Чем большее количество СУБД и ОС поддерживает какая-либо программа – тем больше у нее пользователей, и это хорошо для производителей программы. При этом нужно помнить, что поддержка каждой СУБД – это расходы на разработку и тестирование, и эти расходы хорошо бы минимизировать.
В этой статье мы расскажем о том, как нам удалось написать технологическую платформу, которая способна без изменения кода бизнес-приложения работать с самыми часто используемыми в бизнесе/организациях СУБД.
О том, как мы работаем без изменения кода бизнес-приложения на разных ОС – тут, с различными браузерами - тут, а как на разных мобильных ОС – здесь.

Для тех, кто не в теме 1С - короткий ликбез о технологической платформе 1С:Предприятие. Платформа 1С:Предприятие – это среда быстрой разработки бизнес-приложений. Мы старались спроектировать платформу так, чтобы разработчик бизнес-приложений (в терминологии 1С - прикладной разработчик) как можно меньше думал о том, на какой ОС и СУБД работает его код, да и в целом меньше думал именно о технических деталях, а сосредоточился на бизнес-задачах (подробнее об этом здесь).
Поэтому прикладной разработчик в 1С:Предприятии работает с прикладными же объектами (справочниками, документами, планами счетов и т.д.), не беспокоясь о том, как обеспечить их хранение в базе данных. Почему мы выбрали такой подход – написано в статье «Как мы в 1С:Предприятии работаем с моделями данных, или Почему мы не работаем с таблицами». А ещё необходимо обеспечить целостность и непротиворечивость данных. Т.к. работа может вестись под разными операционными системами, или у заказчиков могут быть установлены свои СУБД, то необходима поддержка наиболее распространенных СУБД. И данные из одной СУБД должны без проблем переноситься в другую.
Уже упомянутый прикладной разработчик сам создаёт объекты в приложении (конфигурации в терминах 1С:Предприятия):

У многих типов прикладных объектов можно добавлять реквизиты для хранения свойств этих объектов (которые являются отражением свойств объектов из реального мира – например наименования у товара). Наиболее близкий аналог реквизита – поле/свойство класса (property, field) в традиционных ООП-языках.
Платформа же сама создаст для этих объектов таблицы и обеспечит связи между этими таблицами. От прикладного разработчика скрыта вся «магия» конкретной СУБД и особенности синтаксиса её языка. Чаще всего разработка конфигурации ведётся в одной СУБД, а непосредственная работа с ней – в другой. Если конфигурация окажется успешной и будет установлена у большого числа пользователей, она может работать с такими СУБД, о которых прикладной разработчик даже не думал при её создании. Все сложности берет на себя платформа 1С:Предприятие.
Какие СУБД поддерживает 1С:Предпрятие?

В качестве «рабочей» СУБД, где хранятся бизнес-данные – четыре самые распространенные промышленные СУБД:
Microsoft SQL Server
PostgreSQL
Oracle Database
IBM DB2
Также существует собственный формат файловой базы данных 1С, предназначенный для работы небольшого числа пользователей.
Ещё есть Дата акселератор – in-memory СУБД нашей собственной разработки, которая хранит все данные в оперативной памяти (в нее копируются данные из рабочей СУБД) и сильно помогает при выполнении сложных аналитических отчетов, иногда ускоряя их выполнение на порядки.
При необходимости можно обратиться из конфигурации к любой другой СУБД, имеющей ODBC-драйвер, через механизм внешних источников данных.
Посмотрим на примере. Надо реализовать в приложении сущность «Товар» с подчиненной сущностью один-ко-многим «Дополнительные реквизиты». И уметь оперировать со списком товаров.

Наш любимый прикладной разработчик выбрал для реализации требования прикладной объект Справочник, позволяющий хранить данные, имеющие одинаковую структуру и списочный характер. Справочник также позволяет для каждого элемента справочника хранить некоторый набор информации, которая одинакова по своей структуре, но различна по количеству, для разных элементов справочника. Для этого у справочника есть подчиненные сущности – табличные части.
И прикладной разработчик создал справочник Товары с табличной частью ДополнительныеСвойства.

Если загрузить эту конфигурацию на разные СУБД, то видны отличия в наименованиях колонок.
Например, в MS SQL и PostgreSQL используется подчеркивание («_») в качестве первого символа.


В Oracle Database своя специфика:

А в IBM DB2 каждое текстовое поле дополнено ещё одним, с постфиксом «U» - там хранятся строки в верхнем регистре, т.к. IBM DB2 может выполнять только регистрозависимый поиск.

Кроме того, в IBM DB2 при работе с 1С:Предприятием используются не таблицы, а их так называемые алиасы, сами же таблицы имеют достаточно замысловатые имена.
Видите, сколько особенностей необходимо учесть? Но прикладному разработчику требуется не больше минуты, чтобы создать такую структуру в любой из поддерживаемых платформой СУБД. Особо хочется подчеркнуть, что прикладной разработчик не заботится о том, на какой конкретно СУБД будет создана структура для хранения данных и будут выполняться запросы на добавление, извлечение, обновление и удаление информации – всё за него сделает платформа «под капотом». Платформа 1С:Предприятие – не единственный фреймворк, обеспечивающий работу с разными СУБД, но один из немногих, обеспечивающий переносимость приложений между разными СУБД без модификации прикладного кода.
To ORM or not to ORM?
Опытный программист тут же скажет, что есть технология ORM (Object-Relational Mapping), обеспечивающая разработку в терминах классов, а не в терминах таблиц базы данных. И будет прав. Эта технология избавляет разработчика от необходимости писать запросы к базе данных и позволяет манипулировать только объектами. Тем более, что уже есть много готовых реализаций этой технологии. Например, для одной только Java:
…и множество других
Вот так примерно будет выглядеть реализация нашего справочника товаров на Hibernate. Мы создаем объект Товар и объект «Строка таблицы 1». Описываем с помощью аннотаций имена таблиц, для каждого класса – своя таблица. Также указываем, какие поля в каких колонках таблицы хранятся. И не забываем про связи между классами, которые потом превратятся в связи между таблицами.

В случае платформы 1С:Предприятие использовать классический ORM не получится, т.к. ORM компилируется вместе с исходным кодом приложения, разработка же конфигураций идет на встроенном языке 1С.
Как правило ORM поддерживают несколько СУБД. Но разработать с помощью ORM приложение, полностью нейтральное по отношению к типу СУБД, почти нереально. В частности, язык запросов ORM довольно прямолинейно транслируется в SQL. При этом, конечно, учитываются некоторые синтаксические детали диалекта SQL конкретной СУБД, но не более. Образно говоря, через языки запросов ORM "протекают" особенности конкретных СУБД.
И как ещё один аргумент против использования концепции Object-Relational Mapping для наших задач, стоит упомянуть, что прикладные разработчики на 1С пишут свои SQL-подобные запросы для доступа к данным.

Учтя всё вышеперечисленное, мы поняли, что для решения наших задач надо писать свой собственный ORM, и даже нечто большее, чем просто ORM. Что мы, в итоге, и сделали.
Язык запросов SDBL
Мы уже видели, что бывают случаи, когда одно свойство объекта преобразуется в два поля. Но бывают ещё и ситуации, когда один объект может состоять из нескольких таблиц. Например, есть прикладной объект «Регистр накопления», составляющий основу механизма учета движения средств (финансов, товаров, материалов и т. д.), который позволяет автоматизировать такие направления, как складской учет, взаиморасчеты, планирование.
Информация в регистре накопления хранится в виде записей, каждая из которых содержит значения измерений и соответствующие им значения ресурсов. Измерения описывают разрезы, в которых хранится информация, а в ресурсах регистра накапливаются нужные числовые данные. Также каждая запись хранит дату (она заполняется платформой автоматически из текущей даты, но прикладной разработчик может её переопределить).
Типичный пример использования регистра накопления – учет товарных запасов. Такой регистр будет содержать единственное измерение Товары и один ресурс – остаток товара. Можно добавить ещё одно измерение – Склад, и тогда мы сможем анализировать информацию не только по остаткам каждого товара в целом, но и по остаткам товаров на каждом складе.
Регистр накопления автоматически рассчитывает итоги по заданным промежуткам времени, что позволяет быстро составлять отчеты. Для реализации регистра накопления в базе данных создаются три таблицы:
Таблица движений (пришло/ушло в нашем случае товаров)
Таблица настроек хранения итогов регистров накопления (до какого момента рассчитаны итоги)
Таблица итогов по периодам времени

Также необходимо избежать потери данных при изменении объекта в конфигурации (например, добавление новых измерений и/или ресурсов или переименование или изменение типов существующих) и миграции на эту новую, измененную версию конфигурации.
Для решения вышеуказанных проблем нами был разработан специальный язык, который мы так и назвали - Special Database Language (SDBL). Это «промежуточный» язык для работы с данными. Любое взаимодействие с базой данных в платформе 1С:Предприятие происходит только через него – все запросы из встроенного языка 1С, все служебные запросы платформы, любая модификация данных объектов выполняются путем выполнения SDBL-запроса.
Например, прикладной разработчик пишет простой запрос к справочнику товаров для получения наименования и вида товара. Этот запрос транслируется платформой в язык SDBL, а затем запрос SDBL транслируется в запрос к конкретной СУБД:

Здесь – более сложный случай, когда разработчик хочет записать новый объект. Платформа автоматически присвоит объекту новый код (для чего найдет запросом максимальный код в справочнике), а затем выполнит вставку объекта в таблицу.

Как можно видеть, на уровне SDBL мы сразу описываем данные объекта и его табличной части. В итоге один запрос SDBL распадается на несколько запросов к СУБД: сначала – вставка в таблицу товаров, затем – вставка в таблицу единиц измерения, и в конце – проверка версии объекта для обеспечения согласованности данных.
Язык SDBL используется также в исходном коде платформы, что позволяет и в платформе писать СУБД-независимый код. В коде на С++ вся работа с данными идет только через SDBL. Например, мы хотим установить прикладному объекту новый код. Для этого в коде платформы формируется текст SDBL-запроса для поиска максимального существующего кода. Затем выполняется запуск этого запроса, который исполняется уже на конкретной СУБД:

А вот как установка нового кода работает на разных СУБД:

Синтаксис самого SQL – стандартный, но в случае каждой СУБД есть нюансы, и чем запрос сложнее – тем их больше.
Давайте посмотрим внутрь. Единицей исполнения SDBL является пакет. Пакет содержит один или несколько операторов SDBL. Существуют два вида пакетов:
Определения данных
Управления данными
Пакет определения данных
Пакет определения данных может содержать операторы:
CREATE
DROP
RENAME
REMOVE
SET_GENERATION
GET_NGENERATIONS
RESTORE
Например, нам нужно создать два справочника – Организации и Склады.

Для этого будет сформирован пакет SDBL, в котором описывается структура новых объектов и их индексов. Остальные операторы относятся к механизму реструктуризации. Механизм реструктуризации предназначен для миграции на новую версию конфигурации, если новая версия содержит изменения структуры прикладных объектов, и, как следствие, изменение структуры базы данных, подробнее про него будет ниже по тексту.

Пакет управления данными
Пакет управления данными может содержать операторы
SELECT
INSERT
DELETE
UPDATE
SET
LOCK
UNLOCK
DROP
Пример запроса 1С:

SQL-запрос для MS SQL Server:

Трансляция и оптимизация
Любое взаимодействие платформы с базой данных превращается в пакет SDBL. Затем этот пакет транслируется в диалект SQL для конкретной СУБД.
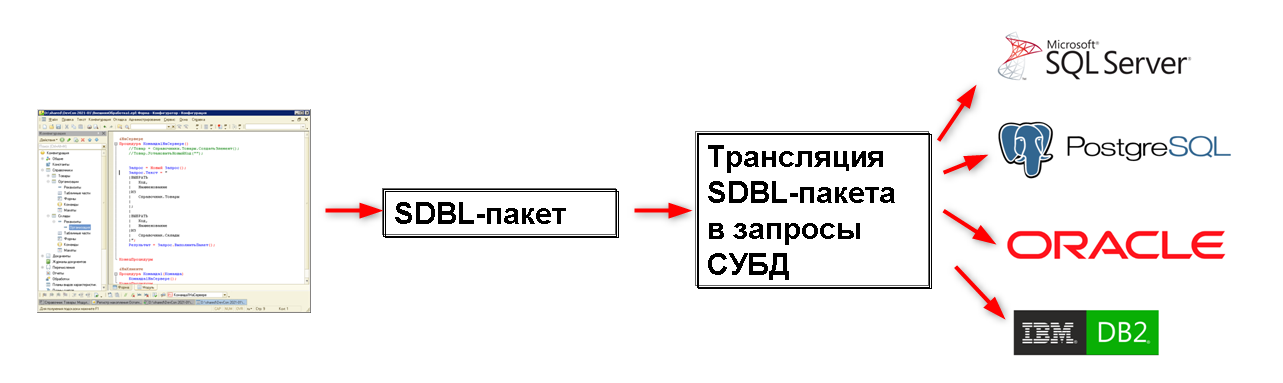
Под понятием трансляции пакета SDBL в диалект SQL скрыт большой и сложный механизм. Помимо собственно трансляции происходит оптимизация SDBL-запроса, добавление ограничений доступа для пользователя на уровне записей, если такие ограничения определены в конфигурации (Row-Level Security, RLS) и много другого. В конечном случае получается, что если нам необходимо поддержать ещё одну СУБД, то достаточно написать транслятор SDBL-запроса в диалект SQL этой СУБД.
Ещё одно преимущество SDBL – быстрая оптимизация запросов для каждой поддерживаемой СУБД. На примере ниже – реальный случай, когда служебный запрос платформы к остаткам регистра накопления (порожденный запросом из конкретной конфигурации) был неоптимальным на MS SQL. Неоптимальность заключалась в использовании оператора ИЛИ (OR) в секции условия отбора запроса.
Запрос и его план на тестовой базе выглядел так:


В итоге для того, чтобы выбрать около 2000 строк, запросу приходилось читать с диска почти 700 000 строк. Для оптимизации этого запроса было изменено условие отбора – оператор ИЛИ был заменен на операторы И НЕ.


Условие отбора был изменено внутри платформы в SDBL-запросе, таким образом, эта оптимизация будет применена для всех поддерживаемых СУБД.
Как мы видим – количество прочтенных строк сократилось более чем в 10 раз:

Реструктуризация данных
Прикладные разработчики могут в ходе разработки новых версий конфигураций менять структуру существующих объектов, добавлять новые объекты, удалять старые. При миграции на новую версию конфигурации некоторые такие изменения могут привести к нарушению целостности данных или даже к потере данных. Чтобы избежать таких проблем существует механизм реструктуризации, который также работает через SDBL.
Работает механизм реструктуризации примерно так:

Давайте попробуем разобраться в этом нагромождении окошек и стрелочек.
Итак, у товара (точнее, у прикладного объекта-справочника Товар) есть реквизит ВладелецТовара. Серым цветом выделено его текущее состояние. Этот реквизит имеет составной тип данных и может принимать значение типа Организация или Склад. В схеме SDBL он описан как реквизит составного типа.
В ходе разработки новой версии было принято решение что владельцем товара может быть только организация. Прикладной разработчик изменил тип реквизита. Теперь реквизит ВладелецТовара – не составной и ссылается только на справочник Организации.
После нажатия кнопки «Обновить конфигурацию базы данных» создается новое поколение таблицы товаров с помощью оператора SDBL “CREATE NEW GENERATION”, где реквизит ВладелецТовара уже не составной и является ссылкой на таблицу организаций. При этом в СУБД «лишние» колонки, которые предназначались для составного типа, помечаются постфиксами «_OO». Пользователю выдается предупреждение об изменении структуры справочника Товары. Если владельцем хотя бы одного товара был склад, то пользователь увидел бы ошибку, сообщающую, что реструктуризация не может быть выполнена, так как это приведет к потере данных, и изменения структуры данных не могут быть применены. Такое поведение платформы – защита от потери данных. В такой ситуации пользователь может найти все товары, владельцем которых является склад, и сознательно заменить владельца на нужную организацию. Но в целом при разработке конфигураций мы стараемся избегать таких изменений.
А в случае отказа от принятия изменений механизм реструктуризации выполнит команду SDBL “ROLLBACK” и вернет конфигурацию базы данных в прежнее состояние.
Если же изменения будут приняты, как показано на иллюстрации выше, то будет выполнен оператор «COMMIT» и база данных переключится на новое поколение, т.е. будут удалены «лишние» колонки таблицы товаров и реквизит ВладелецТовара изменит свой тип.
Внешние источники данных
А ещё через механизм внешних источников данных в конфигурации можно получить данные из любой ODBC-совместимой СУБД. Например, есть таблица работников в СУБД SQLite:

Для доступа к ней из 1С создаём внешний источник данных, пишем строку подключения к базе, выбираем таблицы и поля, нужные нам, и с помощью языка запросов 1С:Предприятия читаем данные:

Эта функциональность также работает через SDBL по знакомой нам схеме. Сначала запрос 1С преобразуется в SDBL, а затем – в запрос к конкретной используемой СУБД.

Транзакции в СУБД
Отдельно стоит упомянуть про такую большую тему, как блокировки данных и уровни изоляции транзакций. Каждая СУБД в этом плане ведёт себя по-разному. Где-то конкурентный доступ к данным управляется на уровне блокировок, когда одна транзакция блокирует работу с данными и другие транзакции в это время не могут работать с этими данными. В других СУБД используется версионный режим, когда перед началом транзакции делается копия данных, и другие транзакции получают данные из этого снимка, пока исходная транзакция не завершится.

Платформа 1С:Предприятие может использовать собственные так называемые управляемые блокировки данных.
Однако с точки зрения прикладного разработчика (да и разработчиков платформы) всё прозрачно – пишутся запросы (прикладным разработчиком на языке запросов 1С, разработчиком платформы – на SDBL). Ну а в случае необходимости у прикладного разработчика есть возможность самому управлять блокировками данных в тех случаях, когда бизнес-логика требует согласованного и целостного чтения данных в транзакции.
А транслятор для конкретной СУБД сам понимает, как управлять целостностью данных в транзакции.
