Специалистам по городскому планированию и урбанистам для проведения количественных исследований необходимо работать данными. Однако чиновники в РФ не спешат делиться городской статистикой открыто, выкладывая в открытый доступ только самый минимум информации. За рубежом ситуация обстоит чуть лучше, но все равно бывают случаи когда какого то датасета нет. (краткий обзор о необходимости и доступности открытых данных можно почитать тут.)
В этом случае приходится собирать данные самостоятельно. При этом не всегда речь идет о работе “в поле”, чаще всего вся информация и так есть в интернете, просто не все готовы ей делится. В этой статье я попытаюсь получить матрицу времен московского метрополитена, по пути реверсинжереним приложение Яндекс метро, а так же сделаем очень крутые визуализации полученной информации.
Постановка проблемы
Необходимо получить данные по времени в пути между любыми двумя станциями метро за любой год (так как Метро развивается, строятся новые станции, пересадки). Время в пути должно учитывать возможность пересадок (и их время).
Возможные решения
В метро ~300 станций, кажется что не особо много, но это C(300, 2) = 300! / (2! (300 - 2)!) = (300 * 299) / 2 = 44850 способов выбрать 2 из них. Любой ручной подсчет такого числа маршрутов обречен на провал. Использования API карт тоже сопряжённо с некоторыми проблемами - во-первых, оно учитывает время на спускса станции, во вторых у меня не будет доступа к архивным данным, так же для некоторых пар станций, маршрут на наземном транспорте окажется значительно быстрее чем с использованием подземки. Тогда путь на метро даже не будет предложен. Так же мне очень хотелось реверсинжинернуть какое-то мобильное приложение, так что идем к выбранному мной методу.

Приложения яндекс метро позволяет строить маршрут по подземке, а так же работает полностью офлайн - значит данные хранятся на телефоне пользователя. Запустив скачанный с компьютера и переброшенный по кабелю на телефон, не имеющий подключения к интернету, к радости для себя, обнаружил что приложение уже умело строить маршруты и ему не требовалось первичная синхронизация с сервером для подгрузки схем. Это означает что огромная база старых версий этой программы на 4pda позволит нам получить архивные данные о матрице времени метро почти любого города мира. Осталось только понять как это приложение устроено внутри.
APK файл
Я буду анализировать версию 2.05 за 2015 год. От версии к версии устройство базы данных, в которой хранится вся необходимая информация практический не менялось, вплоть до 2018 года. Тогда был произведен переход с sqlite на NoSQL базу данных, или проще говоря, данные стали хранить в JSONe (а структура осталось +- такой же).
Отрыв скачанный apk файл на компьютере с использованием zip архиватора мы увидим:
Папка метаинформация (META-INF): содержит файлы с подписями, сертификатами и манифестами приложения.
Папка ресурсы (res): содержит все ресурсы, такие как изображения, макеты и строки, используемые в приложении.
Код (classes.dex): содержит скомпилированный Java-код, который выполняет функции приложения.
Разное (lib): содержит библиотеки, которые используются приложением, например, для работы с изображениями или звуком.
Манифест (AndroidManifest.xml): содержит информацию о приложении, такую как имя пакета, разрешения и компоненты приложения.
Обратите внимание, что файлы в папке APK могут быть зашифрованы или сжаты, поэтому вы не сможете просто открыть их и прочитать содержимое. Если вы хотите изучить код и ресурсы приложения, вам нужно использовать специальные инструменты, такие как декомпилятор.
Однако в нашем случае база данных представляет собой незашифрованный sqlite файл по адресу res/raw/yandex2.db . В данном случае местонахождение этого файла было очевидным, однако для поиска в более сложных ситуациях можно использовать утилитами поиска по расширению и типу файла.
База данных
sqlite файлы проще всего изучать используя sqlitebrowser. Это свободное программное мультиплатформенная программное обеспечение с простым графическим интерфейсам смогло отрыть и нашу базу данных. Структура этой базы данных тоже не вызывает вопросов. Таблица stations содержит информацию о станциях, с указанием их названия, местоположения итп. Информация о пересадках содержится в таблице Transfer. Все оказалось сильно проще чем могло бы быть.
Новые версии
Данные хранятся в папке assets/metrokit/. Теперь JSON файлы прочтем Python-ом, переведя в Networkx Graph, тем более @Sakhar уже написал удобный скрипт, когда строил трехмерную карту метро.
names = json.loads(codecs.open( "l10n.json", "r", "utf_8_sig" ).read()) graph = json.loads(codecs.open( "data.json", "r", "utf_8_sig" ).read())nodeStdict={} for stop in graph['stops']['items']: nodeStdict[stop['nodeId']]=stop['stationId'] G=nx.Graph() for node in graph['nodes']['items']: G.add_node(node['id']) for link in graph['links']['items']: G.add_edge(link['fromNodeId'], link['toNodeId'], length=link['attributes']['time']) nodestoremove=[] for node in G.nodes(): if len(G.edges(node))<2: nodestoremove.append(node) for node in nodestoremove: G.remove_node(node) labels={} for node in G.nodes(): try: labels[node]=names['keysets']['generated'][nodeStdict[node]+'-name']['ru'] except: labels[node]='error'
Давайте посмотрим что у нас вышло:
nx.draw(G)

Схемка, конечно, попонятнее чем от Артемия Лебедева, но к концу статьи мы ее сделаем еще лучше. (Зато теперь понятно как появился логотип хабра, прим acsent1)
Теперь научимся строить маршрут между двумя станциями. Для этого можно использовать алгоритм Дейкстры. Про то, как он работает, написано уже тысячи статей (например тык), так что не будем на этом останавливаться, тем более он уже реализован в нашей библиотеке.
def calc_time(st1, st2): return nx.dijkstra_path_length(G, source=st1, target=st2, weight="length")/60 print(labels) # ... 'nd89811596': 'Римская', 'nd79168908': 'Крестьянская Застава', ... calc_time("nd89811596", "nd79168908") # 4
Как мы видим, получили ответ 4. Именно столько минут занимает путь между этими станциями. (Запрос через сайт выдает 5 минут в пути, однако возомжно он использует какую-то информацию о количестве подвижного состава в реальном времени.
Давайте теперь вычислим искомую матрицу. Очевидным решением было бы рассмотреть всевозможные пары станций и попытаться построить маршрут:
Однако такой способ жутко неэффективен. Если А и В соседние станции, а С находится в отдолении, то строя оптимальный маршрут А - С мы уже знаем (или почти знаем) время в пути по В - С, из-за приципов работы алгоритма Дейкстры. Однако мы про эту информацию “забываем” и строим маршрут заново. Для решения нашей задачи подойдет алгоритм Флойда — Уоршелла. (вот кстати та причина, по которой даже с использованием выскокоуровневых библиотек хорошо бы хотя бы представлять как работают алгоритмы.) NetworkX из коробки умеет и такое:
res: dict = nx.floyd_warshall(G) print(res)
Давайте попытаемся сделать что еще. Например найти количество станций в 20-и минутной окресности от данной. Решим в лоб
res = {} counter = {} for st1_id, st1_name in labels.items(): res[f"{st1_id}_{st1_name}"] = [] counter[f"{st1_id}_{st1_name}"] = 0 for st2_id, st2_name in labels.items(): if st1_id != st2_id and calc_time(st1_id, st2_id) < 20: res[f"{st1_id}_{st1_name}"].append(f"{st2_id}_{st2_name}") counter[f"{st1_id}_{st1_name}"] += 1 print(st1_name, st2_name)
Теперь можно попытаться его оптимизировать. Тут решение немного попроще - обход в ширину. (можно использовать nx.bfs_edges() или реализовать самим):
def get_stations_within_distance(G, source_node, distance): visited = set() queue = [(source_node, 0)] while queue: node, dist = queue.pop(0) visited.add(node) if dist < distance: neighbors = nx.neighbors(G, node) for neighbor in neighbors: if neighbor not in visited: queue.append((neighbor, dist + G[node][neighbor]['length'])) return visited
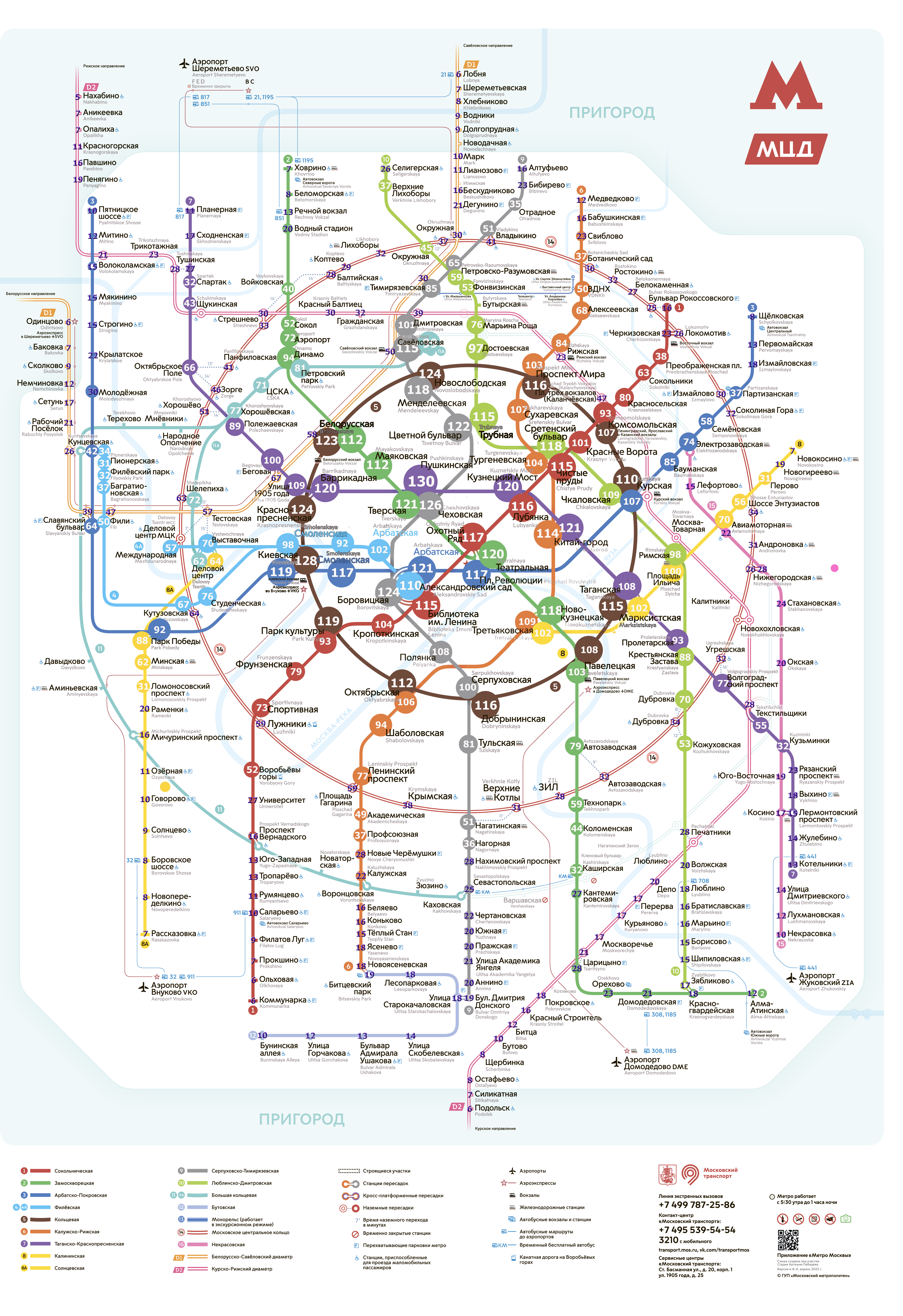
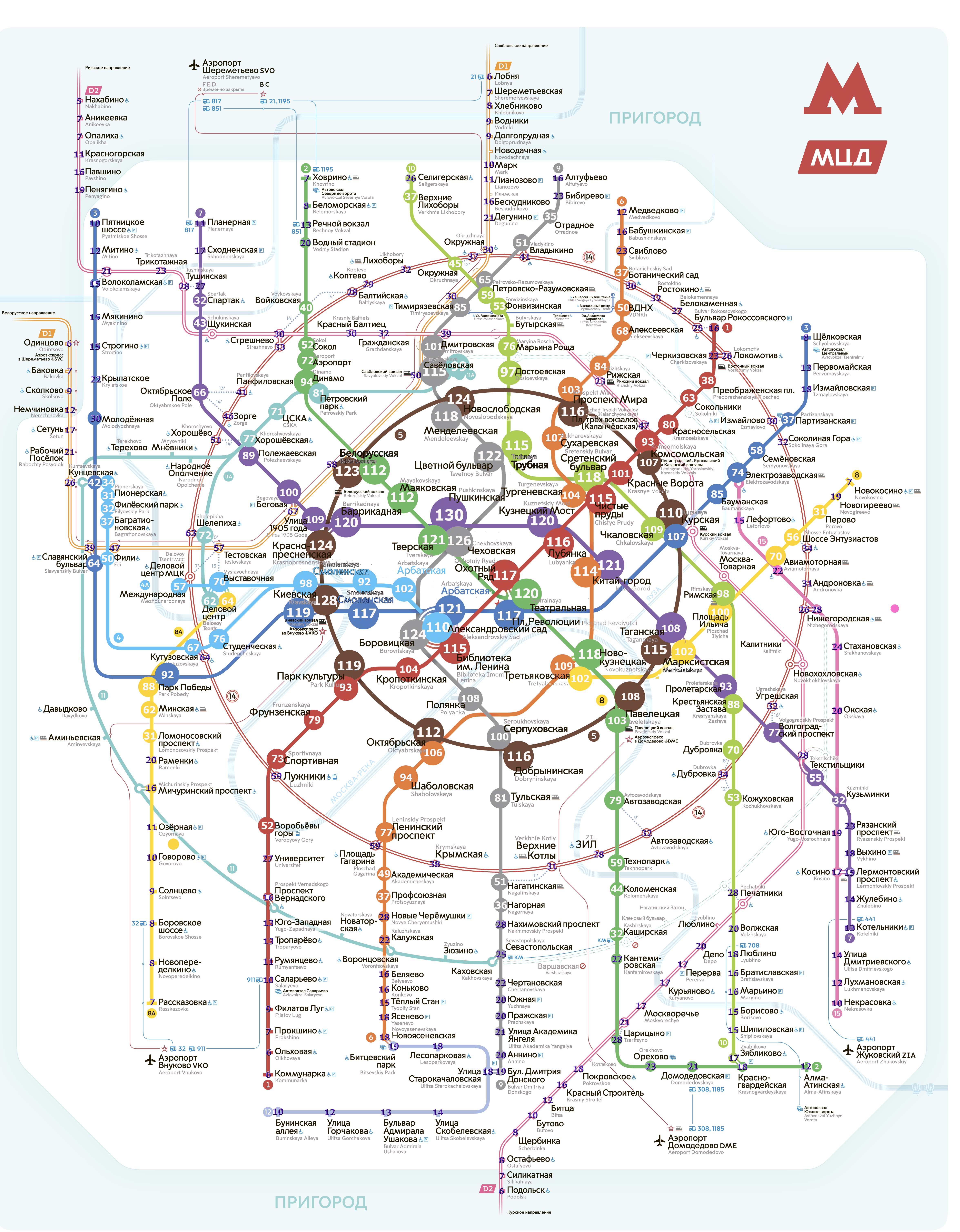
Теперь попытаемся визуализировать полученные данные. Немного магии компьютерного зрения и пару команд PIL позволяют построить вот такую красоту (исходник):

https://i.postimg.cc/szcs3D75/mcd-scheme-crop.png?dl=1
Тут размер круга пропорционален количеству других станций в 20-и минутном интервале. На этой картинке хорошо видно безумную разницу между центром города (где за 20 минут можно попасть на 100+ станций) и спальниками (где есть только один путь - в центр. Разумеется, всегда будут какие станции с большим, а какие-то с меньшим количеством удачных пересадок, плохо когда 100% хабов находятся в центре города

Метро Лондона, для справки
Так же использовать полученные нами данные можно, чтобы сделать более удобную карту метро. По ней можно будет оценить время в пути просто мелько взглянув на карту, без использования мобильных приложений или интерактивных экранов. В чем идея?
На каждой не кольцевой кольца мы пишем время в минутах, которое требуется для поездки до кольцевой на этой линии.
На каждой кольцевой станции мы пишем время в пути до какой-то фиксированной станции метро (например до Комсомольской).

Теперь что бы рассчитать время маршрута достаточно просто:
Вычесть (сложить, если мы переезжаем через кольцо) два указанных времени, для простых маршрутов без пересадок
Сложить два числа на станциях отправления и прибытия, а так же прибавить разность двух пересадок на кольце, если мы едем по пути радиус - кольцо - радиус.
В заключении
Надеюсь, что эта статья была кому-то полезна. Использование таких неочевидных источников данных как мобильное приложение, работающее в режиме оффлайн, может сильно помочь исследователям из стран не развивающих open data активно. Весь исходный код вы сможете найти в гугл колабе, но там довольно большой беспорядок, но разобраться будет проще чем все писать с нуля. Для его работы нужно загрузить JSON файлы с метрополитеном города.

{kind=link}
{kind=link}