пролог и ссылка на оригинал
Это перевод-адаптация https://renegadeotter.com/2023/09/10/death-by-a-thousand-microservices с вкраплениями моих собственных мыслей. Я не профессиональный переводчик, просто во многом согласен с изложенным.
Церковь Великой Сложности
Начнём со скетча, в котором инженер объясняет менеджеру проекта как сильно переусложнённый лабиринт микросервисов работает, чтобы получить дату рождения пользователя - и ему не удаётся. Эта сцена точно показывает абсурдность текущего состояния технической культуры. Мы смеёмся, но поднятие этой темы в серьёзном профессиональном разговоре равносильно профессиональной ереси, делающей вас практически непригодным к трудоустройству.
Как мы к этому пришли? Как мы стали вместо решения наших задач, тратить кучи денег на решение проблем, которых у нас нет?
Предупреждение
Автор не обвиняет JavaScript или NodeJS и не пытается сделать их источником всех проблем, как может показаться из первого абзаца статьи.
Идеальный шторм
Существует несколько событий в недавней истории, которые, возможно, внесли свой вклад в текущее положение вещей.
Во-первых, целая армия разработчиков пишущих на JavaScript для браузера начали самоидентифицировать себя как "фул-стек", погружаясь в серверную разработку и асинхронный код. Javascript он и в африке Javascript. так ведь?
Какая разница что вы создаёте - пользовательские интерфейсы, серверы, игры или встроенные системы? Правда? Node была всё ещё чем-то вроде учебного проекта одного человека и ранний JavaScript был глубоко проблемным выбором для серверной разработки. Указание на это всё ещё зелёным серверным разработчикам обычно приводило к большому нагреву и подгораниям. Это всё что они знали, в конце концов. Мир вне Node будто бы не существовал, путь Node был единственным путём и так это стало причиной упрямого догматического мышления, с которым мы имеем дело по сей день.
А затем непрерывный поток ветеранов FAANG начал объединятся с рекой стартапов, обучая новоприбывших и впечатлительных молодых сервер-сайд JavaScript инженеров. Апостолы Церкви Великой Сложности настойчиво твердили, что "то, как они делают вещи в Гугле" это неоспоримо и правильно - даже если это не имеет никакого смысла при нынешнем контексте и размере проекта. Что значит, что ты не хочешь отдельный User Preferences Service? Это просто не скейлится, братан!
Но легко обвинять ветеранов и новоприбывших во всём. Что происходило ещё? Ах да - лёгкие деньги.
Что вы делаете, когда вас залили инвестициями? Вы не гонитесь за прибылью, конечно же! Не раз я получал письмо от менеджеров, просящих всех быть в офисе, прибраться на столах и выглядеть занятыми, так как прогноз обещает облако инвесторов прямо там. Инвесторы должны увидеть взрывной рост, но не в прибыльности, нет. Они просто должны увидеть как быстро компания может нанять ультра-дорогих инженеров чтобы сделать... что-нибудь.
И вот у вас есть эти программисты, что вы будете с ними делать? Ну, они могли бы построить более простую систему, которую легче развивать и поддерживать, а могли бы и вообразить монструозное созвездие "микросервисов", которое никто реально не понимает.
Микросервисы - новый путь написания скейлящихся программ! Будем ли мы притворяться, что концепция "распределённых систем" никогда не существовала? (Давайте опустим все нюансы насчёт того, что микросервисы не являются реальной распределённой системой)
В давние времена, когда IT индустрия ещё не была таким раздутым фарсом, распределённые системы уважали, боялись и в целом избегали - оставляя лишь как оружие последней надежды для редких кривых задач. С распределёнными системами всё становится более сложно и времязатратно: разработка, отладка, развёртывание, тестирование, надёжность. Но я не знаю, может быть это теперь супер легко с новым туууулингом?
Нет стандартного набора инструментов для разработки основанной на микросервисах - нет общего фреймворка. Работа над распределёнными системами стала лишь незначительно проще в этом десятилетии. Докеры и контейнеры не убрали магически присущую распределённым системам сложность.
Я люблю ссылаться на этот обзор 5 лет аудита стартапов, так как он наполнен выводами со здравым смыслом:
... среди стартапов, которые мы исследовали, лучшие обычно при разработке почти нагло придерживались принципа 'Keep It Simple' . Усложнение ради усложнения жестко каралось. С другой стороны, компании, в которые мы заходили с возгласами "вау, эти парни чертовски умные" в основном исчезли.
В целом, серьёзные грабли на которые многие наступили - преждевременный переход на микросервисы, архитектуры, основанные на распределённых вычислениях или на посылке большого количества сообщений
Буквально - "сложность убивает".
Этот аудит раскрыл интересную закономерность - стартапы испытывали что-то типа коллективного синдрома самозванца, создавая прямолинейные, простые, производительные системы. Вне зависимости от задачи, не решать её с помощью микросервисов с первого дня выглядит чем-то неприемлемым.
"Все делают микросервисы, а у нас один Django монолит, поддерживаемый всего несколькими инженерами да инстанс MySQL - что мы делаем не так?". Ответ почти всегда - "ничего".
от автора перевода
Лично для меня микросервисы на Python звучат как оксюморон. Язык, скрипты на котором должны заканчиваться до того как программа становится "макро" и для неё начинают иметь смысл такие понятия как архитектура используют, чтобы писать микросервисы, которые имеют хоть какой-то смысл, когда проект уже далеко не маленький.
К тому же очень часто опытные инженеры испытывают нерешительность и недоумение в нынешнем IT, и хорошие новости в том, что нет - проблема возможно не в вас. Команды часто притворяются, что занимаются "веб масштабированием", прячась за библиотеками, ORM и кешами - уверенные в своей экспертизе (они порешали этот Leetcode!), в то время как они даже не в курсе основ индексирования в базах данных. Вы работаете в море неоправданного самомнения, расточительства и Даннинга-Крюгера, так кто тут реальный самозванец?
Нет ничего плохого в монолите
Идея того, что вы не можете развиваться без системы, которая выглядит как печально известный слайд военной стратегии войны в Афганистане это миф
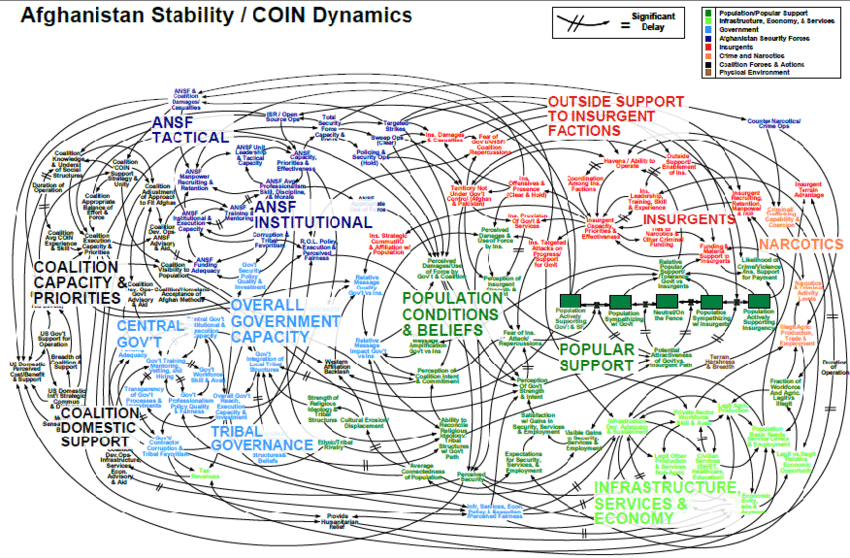
Dropbox, Twitter, Netflix, Facebook, GitHub, Instagram, Shopify, StackOverflow - эти и другие компании начали как монолиты. Многие имеют монолит до сих пор. StackOverflow считают за предмет гордости то, как мало железа им нужно для работы массивного сайта. Shopify всё ещё на монолите Ruby on Rails, используя проверенный и надёжный Resque для обработки миллиардов задач
от автора перевода
Некоторые компании умудряются сделать одновременно микросервисы физически и монолитную кодовую базу для них всех, в которой даже на уровне идеи версионирование отдельных частей отрицается
То есть для разработчика это всё ещё остается монолитом, а микросервисы лишь добавляют своих проблем.
Возможно, заявлять, что ваша конкретная задача требует массивной сложной распределённой системы и открытого офиса, забитого турбо-гениями это просто высокомерие, а не гениальность?
Не решайте проблемы, которых у вас нет
Это простой вопросы - что за проблему вы решаете? Масштабирование? Откуда вы знаете как разбить систему так, чтобы не растерять масштабирование и производительность? Имеете ли вы достаточно данных, чтобы понять что должно быть отдельным сервисом и почему? Распределённые системы строятся с учётом размера и устойчивости. Может ли ваша система масштабироваться и быть устойчивой одновременно? Что произойдёт если один из сервисов упадёт или будет перегружен? Просто масштабируете его? Что будет с другими сервисами, на которые пойдёт трафик? Проводили ли вы учения с бесконечными перестановками вещей, которые могут пойти не так? Есть ли защитные механизмы? Автоматические выключатели? Очереди? Jitter? Разумные таймауты для каждого ендпоинта?Существуют ли надёжные меры защиты, гарантирующие, что простое изменение не обвалит всю систему? Бесчисленные переключатели, за которыми нужно следить, и все они зависят от особенностей использования системы и конкретной нагрузки.
Правда в том, что большинство компаний никогда не достигнут такого размера, который потребует построения реальной распределённой системы. Ваш косплей Amazon и Google - без их размеров, экспертизы и бесконечных ресурсов - скорее всего просто вопиющая растрата денег и времени. Религиозное следование всем шагам из статьи названной "Десять утренних привычек очень успешных людей" не сделает вас миллиардером.
Единственная вещь сложнее распределённой системы - ПЛОХАЯ распределённая система

"Но команды... но раздельное... но API..."
Пытаться засунуть распределённую топологию в структуру вашей компании это благородное усилие, но оно почти всегда приводит к обратным результатам. Общий подход - разбирать проблему на мелкие части и решить их одну за другой. Итак, кажется будто из этого следует, что если вы разобьёте сервис на много сервисов, то всё станет легче.
от автора перевода
Как по мне, главное заблуждение тут в том, что для разделения команд и ответственностей в реальности не нужно физическое разделение программы на части. Вместо того чтобы писать отдельный микросервис с АПИ, почему бы не написать класс с интерфейсом. Может даже выделить под это команду.
Тогда как в нынешней разработке делают по микросервису на класс, а вызов функций заменяют на http запросы, причём пишут на это на С++ и считают, что код каким то магическим образом будет производительный просто потому что это С++, игнорируя то что они сделали буквально всё, чтобы от скорости света в вакууме их программа зависела больше, чем от выбранного языка программирования
Теория проста и элегантна - каждый микросервис хорошо поддерживается отдельной командой, скрытый за прекрасным, обратно-совместимым версионированным API. Он настолько незыблем, что вы даже редко коммуницируете с его командой - как если бы микросервис поддерживался третьесторонним вендором. Это просто!
Если это не кажется знакомым, это потому что так бывает редко. В реальности, каналы наших месседжеров забиты сообщениями от команд, сообщающих о релизах, багах, обновления конфигурации и breaking changes. Все должны знать всё и всегда. И если это ещё не выглядит совсем прекрасно, какая-то команда вовсе забросила почти все микросервисы и работает над одним, а остальные микросервисы постоянно меняют "ответственных", по мере того как люди приходят и сбегают.
В попытках победить гонку мы вместо строительства одного хорошего гоночного автомобиля строим флот дерьмовозок

вольный перевод картинки
Вопрос: Может ли монолит быть также эффективен как микросервисная архитектура?
Ответ: Нет, ему никогда не стать настолько же медленным
Что вы теряете
Создание микросервисов это минное поле и зачастую оно недооценивается или игнорируется. Команды тратят месяца, разрабатывая сильно кастомизированный инструментарий и изучая уроки, не относящиеся к самому продукту. Вот часто упускаемые из виду аспекты....
Попрощайтесь с DRY
После десятилетий обучения разработчиков написанию не повторяющегося кода(DRY), кажется мы вообще перестали об этом говорить. Микросервисы по дефолту не DRY, так как каждый сервис наполнен бесполезным бойлерплейтом. очень часто оверхед такого "заполнения" настолько велик, а размер микросервиса столь мал, что средний мкросервис имеет больше обслуживающего кода, чем "продуктового". Как насчёт общего кода, который можно выделить?
Есть общая библиотека?
Как обновлять общую библиотеку? Сохранять разные версии везде?
Форсить обновления регулярно, создавая десятки пулреквестов по всем репозиториям?
Сложить всё в один монорепозиторий? Это идёт со своим собственным набором проблем.
Разрешить некоторое дублирование кода?
Забудьте, каждая команда изобретёт колесо с нуля. Каждый раз.
Каждая компания пройдёт этот путь, встречая эти проблемы и тут нет хорошего "эргономичного" решения - вам придётся выбирать вашу версию боли.
Эргономика разработчиков ухудшится
"Эргономика разработчиков" - это трение, количество усилий, которое программист должен приложить, чтобы сделать что-нибудь. реализовать новую фичу или найти баг.
С микросервисами, инженер должен иметь ментальную модель всей системы, чтобы понимать какой сервис должен сделать конкретную задачу, к каким командам обращаться, с кем говорить и о чём. Принцип "Ты должен знать всё, перед тем как сделать хоть что-то". Как поддерживать это знание? Spotify, многомиллиардная компания, потратила вероятно не незначительное количество внутренних ресурсов для построения Backstage, приложения для категоризации их бесконечных систем и сервисов.
Это должно по крайней мере дать вам понимание, что эта игра не для всех и цена поездки высока. Так что насчёт тууулинга? Те-Кто-Не-Spotify остаются со своими решениями, о надёжности и портабельности которых вы можете вероятно догадаться.
И сколько команд на самом деле упрощают процесс создания YASS - "yet another stupid service"? Это включает:
Доступы разработчиков на Github/GitLab
Переменные окружения и конфигурации по умолчанию
CI/CD
Проверки качества код
Настройки код-ревью
Правила и защита бранчей (github)
Мониторинг и наблюдаемость
Тестирование
Infrastructure-as-code
И, конечно, умножьте этот список на количество языков, используемых во всей компании. Может быть у вас есть хороший шаблон или инструкция? Может быть, простая однокликовая система для запуска нового сервиса с нуля? Выковать такую автоматизацию занимает месяцы. Так что, вы можете либо решать свою задачу, либо создавать туууулинг.
Интеграционные тесты? ЛОЛ
Если ежедневного микросервисного гринда было недостаточно, вы также потеряете спокойствие ума, даруемое хорошими интеграционными тестами. Один микросервис прошёл юнит тесты, но прогоняются ли тесты после каждого коммита?(в каждый сервис!) Кто отвечает за общий набор интеграционных тестов, в Postman или где-нибудь ещё? Есть такая команда?
Интеграционные тесты в распределённой системе это почти неразрешимая проблема, так что в основном все сдаются и заменяют другим - Наблюдаение. Также как "микросервисы" это новые "распределённые системы", "наблюдение" это новый "дебаг в проде", Вы не пишите реальный код, если вы не делаете "наблюдение"!
от автора перевода
Просто совет, если на собеседовании вас просят написать код на листочке, добавляя что "не всегда у вас будет дебагер", то бегите. У них реально нет дебага и единственный способ что-то узнать, это отладка в проде + логи. А сломанный дизайн своей системы, из-за которой невозможен становится дебаг, они компенсируют биокомпьютерами, собеседование на один из которых проходите вы.
Наблюдаемость стала отдельным сектором и вы заплатите за неё и деньгами и временем разработчиков. И это тоже не идёт из коробки, вам придётся понять и реализовать канареечные релизы, флаги фич и так далее. Кто это сделает? Тот самый итак перегруженный инженер?
Что насчёт "сервисов"?
Почему сервисы должны быть "микро"? Что случилось с просто сервисами? Некоторые стартапы дошли до создания сервиса на каждую функцию, и да, "это как Лямбда чтоль?" валидный вопрос. Это раскрывает глаза на то, как далеко этот неконтролируемый карго культ зашёл.
Ну и что нам делать? Начать с монолита это очевидный выбор. Во многих случаях также может сработать паттерн “trunk & branches”, в котором главный "котлетка с пюрешкой" монолит пользуется вспомогательными сервисами. Вспомогательный сервис может заниматься легко отделяемой и масштабируемой работой. CPU-затратный СервисРесайзаИзображений имеет гораздо больше смысла, чем СервисРегистрацииЮзеров. Или вы получаете так много запросов на регистрацию в секунду, что это требует отдельного горизонтального масштабирования?

Маятник качнулся назад
Хайп, однако, кажется спадает. Поток денег венчурных фондов перекрывается, так что бизнесу под гнётом здравого смысла и рынка придётся делать выбор, осознавая, что возможно тратить деньги на масштабируемую веб архитектуру, когда у них нет проблем с веб масштабированием это невыгодно.



В конечном счёте, когда вам нужно поехать из Москвы в Петербург у вас как минимум две опции: попытаться сконструировать замысловатый космолёт для орбитального спуска к месту назначения или купить билет на <мне не платили за рекламу> и долететь за час. Вот в чём проблема.
от автора перевода
Я бы, конечно, не стал сравнивать поделки на микросервисах с космическим кораблём, ведь строятся они в основном не инженерами космолётов, а нанятыми по дешёвке слесарями, которые позавчера узнали о том как называется инструмент которым они крутят гайки(в их компании это называется "поднял 20 кг на собеседовании - и гайки крутить научится"), а производительность они исключительно теряют
