Rosa Linux - git вроде уже стоит, но если нет, его можно поставить таким же образом, только вместо "apt-get" использовать "yum" и "dnf" соответственно.
Под Windows git можно скачать, после чего во время установки поставить вместе с ним разные линуксные утилиты, которые нам пригодятся для запуска скриптов на баше:

Теперь вы можете клонировать репозиторий с примерами:
git clone https://gitflic.ru/project/yuri-panchul/valid-ready-etc.gitЕсли в процессе работы что-то пойдет не так, и вы заподозрите, что файлы в репозитории неправильные, вы можете клонировать более старую версию с тегом:
git clone -b v0.3-alpha https://gitflic.ru/project/yuri-panchul/valid-ready-etc.gitНедостаток клонирования с тегом: в то время как после обычного клонирования последней версии вы можете обновить файлы для следущих занятий с помощью простого "git pull", в версии с тегом вам нужно будет или клонироват�� новое дерево в новое место, или делать какие-то пляски с бубном, которые я не пробовал.
Важно!!! После скачивания вы обнаружите, что ни одно из упражнений не работает. Это так и задумывалось. Чтобы научиться писанию кода на верилоге, нужно не только читать, но и писать. Примеры заработают, когда вы их допишете - в некоторых достачно дописать три строчки, в других - страницу. Места, которые нужно дописывать, обозначены комментарием "// TODO".
Анимации и демонстрации
Вот как FIFO выглядит с точки зрения пользователя, то есть проектировщика, который вставляет FIFO в свой блок:

Это же можно увидеть на FPGA плате с помощью упражнения valid-ready-etc/boards/01_flip_flop_fifo/08_fifo_with_better_debug_1 . В видео Владимир Ефимов часто употребляет термин "буфер" как синоним "очереди FIFO". В общем случае это не синонимы, но вы предупреждены:
Важно понимать, что очередь FIFO - это не сдвиговый регистр. Чтобы объяснить эту разницу, среди упражнений есть и пример с сдвиговым регистром valid-ready-etc/boards/01_flip_flop_fifo/07_shift_register_to_compare . Анимация:

и на плате:
Другая пара анимации и демо на плате показывает, как FIFO реализовано внутри - с помощью указателей для записи и для чтения. В FIFO, в отличие от сдвигового регистра, перемещаются указатели, а не данные:
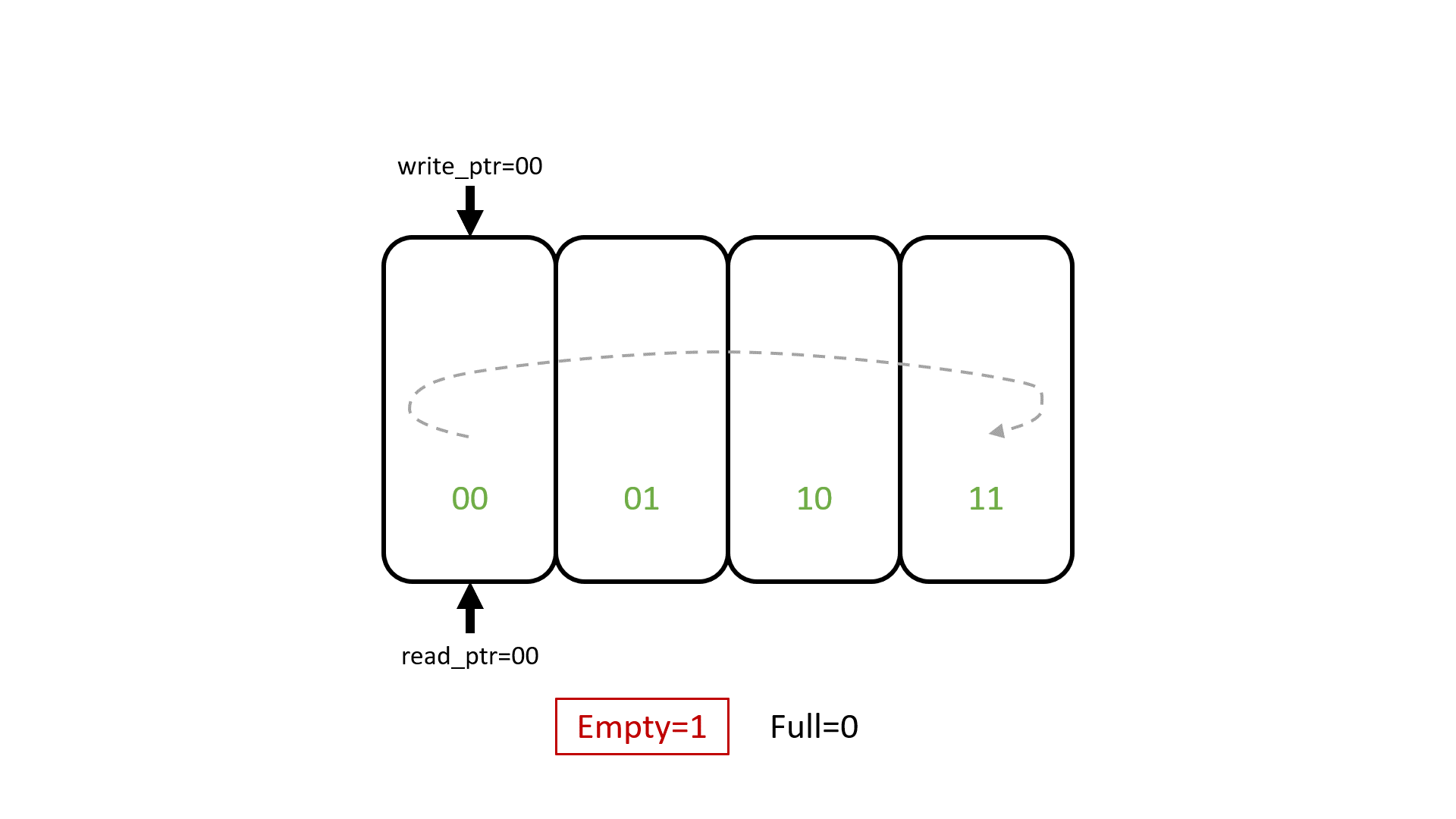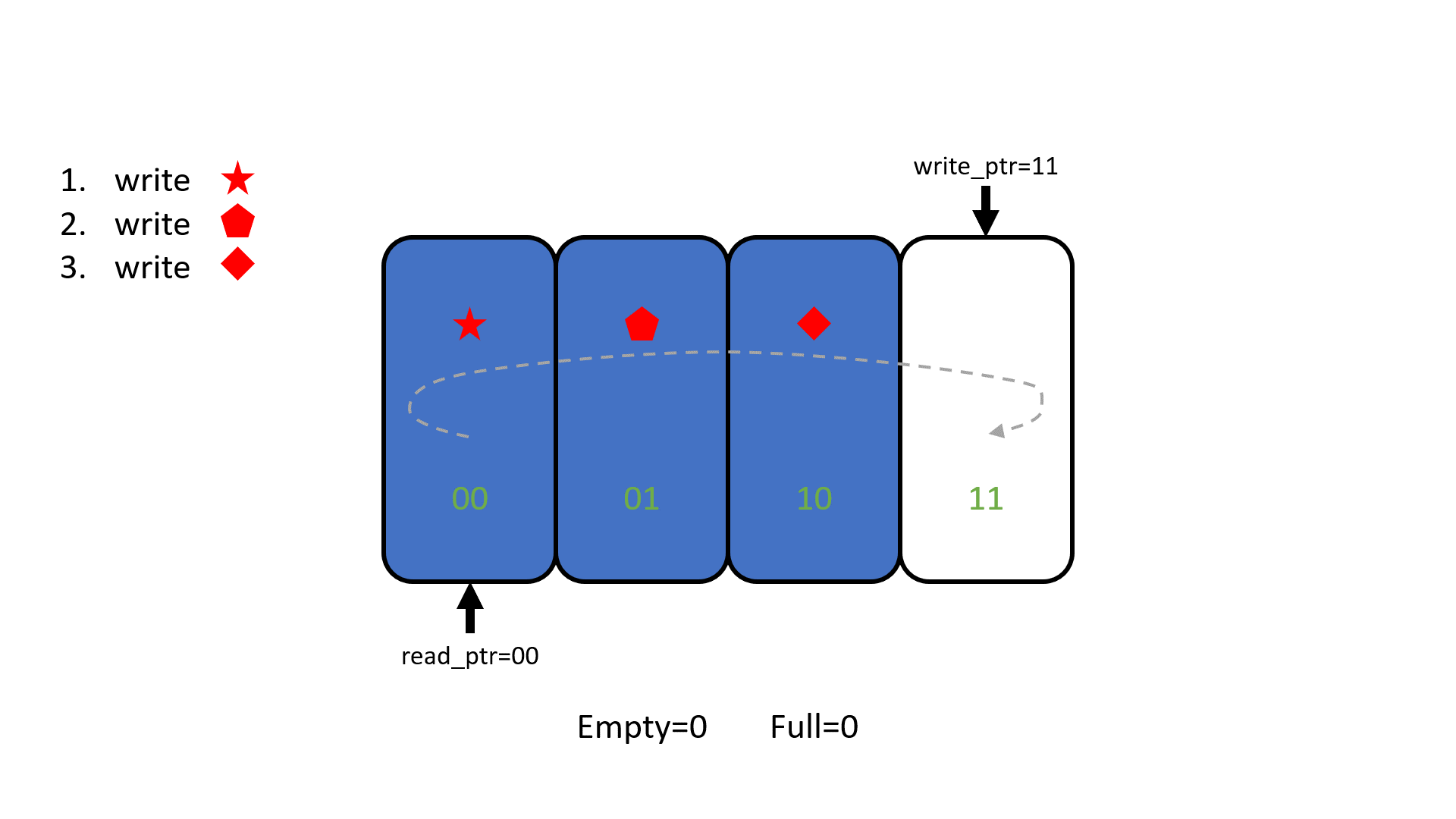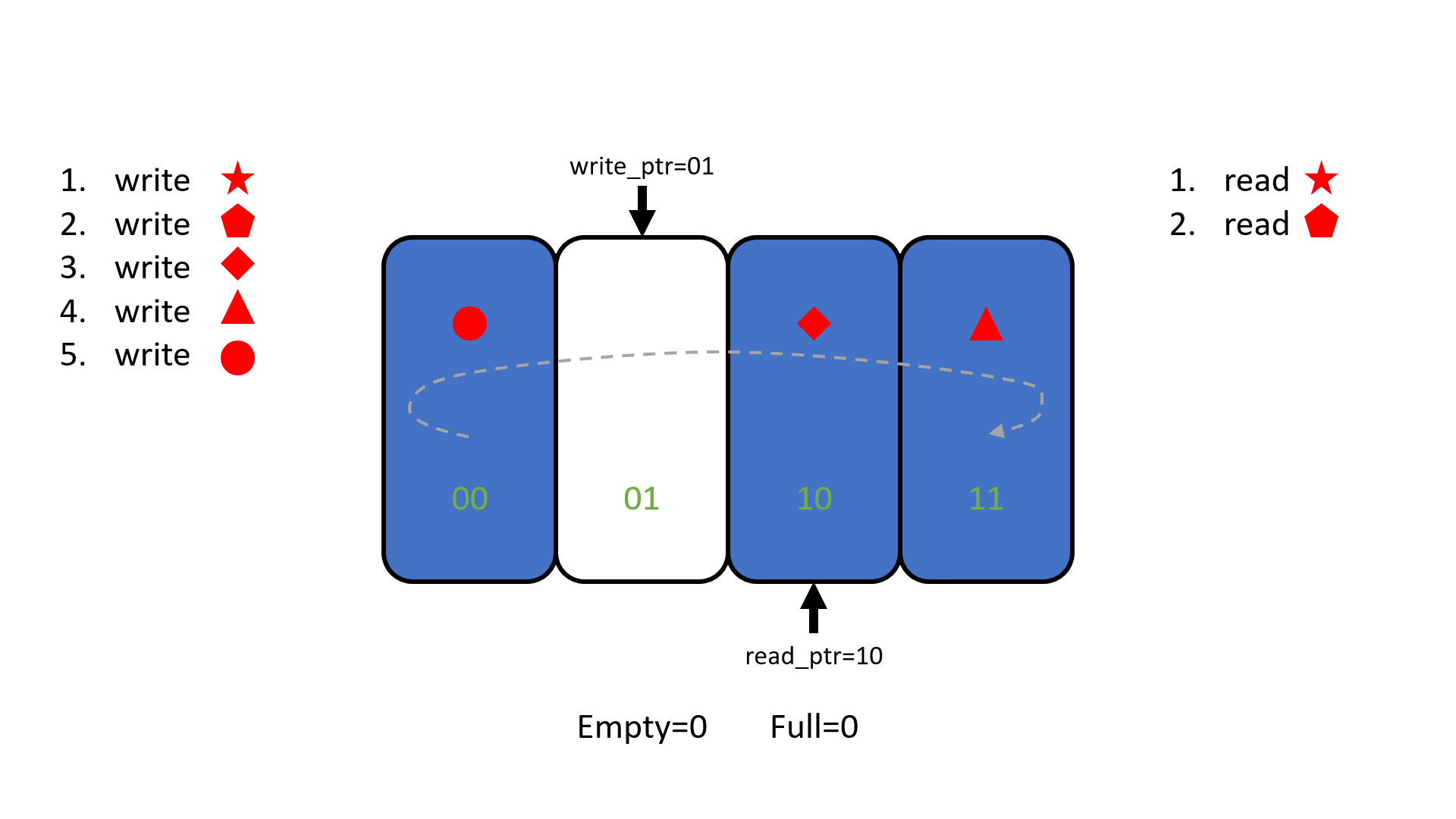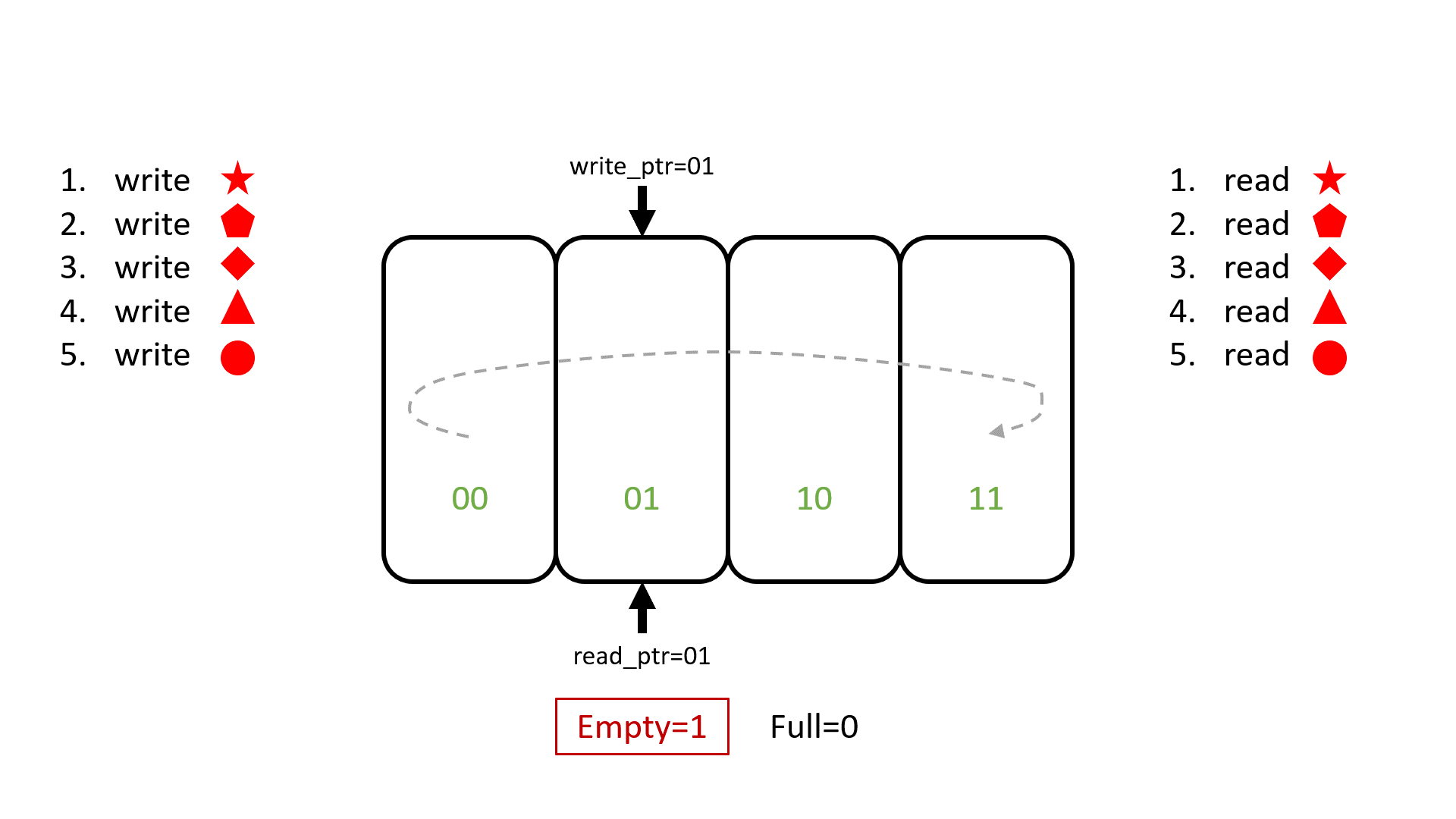
а теперь это же на плате в примере valid-ready-etc/boards/01_flip_flop_fifo/09_fifo_with_better_debug_2 :
Однако все три примера выше не только сознательно недописаны в публичном дистрибутиве, но еще и реализованы только для платы Terasic DE10-Lite. В то время как большинство участников Школы используют платы Omdazz или RzRd (Omdazz и RzRd отличаются друг от друга только порядком подсоединения ножек FPGA к светодиодам на плате). Для Omdazz мы будеи использовать в качестве базового пример valid-ready-etc/omdazz/01_flip_flop_fifo/01_flip_flop_fifo_with_counter_and_slow_clock , в котором на семисегментный индикатор выводятся, слева направо:
Бегущий счетчик, числа из которого будут запихиваться в FIFO.
Положение указателя записи, write pointer.
Точка у положения указателя записи, которая означает, что FIFO наполнено.
Положение указателя чтения, read pointer.
Точка у положения указателя чтения, которая означает, что FIFO пусто.
Значение верхушки FIFO, которое будет вытолкнуто следующим pop-ом.
Аналогичное упражнение на плате DE10-Lite выглядит похоже:
Медленный тактовый сигнал (clock) или сигнал разрешения (enable)?
Вы не могли не заметить, что как счетчик на входе FIFO, так и само FIFO работает отнюдь не на частоте 50 мегагерц (которую генерирует кварцевый генератор на плате), а скорее на частоте 1 герц. Как мы это сделали? PLL (если вы знаете что это такое) снизить частоту с 50 мегагерц до 1 герца не может.Поэтому мы действовали методом хоббистов - делили тактовый сигнал счетчиком - но с некоторым профессиональным улучшением. А именно: мы пропустили поделенный сигнал через специальный альтеровский примитив под названием global (в Xilinx его аналог называется BUFG), чтобы Quartus понял, что этот сигнал является тактовым, и пустил его по специальным соединениями для тактовых сигналов (clock tree). Без такого улучшения схему может глючить, я наблюдал такой эффект со схемой процессора.
Если вы не поняли, что написано в предыдущем абзаце, не волнуйтесь - это может вам объяснить Владимир Ефимов на занятии. А если не объяснит, то это неважно - я никогда не видел такой метод получения тактового сигнала в промышленных дизайнах, это трюк чисто для демо. Просто примите, что в FIFO для игры с ним на плате используется тактовый сигнал с частотой 1-2 герца, то бишь 1-2 биения в секунду. В коде это выглядит так:
module slow_clk_gen
# (
parameter w = 24
)
(
input clk,
input rst,
output slow_clk_raw
);
wire [w - 1:0] cnt;
counter # (w) i_counter (.cnt (cnt), .*);
// Note! You have to pass this clock though
// "global" primitive in Intel FPGA
// or BUFG primitive in Xilinx Vivado
assign slow_clk_raw = cnt [w - 1];
endmodule
module fpga_top
(
input clk,
. . . . . . . . .
wire slow_clk_raw, slow_clk;
slow_clk_gen # (26) i_slow_clk_gen (.slow_clk_raw (slow_clk_raw), .*);
// "global" is Intel FPGA-specific primitive to route
// a signal coming from data into clock tree
global i_global (.in (slow_clk_raw), .out (slow_clk));
. . . . . . . . .
flip_flop_fifo_with_counter
# (
.width (fifo_width),
.depth (fifo_depth)
)
i_fifo (.clk (slow_clk), .*);А можно сделать то же самое демо с FIFO, но без трюка с счетчиком и global? Если в промышленном дизайне проектировщик хочет замедлить получение данных, то корректный способ это сделать - это генерация сигнала разрешения, enable. В нашем случае это пульс на 1 такт 50-мегагерцового тактового сигнала, раз в секунду. Мы реализовали такое решение в valid-ready-etc/boards/omdazz/01_flip_flop_fifo/06_flip_flop_fifo_with_counter_and_clock_enable . Однако для демо оно неудобно, так как требует изменение внутренностей самого FIFO - добавления "if (enable)" внутри всех "always @ (posedge clk".
Философское отступление и тандем из FIFO
При обучении хардверному дизайну полезно знать, что для ученика может быть контринтуитивным. Это собственно и есть места, для которых нужен преподаватель, все остальное ученик выучит по книгам или догадается.
Например, по интуиции из программирования ученик может твердо подразумевать, что для чтения из очереди FIFO ему нужно сначала послать запрос (сделать сигнал pop=1), а потом получить ответ (прочитанное данное в следующем такте).
На самом деле для построения самого широко используемого FIFO на D-триггерах ментальная картина должна быть другой: данное к моменту pop на верхушке FIFO уже лежит и сигнал pop означает "я данное увидел, можешь о нем забыть, и пока я его обрабатываю, подгони на верхушку следующее данное".
У FIFO построенного таким образом есть очень полезное свойство: если поставить два таких FIFO друг за другом и просто соединить их проводами, то они будут функционировать как одно FIFO , без потери пропускной способности. В дизайне же "pop запрос-ответ"возникают всякие головные боли с написанием связывающей (glue) логики и с пропускной способностью.
Мы проиллюстрировали этот тезис упражнением valid-ready-etc/boards/omdazz/01_flip_flop_fifo/04_two_ff_fifos_back_to_back
FIFO с глубиной, равной степени двойки, и его обобщение
Для FIFO с глубиной, равной степени двойки, можно не проверять указатели при их увеличении на 1. Для этого случая также есть простая схема для определения состояний empty и full без счетчика.
valid-ready-etc/boards/omdazz/01_flip_flop_fifo/02_ff_fifo_pow2_depth
valid-ready-etc/boards/de10_lite/01_flip_flop_fifo/02_ff_fifo_pow2_depth
Почему-то во время интервью многие студенты на вопрос "напишите FIFO" пишут именно такое. А на вопрос "а это будет работать, если глубина FIFO - не степень двойки?" - задумываются. Кто виноват? Преподаватели? Случайно нагугленные тьюториалы где разбирается только такой частный случай?
Оправдание "мы просто хотели съэкономить логику за счет лишних D-триггеров" - не катит, так как для FIFO в пару тысяч D-триггеров потери от увеличения FIFO с глубины скажем 35 до глубины 64 при ширине скажем 50 бит - будет около полутора тысяч D-триггеров на ровном месте. Это плохо, так как D-триггеры - это не только место на кристалле, но и динамическое энергопотребление.
Особенно если у вас таких FIFO в дизайне сотни или тысячи. Потом у телефонов будут быстро садиться батарейки, а чипы для магистральных роутеров будут требовать специального жидкостного охлаждения.
(Упражнения по расчету необходимых размеров FIFO будут в Школе на одном из следующих занятий - для этого например используются данные о латентностях конвейеров и блоков статической памяти)
С другой стороны, можно обобщить идею из FIFO с глубиной степени двойки для оптимизации empty/full и для FIFO не с глубиной степени двойки, что мы и сделаем в следующем упражнении:
valid-ready-etc/boards/de10_lite/01_flip_flop_fifo/03_flip_flop_fifo_empty_full_optimized
valid-ready-etc/boards/omdazz/01_flip_flop_fifo/03_flip_flop_fifo_empty_full_optimized
Комбинационная логика после регистров - можно ли ее убрать?
В коде тестового окружения упражнений по FIFO вы могли заметить задержку #1. Она необходимо потому, что у нашего FIFO не все выводы выходят из регистров - после них есть еще немного комбинационной логики, в частности для вычисления признаков empty/full.
Но эти сигналы можно сделать и выходящими из регистров. Этому посвящено упражнение, которое Владимир Ефимов хочет предложить в качестве домашнего задания после субботнего занятия - valid-ready-etc/boards/01_flip_flop_fifo/05_ff_fifo_with_reg_empty_full
Вопрос по FIFO не для джунов, а для миддлов
Я же предлагаю в качестве домашнего задания следующий вопрос: напишите FIFO, в которое в одном такте можно было бы втолкнуть или один, или два куска данных, и вытолкнуть или один, или два куска данных. Причем данные образуют одну цепочку, это не два независимых канала. В обобщенном виде заголовок такого модуля должен выглядеть так:
module multi_push_multi_pop_fifo
# (
parameter w = 13, // fifo width
d = 19, // fifo_depth
n = 2, // max number of pushes or pops
nw = $clog2 (n + 1)
)
(
input clk,
input rst,
input [nw - 1:0] push,
input [n - 1:0][w - 1:0] push_data,
input [nw - 1:0] pop,
output [n - 1:0][w - 1:0] pop_data,
output [nw - 1:0] can_push, // how many items can I push
output [nw - 1:0] can_pop
);
// TODO: Implement the whole example
// with testbench and FPGA demo
endmoduleЕсли вы напишете функционально корректное красивое решение для N > 2 с полной верификацией, разумными результатами static timing analysis, разумным расходованием D-триггеров и демо на FPGA плате, то мне (и наверное не только мне) было бы интересно помотреть на ваше резюме. Но и для N = 2 тоже присылайте, я покритикую.
Как можно еще потренироваться
Как я уже упоминал, часть упражнений сделана только для платы Omdazz/RzRd, а другая - только для платы Terasic DE10-Lite. Для тех или иных студентов может быть хорошим упражнением перенести все упражнения на все платы, причем не только эти две, но еще и на:
ZEOWAA - я в свое время отправил ящик таких плат в казанский Иннополис, а пару месяцев назад я еще и нашел десяток таких плат у себя в гараже. Оказалось, что я заказал их еще в 2019 году, они пришли по почте в мое отсутствие и я о них забыл. Хотя эти платы больше не выпускаются, но я собираюсь использовать этот ящик для своих будущих семинаров, так как сами по себе платы достаточные.
PisWords-06 - я оставил несколько таких плат в Бишкекском университете АУЦА. Они, как и Zeowaa, больше не выпускаются, но те, что есть можно применять.
Tang Primer 20K - новая модная плата с китайским ПЛИС GoWin.
Digilent Nexys A7 - FPGA от Xilinx. Используется многими мировыми университетами, у меня тоже есть.
Digilent Basys3 - более дешевая плата от Xilinx, чем Nexys A7.

Приложение. Описание занятия в субботу
Весенний семестр: от базовых знаний - к профессиональным умениям
28 января ПЛИС изнутри и очереди FIFO
На этом занятии мы рассмотрим две темы, каждая по полтора-два часа.
Сначала мы изучим, как устроена микросхема ПЛИС внутри. Мы рассмотрим ее ячейки, которые состоят из элементов LUT (LookUp Table), D-триггеров и мультиплексоров; изучим, как эти ячейки соединяются и конфигурируются. Зачем мы изучим структуру блочной памяти и выполним упражнение по синтезу схемы “вручную”, используя макросы для ПЛИС Intel FPGA.
Вторая тема нашего занятия - это реализация очередей FIFO (First In First Out), ключевых блоков проектирования. Многие схемы в промышленности представляют из себя смесь из конвейеров для арифметических вычислений, соединенных очередями FIFO. Мы рассмотрим реализацию FIFO на D-триггерах и выполним упражнения на локальные оптимизации: FIFO с глубиной степени двойки и построение логики для empty/full без счетчика.
Одновременно с реализацией очереди FIFO в RTL мы изучим, как моделировать FIFO с помощью структуры данных “очередь” в SystemVerilog (queue[$]) и как использовать такую модель для создания динамического тестового окружения (dynamic testbench).
Мы также продемонстрируем работу FIFO на плате ПЛИС, где вы сможете вталкивать в FIFO и выталкивать из него числа кнопками. Для демонстрации мы покажем, как искусственно замедлять тактовый сигнал до частоты 1 герц, или контролировать операции одногерцовым сигналом разрешения. Мы будем отображать головной и хвостовой элементы FIFO, а также статусы “полное” и “пустое”, на семисегментном индикаторе.
Перед этим занятием может быть полезно пересмотреть обзорную лекцию Ильи Кудрявцева про FIFO с занятия 19 ноября 2022. На этом и следующих занятиях мы будем неоднократно возвращаться к темам, затронутым в лекции, но перенесем фокус с теории на практику.
В качестве домашнего задания вы получите вопрос с реального интервью: реализовать FIFO, которое позволяет запись в него или одного, или двух элементов за один такт, так же как и чтение или одного или двух элементов.
Решение не должно заставлять пользователя FIFO думать, какое данное уже записано, а какое нет. FIFO должно сообщать, есть ли в нем место для одного или двух элементов и потом принимать эти данные. FIFO также не должно расходовать D-триггеры на незаписанную информацию, если в течение многих тактов пишется только один элемент. Если в течение двух тактов писалось по одному элементу, FIFO должно позволить прочитать их сразу за один такт. Также если два элемента были записаны сразу, FIFO должно позволить их читать по одному. Если было записано два, а потом один, FIFO должно позволять читать их любым способом - три чтения по одному, или прочитать два а потом один, или прочитать один, а потом два.
Мы ждем от вас реализацию такого FIFO как в симуляции, так и на FPGA плате. Можете ли вы обобщить эту задачу на чтение и запись от 1 до N элементов за такт?
Больше информации - на сайте Школы Синтеза Цифровых Схем
Ждем вас на школе и онлайн!

